版本共存
文件上传
日志
docker
pm2
pm2解决问题:
在生产环境上,一般不会直接启动node应用,而是通过pm2来跑。
如果你的node应用突然报错,是否需要重新跑起来?这时候就需要一个进程来自动做重启这个事情。
还有,获取node应用写日志到文件,监控cpu,内存等资源,也可以用另一个进程来做
线上的node应用不只是跑起来就行,而是需要做自动重启,日志,多进程,监控这些事情。(现在有些用k8s+docker来搭建服务,pm2用的少了,pod可以通过一些探针来判断该服务是否健康,不健康就会进行重启。)
pm2主要功能:进程管理,日志管理,负债均衡,性能监控等
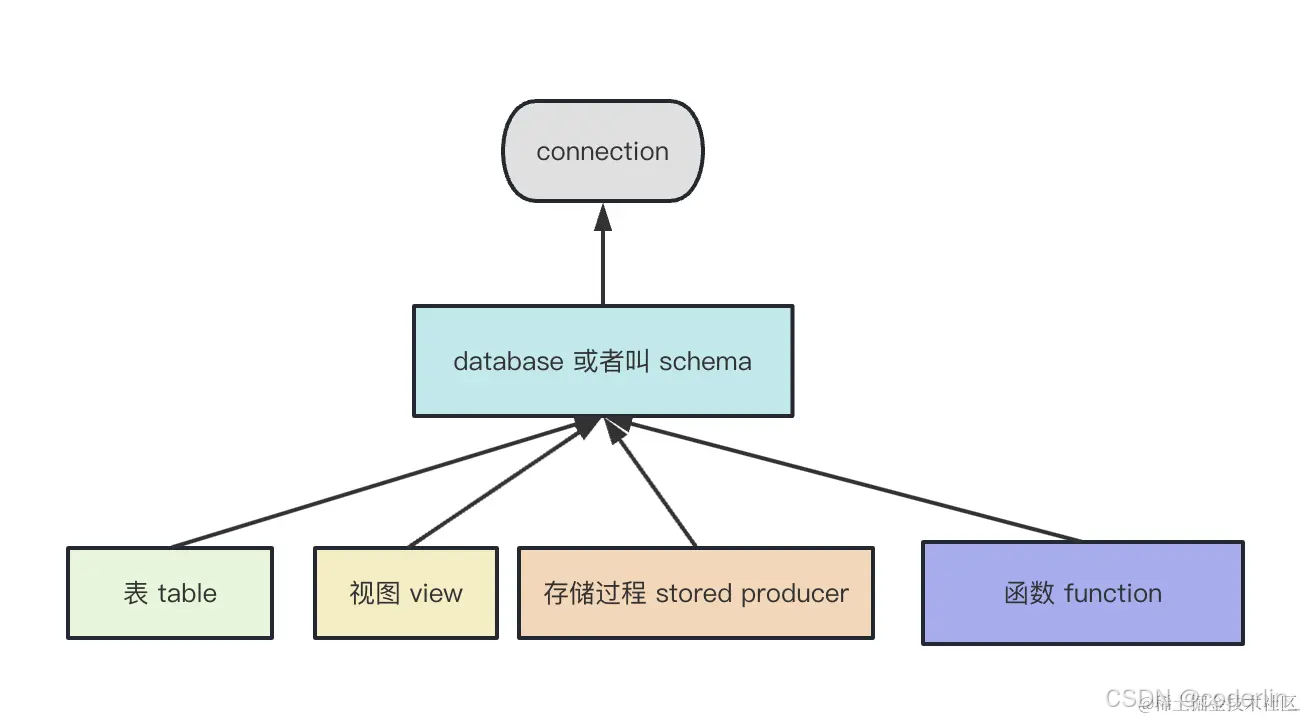
mysql
mysql分为后台守护进程和客户端两方面。
DDL(data definition language): 创建数据库,创建表等修改结构的sql
DML(data manipulate language): 增删改 sql
DQL(data query language): 查询sql
查询语句
- where 查询条件:比如where id = 1
- as:别名,比如select xx as xx;
- and 连接多个条件
- int/not in 集合查找,比如 where a in (1,2)
- between and 区间查找,比如 where a between 1 and 10
- limit 分页 limit 0, 5
- order by 升序,order by a desc, b asc a降序,相等则判断b升序
- group by 分组
- having 分组后再过滤,group b aaa having xx > 5
- distinct 去重
内置函数
- 聚合函数:avg count sum min max
- …
join查询
级联查询:
select * from a join b on a.id = b.a_id
多表关联查询。
如果查出来的字段一样,可以用别名
select a.id, a.name, b.id as b_id, b.name as b_name from user join b on a.id = b.id
查出来应该是
| id | name | b_id | b_name |
|---|---|---|---|
| 1 | a的name | 1 | b的name |
默认的join on 就是inner join on,只返回两个表中能关联上的数据。
还有其他两种类型,left join, right join
left join
左联查询,额外返回左表中没有关联上的数据
right join
右联查询,额外返回右表中没有关联的数据
在from后说的是左表,join后的是右表。比如
select a.id, a.name, b.id as b_id, b.name as b_name from user left join b on a.id = b.id
| id | name | b_id | b_name |
|---|---|---|---|
| 1 | a的name | 1 | b的name |
| 2 | a的name | 2 | b的name |
| 3 | a的name | null | null |
如上,多返回了a表的数据,b表中没有关联的数据信息为null。
使用right join的时候,则相反
一般情况下,用默认的join on较多,也就是inner join
一对多,多对多的表设计
一对一,一对多,都是在多的一方添加外键来引用另一方的id。
多对多的话,我们需要多一张表来记录他们的关系,比如
- a表 a.id a.name
- b表 b.id b.name
- c表. c.id. a_id, b_id
