Lovasz loss
在图像分割任务中,经常出现类别分布不均匀的情况,例如:工业产品的瑕疵检测、道路提取 及 病变区域提取等。我们可使用 lovasz loss 解决这个问题。
Lovasz loss 基于子模损失 (submodular losses) 的凸 Lovasz 扩展,对神经网络的 mean IoU 损失进行优化。
Lovasz loss 根据分割目标的类别数量可分为两种:lovasz hinge loss和lovasz softmax loss.
其中lovasz hinge loss适用于二分类问题,lovasz softmax loss适用于多分类问题。
一、Lovasz loss使用指南
接下来介绍如何使用lovasz loss进行训练。需要注意的是,通常的直接训练方式并一定管用,推荐另外 2 种训练方式:
- (1)与
cross entropy loss或bce loss(binary cross-entropy loss)加权结合使用。 - (2)先使用
cross entropy loss或bce loss进行训练,再使用lovasz softmax loss或lovasz hinge loss进行 finetuning.
以方式(1)为例,通过 MixedLoss 类选择训练时的损失函数, 通过 coef 参数对不同 loss 进行权重配比,从而灵活地进行训练调参。
一般的网络仅有一个输出 logit,使用示例如下:
Lovasz softmax loss示例
loss:
types:
- type: MixedLoss
losses:
- type: CrossEntropyLoss
- type: LovaszSoftmaxLoss
coef: [0.8, 0.2]
coef: [1]
Lovasz hinge loss示例
loss:
types:
- type: MixedLoss
losses:
- type: CrossEntropyLoss
- type: LovaszHingeLoss
coef: [1, 0.02]
coef: [1]
对于多个输出 logit 的网络,使用示例如下(以 2 个输出为例):
loss:
types:
- type: MixedLoss
losses:
- type: CrossEntropyLoss
- type: LovaszSoftmaxLoss
coef: [0.8, 0.2]
- type: MixedLoss
losses:
- type: CrossEntropyLoss
- type: LovaszSoftmaxLoss
coef: [0.8, 0.2]
coef: [1, 0.4]
二、Lovasz softmax loss 实验对比
接下来以经典的 Cityscapes 数据集为例应用 lovasz softmax loss. Cityscapes数据集共有 19 类目标,其中的类别并不均衡,例如类别 road、building 很常见,fence、motocycle、wall 则较为罕见。我们将 lovasz softmax loss 与 softmax loss 进行了实验对比。这里使用 OCRNet 模型,backbone 为 HRNet w18.
2.1 数据准备
2.1.1 关于CityScapes数据集
cityscapes
|
|--leftImg8bit
| |--train
| |--val
| |--test
|
|--gtFine
| |--train
| |--val
| |--test
运行下列命令进行标签转换:
pip install cityscapesscripts
python tools/convert_cityscapes.py --cityscapes_path data/cityscapes --num_workers 8
其中 cityscapes_path 应根据实际数据集路径进行调整。 num_workers决定启动的进程数,可根据实际情况进行调整大小。
2.1.2 关于 Pascal VOC 2012 数据集
Pascal VOC 2012 数据集以对象分割为主,包含 20 个类别和背景类,其中训练集 1464 张,验证集 1449 张。
通常情况下会利用 SBD(Semantic Boundaries Dataset) 进行扩充,扩充后训练集 10582 张。
运行下列命令进行 SBD 数据集下载并进行扩充:
python tools/voc_augment.py --voc_path data/VOCdevkit --num_workers 8
其中 voc_path 应根据实际数据集路径进行调整。
注意 运行前请确保在PaddleSeg目录下执行过下列命令:
export PYTHONPATH=`pwd`
# windows下请执行相面的命令
# set PYTHONPATH=%cd%
2.1.3 关于 ADE20K 数据集
ADE20K 由 MIT 发布的可用于场景感知、分割和多物体识别等多种任务的数据集。
其涵盖了 150 个语义类别,包括训练集 20210 张,验证集 2000 张。
2.1.4 关于 Coco Stuff 数据集
Coco Stuff 是基于 Coco 数据集的像素级别语义分割数据集。它主要覆盖 172个 类别,包含 80 个 'thing',91个 'stuff' 和 1 个 'unlabeled', 其中训练集 118k, 验证集 5k.
在使用 Coco Stuff 数据集前, 请自行前往 COCO-Stuff主页 下载数据集,或者下载 coco2017训练集原图, coco2017验证集原图 及 标注图
数据集下载后请组织成如下结构:
cocostuff
|
|--images
| |--train2017
| |--val2017
|
|--annotations
| |--train2017
| |--val2017
其中,标注图像的标签从 0,1 依次取值,不可间隔。若有需要忽略的像素,则按 255 进行标注。
2.1.4 关于自定义数据集
如果您需要使用自定义数据集进行训练,请按照以下步骤准备数据.
