在快速发展的人工智能(AI)领域,各种名词和术语层出不穷,尤其是模型、算法、模型库和框架这些概念,这些概念构成了AI领域的技术基石,但它们之间的区别和联系往往让人难以厘清。不少开发者和研究人员时常会混淆这些关键术语,而各种技术框架的名字也常常被误用,比如将TensorFlow误认为是一个模型,或是把BERT当成了一种算法?
但别担心,本文正是为了帮你捋清楚这些概念之间的差别和关系,同时列出一些主流的例子,帮助大家更好地理解这些概念。我们并不期望读者能够记住所有的细节,只希望通过这篇文章,大家能对这些技术有一个大致的了解,看到相关的词汇时能够有个眼熟,从而更好地应对AI开发中的各种挑战。
那么,究竟什么是模型?什么是算法?模型库和框架又有什么区别呢?接下来本文都将提供一个简洁而全面的视角。我们不会要求你记住每一个细节,而是希望通过这些例子,让你对这些概念有一个直观的感受。准备好了吗?来吧,让我们开始捋清AI领域的这些核心概念,让它们不再成为我们阅读和理解AI领域知识的绊脚石!
算法、模型、模型库、框架
什么是算法(Algorithm)?
算法(Algorithm):算法是解决某一特定问题的步骤或规则集合。在AI/ML领域中,算法是用于训练模型、优化参数和执行推理的数学规则和计算方法。算法是模型训练的核心,通过不断优化模型参数以最小化误差或最大化性能。
什么是模型(Model)?
模型(Model):在AI中,模型通常是指通过训练数据学习到的函数和参数的集合,用于执行特定任务。模型可以进行预测、分类、回归或其他数据处理任务。一个模型由架构(Architecture)、参数(Parameters)和训练方法(Training Method)组成。模型如神经网络会根据输入数据和设计目标进行调节,从而生成合理的输出。模型可以是浅层模型(如线性回归)或深层模型(如深度神经网络)。
什么是框架(Framework)?
框架(Framework):框架是为开发和训练AI模型提供的工具和库的集合。框架通常包含预定义的模块、算法和方法,简化模型的构建、训练、评估和部署过程。AI框架包括一些常用的工具和底层支持,如自动微分、优化器和数据加载器。框架的主要优点是提高效率和开发速度,减少实现复杂AI模型的技术门槛。
什么是模型库(Model Zoo)?
模型库(Model Zoo):模型库是一个集中存储并共享预训练好的模型的集合,可以从中下载并直接应用到不同的任务中。模型库通常包含各种各样的预训练模型,这些模型在大规模数据集上进行训练并经过验证,研究者和开发者可以直接使用这些模型进行迁移学习,或者作为基准进行模型改进。模型库的一个重要功能是提供方便的接口来载入和使用这些模型。
算法、模型和框架的关系
算法:用于训练和优化模型,是数学规则和方法的具体实现。例如,梯度下降算法用于优化模型的参数。
模型:由算法训练出的具体函数和参数集合,特定领域的数学和计算工具,用于解决特定任务。模型使用算法进行学习,从而在特定数据上执行任务。
框架:广泛的工具和库集合环境,使得构建、训练、和部署模型变得容易。涵盖算法和模型,提供开发和训练模型的工具和库,使构建和优化模型更加便捷。框架中包含了大量的预定义算法和模型架构,简化了开发流程。
简单来说,算法是用来训练模型的,而框架是提供开发和训练模型所需算法的工具包。
模型库与框架的差别
**模型库(Model Zoo)**是一个集中的存储系统,其中包含了各种预训练模型,用户可以从中下载并直接使用这些模型进行特定任务的训练或推理。
特点:
包含各种预训练模型,可以直接下载使用。
提供简便的接口和文档,方便集成到用户的项目中。
支持多种任务类型,如图像分类、目标检测、自然语言处理等。
促进模型复用,减少重复训练的时间和资源消耗。
例子:
TensorFlow Hub:提供了针对TensorFlow的预训练模型。
PyTorch Hub:社区贡献的PyTorch预训练模型。
Hugging Face Model Hub:广泛用于自然语言处理的预训练模型。
ONNX Model Zoo:提供跨框架的预训练模型。
**框架(Framework)**是用于开发、训练和部署AI模型的工具和库的集合。框架提供了丰富的API和工具,简化了模型的构建、训练、优化和推理过程。
特点:
提供快捷的开发工具和API,简化模型的构建和部署。
支持从数据预处理到模型训练、优化和部署的完整流程。
内置自动微分、优化器、数据加载器等模块,方便用户进行模型训练和调试。
支持分布式训练和大规模数据处理。
例子:
TensorFlow:提供了灵活的机器学习模型构建和部署工具。
PyTorch:动态计算图架构,适合研究和快速原型开发。
Keras:易用的高级API,底层支持TensorFlow和其他框架。
MXNet:支持多语言的分布式深度学习框架。
模型库与框架主要差别如下:
从功能上来说,框架提供了开发和训练AI模型的环境和工具,包括构建、优化和部署的全流程支持。而模型库提供了预训练好的模型,用户可以直接使用这些模型进行推理或微调。
从用途上来说,框架主要用于构建和训练新的模型,以及优化现有模型。模型库主要用于获取和复用已经训练好的模型,从而节省时间和计算资源。
依赖关系上来说,模型库通常依赖于特定的框架。例如,TensorFlow Hub 需要在TensorFlow框架中使用,PyTorch Hub 需要在PyTorch框架中使用。而框架可以独立运行,并且提供了接口以集成模型库中的模型。
总结来说,模型库和框架是两种不同但互补的工具。框架提供了开发和训练AI模型全流程所需的工具和API,模型库提供了预训练的高质量模型以供直接使用。
NLP模型与CV模型
什么是CV模型(Computer Vision Model)?