c表用来记录a和b的关联关系。
当有三个表的时候怎么查询呢,join三个表。
select * from a join c on a.id = c.a_id
join b on b.id = c.b_id
where a.id = 1
子查询
假设有个班级表,里面记录着学生的信息+成绩,当我们想查询最高分的那个学生的信息的时候。一般需要
select max(score) from student
得到最高分,再
select name, class from student where score = 95
怎么把两个sql合并呢,就是子查询。
select name, class from student where score = (select MAX(score) from student)
又或者查询成绩高于全校平均成绩的学生
select * from student where score > (select AVG(score) from student)
此外,子查询还有特殊的语法,exists和 not exists
假设有个员工表+部门表
select name from department where EXISTS (select * from employee where department.id = employee.deparament_id)
对于每个department,在子查询里面查询他所有的员工,存在员工,EXISTS成立,返回这个部门的name。这就是EXISTS的作用,子查询返回结果,条件就成立,反之不成立。
此外,子查询还能用于insert update delete语句,如
insert into c (name, price) select name AVG(price) from a group by name
将a中的产品分类和平均价格查询来,插入到c表。
想在员工表里面,为技术部的人的name加技术-,可以
update employee set name = concat('技术-', name) where departmend_id = (select id from deparment where name = '技术部')
- sql和sql组合完成更复杂的功能,这种语法叫做子查询。
- 此外还有关键字EXISTS NOT EXISTS,判断条件成立。
- 子查询还能用于delete update insert等
事务和隔离级别
做多个增删改的时候,可能会有些sql执行成功,有些sql执行失败,这样就需要事务了,开启事务后,除非commit,否则都可以回滚,当发现有些sql执行失败后,就可以执行回滚操作。
语法是:
start transaction开启事务
rollback 回滚事务
commit 提交事务
savepoint 节点位置
事务隔离级别:
- READ UNCOMMITTED:可以读到别的事务尚未提交的数据。
- READ COMMITTED:只读取别的事务已提交的数据。
- REPEATABLE READ:在同一事务内,多次读取数据将保证结果相同。
- SERIALIZABLE:在同一时间只允许一个事务修改数据。
Typeorm
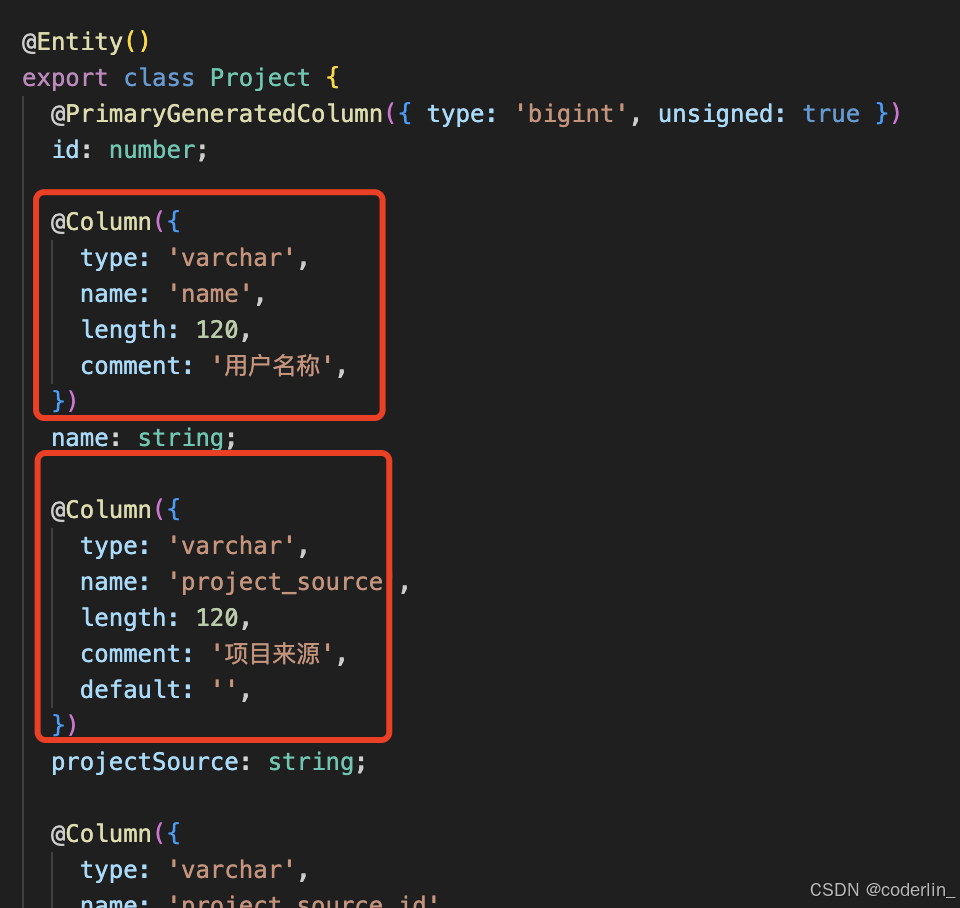
ORM: Object realtion mapping 对象关系映射,将关系型数据库的表映射成面向对象的class,表的字段映射成对象的属性映射,表于表的关联映射成属性的关联。在node中,有一个很流行的ORM框架:TypeORM。
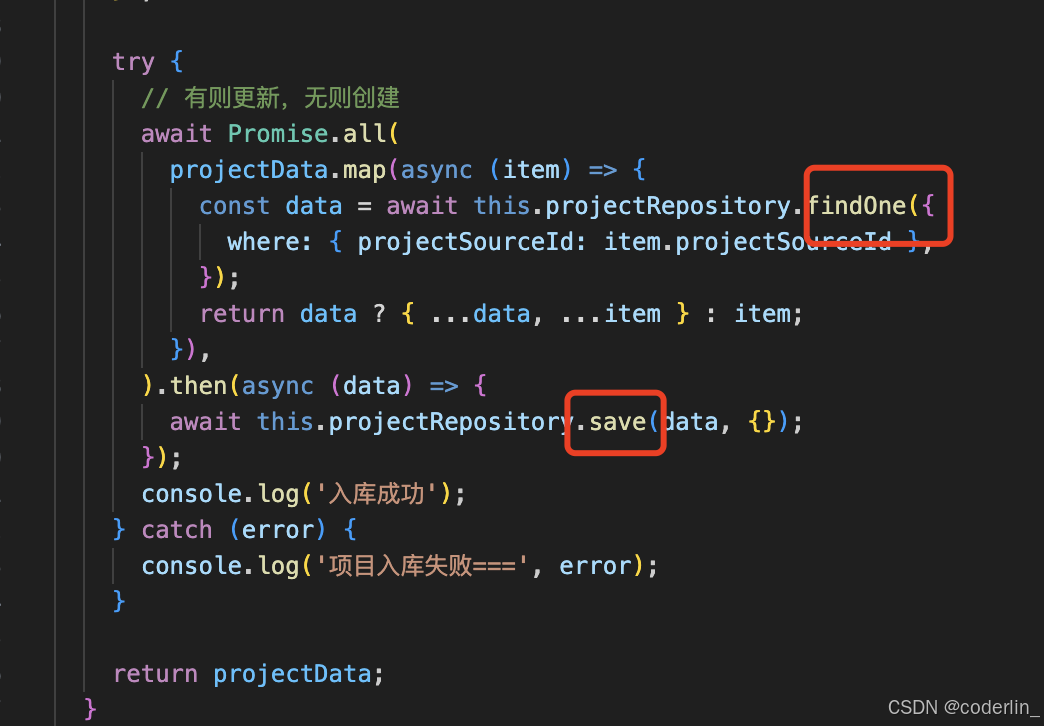
它是机遇class和class上的装饰器来声明和表的映射关系,然后对表的增删改查就变成了对象的操作以及save, find,等方法的调用,会自动生成sql。