1. 推荐整理成如下结构
custom_dataset
|
|--images
| |--image1.jpg
| |--image2.jpg
| |--...
|
|--labels
| |--label1.jpg
| |--label2.png
| |--...
|
|--train.txt
|
|--val.txt
|
|--test.txt
其中 train.txt 和 val.txt 的内容如下所示:
images/image1.jpg labels/label1.png
images/image2.jpg labels/label2.png
...
2. 标注图像的标签从 0,1 依次取值,不可间隔。若有需要忽略的像素,则按255进行标注。
可按如下方式对自定义数据集进行配置:
train_dataset:
type: Dataset
dataset_root: custom_dataset
train_path: custom_dataset/train.txt
num_classes: 2
transforms:
- type: ResizeStepScaling
min_scale_factor: 0.5
max_scale_factor: 2.0
scale_step_size: 0.25
- type: RandomPaddingCrop
crop_size: [512, 512]
- type: RandomHorizontalFlip
- type: Normalize
mode: train
2.2 Lovasz loss训练
CUDA_VISIBLE_DEVICES=0,1,2,3 python -u -m paddle.distributed.launch train.py \
--config configs/ocrnet/ocrnet_hrnetw18_cityscapes_1024x512_160k_lovasz_softmax.yml \
--use_vdl --num_workers 3 --do_eval
- Cross entropy loss 训练
CUDA_VISIBLE_DEVICES=0,1,2,3 python -u -m paddle.distributed.launch train.py \
--config configs/ocrnet/ocrnet_hrnetw18_cityscapes_1024x512_160k.yml \
--use_vdl --num_workers 3 --do_eval
- 结果比较
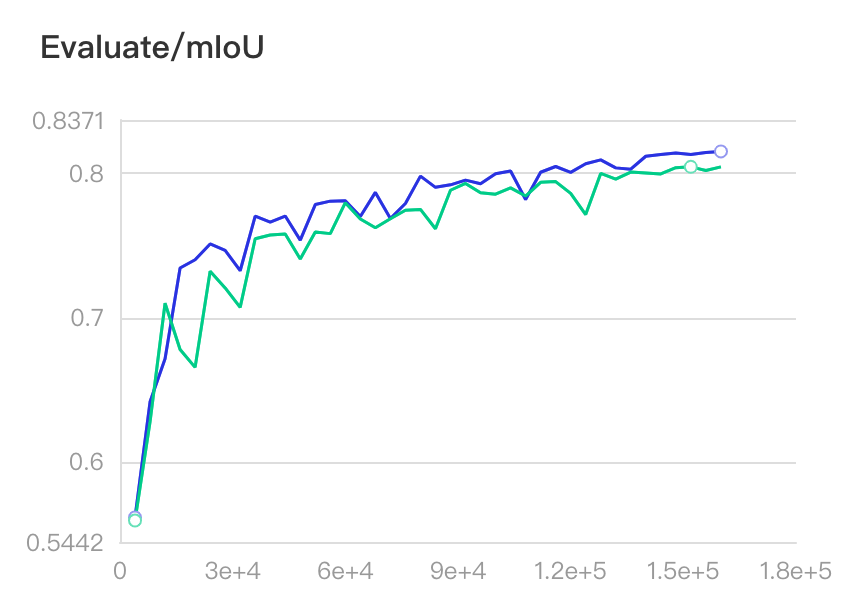
实验 mIoU 曲线如下图所示。
图中蓝色曲线代表 lovasz softmax loss + cross entropy loss,绿色曲线代表 cross entropy loss,相比提升 1 个百分点。
可看出使用 lovasz softmax loss 后,精度曲线基本都高于原来的精度。
| Loss | best mIoU |
|---|---|
| cross entropy loss | 80.46% |
| lovasz softmax loss + cross entropy loss | 81.53% |
三、Lovasz hinge loss实验对比
我们以道路提取任务为例应用 lovasz hinge loss.
