文章目录
图像分割算法类型
正如我在目标检测系列中提到的,图像分割(语义、实例、全景)和目标检测任务是相辅相成的,它们的发展在技术层面已经达到了一个平台。图像分割领域的入门必读文献如下:
| 类别 | 流程/算法 | 论文、年份 | Google学术引用次数 |
|---|---|---|---|
| 基于全卷积的图像分割模型(Encoder+Decoder) | |||
| FCN | 《Fully convolutional networks for semantic segmentation》,2015 | 47741 | |
| SegNet | 《SegNet:A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation》,2015 | 18234 | |
| UNet | 《U-net: Convolutional networks for biomedical image segmentation》,2015 | 74360 | |
| Deeplab v1 | 《Semantic image segmentation with deep convolutional nets and fully connected crfs》,2015 | 5627 | |
| PSPNet | 《Pyramid Scene Parsing Network》,2017 | 13670 | |
| Deeplab v2 | 《Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs》, 2017 | 17746 | |
| Deeplab v3 | 《Rethinking atrous convolution for semantic image segmentation》,2017 | 8588 | |
| Deeplab v3+ | 《Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation》,2018 | 12571 | |
| 基于候选区域的图像分割模型 | |||
| Mask r-cnn | 《Mask r-cnn》,2017 | 33994 | |
| MS r-cnn | 《Mask scoring r-cnn》,2019 | 1073 | |
| 基于GAN的图像分割模型 | |||
| Seggan | 《Seggan: Semantic segmentation with generative adversarial network》,2018 | 53 | |
| Alphagan | 《Alphagan: Generative adversarial networks for natural image matting]》,2018 | 177 | |
| 基于RNN的图像分割模型 | |||
| ReSeg | 《ReSeg: A Recurrent Neural Network-Based Model for Semantic Segmentation》,2015 | 337 | |
| ViT | 《An image is worth 16x16 words: Transformers for image recognition at scale》,2020 | 33341 | |
| Swin Transformer | 《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows 》,2021 | 16264 | |
