手写Strategy模式(策略模式)
Strategy Pattern 的定义
策略模式是属于设计模式中的行为模式中的一种,策略模式主要解决选项过多的问题,避免大量的if else 和 switch下有太多的case。
策略模式的重心不是如何实现算法,而是如何组织、调用这些算法,从而让程序结构更灵活,具有更好的维护性和扩展性
策略(Strategy)模式:
-
该模式定义了一系列算法,并将每个算法封装起来,使它们可以相互替换
-
策略模式让算法独立于使用它的客户而变化。
策略是个形象的表述,所谓策略就是方案,日常生活中,要实现目标,有很多方案,每一个方案都被称之为一个策略。在软件开发中也常常遇到类似的情况,实现某一个功能有多个途径,此时可以使用一种设计模式来使得系统可以灵活地选择解决途径,也能够方便地增加新的解决途径,这就是策略模式。
策略模式的场景分析
这个模式使得我们可以在根据环境或者条件的不同选择不同的策略来完成该任务。
策略模式的的最大优势:方便代码的功能横向扩展,策略模式将解决途径进行封装有利于我们对解决方式的增加或删除。
同时,策略模式(Strategy Pattern) 也符合开闭原则。
策略模式的主要角色
在策略模式中,我们可以定义一些独立的类来封装不同的算法,每一个类封装一种具体的算法,在这里,每一个封装算法的类我们都可以称之为一种策略(Strategy),为了保证这些策略在使用时具有一致性,一般会提供一个抽象的策略类来做规则的定义,而每种算法则对应于一个具体策略类。
策略模式涉及到三个角色,具体如下:
-
抽象策略(Strategy)类:这是一个抽象角色,通常由一个接口或抽象类实现。此角色给出所有的具体策略类所需的接口,所有具体的策略类都要实现这个接口。环境(上下文)类Context 使用这个接口调用具体的策略类。
-
具体策略(Concrete Strategy)类:实现了抽象策略定义的接口,提供具体的算法实现或行为。
-
环境(Context)类:用于配置一个具体的算法策略对象 ,维持一个策略接口类型的引用( Reference ),并且可以定义一个让接口 Strategy 的具体对象访问的接口。在简单情况下,Context 类可以省略。

策略模式是一个比较容易理解和使用的设计模式,策略模式是对算法的封装,它把算法的责任和算法本身分割开,委派给不同的对象管理。策略模式通常把一个系列的算法封装到一系列具体策略类里面,作为抽象策略类的子类。
在策略模式中,对环境类和抽象策略类的理解非常重要,环境类是需要使用算法的类。在一个系统中可以存在多个环境类,它们可能需要重用一些相同的算法。
在客户端代码中只需注入一个具体策略对象,可以将具体策略类类名存储在配置文件中,通过反射来动态创建具体策略对象,从而使得用户可以灵活地更换具体策略类,增加新的具体策略类也很方便。
策略模式提供了一种可插入式(Pluggable)算法的实现方案。
策略模式的主要目的是将算法的定义与使用分开,也就是将算法的行为和环境分开,将算法的定义放在专门的策略类中,每一个策略类封装了一种实现算法,使用算法的环境类针对抽象策略类进行编程,符合“依赖倒转原则”。在出现新的算法时,只需要增加一个新的实现了抽象策略类的具体策略类即可。
策略模式的Java实现
1.创建抽象策略类
2.创建具体策略
(1)具体策略A
(2)具体策略B
(3)具体策略N
3.创建环境类
step1:创建抽象策略类
-
定义所有持的算法的公共接口。
-
所有具体的策略类都要实现这个接口。
-
context使用这个接口来调用某concreteStrategy定义的算法;
定义百货公司所有促销活动的共同接口
package com.crazymakercircle.designpattern.strategy;
//抽象策略类
public interface Strategy {
void show();
}
step2:创建具体策略
进一步拆分策略类 ,将每个促销算法都单独封装在一个类中,也就是将一个类拆分成几个类,每个类都单独封装一个促销策略算法。
这样一来,修改一个算法只需重新编译算法所涉及的那个类,而不需要重新编译其他类。如果想要添加一个新的算法 只需在子类的集合中再添加一个新的封装该算法的类即可。
定义具体策略角色(Concrete Strategy):每个节日具体的促销活动
//为春节准备的促销活动A
public class StrategyA implements Strategy {
public void show() {
System.out.println("买一送一");
}
}
//为中秋准备的促销活动B
public class StrategyB implements Strategy {
public void show() {
System.out.println("满200元减50元");
}
}
//为圣诞准备的促销活动C
public class StrategyC implements Strategy {
public void show() {
System.out.println("满1000元加一元换购任意200元以下商品");
}
}
step3:创建环境类
Context 通常根据配置, 加载和初始化具体的 ConcreteStrategy, 配置的方式是多样化的:
-
系统环境变量
-
xml文件
-
数据库
-
等等
Context将它的客户的请求转发给它的Strategy。
client 仅与Context交互。客户通常从 context 获取 ConcreteStrategy,这样, Context 通常有一系列的ConcreteStrategy类可供 客户从中选择。
package com.crazymakercircle.designpattern.strategy;
import lombok.Data;
@Data
public class Context {
String type = System.getenv("strategy");
Strategy strategy = null;
public Context() {
switch (type) {
case "1":
strategy = new StrategyA();
break;
case "2":
strategy = new StrategyB();
break;
case "3":
strategy = new StrategyC();
break;
default:
strategy = new StrategyA();
}
}
}
运行的时候,设置好环境变量

step4:创建客户类

策略模式的GO代码实现
下面我们就开始以GO代码的形式来展示一下策略模式吧,用一个加减乘除法来模拟。
首先,我们看到的将会是策略接口和一系列的策略,这些策略不要依赖高层模块的实现。
package strategy
/**
* 策略接口
*/
type Strategier interface {
Compute(num1, num2 int) int
}
很简单的一个接口,定义了一个方法Compute,接受两个参数,返回一个int类型的值,很容易理解,我们要实现的策略将会将两个参数的计算值返回。接下来,我们来看一个我们实现的策略,
package strategy
import "fmt"
type Division struct {}
func (p Division) Compute(num1, num2 int) int {
defer func() {
if f := recover(); f != nil {
fmt.Println(f)
return
}
}()
if num2 == 0 {
panic("num2 must not be 0!")