如
Typeorm的流程
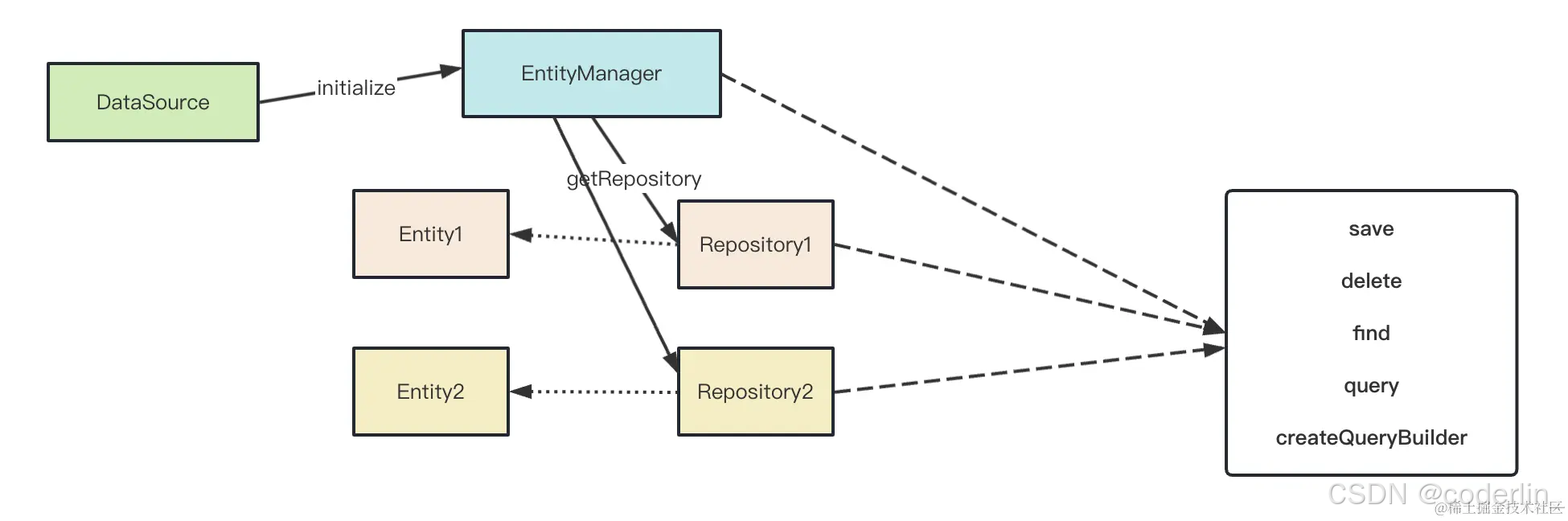
- Datasource管理者数据库连接的配置,数据库驱动包,调用他的initalize方法回创建和mysql的链接,如果制定了sunchronize,会根据传入的Entity生成建表sql。
- Entity通过@Entity指定和数据库表的映射,通过@Column,@PrimaryGeneratedCokumn指定表的字段的映射。
- 对Entity方法做增删改查,typeorm封装了save,delete,find等方法。
- 复杂的sql可以通过createQueryBuilder等方法创建。比如join等。
具体的 EntityManager 和 Repository 的方法有这些:
save:新增或者修改 Entity,如果传入了 id 会先 select 再决定修改还新增
update:直接修改 Entity,不会先 select
insert:直接插入 Entity
delete:删除 Entity,通过 id
remove:删除 Entity,通过对象
find:查找多条记录,可以指定 where、order by 等条件
findBy:查找多条记录,第二个参数直接指定 where 条件,更简便一点
findAndCount:查找多条记录,并返回总数量
findByAndCount:根据条件查找多条记录,并返回总数量
findOne:查找单条记录,可以指定 where、order by 等条件
findOneBy:查找单条记录,第二个参数直接指定 where 条件,更简便一点
findOneOrFail:查找失败会抛 EntityNotFoundError 的异常
query:直接执行 sql 语句
createQueryBuilder:创建复杂 sql 语句,比如 join 多个 Entity 的查询
transaction:包裹一层事务的 sql
getRepository:拿到对单个 Entity 操作的类,方法同 EntityManager
Nest使用typeorm
将typeorm的api封装一层,变成typeormModule。
首先需要传入一系列全局的配置,所以这个是动态模块。
动态模块三种命名规范:register, forRoot, forFeature
这里明显需要使用forRoot,只需要注册一次,这个模块可以在各处被使用。所以
@Module({
imports: [
// 引用依赖的模块,通过imports引用后,对应模块的exports可以在当前module中的Service中注入,而不用声明providers
CacheModule.register({
isGlobal: true,
}),
// 动态模块
TypeOrmModule.forRoot({
type: 'mysql',
host: Context.mySql.host,
port: Context.mySql.port,
username: Context.mySql.username,
password: Context.mySql.password,
database: Context.mySql.database,
entities: [__dirname + '/**/*.entity{.ts,.js}'],
synchronize: false,
}),
forwardRef(() => UserModule),
GithubModule,
WeichatModule,
]
})
export class AppModule {}
在根模块配置,内部会根据传入的配置来创建DataSoruce,调用intialize方法,之后就可以拿到EntityManager,做CRUD操作。
那怎么在对应的模块中通过对应的Repository来CRUD呢?
