文章目录
Python OpenCV 入门指南
OpenCV是一个强大的计算机视觉库,它可以用于处理图像和视频数据,以及进行目标检测和跟踪等任务。,将学会如何使用Python编写OpenCV代码来进行基础和进阶的图像处理和分析。
学习OpenCV可以帮助你掌握基本的图像处理技术,包括图像读取和处理、阈值处理、形态学函数、模板匹配、滤波器、图形处理、视频处理和人脸检测等方面的内容。这些技术都是计算机视觉和图像处理领域的基本内容,也是卷积神经网络的基础。通过学习OpenCV,你可以更好地理解卷积神经网络的工作原理和应用。同时,OpenCV也是一个非常流行的图像处理库,掌握它可以帮助你更好地处理和分析图像数据。
参考书籍:Python Opencv从入门到精通
安装OpenCV
在开始编写OpenCV代码之前,我们需要先安装OpenCV库。我们可以通过pip包管理器来安装:
pip install opencv-python
你可以使用conda或者micromamba来安装虚拟环境,安装好notebook环境
打印opencv版本
import cv2
print("OpenCV version:")
print(cv2.__version__)
输出
OpenCV version:
4.7.0
基础篇
图像读取和显示
在开始处理图像之前,我们需要学习如何读取和显示图像。下面的代码演示了如何使用OpenCV库读取和显示图像:
import cv2
读取图像
img = cv2.imread('image.jpg')
显示图像
opencv显示
cv2.imshow('Image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()`
在上面的代码中,我们首先使用cv2.imread()函数读取了一个名为image.jpg的图像文件。然后,我们使用cv2.imshow()函数来显示这个图像,并使用cv2.waitKey()和cv2.destroyAllWindows()函数来等待用户按下任意键,然后关闭显示窗口。
注意如果是使用notebook执行waitKey(0)显示,会存在第二次运行无法显示的问题,可以cv2.waitKey(3)设置指定时间自动结束,
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
img = cv2.imread('image.jpg')
rgbimg = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) #opencv像素顺序是bgr
plt.title(title)
plt.imshow(img, cmap=cmap)
plt.show()
裁剪图像
从左上角坐标为(200, 100)的位置开始,裁剪一个宽为400像素、高为400像素的矩形区域。
cropped = img[100:500, 200:600]
像素操作
在OpenCV中,图像可以表示为三维的数组,其中每个元素都是表示像素值的数字。图像数组的维度取决于图像的大小和通道数。对于一个大小为 h e i g h t × w i d t h height×width height×width 的彩色图像,它的数组形状为 (height,width,3)其中3表示三个颜色通道,即BGR。BGR是指蓝色、绿色、红色三个通道,这是因为在OpenCV中图像的颜色通道排列顺序是B、G、R。
要访问和修改图像中的像素值,可以使用numpy数组的索引方式,例如:
import numpy as np
img = cv2.imread("image.jpg")
# 获取图像宽高
height, width = img.shape[:2]
# 获取某个像素的BGR值
# 在OpenCV中,通常使用img[y,x]的方式来访问图像的像素值,其中y是像素的行坐标,x是像素的列坐标。因此,在你# 提到的img[20, 100]中,20是y坐标,100是x坐标。
b, g, r = img[20, 100]
# 设置某个像素的BGR值
img[100, 100] = (255, 255, 255)
# 获取某个通道的所有像素值
blue_channel = img[:, :, 0]
green_channel = img[:, :, 1]
red_channel = img[:, :, 2]
# 修改某个通道的所有像素值
img[:, :, 0] = 0 # 将蓝色通道设为0`
注意在OpenCV中,通道顺序是BGR而不是RGB。
色彩空间与通道
OpenCV支持多种色彩空间,比如RGB、HSV、YCrCb、Lab等。不同的色彩空间对应着不同的通道,比如RGB色彩空间有3个通道,分别是红色、绿色、蓝色通道。为了进行图像处理,我们通常需要对图像的色彩空间和通道进行转换。
下面是一些OpenCV常用的色彩空间和通道转换函数:
- cv2.cvtColor(src, code[, dst[, dstCn]]):将图像从一个色彩空间转换到另一个色彩空间。其中,src是输入图像,code是色彩空间转换代码,dst是输出图像,dstCn是输出图像的通道数。
比如,将BGR格式的图像转换为灰度图像:
img = cv2.imread('test.jpg')
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
- cv2.split(src[, mv]):将多通道图像分离成单通道图像。其中,src是输入图像,mv是输出单通道图像的列表。
比如,将BGR格式的图像分离成三个通道:
img = cv2.imread('test.jpg')
b, g, r = cv2.split(img)
- cv2.merge(mv[, dst]):将多个单通道图像合并成一个多通道图像。其中,mv是单通道图像的列表,dst是输出的多通道图像。
比如,将三个单通道图像合并成BGR格式的图像:
b = cv2.imread('test_b.jpg', cv2.IMREAD_GRAYSCALE)
g = cv2.imread('test_g.jpg', cv2.IMREAD_GRAYSCALE)
r = cv2.imread('test_r.jpg', cv2.IMREAD_GRAYSCALE)
img = cv2.merge([b, g, r])
- cv2.addWeighted(src1, alpha, src2, beta, gamma[, dst]):将两个图像按照一定比例进行融合。其中,src1和src2是两个输入图像,alpha和beta是两个图像的权重,gamma是亮度调整值,dst是输出的融合后的图像。
比如,将两个灰度图像按照1:2的比例融合:
img1 = cv2.imread('test1.jpg', cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread('test2.jpg', cv2.IMREAD_GRAYSCALE)
img = cv2.addWeighted(img1, 1, img2, 2, 0)
BGR色彩空间是基于三基色而言的,三基色指的是红色、绿色和蓝色。
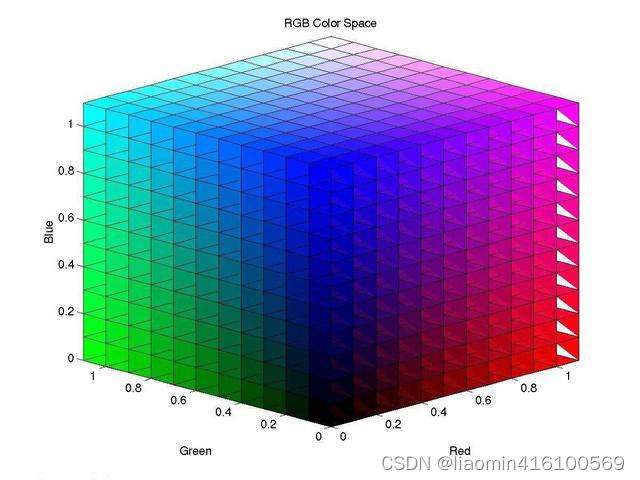
而HSV色彩空间则是基于色调、饱和度和亮度而言的。

其中,色调(H)是指光的颜色,例如,彩虹中的赤、橙、黄、绿、青、蓝、紫分别表示不同的色调,在OpenCV中,色调在区间[0, 180]内取值。例如,代表红色、黄色、绿色和蓝色的色调值分别为0、30、60和120。
饱和度(S)是指色彩的深浅。在OpenCV中,饱和度在区间[0, 255]内取值。当饱和度为0时,图像将变为灰度图像。
亮度(V)是指光的明暗。与饱和度相同,在OpenCV中,亮度在区间[0, 255]内取值。亮度值越大,图像越亮;当亮度值为0时,图像呈纯黑色
图像几何变换
OpenCV提供了许多基础的图像变换函数,可以用于调整图像的大小、旋转、平移、裁剪等操作。下面的代码演示了如何使用这些函数:
缩放图像
将img图像对象缩小了一半并赋值给了resized
resized = cv2.resize(img, (int(img.shape[1]/2), int(img.shape[0]/2)))
仿射变换
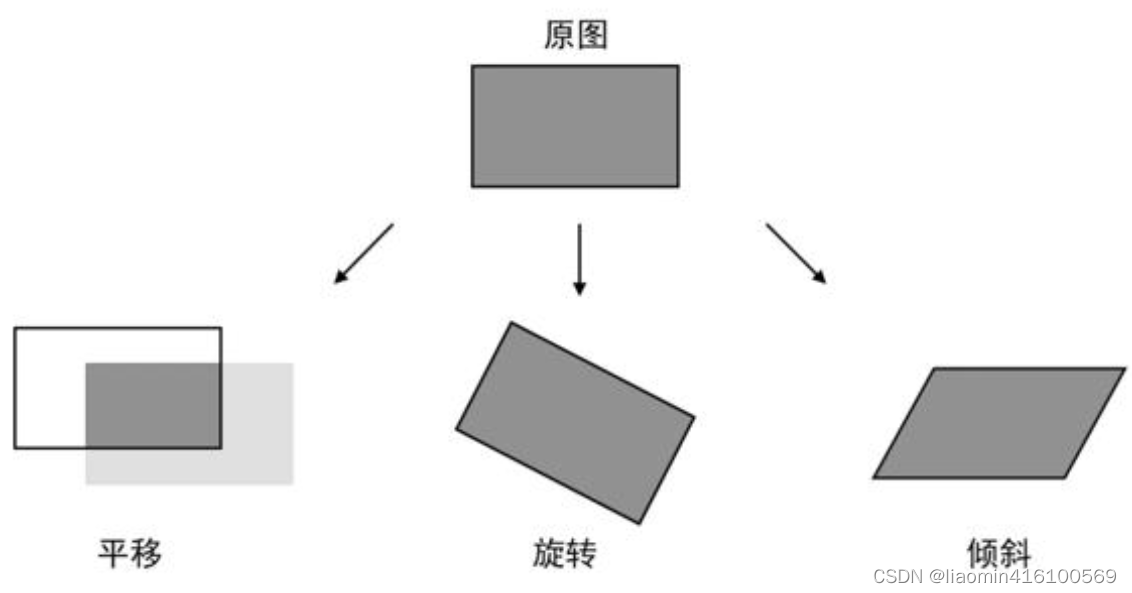
仿射变换是一种仅在二维平面中发生的几何变形,变换之后的图像仍然可以保持直线的“平直性”和“平行性”,也就是说原来的直线变换之后还是直线,平行线变换之后还是平行线。常见的仿射变换效果如图所示,包含平移、旋转和倾斜。
OpenCV通过cv2. warpAffine()方法实现仿射变换效果,其语法如下:
dst = cv2.warpAffine(src, M, dsize, flags, borderMode, borderValue)
参数说明:
- src:原始图像。
- M:一个2行3列的矩阵,根据此矩阵的值变换原图中的像素位置。
- dsize:输出图像的尺寸大小。
- flags:可选参数,插值方式,建议使用默认值。
- borderMode:可选参数,边界类型,建议使用默认值。
- borderValue:可选参数,边界值,默认为0,建议使用默认值。
返回值说明:
- dst:经过反射变换后输出图像。
M也被叫作仿射矩阵,实际上就是一个2×3的列表,其格式如下:
M = [[a, b, c],[d, e, f]]
图像做何种仿射变换,完全取决于M的值,仿射变换输出的图像按照以下公式进行计算:
新x = 原x × a + 原y × b + c
新y = 原x × d + 原y × e + f
原x和原y表示原始图像中像素的横坐标和纵坐标,新x与新y表示同一个像素经过仿射变换后在新图像中的横坐标和纵坐标。
平移图像
平移就是让图像中的所有像素同时沿着水平或垂直方向移动。实现这种效果只需要将M的值按照以下格式进行设置:
M = [[1, 0, 水平移动的距离],[0, 1, 垂直移动的距离]]
原始图像的像素就会按照以下公式进行变换:
新x = 原x × 1 + 原y × 0 + 水平移动的距离 = 原x + 水平移动的距离
新y = 原x × 0 + 原y × 1 + 垂直移动的距离 = 原y + 垂直移动的距离
M = np.float32([[1, 0, 100], [0, 1, 50]])
translated = cv2.warpAffine(img, M, (img.shape[1], img.shape[0]))