| Mask-adapted CLIP | 《Open-vocabulary semantic segmentation with mask-adapted clip》,2023 | 192 | |
| SAM | 《Segment Anything》,2023 | 2825 | |
| SAM+RSPrompter | 《RSPrompter: Learning to prompt for remote sensing instance segmentation based on visual foundation model》,2024 | 40 |
全卷积
FCN
深度学习用于图像分割的“开山之作”
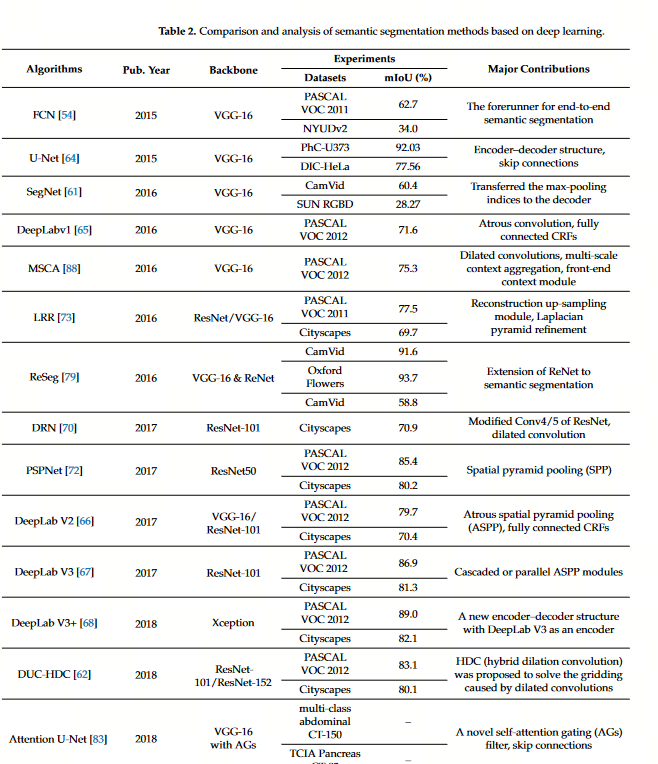
2015年,Long等人提出了用卷积代替全连接的全卷积网络( Fully Convolutional Networks,FCNs ),使得输入任意大小的图像成为可能,FCN架构如下图所示。先通过编码器(Encoder)进行下采样提取高层语义特征,然后采用反卷积进行上采样。
ps:反卷积又称转置卷积,反卷积入门见:转置卷积(Transpose Convolution) — PaddleEdu documentation (paddlepedia.readthedocs.io)
![![[Pasted image 20240402160756.png]]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuL2RpcmVjdC81OWNiN2ZiNmExMDA0NjQzYmQ3NjQ2MWFjMmY2ZGNmZS5wbmc%3D)
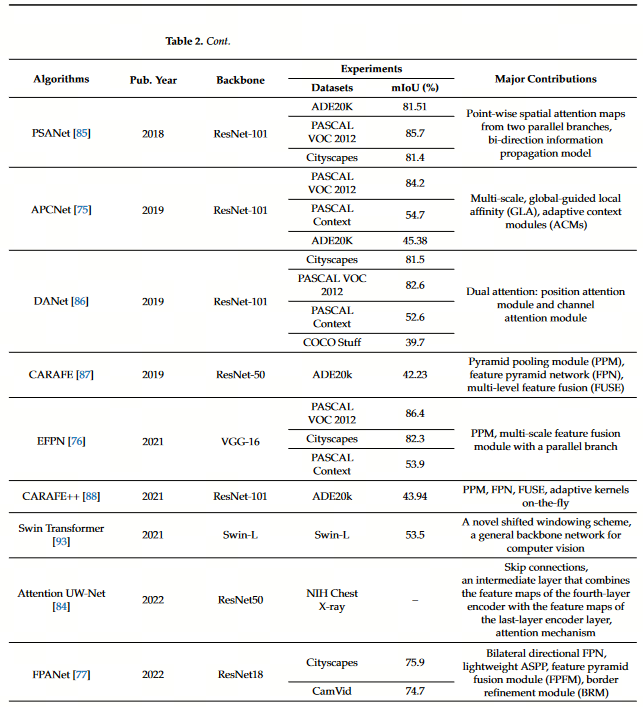
FCN-32s、FCN-16s、FCN-8s的区别在于跳连的不同(分别从32、16、8倍下采样的特征图恢复至输入大小)
![![[Pasted image 20240402160842.png]]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuL2RpcmVjdC9lZDExNjk1YzE2OWQ0Y2ViYjIyYjBjYjNmZmEwYTdlNy5wbmc%3D)
- FCN-8s:((pool5 2x unsampled + pool4) 2x unsampled + pool3) 8x unsampled
- FCN-16s:(pool5 2x unsampled + pool4) 16x unsampled
- FCN-32s:pool5 32x unsampled
FCNs证明了神经网络可以进行端到端的语义分割训练,为深度神经网络在语义分割方面奠定了基础
优点
- FCN对图像进行了像素级的分类,从而解决了语义级别的图像分割问题;
- FCN可以接受任意尺寸的输入图像,可以保留下原始输入图像中的空间信息;
缺点
- 得到的结果由于上采样的原因比较模糊和平滑,对图像中的细节不敏感;
- 对各个像素分别进行分类,没有充分考虑像素与像素的关系,缺乏空间一致性。
SegNet
SegNet是剑桥提出的旨在解决自动驾驶或者智能机器人的图像语义分割深度网络,SegNet与FCN的思路相似,区别在于在decoder中使用逆池化(unpooling)对特征图进行上采样,unpooling与反卷积相比,减少了参数量和运算量。
ps:
- 正向传播时会记录池化窗口中的最大值和最大值所在位置,unpooling时将所选取的最大值重新放置到对应的位置上,其他位置的值都设置为0。这一步仅生成稀疏特征图
- 然后这些稀疏特征图与可训练的解码器滤波器组进行卷积,以生成密集的特征图。
- 除了最后一个解码器(对应于第一个编码器)外,网络中的其他解码器生成的特征图的大小和通道数与其编码器输入相同。
![![[Pasted image 20240402163735.png]]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuL2RpcmVjdC81NzhmNGRlMTBlMWQ0OTJlODllNjhlN2NhYmY5M2Y0MC5wbmc%3D)
![![[Pasted image 20240402162437.png]]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuL2RpcmVjdC84ZjJhMDNjNmI5MzM0NGVlYmE5MDcxYWVhMzkzZjc0Ny5wbmc%3D)
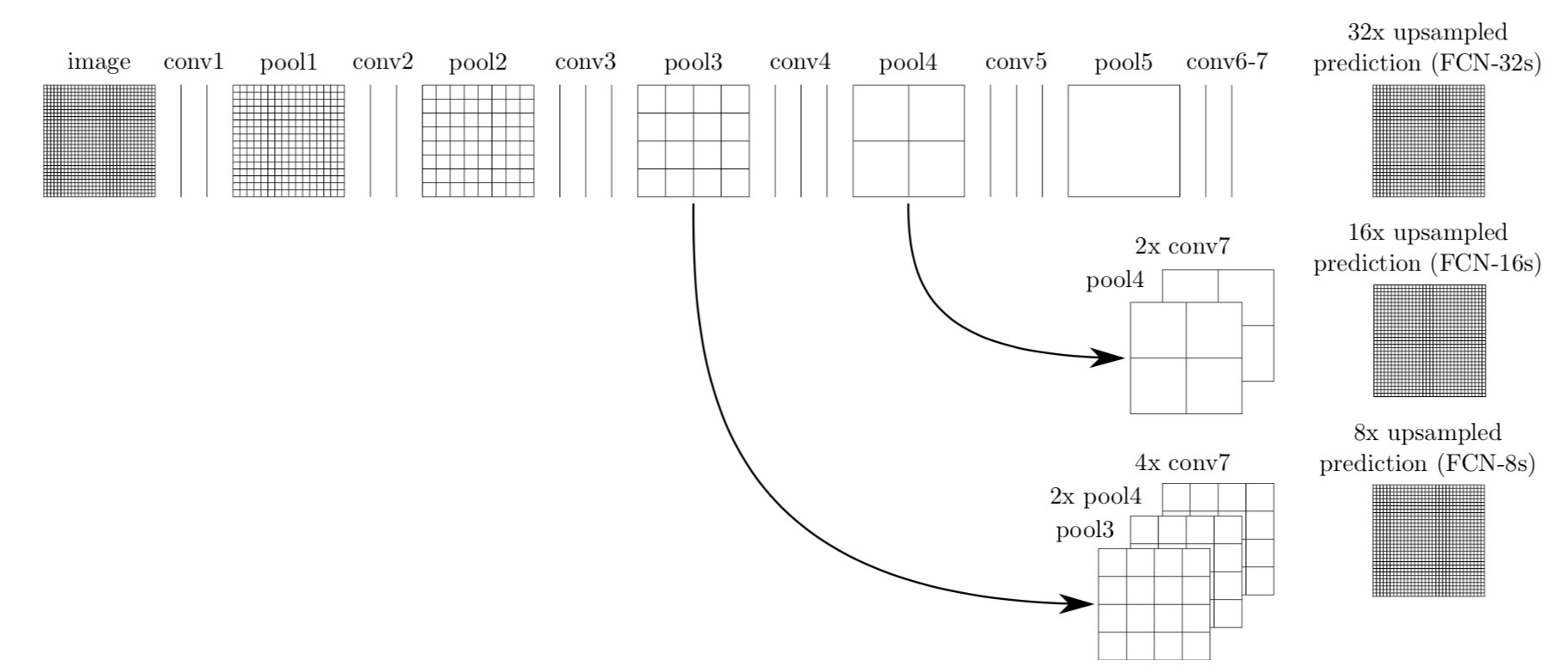
ps:《Understanding Convolution for Semantic Segmentation,2018》一文提出了反卷积、unpooling之外的第三种上采样方法:密集上采样卷积DUC(dense up-sampling convolution),将长宽尺寸上的损失通过通道维度来弥补,和反卷积相比无需再进行padding操作,如下图所示。
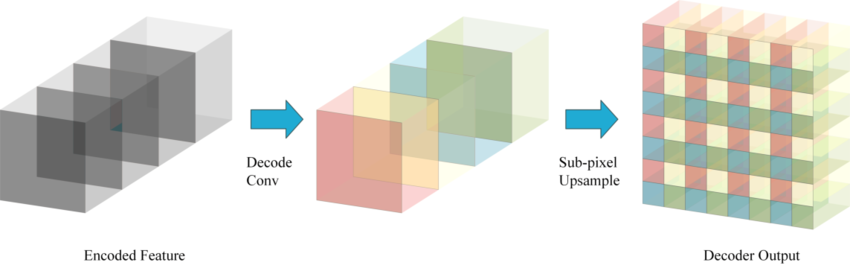
UNet
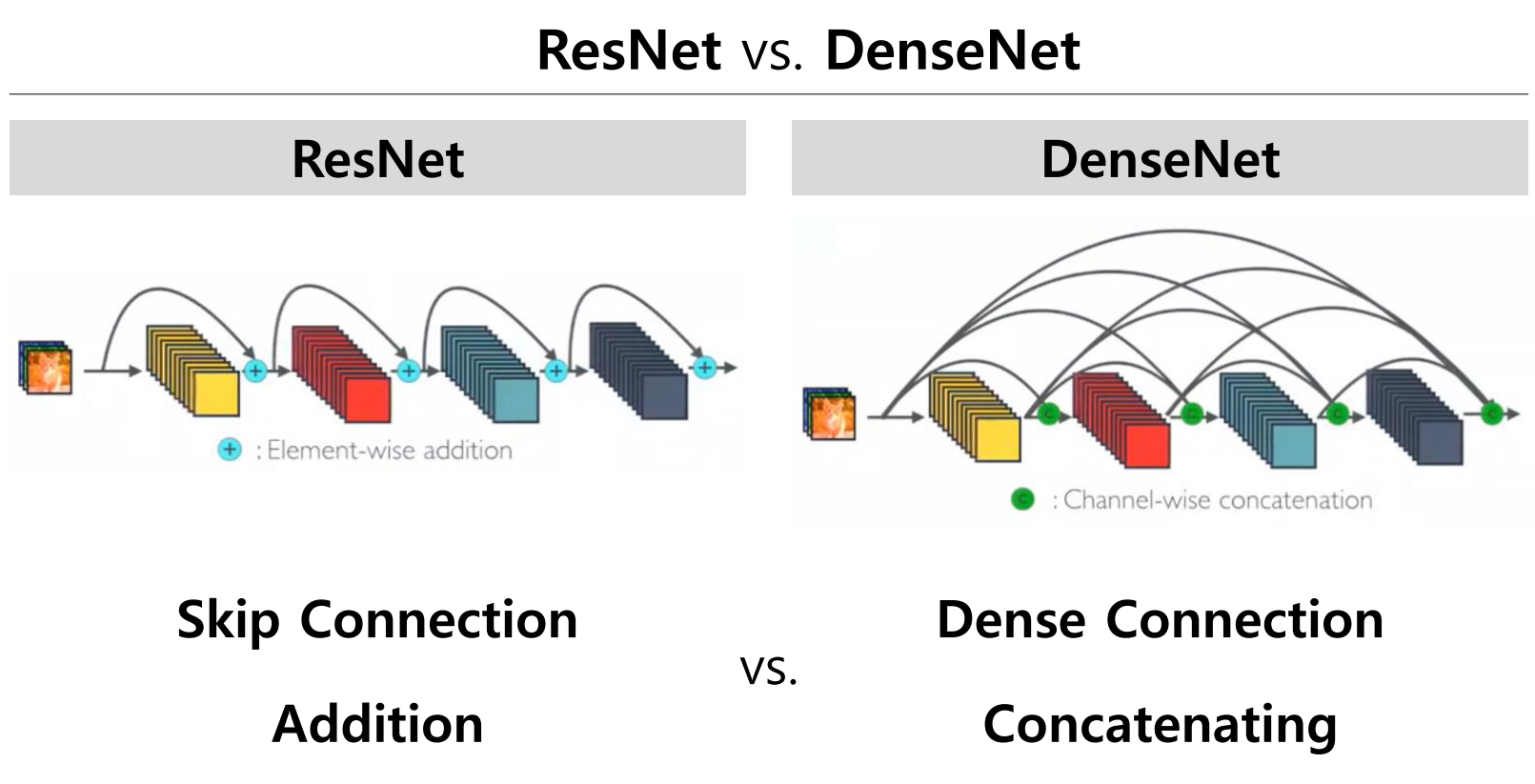
随着深度神经网络的训练,性能随着深度的增加而下降,这是一个退化问题。为了改善这个问题,在ResNet和DenseNet中提出了不同的跳跃连接结构,可以看出主要区别在于连接方式(add、concat)和连接密度,见下图。
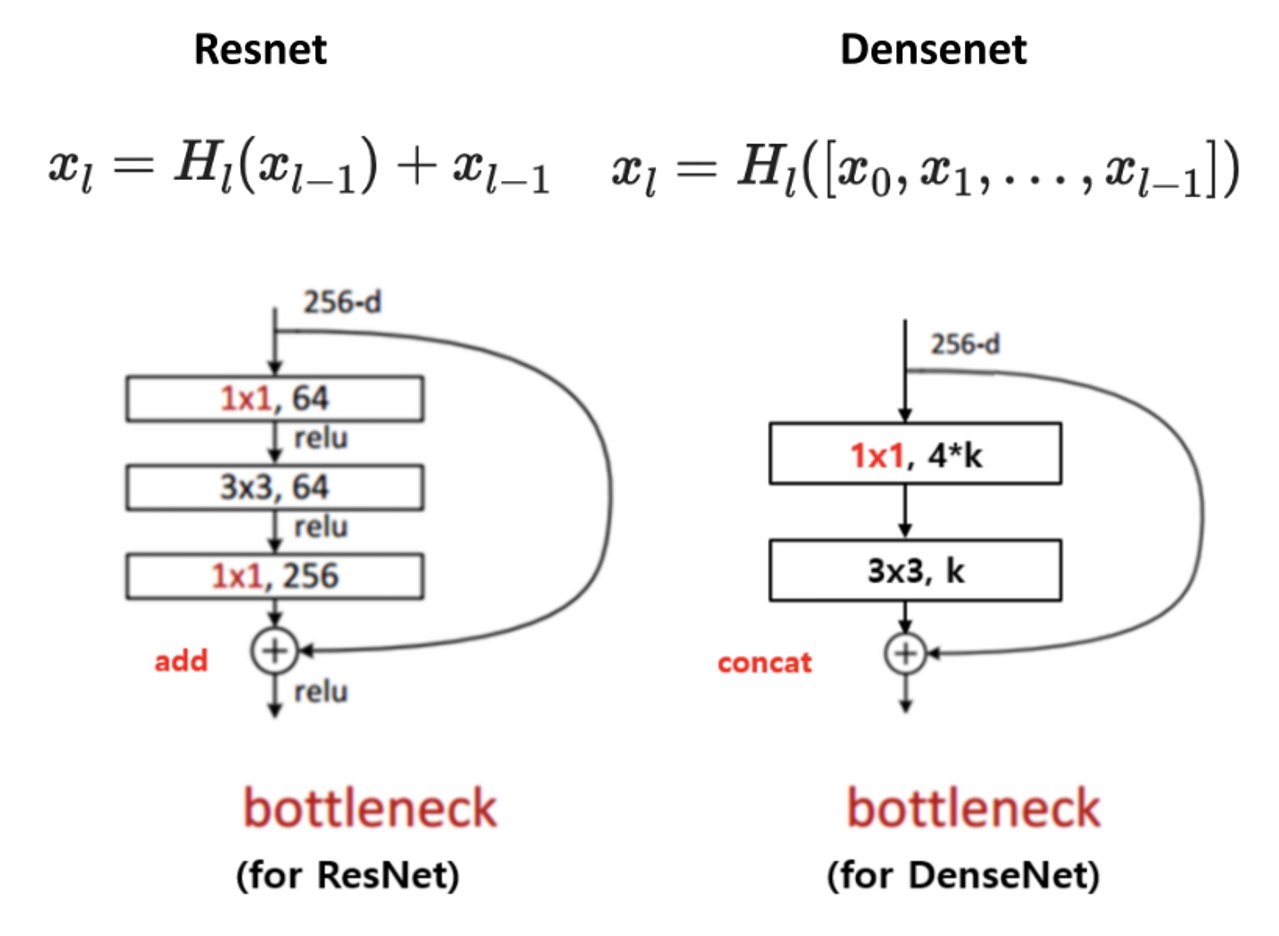
UNet提出了一种新的长跳跃连接,如下图所示,U - Net将从编码器中的层到解码器中的相应层进行特征的跳跃连接和级联,以获得图像的细粒度细节。UNet最初是为了解决基于生物显微镜的图像分割中的标注问题而提出的,此后被广泛应用于医学图像分割的研究中。
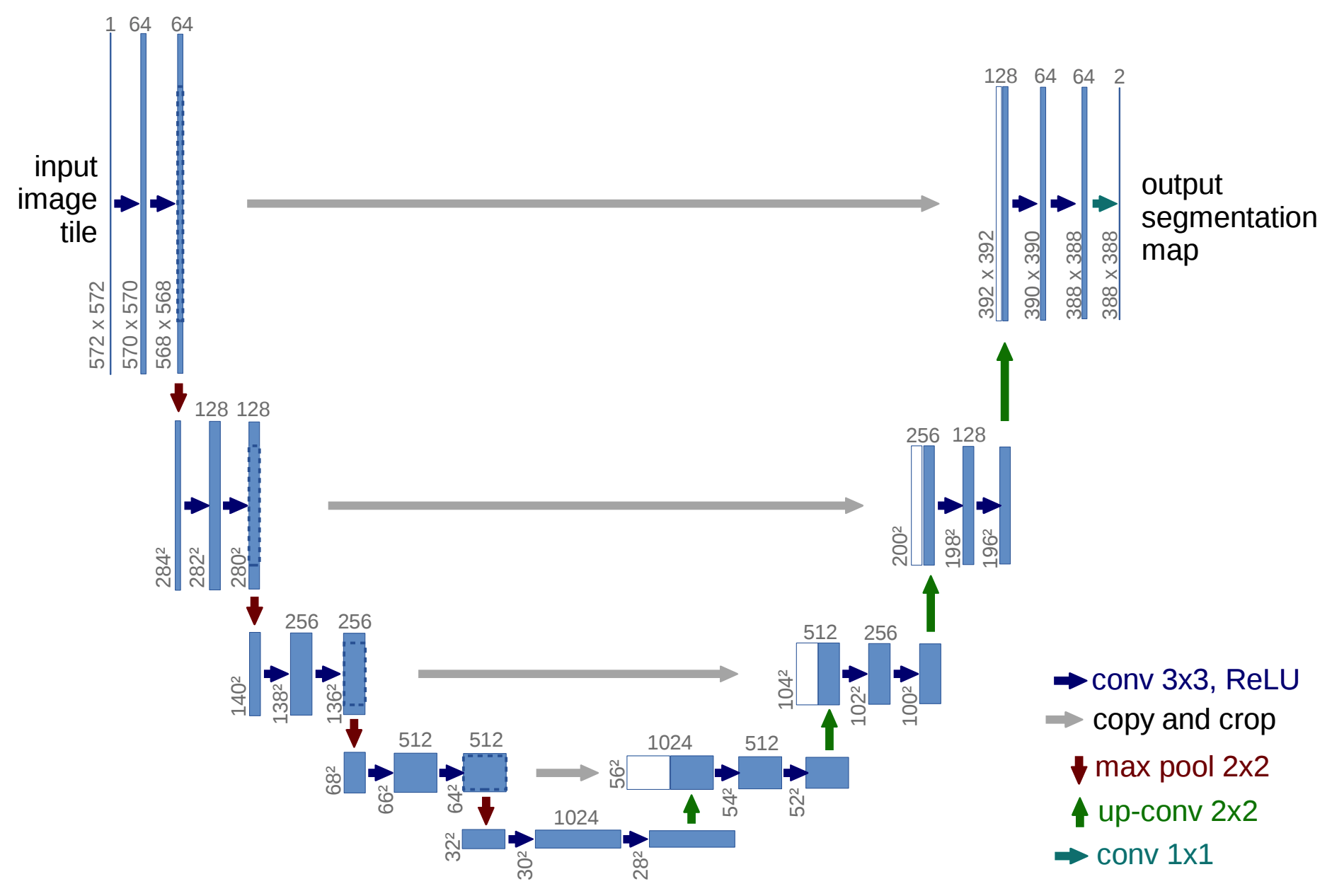
UNet的优点:
- 结构简单,在简单的小数据集中表现良好。
- U型跳连可以一定程度上补充上采样过程中丢失的信息,此外这种跳跃连接(skip connections)将不同层级的特征图连接起来,使得模型能够同时关注到低级和高级语义特征。
UNet的缺点:
- 难以确定最佳的网络深度。
- 跳连仅在编码器和解码器子网的相同比例的特征图上强制融合,施加了不必要的限制性融合方案。
Deeplab v1
在提出Deep Lab V1之前,由于池化过程中丢失了迁移不变性,以及未利用标签之间的概率关系,语义分割结果通常比较粗糙。
-
针对池化过程中丢失迁移不变性的问题,Deep Lab V1使用空洞卷积来解决下采样过程中的分辨率降低的问题
-
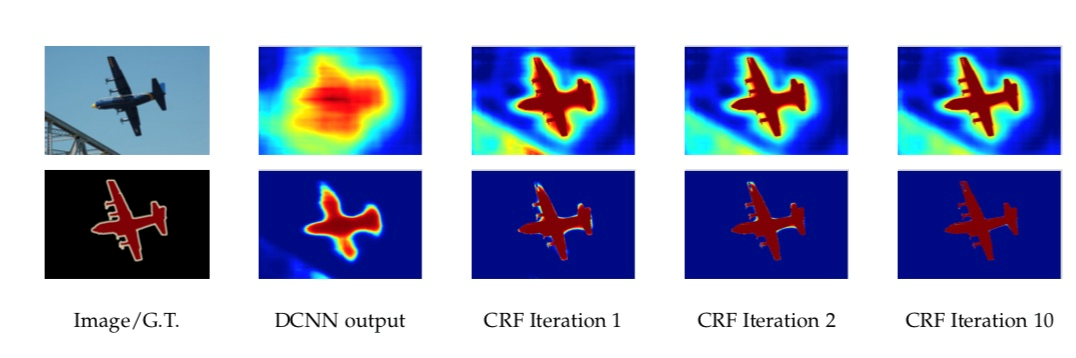