可以先注入EntityManager,再通过EntityManager.getRepository(xxEntity)来获取。
比如
@Injectable()
export class UserService {
@InjectEntityManager()
private manager: EntityManager;
constructor() {
this.userRepository1 = this.manager.getRepository(User)
}
」
如上,通过typeorm提供的EntityManager,可以拿到对应的Repository;
也可以通过动态模块,传入xxEntity,返回Repository。
像这种局部的动态模块,一般是用forFeature。
比如
@Module({
// 配置局部的属性,这里的module依然是app module定义的,exports里面包含UserRepository,所以才能在user.service里面使用
imports: [TypeOrmModule.forFeature([User])],
controllers: [UserController],
providers: [UserService, Response],
})
export class UserModule {}
在UserModule使用TypeOrmModule.forFeature,传入UserEnttiy,这个模块返回
根据传入的entity,返回一个定义好的模块,exports里面就包含我们需要的Repository,所以我们可以直接在serivce里面
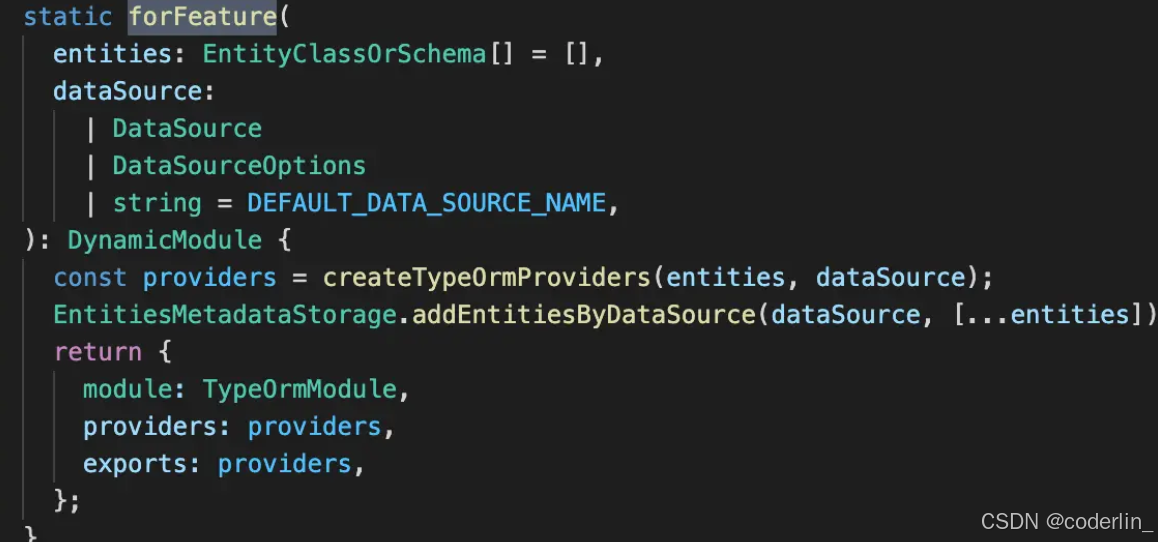
constructor(
@InjectRepository(User)
private UserRepository: Repository<User>,
) {
this.jwtService = jwt;
//this.userRepository1 = this.manager.getRepository(User);
}
通过构造器参数注入或者通过属性注入都行,拿到对应的UserRepository,这个方法只可以修改当前指定的Entity。
此外还能注入dataSource来获取,当然不常用这个。
这个就是Nest集成TypeOrm的方式。
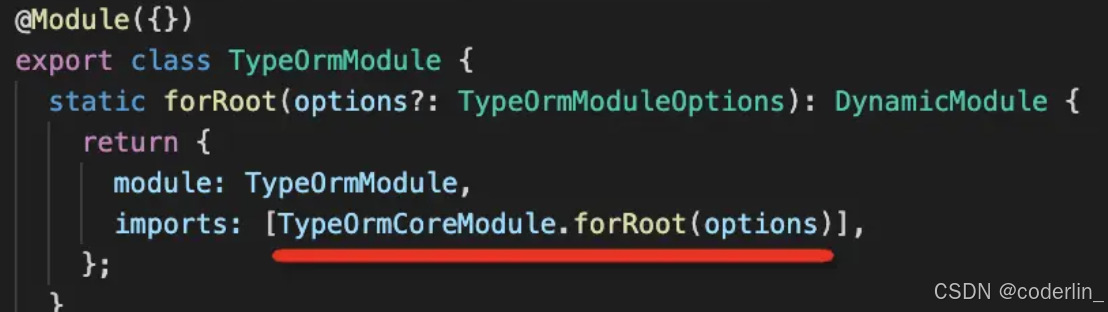
TypeOrm封装了TypeormModule模块,通过forRoot注入配置,通过Feture来获取局部模块的配置,进而得到Resiporty来CRUD。
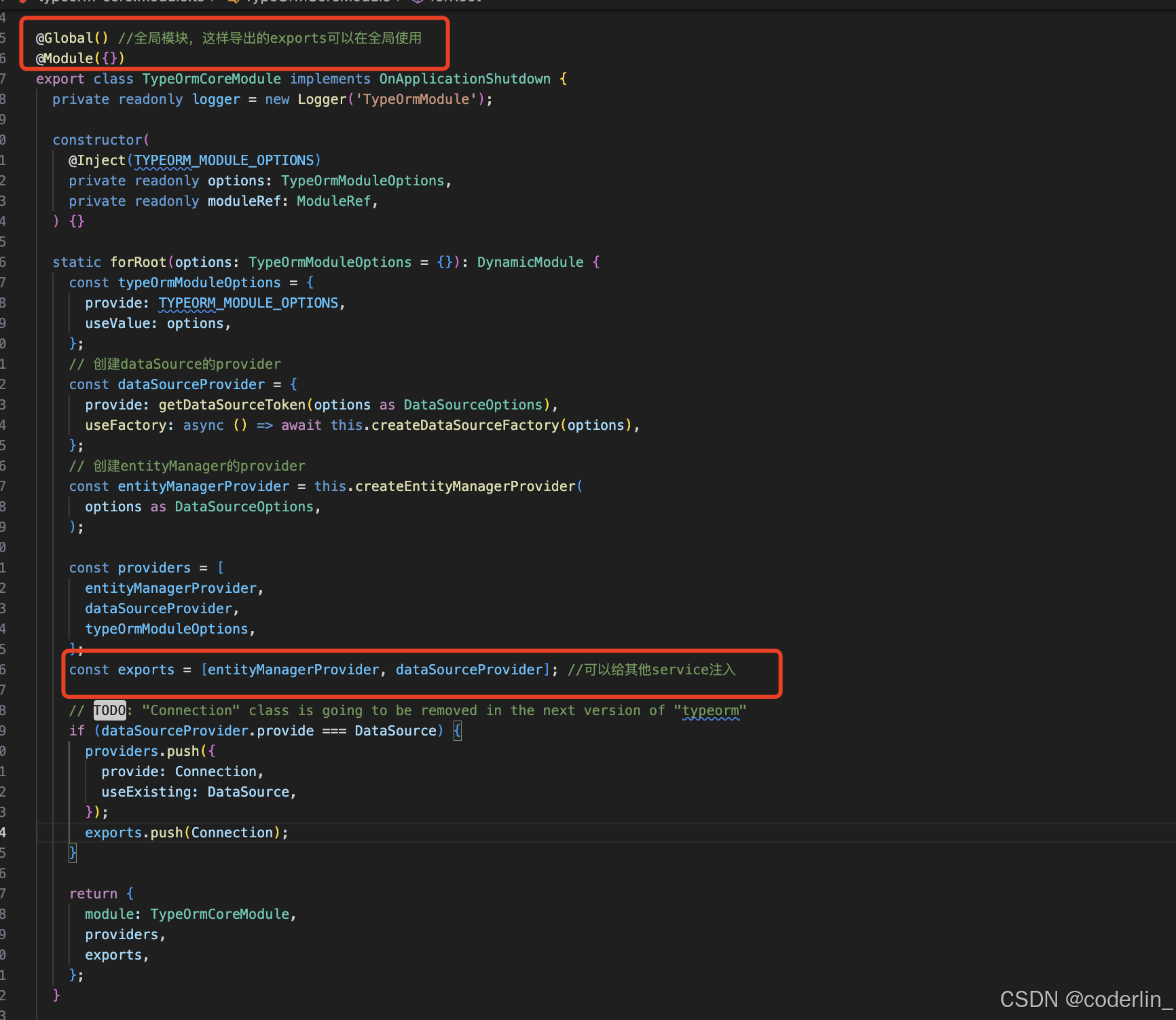
源码实现:
通过TypeOrmModule引入动态模块的时候
根据options创建DataSource和EntityManager,将其放到模块的provider里面,并且放到了exports,而且使用@Global装饰全局模块,因此,dataSource和EntityManager可以在全局任意地方使用。
创建Datasource就是调用initlize方法。
创建entityManager
直接注入dataSource取manager属性。
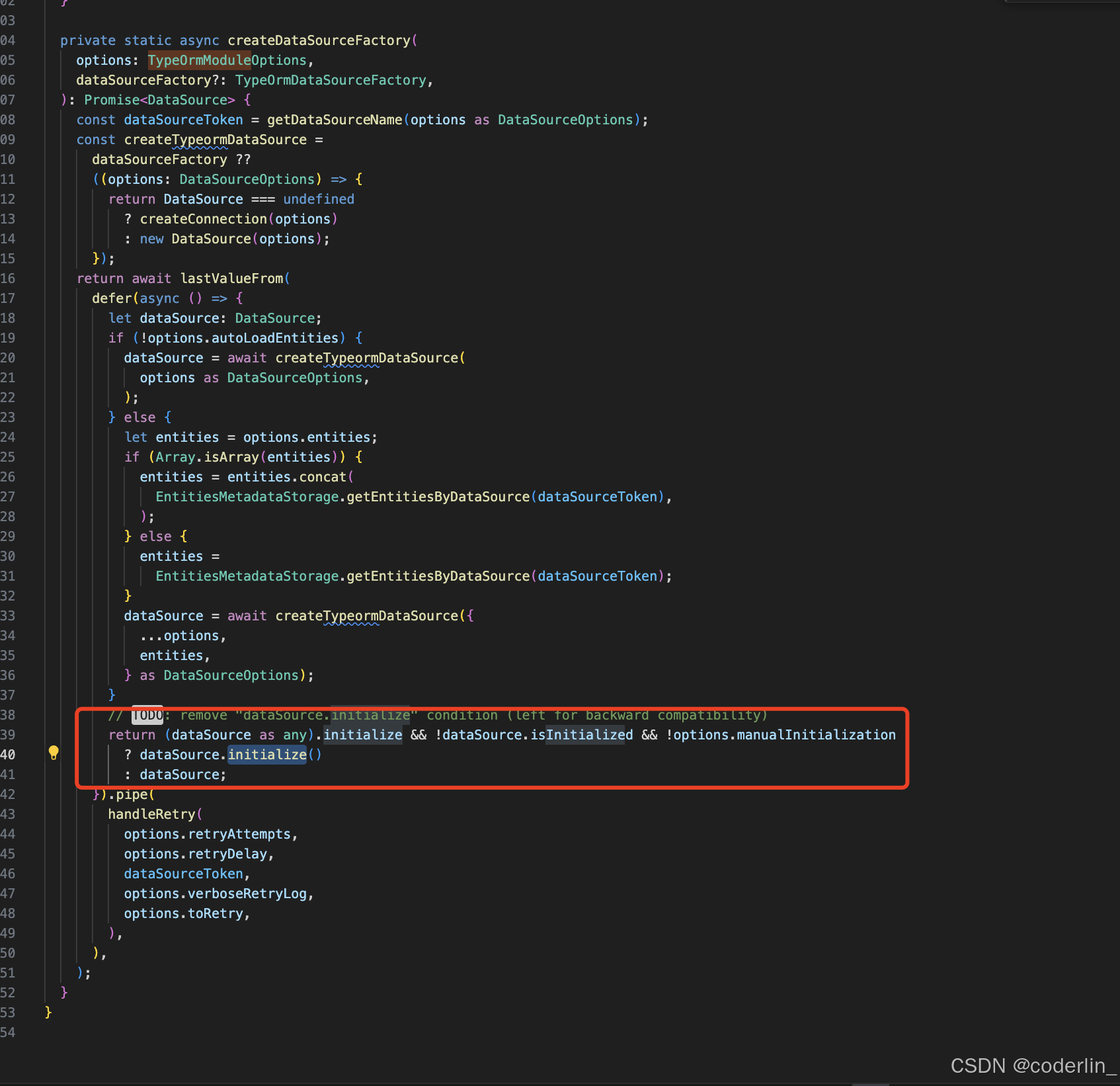
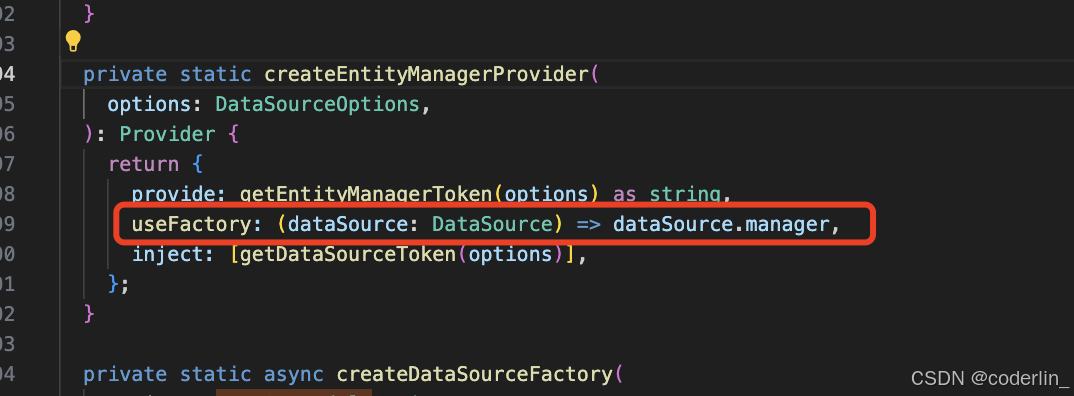
看下注入局部entity的使用
TypeormModule.forFeature([User])
内部也是通过注入Datasource来获取对应的Repository。
这样引入TypeormModule.forFeature就可以使用对应的Repository了。