CV模型(Computer Vision Model):CV模型是专门用于处理和分析图像、视频等视觉数据的模型。这些模型用于任务如图像分类、对象检测、图像分割、人脸识别等。CV模型的特点包括处理二维像素数据、卷积操作(如卷积神经网络,CNN)和视觉数据上的特征提取技术工具。
什么是NLP模型(Natural Language Processing Model)?
NLP模型(Natural Language Processing Model):NLP模型专门用于处理和分析自然语言数据,比如文本和语音。这些模型用于任务如文本分类、情感分析、机器翻译、语音识别等。NLP模型需处理的是语法、语义、情感等语言特性。具有代表性的NLP模型包括循环神经网络(RNN)、长短期记忆网络(LSTM)、以及变压器(Transformer)模型。
CV模型 vs. NLP模型
CV模型处理图像和视频数据,侧重于视觉特征提取;NLP模型处理文本和语音数据,侧重于语言理解和生成。这两者在任务类型、数据特性、主要的模型结构和应用场景方面具有显著区别。
主流AI模型、算法、模型库、框架快速一览
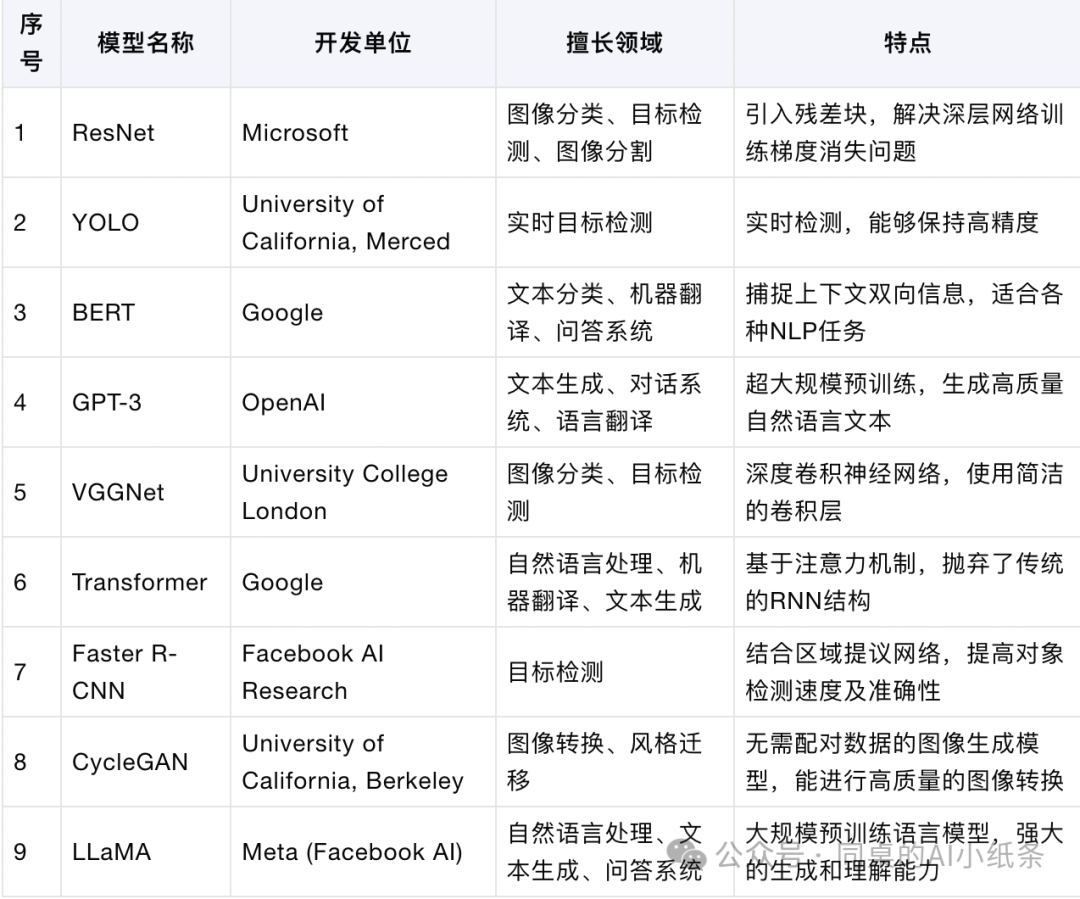
主流AI模型一览
主流AI算法一览
主流AI框架一览
主流AI模型库一览
主流AI模型及介绍
GPT系列模型(Generative Pre-trained Transformer)
由OpenAI开发,GPT(生成式预训练转换器)系列模型以其强大的语言理解和生成能力而闻名,特别是在处理自然语言处理(NLP)任务方面。GPT-4是该系列中的最新和最强大的模型。由OpenAI开发,特别是GPT-4,以其在性能和多种问题处理上的领先地位而闻名。GPT系列模型能够生成连贯的文本,进行问答,甚至编写代码,展现了强大的语言理解和生成能力。
特点:超大规模的预训练模型,具有生成高质量自然语言文本的能力。
应用:文章生成、自动代码生成、对话系统等。
LLaMA模型
LLaMA是Meta(前Facebook)发布的一个大规模语言模型,类似于OpenAI的GPT系列。它被设计用于处理各类自然语言任务,具有强大的生成和理解能力。LLaMA通过大规模预训练,能够在构建对话系统、自动文本生成等任务中表现出色。
特点:
大规模预训练语言模型,拥有数十亿参数,能够捕捉复杂的语言模式和含义。