旋转图像
首先获取了img图像对象的行数和列数,并分别赋值给了rows和cols变量。接着,使用cv2.getRotationMatrix2D函数,生成了一个旋转矩阵M,
其中第一个参数是旋转中心点的坐标,这里是图像中心点(cols/2, rows/2);
第二个参数是旋转的角度,这里是30度;
第三个参数是旋转后的缩放比例,这里是1,表示不进行缩放。最后,使用cv2.warpAffine函数将原始图像对象img按照旋转矩阵M进行旋转,并将结果赋值给rotated。warpAffine函数的第一个参数是需要被旋转的原始图像对象,第二个参数是旋转矩阵,第三个参数是输出图像的尺寸大小,这里使用了原始图像的宽高。函数返回的是旋转后的图像对象rotated。
rows, cols = img.shape[:2]
M = cv2.getRotationMatrix2D((cols/2, rows/2), 30, 1)
rotated = cv2.warpAffine(img, M, (cols, rows))

倾斜图像
OpenCV需要定位图像的3个点来计算倾斜效果,3个点的位置如图所示,这3个点分别是“左上角”点A、“右上角”点B和“左下角”点C。OpenCV会根据这3个点的位置变化来计算其他像素的位置变化。因为要保证图像的“平直性”和“平行性”,所以不需要“右下角”的点做第4个参数,右下角这个点的位置根据A、B、C 3点的变化自动计算得出。
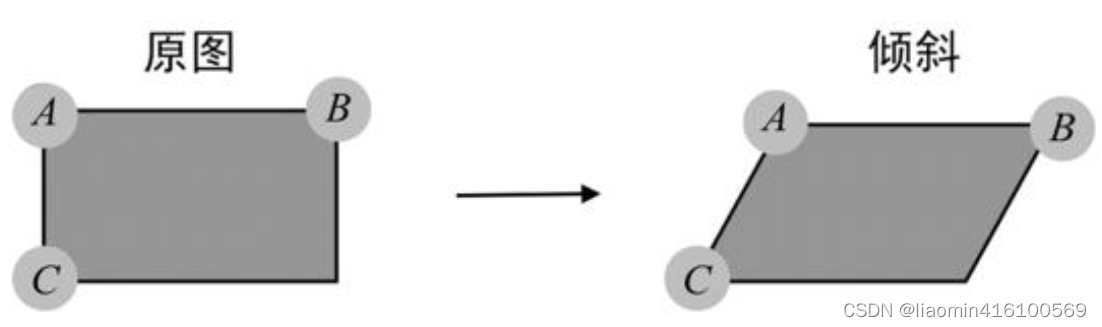
“平直性”是指图像中的直线在经过仿射变换之后仍然是直线。“平行性”是指图像中的平行线在经过仿射变换之后仍然是平行线。
让图像倾斜也是需要通过M矩阵实现的,但得出这个矩阵需要做很复杂的运算,于是OpenCV提供了getAffineTransform()方法来自动计算倾斜图像的M矩阵。getRotationMatrix2D()方法的语法如下:
M = cv2.getAffineTransform(src, dst)
参数说明:
- src:原图3个点坐标,格式为3行2列的32位浮点数列表,例如:[[0, 1], [1, 0], [1, 1]]。
- dst:倾斜图像的3个点坐标,格式与src一样。
返回值说明:
- M:getAffineTransform()方法计算出的仿射矩阵。

rows,cols=len(image),len(image[0])
src=np.float32([[0,0],[cols-1,0],[0,rows-1]])
dst=np.float32([[0,50],[cols-1,0],[0,rows-1]])
M=cv2.getAffineTransform(src,dst)
destImg =cv2.warpAffine(image,M=M,dsize=(len(image[0]),len(image)))
plt.title("图像倾斜")
plt.imshow(cv2.cvtColor(destImg, cv2.COLOR_BGR2RGB))
plt.show()
透视图像
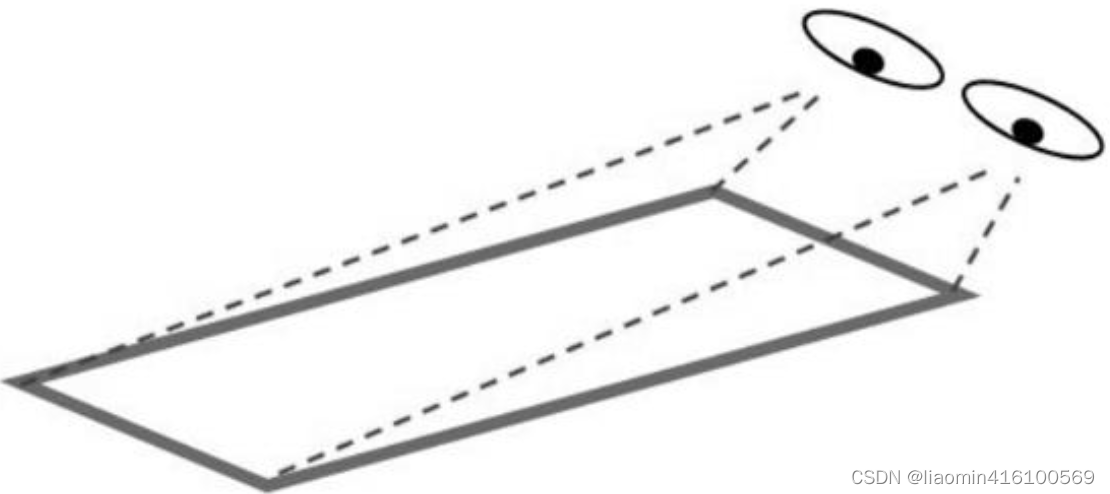
如果说仿射是让图像在二维平面中变形,那么透视就是让图像在三维空间中变形。从不同的角度观察物体,会看到不同的变形画面,例如,矩形会变成不规则的四边形,直角会变成锐角或钝角,圆形会变成椭圆,等等。这种变形之后的画面就是透视图。
从图像的底部观察图),眼睛距离图像底部较近,所以图像底部宽度不变,但眼睛距离图像顶部较远,图像顶部宽度就会等比缩小,于是观察者就会看到所示的透视效果。
OpenCV中需要通过定位图像的4个点计算透视效果,4个点的位置如图7.16所示。OpenCV根据这4个点的位置变化来计算其他像素的位置变化。透视效果不能保证图像的“平直性”和“平行性”。
warpPerspective()方法也需要通过M矩阵计算透视效果,但得出这个矩阵需要做很复杂的运算,于是OpenCV提供了getPerspectiveTransform()方法自动计算M矩阵。getPerspectiveTransform()方法的语法如下:
M = cv2.getPerspectiveTransform(src, dst,)
参数说明:
- src:原图4个点坐标,格式为4行2列的32位浮点数列表,例如:[[0, 0], [1, 0], [0, 1],[1, 1]]。
- dst:透视图的4个点坐标,格式与src一样。
返回值说明:
- M:getPerspectiveTransform()方法计算出的仿射矩阵。
rows=len(image)
cols=len(image[0])
M=cv2.getPerspectiveTransform(np.array([[0,0],[cols-1,0],[0,rows-1],[cols-1,rows-1]],dtype=np.float32),
np.array([[100,0],[cols-1-100,0],[0,rows-1],[cols-1,rows-1]],dtype=np.float32)
)
dImag=cv2.warpPerspective(image,M,(cols,rows))
plt.imshow(dImag)
plt.title("透视")
plt.show()

