Kafka生产者是Kafka消息队列的消息发送端,负责将消息从客户端发送到 Kafka 集群的指定 Topic 下的各个 Partition分区中。并可提供消息预处理、数据序列化、数据压缩、传输确认等数据处理与传输功能。
本文内容为KafkaProducer消息生产过程的源码解析,详细解析了Kafka消息生产中,数据预处理、元数据更新、数据序列化、消息分区、写入消息累加器等各个环节的Kafka源码,完整展现了KafkaProducer进行消息生产的各步骤操作细节。
1.KafkaProducer消息生产功能概述
KafkaProducer的消息生产功能,具体过程包括:拦截器的数据预处理、元数据更新、消息Key与Value的数据序列化、消息的Partition分区ID生成,最终写入RecoredAccumulator消息累加器中,供Sender拉取并向Kafka集群发送。
具体步骤如下:
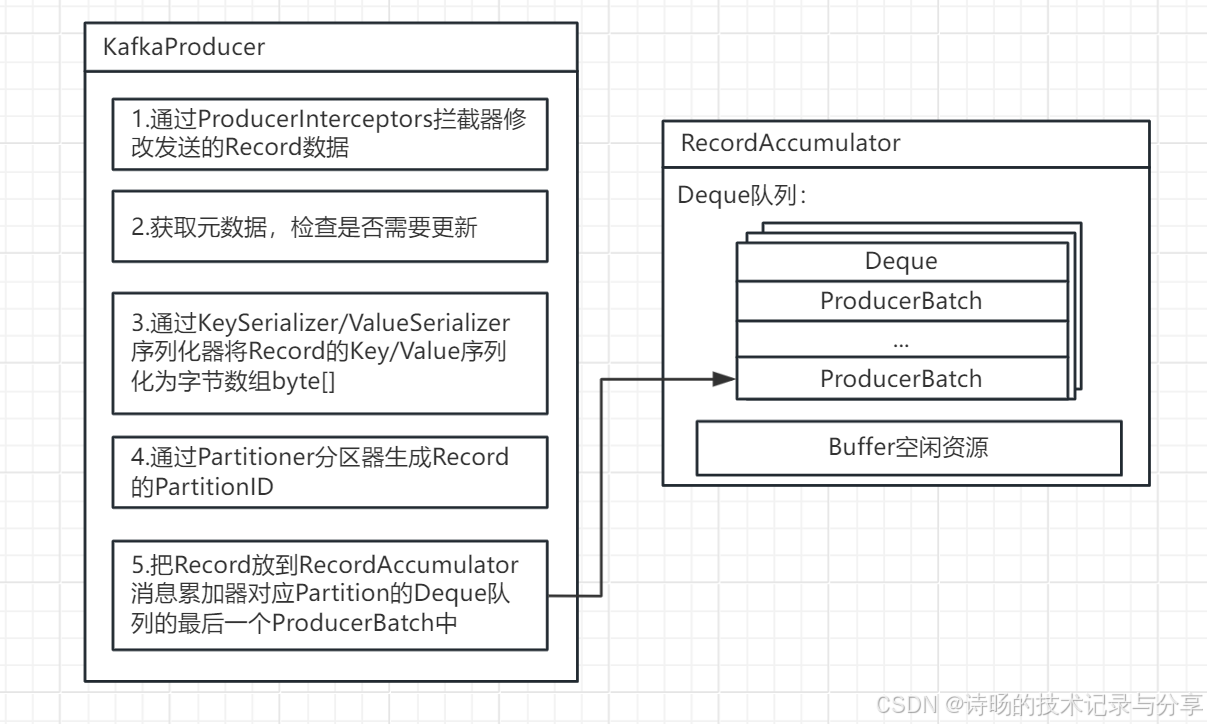
1.KafkaProducer通过遍历ProducerInterceptors拦截器对需要发送的Record消息进行数据预处理。
2.若待发送Record消息所在的Topic和其Partition分区不在本地MetadataCache元数据缓存,KafkaProducer需通过Sender更新元数据。
3.KafkaProducer通过KeySerializer/ValueSerializer序列化器将Record的Key/Value序列化为byte[]字节数组。
4.KafkaProducer通过Partitioner分区器生成Record的Partition分区ID。
5.KafkaProducer把Record追加写入RecordAccumulator消息累加器对应Partition的Deque队列的最后一个ProducerBatch中。
完整的KafkaProducer数据生产过程详解如下:
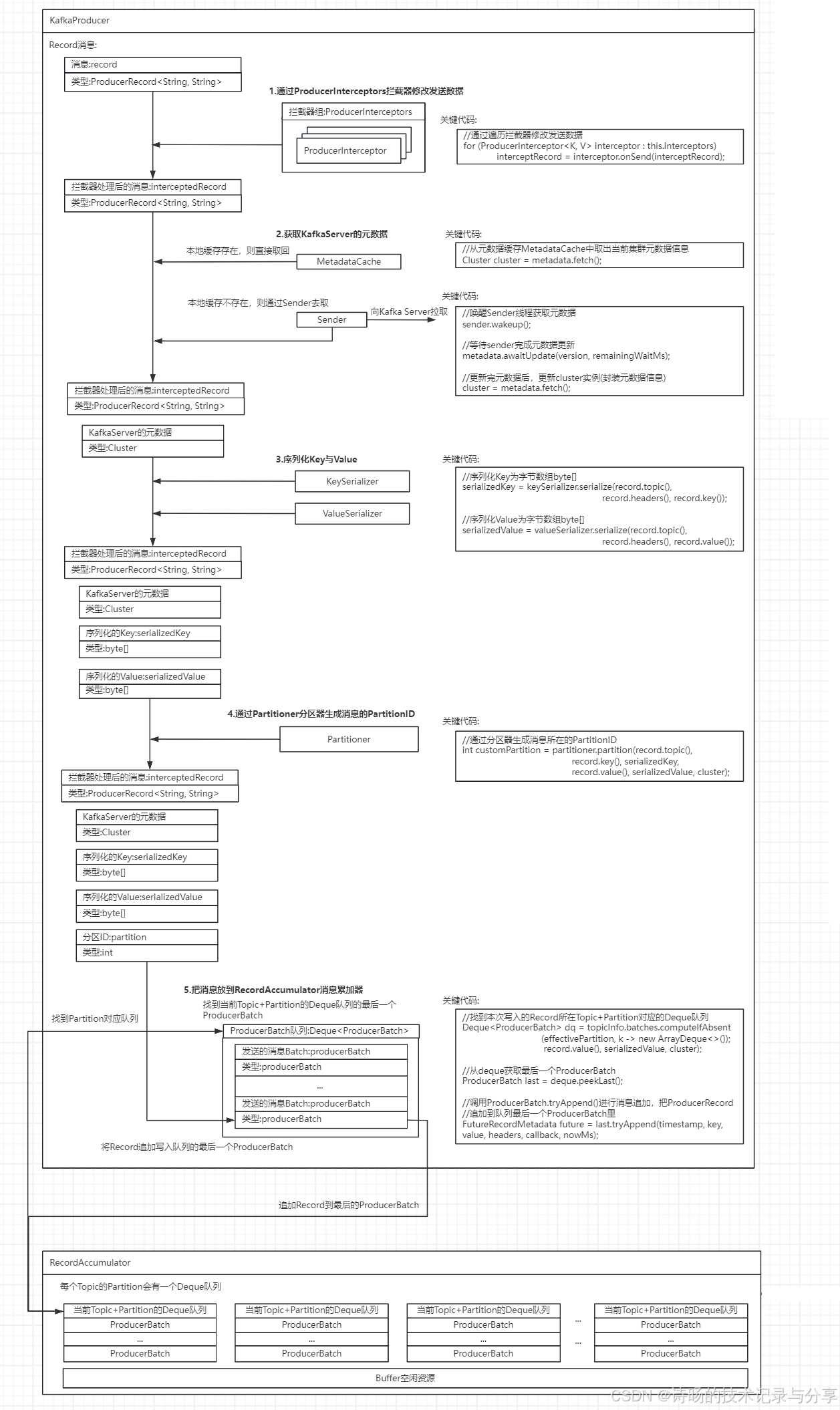
完整代码解析:
下面开始具体展开Kafka消息生产的各步骤的源码解析。
2.消息生产程序入口
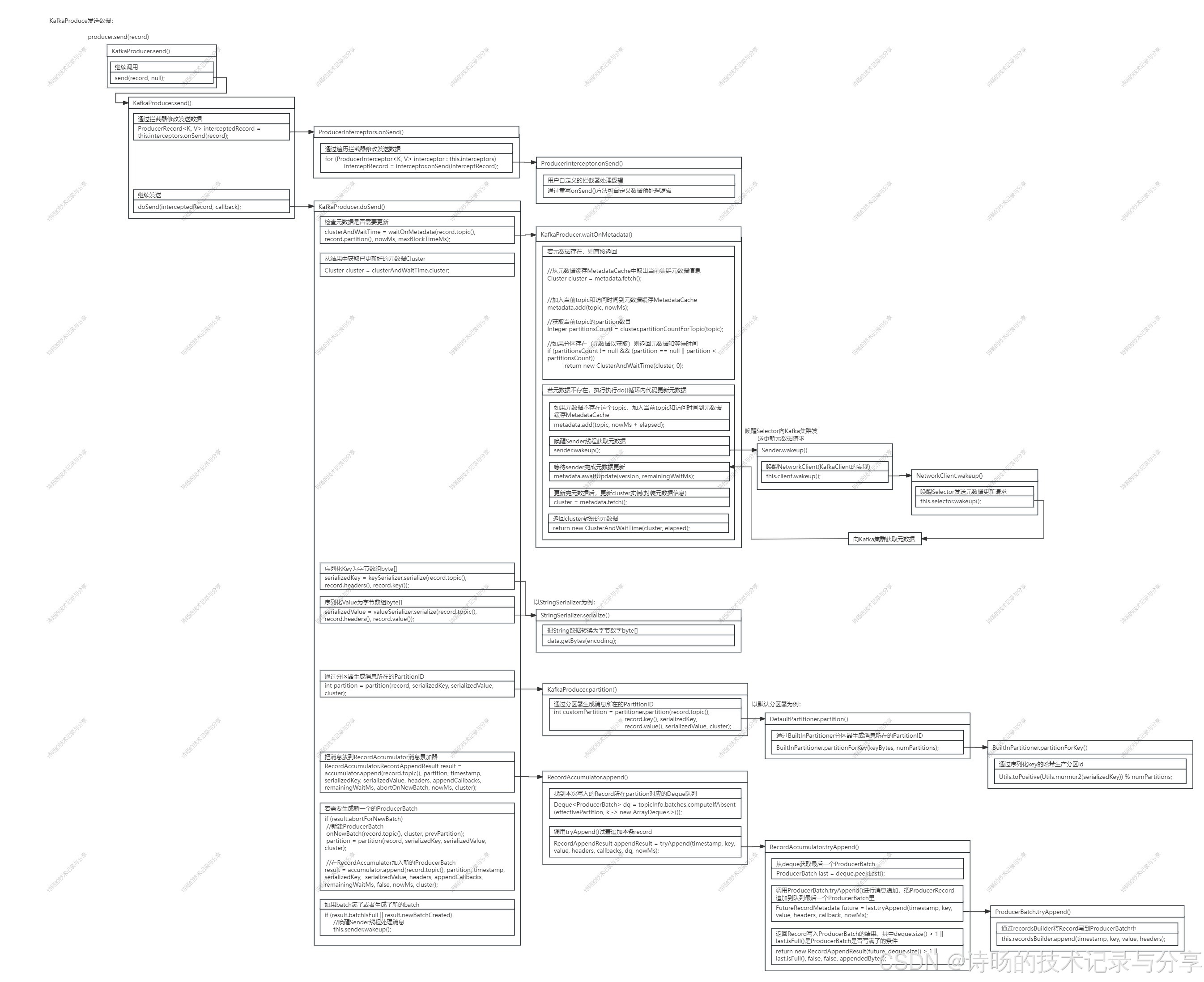
从Kafka Api中可以看出,无论同步还是异步发送,当调用KafkaProducer.send()方法时,程序进入消息生产与发送逻辑。因此程序入口为:KafkaProducer.send()方法。
//同步发送消息
producer.send(record)
//异步发送消息
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception == null) {
// 消息发送成功
System.out.println("消息发送成功");
} else {
// 消息发送失败,需要重新发送
System.out.println("消息发送失败");
}
}
});为统一同步与异步发送,同步发送会多封装一层,传递参数callback为null,继续调用异步发送使用的带callback参数的KafkaProducer.send()方法。
