架构实践02-高性能架构模式
1、 高性能数据库集群:读写分离
(1)引言
- 背景:随着业务的发展和数据的增长,单个数据库服务器难以满足需求,必须考虑数据库集群。
- 目的:介绍高性能数据库集群的第一种方式——读写分离。
(2)读写分离原理
- 基本概念:
- 数据同步:
- 复制机制:主机通过复制将数据同步到从机。
- 存储特性:每台数据库服务器都存储所有业务数据。
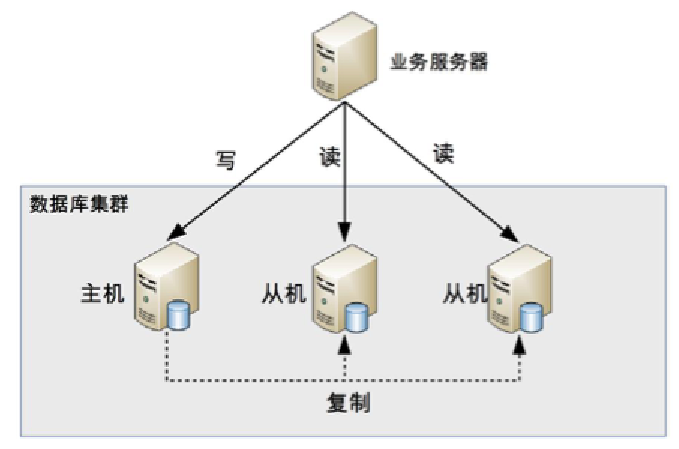
(3)设计复杂度
- 复制延迟:
- 问题:主从复制延迟可能导致读取不到最新数据。
- 解决方案:
- 写操作后的读操作指定发给主机:业务强绑定,对代码侵入较大。
- 读从机失败后再读一次主机:实现简单,但增加主机读操作压力。
- 关键业务读写操作全部指向主机:非关键业务采用读写分离。
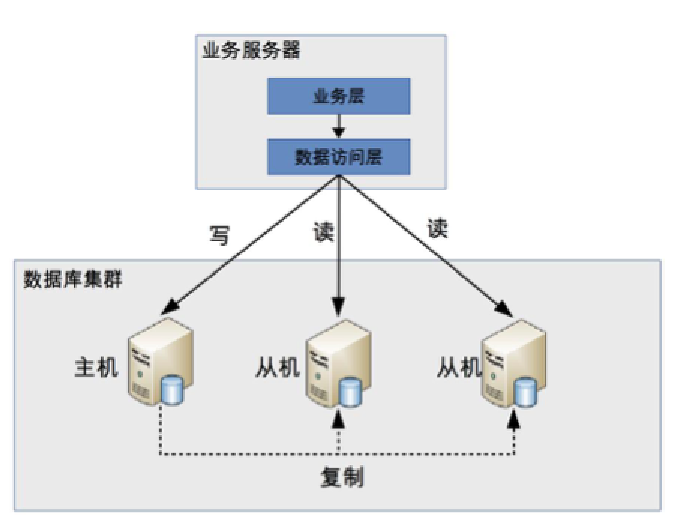
- 分配机制:
- 程序代码封装:
- 特点:实现简单,可定制化,但每个语言需单独实现。
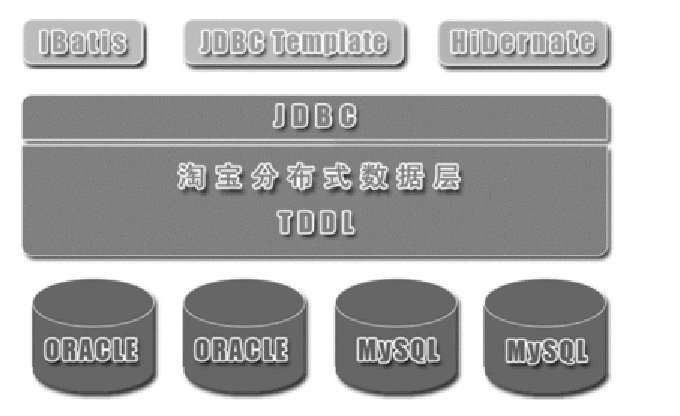
- 示例:TDDL(Taobao Distributed Data Layer)。
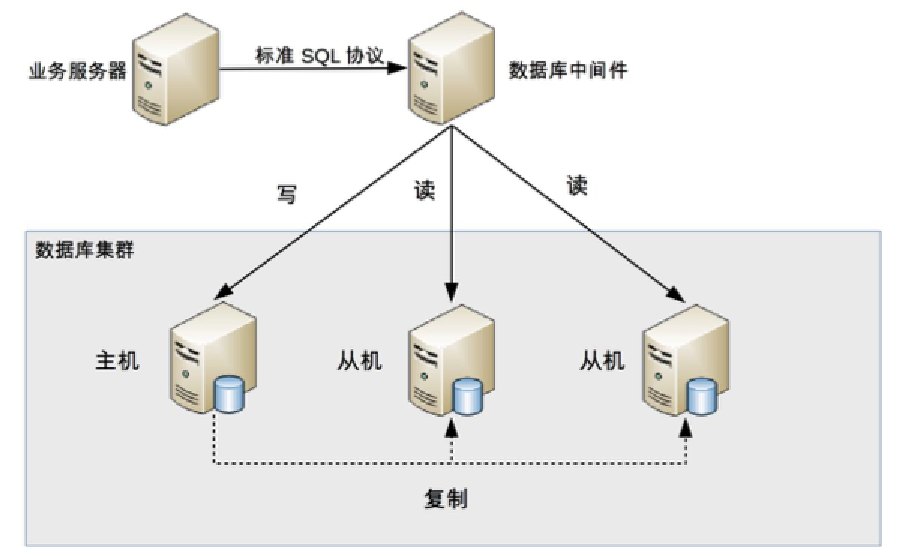
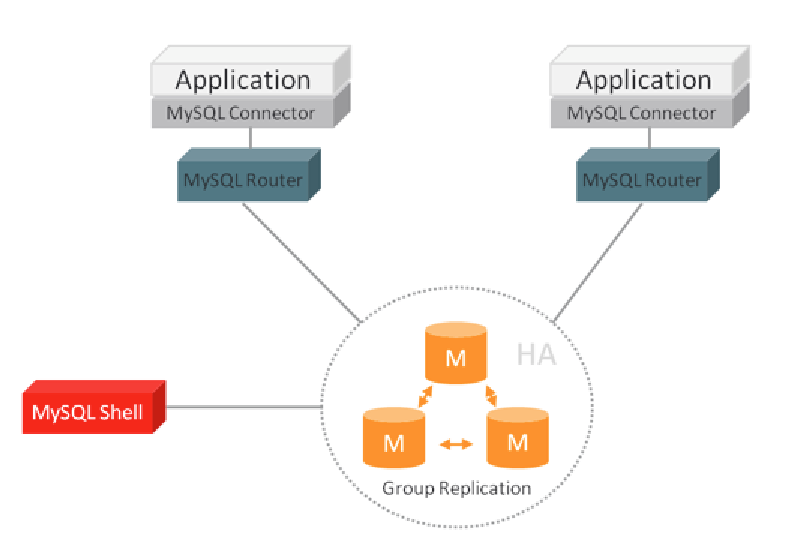
- 中间件封装:
- 特点:复杂度高,支持多种编程语言,但实现难度大。
- 示例:MySQL Router、Atlas。

(4)读写分离的应用场景
- 适用场景:
- 读多写少:如博客、社交媒体等。
- 单机并发无法支撑:读请求远多于写请求。
- 业务优化后仍需提升性能:优化慢查询、调整业务逻辑、引入缓存后仍需进一步提升。
- 不适用场景:
- 高并发写入:单机写入无法支撑。
- 缓存能解决问题:缓存可以有效缓解读压力。
2、高性能数据库集群:分库分表
(1)单台数据库服务器的瓶颈
- 数据量过大:数据量达到千万甚至上亿条时,单台数据库服务器的存储能力和读写性能会成为瓶颈。
- 索引性能下降:即使有索引,索引文件也会变得很大,影响性能。
- 备份和恢复时间长:数据文件越大,备份和恢复所需的时间越长。
- 数据丢失风险高:数据文件越大,极端情况下数据丢失的风险越高。
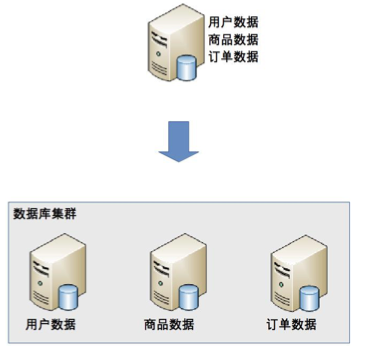
