在这篇文章中介绍了快速排序的排序方法,但未提及快排中的分治策略。本文来介绍一下其中的分治策略
问题描述
对数组从p到r排序
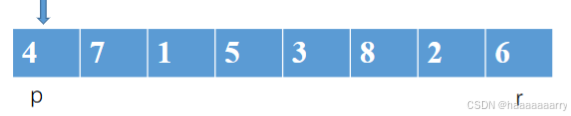
四个条件
对于分治法,需要满足四个条件:
- 该问题的规模缩小到一定程度可以轻松解决
- 该问题可以分成若干个规模较小的相同问题
- 子问题的解可以合并成大问题的解
- 分解出的各个子问题互相不重复(独立)
对于快速排序,其解决方案满足以上四个条件:
- p和r控制问题规模,r≤p为边界条件,此时的问题规模小到可以直接解决(区间中只有一个元素,一定是有序的)
- 大问题可分:利用一个partition函数,将大数组分成两部分,返回中枢q,q左边的元素均比q小,右边的均比q大
- 可合:对每一个子数组排序后,大数组就有序了。子问题的答案可以合成大问题的答案
- 没有任何子问题是重复的
因此,快速排序满足分治法的四个条件,可以使用分治策略解决
递归定义
- 边界条件:
p==r - 左数组:p到q-1排序
- 右数组:q+1到r排序
代码思路
QuickSort
void QuickSort(int a[], int p, int r) ;
作用:对a[]数组,从p到r进行排序
根据递归定义,可以得到QuickSort函数的思路:
- 判断如果数组可分(p<r),利用
Partition函数将大数组分成两个小数组- 对左数组排序
QuickSort(a, p, q - 1) - 对右数组排序
QuickSort(a, q + 1, r)
- 对左数组排序
- 如果数组不可分(只有一个元素),则已有序,无序操作
代码
void QuickSort(int a[], int p, int r) {
int q;
if (p < r)
{
q = Partition(a, p, r);//将大数组划分成两个小数组
QuickSort(a, p, q - 1);//对左数组排序
QuickSort(a, q + 1, r);//对右数组排序
}
return;
}
Partition
int Partition(int a[], int p, int r);
作用:将数组 a[] 的一部分重新排列,使得所有小于或等于某个基准值的元素都位于基准值的左侧,而所有大于基准值的元素都位于基准值的右侧。这个基准值通常是数组的第一个元素 a[p]。
代码
先上代码
int Partition(int a[], int p, int r) {
int i = p, j = r + 1;
int t;
int x = a[p];//a[p]作为划分基准
while (1) {
while (a[++i] <= x && i < r);//从左向右找大于x的数的位置下标i,找不到时i==j
while (a[--j] > x);//从右向左找小于等于x的数的位置下标j,找不到时j==p
if (i >= j)
break;//一遍扫描结束,退出循环
t = a[i];
a[i] = a[j];
a[j] = t; //交换a[i]和a[j]
}
a[p] = a[j]; //首元素a[p]与a[j]交换
a[j] = x; //x放在分界点
return j; //j是分裂位置
}
利用i 、j两个指针,分别从左到右和从右到左扫描数组,扫描过一遍后,退出循环,将首元素与a[j]交换。如果在扫描过程中发现左侧有大于首元素的或右侧有小于等于首元素的,将其交换,使左侧整体均小于右侧。
最后返回j作为划分的位置
变量
在 Partition 函数中,使用了多个变量来实现分区操作。下面对这些变量进行解释:
int i = p
- 作用:
i是从左向右扫描的指针,初始值为p(分区的起始位置)。 - 行为:
- 在第一个
while循环中,i从左向右移动,寻找第一个 大于基准值x的元素。 - 如果找不到这样的元素,
i会停在r(分区的右边界)。
- 在第一个
