第一章 需求分析
现如今阅读、观影、听歌已成为人们日常生活的一部分,每个人手机里或多或少的都有 与这些相关的软件。在每一次的欣赏、聆听的背后,都隐藏着数据的奥秘。比如一部电影每 个评分数量的多少, 反映了大众对于它的直接评价。每年音乐的发行量,反映了彼时音乐创 作人的创作量以及音乐市场的火爆程度。
基于以上认识,本项目旨在分析与电影、图书、音乐有关的数据去了解一部电影、 一首音乐的市场反响,亦或是对多数电影、音乐等综合分析其背后整个市场的情况。因为需 要大量的数据集,由此我们便想到了豆瓣这个平台。
这个平台主要是爬取豆瓣平台的信息,通过对数据的爬取、存储、读取、处理与分 析、可视化等一系列操作,对数据进行了多维度的分析和展示,同时选取了几个热门条目作 为例子,进行单个分析,从中得到了许多有效的信息, 这些信息一方面可以帮助大众更好的 去了解电影、图书、音乐, 另一方面也能够为投资者以及从业者带来便利,更好的为他们展 示哪些是符合当前市场的。很多人在学习中也会进行相关的案例分析,但本项目与其他竞品 有以下区别:
| 本作品 | 其他竞品 | |
| 数据集的获取 | 本项目的数据集均由团队进 行爬取 | 其他竞品中的数据集多来自 于教学团队或他人给予 |
| 数据集的数量以及质量 | 本作品的数据集来自豆瓣相 对于学习案例的数据集更加 丰富且更有实际意义 | 其他竞品中的数据集相对单 一且数据量小 |
| 数据集的分析 | 本作品对数据的分析更加完 整,更加多元化,能够对数 据进行系统的分析 | 其他竞品中的数据分析角度 较单一 |
| 数据分析几个的过程 | 本作品集成了几个步骤为一 体话从数据获取直至数据可 视化自动完成 | 其他竞品中一般为分步骤完 成 |
第二章 概要设计
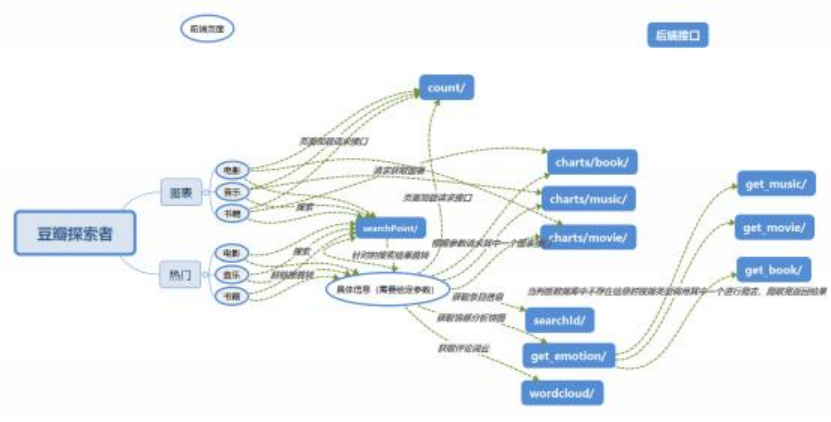
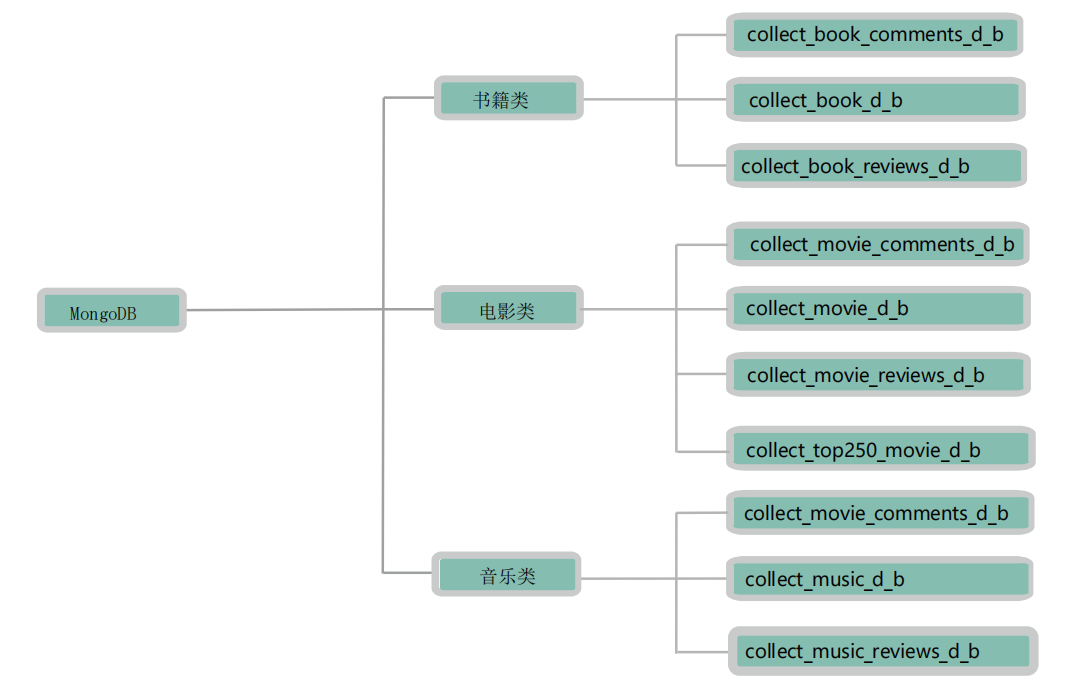
相关调用关系请参考上图,下面为各个文件的介绍。
前端有如下页面:
三个图表页面: index.html(电影) 、chart-2.html(音乐)、chart-3.html(书籍) 三个热门页面: movie.html(电影) 、book.html(书籍) 、music.html(音乐)