针对未利用标签之间的概率关系的问题,Deep Lab V1利用全连接条件随机场(全连接CRFs)对分割后的图像进行优化后处理,以获得多尺度下的对象和上下文信息。优化分类图像中粗糙和不确定性的标记,修正细碎的错分区域,得到更细致的分割边界。
-
空洞卷积
使用卷积或者池化操作进行下采样会导致一个非常严重的问题:图像细节信息被丢失,小物体信息将无法被重建(假设有4个步长为2的池化层,则任何小于 2 4 2^4 24 pixel 的物体信息将理论上无法重建)。
空洞卷积(Dilated Convolution),也被称为扩张卷积(Atrous Deconvolution),是针对图像语义分割问题中下采样带来的图像分辨率降低、信息丢失问题而提出的一种新的卷积思路。
空洞卷积通过引入扩张率(Dilation Rate)这一参数使得同样尺寸的卷积核获得更大的感受野(类似对卷积核做padding从而扩大卷积核)。相应地,也可以使得在相同感受野大小的前提下,空洞卷积比普通卷积的参数量更少。
空洞卷积详见
https://paddlepedia.readthedocs.io/en/latest/tutorials/CNN/convolution_operator/Dilated_Convolution.html
- 全连接CRFs
上采样虽然能够将特征图恢复至原图尺寸,但也造成了特征的损失,自然而然产生了分类目标边界模糊的问题。为了得到更精确的最终分类结果,通常要进行一些图像后处理。
为什么使用CRF呢,简单来说,CRF就是线性条件随机场,是只考虑概率图中相邻变量是否满足特征函数的一个模型。正好解决之前模型未利用标签之间的概率关系的问题,如下图。
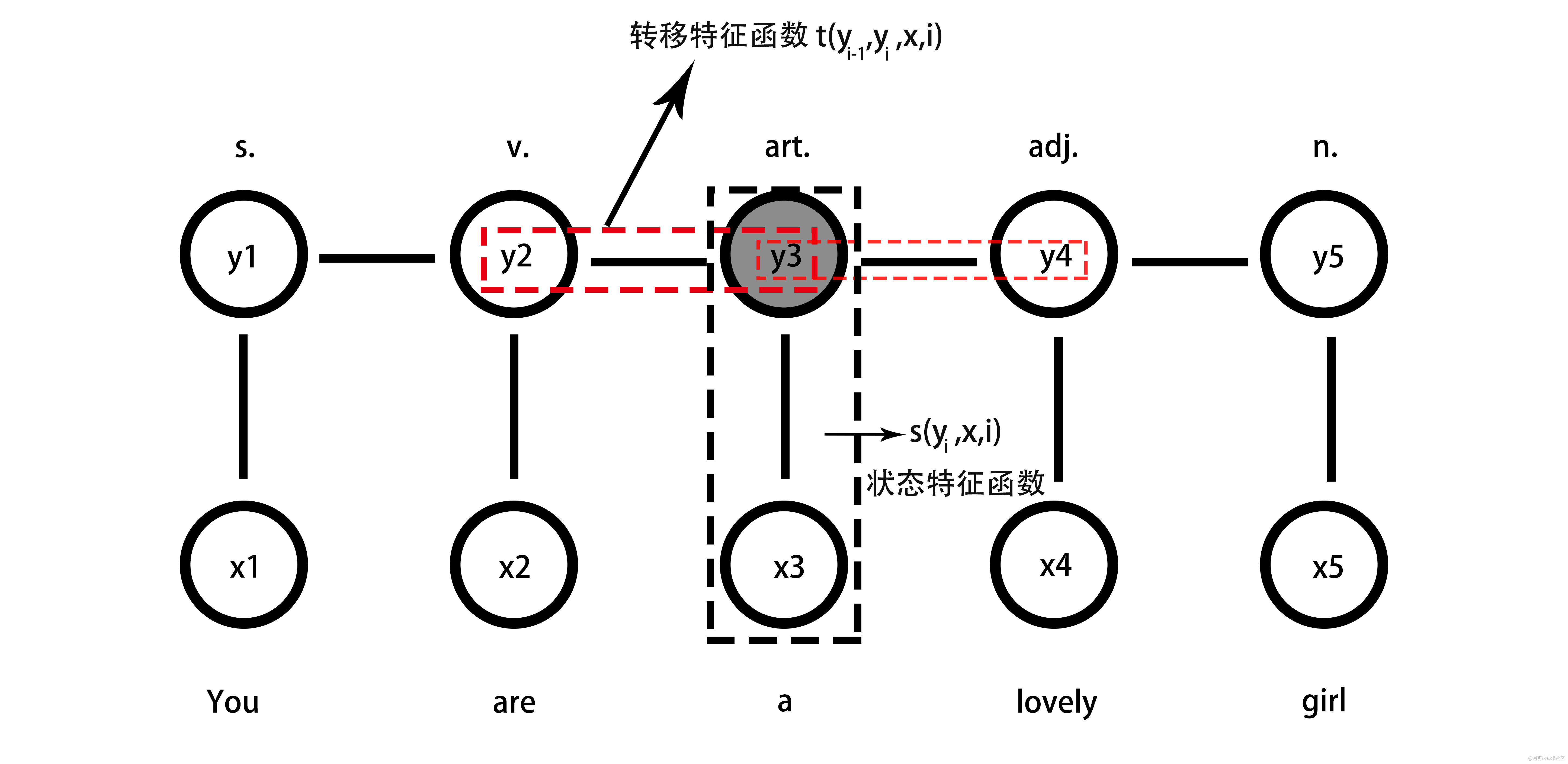
全连接CRFs是在深度学习图像分割应用中常用的一种图像后处理方式,它是CRFs的改进模式,能够结合原始影像中所有像素之间的关系对深度学习得到的分类结果进行处理,优化分类图像中粗糙和不确定性的标记,修正细碎的错分区域,同时得到更细致的分割边界。
全连接CRFs的简单原理描述如下:
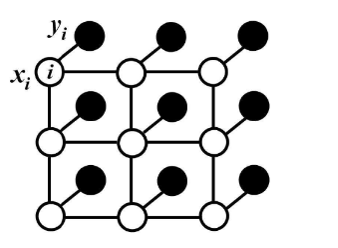
对象通常由大的空间相邻的区域表示,每个像素都拥有一个类别标签yi ,而且还有一个对应观测值xi,这样在无向图中每个像素点都成为某一个节点,若使用像素与像素之间的关系作为边连接,这样就组成了条件随机场。最终目的就是使用观测值来推测这个像素i本来拥有的类别标签。
最终,Deeplab v1整体结构如下图:
PSPNet
在目标检测系列-SPP Net中提到:通过设计Spatial pyramid pooling,不同层次的feature map在平滑和拼接之后被用于图像分类。这种先验信息是为了消除了CNN中固定尺寸的约束。
为了进一步减少不同子区域之间的上下文信息丢失,PSPNet提出了一种分层的全局先验信息,其中包含具有不同尺寸和在不同子区域之间变化的信息。这被称为Pyramid Pooling Module(PPM),用于在深度神经网络的最终层feature map上进行全局场景先验信息的构造。
PSPNet以ResNet为骨干网络,利用PPM在不同尺度下提取和聚合不同的子区域特征,然后上采样(双线性插值)和级联形成特征图,同时携带局部和全局上下文信息。特别值得注意的是,金字塔层数和每层的大小是可变的,这取决于输入到PPM的特征图的大小
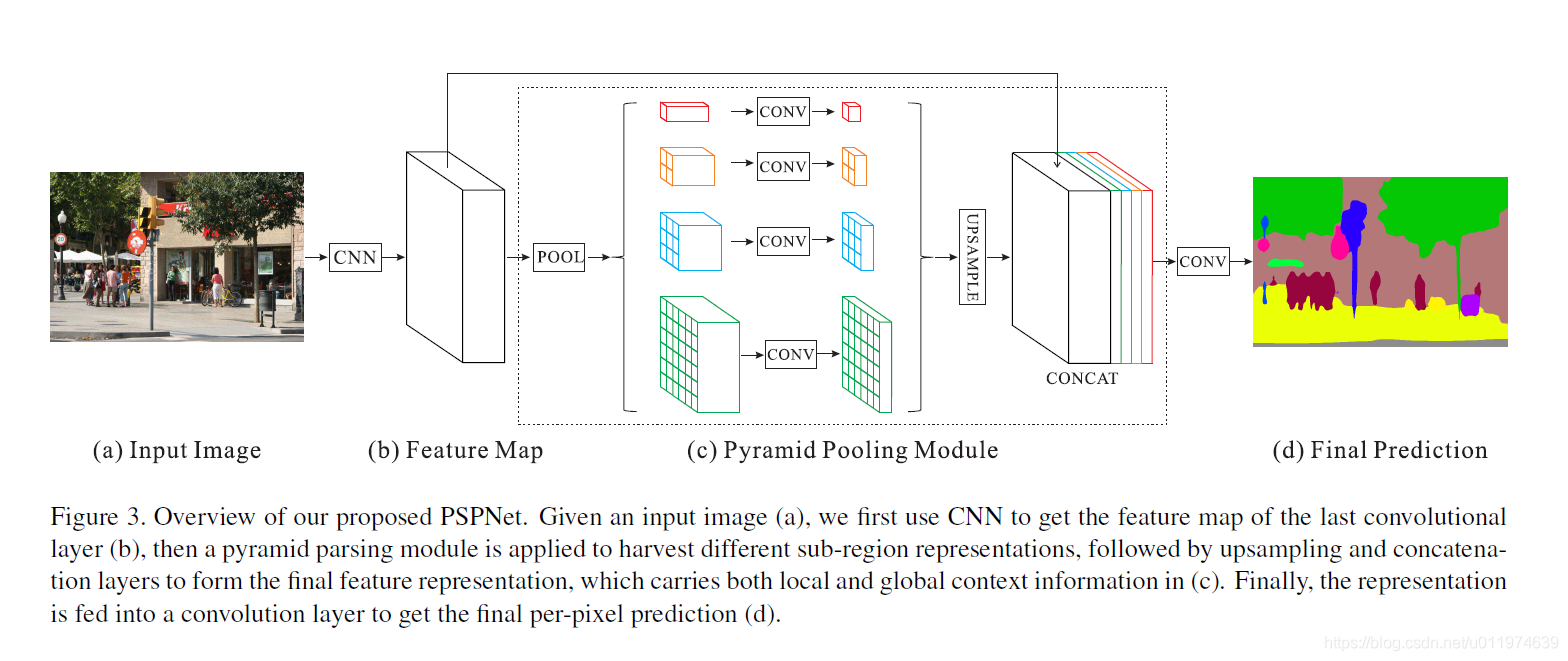
PSPNet的改进点:
- 提出了Pyramid Pooling Module结构,丰富了感受野,增强了全局场景解析能力