源码图解:
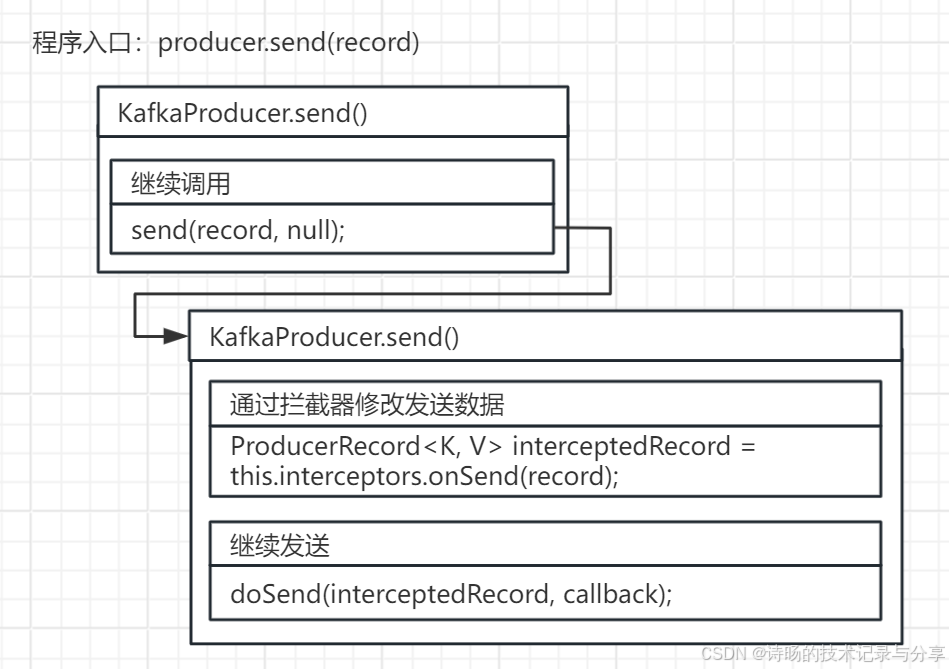
KafkaProducer.send()-不带callback参数-方法源码:
public Future<RecordMetadata> send(ProducerRecord<K, V> record) {
return send(record, null);
}进入带callback参数的KafkaProducer.send()后开始进入了正式的消息生产逻辑。
KafkaProducer.send()-带callback参数-方法源码:
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
//通过拦截器对record消息进行数据预处理
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
//继续调用doSend()方法进入后续数据处理
return doSend(interceptedRecord, callback);
}从KafkaProducer.send()方法可以看出消息生产第一个步骤是通过拦截器进行数据预处理。
3. 通过ProducerInterceptors拦截器对消息进行数据预处理
KafkaProducer对Record消息进行数据预处理,是通过遍历ProducerInterceptors拦截器实现的。
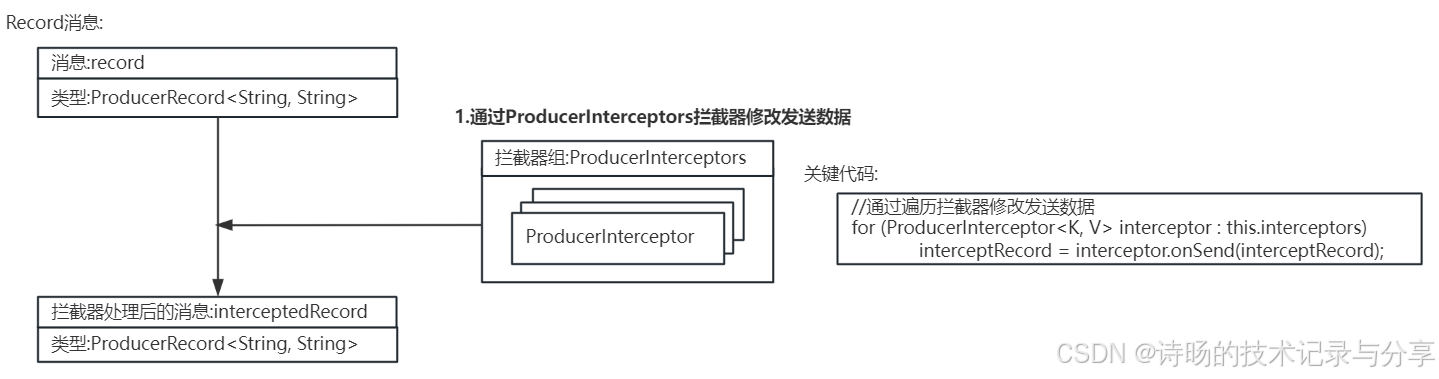
在 KafkaProducer.send()方法中, KafkaProducer调用ProducerInterceptors拦截器的onSend()方法进行数据预处理,ProducerInterceptors.onSend()方法遍历了所有的ProducerInterceptors拦截器,调用每个ProducerInterceptor拦截器的onSend()方法对待发送的Record消息进行预处理。
源码图解:
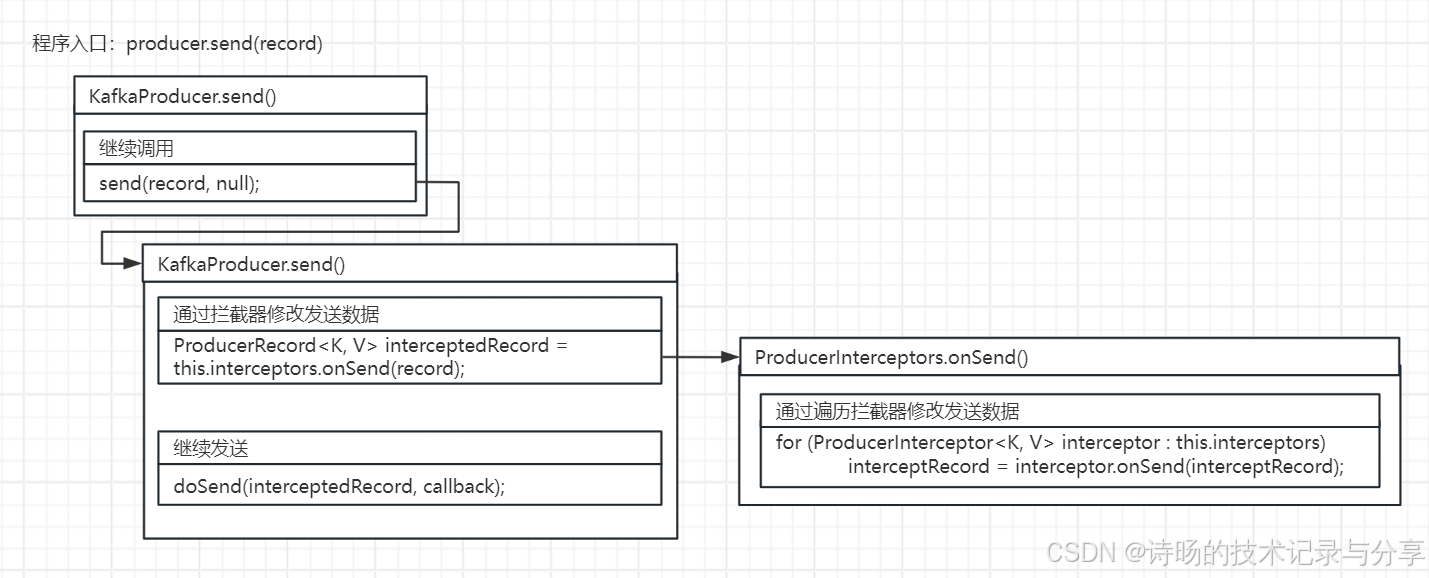
KafkaProducer.send()方法首先调用了ProducerInterceptors的onSend() 方法。
KafkaProducer.send()方法源码:
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
//通过拦截器对record消息进行数据预处理
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
//继续调用doSend()方法进入后续数据处理
return doSend(interceptedRecord, callback);
}ProducerInterceptors的onSend() 方法遍历了所有的拦截器,依次调用每个ProducerInterceptor拦截器的onSend() 进入具体预处理逻辑。
