本文为365天深度学习训练营 中的学习记录博客
原作者:K同学啊
可参考论文:《Conditional Image Synthesis With Auxiliary Classifier GANs》
一、理论基础
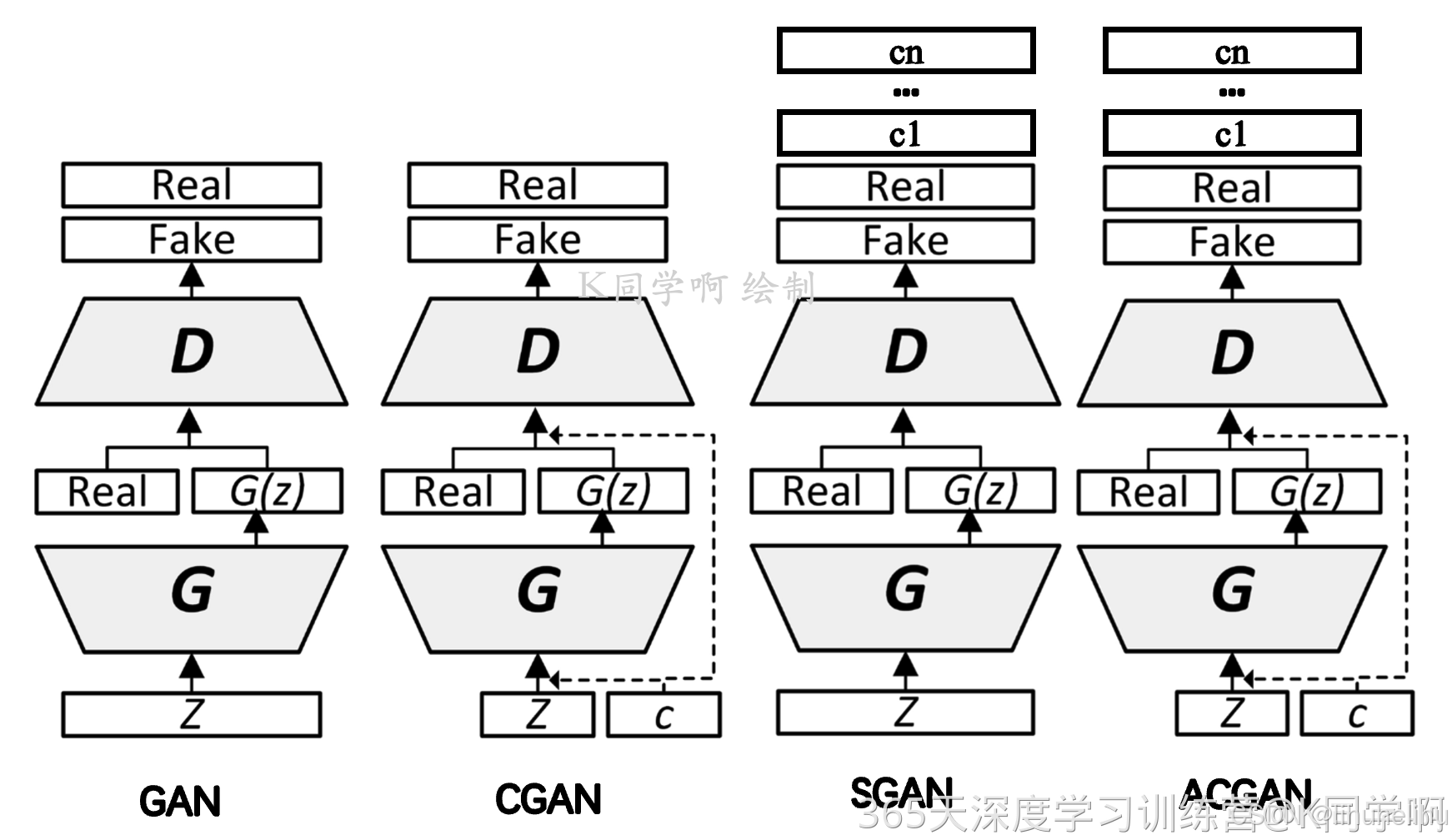
ACGAN的全称Auxiliary Classifier Generative Adversarial Network,翻译成汉语的意思就是带辅助分类器的GAN,ACGAN的原理GAN(CGAN)相似。对于CGAN和ACGAN,生成器输入均为潜在矢量及其标签,输出是属于输入类标签的伪造图像。
对于CGAN,判别器的输入是图像(包含假的或真实的图像)及其标签, 输出是图像属于真实图像的概率。对于ACGAN,判别器的输入是一幅图像,而输出是该图像属于真实图像的概率以及其类别。
图1:
图1是ACGAN的网络结构,可以发现该结构其 实和之前的CGAN和SGAN都非常接近,可以说是两者的结合体。但这样的修改可以有效生成高质量的生成结果,并且使得训练更加稳定
本质上,在CGAN中,向网络提供了标签。在ACGAN中,使用辅助解码器网络重建辅助信息。ACGAN理论认为,强制网络执行其他任务可以提高原始任务的性能。在这种情况下,辅助任务是图像分类。原始任务是生成伪造图像。
二、代码实现
1.导入第三方库
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch
# 创建用于存储生成图像的目录
os.makedirs("images", exist_ok=True)
# 解析命令行参数
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="训练的总轮数")
parser.add_argument("--batch_size", type=int, default=64, help="每个批次的大小")
parser.add_argument("--lr", type=float, default=0.0002, help="Adam优化器的学习率")
parser.add_argument("--b1", type=float, default=0.5, help="Adam优化器的一阶动量衰减")
parser.add_argument("--b2", type=float, default=0.999, help="Adam优化器的二阶动量衰减")
parser.add_argument("--n_cpu", type=int, default=8, help="用于批次生成的CPU线程数")
parser.add_argument("--latent_dim", type=int, default=100, help="潜在空间的维度")
parser.add_argument("--n_classes", type=int, default=10, help="数据集的类别数")
parser.add_argument("--img_size", type=int, default=32, help="每个图像的尺寸")
parser.add_argument("--channels", type=int, default=1, help="图像通道数")
parser.add_argument("--sample_interval", type=int, default=400, help="图像采样间隔")
opt = parser.parse_args()
print(opt)
# 检查是否支持GPU加速
cuda = True if torch.cuda.is_available() else False
2.初始化权重
# 初始化神经网络权重的函数
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
3.构建网络模型
# 生成器网络类
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# 为类别标签创建嵌入层
self.label_emb = nn.Embedding(opt.n_classes, opt.latent_dim)
# 计算上采样前的初始大小
self.init_size = opt.img_size // 4 # Initial size before upsampling
# 第一层线性层
self.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))
# 卷积层块
self.conv_blocks = nn.Sequential(
nn.BatchNorm2d(128),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
nn.Tanh(),
)
def forward(self, noise, labels):
# 将标签嵌入到噪声中
gen_input = torch.mul(self.label_emb(labels), noise)
# 通过第一层线性层
out = self.l1(gen_input)
# 重新整形为合适的形状
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
# 通过卷积层块生成图像
img = self.conv_blocks(out)