- 引入了空洞卷积(backbone中)
- loss改进:除了最后的分类器的softmax loss(loss 1)之外,在res4b22层后新增了一个分类器(loss 2),两个loss函数通过其所在位置之前的所有层。其中loss1决定最终分类,loss2进行了权值平衡。后续的实验证明这样做有利于快速收敛。测试时去除了额外的分类器。
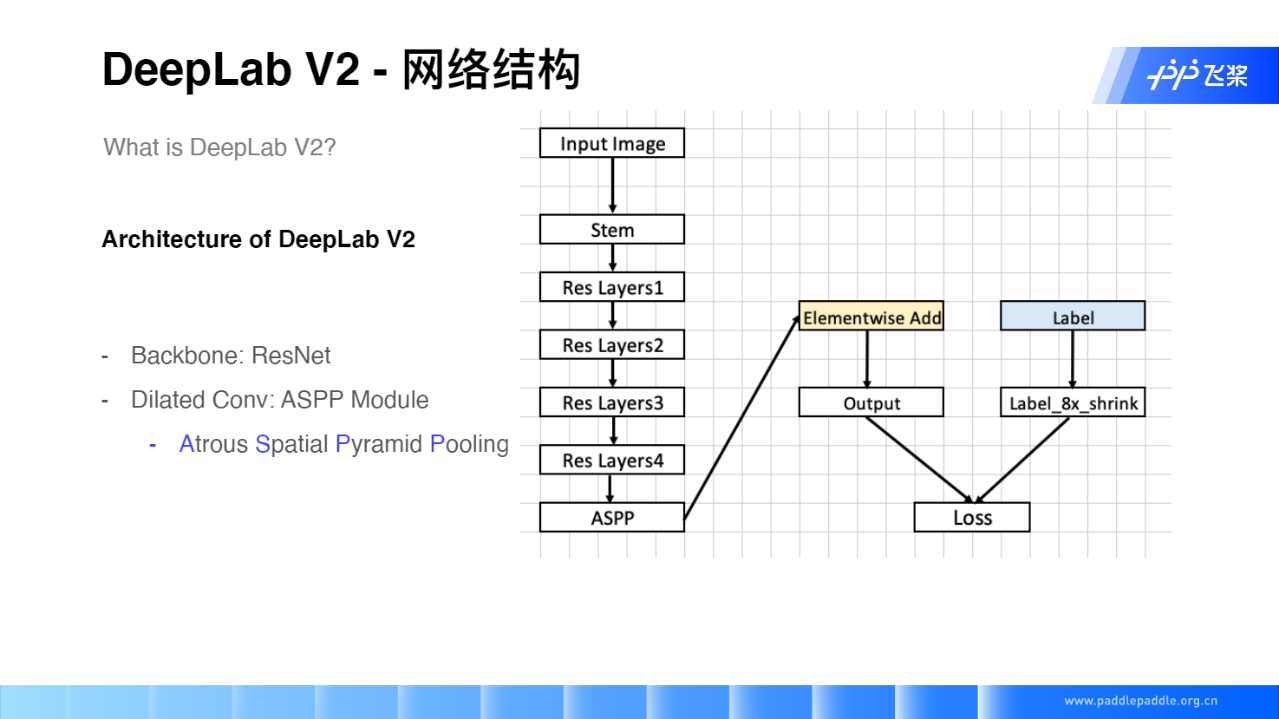
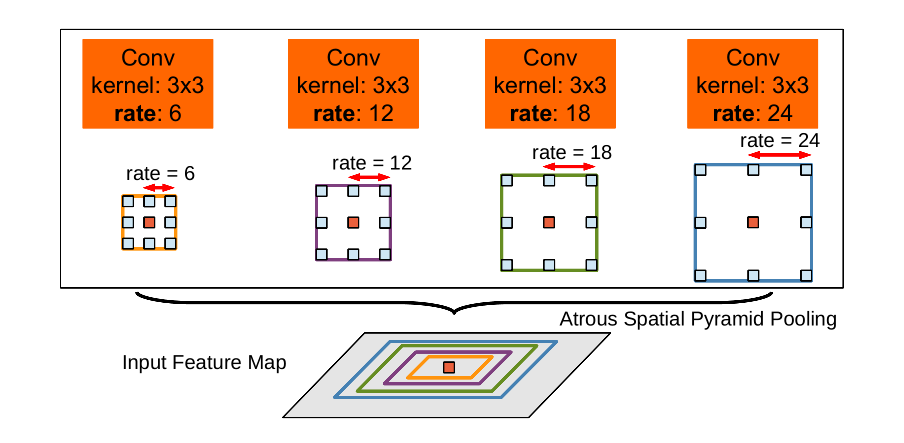
Deeplab v2
创新点:
- 结合SPP/PPM思想,Deep Lab V2 引入空洞空间金字塔池化( ASPP )来扩大感受野,捕获多尺度特征。ASPP模块包含四个扩张率不同的并行空洞卷积。
- backbone修改为ResNet
Deeplab v2的网络结构和Deeplab v1相差不大,结构如下:
ASPP模块图
Deeplab v3
Deeplab v3首先介绍了目前图像分割领域面临的两个挑战:
- 连续的池化层或者较大步长的卷积会降低特征的分辨率,从而不利于提升分割的精度;
- 存在不同大小的目标,也就是multi-scale问题。
然后介绍了目前常见的四种语义分割网络架构:
- Image pyramid (图像金字塔结构):将不同scale的图片同时输入到网络中,不同scale的网络共享权重。较大scale的图片获取局部细节特征、较小scale的图片用来获取更大范围的上下文信息。这种类型的模型的主要缺点是,由于GPU内存有限,它不能很好地扩展到更大/更深的DCNN,因此它通常应用于推理阶段。
- Encoder-Decoder(编码-解码结构):其中编码器用于将特征图的空间维数逐渐降低,从而更容易捕获更远距离的信息,解码器用于将目标细节和空间维数逐渐恢复。SegNet、U-Net和RefineNet都采用了类似的结构,后续的DeeplabV3+也是采用了这种结构。
- Atrous convolution(空洞卷积):基于空洞卷积的模型设计。空洞卷积的主要优势是:可以在不降低特征空间分辨率的同时提升模型的感受野,获取到更大范围的上下文信息。
- Spatial pyramid pooling (空间金字塔池化):采用空间金字塔池化来捕获多个范围内的上下文。
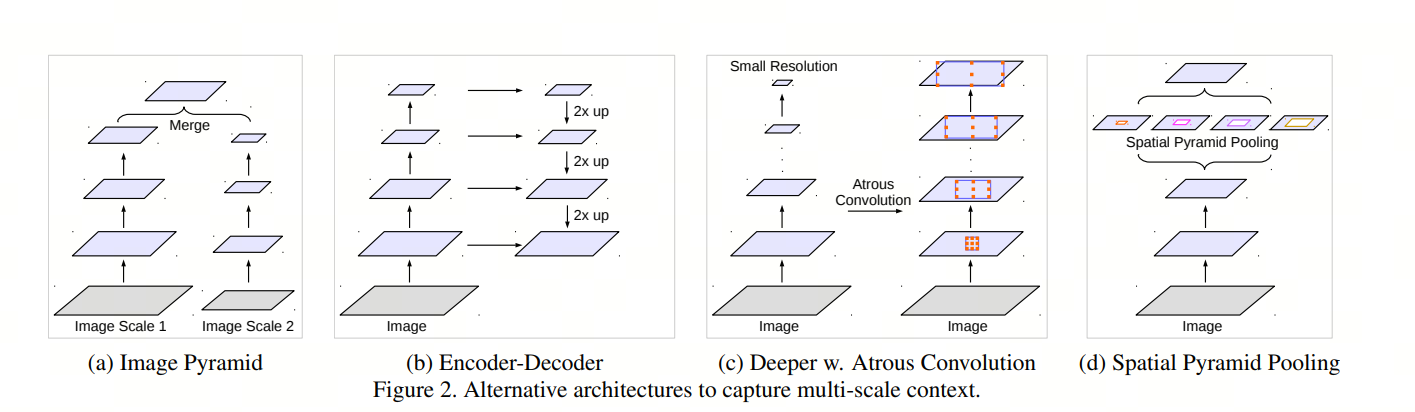
Deeplab v3在结构上改动不大,主要是针对空洞卷积进行了探讨,为了解决上面提出的两个挑战,尝试了级联(cascade)和并行(parallel)的空洞卷积模型,并总结了多个实验tricks。最终,在不使用DenseCRF后处理的情况下,DeeplabV3在PASCAL VOC 2012语义图像分割基准上获得了与其他sota模型相当的性能。
DeeplabV3具体贡献如下:
-
重新讨论了空洞卷积的使用
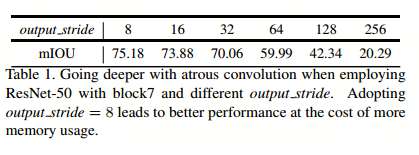
深入研究ResNet发现,随着网络层数的加深,使网络在更深的区块(block)中捕获远程信息变得容易,但与之同时会带来细节信息的丢失,损失细节语义,表现结果就是输出大小变小(stride=256,即比原图像缩小了256倍)
然后引入空洞卷积,研究了合适的stride的大小,避免损失更多的细节语义。研究结果表明,stride=8时网络表现最好,但同时会导致更多的内存占用,通过权衡,Deeplab v3最终采用了stride=16的空洞卷积结构