(2)业务分库
- 定义:按照业务模块将数据分散到不同的数据库服务器。
- 优点:
- 缺点:
- Join操作问题:无法使用 SQL 的 join 查询。
- 事务问题:无法通过事务统一修改不同数据库中的表。
- 成本问题:需要更多的服务器和备份资源。
(3)分表
- 定义:将单表数据拆分成多个表,以提高性能和分散存储压力。
- 方式:
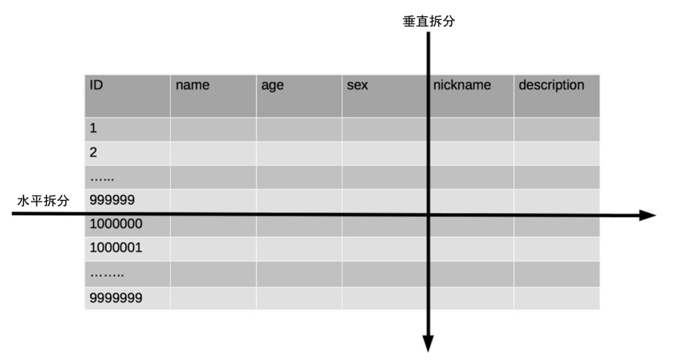
- 垂直分表:将表中某些不常用且占大量空间的列拆分出去。
- 水平分表:将表中的行数据根据某种规则拆分到多个表中。
- 垂直分表:
- 适用场景:表中某些列不常用且占用大量空间。
- 复杂性:表操作数量增加。
- 水平分表:
- 适用场景:表行数特别大。
- 常见路由算法:
- 范围路由:按有序数据列分段。
- Hash路由:按某一列的值进行哈希运算。
- 配置路由:用一张独立的表记录路由信息。
- 复杂性:
- 需要增加路由算法。
- 数据分散在多个表中,join 和 count 操作复杂。
- 排序操作无法在数据库中完成,需要业务代码或中间件处理。
(4)实现方式
- 程序代码封装:在业务代码中实现分库分表的逻辑。
- 中间件封装:使用数据库中间件(如 MyCat)来实现分库分表。
(5)何时引入分库分表
- 数据库性能不足:当数据库性能不足,且通过硬件优化、索引优化、缓存、读写分离等手段无法解决问题时。
- 数据量大:单表数据量超过千万或简单查询的单表数据量超过 5000 万时。
- 业务发展:业务发展迅速,预计未来数据量会快速增长。
(6)其他优化手段
- 硬件优化:升级服务器硬件,如使用 SSD 替代机械硬盘。
- 数据库调优:增加索引,调整数据库参数。
- 引入缓存:使用 Redis 等缓存技术减少数据库压力。
- 全文检索:使用 Elasticsearch 等全文检索引擎处理复杂查询。
3、高性能 NoSQL
(1)关系数据库的局限性
- 数据结构存储问题:关系数据库无法直接存储复杂的数据结构,如列表、嵌套对象等。
- Schema 扩展困难:关系数据库的表结构是强约束的,增加或修改字段需要执行 DDL 语句,可能导致长时间锁表。
- I/O 效率问题:对大量数据进行统计运算时,关系数据库需要读取整行数据,导致 I/O 开销大。
- 全文搜索性能低:关系数据库的全文搜索只能使用