能够执行多种NLP任务,包括文本生成、问答系统、文本摘要等。
强大的生成能力和语言理解能力,适用于各种自然语言处理应用。
**擅长领域:**自然语言处理(NLP)、文本生成、问答系统、机器翻译、文本摘要
BERT模型(Bidirectional Encoder Representations from Transformers)
Google开发的模型,使用双向Transformer进行预训练,以理解文本中的上下文依赖,对于NLP任务非常有效。
用途:文本分类、机器翻译、问答系统。
特点:基于Transformer架构,能够捕捉上下文的双向信息。
应用:广泛用于各种NLP任务,具有很好的迁移能力。
Transformer
由Hugging Face提供,Transformers是一个流行的开源库,支持多种预训练模型,包括BERT、GPT-2等,广泛应用于NLP任务。
一种端到端的序列到序列模型,使用自注意力机制代替传统的循环神经网络(RNN),在自然语言处理(NLP)和计算机视觉(CV)领域广泛应用。
ResNet(Residual Network残差网络)
同样是CV领域的重要模型,通过引入残差学习模块解决了深层网络的退化问题。
用途:图像分类、目标检测、图像分割。
特点:引入残差块,解决了深层网络训练时的梯度消失问题。
应用:大量应用于各种计算机视觉任务,如ImageNet上的冠军模型。
DenseNet(密集连接卷积网络)
在计算机视觉中用于图像分类、目标检测等任务,通过密集层之间的直接连接提高梯度流和参数效率。
YOLO(You Only Look Once)
一种实时目标检测系统,能在单次图像传递中同时预测物体边界框和类别概率。
用途:目标检测。
特点:实时目标检测算法,能够在检测过程中保持高精度。
应用:视频监控、无人驾驶等实时物体检测场景。
GANs(生成对抗网络)
包括一个生成器和一个判别器,用于生成逼真的图像、声音、文本等。
VAEs(变分自编码器)
一种生成模型,用于学习数据的概率分布,常用于图像生成和异常检测。
Faster R-CNN:
用途:目标检测。
特点:结合区域提议网络(RPN)和Fast R-CNN,提高了对象检测的速度和准确性。
应用:自动驾驶、图像搜索、安全监控等。
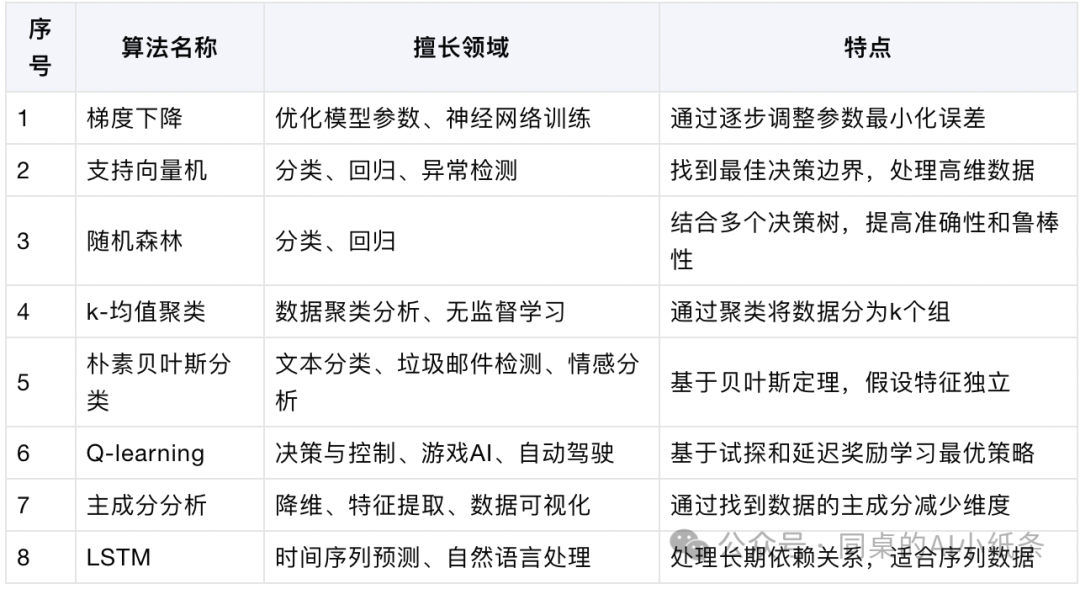
主流AI算法及介绍