ProducerInterceptors.onSend()方法源码:
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record) {
//...
ProducerRecord<K, V> interceptRecord = record;
//遍历每个拦截器进行具体的数据预处理逻辑
for (ProducerInterceptor<K, V> interceptor : this.interceptors) {
interceptRecord = interceptor.onSend(interceptRecord);
}
return interceptRecord;
//...
}
数据预处理功能,用户可编写自定义拦截器实现org.apache.kafka.clients.producer .ProducerInterceptor接口的onSend()方法来研发自己的数据预处理逻辑。
ProducerInterceptor接口源码:
public interface ProducerInterceptor<K, V> extends Configurable, AutoCloseable {
//数据预处理方法
ProducerRecord<K, V> onSend(ProducerRecord<K, V> record);
void onAcknowledgement(RecordMetadata metadata, Exception exception);
void close();
}处理完拦截器数据预处理后,KafkaProducer.send()继续调用KafkaProducer的doSend()方法继续执行后续消息生产逻辑。
//继续调用doSend()方法进入后续数据处理
return doSend(interceptedRecord, callback);KafkaProducer的doSend()方法实现了消息生产的主逻辑,包括:获取集群的元数据;消息的数据序列化;消息的Partition分区ID生成;最终将消息追加写入RecordAccumulator消息累加器的最后一个ProducerBatch中。
源码图解:

ProducerInterceptors.onSend()方法源码:
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
//...
//获取元数据
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
//从结果中获取已更新好的元数据Cluster
Cluster cluster = clusterAndWaitTime.cluster;
//...
//序列化Key为字节数组byte[]
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
//序列化Value为字节数组byte[]
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
//...
