文章目录
介绍
- 这是种wrap的方式, 整体有两个网络, 一个flow network F计算flow field, 一个rendering network进行变换
- 这个说是运用了3DMM, 好像也就是建模的时候用了点
提出了HeadGAN, 一种适用于头部动画和编辑的基于GAN的 one-shot方法。 这里特别的是使用了PNCC特征, 同时使用了3DMM。HeadGAN可以:
- 以20fps的速率运行实时reenactment系统
- 面部视频压缩和面部重建的有效方法
- 面部表情编辑方法
- 新颖的view分析方法, 包括正面化
相关工作提到:Warp-Guided GANs is a more recent work that uses 2D facial landmarks and 2D warps to animate an image, MarioNETte tries to solve this problem, by proposing a method for landmark transformation that adapts the driving landmarks to the reference head shape
方法
3D面部表示
为了转移驱动人的表情, 同时保留source身份的face geometry, 利用3dmm中的先验知识, 给定T帧的视频帧,
y
1
:
t
y_{1:t}
y1:t= {
y
t
∣
t
=
1
,
.
.
.
.
.
T
y_t|t=1, .....T
yt∣t=1,.....T}, 3Dmm fitting阶段产生了相机参数
c
1
:
T
c_{1:T}
c1:T,形状参数
p
1
:
T
p_{1:T}
p1:T, 以及
p
t
=
[
p
t
i
d
T
;
p
t
e
x
p
T
]
T
p_t=[p_t^{idT}; p_t^{expT}]^T
pt=[ptidT;ptexpT]T的序列. 对于每帧t, 我们获得两种shape 参数, 一个是
p
t
i
d
∈
R
n
i
d
p_t^{id}∈R^{n_{id}}
ptid∈Rnid身份有关的参数, 另一个是表情参数
p
t
e
x
p
∈
R
n
e
x
p
p_t^{exp}∈R^{n_{exp}}
ptexp∈Rnexp,表示面部变形.
这里3DMM fitting阶段使用密集的3d points, 是用RetinaFace回归的(所以是一帧帧回归的吗,用半监督的那个方法应该也行?), 这个模型是在WIDER FACE 数据集上预训练的. 给定源身份的参考图
y
r
e
f
y_{ref}
yref, 对其进行3dmm fitting, 获得形状参数
p
r
e
f
i
d
p_{ref}^{id}
prefid,
p
r
e
f
e
x
p
p_{ref}^{exp}
prefexp, 相机参数
c
r
e
f
c_{ref}
cref,下面是fit 算法:
- 给定面部图像y,3DMM fitting阶段恢复形状p和相机c参数。它依赖于面部密集的3D点,这些点通过Retinaface501网络回归,在WIDER FACE dataset上预先训练。使用Procrustes分析将回归点register为LSFM 3DMM的平均形状x

对于每帧t, 计算出的3d mesh公式如下:
其中
s
t
:
s_t:
st:
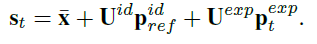
x ˉ ∈ R 3 N \bar x ∈R^{3N} xˉ∈R3N 是平均形状, U i d U_{id} Uid是正交化的bias, U e x p U_{exp} Uexp是来自LSTM morphable 表情正交化bias(论文A 3d morphable model learnt from 10,000 faces.). 然后再就是渲染出3d 脸部的representation, x t = R ( s t , c t ) x_t=R(s_t, c_t) xt=R(st,ct) c是相机参数, 这个 x t x_t xt是一张类似PNCC的RGB图. 同样也渲染出 x r e f x_{ref} xref, 这是从参考图像 y r e f y_{ref} yref中恢复的3D表达,如下图所示.