主流算法主要特点快速一览:
梯度下降:通用优化算法,用于训练各种模型。
SVM:强大的分类算法,适用于高维数据集。
K-Means:常用于聚类分析的无监督学习算法。
随机森林:集成学习算法,通过组合多个决策树提高准确性。
Q-learning:用于强化学习任务,学习环境中的最优策略。
朴素贝叶斯:简单有效的分类算法,适用于文本分类等任务。
PCA:用于数据降维和特征提取。
接下来开始逐个详细的介绍
梯度下降(Gradient Descent):
用途:用于优化模型的参数,是训练神经网络的核心算法。
特点:通过逐步减少损失函数来找到模型参数的最优值,通常有批量梯度下降(BGD)、随机梯度下降(SGD)和迷你批量梯度下降(mini-batch GD)三种变体。
应用:广泛应用于各类机器学习模型和深度学习模型的训练过程。
支持向量机(Support Vector Machine, SVM):
用途:分类、回归和异常检测。
特点:找到最佳的决策边界,最大化类别间的间隔,使用核技巧(Kernel Trick)处理非线性问题。
应用:文本分类、人脸识别、图像分类等任务。
k-均值聚类(K-Means Clustering):
用途:无监督学习,主要用于数据聚类分析。
特点:将数据划分为k个簇,最小化簇内的平方误差和。
应用:客户分类、图像压缩、推荐系统等。
随机森林(Random Forest):
用途:分类、回归。
特点:集成多个决策树,通过多数投票或平均法提高模型的准确性和鲁棒性。
应用:金融预测、市场分析、医疗诊断等。
Q-learning(强化学习的一种):
用途:强化学习,主要用于决策和控制问题
特点:通过试探和延迟奖励来学习最优策略,不需要模型的状态转移矩阵。
应用:自动驾驶、游戏AI、机器人控制等。
朴素贝叶斯分类(Naive Bayes Classifier):
用途:分类任务。
特点:基于贝叶斯定理,假设特征之间独立,计算简单且效果很好。
应用:文本分类、垃圾邮件检测、情感分析等。
主成分分析(Principal Component Analysis, PCA):
用途:降维、特征提取。
特点:通过找到数据的主成分,减少维度,同时保持数据的主要变异性。
应用:数据可视化、降噪、特征工程等。
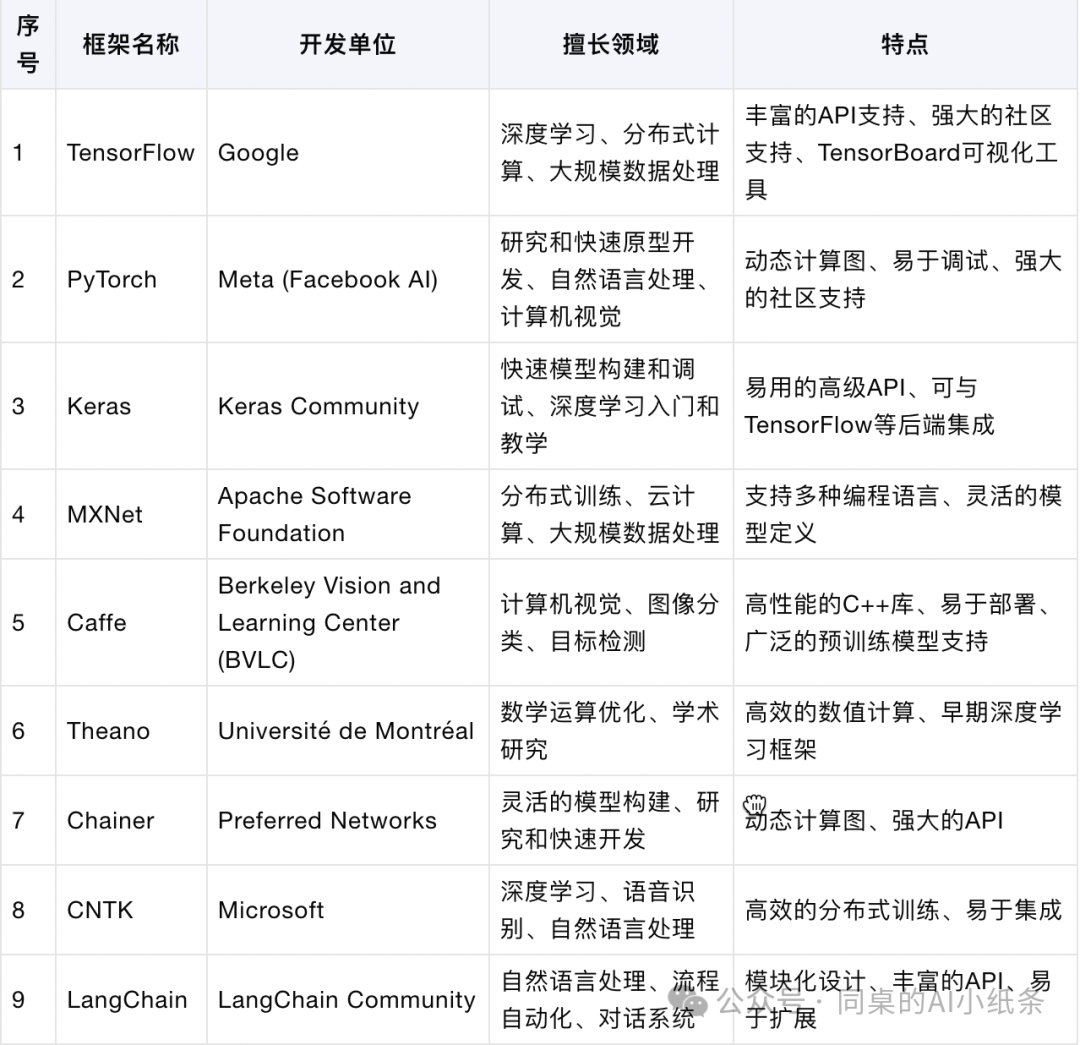
主流AI框架及介绍