一个具体条目信息介绍页面: content.html(具体信息)
后端有如下接口:
| 链接 | 对应文件 | 调用函数 | 用途 |
| count/ | get/count.py | main() | 获取数据库内各个集合的数量 |
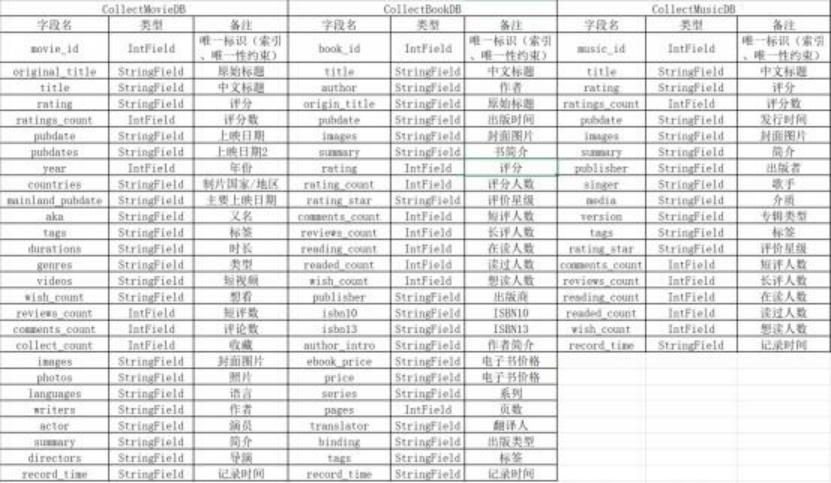
| get/ | collection/g et.py | main() | 采集数据合集, 需给定 id、type |
| get_music/ | collection/g et_music.py | main() | 采集音乐数据, 需给定 id |
| get_movie/ | collection/g et_movie.py | main() | 采集电影数据, 需给定 id |
| get_book/ | collection/g et_book.py | main() | 采集书籍数据, 需给定 id |
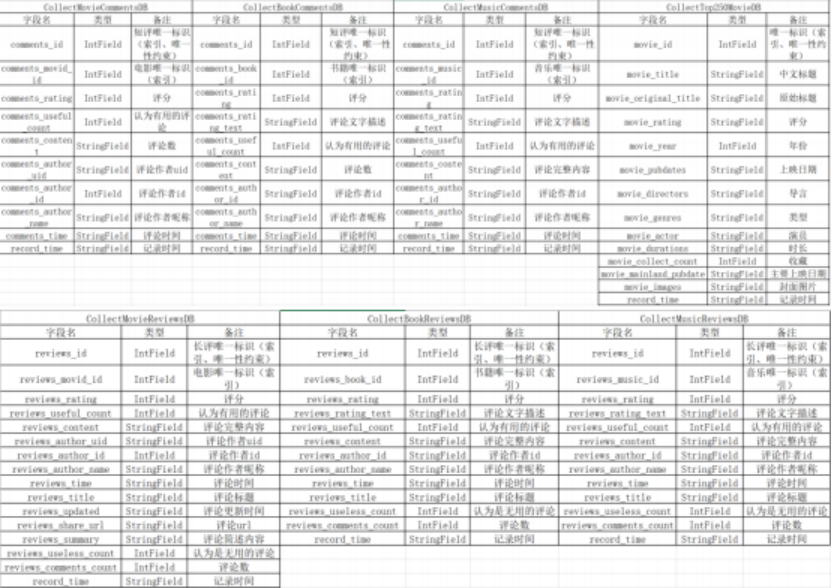
| wordcloud/ | get/wordclou d.py | get_wordcl oud() | 生成评论词云, 需给定 id、type,非必需 nochache 默认为 0 使用 redis 缓存, 为 1 时不使用 redis 缓存 |
| searchPoin t/ | get/search2. py | get_search () | 显示最多 20 条信息,即一次爬取,需给定 q,非必需 cat、start |
| searchId/ | get/search3. py | get_search () | 获取作品信息, 即详情页,需给定 id、 type |
| get_emotio | get/get_emot | ChartView. | 生成情感分析饼图,需给定 id、type、 |
| n/ | ion.py | as_view() | nochache,非必需 n 为 review 个数,默认 1 个 |
| charts/mov ie/ | charts/movie .py | ChartView. as_view() | 生成电影分析图表, 需给定 id、type、 typ,typ 为图表类型, 非必需 num 分析的 数据量,默认为 5000,nochache 默认为 0 使用 redis 缓存,为 1 时不使用 redis 缓 存 |
