DynRefer是由中国科学院大学于2024年提出的用于1种用于区域级多模态任务的模型。DynRefer 通过模拟人类视觉认知过程,显著提升了区域级多模态识别能力。通过引入人眼的动态分辨率机制, 能够以同时完成区域识别、区域属性检测和区域字幕生成任务。

文章链接:https://arxiv.org/abs/2405.16071
代码链接:https://github.com/callsys/DynRefer
一.介绍
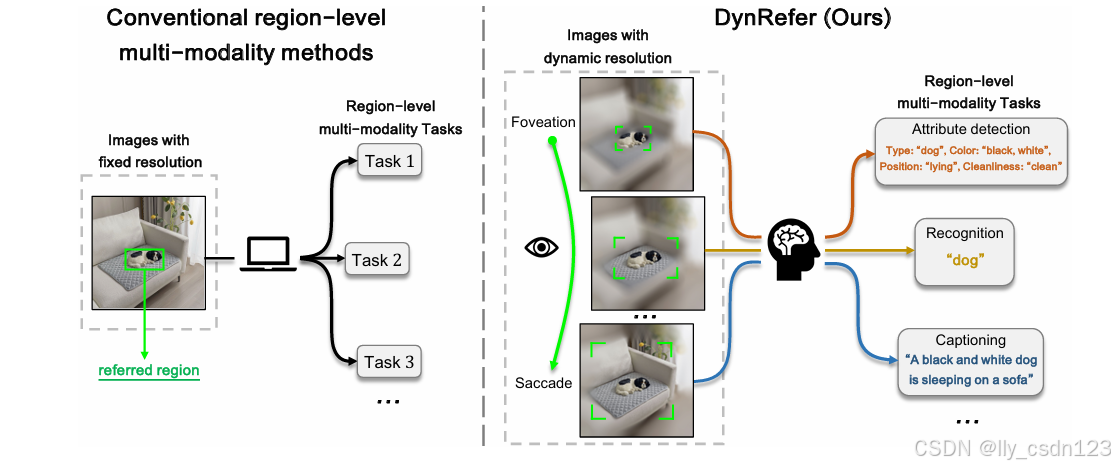
区域级多模态任务模仿人类认知过程,根据特定的任务要求(开放词汇检测、属性识别、字幕生成等)将参考的图像区域翻译为语言输出。现有的方法以固定的分辨率作为输入,限制模型对于丰富分辨率的处理能力且难以捕获上下文信息。
人类的认知系统可以根据特定的语言描述(任务要求)通过注视和调整眼动的过程来调整视觉输入,形成非均匀的分辨率。现存的多模态大语言模型不具备视觉区域选择能力,导致应用于具体任务时缺乏特异性。
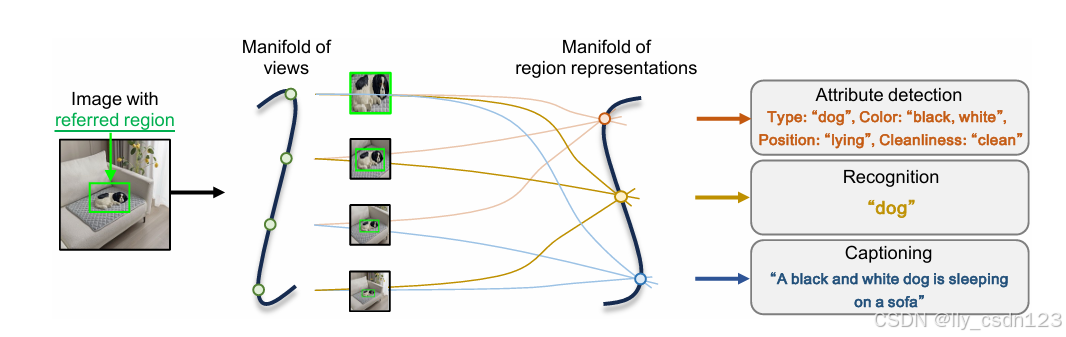
受视觉认知机制的启发,即增加聚焦区域的分辨率,同时抑制不相关的背景区域,提出动态分辨率方法,如下图所示。
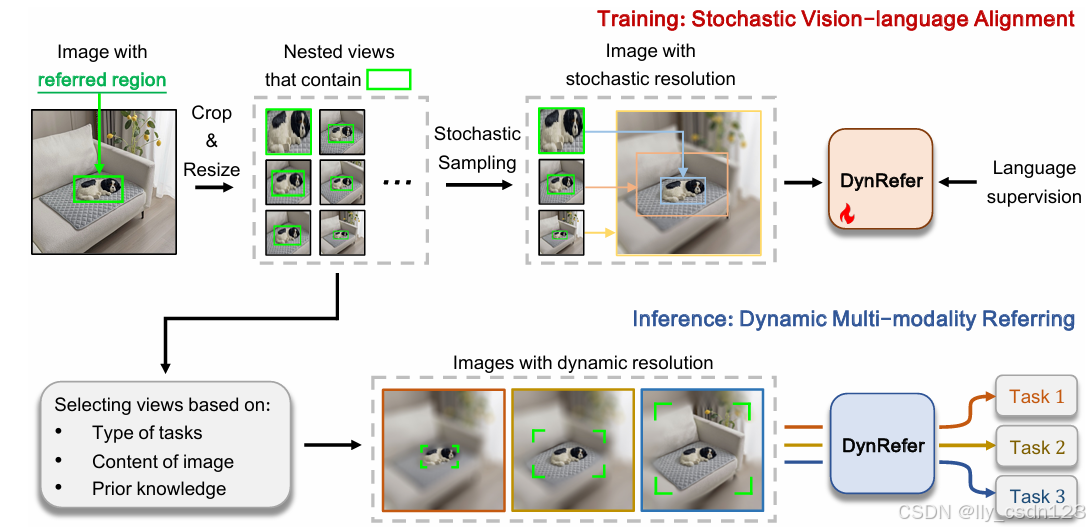