like 进行整表扫描,性能低下。
(2)NoSQL 数据库的分类及特点
- K-V 存储:
- 特点:存储键值对,支持多种数据结构(如字符串、哈希、列表等)。
- 典型代表:Redis。
- 应用场景:缓存、会话管理、排行榜等。
- 文档数据库:
- 特点:存储 JSON/BSON 格式的文档,无须预先定义 Schema。
- 典型代表:MongoDB。
- 应用场景:电商、游戏等需要灵活存储复杂数据的场景。
- 列式数据库:
- 特点:按列存储数据,适合大数据统计和分析。
- 典型代表:HBase。
- 应用场景:离线大数据分析、数据仓库等。
- 全文搜索引擎:
- 特点:使用倒排索引技术,支持高效的全文搜索。
- 典型代表:Elasticsearch。
- 应用场景:搜索引擎、日志分析等。
(3)NoSQL 的优缺点
- 优点:
- 灵活性:NoSQL 数据库通常没有固定的 Schema,易于扩展和修改。
- 性能:在特定场景下(如大数据统计、全文搜索)性能优于关系数据库。
- 可扩展性:NoSQL 数据库通常支持水平扩展,适合分布式部署。
- 缺点:
- 不支持完整 ACID 事务:大多数 NoSQL 数据库不支持完整的 ACID 事务,特别是在多文档或多键操作时。
- 缺乏标准化:NoSQL 数据库种类繁多,缺乏统一的标准和接口。
- 复杂查询能力有限:NoSQL 数据库在复杂查询(如多表关联)方面不如关系数据库强大。
(4)关系数据库与 NoSQL 的互补关系
- NoSQL != No SQL:NoSQL 应作为关系数据库的补充,而不是替代。
- 混合使用:在实际应用中,可以根据业务需求选择合适的数据库类型,例如将核心事务数据存储在关系数据库中,使用 NoSQL 数据库进行缓存、搜索等辅助功能。
(5)选择数据库的考虑因素
- 数据量:大规模数据更适合使用 NoSQL 数据库。
- 并发量:高并发场景下,NoSQL 数据库通常表现更好。
- 实时性:对实时性要求高的场景,可以使用 Redis 等内存数据库。
- 一致性要求:对数据一致性要求高的场景,应优先考虑关系数据库。
- 读写分布:读多写少的场景适合使用列式数据库,写多读少的场景适合使用行式数据库。
- 安全性:关系数据库在数据安全和备份方面通常有更成熟的支持。
- 运维性:NoSQL 数据库的运维复杂度通常高于关系数据库。
4、高性能缓存架构
(1)缓存的基本原理