| charts/boo k/ | charts/book. py | ChartView. as_view() | 生成书籍分析图表, 需给定 id、type、 typ,typ 为图表类型, 非必需 num 分析的 数据量,默认为 5000,nochache 默认为 0 使用 redis 缓存,为 1 时不使用 redis 缓 存 |
| charts/mus ic/ | charts/music .py | ChartView. as_view() | 生成音乐分析图表, 需给定 id、type、 typ,typ 为图表类型, 非必需 num 分析的 数据量,默认为 5000,nochache 默认为 0 使用 redis 缓存,为 1 时不使用 redis 缓 存 |
第三章 详细设计
3.1 界面设计
顶上是项目名以及搜索框,在下面就是各个页面切换的超链接, 中间显示的就是当前 MongoDB 数据库各个集合里所存储的数据量, 每次加载都是实时统计。除了数 据之外,还加了两个按钮, 分别用来调整图表分析的数据量以及重新生成图表,数据 量默认取的是 500 条且为随机取出。
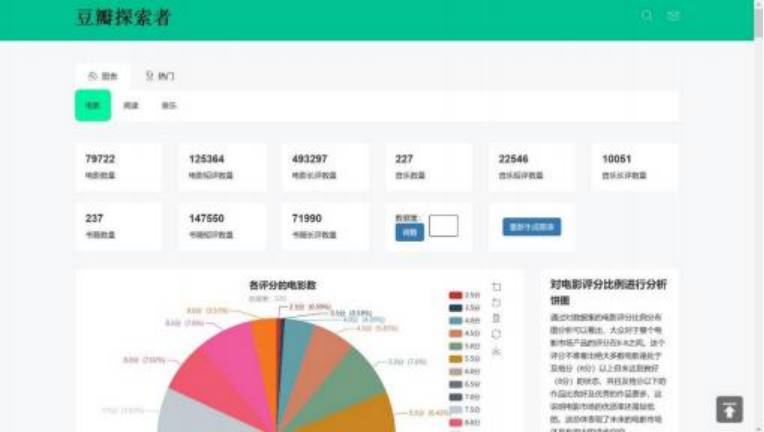
以电影图表最上面的饼图为例,将鼠标放置图表上,也会有具体的信息,右边倒数第二个 Label 可以控制饼图是否显示该数据,最右侧的工具栏也很丰富,缩放工具可以在柱 状图、散点图、折线图中使用, 用查看具体的范围内的数据, 同时还有数据视图功能和图表 下载功能。左下角有页面加载状况,右下角有置顶功能,这两个功能在有图表的页面都会有。
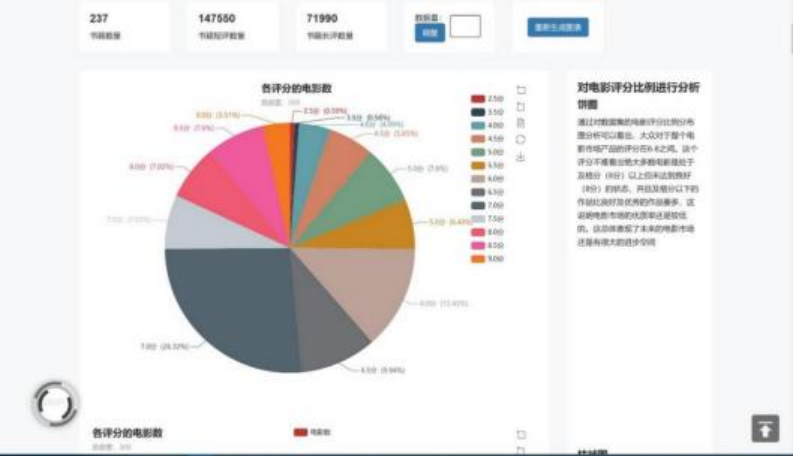
这是电影的热门页面,这类页面由选出的 6 个作为代表展示(可调用豆瓣热门电影 接口获取替换) ,点击单个条目后可跳转到 content.html 具体内容介绍页面。顶上放是点 击搜索按钮后的效果。(每个结果都可跳转到详细内容页面,若跳转过去的是数据库不存在 的条目,那后台将进行自动进行爬取、数据预处理、数据存取等工作, 爬去完成后再读取、 处理和显示图表,爬取的时长由条目评论的数量决定。)