PyTorch框架
由Meta AI(Facebook AI)开发,PyTorch是一个开源机器学习库,特别受学术界欢迎,因其动态计算图(Autograd)和易用性而闻名。以其动态计算图的灵活性和易用性成为深度学习研究的首选框架。PyTorch提供了强大的强化学习库,支持多种环境和算法
特点:动态计算图,容易调试和扩展,适合进行学术研究和快速原型开发。
应用:研究社区的迅速采纳,广泛用于自然语言处理和计算机视觉研究。
TensorFlow框架
由Google开发,TensorFlow是一个强大的机器学习平台,以其可扩展性和适用于生产环境而著称。广泛应用于图像识别、自然语言处理、语音识别等领域。它支持CPU、GPU和TPU等硬件加速器,提供了分布式训练的支持。
特点:提供了灵活的机器学习模型构建和部署工具,广泛支持深度学习模型和TensorBoard可视化工具。
应用:深度学习研究、工业级AI应用开发、大规模模型训练和分布式计算。
LangChain框架
LangChain是一个专注于构建和管理流程自动化的框架,尤其适用于处理自然语言任务。它提供了强大的API和工具,简化了自然语言处理(NLP)任务,如文本生成、对话管理、问答系统等。
特点:
强调流水线和模块化设计,方便用户构建复杂的NLP流程。
集成了多种预训练模型,能够轻松实现对多种NLP任务的处理。
丰富的接口和工具,支持扩展功能和自定义流程。
擅长领域:自然语言处理(NLP)、流程自动化、对话系统、文本生成和理解
Keras框架
Keras框架是由Francois Chollet开发的,是一个高层神经网络API,可以作为TensorFlow的接口使用,它以简单性和易用性而受到初学者和研究人员的青睐。Keras的设计目标是易用性、灵活性以及可扩展性,它使得构建深度学习模型变得更加简单直观。
特点:简单易用的API,快速实现和调试深度学习模型,底层支持TensorFlow。
应用:快速开发原型、进行小规模模型训练、教育和教学。
Caffe框架
由伯克利视觉和学习中心Berkeley Vision and Learning Center (BVLC)开发,Caffe是一个专注于速度和模块化的深度学习框架,特别适合于计算机视觉任务。
特点:高效的C++库,专注于卷积神经网络(CNN),适合图像分类和分割任务。
应用:学术研究、工业界实际应用、大型数据集处理。