//通过分区器生成消息所在的PartitionID
int partition = partition(record, serializedKey, serializedValue, cluster);
//...
//把消息放到RecordAccumulator消息累加器
RecordAccumulator.RecordAppendResult result = accumulator.append(record.topic(), partition, timestamp, serializedKey, serializedValue, headers, appendCallbacks, remainingWaitMs, abortOnNewBatch, nowMs, cluster);
//若需要生成新一个的ProducerBatch
if (result.abortForNewBatch){
//新建ProducerBatch
onNewBatch(record.topic(), cluster, prevPartition);
partition = partition(record, serializedKey, serializedValue, cluster);
//在RecordAccumulator加入新的ProducerBatch
result = accumulator.append(record.topic(), partition, timestamp, serializedKey, serializedValue, headers, appendCallbacks, remainingWaitMs, false, nowMs, cluster);
}
//如果batch满了或者生成了新的batch
if (result.batchIsFull || result.newBatchCreated) {
//唤醒Sender线程处理消息
this.sender.wakeup();
}
//...
//最终返回写入RecordAccumulator的结果
return result.future;
}下面进入KafkaProducer.doSend()方法每项功能的具体解析。
4.获取Kafka元数据,检查元数据是否需要更新
每次消息写入时,KafkaProducer会检查本地元数据缓存是否包含本次写入的消息的Topic与partition,若不存在,则需要拉取集群最新的元数据。
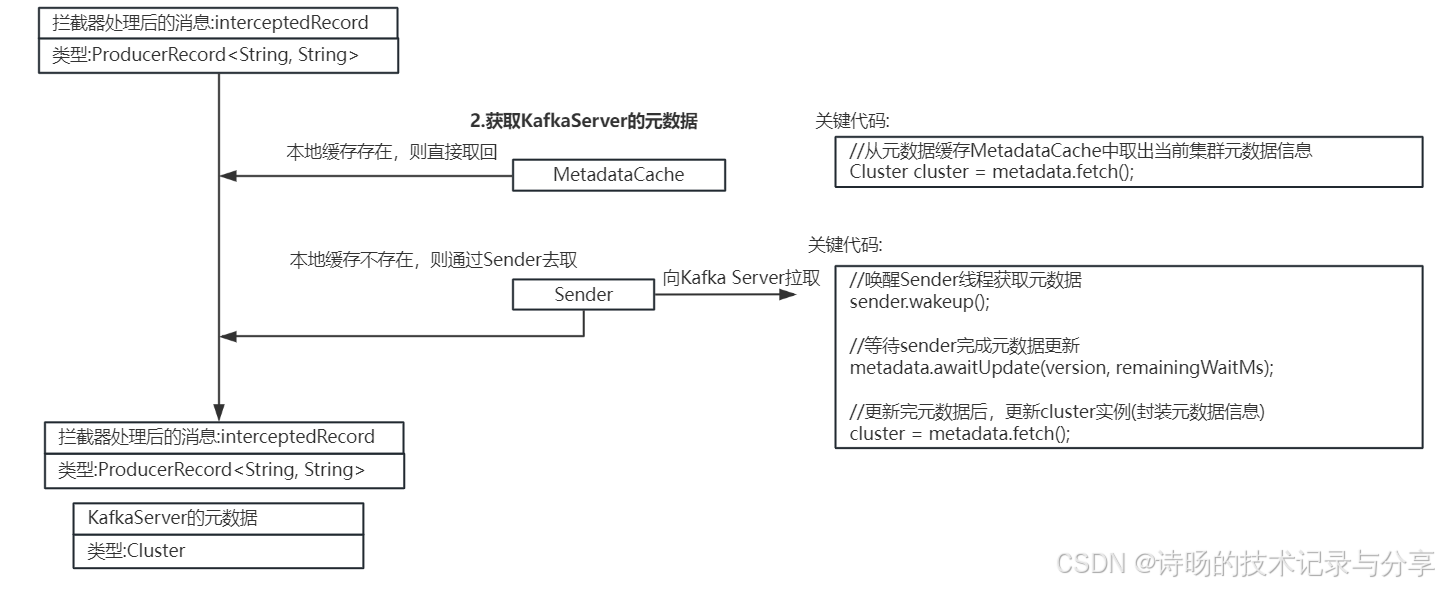
Kafka Producer会从MetadataCache元数据缓存中取出当前Kafka集群的元数据信息,若当前消息需要发送到的Topic和其Partition不在MetadataCache元数据缓存中,则需要通过Sender向Kafka集群重新拉取元数据。
源码图解:
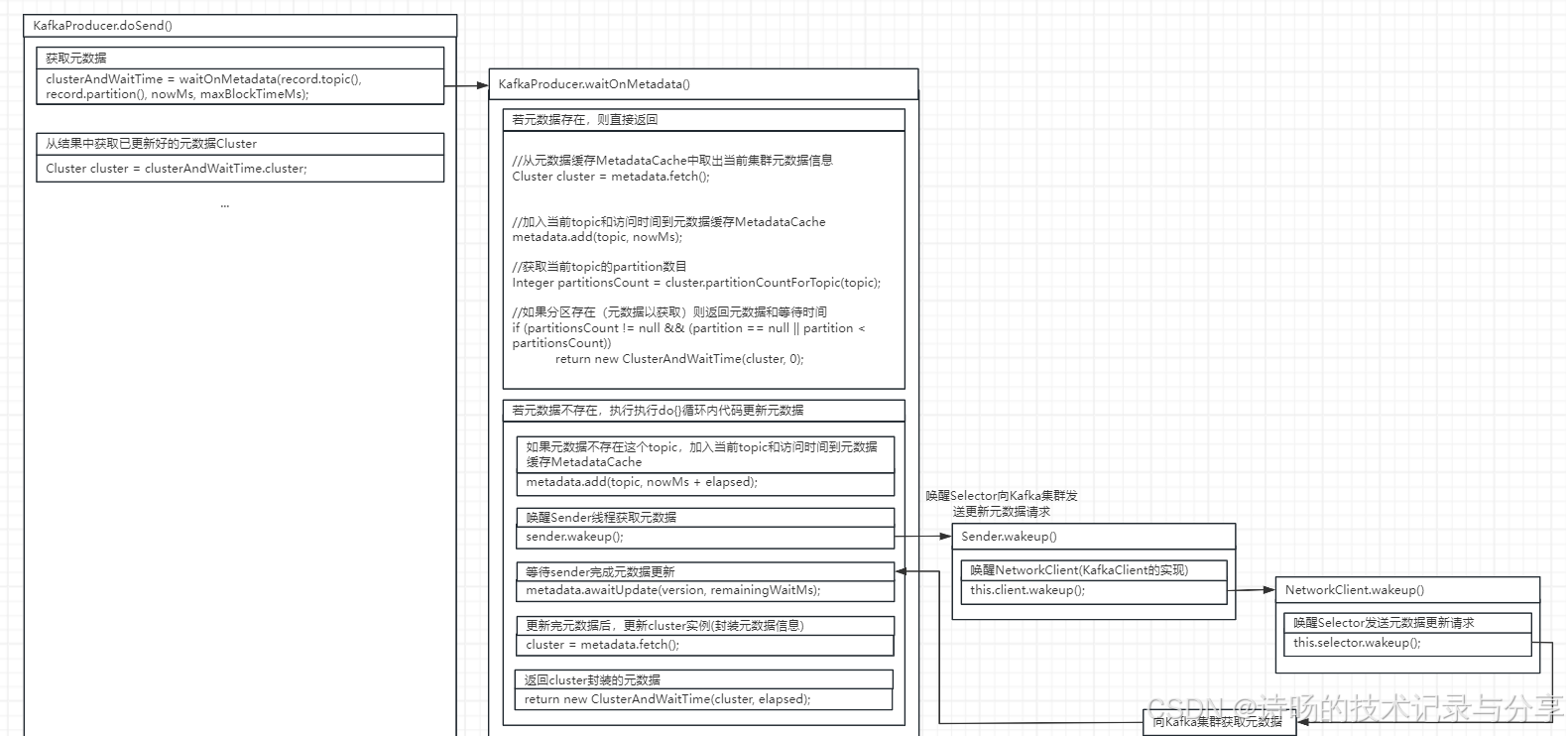
首先进入KafkaProducer.doSend()方法,方法调用了waitOnMetadata()方法判断元数据是否需要更新,并把最新的Kafka元数据封装为Cluster。
KafkaProducer.doSend()方法元数据更新的源码:
//检查元数据是否需要更新
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
//从结果中获取最新的元数据Cluster
Cluster cluster = clusterAndWaitTime.cluster;KafkaProducer.waitOnMetadata()方法为判断元数据是否需要更新的方法。首先在本地元数据存储中查找消息的topic和partiton是否存在,存在则返回,不存在则执行后面do-while()逻辑进行元数据的更新拉取逻辑。
KafkaProducer.waitOnMetadata()方法源码:
private ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long nowMs, long maxWaitMs) throws InterruptedException {
//从元数据缓存MetadataCache中取出当前集群元数据信息
Cluster cluster = metadata.fetch();
//加入当前topic和访问时间到元数据缓存MetadataCache
metadata.add(topic, nowMs);