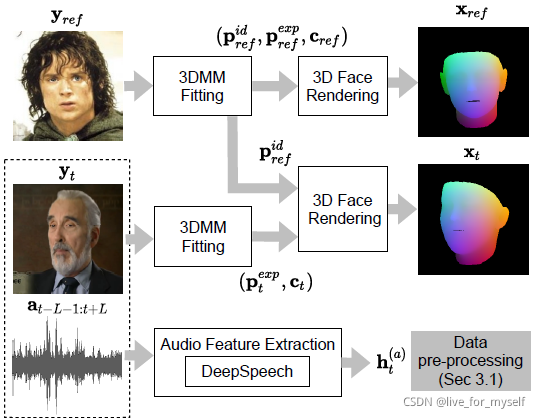
综上, 给定驱动视频 y 1 : t y_{1:t} y1:t以及一个源参考图 y r e f y_{ref} yref, 数据预处理阶段恢复了一系列图片 x 1 : T x_{1:T} x1:T,这些x描述了从驱动视频提取到的并且可以应用到源图片的面部几何信息, 同时还有 x r e f x_{ref} xref
声音特征
我们将音频信号分成T个部分
a
1
:
T
a_{1:T}
a1:T,其中每个部分对应于长度为T的驱动视频的第
y
t
y_t
yt帧。
然后,我们将音频特征提取应用于2L长度的音频窗口。
a
t
−
L
−
1
:
t
+
L
=
{
a
t
−
L
−
1
,
.
.
.
.
a
t
,
.
.
.
.
a
t
+
L
}
a_{t-L-1:t+L} = \{a_{t-L-1},....a_t,....a_{t+L}\}
at−L−1:t+L={at−L−1,....at,....at+L},以帧t为中心,得到一个特征向量
h
t
(
a
)
h_t^{(a)}
ht(a), 它包含了过去和未来的时间步骤的信息. 我们采用(论文An opensource python library for audio signal analysis.)来提取低层次的特征,如MFCCs,信号能量和熵,从而得到一个特征向量
h
t
(
a
L
)
h^{(aL)}_t
ht(aL)∈
R
84
R^{84}
R84。
然后,我们使用DeepSpeech从每个音频部分提取字符级别的logits。这结果是2L个logits,串联后得到一个特征向量
h
t
(
a
H
)
h^{(aH)}_t
ht(aH)∈
R
2
L
∗
27
R^{2L*27}
R2L∗27。我们最终的音频特征向量为
h
t
(
a
)
h^{(a)}_t
ht(a) =
[
h
t
(
a
L
)
T
]
[h_t^{(aL)^T}]
[ht(aL)T];
h
t
(
a
H
)
T
]
T
h_t^{(aH)^T}]^T
ht(aH)T]T ∈R300,对于L = 4。
- L是指的t前后的帧数, 合起来是2L, 也就是说论文是8帧一个单元
HeadGan 框架
HeadGan的生成器有两种模式, 一种是从驱动视频视频和参考图片中提取出的3d 面部表达, 一种是来自驱动者的音频.
网络输入有两个:(1)
x
t
−
k
:
t
x_{t-k:t}
xt−k:t, 即从t帧里得到的3d 脸部表达, 和过去的k=2帧 channel级的连接起来, (2)参考图片
y
r
e
f
y_{ref}
yref及其对应的
x
r
e
f
x_{ref}
xref, 以及声音特征
h
t
(
a
)
h_t^{(a)}
ht(a), 生成器可以将这些输入的特征变为真实的图片, 公式如下:
生成器由两个子网络组成:一个密集流网络F和一个渲染网络R, 整个网络架构如下图:
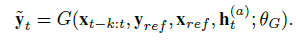