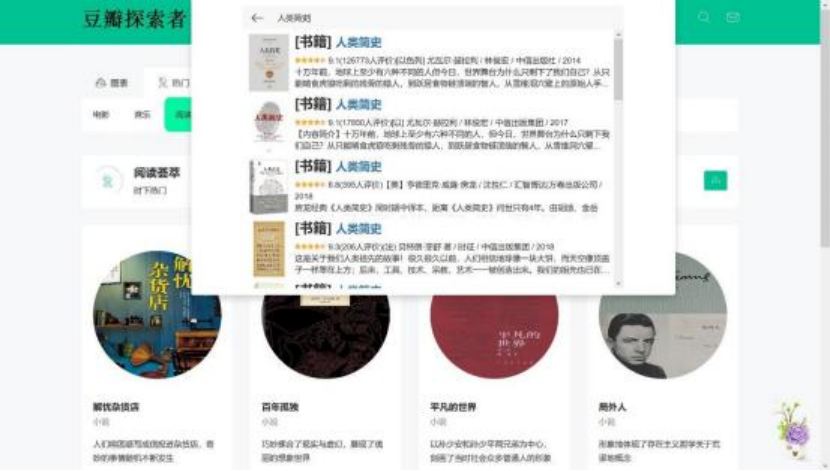
这是详细页面中的上部分内容, 主要为该条目的文字详情信息介绍,在其下面还有五张 针对于该条目所生成的图表。

3.3 关键技术
1) 数据爬取:(重点、难点)
在数据爬取时要不断地完善修改代码,因为代码在初始编写时是针对单个页面来写 的, 能适应单个页面不代表能适应所有类型的页面,因为有些页面即使类别相同,所展示的 内容不同有多有少,就会导致爬取的时候代码出现问题, 因此即使对单个页面的爬取代码也 要反复修改多次,来不断能完善。在爬取的代码中,同时也为了防止被豆瓣的反爬机制 所屏蔽而加入了相关代码,但也相应的造成了爬取时间的延长。
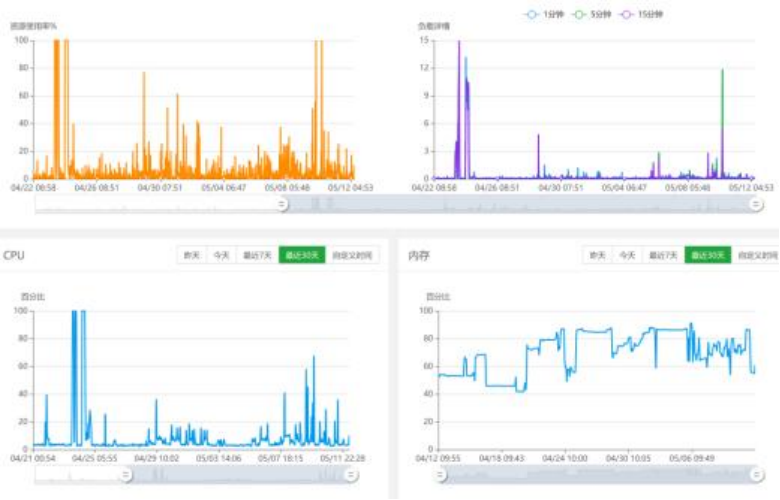
2) 数据存储查询优化:(重点、难点)
为了证明数据存取优化的重要性,下面放了一张在服务器上爬取的几个时间节点的资源消耗图。最左边的一段峰值点时段就是使用未优化过的查询语句所造成的。在完成语 句的优化后,后几次爬取就未达到如此之高。
3) 数据处理:(重点、难点)
因为不知道数据库里所存储的是否符合所要数据的规范,任何类型的数据都会出现,以及是否有对异常值等,所以在提取出数据后, 还需要对其再做相关的处理, 如对数据缺失、极端值、数据格式不统一等问题进行处理。(下图就是其中的一个数据处理的例子)
4) 图表展示和分析:(重点、难点)
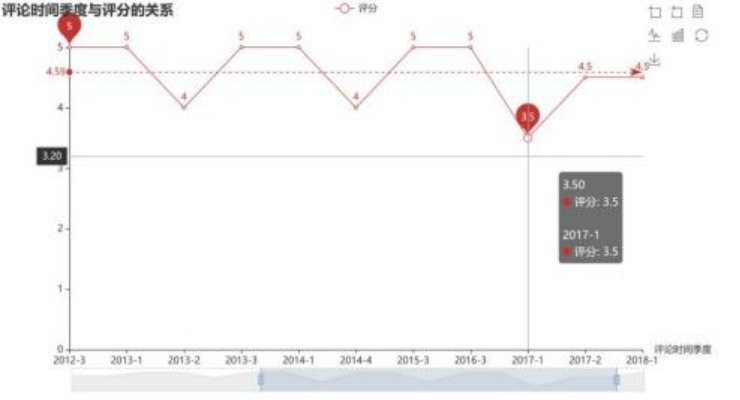
选取完要分析的数据关系后, 就该选择合适的图表来进行输出表示,确定好图表后,还要考虑图表的展现形式, 包括图表中的工具配置等,同时还要对图表进行分析。(下图就是其中的一个数据可视化的例子)

5) Redis 缓存技术:(重点)
一开始在访问网站时,每次生成图表都要再次进行读数据、分析处理数据,这不仅大大 增加了对服务器的性能压力, 同时也加慢了网页的加载速度,由此,选择了 Redis,当图表第一次生成就让 Redis 存储其结果 24 小时,第二次在访问时就可以直接从 Redis 中获取结 果,省去了再次进行读数据、分析处理数据的过程,很好的解决的上述的两个问题。
6) 前端图表的链式调用:(重点)