DynRefer在训练时引入随机视觉-语言对齐,首先,对参考区域的周围进行采样,构建随机分辨率的图像;然后,将图像嵌入于具体任务的语言描述对齐。在推理时,执行动态多模态参考,形成与图像和语言描述先验相对应的动态分辨率图像。
二.相关工作
视觉语言模型
根据训练目标,Vision-Language Models(VLMs)可以分为图文对比学习、图文匹配、语言建模3种类型。应用于区域级任务时,模型在区域-文本对上进行训练以获取区域级理解能力。
区域级多模态任务
(1) 检测
基于对比学习的方法通过计算图像划定区域的特征与文本特征之间的相似度确定检测类别;基于语言建模的方法借助大语言模型,得到开放集中和图像区域最可能的类别。
(2) 属性
一些研究基于COCO Attributes、VAW等属性数据集,训练多分类网络实现属性预测;一些研究受到CLIP 、OVAD模型的启发,从字幕中得到属性类别(开集预测)。
(3)字幕生成
使用多模态模型生成区域级字幕的方法被研究者广泛采用。GRiT通过将对象类别看作为简短的字幕来统一分类和字幕生成任务;CapDet则是在预训练设置中将字幕与开放集检测结合起来。
视觉认知动态分辨率
视觉认知领域的研究表明,人类视觉系统具有动态分辨率。相比之下,计算机视觉系统缺乏动态机制,只能捕获静态视图。
三.方法
3.1 随机视觉-语言对齐
3.1.1 多视图构建
原始图像 x 被裁剪为多个候选视图。裁剪区域的计算方式为