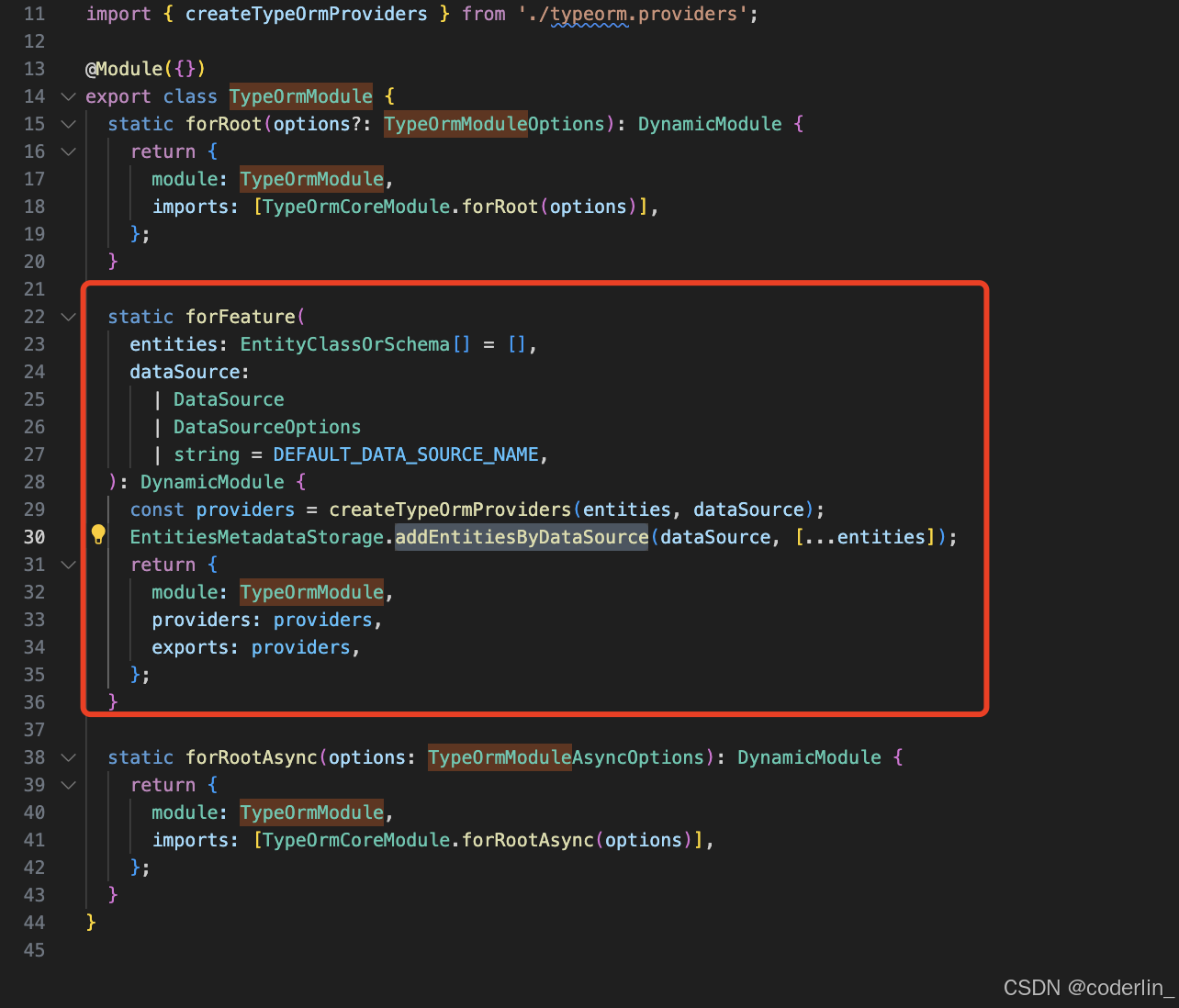
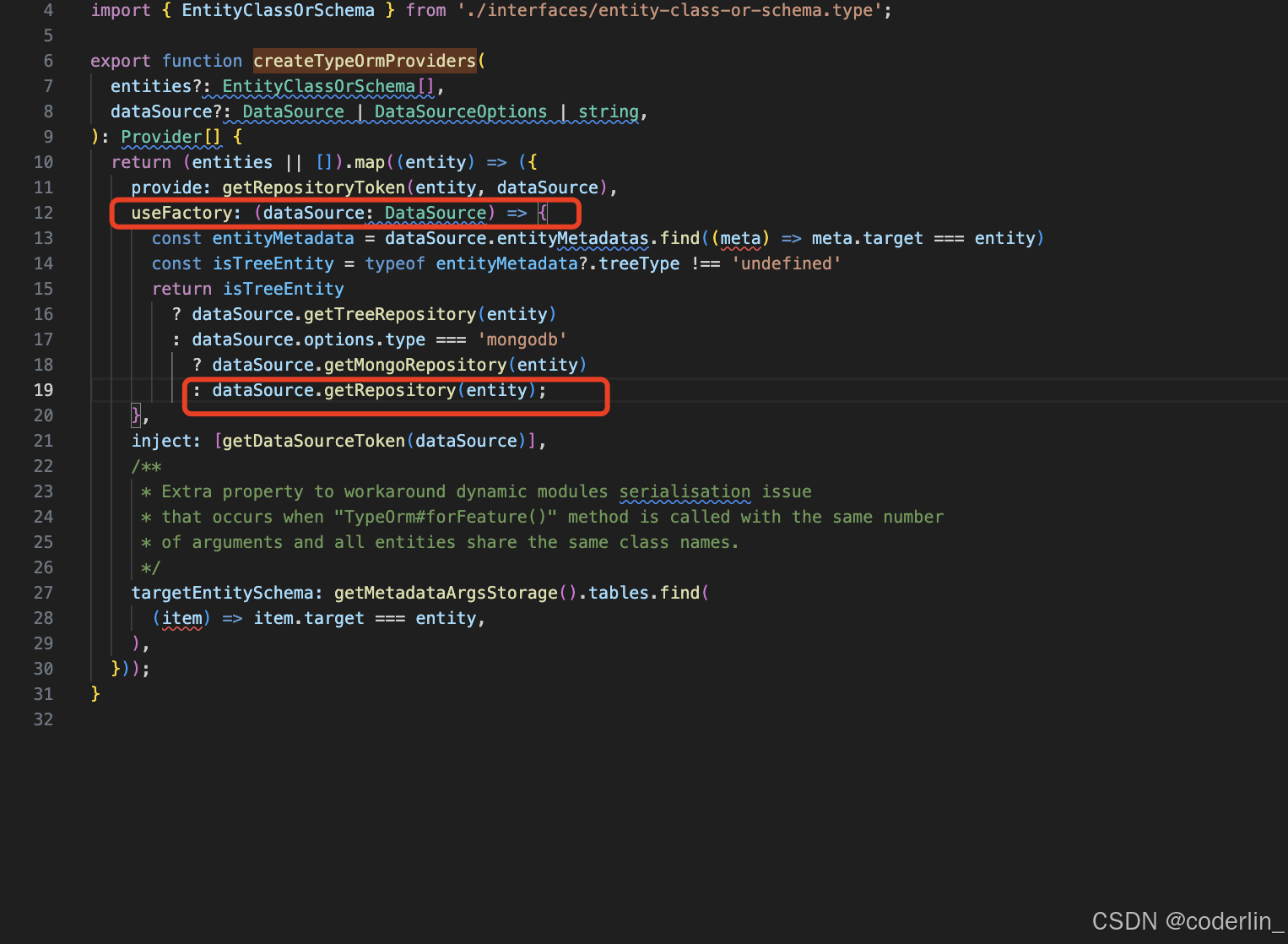
总结
- 在nest中使用typeOrm,可以使用TypeOrmModule,它是对typeOrm的api做一层封装
-
- 用法就是在根模块使用TypeOrmMoudle.forRoot传入数据源配置,他会返回Global的模块定义,还有创建好DataSource和EntityManager作为exports导出
- 因为是全局模块,所以可以在全局任意地方注入DataSource和EntityManager。
- 如果想简化操作,可以使用TypeOrmModule.forFeature来传入对应的entity,内部也是通过注入DataSource来获取对应的Respository,作为exports导出,所以在对应的Service里面可以直接注入Respoitory使用。
TypeORM保存任意层级的关系
有一些树级的数据,比如分类,一级分类,二级分类,保存的时候我们是将数据平铺,通过一张表保存所有数据,然后通过parentId绑定对应的关系
nest中使用redis
mysql通过硬盘存储信息,解析执行sql语句,这些会成为他的性能瓶颈。
redis: 将数据缓存到内存,读取会很快。redis的设计就是key value键值对的形式,并且值的类型有很多,比如字符串,list, set, sortedset, hash等。
nest也提供了一个cache- manager来做一个缓存(也是内存缓存),为什么不用cache-manager而是用redis呢。
cacheManager只提供了set和get方法,而redis提供了list hash zset等数据结构的支持,如果使用cacheManager,要使用这些还需要自己封装。
session+cookie vs jwt
session+cookie
服务端存储session信息,浏览器每次请求默认带上cookie,通过cookie里面的信息判断当前用户是否登陆。
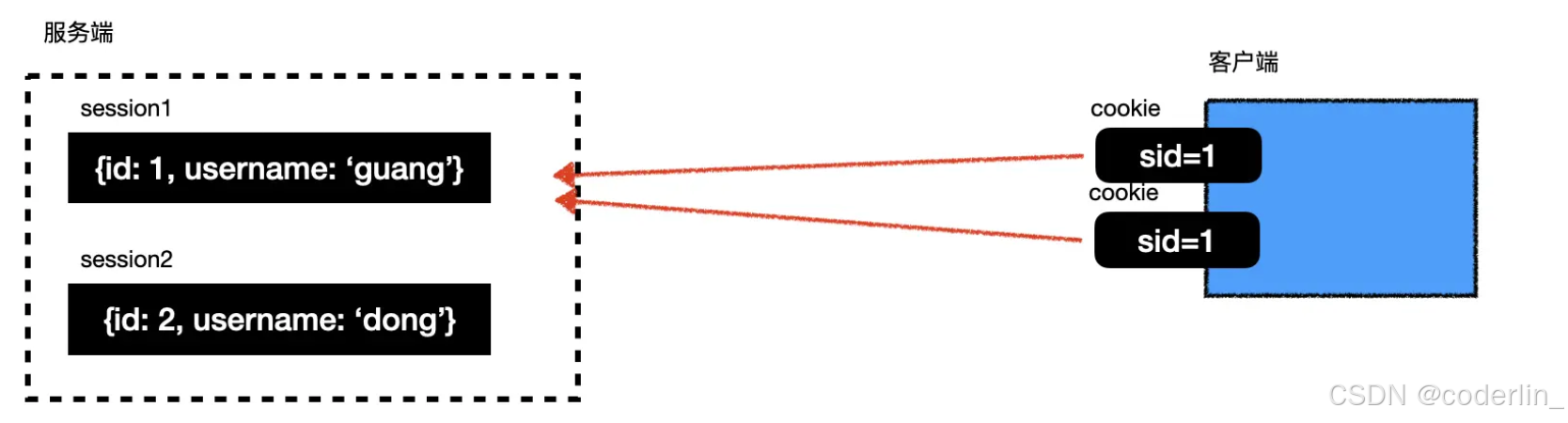
缺陷:
- csrf(跨站请求伪造),当你登陆了一个正常网站abc.cn后,这时候你的浏览器有了对应的cookie,这时你去访问一个钓鱼网站,他会模拟请求触发请求abc.cn,这时候会携带cookie过去,就导致正常的网站认为这是一次正常的请求,从而造成一些问题。为了解决这个问题,一般我们会校验referer,判断请求是哪个网站发起的,但referer也是能伪造的,所以一般都会用一个随机值,每次请求都返回一个随机值,下次带上的时候如果不对,就认为是非法的。
- 分布式session,多服务器的时候,session需要共享。(session复制/存储在redis,每次都去redsi查询)
- 跨于问题,cookie有domain闲置,万一是跨域的请求,cookie就无效了
jwt (json web token)
三部分组成:header+payload+verfiry signature(用header+payload+salt做加密后生成的,salt一般是一个字符串,增加随机性)
服务器不存储用户信息,把用户信息封装成token返回给前端,由前端每次请求的时候主动带在header。
服务器只需要拿到token后,根据header的算法,对header+payload+salt再做一次加密,如果跟verify signature一样,就表示有效,把状态数据都存在payload部分。
这种方式没有cookie哪些问题比如:
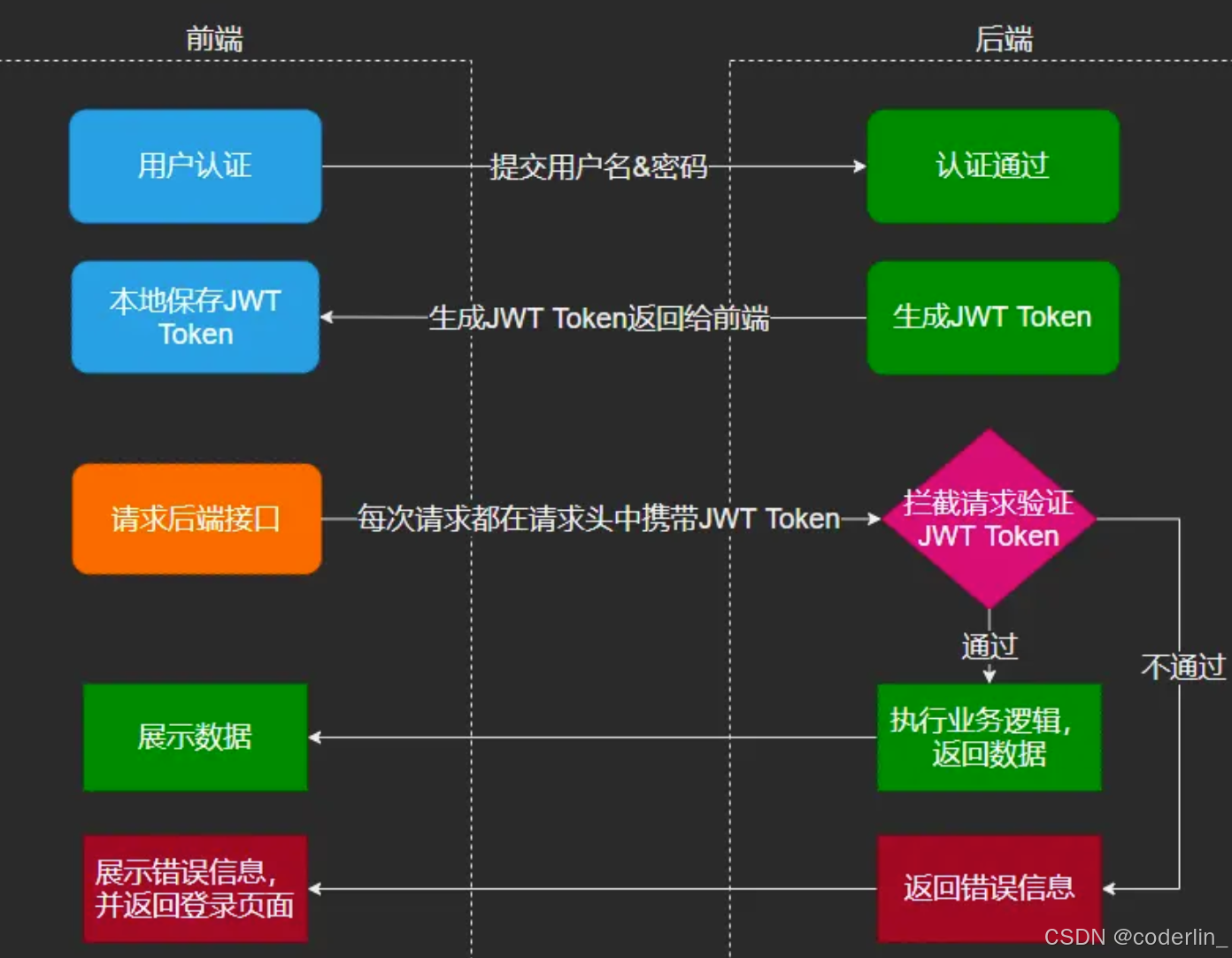
- csrf,token是主动带的,不存在scrf问题。
- 分布式session: 状态保存在客户端