同时,空洞卷积存在"girdding"问题,即空洞卷积在卷积核两个采样像素之间插入0值,如果扩张率过大,卷积会过于稀疏,捕获信息能力差,受采用不同大小网格层次结构的多重网格方法启发(粗网格需要高信息提取力,等到细网格时已经比较接近解了,信息提取力可以适当降低),Deeplab v3使用空洞卷积时使用了不同的扩张率({2,4,6,8}),此外,每个block块内包含3个卷积,Deeplab v3为这3个卷积设置的扩张率网格为atrous rate * Multi Grid = atrous rate * (1; 2; 4),则block4的扩张率网格为2 * Multi Grid = (2; 4; 8) 。
-
改进了ASPP模块
在ASPP中加入了BN
具有不同 atrous rates 的 ASPP 能够有效的捕获多尺度信息。不过,论文发现,随着扩张率(atrous rate)的增加,有效滤波器(filter)特征权重(即应用于有效特征区域的权重,而不是填充的零)的数量会变小,极端情况下,当空洞卷积的atrous rate接近feature map的大小时,3 ×3 卷积不会捕获整个图像上下文,而是会退化成简单的1 ×1卷积,因为只有中心滤波器权重是有效的。

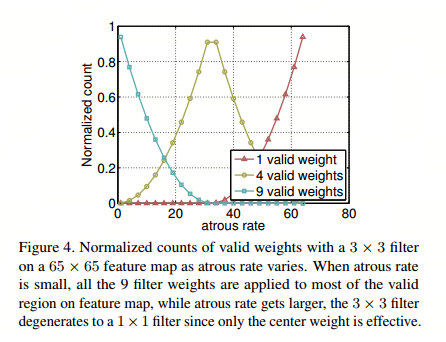
为了克服这个问题并将全局上下文信息纳入模型,Deeplab v3采用了图像级特征。具体而言,将对最后一个特征图进行全局平均池化,然后将得到的图像级特征输入256大小滤波器+BN,最后通过双线性插值上采样将特征提升到所需的空间维度。
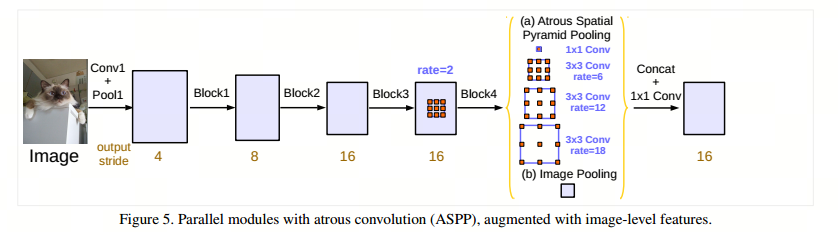
最后改进后的ASPP如下图:
- 由一个 1 ×1的卷积与三个3 ×3 卷积组成(256大小滤波器和BN层),当output_stride=16时,rates=(6,12,18)。当output_stride=8时,扩张率会加倍。
- 然后将所有分支的特征图通过一个1 ×1卷积(256大小滤波器和BN)concatenate起来,送入最后的1×1卷积以产生最终分数。
-
取消了DenseCRF
在deeplab v1/v2中,大扩张率的3X3空洞卷积,图像边界响应无法捕捉远距离信息,会退化为1×1的卷积,导致最终结果边界较为模糊,因此需要使用DenseCRF后处理增强其位置信息。
但是deeplabv3将图像级特征融合到ASPP模块中,融合图像级特征,相当于融合了全局位置信息,增强了分割边界,所以就不需要最后再用CRF了。这就是用了CRF,其精度也增加的不多的原因。
-
其他训练tricks
-
学习率策略:采用了指数学习率衰减策略, 在初始学习率基础上乘以 ( 1 − i t e r m a x _ i t e r ) p o w e r (1−\frac{iter}{max\_iter})^{power} (1−max_iteriter)power ,其中power=0.9
-
Crop Size:为了符合网络输入大小或避免内存溢出,往往需要对输入影像进行裁剪。为了大扩张率的空洞卷积能够有效,需要较大的图片大小;否则,大扩张率的空洞卷积权值就会主要用于padding区域。因此,论文最终在PASCAL VOC 2012数据集的训练和测试过程中,采用了513的Crop Size。
-
Batch normalization:
- 在ResNet之上添加的模块都包括BN层,由于训练BN参数需要大batch size,因此设置output_stride=16、batch size=16,同时BN层的decay参数设置为0.9997。