//获取当前topic的partition数目
Integer partitionsCount = cluster.partitionCountForTopic(topic);
//如果分区存在(元数据以获取)则返回元数据和等待时间
if (partitionsCount != null && (partition == null || partition < partitionsCount))
return new ClusterAndWaitTime(cluster, 0);
//如果分区不存在,则执行下面do-while()逻辑更新元数据
do {
//如果元数据不存在这个topic,加入当前topic和访问时间到元数据缓存MetadataCache
metadata.add(topic, nowMs + elapsed);
//唤醒Sender线程获取元数据
sender.wakeup();
//等待sender完成元数据更新
metadata.awaitUpdate(version, remainingWaitMs);
//更新完元数据后,更新cluster实例(封装元数据信息)
cluster = metadata.fetch();
//返回cluster封装的元数据
return new ClusterAndWaitTime(cluster, elapsed);
} while (partitionsCount == null || (partition != null && partition >= partitionsCount));
}若不存在则需要更新元数据,元数据的更新拉取是通过唤醒Sender向Kafka集群拉取实现的,调用了sender.wakeup()方法通过Sender拉取,并通过metadata.awaitUpdate()方法获取拉取后最新的元数据。
Sender底层通讯是通过NetworkClient实现的,因此Sender又唤醒了NetworkClient进行具体的数据通信。
Sender.wakeup()方法源码:
public void wakeup() {
this.client.wakeup();
}具体NetworkClient拉取元数据的源码解析,将放在后文介绍 Sender与NetworkClient进行数据发送时详细解析。
5. 通过序列化器进行消息的Key与Value的数据序列化
在消息Record发送前,KafkaProducer需要把Key与Value序列化成byte[]字节数组,将应用数据序列化为字节流,以实现高效的消息传输。
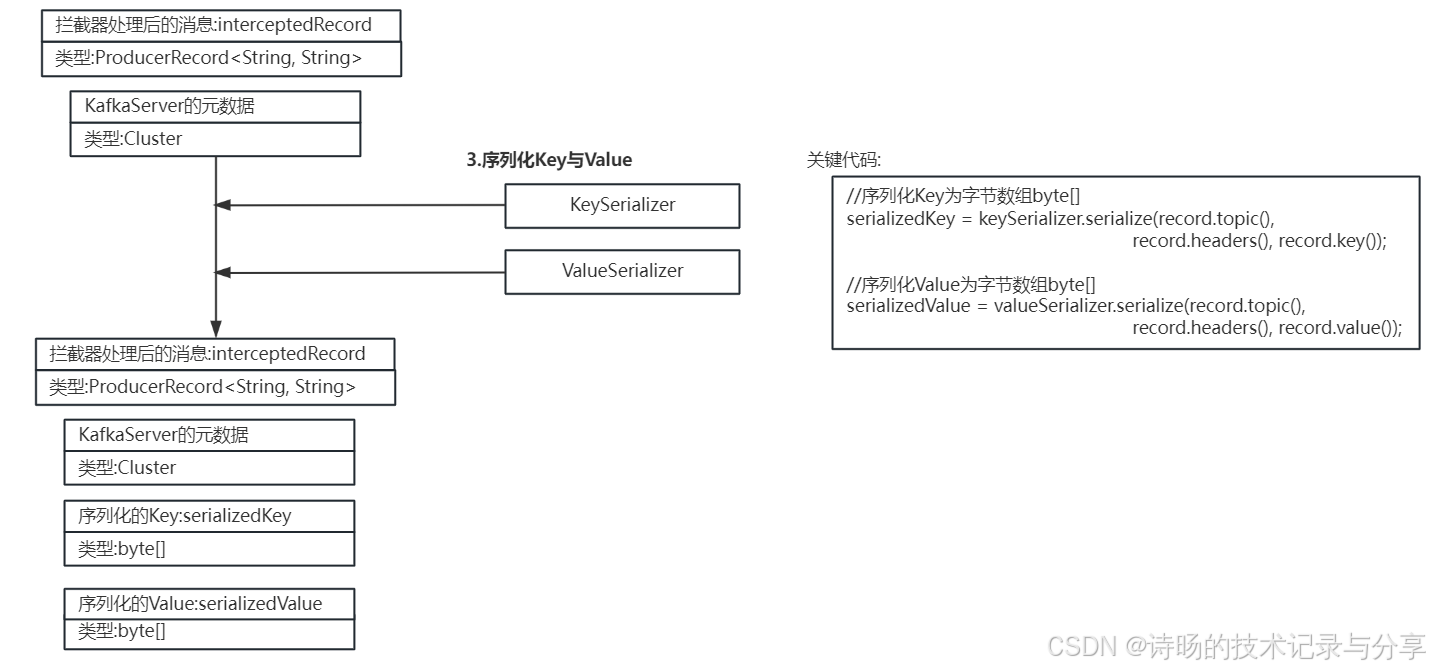
KafkaProducer.doSend()方法,KafkaProducer调用了keySerializer和valueSerializer序列化器的serialize()方法对消息进行了数据序列化。序列化器的serialize()方法为数据序列化的内容,具体代码为把当前数据类型转换为byte[]字节数组的序列化逻辑。
源码图解:
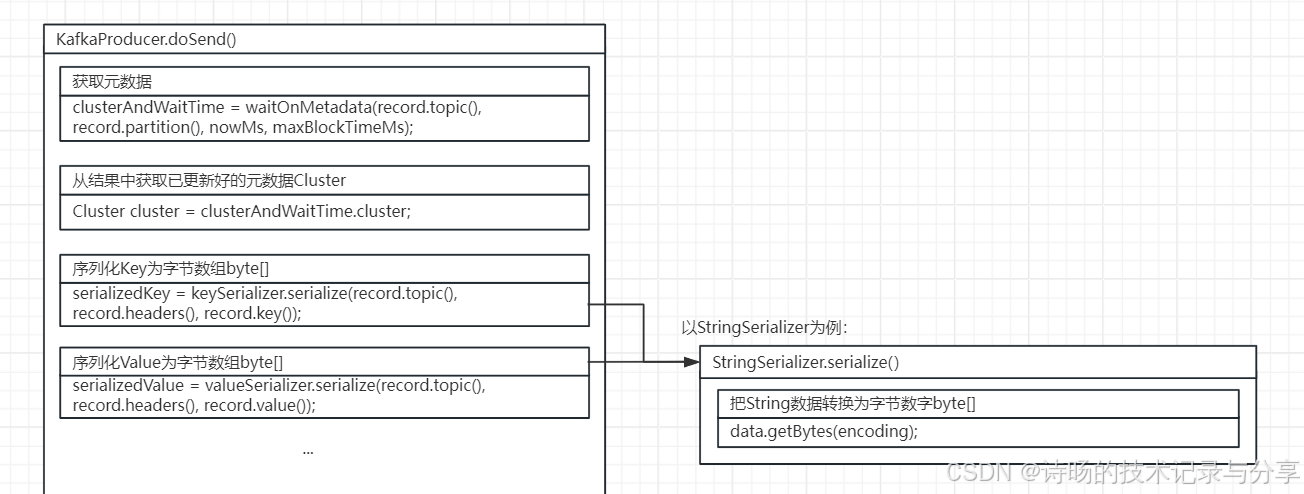
在KafkaProducer.doSend()方法,KafkaProducer分别调用了keySerializer和valueSerializer序列化器的serialize()方法,对消息的Key和Value进行了序列化。
KafkaProducer.doSend()方法序列化部分的源码:
//序列化Key为字节数组byte[]
serializedKey = keySerializer.serialize(record.topic(),record.headers(), record.key());
//序列化Value为字节数组byte[]
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());序列化器的serialize()为具体序列化的逻辑,以StringSerializer为例,serialize()方法中包含了字符串转换为byte[]字节数组的逻辑。
StringSerializer.serialize()方法源码:
public class StringSerializer implements Serializer<String> {
private Charset encoding = StandardCharsets.UTF_8;
//...