其中,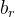
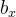
![\left [ t_{1},t_{2},..., t_{n}\right ]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUNsZWZ0JTIwJTVCJTIwdF8lN0IxJTdEJTJDdF8lN0IyJTdEJTJDLi4uJTJDJTIwdF8lN0JuJTdEJTVDcmlnaHQlMjAlNUQ%3D)
3.1.2 随机多视图嵌入
采样的n个视图,经过ViT模块获得空间特征并后接RoI Align模块得到区域嵌入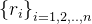
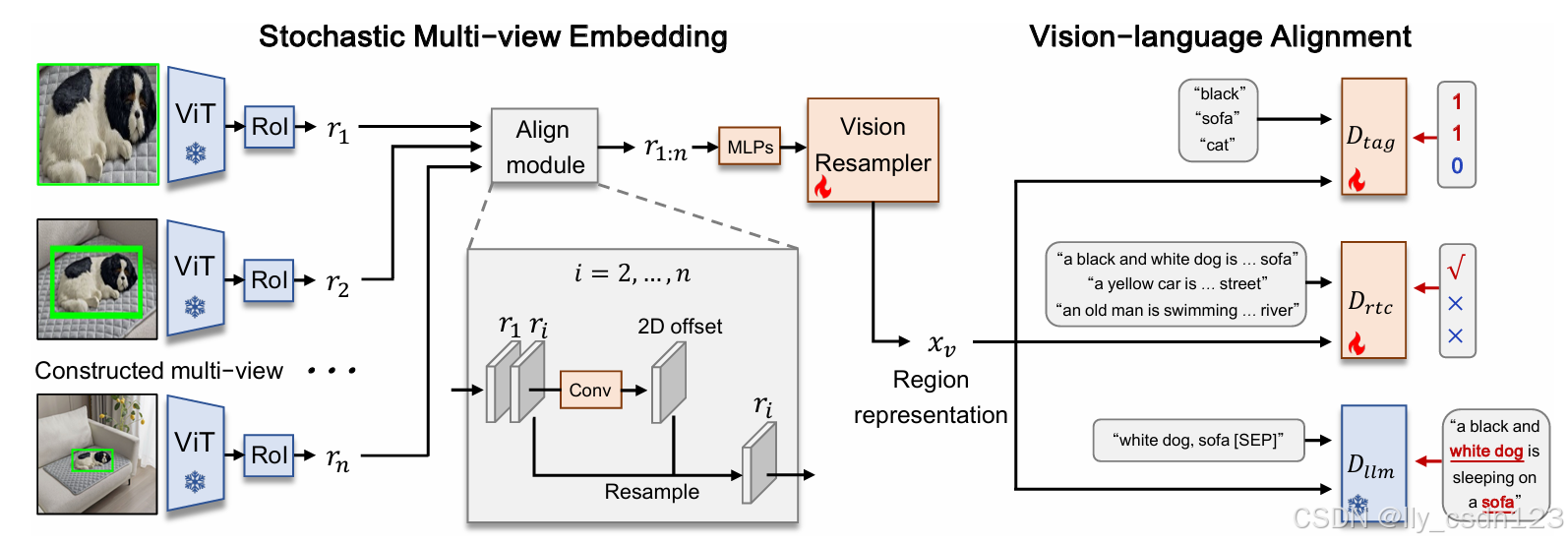
由于crop、resize和 RoI-Align 操作引入的空间误差,区域嵌入在空间上并不对齐。受 deformable convolution 启发,提出了1个对齐模块Align module,通过将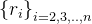
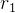