- 在增强的数据集上,以初始学习率0.007迭代30K次后,冻结BN层参数,采用output_stride=8;再使用初始学习率0.001在PASCAL官方的数据集上迭代30K次。
- 注意空洞卷积允许我们在不同的训练阶段控制output_stride,而不需要学习额外的模型参数。
- 还要注意,训练output_stride=16比output_stride=8要快很多,因为其中间的特征映射在空间上小四倍。但output_stride=16在特征映射上相对粗糙,快是因为牺牲了精度。
-
Upsampling logits:之前的工作是将output_stride=8的输出与Ground Truth下采样8倍做比较。但作者发现保持Ground Truth更重要,最终将输出上采样8倍与完整的Ground Truth比较。
-
数据增强(Data augmentation):随机缩放(从0.5到2.0)和随机左右翻转
-
其他结论
- 输出步长为8时效果比更大的步长要好;
- 基于ResNet-101的结构比基于ResNet-50的要好;
- 用变化的扩张率组({2:4:8})比不变的扩张率组({1:1:1})要好;
- 加上多尺度输入和左右翻折数据效果更好;
- 用MS COCO下预训练的模型效果更好。
Deeplab v3+
首先讲述了目前两类语义分割网络架构的优缺点:
- 空间金字塔池模块:能够通过以多个扩张率和多个有效视场,使用卷积或池化操作来探测传入特征,从而对多尺度上下文信息进行编码。
- 编码解码器结构:有助于在编码器路径中进行更快的计算(因为没有扩展特征),并逐渐恢复解码器路径中清晰的对象边界。
于是,Deeplab v3+就想到把这两种架构的优势结合起来。具体而言,Deeplab v3+的贡献如下:
-
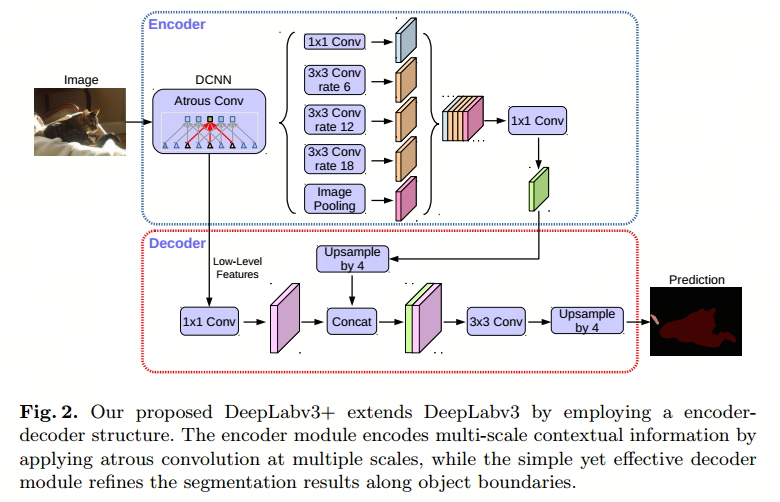
结合空间金字塔池模块和编码解码器结构设计了Deeplab v3+,既能过编码器在多个尺度上应用空洞卷积来编码多尺度上下文信息,又能通过简单而有效的解码器则沿着对象边界细化分割结果。
- 编码器采用的是Deeplab v3
- 解码器中,对编码器的输出特征进行4x双线性上采样,然后与来自网络主干的具有相同空间分辨率的相应低级特征级联
- 对低级别特征应用了另一个1×1卷积来减少通道的数量,以和上采样后的编码器特征保持相同的空间分辨率。
- 在级联之后,应用了一些3×3卷积来细化特征,再通过4x双线性上采样将特征图恢复到期望大小。
-
使用Xception作为backbone,并对Xception进行了改进
-
在InceptionNet之前的卷积backbone,如VGGNet,只是简单的堆叠卷积块,InceptionNet(又称GoogleNet)提出了一种新的卷积结构Inception,通过分通道使用不同尺寸的卷积核,以获取不同的感受野,还能大幅降低参数量。
-
一旦层数加深,普通卷积带来的参数量会非常大,因此有学者提出了深度可分离卷积(Depthwise Separable Convolution,DSC),即先进行逐通道卷积(Depthwise),再进行逐点卷积(Pointwise),通过这种方式,在一定程度上保证精度的同时极大缩减了参数量和计算量。具体可参考可分离卷积(Separable Convolution) — PaddleEdu documentation (paddlepedia.readthedocs.io)
-
