- 概述
进行到该阶段,我们假设您已经完成了geotrellis 版本选型和环境搭建;熟悉本公司的大数据架构原理;初步了解了geotrellis,并且在开发环境中构建了geotrellis配置;可以参考官方文档和有关资料,运行其给出的demo示例,那么恭喜您,可以愉快地进入该阶段。
如果您未经历或完成上述阶段,请参考公司相关文档:
《geotrellis 版本选型和环境搭建》
《飞未大数据架构整理》
《官方文档》
《GeoTrellise系列文章》
对于技能要求,我们假设您已经具备初步的Spark,Scala开发技巧,熟练使用sbt工具,具备geotrellis一定的知识。当然,这些都不在本文档讨论范围,如果您有兴趣,可以去做相应的了解。
注意:以下操作均在单机版本spark环境,但同样适用于spark集群环境
- 前期准备
首先需要下载geotrellis-2.0.0-M2版本,下载网址为:
https://github.com/locationtech/geotrellis/archive/v2.0.0-M2.zip
下载完成后,可以将源码导入到idea中,也可以将源码上传至linux中进行编译打包,etl用的是spark-etl模块,所以打jar包时打spark-etl模块即可,若上传至linux系统,打jar包方式如下:
解压geotrellis-2.0.0-M2
# unzip geotrellis-2.0.0-M2
# cd geotrellis-2.0.0-M2
打包 spark-etl模块:
# ./sbt "project spark-etl" assembly

这个过程比较缓慢,第一次要下载一大堆jar包,如果顺利一次性可以下完,不顺利就多执行几次。
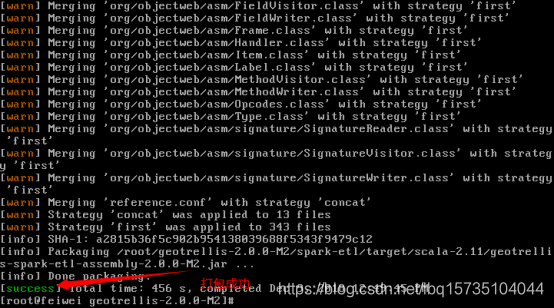
出现 ‘sucess’时表示打包成功
# cd spark-etl/target/
# cd scala-2.11/ (这里你用的是scala的哪个版本,加入吧就在对应的目录下)
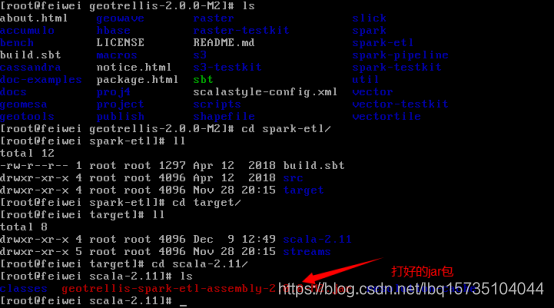
当然,也可以在idea中直接打jar包,其方式为:
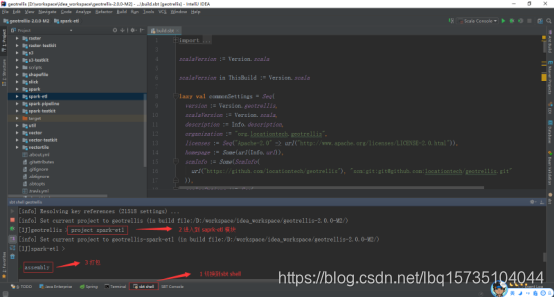
如下为打包成功:
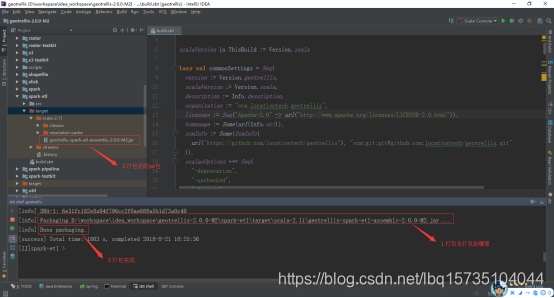
需要指出的是,在桌面版本的LInux系统中,打包成功后,系统会顺带下载一些文件,如测试数据(有png和tif格式),以及其他文件,如图:
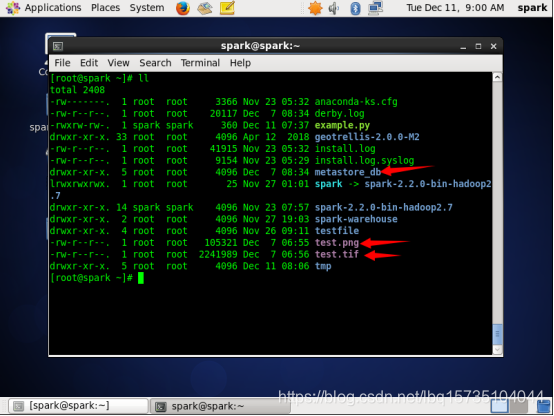
保留它,之后我们将会用到。
- 本地构建ETL程序集
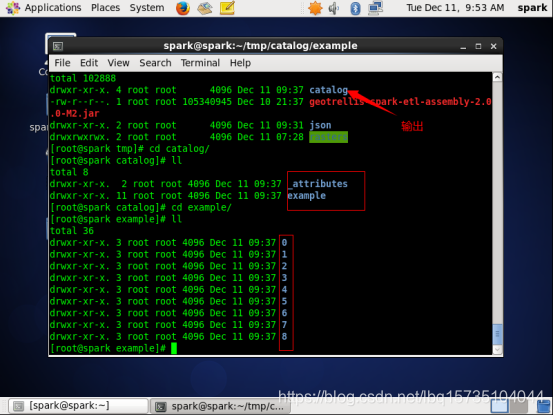
创建tmp目录:
#mkdir /root/tmp
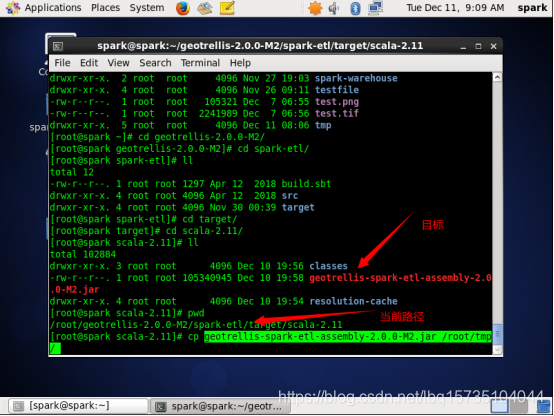
将之前打好的jar包复制到tmp目录下:
#cp geotrellis-spark-etl-assembly-2.0.0-M2.jar /root/tmp/
- 撰写JSON配置文件
我们在本节中创建的配置文件旨在与单个多波段GeoTiff图像一起使用。需要三个JSON文件:一个描述输入数据,一个描述输出数据,一个描述应存储目录的后端。
现在,我们将在创建三个文件/tmp/json目录: input.json,output.json,和backend-profiles.json。
这是input.json
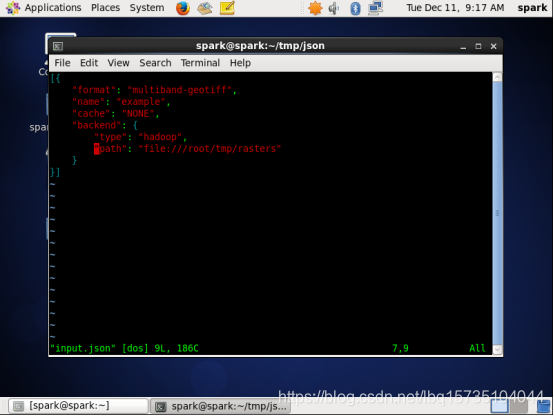
该值multiband-geotiff与format密钥相关联。如果要以SpatialKey- MultibandTile对的RDD访问数据,则需要这样做 。制作该值geotiff ,而不是multiband-geotiff会导致SpatialKey- Tile对。example与键关联的值name提供将要创建的图层的名称。该cache键提供了将在ETL过程中使用的Spark缓存策略。最后,与backend密钥关联的值指定应从何处读取数据。在这种情况下,源数据存储在/tmp/rasters本地文件系统的目录中,并通过Hadoop访问。
这是ouput.json
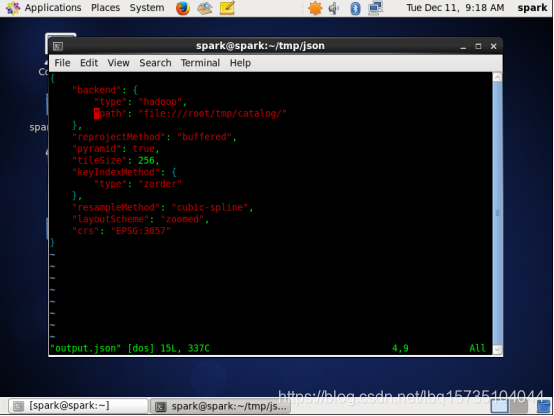
该文件说应该/tmp/catalog使用Hadoop 在目录中的本地文件系统上创建目录。对源数据进行金字塔化,以便在目录中创建缩放级别0到12的层。这些图块的大小为256×256像素,并根据Z顺序编入索引。双重重采样(样条而不是卷积)用于重投影过程,与层相关的CRS是EPSG 3857(又名Web Mercator)。