考虑到如果一加载页面,就一下子请求所有图表,那会对服务器一下子产生很大的压力, 容易出错。所以我们想到了使用链式请求的方法, 一个一个请求图表, 且同时加上 loading 的动态效果,表名当前页面的图表加载状况。
第四章 测试报告
4.1 系统测试的主要内容
为了确保测试的质量,系统多次进行了软件测试, 主要包括代码审阅、模块测试、功能 测试、安全性测试等内容。
代码审阅:在系统实现完成以后,应先对代码的规范性进行检测,并且测试代码的语法 逻辑问题, 保证系统能正常运行。
模块测试: 对系统的主页模块, 页面跳转,搜索框,图表等模块进行测试, 确保其工作 正常。
主要测试过程: 模拟用户访问页面, 不断点击跳转页面; 模拟用户查找特定案例, 进行 搜索框搜索;模拟用户查看数据图表。
测试结果: 页面能正常跳转、搜索功能可以正常使用。词云模块图表展示不正常, 请求 本地时正常。
修正过程: 因为服务器处理数据能力有限,当前条件下在打开相关页面后修改代码可以 达到展示效果。在条件成熟后会选择升级服务器。
4.2 系统模块测试
系统模块测试主要是对系统中各个功能模块进行详细的测试工作,发现问题并处理问题。 测试工作是通过手动反复对系统进行操作,观察系统运行的结果,判断该功能模块是否达到 应用要求。具体测试如下表所示:
表 5-1 系统模块测试表
| 测试内容 | 测试方法 | 预期结果 | 测试情况 |
| 主页测试 | 打开 index 主页面 | 打开成功 | 通过 |
| 页面跳转 | 在页面上点击所有具有链接功 能的模块 | 所有页面都能成功跳转 | 通过 |
| 搜索框 | 在搜索框内输入想要查询的电 影、音乐或图书 | 若查询内容存在数据集内或有与查 找内容相近内容则显示相应选项, 若没有匹配数据则不显示 | 通过 |
| 图表 | 将鼠标放在图标表上,并在具 有缩放功能的图标上使用用鼠 标滚轮或点击图表内缩放功能 | 显示鼠标停放位置所对应的相应信 息,三维立体图以及具有缩放功能 的图表能正常缩放 | 通过 |
4.3 系统测试
模块测试的完成只是保证了模块的正常工作,无法保证整个整体工作是否能够正常的运 行。所以在模块测试完成以后, 要进行系统完整的用例测试, 来验证系统是否运行正常。