阈值处理
阈值是图像处理中一个很重要的概念,类似一个“像素值的标准线”。所有像素值都与这条“标准线”进行比较,最后得到3种结果:像素值比阈值大、像素值比阈值小或像素值等于阈值。程序根据这些结果将所有像素进行分组,然后对某一组像素进行“加深”或“变淡”操作,使得整个图像的轮廓更加鲜明,更容易被计算机或肉眼识别。
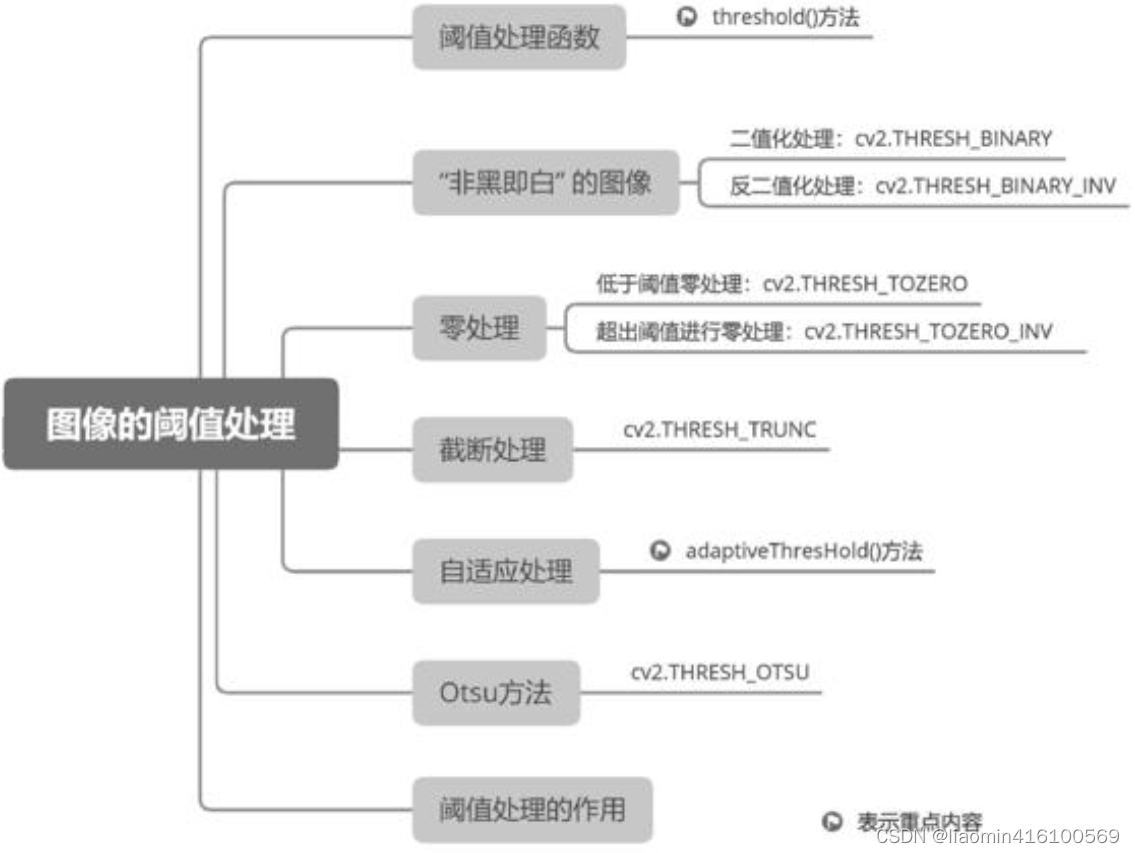
阈值处理函数
图像处理的过程中,阈值的使用使得图像的像素值更单一,进而使得图像的效果更简单。首先,把一幅彩色图像转换为灰度图像,这样图像的像素值的取值范围即可简化为0~255。然后,通过阈值使得转换后的灰度图像呈现出只有纯黑色和纯白色的视觉效果。例如,当阈值为127时,把小于127的所有像素值都转换为0(即纯黑色),把大于127的所有像素值都转换为255(即纯白色)。虽然会丢失一些灰度细节,但是会更明显地保留灰度图像主体的轮廓。
阈值处理在计算机视觉技术中占有十分重要的位置,它是很多高级算法的底层处理逻辑之一。因为二值图像会忽略细节,放大特征,而很多高级算法要根据物体的轮廓来分析物体特征,所以二值图像非常适合做复杂的识别运算。在进行识别运算之前,应先将图像转为灰度图像,再进行二值化处理,这样就得到了算法所需要的物体(大致)轮廓图像。
OpenCV提供的threshold()方法用于对图像进行阈值处理,threshold()方法的语法如下:
retval, dst = cv2.threshold(src, thresh, maxval, type)
参数说明:
- src:被处理的图像,可以是多通道图像。
- thresh:阈值,阈值在125~150取值的效果最好。
- maxval:阈值处理采用的最大值。
- type:阈值处理类型。常用类型和含义。
返回值说明:
- retval:处理时采用的阈值。
- dst:经过阈值处理后的图像。
在OpenCV中,阈值处理类型有以下几种,以及对应的枚举值:
- THRESH_BINARY:二值化阈值处理,将大于阈值的像素设置为最大值,小于等于阈值的像素设置为0。枚举值为0。
- THRESH_BINARY_INV:反二值化阈值处理,将小于阈值的像素设置为最大值,大于等于阈值的像素设置为0。枚举值为1。
- THRESH_TRUNC:截断阈值处理,将大于阈值的像素设置为该阈值,小于等于阈值的像素不变。枚举值为2。
- THRESH_TOZERO:阈值处理为0,将小于阈值的像素设置为0,大于等于阈值的像素不变。枚举值为3。
- THRESH_TOZERO_INV:反阈值处理为0,将大于阈值的像素设置为0,小于等于阈值的像素不变。枚举值为4。
二值化处理
二值化处理也叫二值化阈值处理,该处理让图像仅保留两种像素值,或者说所有像素都只能从两种值中取值。
进行二值化处理时,每一个像素值都会与阈值进行比较,将大于阈值的像素值变为最大值,将小于或等于阈值的像素值变为0,计算公式如下:
if 像素值 <= 阈值: 像素值 = 0
if 像素值 > 阈值: 像素值 = 最大值
通常二值化处理是使用255作为最大值,因为灰度图像中255表示纯白色,0表示黑色,能够很清晰地与纯黑色进行区分,所以灰度图像经过二值化处理后呈现“非黑即白”的效果。
import matplotlib
import matplotlib.pyplot as plt
import cv2
grayimage=cv2.imread("../../images/demo1.png",0) #直接读取灰度图
_,dst=cv2.threshold(grayimage,127,255,cv2.THRESH_BINARY)
plt.subplot(121)
plt.imshow(grayimage,cmap="gray")
plt.title("灰度图")
plt.subplot(122)
plt.imshow(dst,cmap="gray")
plt.title("二值化图")
plt.show()

注意像素值越大表示越白,越小越黑
反二值化处理
反二值化处理也叫反二值化阈值处理,其结果为二值化处理的相反结果。将大于阈值的像素值变为0,将小于或等于阈值的像素值变为最大值。原图像中白色的部分变成黑色,黑色的部分变成白色。计算公式如下:
if 像素值 <= 阈值: 像素值 = 最大值
if 像素值 > 阈值: 像素值 = 0
代码
_,dst=cv2.threshold(grayimage,127,255,cv2.THRESH_BINARY_INV)
plt.subplot(121)
plt.imshow(grayimage,cmap="gray")
plt.title("灰度图")
plt.subplot(122)
plt.imshow(dst,cmap="gray")
plt.title("二值化图")
plt.show()

如果ocr一般都是通过反二值化突出文字,显示出黑底白字,然后膨胀(因为白色是比较大的数字)。

零处理
低于阈值零处理
低于阈值零处理也叫低阈值零处理,该处理将低于或等于阈值的像素值变为0,大于阈值的像素值保持原值,计算公式如下:
if 像素值 <= 阈值: 像素值 = 0
if 像素值 > 阈值: 像素值 = 原值
_,dst=cv2.threshold(grayimage,127,255,cv2.THRESH_TOZERO)
plt.subplot(121)
plt.imshow(grayimage,cmap="gray")
plt.title("灰度图")
plt.subplot(122)
plt.imshow(dst,cmap="gray")
plt.title("低于阈值零[置黑]处理")
plt.show()

超出阈值零处理
超出阈值零处理也叫超阈值零处理,该处理将大于阈值的像素值变为0,小于或等于阈值的像素值保持原值。计算公式如下:
if 像素值 <= 阈值: 像素值 = 原值
if 像素值 > 阈值: 像素值 = 0
_,dst=cv2.threshold(grayimage,127,255,cv2.THRESH_TOZERO_INV)
plt.subplot(121)
plt.imshow(grayimage,cmap="gray")
plt.title("灰度图")
plt.subplot(122)
plt.imshow(dst,cmap="gray")
plt.title("超阈值零[置黑]处理")
plt.show()

截断处理
截断处理也叫截断阈值处理,该处理将图像中大于阈值的像素值变为和阈值一样的值,小于或等于阈值的像素保持原值,其公式如下:
if 像素 <= 阈值: 像素 = 原值
if 像素 > 阈值: 像素 = 阈值
_,dst=cv2.threshold(grayimage,127,255,cv2.THRESH_TRUNC)
plt.subplot(121)
plt.imshow(grayimage,cmap="gray")
plt.title("灰度图")
plt.subplot(122)
plt.imshow(dst,cmap="gray")
plt.title("截断阈值处理")
plt.show()