return img
# 判别器网络类
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# 定义判别器块的函数
def discriminator_block(in_filters, out_filters, bn=True):
"""返回每个判别器块的层"""
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
return block
# 判别器的卷积层块
self.conv_blocks = nn.Sequential(
*discriminator_block(opt.channels, 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
# 下采样后图像的高度和宽度
ds_size = opt.img_size // 2 ** 4
# 输出层
self.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid())
self.aux_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, opt.n_classes), nn.Softmax())
def forward(self, img):
out = self.conv_blocks(img)
out = out.view(out.shape[0], -1)
validity = self.adv_layer(out)
label = self.aux_layer(out)
return validity, label
4.模型初始化
# 损失函数
adversarial_loss = torch.nn.BCELoss()
auxiliary_loss = torch.nn.CrossEntropyLoss()
# 初始化生成器和判别器
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
auxiliary_loss.cuda()
# 初始化权重
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
5.配置数据集
# 配置数据加载器
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
6.模型训练
# 优化器
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if cuda else torch.LongTensor
# 保存生成图像的函数
def sample_image(n_row, batches_done):
"""保存从0到n_classes的生成数字的图像网格"""
# 采样噪声
z = Variable(FloatTensor(np.random.normal(0, 1, (n_row ** 2, opt.latent_dim))))
# 为n行生成标签从0到n_classes
labels = np.array([num for _ in range(n_row) for num in range(n_row)])
labels = Variable(LongTensor(labels))
gen_imgs = generator(z, labels)
save_image(gen_imgs.data, "images/%d.png" % batches_done, nrow=n_row, normalize=True)
# ----------
# 训练
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, labels) in enumerate(dataloader):
batch_size = imgs.shape[0]
# 真实数据的标签
valid = Variable(FloatTensor(batch_size, 1).fill_(1.0), requires_grad=False)
# 生成数据的标签
fake = Variable(FloatTensor(batch_size, 1).fill_(0.0), requires_grad=False)
# 配置输入
real_imgs = Variable(imgs.type(FloatTensor))
labels = Variable(labels.type(LongTensor))
# -----------------
# 训练生成器
# -----------------
optimizer_G.zero_grad()
# 采样噪声和标签作为生成器的输入
z = Variable(FloatTensor(np.random.normal(0, 1, (batch_size, opt.latent_dim))))
gen_labels = Variable(LongTensor(np.random.randint(0, opt.n_classes, batch_size)))
# 生成一批图像
gen_imgs = generator(z, gen_labels)
# 损失度量生成器的欺骗判别器的能力
validity, pred_label = discriminator(gen_imgs)