- 跨域:不是cookie,没有跨于问题
缺陷:
- 用户信息通过base64放在了header里,容易泄漏,一般搭配https用,让别人拿不到header
- 性能:数据变多,性能变差。
- 没法让jwt失效,session存在服务端,所以可以随时让他失效,jwt不是,保存在客户端,但可以通过redis来处理,通过redis查询jwt是否可用。
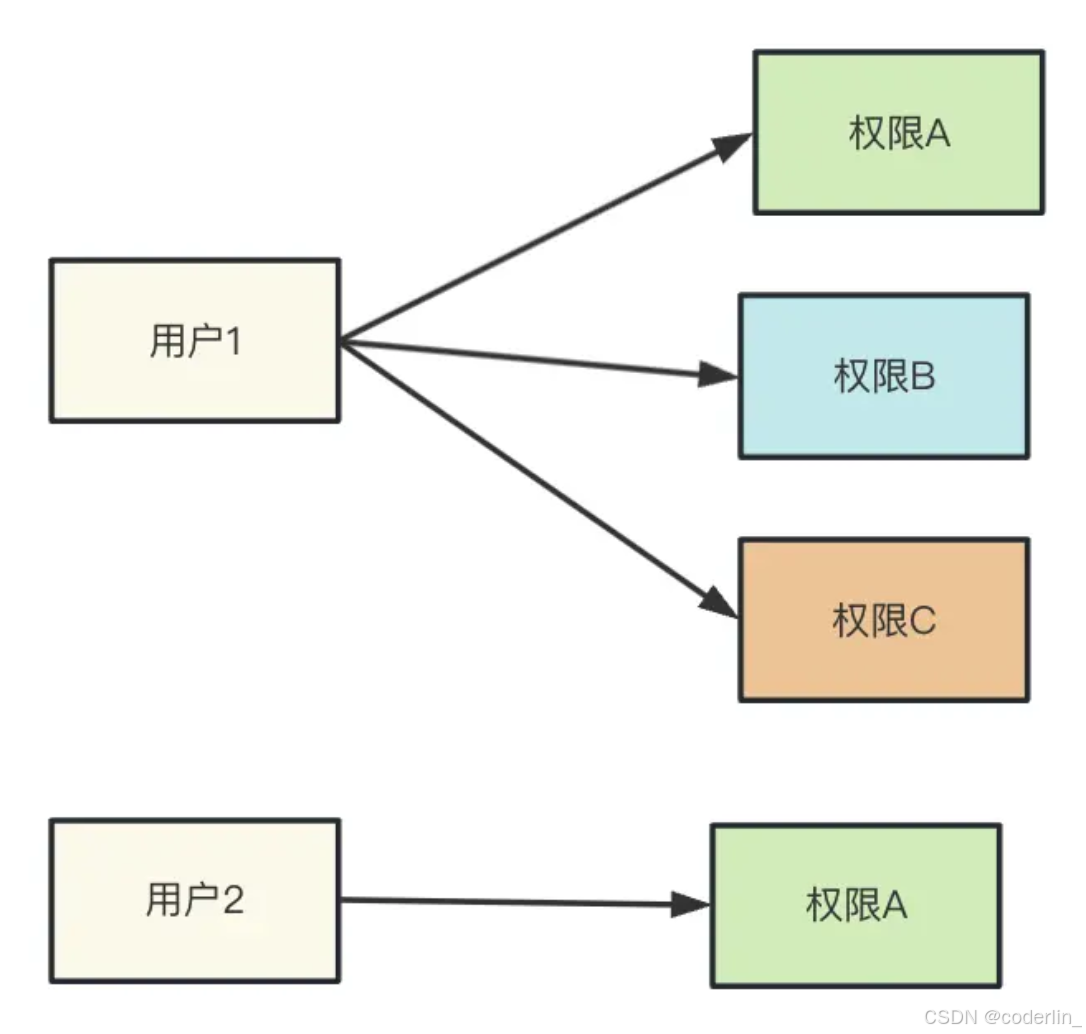
ACL权限控制
记录每个用户有什么权限,比如用户1有权限abc,用户2只有权限b,这种方式就叫访问控制表(Access Controle List)
用户和权限是多对多关系,存储这种关系需要用户表,角色表,用户-角色的中间表。角色就是权限控制。
用户表存储用户信息,角色表存储角色信息,然后用户-角色的关系存储在用户-角色中间表(userId-permissionId)。
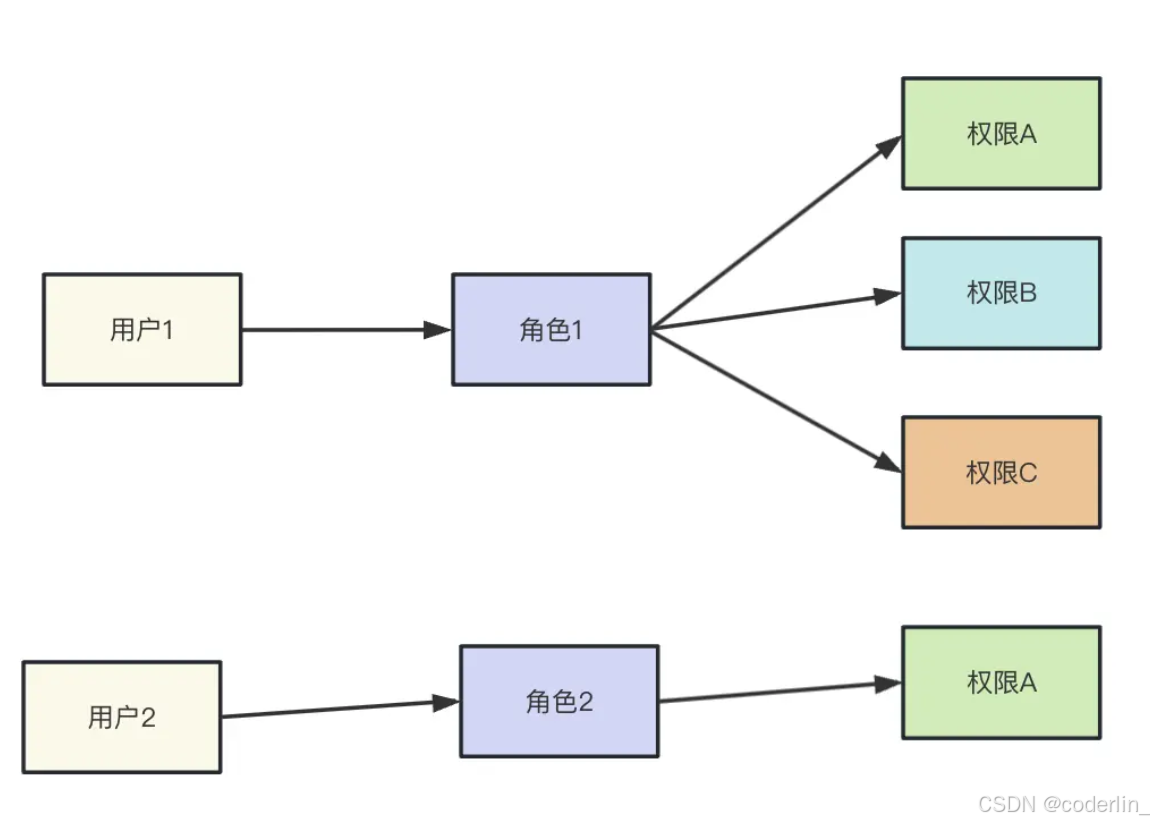
RBAC权限控制
Role Based Access Controle,基于角色的权限控制。
上面的ACL还是比较简单,
直接给用户配置权限,而RBAC则是,将权限赋给角色,再将角色赋给用户。
比如 角色可以有管理员角色,普通用角色
权限则是 查看权限,修改删除权限,增加权限。
将权限赋值给角色,比如管理员有所有权限,但是普通用户只有查看权限。
这时候可以指定哪些用户是管理员,哪些用户是普通用户,用户跟权限并不挂钩,他们中间通过角色来绑定。
这样的好处就是增加或者减少权限只需要通过修改角色-权限之前的关系,
比如哪一天管理员角色多了一个同步用户属性的权限,那么只需要在角色-权限表再加一条记录,记录管理员角色跟这个权限的关系。
如果是之前的ACL,那就需要给对应的很多用户都加这个权限。
用户很多的时候,给不同的用户分配不同的权限会很麻烦,这时候我们一般会先把不同的权限封装到角色里,再把角色授予用户。
一共会有五张表,user, role, permission user-role. role-permission
他们都是多对多的关系。
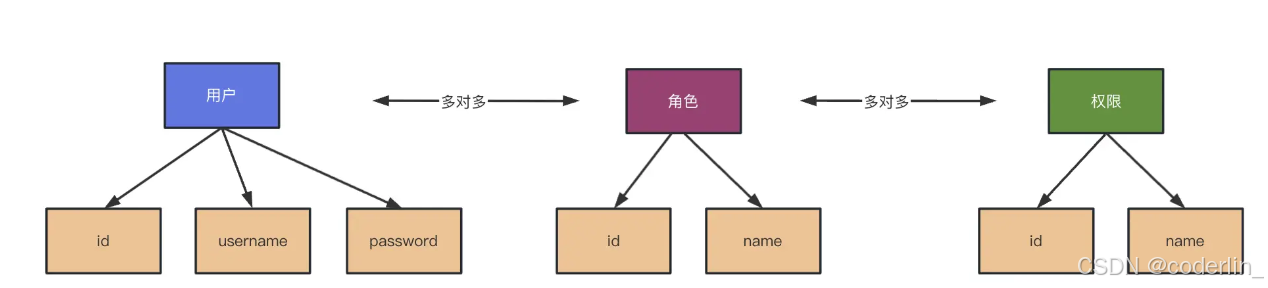
案例思路:
用户小明有一个管理员角色,用户小红是一个普通用户角色。
管理员可以进行创建,编辑,查看,删除操作。
而普通用户只有查看操作。
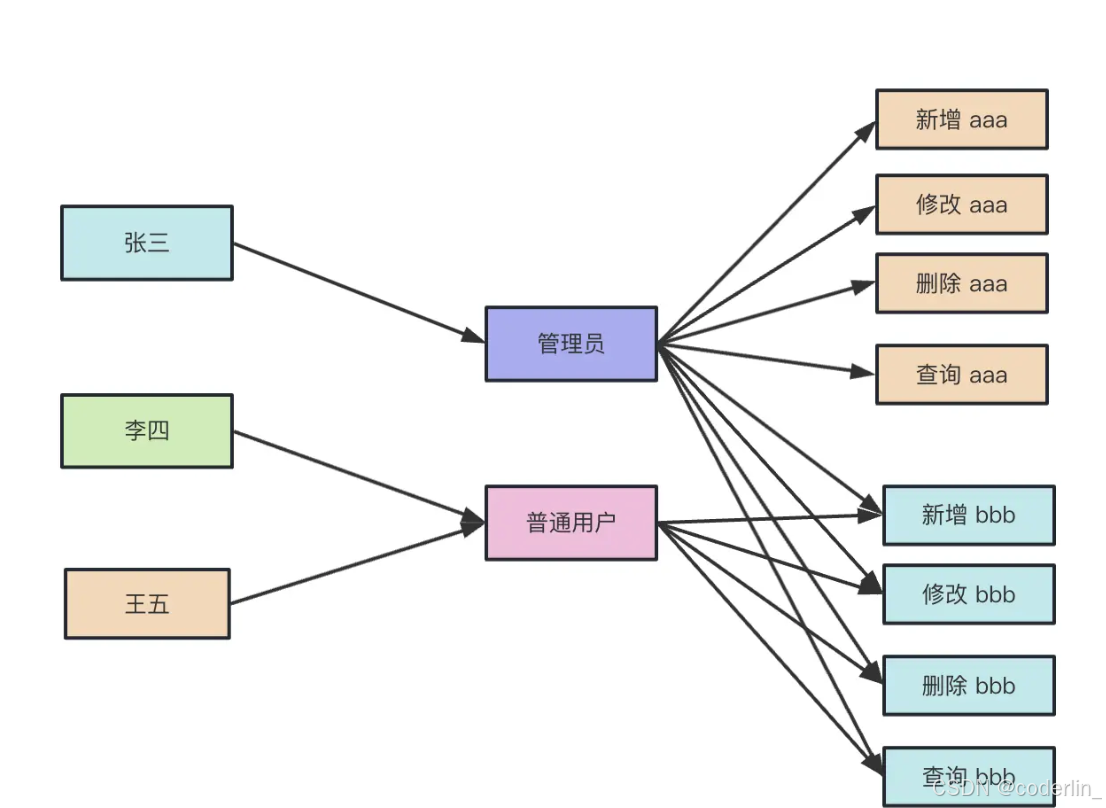
在权限系统给管理员绑定创建,编辑,查看,删除权限,给普通用户绑定查看权限。
给小明绑定管理员角色,给小红绑定普通用户角色。
前端权限校验:进入系统调用接口,获取权限列表,比如小明登陆后,角色列表roleList返回[‘admin’],权限列表permisionList会返回[‘创建’,‘编辑’,‘查看’,‘删除’],这时候根据permisionList即可对对应的操作进行控制。
基于access_token和refresh_token实现登陆无状态无感刷新。
之前基于jwt的登陆,将用户信息放入header里面。
jwt的token一般会设置有效期,一般是几个小时,如果这时候用户还在访问系统某个页面,结果访问到某个接口的时候token生效了,重定向登陆后的体验就比较差。
解决这个问题一般:服务器返回两个token,access_token和refresh_token,access_token用来认证用户身份,refresh_token用来刷新access_token,一般access_token设置30分钟失效,refresh_token设置七天过期。
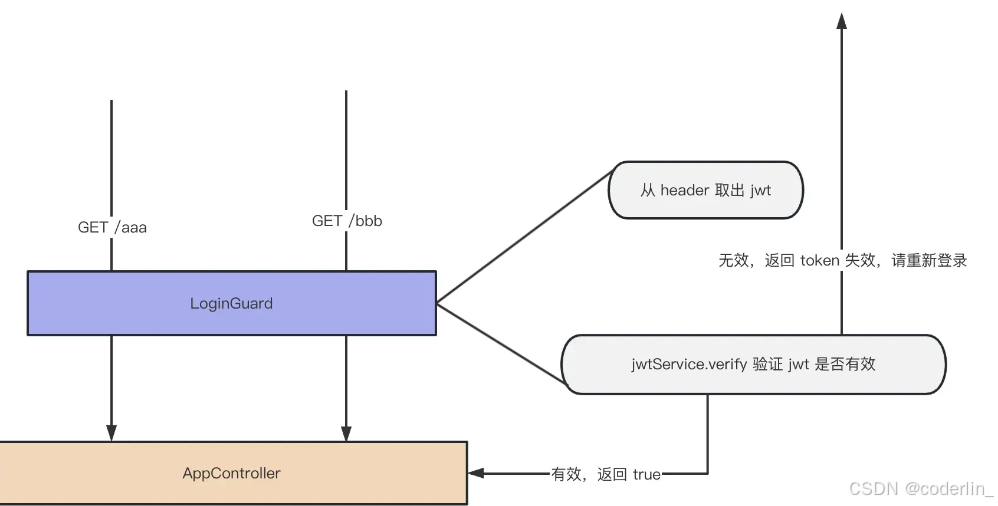
当access_token有效的时候,直接放行