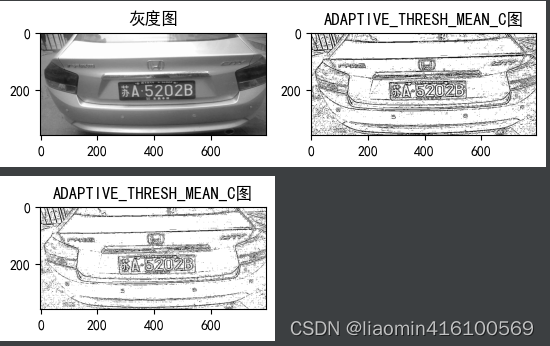
自适应处理
OpenCV提供了一种改进的阈值处理技术:图像中的不同区域使用不同的阈值。把这种改进的阈值处理技术称作自适应阈值处理也称自适应处理,自适应阈值是根据图像中某一正方形区域内的所有像素值按照指定的算法计算得到的。与前面讲解的5种阈值处理类型相比,自适应处理能更好地处理明暗分布不均的图像,获得更简单的图像效果。
OpenCV提供了adaptiveThresHold()方法对图像进行自适应处理,adaptiveThresHold()方法的语法如下:
dst = cv2.adaptiveThreshold(src, maxValue, adaptiveMethod, thresholdType, blockSize, C)
参数说明:
- src:被处理的图像。需要注意的是,该图像需是灰度图像。
- maxValue:阈值处理采用的最大值。
- adaptiveMethod:自适应阈值的计算方法。自适应阈值的计算方法及其含义如表8.2所示。
自适应阈值的计算方法及其含义
ADAPTIVE_THRESH_MEAN_C:对一个正方形的区域所有像素平均加权。
ADAPTIVE_THRESH_GAUSSIAN_C:根据高斯函数按照像素与中心点的距离对一个正方形区域内的所有像素加权计算。 - thresholdType:阈值处理类型;需要注意的是,阈值处理类型需是cv2.THRESH_BINARY或cv2.THRESH_BINARY_INV中的一个。
- blockSize:一个正方形区域的大小。例如,5指的是5×5的区域。
- C:常量。阈值等于均值或者加权值减去这个常量。
返回值说明: - dst:经过阈值处理后的图像。
自适应处理保留了图像中更多的细节信息,更明显地保留了灰度图像主体的轮廓。
plt.subplot(221)
plt.imshow(grayimage,cmap="gray")
plt.title("灰度图")
plt.subplot(222)
meanImg=cv2.adaptiveThreshold(grayimage,255,cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY,5,3)
plt.imshow(meanImg,cmap="gray")
plt.title("ADAPTIVE_THRESH_MEAN_C图")
plt.show()
plt.subplot(223)
guassImg=cv2.adaptiveThreshold(grayimage,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY,5,3)
plt.imshow(guassImg,cmap="gray")
plt.title("ADAPTIVE_THRESH_MEAN_C图")
plt.show()
Otsu方法
前面5种阈值处理类型的过程中,每个实例设置的阈值都是127,并不是通过算法计算得到的。对于有些图像,当阈值被设置为127时,得到的效果并不好,这时就需要一个个去尝试,直到找到最合适的阈值。
逐个寻找最合适的阈值不仅工作量大,而且效率低。为此,OpenCV提供了Otsu方法。Otsu方法能够遍历所有可能的阈值,从中找到最合适的阈值。
Otsu方法的语法与threshold()方法的语法基本一致,只不过在为type传递参数时,要多传递一个参数,即cv2.THRESH_OTSU。cv2.THRESH_OTSU的作用就是实现Otsu方法的阈值处理。Otsu方法的语法如下:
retval, dst = cv2.threshold(src, thresh, maxval, type)
参数说明:
- src:被处理的图像。需要注意的是,该图像需是灰度图像。
- thresh:阈值,且要把阈值设置为0。
- maxval:阈值处理采用的最大值,即255。
- type:阈值处理类型。除在表8.1中选择一种阈值处理类型外,还要多传递一个参数,即cv2.THRESH_OTSU。例如,cv2.THRESH_BINARY+cv2.THRESH_OTSU。
返回值说明:
- retval:由Otsu方法计算得到并使用的最合适的阈值。
- dst:经过阈值处理后的图像。
plt.subplot(221)
plt.imshow(grayimage,cmap="gray")
plt.title("灰度图")
plt.subplot(222)
_,dst=cv2.threshold(grayimage,127,255,cv2.THRESH_BINARY)
plt.imshow(dst,cmap="gray")
plt.title("二值化图")
plt.show()
plt.subplot(223)
_,ostuImg=cv2.threshold(grayimage,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
plt.imshow(ostuImg,cmap="gray")
plt.title("OTSU图")
plt.show()

进阶篇
模板匹配
模板是被查找目标的图像,查找模板在原始图像中的哪个位置的过程就叫模板匹配。OpenCV提供的matchTemplate()方法就是模板匹配方法,其语法如下:
result = cv2.matchTemplate(image, templ, method, mask)
参数说明:
- image:原始图像。
- templ:模板图像,尺寸必须小于或等于原始图像。
- method:匹配的方法,可用参数值如表10.1所示。
- mask:可选参数。掩模,只有cv2.TM_SQDIFF和cv2.TM_CCORR_NORMED支持此参数,建议采用默认值。
返回值说明: - result:计算得出的匹配结果。如果原始图像的宽、高分别为W、H,模板图像的宽、高分别为w、h,result就是一个W-w+1列、H-h+1行的32位浮点型数组。数组中每一个浮点数都是原始图像中对应像素位置的匹配结果,其含义需要根据method参数来解读。
在模板匹配的计算过程中,模板会在原始图像中移动。模板与重叠区域内的像素逐个对比,最后将对比的结果保存在模板左上角像素点索引位置对应的数组位置中
OpenCV的matchTemplate函数是用来在一幅图像中寻找另一幅图像的匹配的。在匹配过程中,可以选择不同的匹配方法,也就是method参数。常用的method参数有以下几种:
- cv2.TM_SQDIFF:平方差匹配法,最简单的匹配方法,计算平方差和,值越小越匹配。
- cv2.TM_SQDIFF_NORMED:标准平方差匹配法,同样计算平方差和,但是会对结果进行标准化处理。注意使用距离来计算被匹配图像一定要小于原图像
- cv2.TM_CCORR:相关性匹配法,#,值越大越匹配。
- cv2.TM_CCORR_NORMED:标准相关性匹配法,对结果进行标准化处理,返回值越大表示匹配程度越高,越小表示匹配程度越低。
该参数使用的是归一化相关系数匹配模式,
返回的是匹配图像和模板图像之间的相关系数,取值范围在 0 到 1 之间,1 表示完美匹配,0 表示没有匹配。
- cv2.TM_CCOEFF:相关系数匹配法,计算两个图像的相关系数,值越大越匹配。
- cv2.TM_CCOEFF_NORMED:标准相关系数匹配法,对结果进行标准化处理。
假设原图
被匹配图