//序列化方法
@Override
public byte[] serialize(String topic, String data) {
if (data == null)
return null;
else
//将字符串转换为byte[]数组
return data.getBytes(encoding);
}
}自定义序列化器:
研发时也可编写自定义序列化器拓展数据序列化功能,可通过实现org.apache.kafka.common.serialization.Serializer接口,重写serialize()方法实现自己的序列化逻辑。
Serializer接口源码:
public interface Serializer<T> extends Closeable {
//序列化方法
byte[] serialize(String topic, T data);
//...
}6.通过Partitioner分区器生成消息的Partition分区ID
KafkaProducer需要为每个Record消息生成Partition分区ID,分配到指定的Partition分区,为消息进行路由选择。
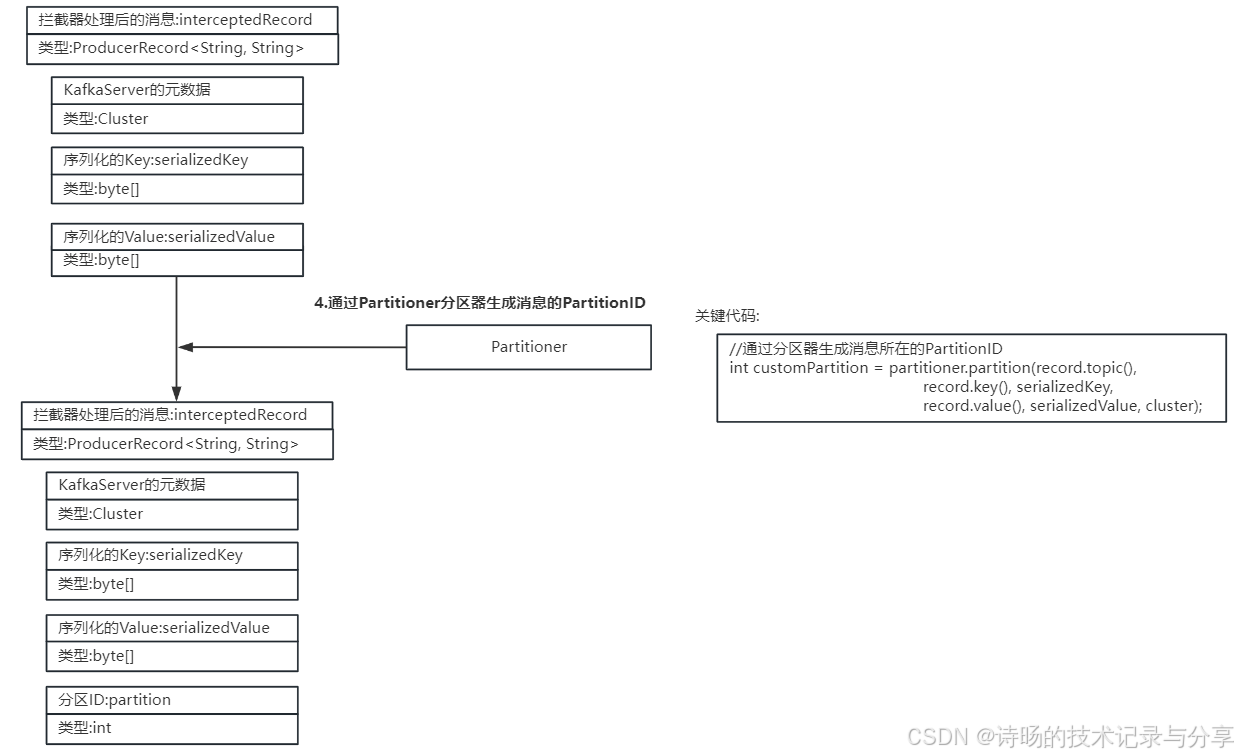
在KafkaProducer.doSend()方法中,KafkaProducer先调用了自己的partition()方法,KafkaProducer.partition()方法又具体调用了partitioner序列化器的partition()方法,完成对对消息生成partition分区ID的功能。
源码图解:
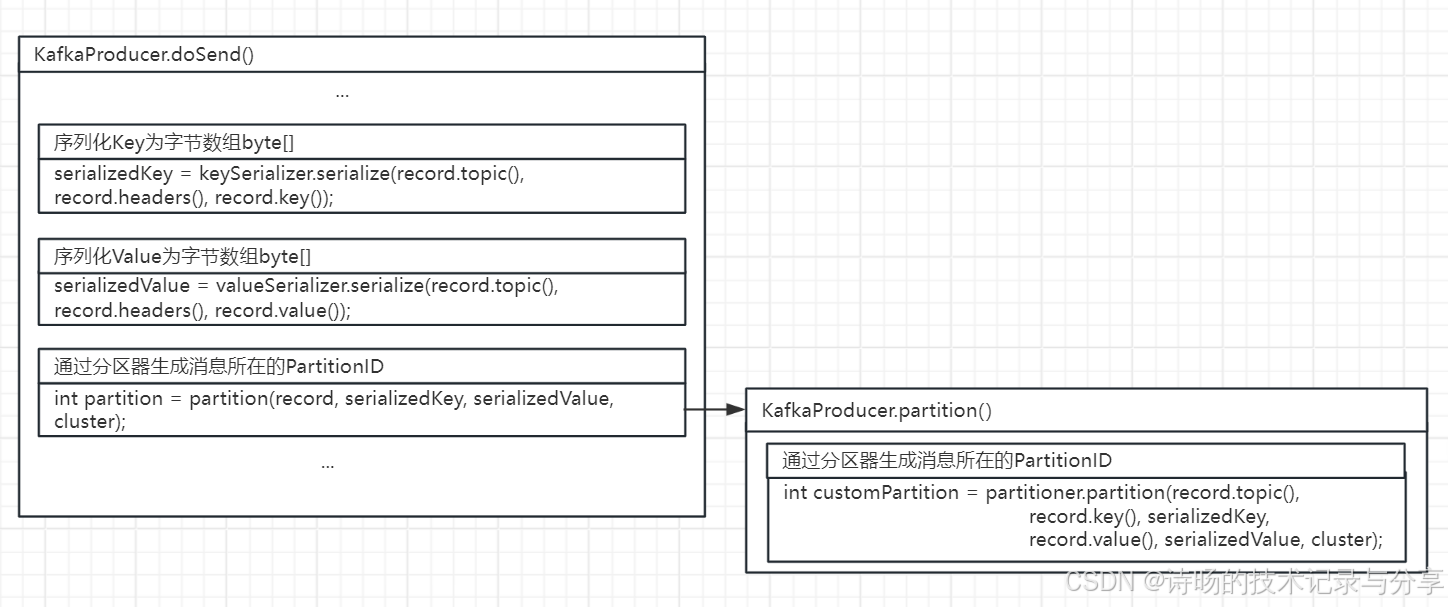
KafkaProducer的分区功能首先是在KafkaProducer.doSend()方法中调用了KafkaProducer自身的partition()方法。
KafkaProducer.doSend()分区部分的源码:
//通过分区器生成消息所在的PartitionID
int partition = partition(record, serializedKey, serializedValue, cluster);KafkaProducer.partition()中又调用了partitioner分区器的partition()方法执行具体的分区逻辑。
KafkaProducer.partition()方法源码:
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
//...