本系统为基于 Window 10 平台, 系统设计分为四部分。测试过程中首先测试主页面展 示, 确保主页面模块可以正确打开并展示相关内容。然后测试页面跳转模块,能保证页面之 间能够互相跳转。然后测试搜索框模块,确保能够进行精确定位查询, 展示用户所需要查找 的内容。最后测试图表模块, 确保图表能正常显示,以及图表内某一块内容能够展示其独有 的信息。若图表具有缩放功能,测试其能够利用缩放功能对图表的整体或局部内容进行查看。 如果四个模块均正常运行,说明该系统均已正常工作。
4.4 技术指标
通过测试发现,本系统因图表展示较多,运行速度相对较慢达到 6.5s。因为本系统数 据来源为豆瓣,因此数据安全性较高。在系统初期阶段没有上线用户登录注册功能,因此没 有账号安全性的威胁。系统扩展性较强,耦合性较低内聚性较强。本系统的部署非常简单, 方便性极强。可用性很强。
第五章 安装及使用
5.1 安装环境要求
操作系统: Windows 10 或 Centos 7
应用软件环境: Python 3.6 及以上、 Redis、MongoDB(后两个可根据需要搭建)
浏览器:Chrome 或 Firefox
5.2 Python3.7 安装
(注: 以下安装过程皆为 Windows 下的, 如需 Linux 安装教程,请咨询相关服务人员) 去官网下载安装包, 下载链接: Python Releases for Windows | Python.org
进入下载链接后选择对应的版本下载
①点击 customize installation。(自定义安装路径),也可以选择 Install Now 选择默认 路径安装
②勾选 add python 3.7 to PATH(这样可以避免安装后,还要手动去配置 python 的环境变 量)
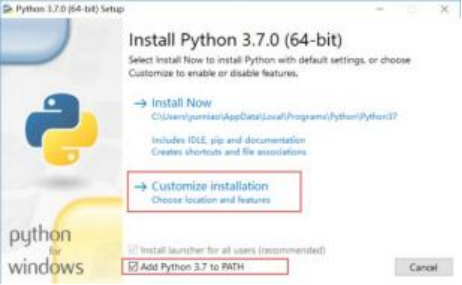
后续操作默认即可, 安装完成, 点击 close 按钮
win+r,录入 cmd,进入如下窗口,录入: python,点击 enter,出现如下内容,则为安 装成功。
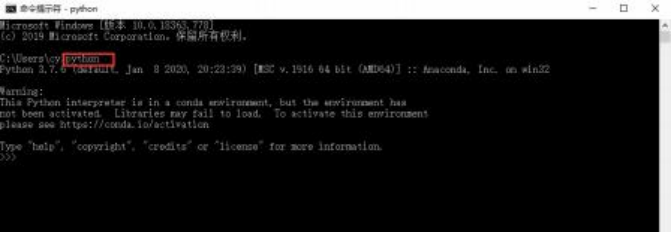
5.3 启动服务
...
...
...
完整方案及学习源码地址:基于Python的BeautifulSoup库爬取电影、图书、音乐数据的数据分析系统源码+文档.zip资源-CSDN文库