#多目标匹配
image=cv2.imread("./images/2.jpg");
grayImg=cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
matchImg=cv2.imread("./images/2_match_1.jpg",0);
height,width=matchImg.shape
result=cv2.matchTemplate(grayImg,matchImg,cv2.TM_CCORR_NORMED)
showImage=image.copy()
for y in range(len(result)):
for x in range(len(result[y])):
if result[y][x]>0.999:
cv2.rectangle(showImage, (x,y), (x + width, y + height), (255, 0, 0), 1)
plt.imshow(showImage,cmap="gray")
匹配到结果
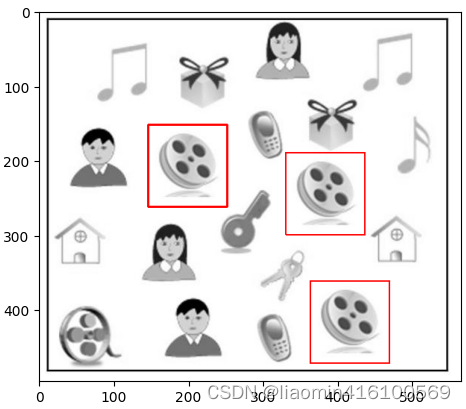
滤波器
在尽量保留原图像信息的情况下,去除图像内噪声、降低细节层次信息等一系列过程,叫作图像的平滑处理(或图像的模糊处理)。实现平滑处理最常用的工具就是滤波器。通过调节滤波器的参数,可以控制图像的平滑程度。OpenCV提供了种类丰富的滤波器,每种滤波器使用的算法均不同,但都能对图像中的像素值进行微调,让图像呈现平滑效果。本章将介绍均值滤波器、中值滤波器、高斯滤波器和双边滤波器的使用方法。
可能会出现这样一种像素,该像素与周围像素的差别非常大,导致从视觉上就能看出该像素无法与周围像素组成可识别的图像信息,降低了整个图像的质量。这种“格格不入”的像素就是图像的噪声。如果图像中的噪声都是随机的纯黑像素或者纯白像素,这样的噪声称作“椒盐噪声”或“盐噪声”。例如如图7.1所示的就是一幅只有噪声的图像,常称为“雪花点”。
均值滤波器
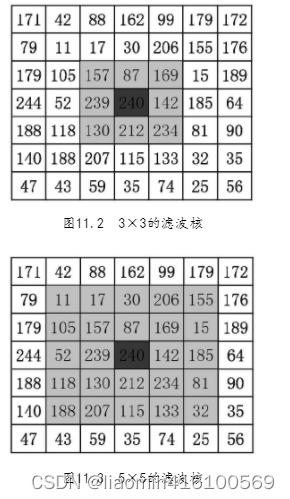
以一个像素为核心,其周围像素可以组成一个n行n列(简称n×n)的矩阵,这样的矩阵结构在滤波操作中被称为“滤波核”。矩阵的行、列数决定了滤波核的大小,滤波核大小为3×3,包含9个像素;图滤波核大小为5×5,包含25个像素。
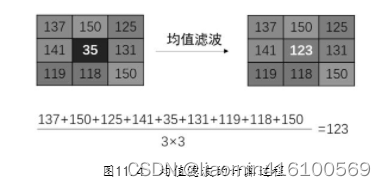
均值滤波器(也称为低通滤波器)可以把图像中的每一个像素都当成滤波核的核心,然后计算核内所有像素的平均值,最后让核心像素值等于这个平均值。
OpenCV将均值滤波器封装成blur()方法,其语法如下:
dst = cv2.blur(src, ksize, anchor, borderType)
参数说明:
- src:被处理的图像。
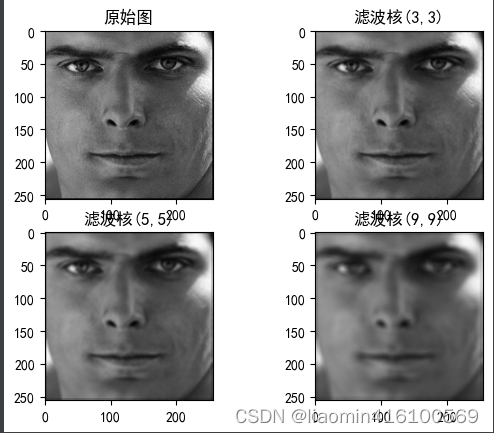
- ksize:滤波核大小,其格式为(高度,宽度),建议使用如(3, 3)、(5, 5)、(7, 7)等宽、高相等的奇数边长。滤波核越大,处理之后的图像就越模糊。
- anchor:可选参数,滤波核的锚点,建议采用默认值,可以自动计算锚点。
- borderType:可选参数,边界样式,建议采用默认值。
返回值说明: - dst:经过均值滤波处理之后的图像。
import matplotlib.pyplot as plt
import matplotlib
import cv2
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
image=cv2.imread("./images/1.png");
plt.subplot(221)
plt.title("原始图")
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.subplot(222)
plt.title("滤波核(3,3)")
plt.imshow(cv2.cvtColor(cv2.blur(image,(3,3)), cv2.COLOR_BGR2RGB))
plt.subplot(223)
plt.title("滤波核(5,5)")
plt.imshow(cv2.cvtColor(cv2.blur(image,(5,5)), cv2.COLOR_BGR2RGB))
plt.subplot(224)
plt.title("滤波核(9,9)")
plt.imshow(cv2.cvtColor(cv2.blur(image,(9,9)), cv2.COLOR_BGR2RGB))
中值滤波器
中值滤波器的原理与均值滤波器非常相似,唯一的不同就是不计算像素的平均值,而是将所有像素值排序,把最中间的像素值取出,赋值给核心像素。
OpenCV将中值滤波器封装成medianBlur()方法,其语法如下:
dst = cv2.medianBlur(src, ksize)
参数说明:
- src:被处理的图像。
- ksize:滤波核的边长,必须是大于1的奇数,如3、5、7等。该方法根据此边长自动创建一个正方形的滤波核。
返回值说明: - st:经过中值滤波处理之后的图像。
import matplotlib.pyplot as plt
import matplotlib
import cv2
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
image=cv2.imread("./images/1.png");
plt.subplot(221)
plt.title("原始图")
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.subplot(222)
plt.title("滤波核(3,3)")
plt.imshow(cv2.cvtColor(cv2.medianBlur(image,3), cv2.COLOR_BGR2RGB))
plt.subplot(223)
plt.title("滤波核(5,5)")
plt.imshow(cv2.cvtColor(cv2.medianBlur(image,5), cv2.COLOR_BGR2RGB))
plt.subplot(224)
plt.title("滤波核(9,9)")
plt.imshow(cv2.cvtColor(cv2.medianBlur(image,9), cv2.COLOR_BGR2RGB))
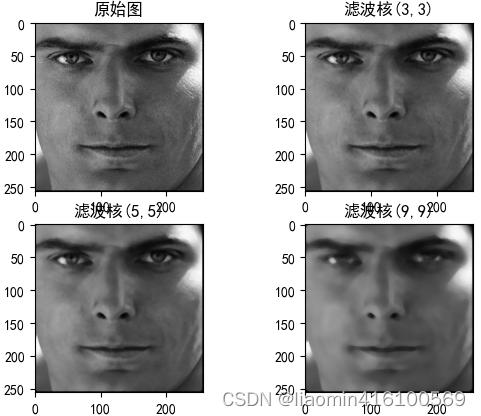
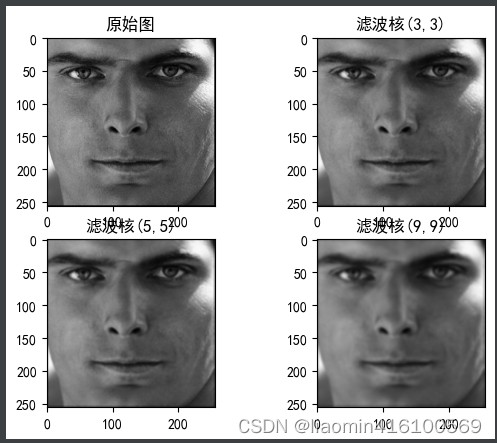
高斯滤波器
高斯滤波也被称为高斯模糊或高斯平滑,是目前应用最广泛的平滑处理算法。高斯滤波可以很好地在降低图片噪声、细节层次的同时保留更多的图像信息,经过处理的图像呈现“磨砂玻璃”的滤镜效果。
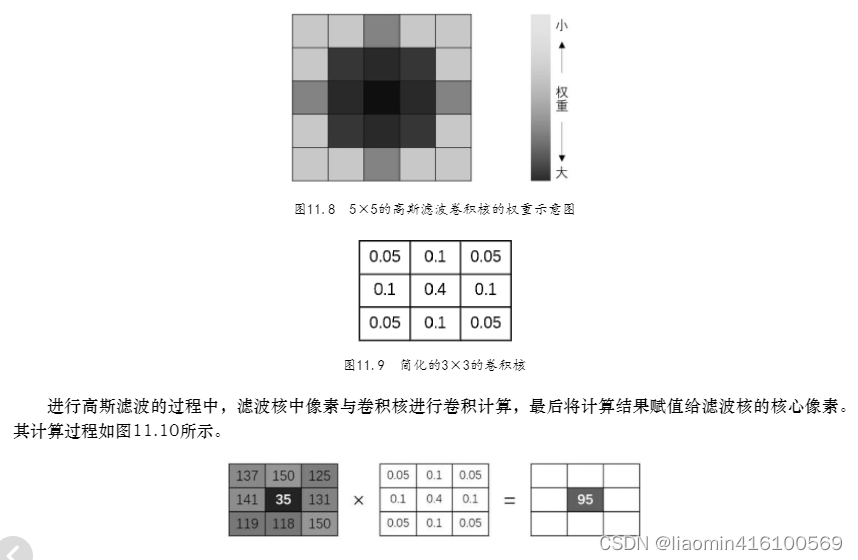
进行均值滤波处理时,核心周围每个像素的权重都是均等的,也就是每个像素都同样重要,所以计算平均值即可。但在高斯滤波中,越靠近核心的像素权重越大,越远离核心的像素权重越小,例如5×5大小的高斯滤波卷积核的权重示意图如图11.8所示。像素权重不同不能取平均值,要从权重大的像素中取较多的信息,从权重小的像素中取较少的信息。简单概括就是“离谁更近,跟谁更像”。
高斯滤波的计算过程涉及卷积运算,会有一个与滤波核大小相等的卷积核。本节仅以3×3的滤波核为例,简单地描述一下高斯滤波的计算过程。
卷积核中保存的值就是核所覆盖区域的权重值,其遵循图11.8的规律。卷积核中所有权重值相加的结果为1。例如,3×3的卷积核可以是如图11.9所示的值。随着核大小、σ标准差的变化,卷积核中的值也会发生较大变化,图11.9仅是一种最简单的情况。
import matplotlib.pyplot as plt
import matplotlib
import cv2
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
image=cv2.imread("./images/1.png");
plt.subplot(221)
plt.title("原始图")
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.subplot(222)
plt.title("滤波核(3,3)")
plt.imshow(cv2.cvtColor(cv2.GaussianBlur(image,(3,3),0,0), cv2.COLOR_BGR2RGB))
plt.subplot(223)
plt.title("滤波核(5,5)")
plt.imshow(cv2.cvtColor(cv2.GaussianBlur(image,(5,5),0,0), cv2.COLOR_BGR2RGB))
plt.subplot(224)
plt.title("滤波核(9,9)")
plt.imshow(cv2.cvtColor(cv2.GaussianBlur(image,(9,9),0,0), cv2.COLOR_BGR2RGB))
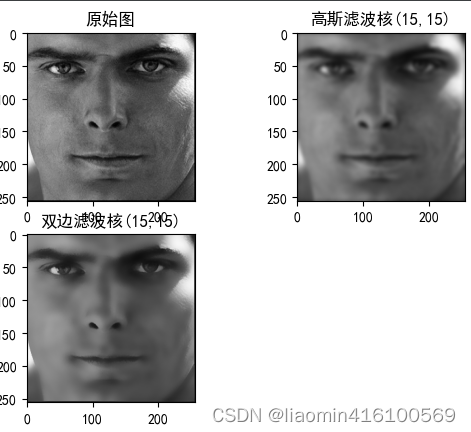
双边滤波器
不管是均值滤波、中值滤波还是高斯滤波,都会使整幅图像变得平滑,图像中的边界会变得模糊不清。双边滤波是一种在平滑处理过程中可以有效保护边界信息的滤波操作方法。
双边滤波器自动判断滤波核处于“平坦”区域还是“边缘”区域:如果滤波核处于“平坦”区域,则会使用类似高斯滤波的算法进行滤波;如果滤波核处于“边缘”区域,则加大“边缘”像素的权重,尽可能地让这些像素值保持不变。

