原文:Image Style Transfer Using Convolutional Neural Networks
一、IST(Image Style Transfer)基础
L c o n t e n t ( C , G ) = 1 4 n H [ l ] n W [ l ] n C [ l ] ∑ i j ( a i j [ l ] [ C ] − a i j [ l ] [ G ] ) 2 L_{content}(C,G)=\frac{1}{4n_H^{[l]}n_W^{[l]}n_C^{[l]}}\sum_{ij}(a_{ij}^{[l][C]}-a_{ij}^{[l][G]})^2 Lcontent(C,G)=4nH[l]nW[l]nC[l]1ij∑(aij[l][C]−aij[l][G])2
-
C C C 和 G G G 分别是内容图片和生成的图片(与风格图片融合后的)。
-
a i j [ l ] [ C ] a_{ij}^{[l][C]} aij[l][C] 是一个在内容图片 C C C 第 l l l 层第 i i i 个filter 第 j j j 个 activation 。
-
n H n_H nH、 n W n_W nW、 n C n_C nC 分别是隐藏层的高,宽和通道数。
G k k ′ [ l ] [ S ] = ∑ i = 1 n H [ l ] ∑ i = 1 n W [ l ] a i , j , k [ l ] [ S ] a i , j , k ′ [ l ] [ S ] G k k ′ [ l ] [ G ] = ∑ i = 1 n H [ l ] ∑ i = 1 n W [ l ] a i , j , k [ l ] [ G ] a i , j , k ′ [ l ] [ G ] G_{kk^{'}}^{[l][S]}=\sum_{i=1}^{n_H^{[l]}}\sum_{i=1}^{n_W^{[l]}}a_{i,j,k}^{[l][S]}a_{i,j,k^{'}}^{[l][S]} \quad G_{kk^{'}}^{[l][G]}=\sum_{i=1}^{n_H^{[l]}}\sum_{i=1}^{n_W^{[l]}}a_{i,j,k}^{[l][G]}a_{i,j,k^{'}}^{[l][G]} Gkk′[l][S]=i=1∑nH[l]i=1∑nW[l]ai,j,k[l][S]ai,j,k′[l][S]Gkk′[l][G]=i=1∑nH[l]i=1∑nW[l]ai,j,k[l][G]ai,j,k′[l][G]
L s t y l e ( S , G ) = ∑ l = 0 L ω l 1 ( 2 n H [ l ] n W [ l ] n C [ l ] ) 2 ∑ k ∑ k ′ ( G k k ′ [ l ] [ S ] − G k k ′ [ l ] [ G ] ) 2 L_{style}(S,G)=\sum_{l=0}^L \omega_l \frac{1}{(2n_H^{[l]}n_W^{[l]}n_C^{[l]})^2}\sum_{k}\sum_{k^{'}}(G_{kk^{'}}^{[l][S]}-G_{kk^{'}}^{[l][G]})^2 Lstyle(S,G)=l=0∑Lωl(2nH[l]nW[l]nC[l])21k∑k′∑(Gkk′[l][S]−Gkk′[l][G])2
-
G k k ′ [ l ] [ S ] G_{kk^{'}}^{[l][S]} Gkk′[l][S] 和 G k k ′ [ l ] [ G ] G_{kk^{'}}^{[l][G]} Gkk′[l][G] 分别是风格图片和生成图片第 l l l 层的第 k k k 和第 k ′ k' k′ 个特征图之间的相关系数构成的协方差矩阵。
-
ω l \omega_l ωl 是衡量每一层对总损失影响的权重因子。
-
n H n_H nH、 n W n_W nW、 n C n_C nC 分别是隐藏层的高,宽和通道数。
L ( G ) = α L c o n t e n t ( C , G ) + β L s t y l e ( S , G ) L(G)=\alpha L_{content}(C,G)+\beta L_{style}(S,G) L(G)=αLcontent(C,G)+βLstyle(S,G)
- α α α 和 β β β 分别是内容图片和风格图片重建损失的权重因子。
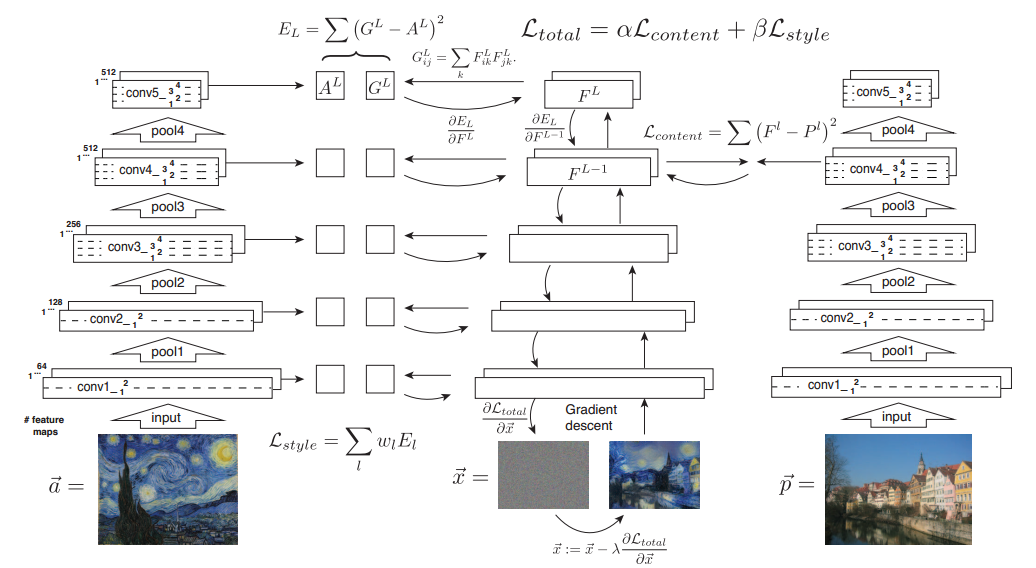