- 目的:将可能重复使用的数据放到内存中,一次生成、多次使用,避免每次使用都去访问存储系统。
- 优势:显著提升系统性能,减轻存储系统的压力。

(2)缓存穿透
- 定义:缓存没有发挥作用,业务系统虽然去缓存查询数据,但缓存中没有数据,业务系统需要再次去存储系统查询数据。
- 常见情况:
- 数据不存在:存储系统中没有某个数据,缓存中也不会存储相应的数据。
- 缓存生成耗费时间:存储系统中存在数据,但生成缓存数据需要耗费较长时间或资源。
- 解决方案:
- 设置默认值:如果查询存储系统的数据没有找到,则直接设置一个默认值存到缓存中。
- 预生成缓存:提前生成缓存数据,减少实时生成的压力。
(3)缓存雪崩
- 定义:当缓存失效(过期)后引起系统性能急剧下降的情况。
- 常见情况:
- 缓存过期:缓存过期被清除后,业务系统需要重新生成缓存,导致大量请求集中访问存储系统。
- 解决方案:
- 更新锁机制:对缓存更新操作进行加锁保护,保证只有一个线程能够进行缓存更新。
- 后台更新机制:由后台线程来更新缓存,而不是由业务线程来更新缓存,缓存本身的有效期设置为永久,后台线程定时更新缓存。
(4)缓存热点
- 定义:特别热点的数据,如果大部分甚至所有的业务请求都命中同一份缓存数据,导致该缓存服务器压力巨大。
- 解决方案:
- 复制多份缓存副本:将请求分散到多个缓存服务器上,减轻单台缓存服务器的压力。
- 随机过期时间:不同的缓存副本设置不同的过期时间,避免同时生成同时失效的情况。
(5)缓存与存储系统的一致性
- 挑战:缓存和存储系统之间的数据一致性问题。
- 解决方案:
- 同步刷新缓存:当更新了某些信息后,立刻让缓存失效。
- 适当容忍不一致:例如,商品列表中的价格可以在一定范围内容忍不一致。
- 关键信息不缓存:对于查询简单且效率高的数据(如库存、价格),可以直接从数据库查询。
(6)缓存设计的注意事项
- 数据选择:确定哪些数据需要缓存,哪些数据不需要缓存。
- 触发机制:确定缓存的触发时机和方式。
- 缓存层次和粒度:考虑网关缓存、本地缓存、分布式缓存等不同层次的缓存。
- 缓存过期策略:设置合理的缓存过期时间和过期策略。
(7)实际案例
- 缓存穿透:通过设置默认值解决数据不存在的问题。
- 缓存雪崩:通过更新锁机制和后台更新机制解决缓存过期后的性能问题。
- 缓存热点:通过复制多份缓存副本和随机过期时间解决热点数据的压力问题。
5、单服务器高性能模式:PPC 与 TPC