g_loss = 0.5 * (adversarial_loss(validity, valid) + auxiliary_loss(pred_label, gen_labels))
g_loss.backward()
optimizer_G.step()
# ---------------------
# 训练判别器
# ---------------------
optimizer_D.zero_grad()
# 真实图像的损失
real_pred, real_aux = discriminator(real_imgs)
d_real_loss = (adversarial_loss(real_pred, valid) + auxiliary_loss(real_aux, labels)) / 2
# 生成图像的损失
fake_pred, fake_aux = discriminator(gen_imgs.detach())
d_fake_loss = (adversarial_loss(fake_pred, fake) + auxiliary_loss(fake_aux, gen_labels)) / 2
# 判别器的总损失
d_loss = (d_real_loss + d_fake_loss) / 2
# 计算判别器的准确率
pred = np.concatenate([real_aux.data.cpu().numpy(), fake_aux.data.cpu().numpy()], axis=0)
gt = np.concatenate([labels.data.cpu().numpy(), gen_labels.data.cpu().numpy()], axis=0)
d_acc = np.mean(np.argmax(pred, axis=1) == gt)
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f, acc: %d%%] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), 100 * d_acc, g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
sample_image(n_row=10, batches_done=batches_done)
上面的代码不适合在jupyter notebook中运行,要在jupyter notebook中运行,把
“1.导入第三方库”的一行代码“opt = parser.parse_args()”修改为“opt = parser.parse_args([])”,就是在小括号中加了“[]”。
根据我的电脑配置,我在“1.导入第三方库”的代码中将一些参数进行了修改,如下:
parser.add_argument("--n_epochs", type=int, default=50, help="训练的总轮数")
将训练的总轮数从200修改为50。
parser.add_argument("--batch_size", type=int, default=20, help="每个批次的大小")
将每个批次的大小从64修改为20。
parser.add_argument("--n_cpu", type=int, default=2, help="用于批次生成的CPU线程数")
将批次生成的CPU线程数从8修改为2。
7.训练结果:
训练到Epoch=25,提示内存不足中断了。
[Epoch 0/50] [Batch 0/3000] [D loss: 1.498029, acc: 12%] [G loss: 1.502995]
[Epoch 0/50] [Batch 1/3000] [D loss: 1.498098, acc: 7%] [G loss: 1.502954]
[Epoch 0/50] [Batch 2/3000] [D loss: 1.498010, acc: 7%] [G loss: 1.502662]
[Epoch 0/50] [Batch 3/3000] [D loss: 1.497425, acc: 17%] [G loss: 1.501645]
[Epoch 0/50] [Batch 4/3000] [D loss: 1.498067, acc: 7%] [G loss: 1.502065]
[Epoch 0/50] [Batch 5/3000] [D loss: 1.497552, acc: 12%] [G loss: 1.501671]
[Epoch 0/50] [Batch 6/3000] [D loss: 1.497572, acc: 20%] [G loss: 1.501391]
[Epoch 0/50] [Batch 7/3000] [D loss: 1.497714, acc: 7%] [G loss: 1.501517]
[Epoch 0/50] [Batch 8/3000] [D loss: 1.497851, acc: 5%] [G loss: 1.501785]
[Epoch 0/50] [Batch 9/3000] [D loss: 1.497713, acc: 12%] [G loss: 1.501432]
[Epoch 0/50] [Batch 10/3000] [D loss: 1.497569, acc: 17%] [G loss: 1.501399]
.