//通过调用partitioner分区器的partition()进行分区id生成
int customPartition = partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
//返回值为生成的partition分区id
return customPartition;
//...
}Kafka在org.apache.kafka.clients.producer.internals包中内置了DefaultPartitioner默认分区器,会根据Key的哈希值为Record生成Partition分区ID。研发时也可编写自定义分区器,通过实现org.apache.kafka.clients.producer.Partitioner接口,重写partition()方法实现自己的分区逻辑。
源码图解:

以默认分区器DefaultPartitioner为例。
DefaultPartitioner.partition()方法源码:
public class DefaultPartitioner implements Partitioner {
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster, int numPartitions) {
//...
//通过BuiltInPartitioner进行分区
return BuiltInPartitioner.partitionForKey(keyBytes, numPartitions);
}
//...
}再看BuiltInPartitioner.partitionForKey()方法的具体分区逻辑
BuiltInPartitioner.partitionForKey()方法源码:
public class BuiltInPartitioner {
//...
//通过对序列化key做hash,再取模到partition的范围内,完成对partitionID的生成。
public static int partitionForKey(final byte[] serializedKey, final int numPartitions) {
return Utils.toPositive(Utils.murmur2(serializedKey)) % numPartitions;
}
//...
}BuiltInPartitioner.partitionForKey()方法通过对序列化key做hash,再取模到partition的范围内,完成对partitionID的生成。
自定义分区器:
在研发时,也通过实现org.apache.kafka.clients.producer.Partitioner接口,重写partition()方法实现自己的序列化逻辑。
Partitioner接口源码:
public interface Partitioner extends Configurable, Closeable {
//分区方法
int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
//...
}7.把消息加入RecordAccumulator消息累加器
在完成拦截器的数据预处理、序列化器的数据序列化、分区器的分区ID生成这一系列数据操作后,KafkaProducer需把处理好的Record写入RecordAccumulator消息累加器中,供Sender取走发送给Kafka集群。
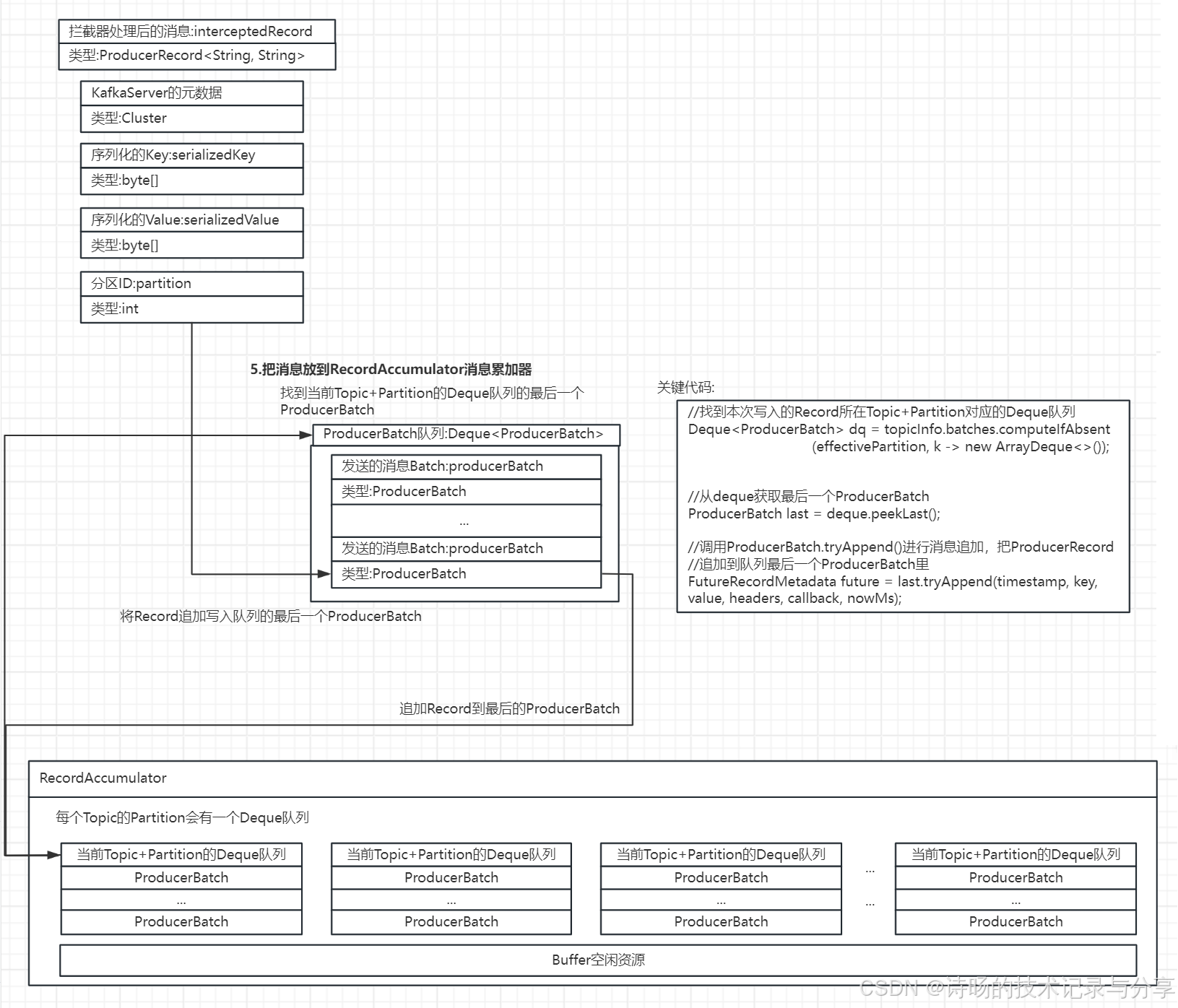
在KafkaProducer.doSend()方法中,通过调用RecordAccumulator消息累加器的append()方法将消息加入到消息累加器中,并提供ProducerBatch写满后,生成新Batch及唤醒Sender发送数据的逻辑。RecordAccumulator.append()则包含了具体的消息写入逻辑,先找到消息所在Partition的Deque队列,再通过tryAddend()方法将消息写入到队列中最后一个ProducerBatch,完成具体数据写入。
源码图解:
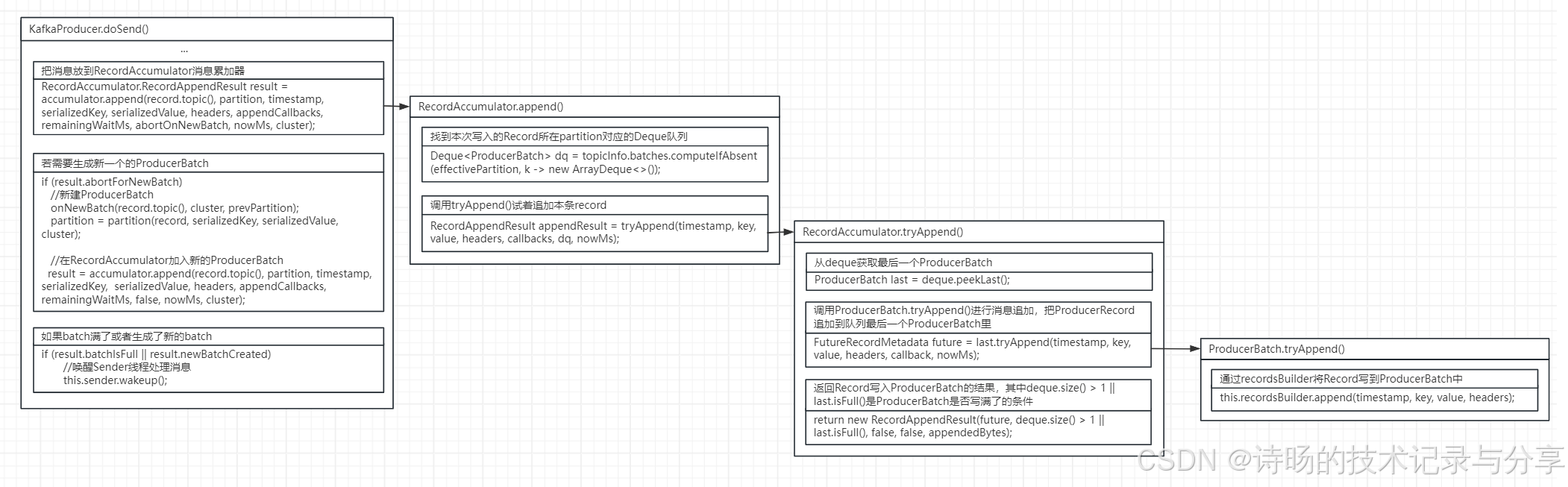
在KafkaProducer.doSend()方法中,KafkaProducer先调用了RecordAccumulator消息累加器的append()方法将消息加入到消息累加器中消息对应partition的队列的最后一个ProducerBatch上。
若出现需要生成新的ProducerBatch的情况,KafkaProducer会生成新的ProducerBatch,并添加到RecordAccumulator消息累加器中。若写满或有新的ProducerBatch生成,KafkaProducer会唤醒Sender,取出RecordAccumulator的ProducerBatch,进行数据发送。
KafkaProducer.doSend()方法写入消息累加器的源码:
//把消息放到RecordAccumulator消息累加器
RecordAccumulator.RecordAppendResult result = accumulator.append(record.topic(), partition, timestamp, serializedKey, serializedValue, headers, appendCallbacks, remainingWaitMs, abortOnNewBatch, nowMs, cluster);
//若生成新一个的ProducerBatch
if (result.abortForNewBatch){
//新建ProducerBatch
onNewBatch(record.topic(), cluster, prevPartition);
