1.仅加go
在一个golang编写的程序,主函数运行完毕后,程序就结束了
package main
import (
"fmt"
"time"
)
func main() {
// 如果这样写go 要加在上面的函数,因为如果只单独加在下面的函数或者都加上,程序就会直接仅执行上面的函数或者不执行
go count(5, "羊")
count(5, "牛")
}
func count(n int, animal string) {
for i := 0; i < n; i++ {
fmt.Println(i+1, animal)
time.Sleep(time.Millisecond * 500)
}
}
2.使得两个go都执行
1.直接time.Sleep(3 * time.Second)
package main
import (
"fmt"
"time"
)
func main() 。
// 如果这样写go 要加在上面的函数,因为如果只单独加在下面的函数或者都加上,程序就会直接仅执行上面的函数或者不执行
go count(5, "羊")
go count(5, "牛")
time.Sleep(3 * time.Second)
}
func count(n int, animal string) {
for i := 0; i < n; i++ {
fmt.Println(i+1, animal)
time.Sleep(time.Millisecond * 500)
}
}
2.WaitGroup 计数器 执行完一个任务就减1
追踪还有多少任务没有执行
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var wg sync.WaitGroup
wg.Add(2)
go func() {
count(5, "羊")
wg.Done()
}()
go func() {
count(5, "牛")
wg.Done()
}()
wg.Wait() // 函数结束前原地听命,计数器变为0才继续
}
func count(n int, animal string) {
for i := 0; i < n; i++ {
fmt.Println(i+1, animal)
time.Sleep(time.Millisecond * 500)
}
}
3.交流goroutine
其他具有多线程的编程语言中,线程之间的交流通过共享内存完成
1.通过计数交流,counte 缺点是可能分配在不同的核心 可能同时执行
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var wg sync.WaitGroup
wg.Add(2)
go func() {
count(5, "羊")
wg.Done()
}()
go func() {
count(5, "牛")
wg.Done()
}()
wg.Wait() // 函数结束前原地听命,计数器变为0才继续
fmt.Println(counte)
}
var counte int
func count(n int, animal string) {
for i := 0; i < n; i++ {
fmt.Println(i+1, animal)
counte++
time.Sleep(time.Millisecond * 500)
}
}
2.Channel
不通过共享内存交流,通过交流去共享内存
往channel发送和接收一条消息,都会阻塞代码的执行
当我要发送一条消息,我会一直在这里等着,直到一条消息在channel另一方被接收了
反过来,如果我想从channel接受一条消息 我会等着
如果channel另一方有一个人拿着消息等着,我会立刻收到消息,他会立刻发送消息,然后都会运行
可以通过阻塞的特性同步我们的代码
package main
import (
"fmt"
"time"
)
func main() {
c := make(chan string)
