Jammy@Jetson Orin - Tensorflow & Keras Get Started: Transfer Learning & Fine Tuning
1. 源由
- 《Jammy@Jetson Orin - Tensorflow & Keras Get Started: 003 Implementing a CNN in TensorFlow & Keras》
- 《Jammy@Jetson Orin - Tensorflow & Keras Get Started: 004 Keras Pre-Trained ImageNet Models》
上面展示了如何使用Keras进行CNN神经网络训练预测和基于VGG16、ResNet50、InceptionV3预训练模型进行图像分类。
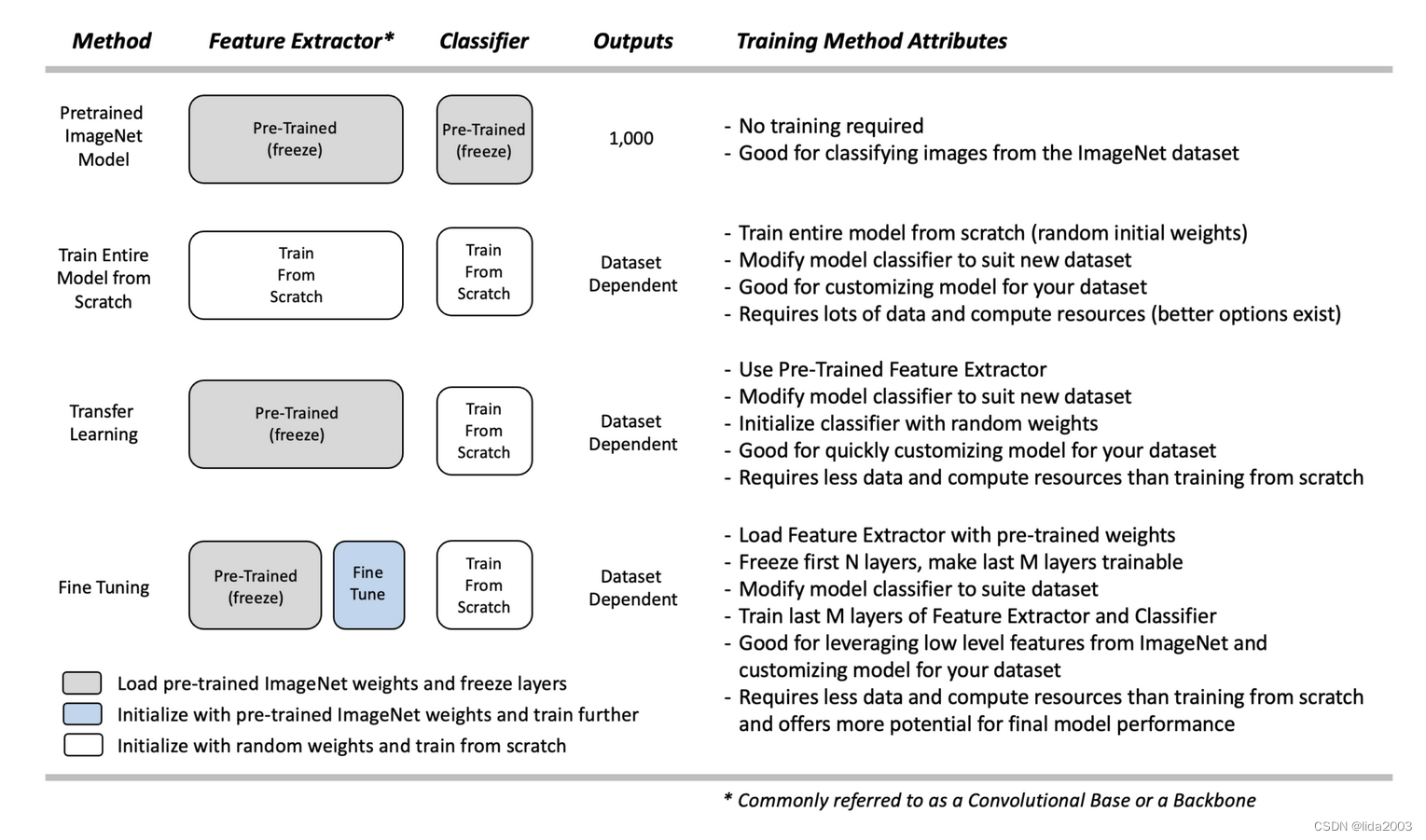
- 直接使用【Pretrained Model,预训练模型】
- 从头开始【Train Entire Model,训练模型】
因为,神经网络训练的资源(内存、GPU/CPU、时间)开销是非常大的,那么是否有技术能够兼顾这些从而高效的训练呢?