- 意义:
i标记了从左向右扫描时第一个需要交换的元素位置。 - 细节:
i的初始化为p,而划分基准就是a[p],在后面从左向右找大于x的数的位置下标时,使用的是前缀++,这样可以跳过首元素,即基准a[p],从第二个元素开始找,下面的j也是相同道理
int j = r + 1
- 作用:
j是从右向左扫描的指针,初始值为r + 1(分区的右边界 + 1)。 - 行为:
- 在第二个
while循环中,j从右向左移动,寻找第一个 小于或等于基准值x的元素。 - 如果找不到这样的元素,
j会停在p(分区的左边界)。
- 在第二个
- 意义:
j标记了从右向左扫描时第一个需要交换的元素位置。 - 细节:
j的初始化为r + 1,此时j指针指向的是数组外的第一个元素,后面使用后缀–,可以直接指向数组的最后一个元素
int t
- 作用:
t是一个临时变量,用于交换a[i]和a[j]的值。 - 行为:
- 当
i和j找到需要交换的元素时,t用于暂存a[i]的值,然后完成交换。
- 当
- 意义:
t是交换两个元素值的辅助变量。
int x = a[p]
- 作用:
x是基准值(pivot),用于分区的比较标准。 - 行为:
x被初始化为a[p],即分区的第一个元素。- 在分区过程中,所有元素会与
x进行比较,小于或等于x的元素放在左侧,大于x的元素放在右侧。
- 意义:
x是分区的核心,决定了分区的划分标准。
a[i]和a[j]
- 作用:
a[i]和a[j]是数组中的元素,分别由指针i和j指向。 - 行为:
a[i]是从左向右扫描时找到的第一个 大于x的元素。a[j]是从右向左扫描时找到的第一个 小于或等于x的元素。- 如果
i < j,则交换a[i]和a[j],使得较小的元素移到左侧,较大的元素移到右侧。
- 意义:
a[i]和a[j]是需要交换的元素,通过交换它们来维护分区的正确性。
a[p]和a[j]
- 作用:
a[p]是分区的第一个元素(基准值),a[j]是分区完成后基准值的正确位置。 - 行为:
- 在分区完成后,
a[p]和a[j]会交换,将基准值x放到正确的位置。
- 在分区完成后,
- 意义:这一步确保基准值位于分区的中间,左侧元素都小于或等于基准值,右侧元素都大于基准值。
return j
- 作用:
j是分区完成后基准值的最终位置。 - 行为:
- 分区完成后,
j指向基准值的正确位置。 - 函数返回
j,作为递归调用快速排序的分裂点。
- 分区完成后,
- 意义:
j是分区的分裂点,用于将数组分为两部分,分别递归排序。
变量总结
| 变量 | 作用 | 初始值 | 行为 |
|---|---|---|---|
i | 从左向右扫描的指针,寻找大于基准值的元素 | p | 从左向右移动,停在第一个大于 x 的元素或 r |
j | 从右向左扫描的指针,寻找小于或等于基准值的元素 | r + 1 | 从右向左移动,停在第一个小于或等于 x 的元素或 p |
t | 临时变量,用于交换 a[i] 和 a[j] | 无 | 暂存 a[i] 的值,完成交换 |
x | 基准值,用于分区的比较标准 | a[p] | 作为分区的标准,所有元素与 x 比较 |
a[i] | 从左向右扫描时找到的第一个大于 x 的元素 | 无 | 与 a[j] 交换,移到右侧 |
a[j] | 从右向左扫描时找到的第一个小于或等于 x 的元素 | 无 | 与 a[i] 交换,移到左侧 |
a[p] | 分区的第一个元素(基准值) | 无 | 与 a[j] 交换,将基准值放到正确位置 |
j | 分区完成后基准值的最终位置,作为返回值 | 无 | 返回 j,作为递归调用的分裂点 |
变量之间的关系
i和j是双指针,分别从左右两端向中间扫描,寻找需要交换的元素。x是基准值,决定了分区的划分标准。t是辅助变量,用于交换a[i]和a[j]。- 分区完成后,
a[p]和a[j]交换,确保基准值位于正确的位置。 - 最终返回