}
return num1 / num2
}
为什么要拿除法作为代表呢?因为除法特殊,被除数不能为0,其他的加减乘基本都是一行代码搞定,除法我们需要判断被除数是否为0,如果是0则直接抛出异常。基本的策略定义好了,我们还需要一个工厂方法,根据不用的type来返回不同的策略,这个type我们准备从命令好输入。
func NewStrategy(t string) (res Strategier) {
switch t {
case "s": // 减法
res = Subtraction{}
case "m": // 乘法
res = Multiplication{}
case "d": // 除法
res = Division{}
case "a": // 加法
fallthrough
default:
res = Addition{}
}
return
}
这个工厂方法会根据不用的类型来返回不同的策略实现,当然,哪天我们需要新增新的策略,我们只需要在这个函数中增加对应的类型判断就ok。
现在策略貌似已经完成了,接下来我们来看看主流程代码,一个Computer,
package compute
import (
"fmt"
s "../strategy"
)
type Computer struct {
Num1, Num2 int
strate s.Strategier
}
func (p *Computer) SetStrategy(strate s.Strategier) {
p.strate = strate
}
func (p Computer) Do() int {
defer func() {
if f := recover(); f != nil {
fmt.Println(f)
}
}()
if p.strate == nil {
panic("Strategier is null")
}
return p.strate.Compute(p.Num1, p.Num2)
}
这个Computer中有三个参数,Num1和Num2当然是我们要操作的数了,strate是我们要设置的策略,可能是上面介绍的Division,也有可能是其他的,在main函数中我们会调用SetStrategy方法来设置要使用的策略,Do方法会执行运算,最后返回运算的结果,可以看到在Do中我们将计算的功能委托给了Strategier。
貌似一切准备就绪,我们就来编写main的代码吧。
package main
import (
"fmt"
"flag"
c "./computer"
s "./strategy"
)
var stra *string = flag.String("type", "a", "input the strategy")
var num1 *int = flag.Int("num1", 1, "input num1")
var num2 *int = flag.Int("num2", 1, "input num2")
func init() {
flag.Parse()
}
func main() {
com := c.Computer{Num1: *num1, Num2: *num2}
strate := s.NewStrategy(*stra)
com.SetStrategy(strate)
fmt.Println(com.Do())
}
首先我们要从命令行读取要使用的策略类型和两个操作数,在main函数中,我们初始化Computer这个结构体,并将输入的操作数赋值给Computer的Num1和Num2,接下来我们根据策略类型通过调用NewStrategy函数来获取一个策略,并调用Computer的SetStrategy方法给Computer设置上面获取到的策略,最后执行Do方法计算结果,最后打印。
就是这么简单,现在我们在命令行定位到main.go所在的目录,并执行一下命令来编译文件
go build main.go
继续执行命令
main -type d -num1 4 -num2 2
来尝试一下使用加法策略操作4和2这两个数,来看看结果如何,

结果很正确,换一个策略试试,来个乘法吧,执行命令
main -type m -num1 4 -num2 2
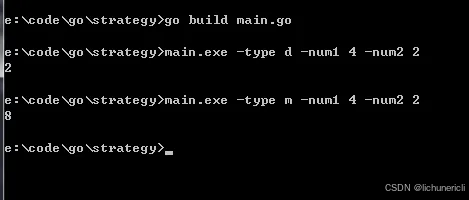
结果也是正确的。
策略模式的优缺
优点
-
策略模式的关注点不是如何实现算法,而是如何组织、调用这些算法,从而让程序结构更灵活,具有更好的维护性和扩展性。
-
策略模式中各个策略算法是平等的。对于一系列具体的策略算法,地位是完全一样的。正因为这个平等性,才能实现算法之间可以相互替换。所有的策略算法在实现上也是相互独立的,相互之间是没有依赖的。所以可以这样描述这一系列策略算法:策略算法是相同行为的不同实现。
-
运行期间,策略模式在每一个时刻只能使用一个具体的策略实现对象,虽然可以动态地在不同的策略实现中切换,但是同时只能使用一个。
如果所有的具体策略类都有一些公有的行为。这时候,就应当把这些公有的行为放到共同的抽象策略角色 Strategy 类里面。当然这时候抽象策略角色必须要用 Java 抽象类实现,而不能使用接口。但是,编程中没有银弹,策略模式也不例外,也有一些缺点,先来回顾总结下优点:
-
策略模式提供了对“开闭原则”的完美支持,用户可以在不修改原有系统的基础上选择算法或行为,也可以灵活地增加新的算法或行为。
-
策略模式提供了管理相关的算法族的办法。策略类的等级结构定义了一个算法或行为族。恰当使用继承可以把公共的代码移到父类里面,从而避免代码重复。
-
使用策略模式可以避免使用多重条件(if-else)语句。多重条件语句不易维护,它把采取哪一种算法或采取哪一种行为的逻辑与算法或行为的逻辑混合在一起,统统列在一个多重条件语句里面,比使用继承的办法还要原始和落后。
缺点
-
客户端必须知道所有的策略类,并自行决定使用哪一个策略类。这就意味着客户端必须理解这些算法的区别,以便适时选择恰当的算法类。这种策略类的创建及选择其实也可以通过工厂模式来辅助进行。
-
由于策略模式把每个具体的策略实现都单独封装成为类,如果备选的策略很多的话,那么对象的数目就会很可观。可以通过使用享元模式在一定程度上减少对象的数量。
关于策略模式的讨论
策略模式的核心就是将容易变动的代码从主逻辑中分离出来,通过一个接口来规范它们的形式,在主逻辑中将任务委托给策略。这样做既减少了我们对主逻辑代码修改的可能性,也增加了系统的可扩展性。
设计的核心原则:对扩展开发,对修改关闭
使用策略模式主要有两个出发点:
(1) 将一组相关的算法封装为各个策略分支,从而将策略分支相关的代码隐藏起来。
(2) 希望可以提升程序的可扩展性。
下面我们就策略模式的可扩展性进行简单的讨论,实际上 策略模式的初衷是要减少与各个分支下的行为相关的条件语句。这已经通过将一个具有条件相关的多种行为的类拆分成一个策略超类与若干个策略子类得到了解决。也就是说,将原来的一个单独的但是包含多个条件语句的类改变为一个没有条件语句的策略层次类。
这里虽然看似条件语句消失,但是在客户程序与 Context 类中是否也不存在与策略子类相关的条件语句?答案当然不是。
实际上一般在策略模式的设计中 客户类根据不同的条件负责创建不同的策略子类的对象,然后再将该对象传递给 Context 环境类,Context 类的作用可以理解为:为被调用策略子类的一些方法提供一些参数,以及使用该由 Client 类传入的对象去调用 Strategy 类的某些方法。
这说明,在客户类 Client 中 存在许多与策略分支子类相关的条件语句,而在 Context 类中,没有这样的语句。那么,是否可以将创建策略子类的对象的责任交给 Context 类,而客户类 Client 只为 Context 类提供一些代表客户请求的参数呢?