这是backend-profiles.json文件:
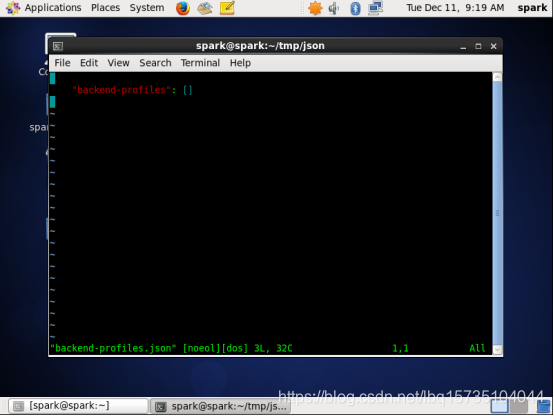
在这种情况下,我们不需要指定任何内容,因为我们使用Hadoop进行输入和输出。碰巧Hadoop只需要知道它应该读取或写入的路径,并且我们在input.json和output.json文件中提供了这些信息。其他后端如Cassandra和Accumulo需要在backend-profiles.json文件中提供信息。
- 创建目录
#mkdir -p /tmp/rasters
将测试数据拷贝到tmp/rasters目录下
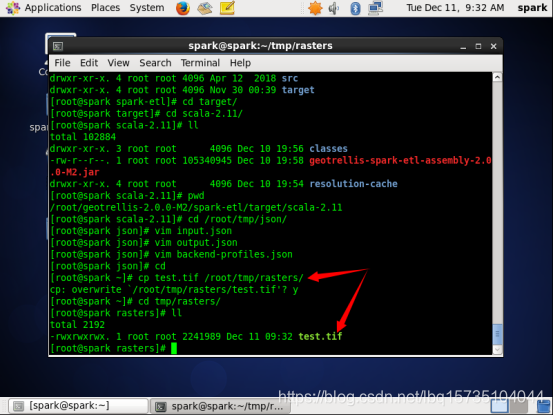
现在,所有我们需要的地方(文件/tmp/geotrellis-spark-etl-assembly-1.0.0.jar,/tmp/json/input.json,/tmp/json/output.json,/tmp/json/backend-profiles.json,和 /tmp/rasters/*.tif),我们已经准备好进行切割。
- 执行操作
键入:
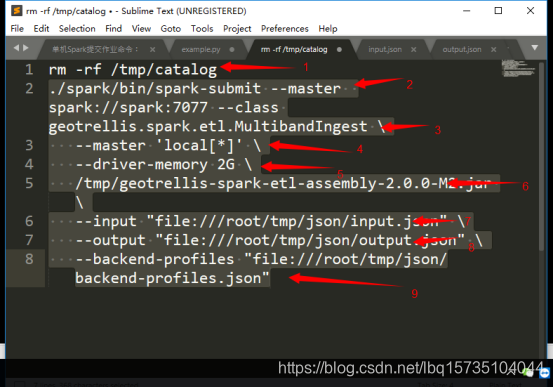
解释:
- : 删除本地上的catalog目录,目地是不影响再次运行的结果
- : 提交spark任务
- : 指定运行主类
- : 指定spark运行在哪里,有“yarn” 和 “local[*]”两种配置(特别是集群环境)
- : 缓存内存
- : 指定运行jar包的位置
- : 指定input.json,即输入参数配置的文件位置
- : 指定output.json,即输出参数配置的文件位置
9: 指定backend-profiles.json,即后端参数配置的文件位置
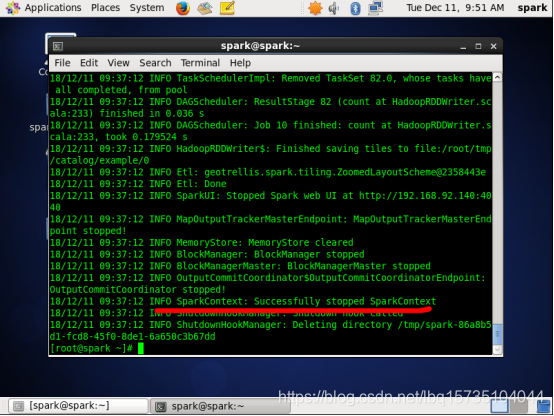
- 运行结果
-
查看结果:
- 总结
-
好啦,到这里,您应该可以轻松的使用geotrellis进行一些有趣的开发,测试啦。当然,文档并非完美,撰写者也在前行中,如果文档有不足之处,欢迎您指正!