j,作为分区的分裂点,用于递归调用快速排序。
测试代码
#include<stdio.h>
int Partition(int a[], int p, int r) {
int i = p, j = r + 1;
int t;
int x = a[p];//a[p]作为划分基准
while (1) {
while (a[++i] <= x && i < r);//从左向右找大于x的数的位置下标i,找不到时i==j
while (a[--j] > x);//从右向左找小于等于x的数的位置下标j,找不到时j==p
if (i >= j)
break;//一遍扫描结束,退出循环
t = a[i];
a[i] = a[j];
a[j] = t; //交换a[i]和a[j]
}
a[p] = a[j]; //首元素a[p]与a[j]交换
a[j] = x; //x放在分界点
return j; //j是分裂位置
}
void QuickSort(int a[], int p, int r) {
int q;
if (p < r)
{
q = Partition(a, p, r);
QuickSort(a, p, q - 1);//对左数组排序
QuickSort(a, q + 1, r);//对右数组排序
}
return;
}
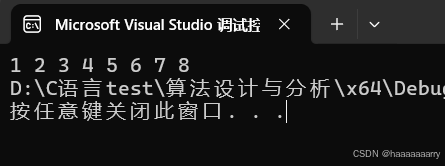
int main() {
int a[8] = { 4,7,1,5,3,8,2,6 };
int p = 0, r = 7;
QuickSort(a, p, r);
for (int i = 0; i <= r; i++)
printf("%d ", a[i]);
return 0;
}
运行结果
算法分析
快速排序的整体时间复杂度取决于分组操作的分裂点以及递归调用的深度。以下是详细的时间复杂度分析:
- 分区操作的时间复杂度
- 每次调用
Partition函数的时间复杂度是 O(n)(对数组进行一次扫描),其中n是当前子数组的长度。 - 分区操作会将数组分为两部分:
- 左侧部分:所有元素小于或等于基准值。
- 右侧部分:所有元素大于基准值。
- 每次调用
- 递归调用的深度
- 快速排序通过递归调用对分区后的子数组进行排序。
- 递归调用的深度取决于分区操作的分裂点:
- 如果每次分区都能将数组均匀分成两部分,递归深度为 O(log n)。
- 如果每次分区都极度不均匀(例如,数组已经有序或逆序),递归深度为 O(n)。
- 最好情况
- 分区均匀:每次分区都能将数组均匀分成两部分,即基准值位于数组的中间位置。
- 递归深度:O(log n)。
- 每层的时间复杂度:O(n)。
- 总时间复杂度:O(n) × O(log n) = O(n log n)。
- 最坏情况
- 分区极度不均匀:每次分区都只能将数组分成
一个元素和剩余n-1个元素(例如,数组已经有序或逆序)。 - 递归深度:O(n)。
- 每层的时间复杂度:O(n)。
- 总时间复杂度:O(n) × O(n) = O(n²)。
T ( n ) = { T ( n − 1 ) + n n > 1 1 n = 1 T(n)=\Big\{^{1 \quad n=1}_{T(n-1)+n \quad n>1} T(n)={T(n−1)+nn>11n=1
- 平均情况
- 分区随机:在随机数据下,分区操作的分裂点通常是均匀的。
- 递归深度:O(log n)。
- 每层的时间复杂度:O(n)。
- 总时间复杂度:O(n) × O(log n) = O(n log n)。
- 空间复杂度
- 递归调用栈:
- 最好情况下,递归深度为 O(log n),空间复杂度为 O(log n)。
- 最坏情况下,递归深度为 O(n),空间复杂度为 O(n)。
- 原地排序:快速排序是原地排序算法,不需要额外的存储空间(除了递归调用栈)。
- 稳定性
快速排序的过程演示可以看这篇文章