文章目录
传送门:
- 视频地址:黑马程序员Spark全套视频教程
- 1.PySpark基础入门(一)
- 2.PySpark基础入门(二)
- 3.PySpark核心编程(一)
- 4.PySpark核心编程(二)
- 5.PySaprk——SparkSQL学习(一)
- 6.PySaprk——SparkSQL学习(二)
- 7.Spark综合案例——零售业务统计分析
- 8. Spark3新特性及核心概念(背)
一、快速入门
1. 什么是SparkSQL
SparkSQL是Spark的一个模块,用于处理海量结构化数据。
限定:结构化数据处理。
RDD算子可以处理结构化数据,非结构化数据,半结构化数据
2. 为什么要学习SparkSQL
SparkSQL是非常成熟的海量结构化数据处理框架。学习SparkSQL主要在2个点:
- SparkSQL本身十分优秀, 支持SQL语言\性能强\可以自动优化\API简单\兼容HIVE等
- 企业大面积在使用SparkSQL处理业务数据
- 离线开发
- 数仓搭建
- 科学计算
- 数据分析
3. SparkSQL特点
- 融合性
SQL可以无缝集成在代码中,随时用SQL处理数据 - 统一数据访问
一套标准API可读写不同数据源 - Hive兼容
可以使用SparkSQL直接计算并生成Hive数据表 - 标准化连接
支持标准化JDBC\ODBC连接,方便和各种数据库进行数据交互。
二、SparkSQL概述
1. SparkSQL和Hive的异同
相同点:
- Hive和Spark 均是:“分布式SQL计算引擎”,均是构建大规模结构化数据计算的绝佳利器。
不同点:
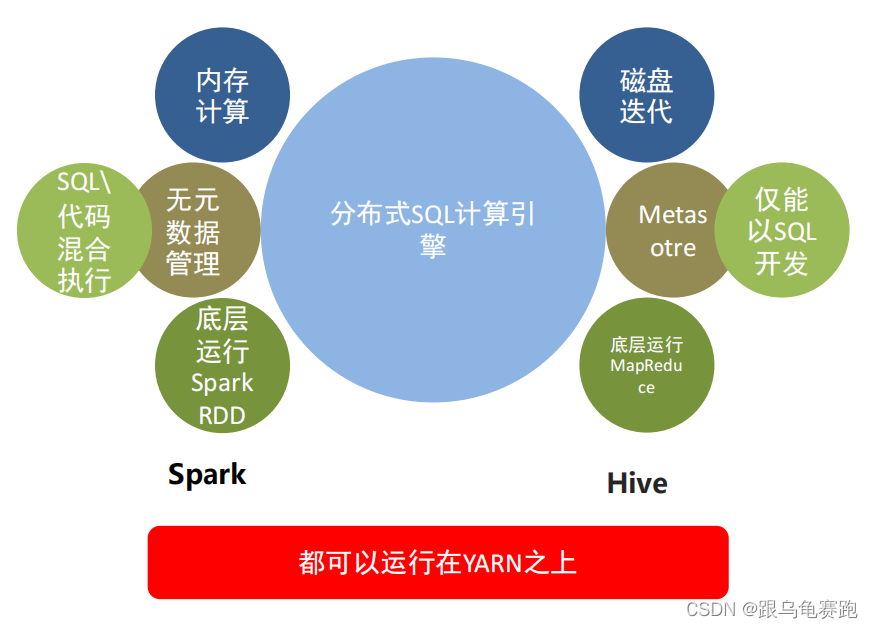
2. SparkSQL的数据抽象
SparkSQL的DataFrame底层借鉴了Pandas的DataFrame,是二维表数据结构、分布式集合(分区)。SparkSQL现在使用的有2类数据抽象对象:
- DataSet对象,可用于Java、Scala语言
DataSet支持泛型特性(Python语言没有泛型特性),可以让Java、Scala语言更好的利用到 - DataFrame对象,可用于Java、Scala、Python、R语言
我们以Python开发SparkSQL,主要使用的就是DataFrame对象作为核心数据结构。
3. DataFrame数据抽象
DataFrame和RDD都是:弹性的、分布式的数据集。只是,DataFrame存储的数据结构“限定”为:二维表结构化数据而RDD可以存储的数据则没有任何限制,想处理什么就处理什么。
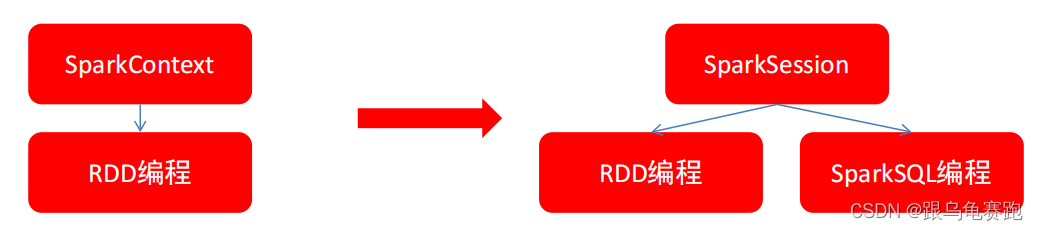
4. SparkSession对象
在RDD阶段,程序的执行入口对象是: SparkContext对象。在Spark 2.0后,推出了SparkSession对象,作为Spark编码的统一入口对象。
SparkSession对象可以:
- 用于SparkSQL编程作为入口对象
- 用于SparkCore编程,可以通过SparkSession对象中获取到SparkContext
所以,我们后续的代码,执行环境入口对象,统一变更为SparkSession对象。
6. SparkSQL HelloWorld
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
SparkSession入口对象作为SQL的编程入口
SparkContext入口对象作为RDD的编程入口
"""
# SparkSession对象的导包,SparkSQL 中的入口对象是SparkSession对象
from pyspark.sql import SparkSession