partition = partition(record, serializedKey, serializedValue, cluster);
//在RecordAccumulator加入新的ProducerBatch
result = accumulator.append(record.topic(), partition, timestamp, serializedKey, serializedValue, headers, appendCallbacks, remainingWaitMs, false, nowMs, cluster);
}
//如果batch满了或者生成了新的batch
if (result.batchIsFull || result.newBatchCreated){
//唤醒Sender线程处理消息
this.sender.wakeup();
}RecordAccumulator消息累加器的append()方法为消息写入RecordAccumulator消息累加器的具体实现。首先先找到消息对应的Deque队列,再调用tryAddend()方法,把消息加入Deque队列中最后一个ProdcuerBatch中,完成数据写入。
RecordAccumulator.append()方法源码:
public RecordAppendResult append(String topic,
int partition,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
AppendCallbacks callbacks,
long maxTimeToBlock,
boolean abortOnNewBatch,
long nowMs,
Cluster cluster) throws InterruptedException {
//...
//找到本次写入的Record所在partition对应的Deque队列
Deque<ProducerBatch> dq = topicInfo.batches.computeIfAbsent(effectivePartition, k -> new ArrayDeque<>());
//调用tryAppend()试着追加本条record
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callbacks, dq, nowMs);
//...
}RecordAccumulator.tryAddend()方法首先找到了Deque队列的最后一个ProducerBatch,再通过调用ProducerBatch的tryAppend()方法具体完成写入。
RecordAccumulator.tryAddend()方法源码:
private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers,
Callback callback, Deque<ProducerBatch> deque, long nowMs) {
//...
//从deque获取最后一个ProducerBatch
ProducerBatch last = deque.peekLast();
//调用ProducerBatch.tryAppend()进行消息追加,把ProducerRecord追加到队列最后一个ProducerBatch里
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, headers, callback, nowMs);
//返回Record写入ProducerBatch的结果,其中deque.size() > 1 || last.isFull()是ProducerBatch是否写满了的条件
return new RecordAppendResult(future, deque.size() > 1 || last.isFull(), false, false, appendedBytes);
//...
}ProducerBatch.tryAppend()方法为具体的消息写入ProducerBatch的写入逻辑,是通过recordsBuilder将Record消息的时间戳、key、value、headers追加写入到ProducerBatch末尾的位置。
ProducerBatch.tryAppend()方法源码:
public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long now) {
//...
//通过recordsBuilder将Record写到ProducerBatch中
this.recordsBuilder.append(timestamp, key, value, headers);
//...
}当KafkaProducer将消息写入RecordAccumulator消息累加器后,消息生产的全部操作就结束了,下面就由Sender从RecordAccumulator消息累加器取走ProducerBatch数据,将数据发送到Kafka集群,进入数据发送的环节了。
8.RecordAccumulator消息累加器数据存储
从上述消息写入RecordAccumulator消息累加器的过程也可以看到RecordAccumulator消息累加器的数据存储结构。RecordAccumulator是按Partition分区为单位建立Deque队列,以ProducerBatch为存储粒度存储待发送的Record消息。

9.结语
KafkaProducer消息生产过程主要是经历了拦截器的数据预处理、元数据拉取、消息Key与Value的序列化、消息的Partition分区ID生成,最终写入RecoredAccumulator消息累加器中。下文将继续介绍Sender拉取RecoredAccumulator消息累加器的ProducerBatch并向Kafka集群发送的数据发送过程源码。