.
.
[Epoch 13/50] [Batch 2355/3000] [D loss: 1.072117, acc: 100%] [G loss: 1.086913]
[Epoch 13/50] [Batch 2356/3000] [D loss: 1.033993, acc: 100%] [G loss: 1.025148]
[Epoch 13/50] [Batch 2357/3000] [D loss: 1.022748, acc: 100%] [G loss: 1.106511]
[Epoch 13/50] [Batch 2358/3000] [D loss: 1.082724, acc: 97%] [G loss: 1.014220]
[Epoch 13/50] [Batch 2359/3000] [D loss: 1.033016, acc: 100%] [G loss: 1.019743]
[Epoch 13/50] [Batch 2360/3000] [D loss: 1.068177, acc: 100%] [G loss: 1.053721]
[Epoch 13/50] [Batch 2361/3000] [D loss: 1.092813, acc: 100%] [G loss: 1.247668]
[Epoch 13/50] [Batch 2362/3000] [D loss: 1.094978, acc: 100%] [G loss: 1.021421]
[Epoch 13/50] [Batch 2363/3000] [D loss: 1.104166, acc: 100%] [G loss: 1.132263]
[Epoch 13/50] [Batch 2364/3000] [D loss: 1.036187, acc: 100%] [G loss: 1.187175]
[Epoch 13/50] [Batch 2365/3000] [D loss: 1.130796, acc: 100%] [G loss: 1.042516]
[Epoch 13/50] [Batch 2366/3000] [D loss: 1.138925, acc: 97%] [G loss: 1.103560]
[Epoch 13/50] [Batch 2367/3000] [D loss: 1.021010, acc: 95%] [G loss: 1.132648]
.
.
.
[Epoch 25/50] [Batch 1144/3000] [D loss: 1.070707, acc: 97%] [G loss: 0.945396]
[Epoch 25/50] [Batch 1145/3000] [D loss: 1.237007, acc: 95%] [G loss: 0.901225]
[Epoch 25/50] [Batch 1146/3000] [D loss: 1.111042, acc: 95%] [G loss: 0.935542]
[Epoch 25/50] [Batch 1147/3000] [D loss: 1.005116, acc: 97%] [G loss: 1.130742]
[Epoch 25/50] [Batch 1148/3000] [D loss: 1.169584, acc: 100%] [G loss: 1.262556]
[Epoch 25/50] [Batch 1149/3000] [D loss: 1.103625, acc: 100%] [G loss: 1.413946]
[Epoch 25/50] [Batch 1150/3000] [D loss: 1.108610, acc: 100%] [G loss: 1.131632]
[Epoch 25/50] [Batch 1151/3000] [D loss: 1.208073, acc: 100%] [G loss: 1.218580]
[Epoch 25/50] [Batch 1152/3000] [D loss: 1.077138, acc: 100%] [G loss: 1.279561]
[Epoch 25/50] [Batch 1153/3000] [D loss: 1.188535, acc: 97%] [G loss: 1.382063]
[Epoch 25/50] [Batch 1154/3000] [D loss: 1.038458, acc: 100%] [G loss: 1.193373]
[Epoch 25/50] [Batch 1155/3000] [D loss: 1.112019, acc: 97%] [G loss: 1.199610]
[Epoch 25/50] [Batch 1156/3000] [D loss: 1.040841, acc: 97%] [G loss: 1.090939]
[Epoch 25/50] [Batch 1157/3000] [D loss: 1.113839, acc: 97%] [G loss: 1.012117]
[Epoch 25/50] [Batch 1158/3000] [D loss: 1.214235, acc: 95%] [G loss: 1.021340]
[Epoch 25/50] [Batch 1159/3000] [D loss: 1.022690, acc: 100%] [G loss: 1.198403]
[Epoch 25/50] [Batch 1160/3000] [D loss: 1.070059, acc: 100%] [G loss: 1.172541]
[Epoch 25/50] [Batch 1161/3000] [D loss: 1.284220, acc: 92%] [G loss: 1.028713]
[Epoch 25/50] [Batch 1162/3000] [D loss: 1.019574, acc: 97%] [G loss: 1.485696]
生成的第一张图像:
生成的第150张图像:
生成的第283张图像(也是最后一张图像):