if __name__ == '__main__':
# 0.构建SparkSession入口对象
# appName 设置程序名称, config设置一些常用属性
spark = SparkSession.builder. \
appName('test'). \
master('local[*]'). \
getOrCreate()
# 1.通过SparkSession对象获取SparkContext对象
sc = spark.sparkContext
# SparkSQL的HelloWord
# 读取数据
df = spark.read.csv('../data/input/stu_score.txt', sep=',', header=False)
# 设置列名
df2 = df.toDF('id', 'name', 'score')
df2.printSchema() # 打印表结构
df2.show() # 打印表内容
df2.createTempView('score')
# SQL风格
spark.sql("""
SELECT * FROM score WHERE name='语文' LIMIT 5
""").show()
# DSL风格
df2.where("name='语文'").limit(5).show()
root
|-- id: string (nullable = true)
|-- name: string (nullable = true)
|-- score: string (nullable = true)
+---+----+-----+
| id|name|score|
+---+----+-----+
| 1|语文| 99|
| 2|语文| 99|
| 3|语文| 99|
| 4|语文| 99|
| 5|语文| 99|
| 6|语文| 99|
| 7|语文| 99|
| 8|语文| 99|
| 9|语文| 99|
| 10|语文| 99|
| 11|语文| 99|
| 12|语文| 99|
| 13|语文| 99|
| 14|语文| 99|
| 15|语文| 99|
| 16|语文| 99|
| 17|语文| 99|
| 18|语文| 99|
| 19|语文| 99|
| 20|语文| 99|
+---+----+-----+
only showing top 20 rows
+---+----+-----+
| id|name|score|
+---+----+-----+
| 1|语文| 99|
| 2|语文| 99|
| 3|语文| 99|
| 4|语文| 99|
| 5|语文| 99|
+---+----+-----+
+---+----+-----+
| id|name|score|
+---+----+-----+
| 1|语文| 99|
| 2|语文| 99|
| 3|语文| 99|
| 4|语文| 99|
| 5|语文| 99|
+---+----+-----+
三、DataFrame入门和操作
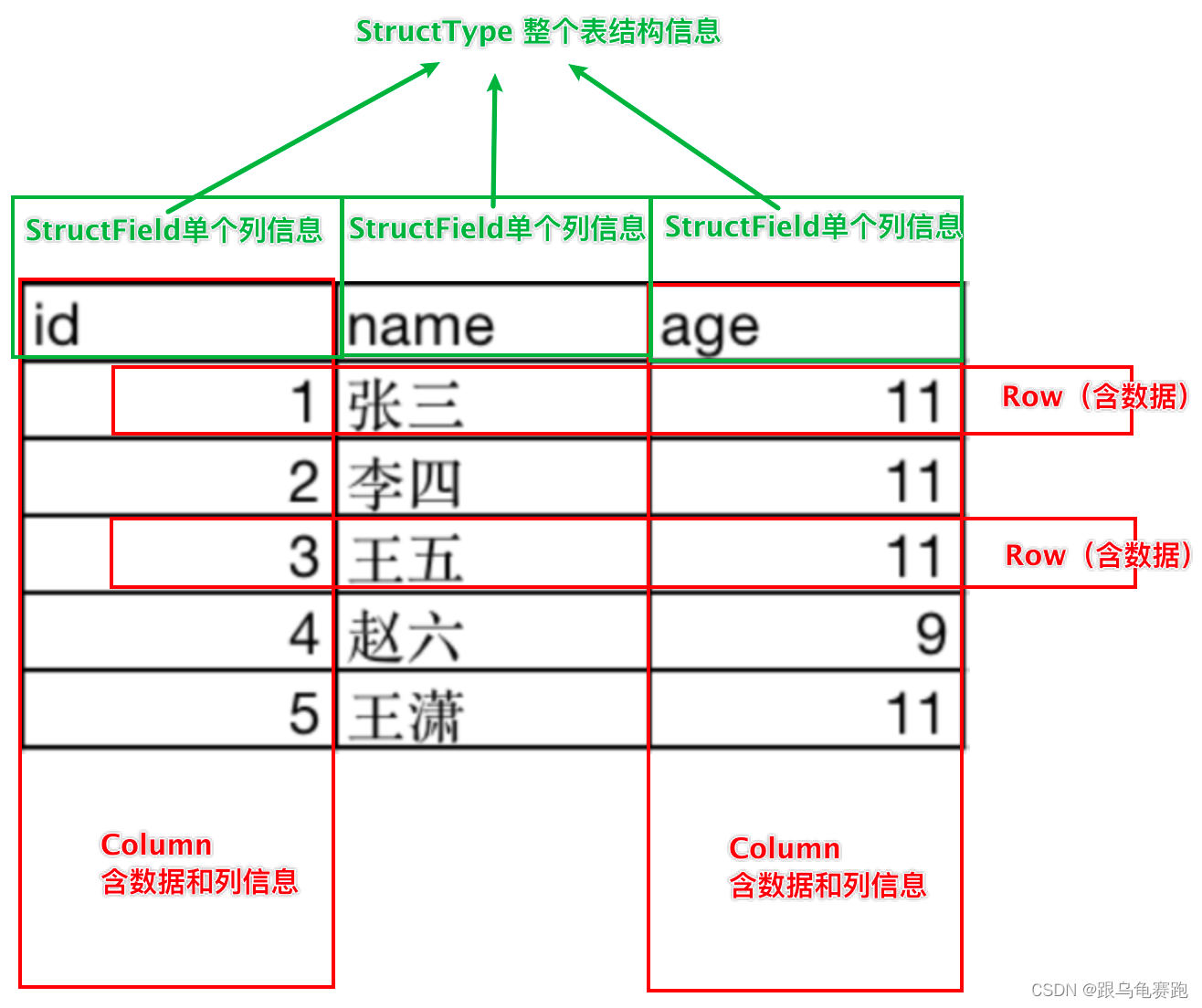
1. DataFrame的组成
DataFrame是一个二维表结构, 那么表格结构就有无法绕开的三个点:
- 行
- 列
- 表结构描述
基于这个前提,DataFrame的组成如下:
在结构层面:
- StructType对象描述整个DataFrame的表结构
- StructField对象描述一个列的信息
在数据层面
- Row对象记录一行数据
- Column对象记录一列数据并包含列的信息
如图,在表结构层面,DataFrame的表结构由StructType对象来描述,如下图:
一个StructField记录:列名、列类型、列是否为空。多个StructField组成一个StructType对象。一个StructType对象可以描述一个DataFrame:有几个列、每个列的名字和类型、每个列是否为空。

2. DataFrame的代码构建
2.1 基于RDD的方式1
DataFrame对象可以从RDD转换而来,都是分布式数据集,就是转换一下内部存储的结构,转换为二维表结构。通过SparkSession对象的createDataFrame方法来将RDD转换为DataFrame。这里只传入列名称,类型从RDD中进行推断,是否允许为空默认为允许(True)。
#!usr/bin/env python
# -*- coding:utf-8 -*-
# TODO:基于RDD的方式构建DataFrame对象
from pyspark.sql import SparkSession
if __name__ == '__main__':
# 0.构建SparkSession执行环境入口对象
spark = SparkSession.builder. \
appName('test'). \
master('local[*]'). \
getOrCreate()
sc = spark.sparkContext
# 1.基于RDD转换成DataFrame
rdd = sc.textFile('../data/input/sql/people.txt'). \
map(lambda x: x.split(',')). \
map(lambda x: (x[0], int(x[1])))
# 2. 构建DataFrame对象
# 参数1:被转换的RDD;参数2指定列名,通过list的形式指定,按照顺序依次提供字符串名称
df = spark.createDataFrame(rdd, schema=['name', 'age'])
# 打印DataFrame表结构
df.printSchema()
# 打印DataFrame数据
# 参数1表示展示多少条数据,默认不传的话是20
# 参数2表示是否对列进行截断,如果列的数据长度超过20个字符串程度,后续的内容不显示,以...代替
# 如果给False,表示全部显示(不截断),默认是True
df.show()
# 将DF对象转换为临时视图表,可供sql语句查询
df.createOrReplaceTempView('people')
spark.sql("SELECT * FROM people WHERE age < 30").show()
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
+-------+---+
| name|age|
+-------+---+
|Michael| 29|
| Andy| 30|
| Justin| 19|
+-------+---+
+-------+---+
| name|age|
+-------+---+
|Michael| 29|
| Justin| 19|
+-------+---+
2.2 基于RDD的方式2
通过StructType对象来定义DataFrame的“表结构”转换RDD。
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
基于RDD的方式构建DataFrame对象,
通过StructType对象来定义DataFrame的“表结构”转换RDD
"""
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