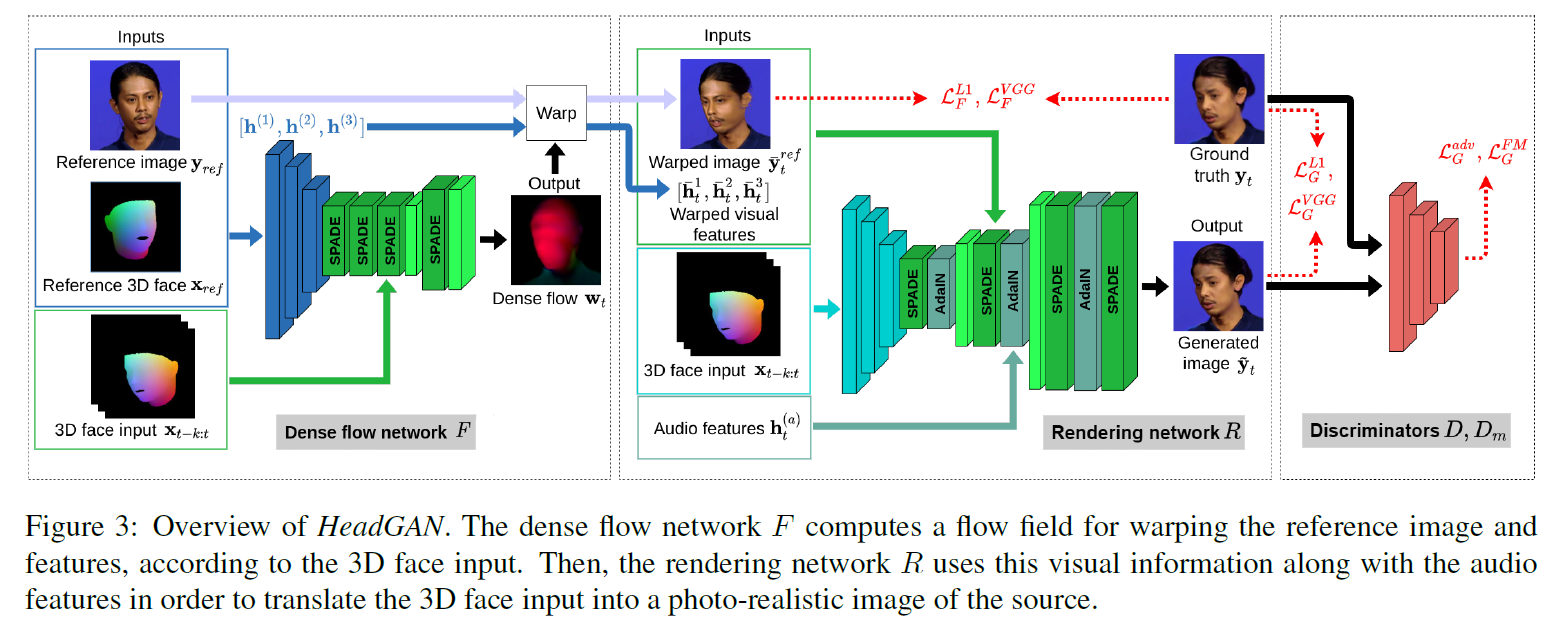
Dense flow network F
- 渲染网络R是依赖前一个阶段的信息的,但是只从参考图像中提取信息不太行, 假如是视觉特征和想要的头部姿态对齐就好了, 头部姿态在我们的驱动视频的3d model x t x_t xt 中有体现
F可以学习到流
w
t
w_t
wt来扭曲视觉特征.
把参考图片和其对应的3d 特征 cat起来 (
y
r
e
f
,
x
r
e
f
y_{ref}, x_{ref}
yref,xref) 通过encoder提取三个空间尺度的特征
h
(
1
)
,
h
(
2
)
,
h
(
3
)
h^{(1)}, h^{(2)}, h^{(3)}
h(1),h(2),h(3) 来表示原图片 identity 的信息. (参考图片有三个空间尺度的身份信息)
输入驱动视频的3d特征 x t − k : t x_{t-k:t} xt−k:t 到decoder, 预测出流 w t w_t wt 然后 w 被注入F, 通过SPADE blocks , 这个block 是论文(Semantic image synthesis with spatially-adaptive normalization.)里面的, 结构大致如下:
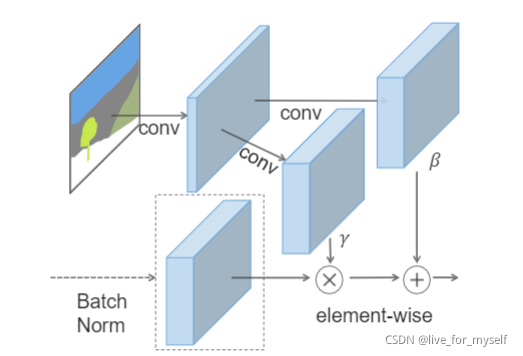
理想情况下, 通过这个流, 参考图片就能做出和驱动视频同样的动作和表情了, 这个流w是用到每个视觉特征的, 之前不是提取了 h ( 1 ) , h ( 2 ) , h ( 3 ) h^{(1)}, h^{(2)}, h^{(3)} h(1),h(2),h(3) 来表示原图片 identity 的信息, 都用上这个场就得到了warped 视觉特征, h ˉ t ( 1 ) , h ˉ t ( 2 ) , h ˉ t ( 3 ) \bar h_t^{(1)}, \bar h_t^{(2)}, \bar h_t^{(3)} hˉt(1),hˉt(2),hˉt(3),以及warped 参考图片 y ˉ t r e f \bar y_t^{ref} yˉtref,
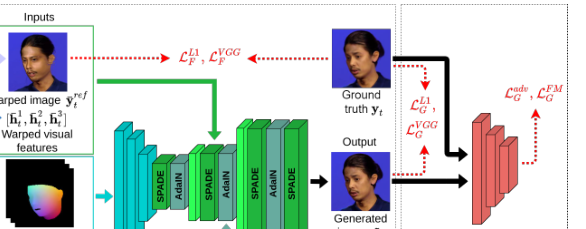
Rendering network
- 这个部分的主要输入是驱动视频的3d model 的类似pncc的图 x t − k : t x_{t-k:t} xt−k:t
- 其他额外的辅助输入还有之前提取的音频特征 h t ( a ) h^{(a)}_t ht(a) (这个音频特征提取的挺多, 还用两种cat起来) , 还有之前被流wrap后的特征 h ˉ t ( 1 ) , h ˉ t ( 2 ) , h ˉ t ( 3 ) \bar h_t^{(1)}, \bar h_t^{(2)}, \bar h_t^{(3)} hˉt(1),hˉt(2),hˉt(3) (既然可以直接得到wrap的图片 y r e f y_{ref} yref 为啥不到这里就停止了呢)
编码器接收
x
t
−
k
:
t