(1) 客户类负责创建策略子类的对象的情况
客户类根据用户提供的不同的请求,负责创建不同的策略子类的对象 ,然后再将该对象传递给 Context 类。在这种情况下,客户类中通常包含与策略相关的条件语句,而在 Context 类中不必使用任何与策略有关的条件语句,因此,修改或者添加一个策略子类都不必修改 Context 类。但是,在添加一个新的策略子类的情况下,如果客户类需要使用该子类,往往需要在客户类中添加一个新的条件语句,即客户类需要修改。
(2) Context 类负责创建策略子类的对象的情况
将创建策略子类的对象的责任交给 Context 类, 而客户类 Client 只为 Context 类提供一些代表客户请求的参数 ;在此情况下,Context 类在创建策略子类的对象时,必然会使用与策略子类有关的条件语句。此时,修改一个策略子类不需要修改客户类与 Context 类。而在添加一个新的策略子类时,如果此时客户类暂时不使用该新的子类,则新子类的添加不会影响客户类与 Context 类的源代码。但是,如果客户类要使用新的策略子类,则必须同时在客户类与 Con-text 类中添加新的条件分支,也就是说,需要同时修改客户类与 Context 类。
在以上两种情况下,只是需要修改策略子类的代码时,客户类与Context类都不需要进行修改。综上所述 由客户类创建对象的设计 可扩展性好一些。这样,可以做到在 Context 类中出现与策略子类相关的条件语句,从而可扩展性也得到了提高。
策略模式的应用场景

-
多个类只有算法或行为上稍有不同的场景
-
算法需要自由切换的场景
-
需要屏蔽算法规则的场景
-
出行方式,自行车、汽车等,每一种出行方式都是一个策略
-
商场促销方式,打折、满减等
策略模式和工厂模式的区别
工厂模式
-
目的是创建不同且相关的对象
-
侧重于"创建对象"
-
实现方式上可以通过父类或者接口
-
一般创建对象应该是现实世界中某种事物的映射,有它自己的属性与方法
策略模式
-
目的实现方便地替换不同的算法类
-
侧重于算法(行为)实现
-
实现主要通过接口
-
创建对象对行为的抽象而非对对象的抽象,很可能没有属于自己的属性
分布式ID,如何达到1000Wqps?
超高并发、超高性能分布式ID生成系统的要求
在复杂的超高并发、分布式系统中,往往需要对大量的数据和消息进行唯一标识。
如在高并发、分布式的金融、支付、餐饮、酒店、电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求;特别一点的如订单、骑手、优惠券也都需要有唯一ID做标识。
此时能够生成全局唯一ID的系统是非常必要的。那业务系统对ID号的要求有哪些呢?
主要有四点:
-
全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
-
趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
-
单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
-
信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
注意,上述1234对应不同的场景,特别注意:3和4需求还是互斥的,无法使用同一个方案满足。
同时除了对ID号码自身的要求,业务还对ID号生成系统的可用性要求极高,并且处于业务的黄金链路上,想象一下,如果ID生成系统瘫痪,整个系统黄金链路上关键动作都无法执行,这就会带来一场灾难。
超高并发、超高性能分布式ID生成系统三个超高
由此总结下一个ID生成系统应该做到如下三个超高:
-
超低延迟:平均延迟和TP999延迟都要尽可能低;
-
超高可用:可用性5个9;
-
超高并发: 高QPS。
超高并发, 最好是100Wqps以上,比如滴滴的tinyid,就达到千万QPS。
从最为基础的原理讲起,来看看 一个基本的问题:
-
什么是本地ID生成器?
-
什么是分布式ID生成器?