if __name__ == '__main__':
# 0.构建SparkSession执行环境入口对象
spark = SparkSession.builder. \
appName('test'). \
master('local[*]'). \
getOrCreate()
sc = spark.sparkContext
# 1.基于RDD转换成DataFrame
rdd = sc.textFile('../data/input/sql/people.txt'). \
map(lambda x: x.split(',')). \
map(lambda x: (x[0], int(x[1])))
# 2. 构建表结构描述对象——StructType对象
schema = StructType().\
add("name", StringType(), nullable=True). \
add("age", IntegerType(), nullable=False)
# 3.基于StructType对象去构建RDD到DF的转换
df = spark.createDataFrame(rdd, schema=schema)
df.printSchema()
df.show()
root
|-- name: string (nullable = true)
|-- age: integer (nullable = false)
+-------+---+
| name|age|
+-------+---+
|Michael| 29|
| Andy| 30|
| Justin| 19|
+-------+---+
2.3 基于RDD的方式3
使用RDD的toDF方法转换RDD。
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
基于RDD的方式构建DataFrame对象,
使用RDD的toDF方法转换RDD
"""
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
if __name__ == '__main__':
# 0.构建SparkSession执行环境入口对象
spark = SparkSession.builder. \
appName('test'). \
master('local[*]'). \
getOrCreate()
sc = spark.sparkContext
# 1.基于RDD转换成DataFrame
rdd = sc.textFile('../data/input/sql/people.txt'). \
map(lambda x: x.split(',')). \
map(lambda x: (x[0], int(x[1])))
# TODO:toDF的方式构建DataFrame
df1 = rdd.toDF(['name','age'])
df1.printSchema()
df1.show()
# TODO:通过表结构描述对象——StructType对象的方式构建DataFrame
schema = StructType().\
add("name", StringType(), nullable=True). \
add("age", IntegerType(), nullable=False)
df2 = rdd.toDF(schema=schema)
df2.printSchema()
df2.show()
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
+-------+---+
| name|age|
+-------+---+