import matplotlib.pyplot as plt
import matplotlib
import cv2
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
image=cv2.imread("./images/1.png");
plt.subplot(221)
plt.title("原始图")
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.subplot(222)
plt.title("高斯滤波核(15,15)")
plt.imshow(cv2.cvtColor(cv2.GaussianBlur(image,(15,15),0,0), cv2.COLOR_BGR2RGB))
plt.subplot(223)
plt.title("双边滤波核(15,15)")
plt.imshow(cv2.cvtColor(cv2.bilateralFilter(image,15,120,100), cv2.COLOR_BGR2RGB))
形态学运算
腐蚀和膨胀是形态学的基础操作,除了开运算和闭运算以外,形态学中还有几种比较有特点的运算。OpenCV提供了一个morphologyEx()形态学方法,包含所有常用的运算,其语法如下:
dst = cv2.morphologyEx(src, op, kernel, anchor, iterations, borderType, borderValue)
参数说明:
- src:原始图像。
- op:操作类型,具体值如表12.1所示。
具体枚举值如下:
- MORPH_ERODE:腐蚀操作
- MORPH_DILATE:膨胀操作
- MORPH_OPEN:开运算
- MORPH_CLOSE:闭运算
- MORPH_GRADIENT:形态学梯度
- MORPH_TOPHAT:顶帽操作
- MORPH_BLACKHAT:黑帽操作
- kernel:操作过程中使用的核。
- anchor:可选参数,核的锚点位置。
- iterations:可选参数,迭代次数,默认值为1。
- borderType:可选参数,边界样式,建议默认。
- borderValue:可选参数,边界值,建议默认。
返回值说明: - dst:操作之后得到的图像。
腐蚀
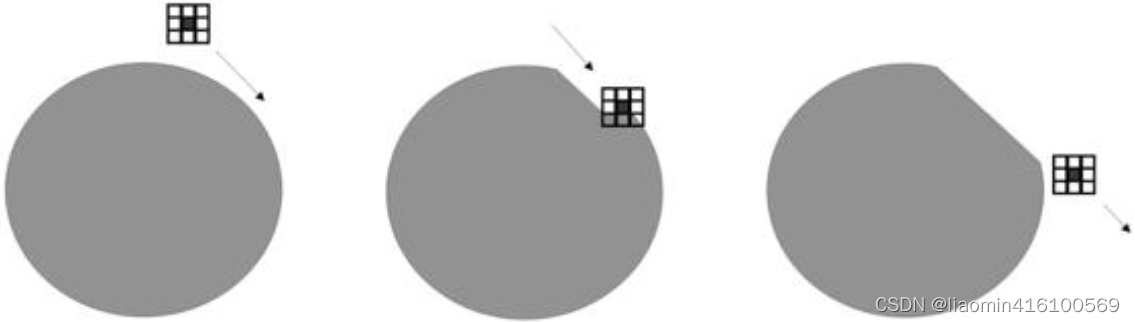
腐蚀操作可以让图像沿着自己的边界向内收缩。OpenCV通过“核”来实现收缩计算。“核”的英文名为kernel,在形态学中可以理解为“由n个像素组成的像素块”,像素块包含一个核心(核心通常在中央位置,也可以定义在其他位置)。像素块在图像的边缘移动,在移动过程中,核会将图像边缘那些与核重合但又没有越过核心的像素点都抹除,效果类似图12.1所示的过程,就像削土豆皮一样,将图像一层一层地“削薄”。
OpenCV将腐蚀操作封装成erode()方法,该方法的语法如下:
dst = cv2.erode(src, kernel, anchor, iterations, borderType, borderValue)
参数说明:
- src:原始图像。
- kernel:腐蚀使用的核。
- anchor:可选参数,核的锚点位置。
- iterations:可选参数,腐蚀操作的迭代次数,默认值为1。
- borderType:可选参数,边界样式,建议默认。
- borderValue:可选参数,边界值,建议默认。
返回值说明: - dst:经过腐蚀之后的图像。
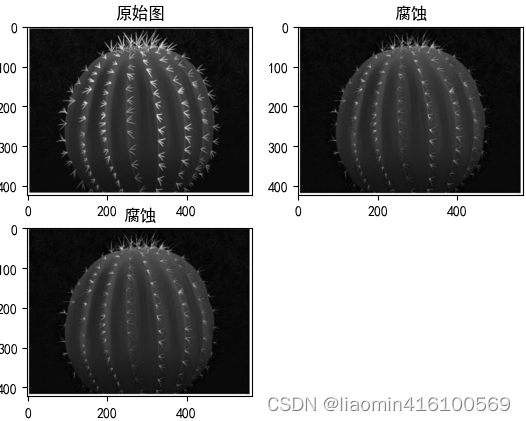
图像经过腐蚀操作之后,可以抹除一些外部的细节,如图12.2所示是一个卡通小蜘蛛,如果用一个5×5的像素块作为核对小蜘蛛进行腐蚀操作,可以得到如图12.3所示的结果。小蜘蛛的腿被当成外部细节抹除了,同时小蜘蛛的眼睛变大了,因为核从内部也“削”了一圈。
腐蚀之后


import matplotlib.pyplot as plt
import matplotlib
import cv2
import numpy as np
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
image=cv2.imread("./images/1.jpg");
plt.subplot(221)
plt.title("原始图")
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.subplot(222)
plt.title("腐蚀")
zeroArray=np.ones((3,3))
plt.imshow(cv2.erode(image, zeroArray))
plt.subplot(223)
plt.title("腐蚀")
dst = cv2.morphologyEx(image, cv2.MORPH_ERODE, zeroArray) #也可以使用这个形态学方法,效果和erode一致
plt.imshow(dst)
膨胀
膨胀操作与腐蚀操作相反,膨胀操作可以让图像沿着自己的边界向内扩张。同样是通过核来计算,当核在图像的边缘移动时,核会将图像边缘填补新的像素,效果类似图12.6所示的过程,就像在一面墙上反反复复地涂水泥,让墙变得越来越厚。
OpenCV将膨胀操作封装成dilate()方法,该方法的语法如下:
dst = cv2.dilate(src, kernel, anchor, iterations, borderType, borderValue)
参数说明:

- src:原始图像。
- kernel:膨胀使用的核。
- anchor:可选参数,核的锚点位置。
- iterations:可选参数,腐蚀操作的迭代次数,默认值为1。
- borderType:可选参数,边界样式,建议默认。
- borderValue:可选参数,边界值,建议默认。
返回值说明: - dst:经过膨胀之后的图像。
图像经过膨胀操作之后,可以放大一些外部的细节,如图12.7(a)所示的卡通小蜘蛛,如果用一个5×5的像素块作为核对小蜘蛛进行膨胀操作,可以得到如图12.7(b)所示的结果,小蜘蛛不仅腿变粗了,而且连眼睛都胖没了。

matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
image=cv2.imread("./images/2.jpg");
plt.subplot(221)
plt.title("原始图")
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.subplot(222)
plt.title("膨胀")
zeroArray=np.ones((9,9))
plt.imshow(cv2.dilate(image, zeroArray))
plt.subplot(223)
plt.title("膨胀")
dst = cv2.morphologyEx(image, cv2.MORPH_DILATE, zeroArray) #也可以使用这个形态学方法,效果和erode一致
plt.imshow(dst)

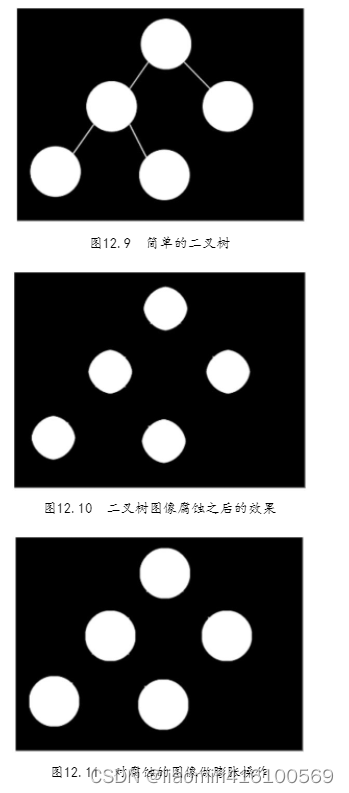
开运算
开运算是将图像先进行腐蚀操作,再进行膨胀操作。开运算可以用来抹除图像外部的细节(或者噪声)。
import matplotlib.pyplot as plt
import matplotlib
import cv2
import numpy as np
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
image=cv2.imread("./images/2.jpg");
plt.subplot(221)
plt.title("原始图")
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.subplot(222)
plt.title("开运算")
zeroArray=np.ones((5,5))
#腐蚀掉噪音,然后在膨胀特点
dest=cv2.erode(image, zeroArray)
dest=cv2.dilate(dest, zeroArray)
plt.imshow(dest)
plt.subplot(223)
plt.title("开运算")
dst = cv2.morphologyEx(image, cv2.MORPH_OPEN, zeroArray) #也可以使用这个形态学方法,效果和erode一致
plt.imshow(dst)
效果图

闭运算
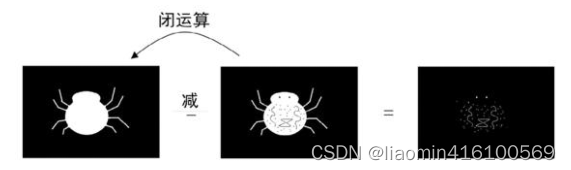
闭运算是将图像先进行膨胀操作,再进行腐蚀操作。闭运算可以抹除图像内部的细节(或者噪声)。