基于 MiniDeepGlobeRoadExtraction 数据集与 cross entropy loss 进行了实验对比。
该数据集来源于 DeepGlobe CVPR2018挑战赛 的 Road Extraction 单项,训练数据道路占比为 4.5%. 道路在整张图片中的比例很小,是典型的类别不均衡场景。图片样例如下:
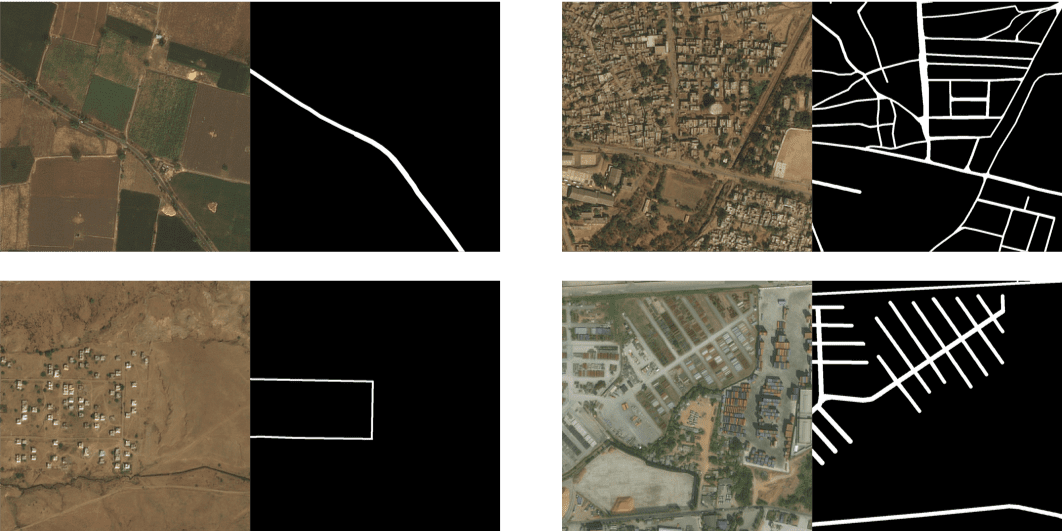
这里使用 OCRNet 模型,backbone 为 HRNet w18.
-
数据集
从 DeepGlobe 比赛的 Road Extraction 的训练集中随机抽取了 800 张图片作为训练集,200 张图片作为验证集,制作了一个小型的道路提取数据集 MiniDeepGlobeRoadExtraction。
运行训练脚本将自动下载该数据集。 -
Lovasz loss 训练
CUDA_VISIBLE_DEVICES=0,1,2,3 python -u -m paddle.distributed.launch train.py \
--config configs/ocrnet/ocrnet_hrnetw18_road_extraction_768x768_15k_lovasz_hinge.yml \
--use_vdl --num_workers 3 --do_eval
- Cross entropy loss 训练
CUDA_VISIBLE_DEVICES=0,1,2,3 python -u -m paddle.distributed.launch train.py \
--config configs/ocrnet/ocrnet_hrnetw18_road_extraction_768x768_15k.yml \
--use_vdl --num_workers 3 --do_eval
- 结果比较
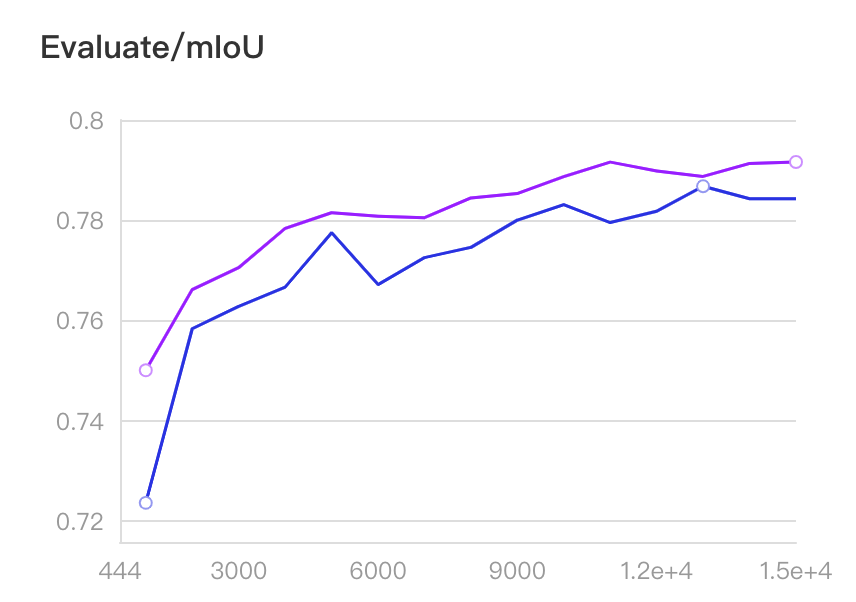
实验 mIoU 曲线如下图所示。
图中紫色曲线为 lovasz hinge loss + cross entropy loss,蓝色曲线为 cross entropy loss,相比提升 0.5 个百分点。
可看出使用 lovasz hinge loss 后,精度曲线全面高于原来的精度。
| Loss | best mIoU |
|---|---|
| cross entropy loss | 78.69% |
| lovasz softmax loss + cross entropy loss | 79.18% |