(1)高性能架构的重要性
- 高性能追求:无论是系统设计还是代码编写,高性能都是每个程序员的目标。
- 影响因素:磁盘、操作系统、CPU、内存、缓存、网络、编程语言、架构等都会影响系统性能。
- 性能瓶颈:一个小的不当操作(如不恰当的 debug 日志)可能会大幅降低服务器性能。
(2)高性能架构设计的两个主要方面
- 提升单服务器性能:将单服务器的性能发挥到极致。
- 设计服务器集群方案:当单服务器无法支撑性能需求时,设计集群方案。
(3)单服务器高性能的关键
- 并发模型:选择合适的并发模型是提升单服务器性能的关键。
- I/O 模型和进程模型:并发模型的设计与操作系统的 I/O 模型及进程模型密切相关。
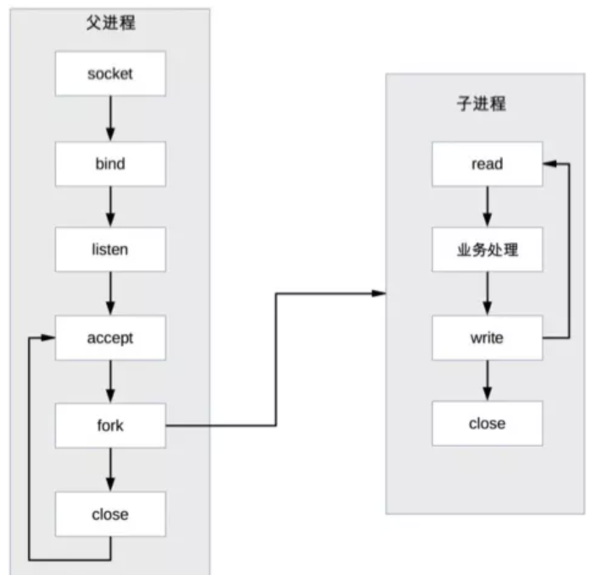
(4)PPC(Process Per Connection)模式
- 定义:每次有新的连接就新建一个进程去处理该连接的请求。
- 优点:实现简单,适合连接数较少的场景。
- 缺点:
- 创建进程代价高。
- 父子进程通信复杂。
- 支持的并发连接数量有限(通常几百个)。
(5)Prefork 模式
- 定义:系统启动时预先创建好进程,然后开始接受用户请求。
- 优点:减少创建进程的时间,提高响应速度。
- 缺点:
- 仍然存在父子进程通信复杂的问题。
- 支持的并发连接数量有限。
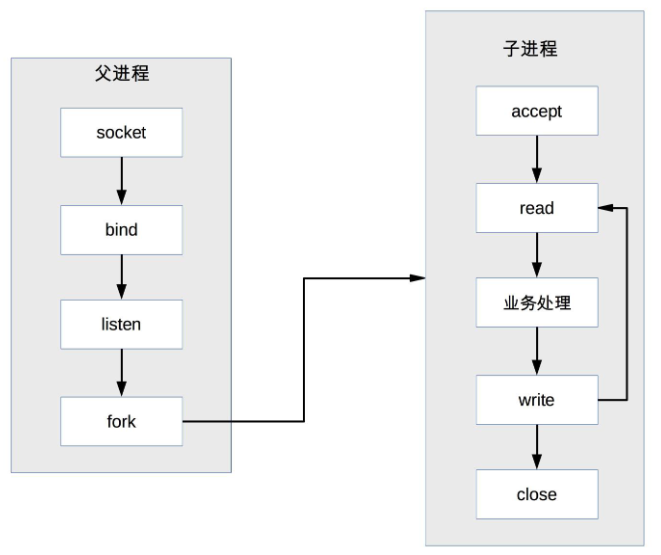
(6)TPC(Thread Per Connection)模式
- 定义:每次有新的连接就新建一个线程去处理该连接的请求。
- 优点:
- 创建线程比创建进程代价低。
- 线程通信比进程通信简单。
- 缺点:
- 创建线程也有一定代价,高并发时仍有性能问题。
- 存在线程调度和切换的代价。
- 可能出现死锁问题。
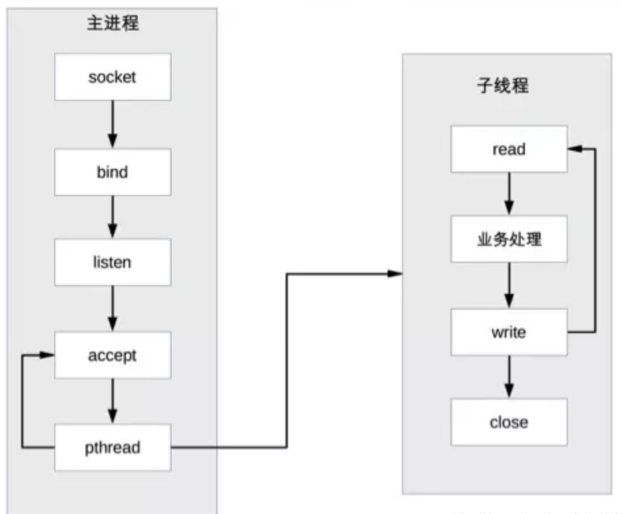
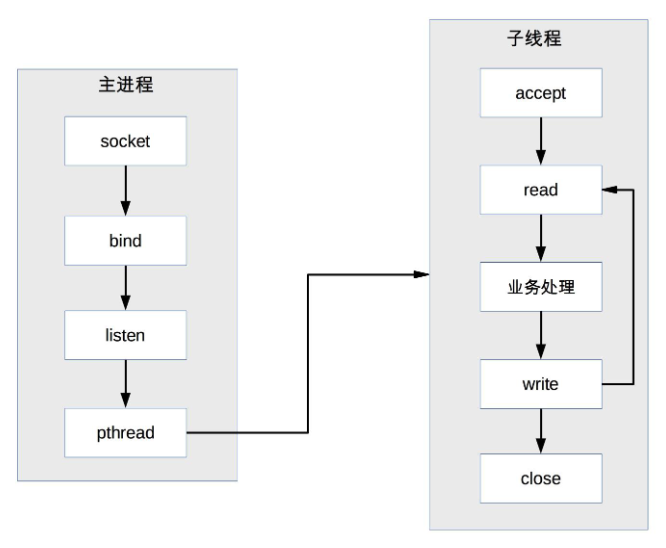
(7)Prethread 模式
- 定义:系统启动时预先创建好线程,然后开始接受用户请求。
- 优点:减少创建线程的时间,提高响应速度。
- 实现方式:
- 主进程 accept,然后将连接交给某个线程处理。
- 子线程都尝试去 accept,最终只有一个线程 accept 成功。
- 缺点:
- 线程间的互斥和共享引入了复杂度。