go count(5, "羊", c)
for { // 消息有很多 使用for循环
message := <-c // 从channel收到消息
fmt.Println(message)
}
}
func count(n int, animal string, c chan string) {
for i := 0; i < n; i++ {
// 直接往channel里喊话
c <- animal
time.Sleep(time.Millisecond * 500)
}
}
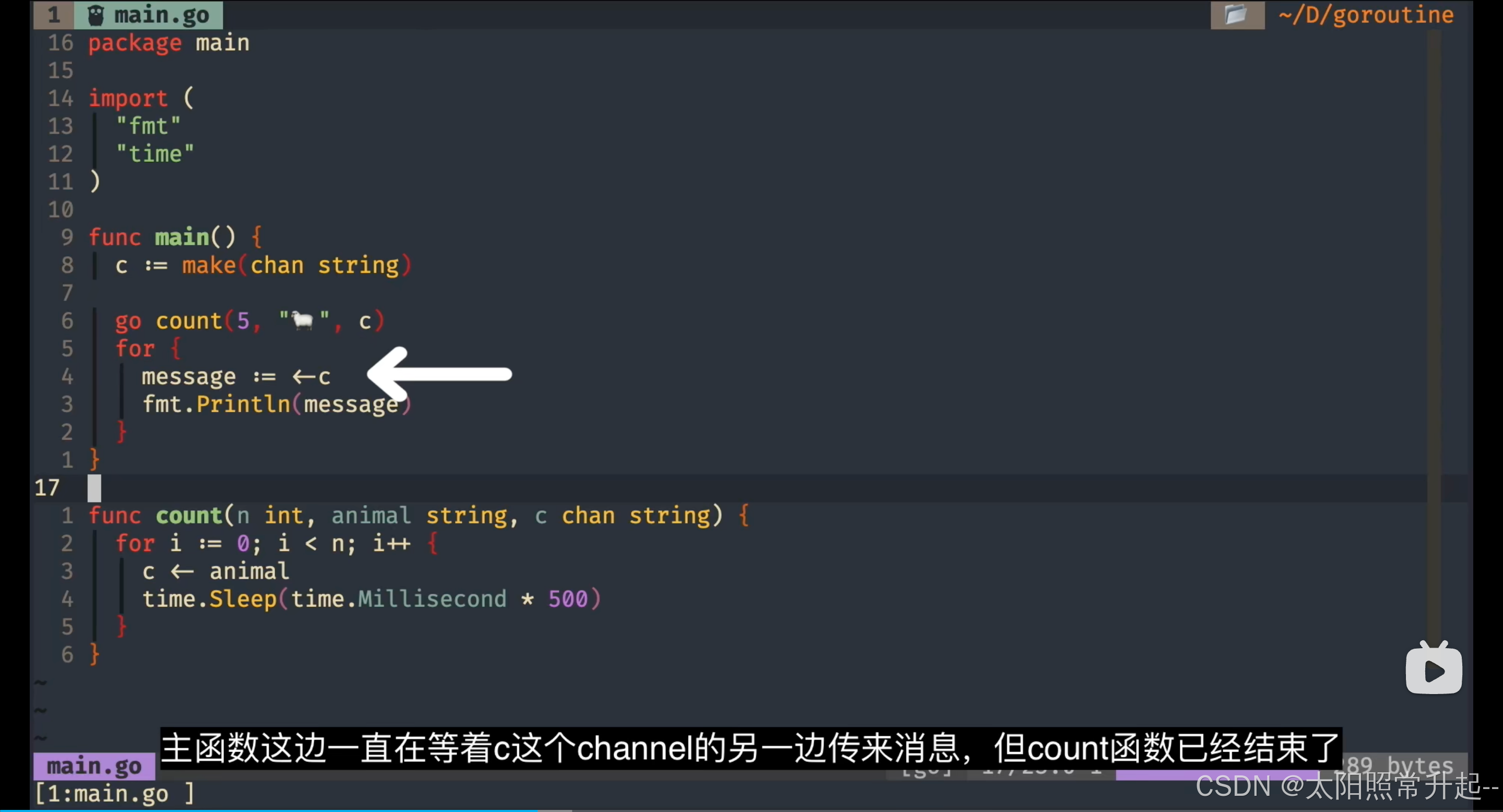
主函数一直等待channel传来消息,但是count函数已经结束了
对程序来说,新的数据不会传进来
go检测到这一点,报错

package main
import (
"fmt"
"time"
)
func main() {
c := make(chan string)
go count(5, "羊", c)
// 方式1
for { // 消息有很多 使用for循环
message, open := <-c // 从channel收到消息 会额外获得一个bool值,使用open接收
if !open { // 通过bool判断是不是要继续从channel接收消息
break
}
fmt.Println(message)
}
// 方式2
for message2 := range c {
fmt.Println(message2)
}
}
func count(n int, animal string, c chan string) {
for i := 0; i < n; i++ {
// 直接往channel里喊话
c <- animal
time.Sleep(time.Millisecond * 500)
}
close(c) // 关闭channel
}
3.从多个channel接收数据
当你把一个任务分为多个子任务时
可能和每一个子任务都有一个单独的channel专门和那一个子任务通讯
这些channel随时可能传来数据,怎么去管理
往channel发送和接收一条数据都会阻塞程序
有多个channel发送消息时
使用channel保证第一时间从有新消息的channel接收数据
不受不同channel消息频率不同的影响
package main
import (
"fmt"
"time"
)
func main() {
c1 := make(chan string)
c2 := make(chan string)
go func() {
for {
c1 <- "羊"
time.Sleep(time.Millisecond * 500)
}
}()
go func() {
for {
c1 <- "牛"
time.Sleep(time.Millisecond * 2000)
}
}()
//for {
// fmt.Println(<-c1) // 往channel发送和接收一条数据都会阻塞程序 所以c1执行完之后就会到c2,然后就会阻塞,c1的消息此时无人接收,所以使用select方法
// fmt.Println(<-c2)
//}
for {
select { // 有很多case 哪个不阻塞就先执行
case msg := <-c1:
fmt.Println(msg)
case msg := <-c2:
fmt.Println(msg)
}
}
}
4.树形结构便利 搜索文件
搜索所有叫test的文件或者文件夹
深度优先的搜索实现
1.直接遍历
package main
import (
"fmt"
"io/ioutil"
"time"
)
var query = "test"
var matches int // 计量数字
var workerCount = 0
var maxWorkerCount = 32
var searchRequest = make(chan string) // 让包工头指派工作