MXNet框架
由Apache软件基金会开发和维护的开源项目,MXNet是一个灵活且高效的深度学习框架,支持多种语言和平台。
特点:分布式深度学习框架,支持多种编程语言(如Python、Scala、Julia),具有适用于计算机视觉、自然语言处理、时间序列等的工具包和库。
应用:大规模深度学习训练、分布式计算、云计算集成。
Theano框架
Theano是一个数值计算库,允许用户定义、优化和评估涉及多维数组的数学表达式。
Microsoft Cognitive Toolkit(CNTK)
由微软开发,CNTK是一个开源的深度学习工具包,支持多台计算机和GPU上的分布式训练。
MindSpore
华为推出的新一代全场景AI计算框架,旨在实现易开发、高效执行、全场景覆盖。MindSpore支持云、边缘以及端侧场景,提供了简单的开发体验和灵活的调试模式
PaddlePaddle
百度推出的深度学习框架,是一个开源深度学习平台,支持多种深度学习模型,并且提供了丰富的API和工具。PaddlePaddle支持多种深度学习模型和算法,广泛应用于工业界和学术界AI领域涉及的模型和框架非常广泛,涵盖了从机器学习到深度学习的各种技术和应用。
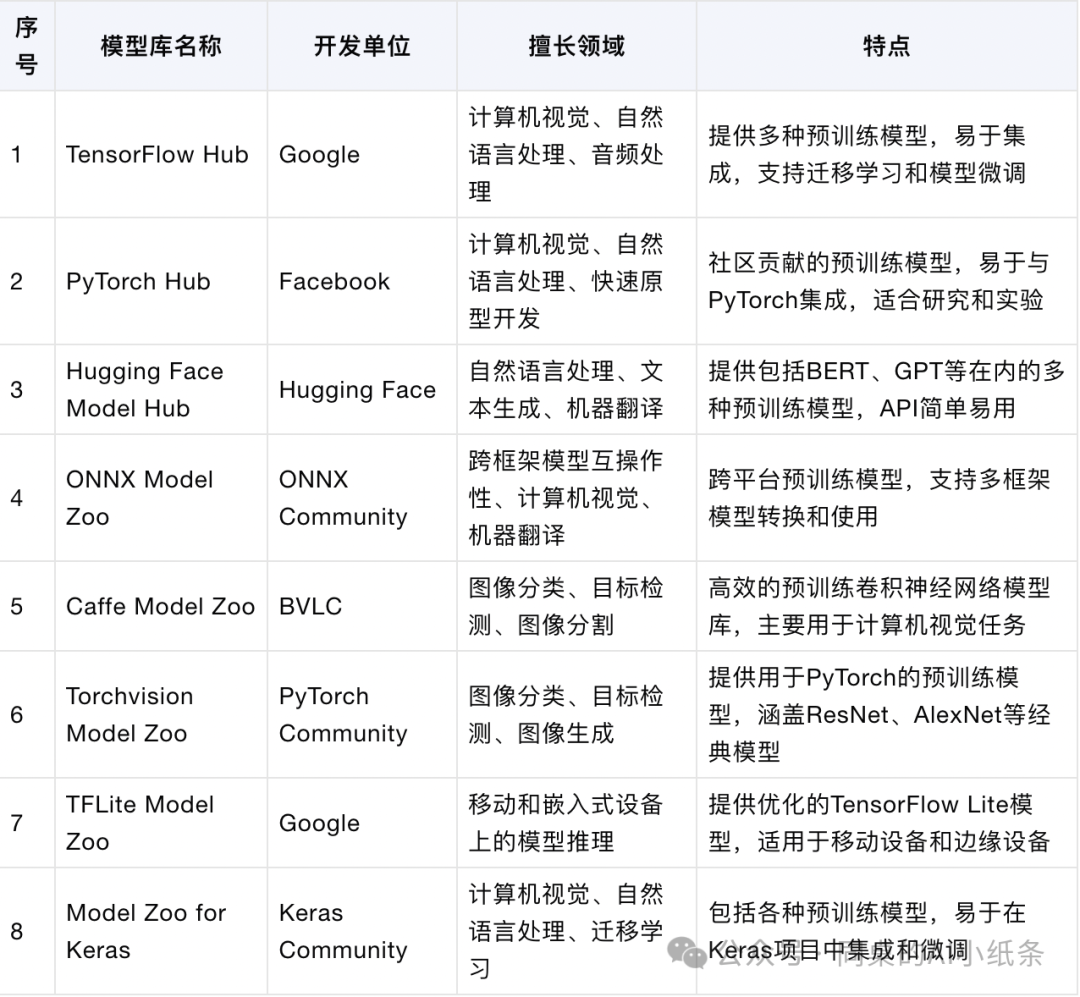
主流模型库介绍
模型库(Model Zoo)提供了多种预训练的高质量模型,供用户方便快捷地下载、使用和微调。不同的模型库对应不同的框架和应用场景,快速一览:
TensorFlow Hub 和 TFLite Model Zoo 专注于TensorFlow生态系统,适合大规模数据处理和移动设备上的推理。
PyTorch Hub 和 Torchvision Model Zoo 提供了适用于PyTorch的模型库,广泛用于学术研究和工业应用。
Hugging Face Model Hub 强调自然语言处理,特别适用于文本生成和机器翻译。
ONNX Model Zoo 提供跨框架的模型互操作性,适用于多框架集成。
Caffe Model Zoo 专注于计算机视觉任务,提供高效的预训练模型。
Model Zoo for Keras 提供简易集成和微调的模型,适合快速开发和实验。
接下来逐个详细介绍:
TensorFlow Hub
开发单位:Google