什么是本地ID生成器、分布式ID生成器
本地ID生成器是指在本地环境中生成唯一标识符(ID)的工具或算法。
本地ID生成器是相对于 分布式ID生成器而言的。二者的区分不是ID的用途,而是生产ID是否存在 网络IO开销:
-
本地ID生成器在本地生产ID,没有网络IO开销;
-
分布式ID生成器 需要进行远程调用生产ID,有网络IO开销;
总之,本地ID生成器所生产的ID并不是仅仅用于本地,也会用于分布式系统,拥有分布式系统中唯一标识实体或资源,例如数据库记录、消息、文件等。
在设计本地ID生成器时,需要考虑以下几个方面:
-
唯一性:生成的ID必须在整个系统中是唯一的,以避免冲突。
-
可排序性:生成的ID应该具有可排序性,以便根据ID的顺序进行查询和排序操作。
-
性能:ID生成的过程应该高效,不应该成为系统的瓶颈。
-
可读性:生成的ID可以是可读的,便于调试和理解。
-
分布式支持:如果系统是分布式的,需要确保在多个节点上生成的ID也是唯一的。
常见的本地ID生成器算法包括:
-
自增ID:使用一个计数器,在每次生成ID时递增。这种方式简单高效,但在分布式环境中需要额外的考虑,以避免冲突。
-
UUID(Universally Unique Identifier):使用标准的UUID算法生成唯一的128位标识符。UUID可以使用时间戳、MAC地址等信息来保证唯一性,但不具备可排序性。
-
雪花算法(Snowflake):雪花算法是Twitter开源的一种分布式ID生成算法。它使用一个64位的整数,结合时间戳、机器ID和序列号来生成唯一的ID。雪花算法具备可排序性和高性能,适用于分布式环境。
常见的分布式ID生成器算法包括:
-
数据库自增id,如Mysql 生产ID
-
Redis生成ID
-
Mongdb 生产ID
-
zookeeper 生产ID
-
其他的分布式生产ID
-
分布式雪花算法
-
分布式号段算法
常见的本地ID生成器算法
(一)uuid
UUID是一种本地生成ID的方式,UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符。
UUID的优点是:性能非常高,本地生成,没有网络消耗;
UUID的缺点是:不易于存储,信息不安全
uuid有两种包:
-
github.com/google/uuid ,仅支持V1和V4版本。
-
github.com/gofrs/uuid ,支持全部五个版本。
下面简单说下五种版本的区别:
-
Version 1,基于mac地址、时间戳。
-
Version 2,based on timestamp,MAC address and POSIX UID/GID (DCE 1.1)
-
Version 3,Hash获取入参并对结果进行MD5。
-
Version 4,纯随机数。
-
Version 5,based on SHA-1 hashing of a named value。
特点
-
5个版本可供选择。
-
定长36字节,偏长。
-
无序。
参考案例
下面是go版本的uuid 算法实现。
package mian
import (
"github.com/gofrs/uuid"
"fmt"
)
func main() {
// Version 1:时间+Mac地址
id, err := uuid.NewV1()
if err != nil {
fmt.Printf("uuid NewUUID err:%+v", err)
}
// id: f0629b9a-0cee-11ed-8d44-784f435f60a4 length: 36
fmt.Println("id:", id.String(), "length:", len(id.String()))
// Version 4:是纯随机数,error会在内部报panic
id, err = uuid.NewV4()
if err != nil {
fmt.Printf("uuid NewUUID err:%+v", err)
}
// id: 3b4d1268-9150-447c-a0b7-bbf8c271f6a7 length: 36
fmt.Println("id:", id.String(), "length:", len(id.String()))
}
(二)shortuuid
-
初始值基于uuid Version4;
-
第二步根据alphabet变量长度(定长57)计算id长度(定长22);
-
第三步依次用DivMod(欧几里得除法和模)返回值与alphabet做映射,合并生成id。
特点
-
基于uuid,但比uuid的长度短,定长22字节。
下面是go版本的shortuuid算法实现。
package mian
import (
"github.com/lithammer/shortuuid/v4"
"fmt"
)
func main() {
id := shortuuid.New()
// id: iDeUtXY5JymyMSGXqsqLYX length: 22
fmt.Println("id:", id, "length:", len(id))
// V22s2vag9bQEZCWcyv5SzL 固定不变
id = shortuuid.NewWithNamespace("http://127.0.0.1.com")
// id: K7pnGHAp7WLKUSducPeCXq length: 22
fmt.Println("id:", id, "length:", len(id))
// NewWithAlphabet函数可以用于自定义的基础字符串,字符串要求不重复、定长57
str := "12345#$%^&*67890qwerty/;'~!@uiopasdfghjklzxcvbnm,.()_+·><"
id = shortuuid.NewWithAlphabet(str)
// id: q7!o_+y('@;_&dyhk_in9/ length: 22
fmt.Println("id:", id, "length:", len(id))
}
(三)xid
XID(eXtended Identifier)是一个用于生成全局唯一标识符(GUID)的库。它是一个基于时间的、分布式的ID生成算法,旨在提供高性能和唯一性。
XID生成的ID是一个64位的整数,由以下部分组成:
-
时间戳(40位):使用40位存储纳秒级的时间戳,可以支持约34年的时间范围。与雪花算法不同,XID使用纳秒级时间戳,因此具有更高的时间分辨率。
-
机器ID(16位):使用16位表示机器的唯一标识符。每个机器在分布式系统中应具有唯一的机器ID,可以手动配置或通过自动分配获得。
-
序列号(8位):使用8位表示在同一纳秒内生成的序列号。如果在同一纳秒内生成的ID数量超过了8位能够表示的范围,那么会等待下一纳秒再生成ID。
xid是由时间戳、进程id、Mac地址、随机数组成。
有序性来源于对随机数部分的原子+1。

XID特点
-
长度短
-
有序
-
不重复
-
时间戳这个随机数原子+1操作,避免了时钟回拨的问题
XID生成的ID是趋势递增、唯一且可排序的,适用于分布式环境下的ID生成需求。与雪花算法相比,XID具有更高的时间分辨率,但在唯一性方面稍微弱一些,因为它使用了较短的机器ID和序列号。
XID库提供了生成ID、解析ID和验证ID的功能。
以下是使用Go语言中的XID库生成ID的示例代码:
package main
import (
"fmt"
"github.com/rs/xid"
)
func main() {
// 生成一个新的XID
id := xid.New()
// 打印生成的ID
fmt.Println(id.String())
}
上述代码导入了XID库,并使用xid.New()函数生成一个新的XID。通过调用String()方法,可以将XID转换为字符串形式进行打印输出。