从论文的这幅图很明显可以看出风格损失在每一层都进行计算,最后分别乘上权重因子 ω \omega ω 再加起来。而内容损失只在conv_4进行。
二、代码解读(tensorflow $ pytorch)
1、VGG模型参数下载
2、tf 完整代码
3、py 完整代码
4、参考链接:TensorFlow Implementation of “A Neural Algorithm of Artistic Style”
#main.py
import os
import sys
import scipy.io
import scipy.misc
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
from PIL import Image
from nst_utils import *
import numpy as np
import tensorflow as tf
#matplotlib inline
def compute_content_cost(a_C, a_G):
"""
计算内容损失函数
参数:
a_C -- (1, n_H, n_W, n_C)维张量, 内容图片C隐藏层的activation;
a_G -- (1, n_H, n_W, n_C)维张量, 生成图片G隐藏层的activation。
"""
# 从 a_G 中取出维度
m, n_H, n_W, n_C = a_G.get_shape().as_list()
# 重塑 a_C 和a_G (≈2 lines)
a_C_unrolled = tf.reshape(tf.transpose(a_C, perm=[3, 2, 1, 0]), [n_C, n_H*n_W, -1])
a_G_unrolled = tf.reshape(tf.transpose(a_G, perm=[3, 2, 1, 0]), [n_C, n_H*n_W, -1])
# 计算损失
J_content = tf.reduce_sum(tf.square(tf.subtract(a_C_unrolled, a_G_unrolled))) / (4 * n_H * n_W * n_C)
return J_content
def gram_matrix(A):
"""
参数:
A -- (n_C, n_H*n_W)的矩阵
返回:
GA -- A的 Gram 矩阵 ,形状(n_C, n_C)
"""
GA = tf.matmul(A,tf.transpose(A))
return GA
def compute_layer_style_cost(a_S, a_G):
"""
参数:
a_S -- (1, n_H, n_W, n_C)维张量, 风格图片S隐藏层的activation。
a_G -- (1, n_H, n_W, n_C)维张量, 生成图片G隐藏层的activation。
"""
#从 a_G 中取出维度数据
m, n_H, n_W, n_C = a_G.get_shape().as_list()
# 重塑矩阵形状为(n_C, n_H*n_W)
a_S = tf.reshape(tf.transpose(a_S, perm=[3, 1, 2, 0]), [n_C, n_W*n_H])
a_G = tf.reshape(tf.transpose(a_G, perm=[3, 1, 2, 0]), [n_C, n_W*n_H])
# 计算S和G的gram矩阵
GS = gram_matrix(a_S)
GG = gram_matrix(a_G)
# 计算损失
J_style_layer = tf.reduce_sum(tf.square(tf.subtract(GS, GG))) / (4 * n_C**2 * (n_W * n_H)**2)
return J_style_layer
#选取一样的权重因子 w=0.2
STYLE_LAYERS = [
('conv1_1', 0.2),
('conv2_1', 0.2),
('conv3_1', 0.2),
('conv4_1', 0.2),
('conv5_1', 0.2)]
def compute_style_cost(model, STYLE_LAYERS):
"""
计算总的风格损失
参数:
model -- 我们的 tensorflow 模型
STYLE_LAYERS -- 一个列表包括:
- 我们取出的隐藏层的名字
- 每一层的系数
"""
# 初试化总的风格损失
J_style = 0
for layer_name, coeff in STYLE_LAYERS:
# 得到选定层的输出张量
out = model[layer_name]
a_S = sess.run(out)
a_G = out
# 计算当前层的风格损失
J_style_layer = compute_layer_style_cost(a_S, a_G)
# 加上系数构成总的损失
J_style += coeff * J_style_layer
return J_style
def total_cost(J_content, J_style, alpha = 10, beta = 40):
"""
计算总的损失
参数:
J_content -- 上面代码返回的内容损失
J_style -- 上面代码返回的风格损失
alpha -- 内容损失的权重超参数
beta -- 风格损失的权重超参数
"""
J = alpha*J_content + beta*J_style
return J
# 重置图
tf.reset_default_graph()
# 开启交互式会话
sess = tf.InteractiveSession()
#导入内容图片
content_image =scipy.misc.imread("images/louvre_small.jpg")
#加入噪声
content_image = reshape_and_normalize_image(content_image)
#导入风格图片
style_image = scipy.misc.imread("images/monet.jpg")
style_image = reshape_and_normalize_image(style_image)
generated_image = generate_noise_image(content_image)
#导入VGG19参数
model = load_vgg_model("pretrained-model/imagenet-vgg-verydeep-19.mat")
# 将加了噪声的内容图片assign到VGG模型的输入
sess.run(model['input'].assign(content_image))
# 选择conv4_2的输出张量(用于计算内容损失的Layer)
out = model['conv4_2']
a_C = sess.run(out)
a_G = out
# 计算内容损失
J_content = compute_content_cost(a_C, a_G)
# 将加了噪风格图片assign到VGG模型的输入
sess.run(model['input'].assign(style_image))
# 计算风格损失
J_style = compute_style_cost(model, STYLE_LAYERS)
J = total_cost(J_content, J_style, alpha = 10, beta = 40)
# 定义优化器
optimizer = tf.train.AdamOptimizer(2.0)
train_step = optimizer.minimize(J)
def model_nn(sess, input_image, num_iterations = 50):
sess.run(tf.global_variables_initializer())
sess.run(model['input'].assign(input_image))
for i in range(num_iterations):
sess.run(train_step)
generated_image = sess.run(model['input'])
# 每25次迭代打印一次.
if i%25 == 0:
Jt, Jc, Js = sess.run([J, J_content, J_style])
print("Iteration " + str(i) + " :")
print("total cost = " + str(Jt))
print("content cost = " + str(Jc))
print("style cost = " + str(Js))
# 保存迭代中的生成图片G
save_image("output/" + str(i) + ".png", generated_image)
# 保存最后的生成图片G
save_image('output/generated_image.jpg', generated_image)
return generated_image
model_nn(sess, generated_image)