梯度运算
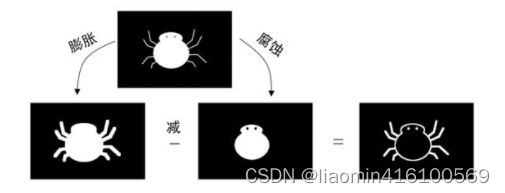
这里的梯度是指图像梯度,可以简单地理解为像素的变化程度。如果几个连续的像素,其像素值跨度越大,则梯度值越大。
梯度运算的运算过程如图12.15所示,让原图的膨胀图减原图的腐蚀图。因为膨胀图比原图大,腐蚀图比原图小,利用腐蚀图将膨胀图掏空,就得到了原图的轮廓图。
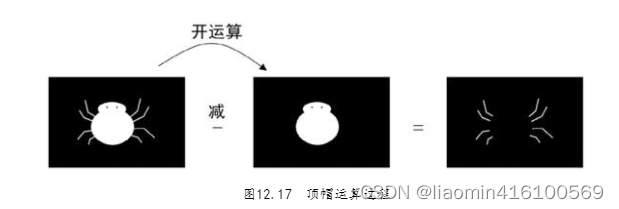
顶帽运算
顶帽运算的运算过程如图12.17所示,让原图减原图的开运算图。因为开运算抹除图像的外部细节,“有外部细节”的图像减去“无外部细节”的图像,得到的结果就只剩外部细节了,所以经过顶帽运算之后,小蜘蛛就只剩蜘蛛腿了。
黑帽运算
黑帽运算的运算过程如图12.19所示,让原图的闭运算图减去原图。因为闭运算抹除图像的内部细节,“无内部细节”的图像减去“有内部细节”的图像,得到的结果就只剩内部细节了,所以经过黑帽运算之后,小蜘蛛就只剩下斑点、花纹和眼睛了。
图形检测
图像轮廓
轮廓是指图像中图形或物体的外边缘线条。简单的几何图形轮廓是由平滑的线构成的,容易识别,但不规则图形的轮廓可能由许多个点构成,识别起来比较困难。
OpenCV提供的findContours()方法可以通过计算图像梯度来判断图像的边缘,然后将边缘的点封装成数组返回。findContours()方法的语法如下:
contours, hierarchy = cv2.findContours(image, mode, methode)
参数说明:
- image:被检测的图像,必须是8位单通道二值图像。如果原始图像是彩色图像,必须转为灰度图像,并经过二值化处理。
- mode:轮廓的检索模式,具体值如表所示。
cv2.RETR_EXTERNAL: 只检索外部轮廓。
cv2.RETR_LIST: 检索所有轮廓,并将其存储在列表中。
cv2.RETR_CCOMP: 检索所有轮廓,并将它们组织为两级层次结构。在顶层中,只有外部轮廓,而在第二层中,有内部轮廓。如果内部轮廓还有孔,则将其视为第三级。
cv2.RETR_TREE: 检索所有轮廓,并将它们组织为完整的层次结构树。 - methode:检测轮廓时使用的方法,具体值如表13.2所示。
cv2.CHAIN_APPROX_NONE: 存储所有的轮廓点,相邻的两个轮廓点的像素位置差不超过 1。
cv2.CHAIN_APPROX_SIMPLE: 压缩水平、竖直和对角线方向上的冗余点,仅保留相邻的端点,如一个矩形轮廓只需存储其四个顶点。
cv2.CHAIN_APPROX_TC89_L1 或 cv2.CHAIN_APPROX_TC89_KCOS: 应用 Teh-Chin 链逼近算法中的一种,可以进一步减少轮廓的点数,但需要更长的计算时间。
返回值说明:
- ontours:检测出的所有轮廓,list类型,每一个元素都是某个轮廓的像素坐标数组。
- hierarchy:轮廓之间的层次关系。
通过findContours()方法找到图像轮廓后,为了方便开发人员观测,最好能把轮廓画出来,于是OpenCV提供了drawContours()方法用来绘制这些轮廓。drawContours()方法的语法如下:
image = cv2.drawContours(image, contours, contourIdx, color, thickness, lineTypee, hierarchy, maxLevel, offse)
参数说明:
- mage:被绘制轮廓的原始图像,可以是多通道图像。
- contours:findContours()方法得出的轮廓列表。
- contourIdx:绘制轮廓的索引,如果为-1则绘制所有轮廓。
- color:绘制颜色,使用BGR格式。
- thickness:可选参数,画笔的粗细程度,如果该值为-1则绘制实心轮廓。
- lineTypee:可选参数,绘制轮廓的线型。
- hierarchy:可选参数,findContours()方法得出的层次关系。
- maxLevel:可选参数,绘制轮廓的层次深度,最深绘制第maxLevel层。
- offse:可选参数,偏移量,可以改变绘制结果的位置。
返回值说明:
- image:同参数中的image,执行后原始图中就包含绘制的轮廓了,可以不使用此返回值保存结果。
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
img=cv2.imread("./images/2.jpg")
grayImg=cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
plt.title("灰度图")
plt.subplot(221)
plt.imshow(grayImg,cmap="gray")
#二值化
_,dst=cv2.threshold(grayImg,127,255,cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(dst, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)
plt.subplot(222)
plt.imshow(cv2.drawContours(img.copy(), contours, 2, (0, 0, 255), 5))
"""
矩形包围框是指图像轮廓的最小矩形边界。OpenCV提供的boundingRect()方法可以自动计算轮廓最小矩形边界的坐标、宽和高。boundingRect()方法的语法如下:
retval = cv2.boundingRect (array)
参数说明:
array:轮廓数组。
返回值说明:
retval:元组类型,包含4个整数值,分别是最小矩形包围框的:左上角顶点的横坐标、左上角顶点的纵坐标、矩形的宽和高。所以也可以写成x, y, w, h = cv2.boundingRect (array)的形式。
"""
x,y,w,h = cv2.boundingRect (contours[2])
print(x,y,w,h)
dstImg=img.copy()
plt.subplot(223)
cv2.rectangle(dstImg,(x,y),(x+w,y+h),(0,0,255),2)
plt.imshow(cv2.cvtColor(dstImg, cv2.COLOR_BGR2RGB))
plt.show()
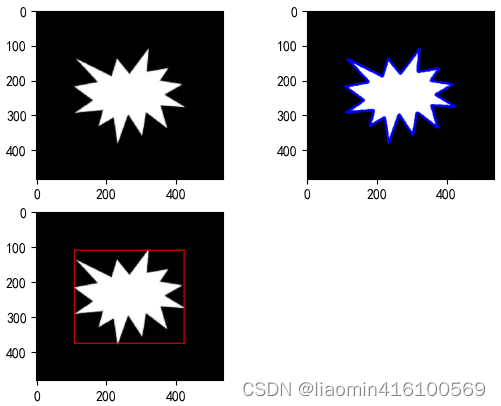
轮廓拟合
拟合是指将平面上的一系列点,用一条光滑的曲线连接起来。轮廓的拟合就是将凹凸不平的轮廓用平整的几何图形体现出来。本节将介绍如何按照轮廓绘制矩形包围框和圆形包围框。
矩形包围框
矩形包围框是指图像轮廓的最小矩形边界。OpenCV提供的boundingRect()方法可以自动计算轮廓最小矩形边界的坐标、宽和高。boundingRect()方法的语法如下:
retval = cv2.boundingRect (array)
参数说明:
- rray:轮廓数组。
返回值说明:
- retval:元组类型,包含4个整数值,分别是最小矩形包围框的:左上角顶点的横坐标、左上角顶点的纵坐标、矩形的宽和高。所以也可以写成x, y, w, h = cv2.boundingRect (array)的形式。
同上面图像轮廓的例子
圆形包围框
圆形包围框与矩形包围框一样,是图像轮廓的最小圆形边界。OpenCV提供的minEnclosingCircle ()方法可以自动计算轮廓最小圆形边界的圆心和半径。minEnclosingCircle()方法的语法如下:
center, radius = cv2.minEnclosingCircle(points)
参数说明:
- points:轮廓数组。
返回值说明:
- enter:元组类型,包含2个浮点值,是最小圆形包围框圆心的横坐标和纵坐标。
- radius:浮点类型,最小圆形包围框的半径。
效果

多边形包围框
cv2.approxPolyDP 函数是 OpenCV 中针对轮廓近似的函数,其可以将轮廓中的点根据一定的精度要求进行近似,从而化简轮廓的点数,方便后续处理。
该函数的语法如下:
epsilon = cv2.arcLength(curve, closed)
approx = cv2.approxPolyDP(curve, epsilon, closed)
其中,curve 表示输入的轮廓,epsilon 表示近似精度,closed 表示轮廓是否闭合。函数返回一个近似的轮廓。
cv2.approxPolyDP 函数的工作原理是通过 Douglas-Peucker 算法来实现的。该算法的基本思想是:在轮廓中找到一条最长的线段,将其作为轮廓的近似线段,并将轮廓分成两个部分。然后对这两个部分递归进行处理,直到满足精度要求为止。经过这样的处理,得到的轮廓点数将会大大减少,但轮廓的形状仍能得到保留。
需要注意的是,epsilon 的值越小,得到的近似轮廓点数就越多,但轮廓的形状精度也就越高;反之,epsilon 的值越大,得到的轮廓点数就越少,但轮廓的形状精度也就越低。因此,选择适当的 epsilon 值对于轮廓近似的效果是非常重要的。
img=cv2.imread("./images/2.jpg")
grayImg=cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_,dst=cv2.threshold(grayImg,127,255,cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(dst, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)
#近似轮廓
# 对每个轮廓进行近似
for i,e in enumerate([0.01,0.05,0.1,1]):
img1=img.copy()
for cnt in contours:
epsilon = e * cv2.arcLength(cnt, True) #获取轮廓的周长
approx = cv2.approxPolyDP(cnt, epsilon, True)
# 绘制近似的轮廓
cv2.drawContours(img1, [approx], 0, (0, 255, 0), 3)
plt.subplot(int("22"+str(i+1)))
plt.title(e)
plt.imshow(cv2.cvtColor(img1, cv2.COLOR_BGR2RGB))
plt.show()
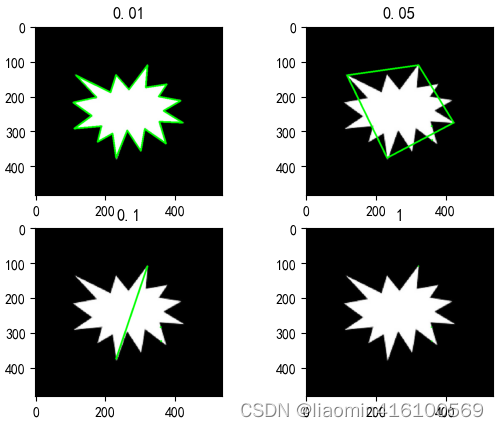
凸包
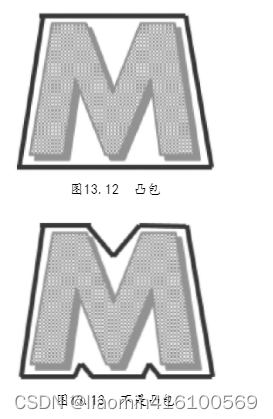
之前介绍了矩形包围框和圆形包围框,这2种包围框虽然已经逼近了图形的边缘,但这种包围框为了保持几何形状,与图形的真实轮廓贴合度较差。如果能找出图形最外层的端点,将这些端点连接起来,就可以围出一个包围图形的最小包围框,这种包围框叫凸包。
凸包是最逼近轮廓的多边形,凸包的每一处都是凸出来的,也就是任意3个点组成的内角均小于180°。例如,图13.12就是凸包,而图13.13就不是凸包。
OpenCV提供的convexHull()方法可以自动找出轮廓的凸包,该方法的语法如下:
hull = cv2.convexHull(points, clockwise, returnPoints)
参数说明:
- oints:轮廓数组。
- clockwise:可选参数,布尔类型。当该值为True时,凸包中的点按顺时针排列,为False时按逆时针排列。
- returnPoints:可选参数,布尔类型。当该值为True时返回点坐标,为False时返回点索引。默认值为True。
返回值说明:
- hull:凸包的点阵数组
img=cv2.imread("./images/2.jpg")
grayImg=cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_,dst=cv2.threshold(grayImg,127,255,cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(dst, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)
# 根据轮廓面积从大到小排序
sorted_contours = sorted(contours, key=cv2.contourArea, reverse=True)
hull=cv2.convexHull(sorted_contours[0])
cv2.polylines(img1,[hull],True,(0,0,255),2)
plt.imshow(cv2.cvtColor(img1, cv2.COLOR_BGR2RGB))
plt.show()

Canny边缘检测
Canny边缘检测算法是John F. Canny于1986年开发的一个多级边缘检测算法,该算法根据像素的梯度变化寻找图像边缘,最终可以绘制十分精细的二值边缘图像。
OpenCV将Canny边缘检测算法封装在Canny()方法中,该方法的语法如下:
edges = cv2.Canny(image, threshold1, threshold2, apertureSize, L2gradient)
参数说明:
- mage:检测的原始图像。
- threshold1:计算过程中使用的第一个阈值,可以是最小阈值,也可以是最大阈值,通常用来设置最小阈值。
- threshold2:计算过程中使用的第二个阈值,通常用来设置最大阈值。
- apertureSize:可选参数,Sobel算子的孔径大小。
- L2gradient:可选参数,计算图像梯度的标识,默认值为False。值为True时采用更精准的算法进行计算。
返回值说明:
- dges:计算后得出的边缘图像,是一个二值灰度图像。
import cv2
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
img=cv2.imread("./images/1.jpg")
plt.subplot(221)
plt.title("原始图")
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
#二值化
r1=cv2.Canny(img,10,50)
plt.subplot(222)
plt.title("Canny")
plt.imshow(cv2.cvtColor(r1, cv2.COLOR_BGR2RGB))