特点:TensorFlow Hub 提供了多种预训练模型,包括文本、图像、视频等领域的模型。它让用户可以轻松地将这些模型集成到TensorFlow项目中。
应用:TensorFlow Hub 上的模型广泛用于迁移学习、特征提取和模型微调,大大减少了从头开始训练模型所需的时间和资源。
使用示例:
import tensorflow_hub as hub
model = hub.load(“https://tfhub.dev/google/imagenet/mobilenet_v2_100_224/classification/5”)
PyTorch Hub
开发单位:Facebook
特点:PyTorch Hub 提供了社区贡献的预训练模型,并可以与PyTorch轻松地链接。这些模型涵盖了计算机视觉、自然语言处理等多个领域。
应用:PyTorch Hub 全面支持迁移学习和快速原型开发,用户可以利用它在自己的数据集上进行微调,从而获得好的结果。
使用示例:
import torch
model = torch.hub.load(‘pytorch/vision:v0.10.0’, ‘resnet50’, pretrained=True)
Model Zoo for PyTorch
开发单位:社区
特点:Model Zoo for PyTorch 提供了高质量的预训练模型,并附有详尽的文档和教程,帮助用户快速上手并使用这些模型。
应用:适用于各种研究和开发,特别是深度学习里面的计算机视觉和自然语言处理等领域。
使用示例:
from torchvision import models
resnet50 = models.resnet50(pretrained=True)
Hugging Face Model Hub
开发单位:Hugging Face
特点:Hugging Face Model Hub 专注于自然语言处理(NLP)领域,提供了超过数千个预训练的NLP模型,包括BERT、GPT等主流模型。它提供了简单的API来加载和使用这些模型。
应用:广泛应用于文本分类、情感分析、机器翻译等NLP任务。
使用示例:
from transformers import pipeline
classifier = pipeline(‘sentiment-analysis’)
result = classifier(‘We are very happy to show you the 🤗 Transformers library.’)