当access_token失效的时候,校验refresh_token,refresh_token有效,返回新的access_token和refresh_token。refresh_token失效的时候,拒绝访问
所以只要不超过七天访问系统,就可以一直是登陆状态,而超过七天后,refresh_token也过期了,就需要重新登陆了。
想想我们用的app,常用的是不是基本不用登陆,超过一段时间没用后,就会让我们重新登陆。
demo案例
单token无限续签
双token实现较为麻烦,单token的原理也很简单,每次调用接口就返回新的token。比如设置一天过期,只有一天内任意访问一次,就会保持登陆状态。
使用passport做身份认证
使用账号密码登陆,和使用jwt鉴权登陆都有相似性。
从request的body/header,取出数据,进行验证,验证成功后在request.user中注入数据。
像这种身份认证逻辑很通用,用户密码,jwt,github登陆等,这多种方式都可以实现身份认证,所以可以用策略模式将他们封装成一个个策略类。
策略模式:定义一系列的算法,将他们一个一个封装起来,并且使他们可以互相替换。
优点:
- 利用组合,委托等技术和思想,有效避免很多if条件语句。
- 提供开放-封闭原则,使代码容易理解和扩展。
- 策略模式中的代码可以复用。
菜鸟教程:


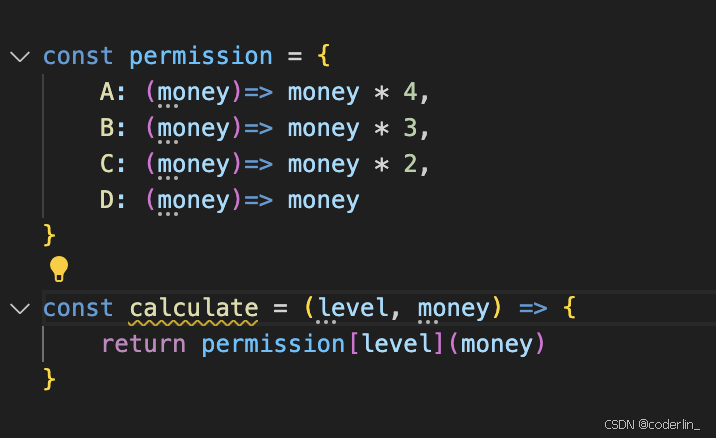
demo: 计算奖金
const calculate = (salary, level) => {
if(level === 'A'){return salary * 4 };
if(level === 'B'){return salary * 3 };
if(level === 'C'){return salary * 2 };
return salary
}
可以看到,多个if-else,缺乏弹性,如果有其他等级,需要在calculate函数中修改代码。复用性差,其他地方有类似的算法,规则不一样,则不可以复用。
使用策略模式:
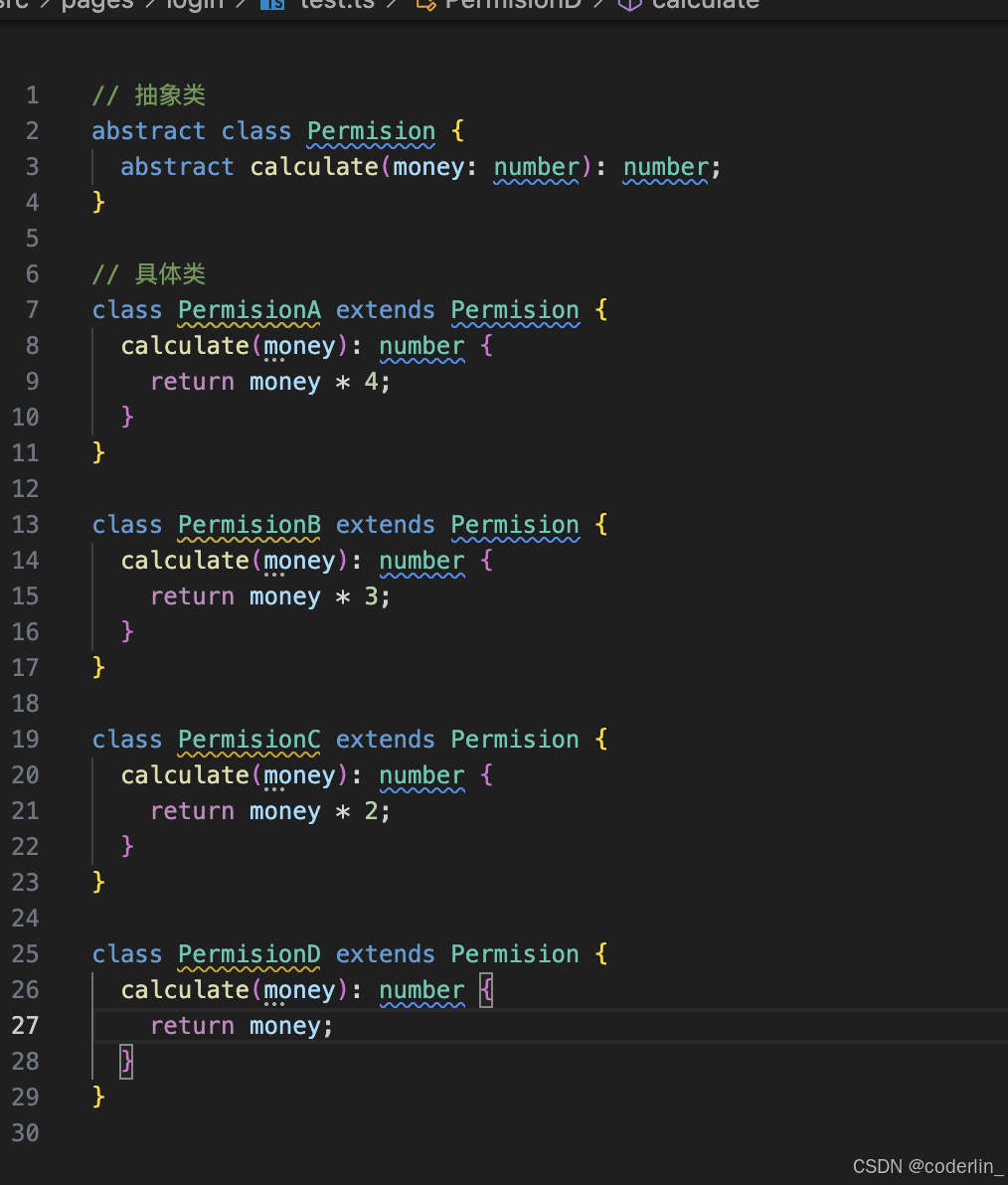
定义抽象类和具体的实现类
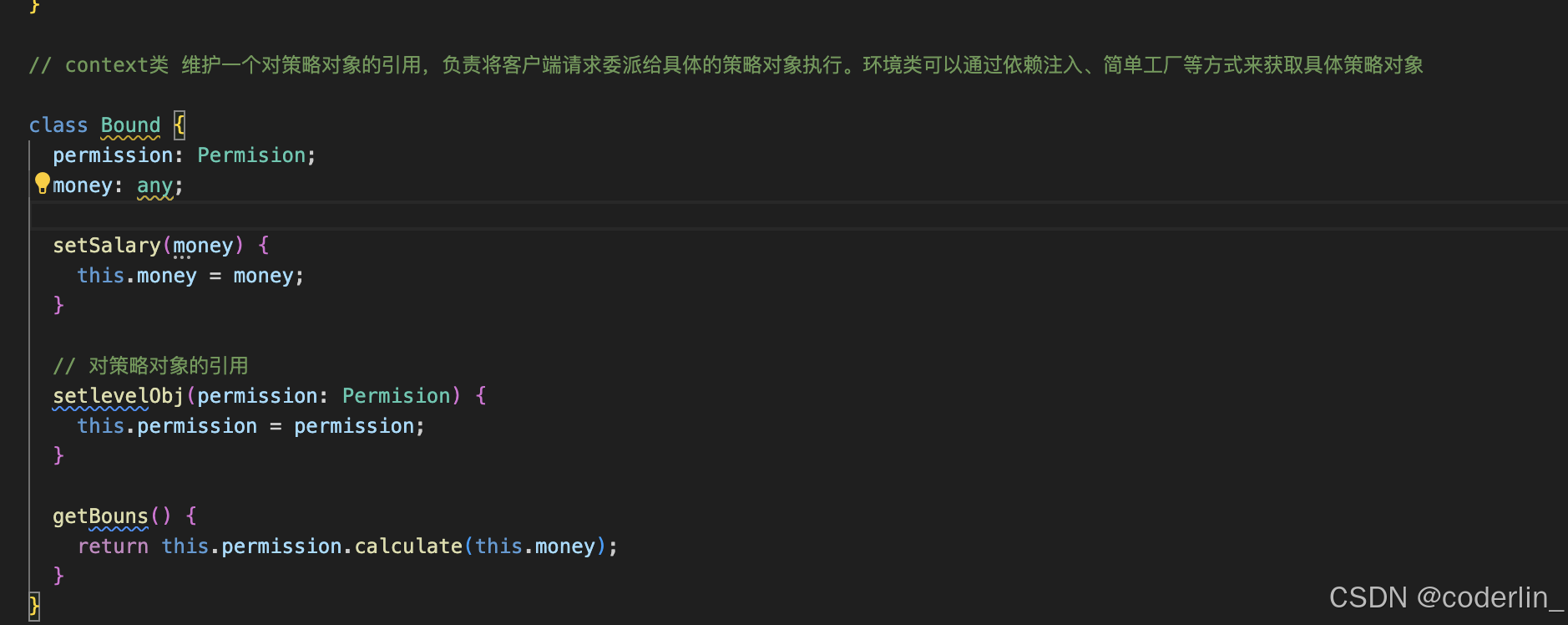
定义context类,对策略对象进行引用,将客户端的请求委派给具体的策略对象执行。
使用
如果有多一个等级,再写一个实现类即可。
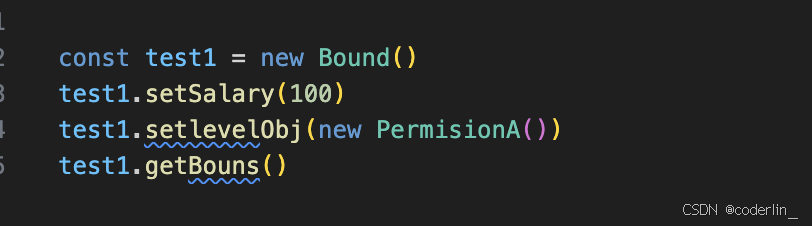
js版本下的策略模式:
策略模式不仅只封装算法,也可以封装一系列的业务规则,如上。
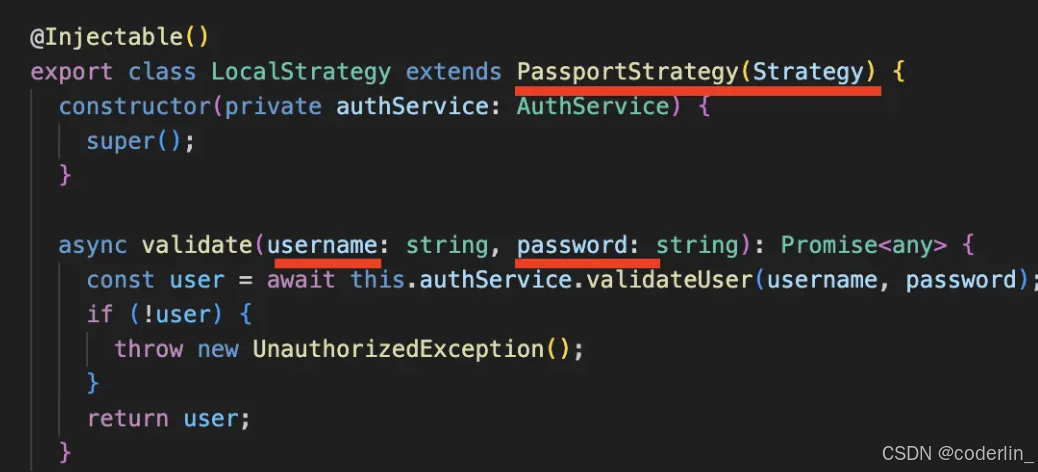
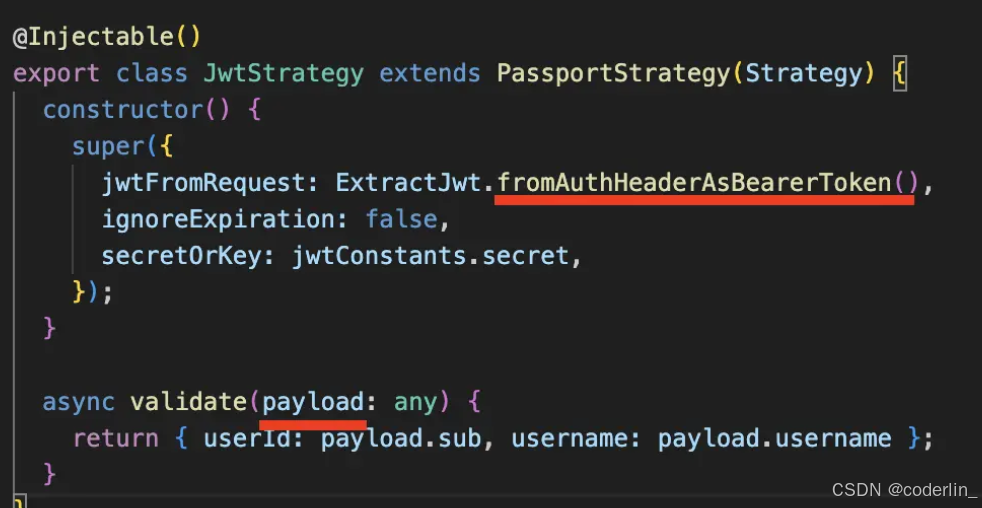
使用身份认证库passport的两种策略
不管用户密码的身份认证,或者是jwt的身份认证,都会从request的body和header中取出一些信息来,然后认证通过后返回user的信息,passport会设置到request.user上。
oauth2 登录
基于nginx实现灰度系统
灰度流程
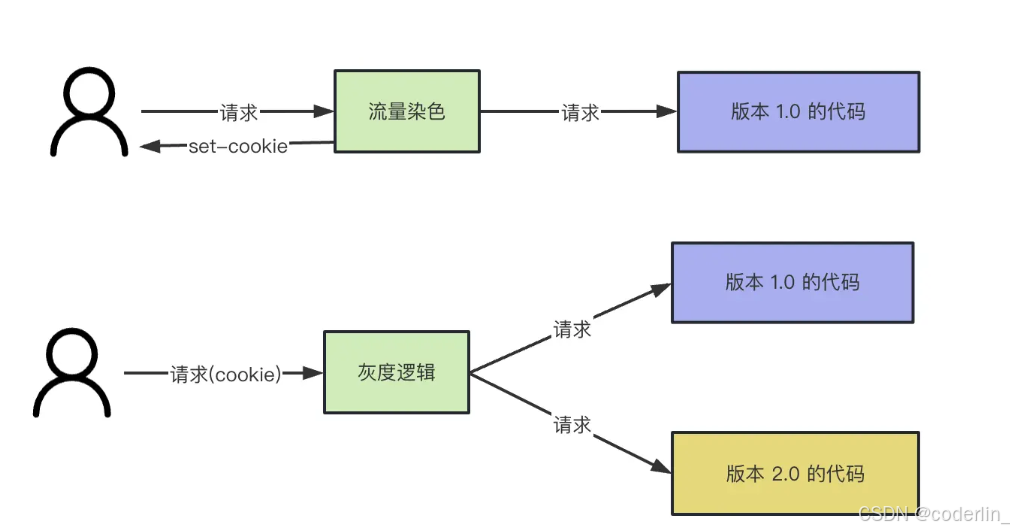
第一次访问的时候,按照设定的比例随机对流量染色,设置不同的cookie。
再次访问的时候会根据cookie来走到不同的版本。
nginx有反向代理的功能,可以转发请求到应用服务器,也就是网关层。
nginx相关配置
upstream version1.0_server {
server 192.168.1.6:3000;
}
upstream version2.0_server {
server 192.168.1.6:3001;
}
upstream default {
server 192.168.1.6:3000;
}
server {
listen 80;
...