总之,XID是一个用于生成全局唯一标识符的库,基于时间和机器ID生成唯一的ID。
(四)ksuid
KSUID(K-Sortable Unique Identifier)是一种用于生成全局唯一标识符(GUID)的算法和格式。它是由Segment.io开发的一种分布式ID生成方案,旨在提供高性能、唯一性和可排序性。
KSUID生成的ID是一个全局唯一的字符串,由以下部分组成:
-
时间戳(32位):使用32位存储秒级的时间戳,表示自协调世界时(UTC)1970年1月1日以来的秒数。与传统的UNIX时间戳相比,KSUID使用了更长的时间戳,可以支持更长的时间范围。
-
随机字节(16位):使用16位随机生成的字节,用于增加ID的唯一性。
-
附加信息(可选):在KSUID的格式中,还可以包含附加的信息,例如节点ID或其他标识符。这部分是可选的,可以根据需要进行使用。
KSUID生成的ID是按照时间顺序排序的,因此可以方便地按照生成的顺序进行排序和比较。它具有全局唯一性,并且不依赖于任何中央化的ID生成服务。
以下是使用Go语言中的github.com/segmentio/ksuid库生成KSUID的示例代码:
package main
import (
"fmt"
"github.com/segmentio/ksuid"
)
func main() {
// 生成一个新的KSUID
id := ksuid.New()
// 打印生成的ID
fmt.Println(id.String())
}
上述代码导入了github.com/segmentio/ksuid库,并使用ksuid.New()函数生成一个新的KSUID。通过调用String()方法,可以将KSUID转换为字符串形式进行打印输出。
总之,KSUID是一种用于生成全局唯一标识符的算法和格式。它具有高性能、唯一性和可排序性的特点,适用于分布式系统中的ID生成需求。通过使用github.com/segmentio/ksuid库,可以方便地生成和操作KSUID。
(五)ulid
随机数和时间戳组成
package mian
import (
"github.com/oklog/ulid"
"fmt"
)
func main() {
t := time.Now().UTC()
entropy := rand.New(rand.NewSource(t.UnixNano()))
id := ulid.MustNew(ulid.Timestamp(t), entropy)
// id: 01G902ZSM96WV5D5DC5WFHF8WY length: 26
fmt.Println("id:", id.String(), "length:", len(id.String()))
}
(六)snowflake
Snowflake是Twitter开源的一种分布式ID生成算法,用于在分布式系统中生成全局唯一的ID。它的设计目标是高性能、低延迟和趋势递增的ID生成。
Snowflake生成的ID是一个64位的整数,由以下部分组成:
-
时间戳(41位):使用41位存储毫秒级的时间戳,表示自定义的起始时间(Epoch)到生成ID的时间之间的毫秒数。
-
节点ID(10位):用于标识不同的节点或机器。在分布式系统中,每个节点应具有唯一的节点ID。
-
序列号(12位):在同一毫秒内生成的序列号。如果在同一毫秒内生成的ID数量超过了12位能够表示的范围,那么会等待下一毫秒再生成ID。
Snowflake生成的ID具有趋势递增的特点,因为高位部分是基于时间戳生成的。这样设计的目的是为了在数据库索引中提供更好的性能,使新生成的ID更容易被插入到索引的末尾,减少索引的分裂和碎片化。
以下是一个使用Go语言实现Snowflake算法的简单示例:
package main
import (
"fmt"
"sync"
"time"
)
const (
epoch = int64(1609459200000) // 起始时间戳,这里使用2021年1月1日的时间戳
nodeBits = 10 // 节点ID的位数
sequenceBits = 12 // 序列号的位数
)
// Snowflake 结构体
type Snowflake struct {
mu sync.Mutex
timestamp int64
nodeID int64
sequence int64
}
// NewSnowflake 创建一个新的Snowflake实例
func NewSnowflake(nodeID int64) *Snowflake {
return &Snowflake{
timestamp: 0,
nodeID: nodeID,
sequence: 0,
}
}
// Generate 生成一个新的ID
func (sf *Snowflake) Generate() int64 {
sf.mu.Lock()
defer sf.mu.Unlock()
now := time.Now().UnixNano() / 1e6
if now < sf.timestamp {
panic("Invalid system clock")
}
if now == sf.timestamp {
sf.sequence = (sf.sequence + 1) & ((1 << sequenceBits) - 1)
if sf.sequence == 0 {
// 序列号用尽,等待下一毫秒
for now <= sf.timestamp {
now = time.Now().UnixNano() / 1e6
}
}
} else {
sf.sequence = 0
}
sf.timestamp = now
id := (now-epoch)<<nodeBits | sf.nodeID<<sequenceBits | sf.sequence
return id
}
func main() {
// 创建一个Snowflake实例,传入节点ID
sf := NewSnowflake(1)
// 生成ID并打印
id := sf.Generate()
fmt.Println(id)
}
上述示例代码实现了一个简单的Snowflake算法,通过调用Generate()方法生成一个新的ID。在示例中,我们使用当前时间戳作为时间基准,并传入节点ID作为参数。
总之,Snowflake是一种分布式ID生成算法,用于在分布式系统中生成全局唯一的ID。它具有高性能、低延迟和趋势递增的特点,适用于需要在分布式环境下生成唯一ID的场景。
相对于UUID来说,雪花算法不会暴露MAC地址更安全、生成的ID也不会过于冗余。雪花的一部分ID序列是基于时间戳的,那么时钟回拨的问题就来了。snowflake 存在一个很大的问题:时钟回拨 问题
什么是时钟回拨问题
服务器上的时间突然倒退回之前的时间:
-
可能是人为的调整时间;
-
也可能是服务器之间的时间校对。
具体来说,时钟回拨(Clock Drift)指的是系统时钟在某个时刻向回调整,即时间向过去移动。时钟回拨可能发生在分布式系统中的某个节点上,这可能是由于时钟同步问题、时钟漂移或其他原因导致的。
时钟回拨可能对系统造成一些问题,特别是对于依赖于时间顺序的应用程序或算法。
在分布式系统中,时钟回拨可能导致以下问题:
-
ID冲突:如果系统使用基于时间的算法生成唯一ID(如雪花算法),时钟回拨可能导致生成的ID与之前生成的ID冲突,破坏了唯一性。
-
数据不一致:时钟回拨可能导致不同节点之间的时间戳不一致,这可能影响到分布式系统中的时间相关操作,如事件排序、超时判断等。数据的一致性可能会受到影响。
-
缓存失效:时钟回拨可能导致缓存中的过期时间计算错误,使得缓存项在实际过期之前被错误地认为是过期的,从而导致缓存失效。