var workerDone = make(chan bool) // 让工人们互相告诉包工头说工作做完了
var foundMatch = make(chan bool) // 传输关于我找到搜索的结果的消息
func main() {
start := time.Now()
workerCount = 1
go search("/Users/lfzxmw/", true)
waitForWorkers() //指派完第一个search等待一下
fmt.Print(matches, "matches")
fmt.Println(time.Since(start))
}
func waitForWorkers() {
for {
select {
case path := <-searchRequest: // 有新的工作 search request有新的消息 把此时工人数量加一
workerCount++
go search(path, true) // 指派一个新的工人工作
case <-workerDone: // 有工人工作结束 数量就减一
workerCount--
if workerCount == 0 { // 工作都做完了
return // 退出等待的函数
}
case <-foundMatch: // 有新的结果找到
matches++
}
}
}
func search(path string, master bool) {
files, err := ioutil.ReadDir(path)
if err == nil {
for _, file := range files {
name := file.Name()
if name == query {
foundMatch <- true
}
if file.IsDir() {
if workerCount < maxWorkerCount {
searchRequest <- path + name + "/"
} else {
search(path+name+"/", false)
}
}
}
}
if master { // 看一下当前的搜索函数是不是一个在goroutine运行的搜索函数
workerDone <- true // 是的话告诉总部工作结束
}
}
5.扩展
1.带有buffer(缓存)的channel
2.go语言的context包裹
1.带有buffer(缓存)的channel
在 Go 语言中,带有缓冲的通道(buffered channel)允许你在通道中存储一定数量的数据,而不需要立即接收。这使得发送者在发送数据时可以继续工作,而不必等到接收者准备好接收。带缓冲的通道在需要在 goroutine 之间异步通信时非常有用。
package main
import (
"fmt"
"time"
)
func main() {
// 创建一个缓冲区大小为 3 的通道
bufferedChannel := make(chan int, 3)
// 启动一个 goroutine 发送数据
go func() {
for i := 1; i <= 5; i++ {
fmt.Printf("Sending %d to the channel\n", i)
bufferedChannel <- i // 发送数据到通道
fmt.Printf("Sent %d to the channel\n", i)
time.Sleep(1 * time.Second) // 模拟工作延迟
}
close(bufferedChannel) // 发送完成后关闭通道
}()
// 接收数据
for value := range bufferedChannel {
fmt.Printf("Received %d from the channel\n", value)
time.Sleep(2 * time.Second) // 模拟处理数据的延迟
}
fmt.Println("All values received from the channel.")