- 多线程互相影响,可能导致整个进程退出。
(8)不同并发模式的适用场景
- 高连接数、高请求数:例如抢购、双十一等,需要使用 I/O 复用模型或异步 I/O 模型。
- 常量连接、高请求数:例如中间件,可以使用 PPC 或 TPC。
- 高连接数、常量请求数:例如门户网站,可以使用 I/O 复用模型。
- 常量连接、常量请求数:例如内部运营系统、管理系统,可以使用 PPC 或 TPC。
(9)性能指标
- 响应时间(RT):用户请求的响应时间。
- 并发数(Concurrency):系统可以同时处理的请求数。
- 吞吐量(TPS):系统单位时间内处理的请求数。
- 关系:吞吐量 = 并发数 / 平均响应时间。
6、 单服务器高性能模式:Reactor 与Proactor
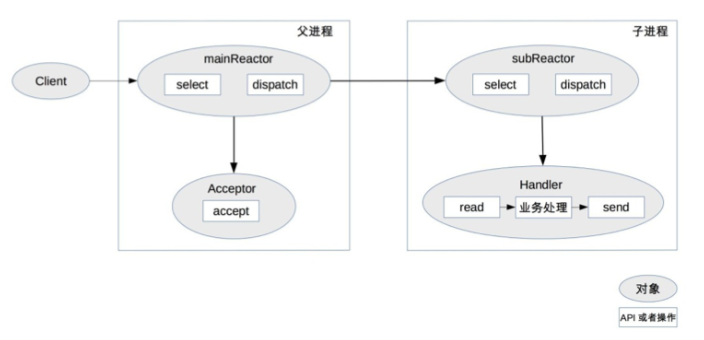
(1)Reactor 模式
- 背景:传统的 PPC(每连接一个进程)和 TPC(每连接一个线程)模式在高并发场景下性能不佳,因为每次连接都需要创建和销毁进程或线程,资源消耗大。
- 核心思想:通过资源复用(进程池或线程池)和 I/O 多路复用技术,提高单服务器的并发处理能力。
- 关键组件:
- Reactor:负责监听和分配 I/O 事件。
- 处理资源池:负责处理具体的业务逻辑。
- 实现方式:
- 单 Reactor 单进程/线程:简单,但无法充分利用多核 CPU。
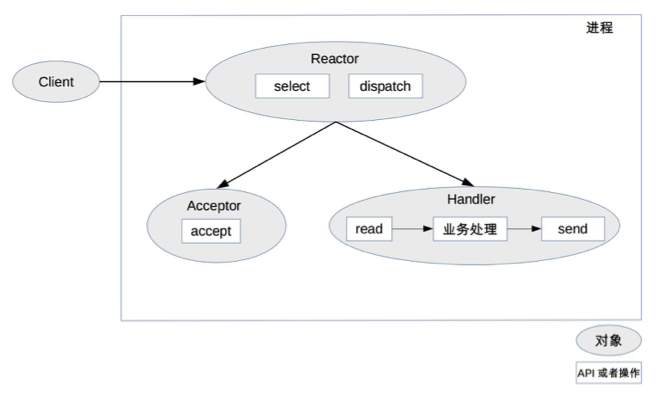
- 单 Reactor 多线程:利用多核 CPU,但线程间同步复杂。

- 多 Reactor 多进程/线程:进一步提高并发处理能力,但实现复杂度较高。
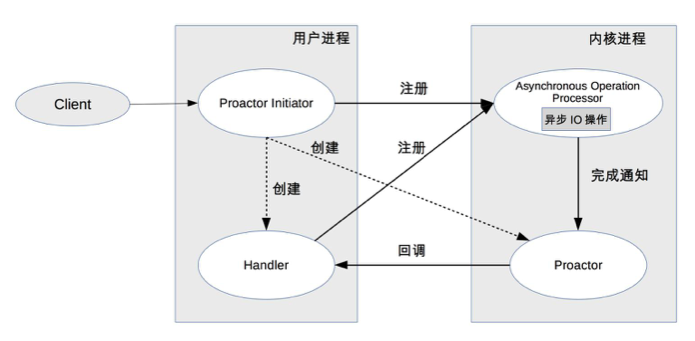
(2)Proactor 模式
- 背景:Reactor 模式虽然提高了并发处理能力,但 I/O 操作仍然是同步的,限制了性能。
- 核心思想:通过异步 I/O 操作,进一步提升性能。操作系统内核在 I/O 操作完成后通知用户进程。
- 关键组件:
- Initiator:创建 Proactor 和 Handler,并注册到内核。
- Asynchronous Operation Processor:处理 I/O 操作并通知 Proactor。
- Proactor:根据事件类型调用相应的 Handler 进行业务处理。