霍夫直线
霍夫变换是一种特征检测,通过算法识别图像的特征,从而判断图像中的特殊形状,例如直线和圆。
直线检测
霍夫直线变换是通过霍夫坐标系的直线与笛卡儿坐标系的点之间的映射关系来判断图像中的点是否构成直线。OpenCV将此算法封装成两个方法,分别是cv2.HoughLines()和cv2.HoughLinesP(),前者用于检测无限延长的直线,后者用于检测线段
HoughLinesP()方法名称最后有一个大写的P,该方法只能检测二值灰度图像,也就是只有两种像素值的黑白图像。该方法最后把找出的所有线段的两个端点坐标保存成一个数组。
HoughLinesP()方法的语法如下:
lines = cv2.HoughLinesP(image, rho, theta, threshold, minLineLength, maxLineGap)
参数说明:
- mage:检测的原始图像。
- rho:检测直线使用的半径步长,值为1时,表示检测所有可能的半径步长。
- theta:搜索直线的角度,值为π/180°时,表示检测所有角度。
- threshold:阈值,该值越小,检测出的直线就越多。
- minLineLength:线段的最小长度,小于该长度的线段不记录到结果中。
- maxLineGap:线段之间的最小距离。
返回值说明: - lines:一个数组,元素为所有检测出的线段,每条线段是一个数组,代表线段两个端点的横、纵坐标,格式为[[[x1, y1, x2, y2], [x1, y1, x2, y2]]]。
import cv2
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
from utils import common
def show(dilate, title, cmap=None, debug=False):
if debug:
plt.title(title)
plt.imshow(dilate, cmap=cmap)
plt.show()
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
img=cv2.imread("./images/1.jpg")
grayImg=cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
common.show(grayImg,"原图",cmap="gray",debug=True)
edges = cv2.Canny(grayImg, 20, 40)
common.show(edges,"边缘检测图",cmap="gray",debug=True)
lines = cv2.HoughLinesP(edges, 1, np.pi/180, 15, 100, 18)
img1=img.copy()
for line in lines:
x1,y1,x2,y2=line[0]
cv2.line(img1,(x1,y1),(x2,y2),(0,0,255),2)
common.show(img1,"直线",cmap="gray",debug=True)
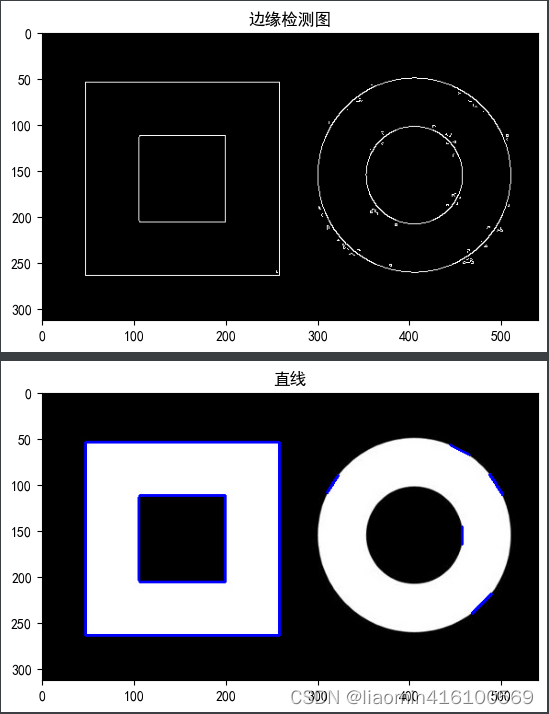
圆环检测
霍夫圆环变换的原理与霍夫直线变换类似。OpenCV提供的HoughCircles()方法用于检测图像中的圆环,该方法在检测过程中进行两轮筛选:第一轮筛选找出可能是圆的圆心坐标,第二轮筛选计算这些圆心坐标可能对应的半径长度。该方法最后将圆心坐标和半径封装成一个浮点型数组。
HoughCircles()方法的语法如下:
circles = cv2.HoughCircles(image, method, dp, minDist, param1, param2, minRadius, maxRadius)
参数说明:
- mage:检测的原始图像。
- method:检测方法,OpenCV 4.0.0及以前版本仅提供了cv2.HOUGH_GRADIENT作为唯一可用方法。
- dp:累加器分辨率与原始图像分辨率之比的倒数。值为1时,累加器与原始图像具有相同的分辨率;值为2时,累加器的分辨率为原始图像的1/2。通常使用1作为参数。
- minDist:圆心之间的最小距离。
- param1:可选参数,Canny边缘检测使用的最大阈值。
- param2:可选参数,检测圆环结果的投票数。第一轮筛选时投票数超过该值的圆环才会进入第二轮筛选。值越大,检测出的圆环越少,但越精准。
- minRadius:可选参数,圆环的最小半径。
- maxRadius:可选参数,圆环的最大半径。
返回值说明:
- circles:一个数组,元素为所有检测出的圆环,每个圆环也是一个数组,内容为圆心的横、纵坐标和半径长度,格式为:[[[x1 ,y1, r1], [x2 ,y2, r2]]]。
视频处理
OpenCV不仅能够处理图像,还能够处理视频。视频是由大量的图像构成的,这些图像以固定的时间间隔从视频中获取。这样,就能够使用图像处理的方法对这些图像进行处理,进而达到处理视频的目的。要处理视频,需要先对视频进行读取、显示和保存等相关操作。为此,OpenCV提供了VideoCapture类和VideoWriter类的相关方法。
VideoCapture类提供了构造方法VideoCapture(),用于完成摄像头的初始化工作。VideoCapture()的语法
apture = cv2.VideoCapture(index|视频文件路径)
参数说明:
- video:要打开的视频。
- filename:打开视频的文件名。例如,公司宣传.avi等。
import cv2
# 打开视频文件
cap = cv2.VideoCapture('video.avi')
while True:
# 读取视频帧
ret, frame = cap.read()
# 如果视频结束或者读取失败,退出循环
if not ret:
break
# 显示当前帧
cv2.imshow('frame', frame)
# 等待按键输入
key = cv2.waitKey(1) & 0xFF
# 如果按下 'q' 键,退出循环
if key == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
人脸检测
人脸识别是基于人的脸部特征信息进行身份识别的一种生物识别技术,也是计算机视觉重点发展的技术。机器学习算法诞生之后,计算机可以通过摄像头等输入设备自动分析图像中包含的内容信息,随着技术的不断发展,现在已经有了多种人脸识别的算法。本章将介绍OpenCV自带的多种图像跟踪技术和3种人脸识别技术的用法。

级联分类器
将一系列简单的分类器按照一定顺序级联到一起就构成了级联分类器,使用级联分类器的程序可以通过一系列简单的判断来对样本进行识别。例如,依次满足“有6条腿”“有翅膀”“有头、胸、腹”这3个条件的样本就可以被初步判断为昆虫,但如果任何一个条件不满足,则不会被认为是昆虫
OpenCV提供了一些已经训练好的级联分类器,这些级联分类器以XML文件的方式保存在以下路径中:
…\Python\Lib\site-packages\cv2\data
我的window在:D:/condaenv/tensorflowcpu/Library/etc/haarcascades/
OpenCV实现人脸检测需要做两步操作:加载级联分类器和使用分类器识别图像。这两步操作都有对应的方法。
首先是加载级联分类器,OpenCV通过CascadeClassifier()方法创建了分类器对象,其语法如下:
<CascadeClassifier object> = cv2.CascadeClassifier(filename)
参数说明:
- filename:级联分类器的XML文件名。
返回值说明: - object:分类器对象。
然后使用已经创建好的分类器对图像进行识别,这个过程需要调用分类器对象的detectMultiScale()方法,其语法如下:
objects = cascade.detectMultiScale(image, scaleFactor, minNeighbors, flags, minSize, maxSize)
对象说明:
cascade:已有的分类器对象。
参数说明:
- image:待分析的图像。
- scaleFactor:可选参数,扫描图像时的缩放比例。
- minNeighbors:可选参数,每个候选区域至少保留多少个检测结果才可以判定为人脸。该值越大,分析的误差越小。
- flags:可选参数,旧版本OpenCV的参数,建议使用默认值。
- minSize:可选参数,最小的目标尺寸。
- maxSize:可选参数,最大的目标尺寸。
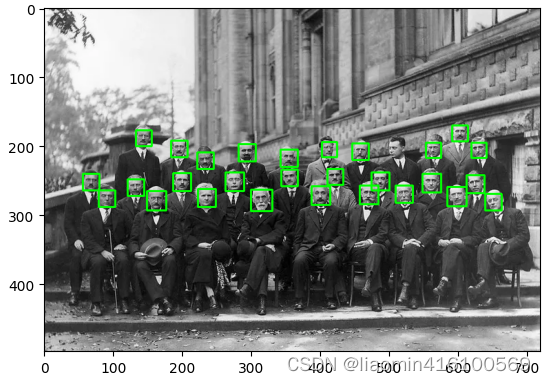
返回值说明: - objects:捕捉到的目标区域数组,数组中每一个元素都是一个目标区域,每一个目标区域都包含4个值,分别是:左上角点横坐标、左上角点纵坐标、区域宽、区域高。object的格式为:[[244 203 111 111] [432 81 133 133]]。
原图:

#%%
import cv2
import matplotlib.pyplot as plot
#加载人脸模型
xml_dir="D:/condaenv/tensorflowcpu/Library/etc/haarcascades/"
# 加载人脸检测器
face_cascade = cv2.CascadeClassifier(xml_dir+'haarcascade_frontalface_alt2.xml')
print(face_cascade)
# 读取要处理的图片
img = cv2.imread('../images/people.png')
# 转换为灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 检测人脸
faces = face_cascade.detectMultiScale(gray)
# 在图像中框出人脸
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 显示结果
plot.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plot.show()