set $group "default";
if ($http_cookie ~* "version=1.0"){
set $group version1.0_server;
}
if ($http_cookie ~* "version=2.0"){
set $group version2.0_server;
}
location ^~ /api {
rewrite ^/api/(.*)$ /$1 break;
proxy_pass http://$group;
}
}
有对应cookie的请求转发到对应服务器,默认走default服务。
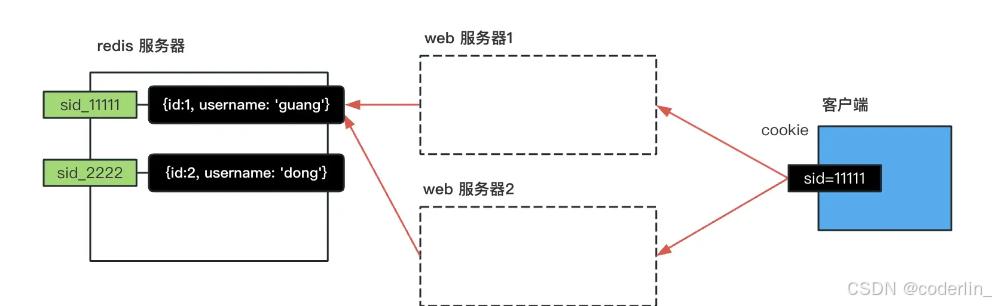
基于redis实现分布式session。
上面讲过,采用session的话,如果是分布式后端服务,不同机器之间session数据不一样,他的数据是存放在单独的服务器的内存的,其他服务器无法拿到。
如何让session支持分布式呢?
一种是自己做session的同步,在多台服务器之间复制session。
还有一种比较常用的是用redis做同步,将session信息存在redis中,每台服务器去redsi取数据即可。
基于redis实现附近的充电宝
redis不只可以做缓存,很多临时的数据,比如验证码,token都可以放到redsi中。
redis 是 key-value 的数据库,value 有很多种类型:
string: 可以存数字、字符串,比如存验证码就是这种类型
hash:存一个 map 的结构,比如文章的点赞数、收藏数、阅读量,就可以用 hash 存
set:存去重后的集合数据,支持交集、并集等计算,常用来实现关注关系,比如可以用交集取出互相关注的用户
zset:排序的集合,可以指定一个分数,按照分数排序。我们每天看的文章热榜、微博热榜等各种排行榜,都是 zset 做的
list:存列表数据
geo:存地理位置,支持地理位置之间的距离计算、按照半径搜索附近的位置
其中,geo的数据结构,就是用来实现附近的人的功能的。
比如,大众点评,美团外卖就是用redis实现的基于地理位置的功能。

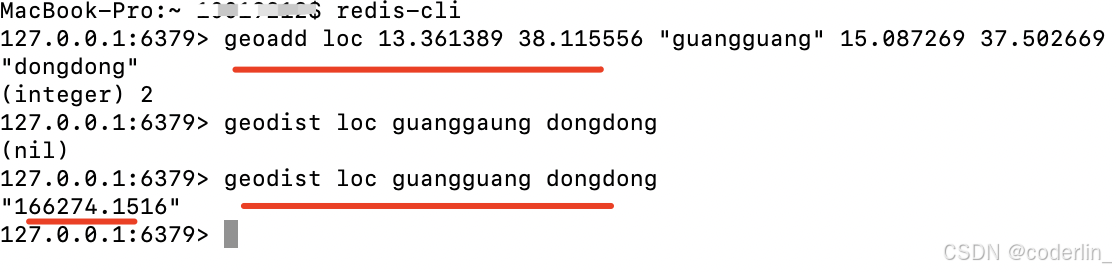
GEOADD key longitude(经度) latitude(纬度) member(名称) [longitude latitude member ...]
GEODIST key member1 member2 [m|km|ft|mi]
往redis插入一条数据。
根据geidust计算两个位置之间的距离。
可以看到算出来两者差166km左右(默认是m)
接下来可以通过geiradius根据指定的经纬度获取周边的点。
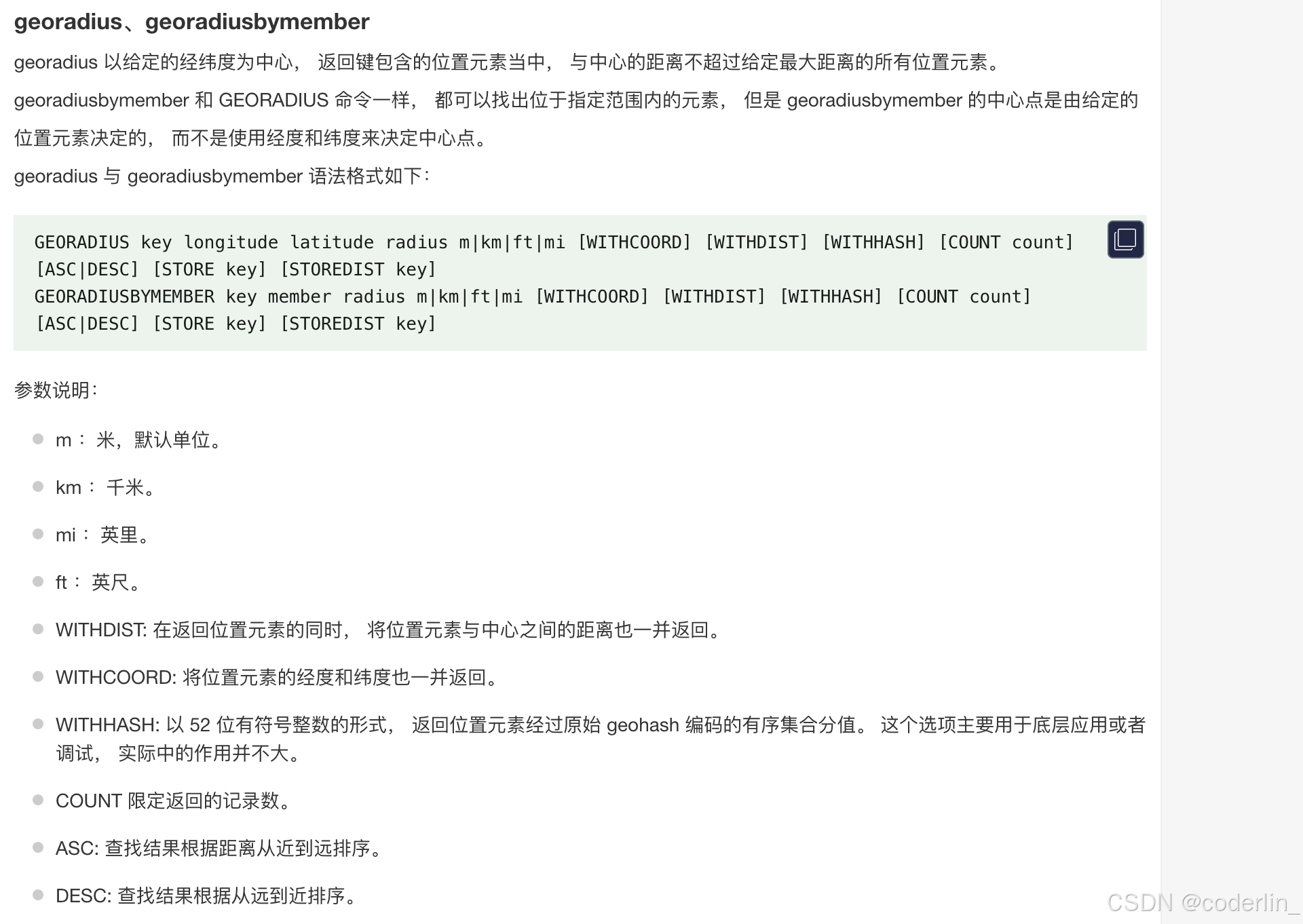
georadius 以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。
GEORADIUS key longitude(经度) latitude(纬度) radius(距离) m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
georadius loc 15 37 100 km
经纬度13 17旁边100km的只有一个点。
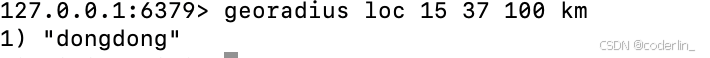
200km的就有两个点。

通过上述,我们可以实现搜索附近1km充电宝的功能。
后端:
只需要服务器提供一个接口,让充电宝机器上传位置,然后把它存到redis中。
再提供一个搜索接口,基于用户的位置,用georradius来搜索附近的充电宝机器,返回客户端。
前端:
客户端可以在地图上把这些点画出来。
高德和百度都提供了api支持在地图上绘制marker标记功能。
灵活创建DTO
开发 CRUD 接口的时候,经常会发现 update 的 dto 和 create 的 dto 很类似,而我们要重复的写两次。
可以用 @nestjs/mapped-types 的 PartialType、PickType、OmitType、IntersectionType 来避免重复。
PickType 是从已有 dto 类型中取某个字段。
OmitType 是从已有 dto 类型中去掉某个字段。
PartialType 是把 dto 类型变为可选。
IntersectionType 是组合多个 dto 类型。
有点类似于ts的Pick,Omit,Partial。
class-validator内置装饰器,自定义装饰器。
内装装饰器相关文档
自定义校验装饰器
import { ValidationArguments, ValidatorConstraint, ValidatorConstraintInterface } from "class-validator";
@ValidatorConstraint()
export class MyValidator implements ValidatorConstraintInterface {
validate(text: string, validationArguments: ValidationArguments) {
console.log(text, validationArguments)
return true;
}
}
使用
@Validate(MyValidator, [11, 22], {
message: 'jjj 校验失败',
})
jjj: string;
text就是传入的jjj的值,第二个参数包含更多信息。

自定义装饰器封装。
import { applyDecorators } from '@nestjs/common';
import { Validate, ValidationOptions } from 'class-validator';
import { MyValidator } from './my-validator';
export function MyContains(content: string, options?: ValidationOptions) {
return applyDecorators(
Validate(MyValidator, [content], options)
)
}
使用起来更方便
@MyContains('111', {
message: 'jjj 必须包含 111'
})
jjj: string;