- Handler:完成业务处理,可以注册新的 Handler 到内核。
(3)I/O 模型
- 阻塞 I/O:I/O 操作过程中进程会被阻塞。
- 非阻塞 I/O:I/O 操作过程中进程不会被阻塞,但需要不断轮询。
- I/O 多路复用:通过一个阻塞对象监听多个 I/O 事件,提高效率。
- 信号驱动 I/O:通过信号通知 I/O 事件。
- 异步 I/O:操作系统内核在 I/O 操作完成后通知用户进程。
(4)应用场景
- 单 Reactor 单进程/线程:适用于业务处理非常快速的场景,如 Redis。
- 单 Reactor 多线程:适用于需要充分利用多核 CPU 的场景,如 Netty。
- 多 Reactor 多进程/线程:适用于高并发、高性能要求的场景,如 Nginx 和 Memcache。
7、高性能负载均衡:分类与架构
(1)高性能集群的重要性
- 性能天花板:单服务器的性能总有上限,无法满足高并发需求。
- 计算特点:相同输入和逻辑应产生相同输出,适合分布式计算。
(2)负载均衡的分类
- DNS 负载均衡
- 优点:简单、成本低、就近访问。
- 缺点:更新不及时、扩展性差、分配策略简单。
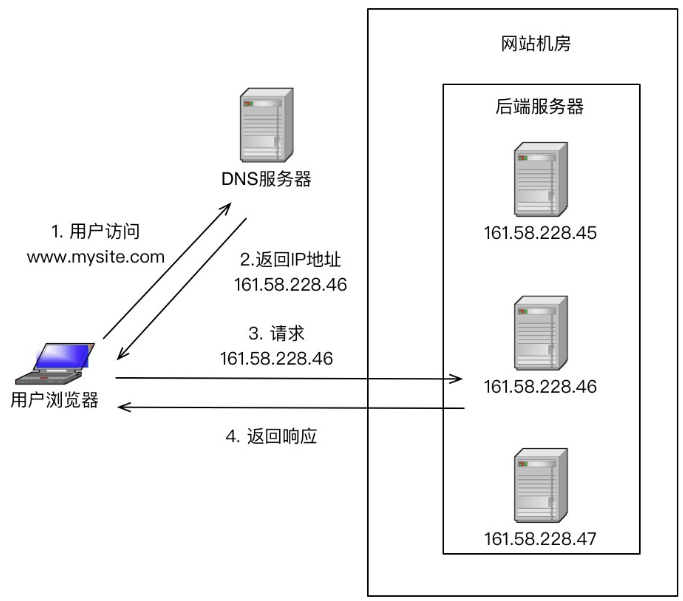
- 硬件负载均衡
- 优点:功能强大、性能高、稳定性强、支持安全防护。
- 缺点:价格昂贵、扩展能力差。
- 软件负载均衡
- 优点:便宜、灵活、扩展性强。
- 缺点:性能一般、功能不如硬件负载均衡强大。
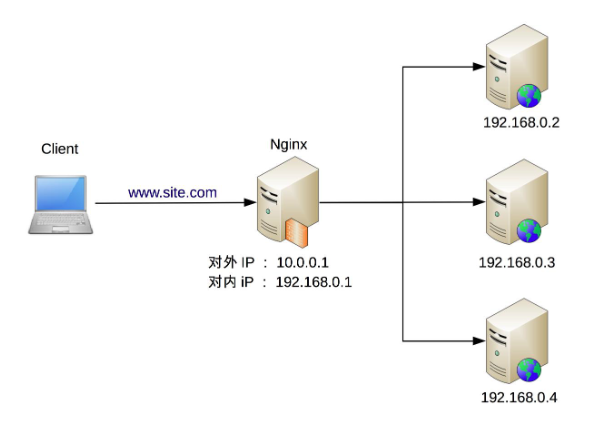
(3)负载均衡的典型架构
- 地理级别负载均衡:使用 DNS 实现,根据用户地理位置分配到最近的机房。
- 集群级别负载均衡:使用硬件负载均衡设备(如 F5)实现,将请求分配到多个集群。
- 机器级别负载均衡:使用软件负载均衡(如 Nginx 或 LVS)实现,将请求分配到具体服务器。
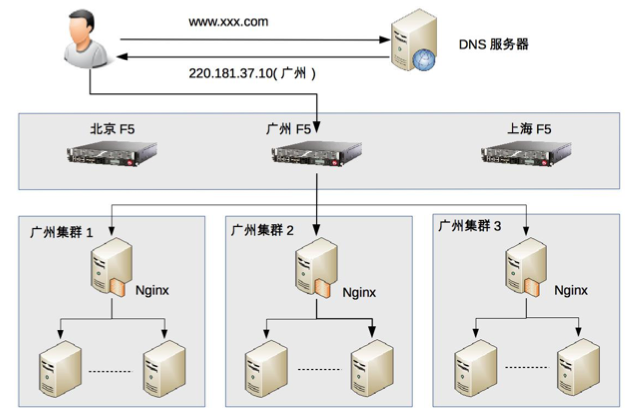
(4)设计日活跃用户 1000 万的论坛负载均衡集群
- 流量评估:
- 平均 QPS:1000 万 DAU 换算成秒级,平均约 116 QPS。
- 峰值 QPS:考虑波峰波谷,峰值约为均值的 3-5 倍。
- 架构设计:
- DNS 负载均衡:实现地理级别的负载均衡,将用户分配到最近的机房。