为了应对时钟回拨问题,可以采取以下措施:
-
使用时钟同步服务:通过使用网络时间协议(NTP)等时钟同步服务,可以将节点的时钟与参考时钟进行同步,减少时钟回拨的可能性。
-
引入时钟漂移校正:在分布式系统中,可以通过周期性地校正节点的时钟漂移,使其保持与其他节点的时间同步。
-
容忍时钟回拨:某些应用场景下,可以容忍一定范围的时钟回拨。在设计应用程序时,可以考虑引入一些容错机制,以适应时钟回拨带来的影响。
总之,时钟回拨是分布式系统中需要关注的一个问题,可能对系统的时间相关操作、数据一致性和唯一ID生成等方面产生影响。
通过使用时钟同步服务、时钟漂移校正和容忍机制等方法,可以减少时钟回拨带来的问题。
分布式ID
数据库自增ID
这里常规是指数据库主键自增索引。
特点如下:
-
架构简单容易实现。
-
ID有序递增,IO写入连续性好。
-
INT和BIGINT类型占用空间较小。
-
由于有序递增,易暴露业务量。
-
受到数据库性能限制,对高并发场景不友好。
-
bigint最大是2^64-1,但是数据库单表肯定放不了这么多,那么就涉及到分表。如果业务量真的太大了,主键的自增id涨到头了,会发生什么?报错:主键冲突。
Redis生成ID
通过redis的原子操作INCR和INCRBY获得id。
相比数据库自增ID,redis性能更好、更加灵活。
不过架构强依赖redis,redis在整个架构中会产生单点问题。
在流量较大的场景下,网络耗时也可能成为瓶颈。
ZooKeeper唯一ID
ZooKeeper是使用了Znode结构中的Zxid实现顺序增ID。
Zookeeper类似一个文件系统,每个节点都有唯一路径名(Znode),Zxid是个全局事务计数器,每个节点发生变化都会记录响应的版本(Zxid),这个版本号是全局唯一且顺序递增的。
这种架构还是出现了ZooKeeper的单点问题。
分布式雪花算法
虽然Snowflake 可以很容易扩展成为分布式架构
-
Snowflake + 机器固定编号
-
Snowflake +zookeeper 自增编号
-
Snowflake + 数据库 自增编号
-
......
分布式雪花算法的代表作:百度的 UidGenerator。
UidGenerator是Java实现的, 基于Snowflake (https://github.com/twitter/snowflake)算法的唯一ID生成器。
UidGenerator以组件形式工作在应用项目中, 支持自定义workerId位数和初始化策略, 从而适用于docker (https://www.docker.com/)等虚拟化环境下实例自动重启、漂移等场景。
在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费, 同时对CacheLine补齐,避免了由RingBuffer带来的硬件级「伪共享」问题. 最终单机QPS可达600万。
分布式雪花ID方案1: 600万qps的百度 UidGenerator
UidGenerator是Java实现的, 基于Snowflake算法的唯一ID生成器。UidGenerator以组件形式工作在应用项目中, 支持自定义workerId位数和初始化策略, 从而适用于docker等虚拟化环境下实例自动重启、漂移等场景。
在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费, 同时对CacheLine补齐,避免了由RingBuffer带来的硬件级「伪共享」问题. 最终单机QPS可达600万。
依赖版本:
-
Java8 (http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html)及以上版本,
-
MySQL (https://dev.mysql.com/downloads/mysql/)(内置WorkerID分配器, 启动阶段通过DB进行分配; 如自定义实现, 则DB非必选依赖)
回顾Snowflake算法

Snowflake算法描述:指定机器 & 同一时刻 & 某一并发序列,是唯一的。据此可生成一个64 bits的唯一ID(long)。
默认采用上图字节分配方式:
-
sign(1bit)
固定1bit符号标识,即生成的UID为正数。
-
delta seconds (28 bits)
当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约8.7年 -
worker id (22 bits)
机器id,最多可支持约420w次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略。 -
sequence (13 bits)
每秒下的并发序列,13 bits可支持每秒8192个并发。
以上参数均可通过Spring进行自定义
CachedUidGenerator
RingBuffer环形数组,数组每个元素成为一个slot。RingBuffer容量,默认为Snowflake算法中sequence最大值,且为2^N。可通过boostPower配置进行扩容,以提高RingBuffer 读写吞吐量。
Tail指针、Cursor指针用于环形数组上读写slot:
-
Tail指针
表示Producer生产的最大序号(此序号从0开始,持续递增)。Tail不能超过Cursor,即生产者不能覆盖未消费的slot。当Tail已赶上curosr,此时可通过rejectedPutBufferHandler指定PutRejectPolicy -
Cursor指针
表示Consumer消费到的最小序号(序号序列与Producer序列相同)。Cursor不能超过Tail,即不能消费未生产的slot。当Cursor已赶上tail,此时可通过rejectedTakeBufferHandler指定TakeRejectPolicy

RingBuffer
CachedUidGenerator采用了双RingBuffer,Uid-RingBuffer用于存储Uid、Flag-RingBuffer用于存储Uid状态(是否可填充、是否可消费)
由于数组元素在内存中是连续分配的,可最大程度利用CPU cache以提升性能。但同时会带来「伪共享」FalseSharing问题,为此在Tail、Cursor指针、Flag-RingBuffer中采用了CacheLine补齐方式。

FalseSharing
RingBuffer填充时机
-
初始化预填充
RingBuffer初始化时,预先填充满整个RingBuffer. -
即时填充
Take消费时,即时检查剩余可用slot量(tail-cursor),如小于设定阈值,则补全空闲slots。阈值可通过paddingFactor来进行配置,请参考Quick Start中CachedUidGenerator配置 -
周期填充
通过Schedule线程,定时补全空闲slots。可通过scheduleInterval配置,以应用定时填充功能,并指定Schedule时间间隔
UidGeneratorQuick Start
这里介绍如何在基于Spring的项目中使用UidGenerator, 具体流程如下:
步骤1: 安装依赖
先下载Java8 (http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html)、 MySQL (https://dev.mysql.com/downloads/mysql/)和Maven (https://maven.apache.org/download.cgi)
设置环境变量
maven无须安装,设置好MAVEN_HOME即可。可像下述脚本这样设置JAVA_HOME和MAVEN_HOME,如已设置请忽略.