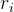
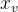
3.1.3 视觉语言对齐
通过随机多视图嵌入模块计算得到的区域表示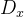
i) 图像区域标签生成。采用基于查询的轻量级识别解码器进行区域标签生成。解码器 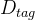
ii) 区域 - 文本对比学习。解码器 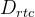
iii) 语言建模。采用预训练的大语言模型 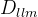
3.2 动态多模态参考
在推理过程中,通过调整插值系数t=
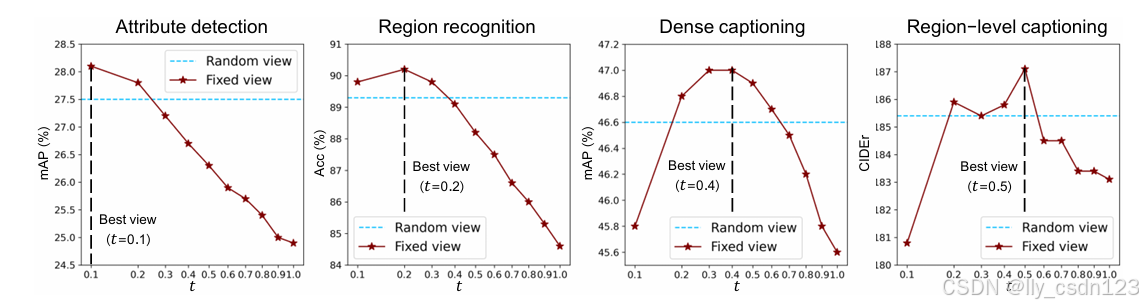
可以看出,属性检测在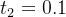
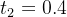
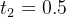

当任务已知时,可以根据任务特性采样合适的视图;当任务未知时,需要根据插值系数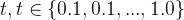