}
代码说明
- 创建缓冲通道:
- 使用
make(chan int, 3)创建一个整型的缓冲通道,缓冲大小为 3。
- 使用
- 发送数据的 goroutine:
- 在一个 goroutine 中,循环发送 5 个整数到通道中。由于通道是缓冲的,所以最多可以容纳 3 个整数而不会阻塞发送。
- 接收数据:
- 使用
for range循环接收通道中的数据。接收者会阻塞,直到通道中有数据可用。
- 使用
- 关闭通道:
- 发送完成后,使用
close(bufferedChannel)关闭通道。这是一个好习惯,可以避免接收者在通道中等待更多数据。
- 发送完成后,使用
注意事项
- 如果缓冲通道已满,发送者将被阻塞,直到接收者读取数据,使得通道中有空位。
- 如果通道已空,接收者将被阻塞,直到有数据可接收。
- 关闭通道是必要的,特别是在需要通知接收者发送完成时。
总结
带缓冲的通道可以有效地在 goroutine 之间传递消息,允许更灵活的并发设计。它们非常适合需要一定程度的异步处理的场景。希望这个示例能够帮助您理解带缓冲通道的使用!如果您有任何进一步的问题,欢迎随时提问。
6.go语言的context包裹
在 Go 语言中,context 包是一个用于处理上下文(context)信息的标准库,广泛用于处理并发操作中的请求传递、取消信号以及超时控制。它尤其在编写网络服务和分布式系统时非常有用。
主要功能
- 请求的传递:可以在多个 goroutine 之间传递请求范围的值。
- 取消信号:允许上下文的持有者通知其他 goroutine 取消操作。
- 超时控制:可以设置超时,从而避免操作长时间阻塞。
常用类型
- Context:接口类型,表示上下文。
- Background:返回一个非空的
Context,通常用于顶层的 context。 - TODO:返回一个非空的
Context,用于某些还未决定的上下文。
创建 Context
1. 背景上下文
ctx := context.Background()
2. 带取消的上下文
ctx, cancel := context.WithCancel(context.Background())
defer cancel() // 确保在不再需要时调用取消
3. 带超时的上下文
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel() // 确保在不再需要时调用取消
4. 带截止时间的上下文
deadline := time.Now().Add(5 * time.Second)
ctx, cancel := context.WithDeadline(context.Background(), deadline)
defer cancel() // 确保在不再需要时调用取消
5. 带值的上下文
ctx = context.WithValue(context.Background(), "key", "value")
value := ctx.Value("key")
示例代码
下面是一个完整的示例,展示如何使用 context 包处理并发操作和取消信号:
package main
import (
"context"
"fmt"
"time"
)
func worker(ctx context.Context, id int) {
for {
select {
case <-ctx.Done():
fmt.Printf("Worker %d: stopped\n", id)
return // 处理取消信号
default:
fmt.Printf("Worker %d: working...\n", id)
time.Sleep(1 * time.Second) // 模拟工作
}
}
}
func main() {
// 创建一个带取消的上下文
ctx, cancel := context.WithCancel(context.Background())
// 启动多个工作 goroutine
for i := 1; i <= 3; i++ {
go worker(ctx, i)
}
// 等待 5 秒后取消上下文
time.Sleep(5 * time.Second)
cancel() // 通知所有 goroutine 停止工作
// 等待一段时间以确保所有 goroutine 都已退出
time.Sleep(2 * time.Second)
fmt.Println("All workers stopped.")
}
代码说明
-
上下文的创建:
- 使用
context.WithCancel创建一个可取消的上下文。
- 使用
-
工作 goroutine:
- 每个 worker 在一个无限循环中运行,检查上下文是否已被取消。
-
取消上下文:
- 在主函数中,等待 5 秒后调用
cancel(),通知所有 worker 停止工作。
- 在主函数中,等待 5 秒后调用
-
输出:
- 每个 worker 每秒输出一次工作信息,直到被取消。
注意事项
- 避免使用全局上下文:尽量避免在函数中使用
context.Background()或context.TODO(),而应将上下文信息传递给需要它的函数。 - 使用
defer:确保调用cancel(),以避免资源泄露。 - 优雅地停止 goroutine:通过
ctx.Done()来监听取消信号,确保 goroutine 能够优雅地停止。
总结
context 包是 Go 语言中用于处理并发操作的重要工具,能够帮助你更好地管理请求的生命周期、取消操作和超时控制。希望这个介绍能帮助您理解 context 包的基本使用。如果您还有其他问题,欢迎提问!