- 硬件负载均衡:在每个机房内部使用 F5 设备实现集群级别的负载均衡。
- 软件负载均衡:在每个集群内部使用 Nginx 实现机器级别的负载均衡。
- 其他考虑:
- 高可用:使用 Keepalived 实现故障转移。
- 读写分离:数据库采用一主多从架构,提高读性能。
- 缓存设计:使用缓存减少数据库压力,提高响应速度。
8、高性能负载均衡:算法
(1)负载均衡算法分类
- 任务平分类:将任务平均分配给服务器,可以是绝对数量的平均,也可以是比例或权重上的平均。
- 负载均衡类:根据服务器的当前压力进行任务分配,压力可以用 CPU 负载、连接数、I/O 使用率等指标衡量。
- 性能最优类:根据服务器的响应时间进行任务分配,优先将任务分配给响应最快的服务器。
- Hash 类:根据任务中的某些关键信息进行 Hash 运算,将相同 Hash 值的请求分配到同一台服务器上。
(2)常见负载均衡算法及其优缺点
- 轮询
- 优点:简单,无须关注服务器状态。
- 缺点:无法感知服务器状态,可能导致任务分配不合理。
- 加权轮询
- 优点:解决了不同服务器处理能力差异的问题。
- 缺点:仍然无法根据服务器的实时状态进行任务分配。
- 负载最低优先
- 优点:能够根据服务器的当前压力进行任务分配,提高资源利用率。
- 缺点:复杂度高,需要收集和分析服务器状态。
- 性能最优优先
- 优点:从客户端角度优化,优先分配给响应最快的服务器。
- 缺点:复杂度高,需要收集和分析响应时间。
- Hash 类
- 优点:满足特定业务需求,如会话保持。
- 缺点:可能导致某些服务器负载过高。
(3)微信抢红包高并发架构
- 发红包:可以采用加权轮询算法,简单适用,成功后返回红包ID给客户端。
- 抢红包:根据红包ID进行Hash负载均衡,将所有相关请求路由到同一台服务器,减少后端逻辑复杂度。
- 查询红包:同样根据红包ID进行Hash负载均衡,确保数据一致性。
- 回收红包:并发要求较低,可以采用简单的轮询算法。
(4)其他注意事项
- 负载均衡系统需要感知服务器状态:对于负载最低优先和性能最优优先算法,负载均衡系统需要收集和分析服务器状态,这增加了复杂度。
- 业务特点决定算法选择:不同的业务场景需要选择不同的负载均衡算法,如会话保持业务适合使用Hash类算法,高并发业务适合使用负载最低优先算法。
- 调优和测试:无论选择哪种算法,都需要进行调优和测试,确保系统在高并发场景下的稳定性和性能。