x_{t-k:t}
xt−k:t 然后对其进行卷积下采样, 然后由交替的SPADE和AdaIN层 组成的解码器生成需要的帧
y
~
t
\tilde y_t
y~t. (用到辅助信息了, 声音ha和wrap的特征ht)
这些自适应归一化层能够将2d 的特征图通过SPADE blocks注入到渲染网络中, 也可以将1d 的音频特征通过AdaIN注入到渲染网络中.
与SPADE的原始工作相反,所有SPADE层的条件输入都是相同的分割图(segmentation map)向下采样以匹配每个层的空间大小,我们利用了多个空间尺度的视觉特征图 h ˉ t ( 1 ) , h ˉ t ( 2 ) , h ˉ t ( 3 ) \bar h_t^{(1)}, \bar h_t^{(2)}, \bar h_t^{(3)} hˉt(1),hˉt(2),hˉt(3)和 y ˉ t r e f \bar y_t^{ref} yˉtref作为SPADE blocks的调制输入。
我们将相同的音频特征向量 h t ( a ) h_t^{(a)} ht(a)传递给所有空间尺度的AdaIN块。解码器还配备有用于上采样的PixelShuffle layers,来自论文(Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network) , 这有助于提高生成样本的质量。
Discriminators D and Dm.
图像鉴别器接收合成的一对 ( x t ; y ~ t ) (x_t; \tilde y_t) (xt;y~t),或一个真实的一对 ( x t ; y t ) (x_t; y_t) (xt;yt),并且学习如何区分它们。我们使用第二个鉴别器Dm,它专注于嘴部区域。除了真实的 y t m y^m_t ytm或生成的 y ~ t m \tilde y^m_t y~tm裁剪的嘴部区域, 该网络以音频特征向量 h t ( a ) h^{(a)}_t ht(a)为条件,在空间上进行复制(spatially replicated),然后与裁剪后的图像进行channel-wise级联。
Training Objective.
构成生成器的网络F和R联合优化。我们通过应用感知和像素损失(perceptual and pixel losses) L F V G G , L G V G G L_F^{VGG}, L_G^{VGG} LFVGG,LGVGG, L F L 1 , L G L 1 L_F^{L1}, L_G^{L1} LFL1,LGL1上面结构图中所示(红色箭头)。还有其他的损失作者在附录中讲了.
- 这里对warp的图和生成的都用这两个loss
这个ground truth是哪的???

实验
3D Face Rendering
这里的参数是shape参数和相机参数, 也就是35维度加上驱动视频帧就可以重建出人脸来
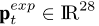
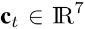
- VoxCeleb