答案当然是有的,接下来将从概念上探讨利用预训练模型对定制 数据集的训练:
- 使用【Transfer Learning,迁移学习】
- 使用【Fine-Tuning,微调预训练模型】
当拥有有限的相似自定义数据集和/或有限的计算资源时,上述【Transfer Learning,迁移学习】和【Fine-Tuning,微调预训练模型】技术,将非常好的解决实际问题。
2. 迁移学习(Transfer Learning)
迁移学习是使用模型的预训练特征提取器(卷积基础),并重新训练一个新的分类器来学习新数据集的新权重。这有时被称为“冻结”特征提取器中的层,意味着我们加载预训练权重,并且在训练过程中不尝试进一步修改它们。
- 理论上,预训练模型已经学习了用于检测许多不同对象类型的有价值的特征。
- 假设这些特征足够通用,只需要重新训练网络的分类器部分。
- 与从头开始训练相比,这种方法需要的数据量和计算资源要少得多。

3. 微调预训练模型(Fine-Tuning)
然而,有时重新训练分类器并不足够。微调代表了对迁移学习的一种灵活替代方法。它与迁移学习非常相似。与完全锁定特征提取器不同,微调加载特征提取器与ImageNet权重,并且冻结特征提取器的前几层,但允许最后几层继续进行训练。其思想是特征提取器中的前几层代表通用的低级特征(例如,边缘、角落和弧线),这些特征是支持许多分类任务所必需的基本构建模块。特征提取器中的后续层建立在低级特征之上,学习更复杂的表示,这些表示与特定数据集的内容更密切相关。
通过微调,希望专门利用预训练模型的低级特征,但提供一些灵活性来“微调”卷积基础的最后几层,以为数据集提供最佳的定制化。因此,我们“冻结”初始层(即,使它们不可训练),并让模型训练特征提取器的最后几层以及分类器。
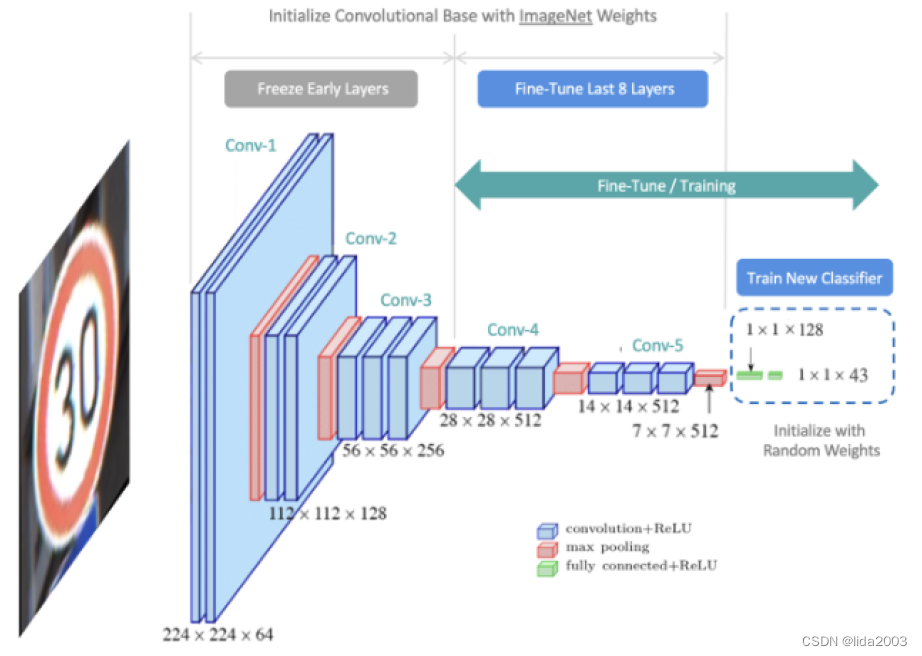
注:特征提取器中的所有层都初始化为ImageNet权重。一旦训练开始,特征提取器中最后几层的权重将进一步更新,这就是为什么这种方法被称为微调。此外,请注意,分类器中的权重被初始化为小的随机值,因为我们希望分类器学习分类新内容所需的新权重。
4. 总结
Jetson Orin Nano主要针对边缘计算应用,从定位的角度更倾向于推理应用,也就是在实际场景中用于【Pretrained Model,预训练模型】。
当然,一些简单的多因素工程算法(物联网应用,非图像类),可以考虑做更多工程应用。
- Jammy@Jetson Orin Nano - Tensorflow GPU版本安装
- Multiple executive warnings after switching tensorflow from 2.16.1 CPU to v60dp tensorflow==2.15.0+nv24.03 GPU version
后续,我们会尽量寻找一些占用资源少的算法,来进行介绍。