ONNX Model Zoo
开发单位:ONNX community
特点:ONNX Model Zoo 是一个跨平台的模型仓库,旨在提供各种框架(如TensorFlow、PyTorch、Caffe等)之间的互操作性。模型库中包含了多个框架转换后的预训练模型。
应用:在不同的深度学习框架之间迁移模型,并在不同的硬件平台上进行推理和优化。
使用示例:
import onnx
model = onnx.load(‘model.onnx’)
Caffe Model Zoo
开发单位:Berkeley Vision and Learning Center (BVLC)
特点:Caffe Model Zoo 提供了大量预训练的卷积神经网络模型,这些模型主要用于计算机视觉任务,如图像分类和目标检测。
应用:主要用于计算机视觉研究和应用开发。
使用示例:
import caffe
net= caffe.Net(‘deploy.prototxt’, ‘weights.caffemodel’, caffe.TEST)
随着大模型的持续爆火,各行各业都在开发搭建属于自己企业的私有化大模型,那么势必会需要大量大模型人才,同时也会带来大批量的岗位?“雷军曾说过:站在风口,猪都能飞起来”可以说现在大模型就是当下风口,是一个可以改变自身的机会,就看我们能不能抓住了。
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场
L2级别:AI大模型API应用开发工程
L3级别:大模型应用架构进阶实践
L4级别:大模型微调与私有化部署
一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
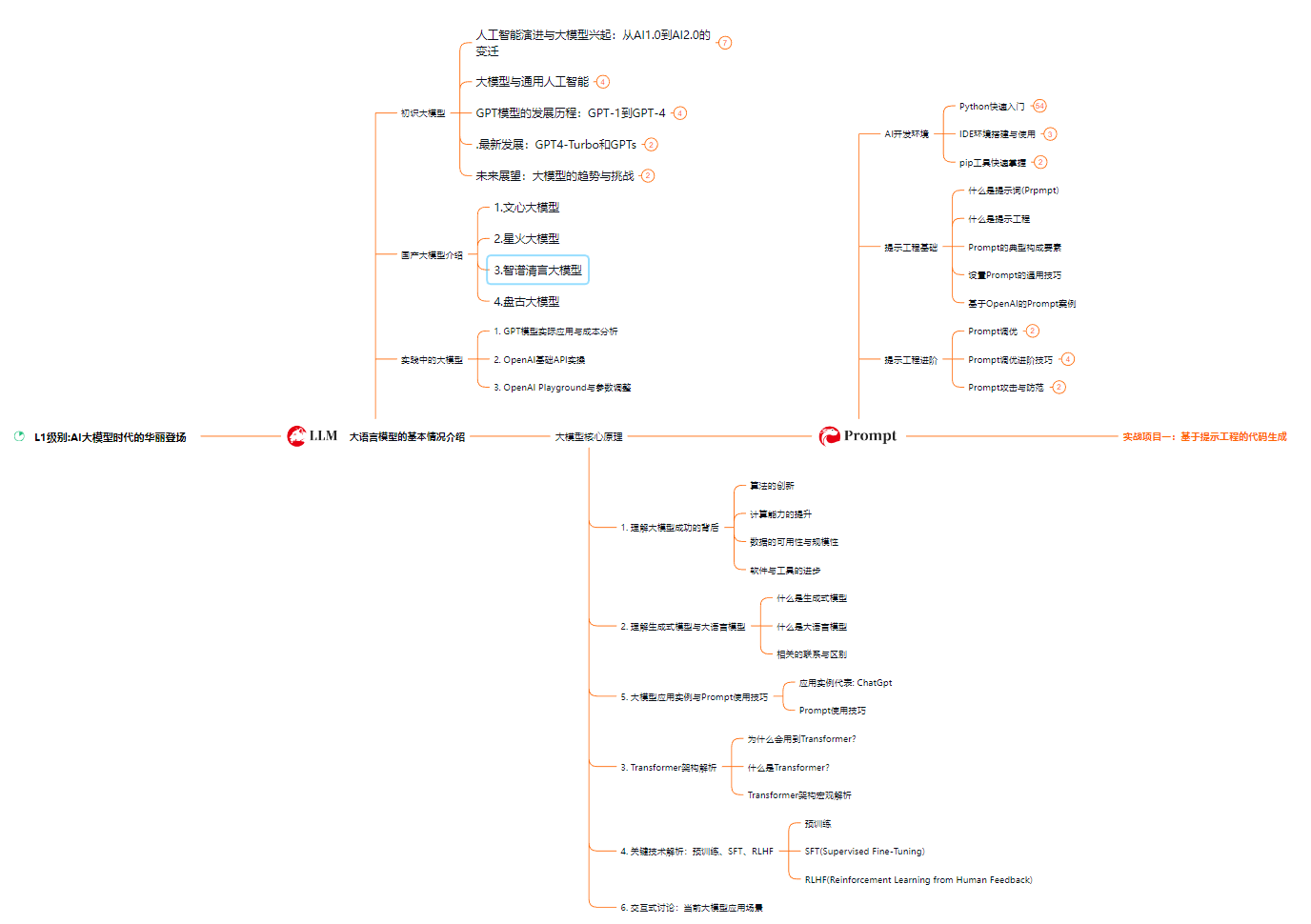
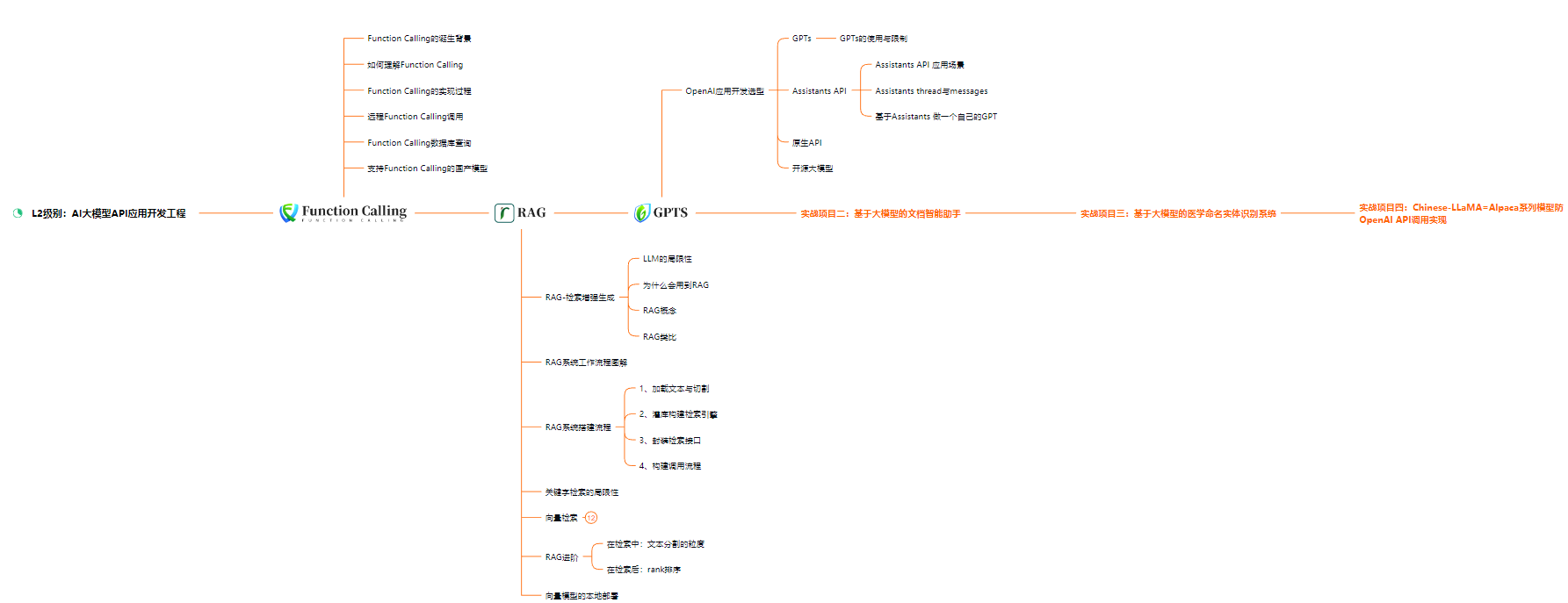


以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
四、AI大模型商业化落地方案

以上的AI大模型学习资料,都已上传至CSDN,需要的小伙伴可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。