export MAVEN_HOME=/xxx/xxx/software/maven/apache-maven-3.3.9
export PATH=$MAVEN_HOME/bin:$PATH
JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_91.jdk/Contents/Home";
export JAVA_HOME;
步骤2: 创建表WORKER_NODE
运行sql脚本以导入表WORKER_NODE, 脚本如下:
DROP DATABASE IF EXISTS `xxxx`;
CREATE DATABASE `xxxx` ;
use `xxxx`;
DROP TABLE IF EXISTS WORKER_NODE;
CREATE TABLE WORKER_NODE
(
ID BIGINT NOT NULL AUTO_INCREMENT COMMENT 'auto increment id',
HOST_NAME VARCHAR(64) NOT NULL COMMENT 'host name',
PORT VARCHAR(64) NOT NULL COMMENT 'port',
TYPE INT NOT NULL COMMENT 'node type: ACTUAL or CONTAINER',
LAUNCH_DATE DATE NOT NULL COMMENT 'launch date',
MODIFIED TIMESTAMP NOT NULL COMMENT 'modified time',
CREATED TIMESTAMP NOT NULL COMMENT 'created time',
PRIMARY KEY(ID)
)
COMMENT='DB WorkerID Assigner for UID Generator',ENGINE = INNODB;
修改mysql.properties (https://github.com/baidu/uid-generator/blob/master/src/test/resources/uid/mysql.properties) 配置中, jdbc.url, jdbc.username和jdbc.password, 确保库地址, 名称, 端口号, 用户名和密码正确.
步骤3: 修改Spring配置
提供了两种生成器: DefaultUidGenerator (https://github.com/baidu/uid-generator/blob/master/src/main/java/com/baidu/fsg/uid/impl/DefaultUidGenerator.java)、CachedUidGenerator (https://github.com/baidu/uid-generator/blob/master/src/main/java/com/baidu/fsg/uid/impl/CachedUidGenerator.java)。
如对UID生成性能有要求, 请使用CachedUidGenerator
对应Spring配置分别为: https://github.com/baidu/uid-generator/blob/master/default-uid-spring.xml (src/test/resources/uid/default-uid-spring.xml)、cached-uid-spring.xml (https://github.com/baidu/uid-generator/blob/master/src/test/resources/uid/cached-uid-spring.xml)
DefaultUidGenerator配置
<!-- DefaultUidGenerator -->
<bean id="defaultUidGenerator" class="com.baidu.fsg.uid.impl.DefaultUidGenerator" lazy-init="false">
<property name="workerIdAssigner" ref="disposableWorkerIdAssigner"/>
<!-- Specified bits & epoch as your demand. No specified the default value will be used -->
<property name="timeBits" value="29"/>
<property name="workerBits" value="21"/>
<property name="seqBits" value="13"/>
<property name="epochStr" value="2016-09-20"/>
</bean>
<!-- 用完即弃的WorkerIdAssigner,依赖DB操作 -->
<bean id="disposableWorkerIdAssigner" class="com.baidu.fsg.uid.worker.DisposableWorkerIdAssigner" />
CachedUidGenerator配置
<!-- CachedUidGenerator -->
<bean id="cachedUidGenerator" class="com.baidu.fsg.uid.impl.CachedUidGenerator">
<property name="workerIdAssigner" ref="disposableWorkerIdAssigner" />
<!-- 以下为可选配置, 如未指定将采用默认值 -->
<!-- Specified bits & epoch as your demand. No specified the default value will be used -->
<property name="timeBits" value="29"/>
<property name="workerBits" value="21"/>
<property name="seqBits" value="13"/>
<property name="epochStr" value="2016-09-20"/>
<!-- RingBuffer size扩容参数, 可提高UID生成的吞吐量. -->
<!-- 默认:3, 原bufferSize=8192, 扩容后bufferSize= 8192 << 3 = 65536 -->
<property name="boostPower" value="3"></property>
<!-- 指定何时向RingBuffer中填充UID, 取值为百分比(0, 100), 默认为50 -->
<!-- 举例: bufferSize=1024, paddingFactor=50 -> threshold=1024 * 50 / 100 = 512. -->
<!-- 当环上可用UID数量 < 512时, 将自动对RingBuffer进行填充补全 -->
<property name="paddingFactor" value="50"></property>
<!-- 另外一种RingBuffer填充时机, 在Schedule线程中, 周期性检查填充 -->
<!-- 默认:不配置此项, 即不实用Schedule线程. 如需使用, 请指定Schedule线程时间间隔, 单位:秒 -->
<property name="scheduleInterval" value="60"></property>
<!-- 拒绝策略: 当环已满, 无法继续填充时 -->
<!-- 默认无需指定, 将丢弃Put操作, 仅日志记录. 如有特殊需求, 请实现RejectedPutBufferHandler接口(支持Lambda表达式) -->
<property name="rejectedPutBufferHandler" ref="XxxxYourPutRejectPolicy"></property>
<!-- 拒绝策略: 当环已空, 无法继续获取时 -->
<!-- 默认无需指定, 将记录日志, 并抛出UidGenerateException异常. 如有特殊需求, 请实现RejectedTakeBufferHandler接口(支持Lambda表达式) -->
<property name="rejectedTakeBufferHandler" ref="XxxxYourTakeRejectPolicy"></property>
</bean>
<!-- 用完即弃的WorkerIdAssigner, 依赖DB操作 -->
<bean id="disposableWorkerIdAssigner" class="com.baidu.fsg.uid.worker.DisposableWorkerIdAssigner" />
Mybatis配置
mybatis-spring.xml (https://github.com/baidu/uid-generator/blob/master/src/test/resources/uid/mybatis-spring.xml) 配置说明如下:
<!-- Spring annotation扫描 -->
<context:component-scan base-package="com.baidu.fsg.uid" />
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="mapperLocations" value="classpath:/META-INF/mybatis/mapper/M_WORKER*.xml" />
</bean>
<!-- 事务相关配置 -->
<tx:annotation-driven transaction-manager="transactionManager" order="1" />