其中,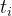
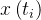
3.3 多种视图
DynRefer学习多个区域表示
四.实验
DynRefer基于LAVIS框架实现,LLM模型采用Flan-T5XL,视觉重采样采用Q-former,采样视图呗调整为224*224分辨率,模型在VG V1.2上进行训练。
4.1 性能
区域级字幕
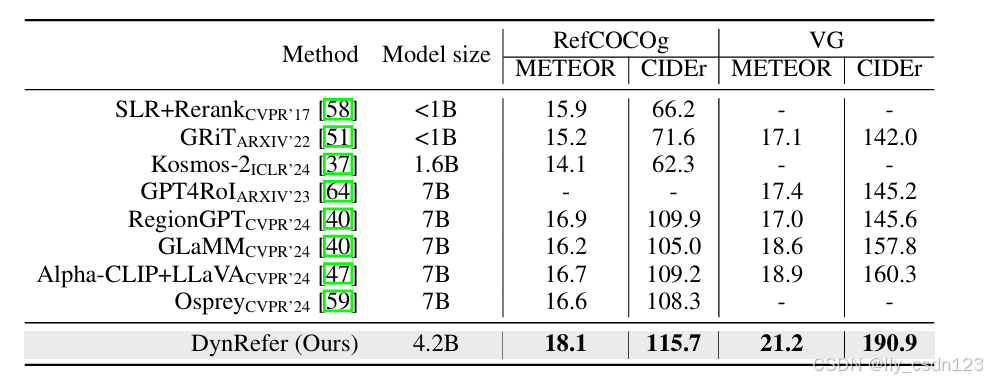
在区域级字幕任务中,与SOTA方法的对比结果如下。
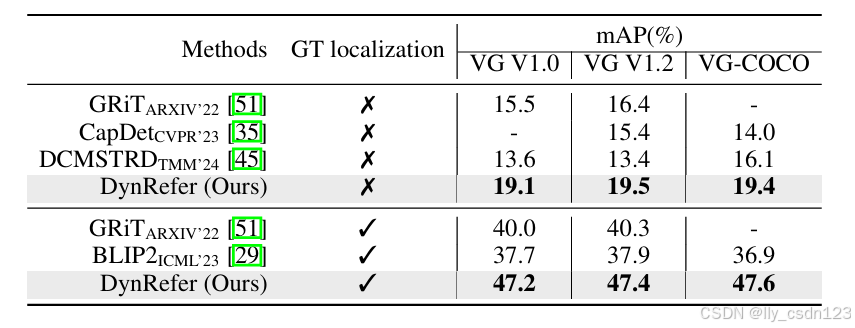
在密集字幕中,与SOTA方法的对比结果如下。
开放词汇属性识别
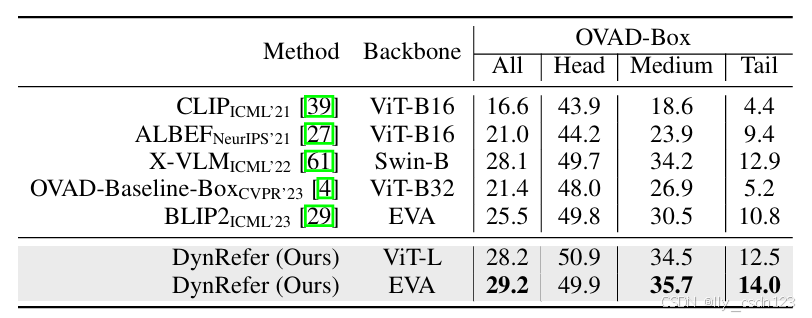
在OVAD数据集上的表现如下表所示。
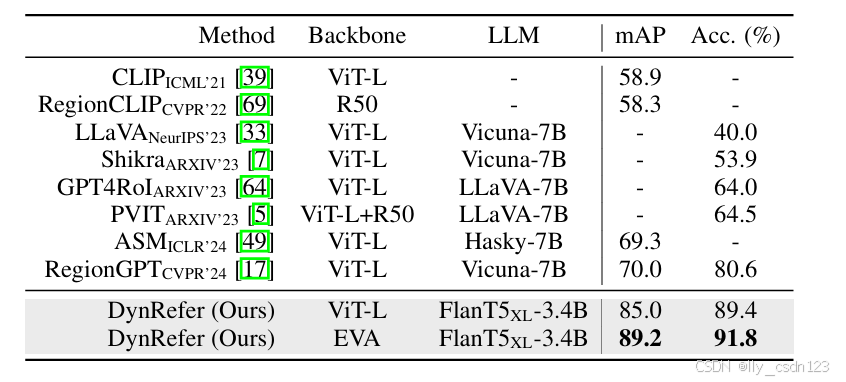
开放词汇区域识别
在COCO-2017数据集上的表现如下表所示。
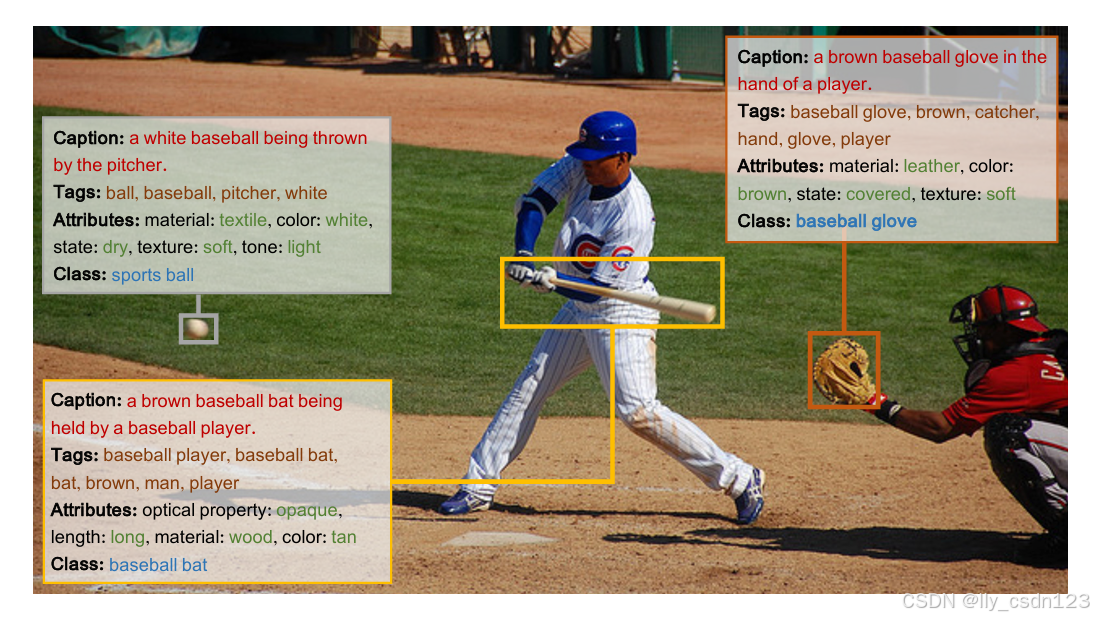
多任务能力
DynRefer模型可以实现多模态多任务处理(字幕、标签、属性、类别),如下图所示。