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<!-- Mybatis Mapper扫描 -->
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="annotationClass" value="org.springframework.stereotype.Repository" />
<property name="basePackage" value="com.baidu.fsg.uid.worker.dao" />
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory" />
</bean>
<!-- 数据源配置 -->
<bean id="dataSource" parent="abstractDataSource">
<property name="driverClassName" value="${mysql.driver}" />
<property name="maxActive" value="${jdbc.maxActive}" />
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
</bean>
<bean id="abstractDataSource" class="com.alibaba.druid.pool.DruidDataSource" destroy-method="close">
<property name="filters" value="${datasource.filters}" />
<property name="defaultAutoCommit" value="${datasource.defaultAutoCommit}" />
<property name="initialSize" value="${datasource.initialSize}" />
<property name="minIdle" value="${datasource.minIdle}" />
<property name="maxWait" value="${datasource.maxWait}" />
<property name="testWhileIdle" value="${datasource.testWhileIdle}" />
<property name="testOnBorrow" value="${datasource.testOnBorrow}" />
<property name="testOnReturn" value="${datasource.testOnReturn}" />
<property name="validationQuery" value="${datasource.validationQuery}" />
<property name="timeBetweenEvictionRunsMillis" value="${datasource.timeBetweenEvictionRunsMillis}" />
<property name="minEvictableIdleTimeMillis" value="${datasource.minEvictableIdleTimeMillis}" />
<property name="logAbandoned" value="${datasource.logAbandoned}" />
<property name="removeAbandoned" value="${datasource.removeAbandoned}" />
<property name="removeAbandonedTimeout" value="${datasource.removeAbandonedTimeout}" />
</bean>
<bean id="batchSqlSession" class="org.mybatis.spring.SqlSessionTemplate">
<constructor-arg index="0" ref="sqlSessionFactory" />
<constructor-arg index="1" value="BATCH" />
</bean>
步骤4: 运行示例单测
运行单测CachedUidGeneratorTest (https://github.com/baidu/uid-generator/blob/master/src/test/java/com/baidu/fsg/uid/CachedUidGeneratorTest.java) ,展示UID生成、解析等功能
@Resource
private UidGenerator uidGenerator;
@Test
public void testSerialGenerate() {
// Generate UID
long uid = uidGenerator.getUID();
// Parse UID into [Timestamp, WorkerId, Sequence]
// {"UID":"180363646902239241","parsed":{ "timestamp":"2017-01-19 12:15:46", "workerId":"4", "sequence":"9" }}
System.out.println(uidGenerator.parseUID(uid));
}
分布式雪花ID方案2:美团 Leaf-snowflake
美团 Leaf-snowflake 方案,属于 Snowflake + zookeeper 自增编号 的类型。
美团 Leaf-snowflake架构

-
用Zookeeper顺序增、全局唯一的节点版本号,替换了原有的机器地址。
-
强依赖ZooKeeper的缺点:强依赖ZooKeeper、大流量下的网络下,存在网络瓶颈。
-
解决了时钟回拨的问题。运行时运行时,时差小于5ms会等待时差两倍时间,如果时差大于5ms报警并停止启动。
-
通过缓存一个ZooKeeper文件夹,提高可用性。

Leaf-snowflake方案完全沿用snowflake方案的bit位设计,即是“1+41+10+12”的方式组装ID号。
对于workerID的分配,当服务集群数量较小的情况下,完全可以手动配置。Leaf服务规模较大,动手配置成本太高。
所以使用Zookeeper持久顺序节点的特性自动对snowflake节点配置wokerID。
Leaf-snowflake是按照下面几个步骤启动的:
-
启动Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)。
-
如果有注册过直接取回自己的workerID(zk顺序节点生成的int类型ID号),启动服务。
-
如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerID号,启动服务。

从强依赖ZooKeeper优化为弱依赖ZooKeeper
除了每次会去ZK拿数据以外,也会在本机文件系统上缓存一个workerID文件。
当ZooKeeper出现问题,恰好机器出现问题需要重启时,能保证服务能够正常启动。
这样做到了对三方组件的弱依赖。一定程度上提高了 系统的可用性。
解决时钟问题
因为这种方案依赖时间,如果机器的时钟发生了回拨,那么就会有可能生成重复的ID号,需要解决时钟回退的问题。

参见上图整个启动流程图,服务启动时首先检查自己是否写过ZooKeeper leaf_forever节点:
-
若写过,则用自身系统时间与
leaf_forever/${self}节点记录时间做比较,若小于leaf_forever/${self}时间则认为机器时间发生了大步长回拨,服务启动失败并报警。 -
若未写过,证明是新服务节点,直接创建持久节点
leaf_forever/${self}并写入自身系统时间,接下来综合对比其余Leaf节点的系统时间来判断自身系统时间是否准确,具体做法是取leaf_temporary下的所有临时节点(所有运行中的Leaf-snowflake节点)的服务IP:Port,然后通过RPC请求得到所有节点的系统时间,计算sum(time)/nodeSize。 -
若abs( 系统时间
-sum(time)/nodeSize) < 阈值,认为当前系统时间准确,正常启动服务,同时写临时节点leaf_temporary/${self}维持租约。 -
否则认为本机系统时间发生大步长偏移,启动失败并报警。
-
每隔一段时间(3s)上报自身系统时间写入
leaf_forever/${self}。
由于强依赖时钟,对时间的要求比较敏感,在机器工作时NTP同步也会造成秒级别的回退,建议可以直接关闭NTP同步。
要么在时钟回拨的时候直接不提供服务直接返回ERROR_CODE,等时钟追上即可。
或者做一层重试,然后上报报警系统,更或者是发现有时钟回拨之后自动摘除本身节点并报警,如下:
//发生了回拨,此刻时间小于上次发号时间
if (timestamp < lastTimestamp) {
long offset = lastTimestamp - timestamp;
if (offset <= 5) {
try {
//时间偏差大小小于5ms,则等待两倍时间
wait(offset << 1);//wait
timestamp = timeGen();
if (timestamp < lastTimestamp) {
//还是小于,抛异常并上报
throwClockBackwardsEx(timestamp);
}
} catch (InterruptedException e) {
throw e;
}
} else {
//throw
throwClockBackwardsEx(timestamp);
}
}
//分配ID
从上线情况来看,在2017年闰秒出现那一次出现过部分机器回拨,由于Leaf-snowflake的策略保证,成功避免了对业务造成的影响。