Xception是Inception的极端情况,即将1 * 1 卷积核的通道数完全展开,再进行逐通道卷积,可以看出和DSC相比,Xception是先PW再DW。在当时,Xception模型在ImageNet上是图像分类任务的SOTA。
-
MSRA团队(微软亚洲研究院)对Xception进行了改进,提出了Aligned Xception(来自可变形卷积DCN):传统/常规卷积根据定义的滤波器大小,在来自输入图像或一组输入特征图的预定义矩形网格上进行操作。这个网格的大小可以是3×3和5×5等。然而,我们想要检测和分类的对象可能会在图像中变形或被遮挡。在 DCN 中,滤波器网格是可变形的,即针对每个网格点增加了可学习的偏移量参数。卷积对这些移动的网格点进行操作,因此称为可变形卷积,可变形 RoI 池化与之类似。
-
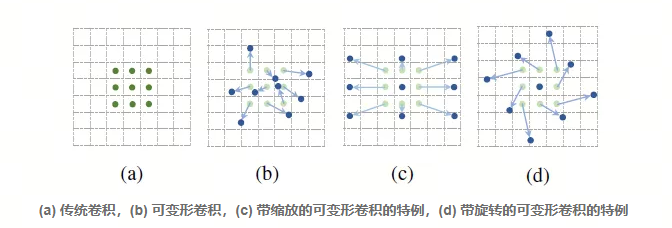
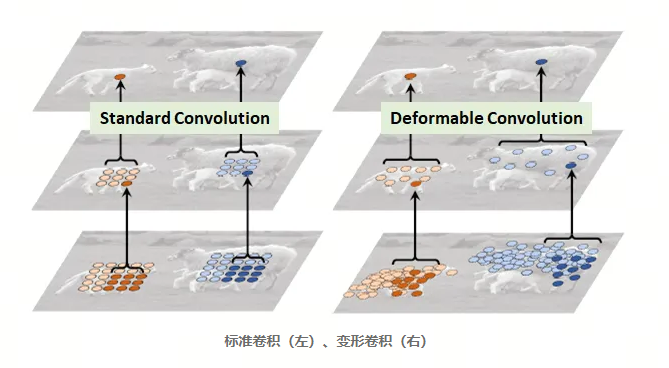
- 在Inception-v4中提出的原始Inception-ResNet中,存在对齐问题,即对于特征图上靠近输出的单元,其在图像上的投影空间位置与其感受野中心的位置不对齐。
- Aligned Inception-ResNet结构如下图所示,我们可以看到,在 Inception Residual Block (IRB) 中,用于分解的所有非对称卷积(例如:1×7、7×1、1×3、3×1 卷积)都被删除了。
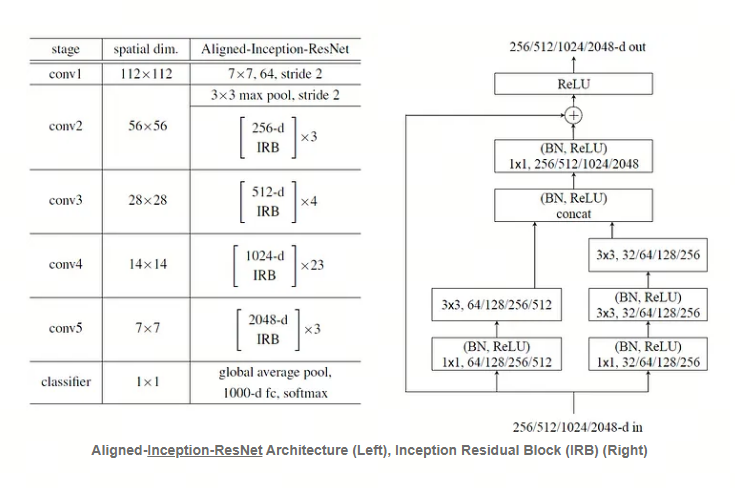
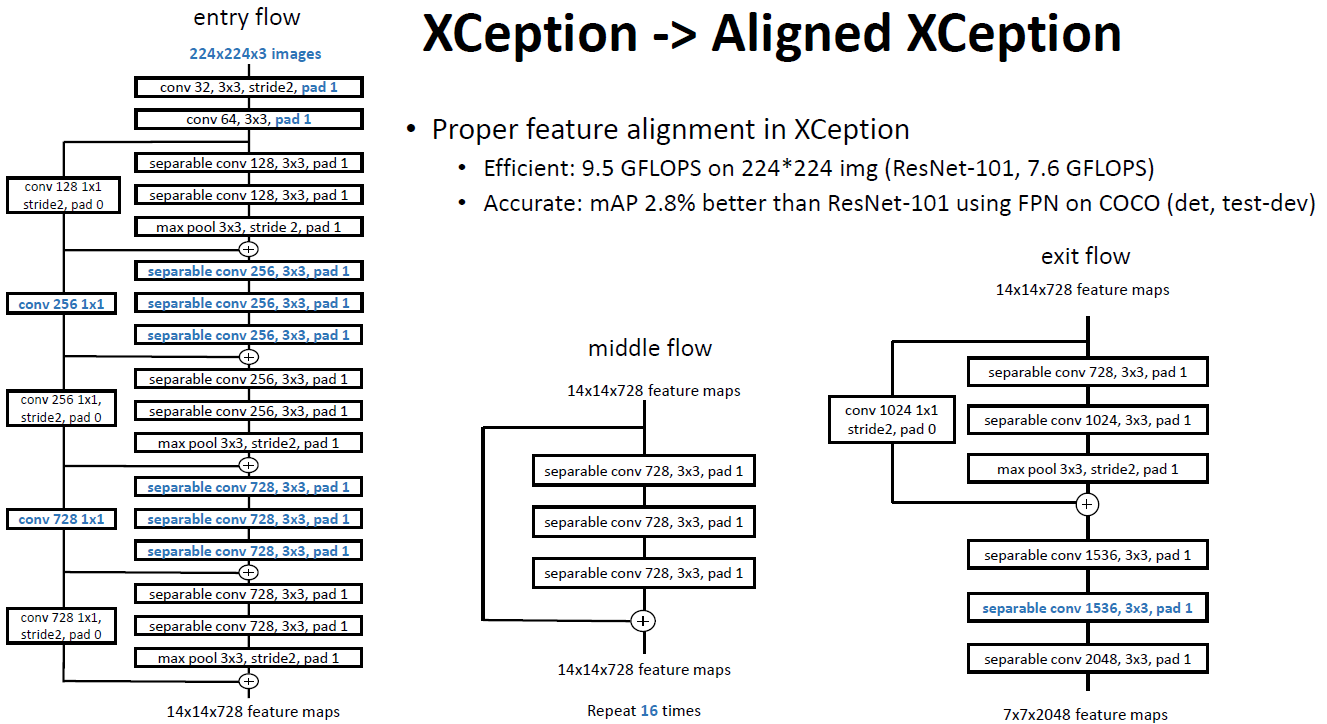
- Deeplabv3+针对Aligned Xception做了改进:1)更深的Xception,但为了快速计算和有效的使用内存,未修改entry flow network的结构;2)所有最大池化层都由带stride=2的深度可分离卷积替代,这使得我们可以利用空洞可分离卷积提取任意分辨率特征图;3)与MobileNet设计类似,在每个3×3 depthwise卷积后都添加BN和ReLU。
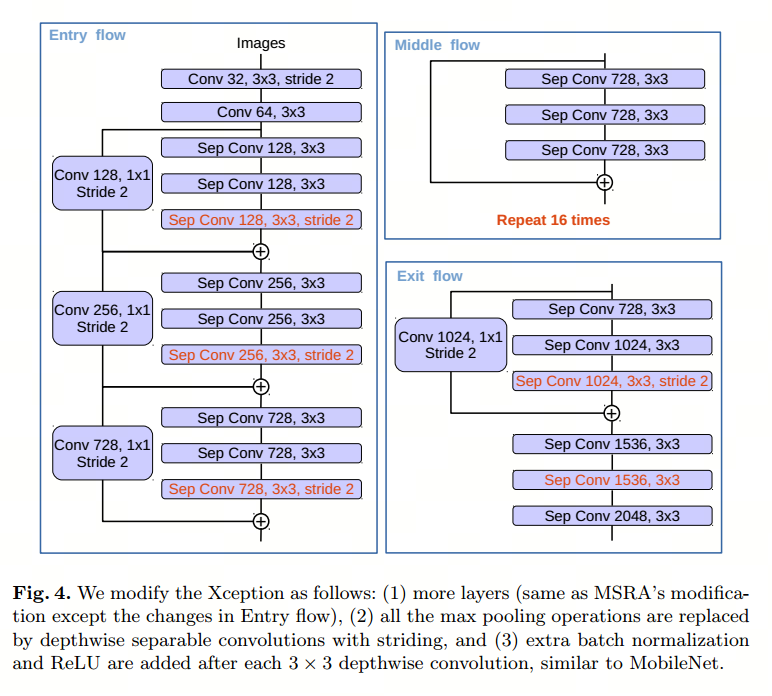
- 消融实验
- 论文使用modified aligned Xception改进后的ResNet-101作为主干,评估了1×1卷积不同通道数对PASCAL VOC 2012 val set的影响,发现48个通道的1×1通道用于减少低等级特征图通道的性能最好。

- 编解码特征图融合后经过了3x3卷积,论文探索了这个卷积的不同结构对结果的影响,发现在将Conv2特征图(跨步前)与DeepLabv3特征图连接后,使用两个[3×3, 256]卷积比简单地使用一个或三个卷积更有效。

基于候选区
Mask RCNN
实例分割领域的”开山之作“,同时也使得计算机视觉网络走向多任务时代。
语义分割:将图像中的每个像素分配给预定义的语义类别,从而实现对图像的像素级别的分类。
实例分割:在语义分割的基础上,进一步将图像中的每个像素分配给不同的物体实例,从而实现对图像中不同物体实例的分割。
全景分割:将图像中的每个像素分配给预定义的语义类别或不同物体实例,同时保留类别和实例信息,从而实现对图像的全景级别的分割。
![![[Pasted image 20240402172851.png|500]]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuL2RpcmVjdC9kOTU5N2RkZDlhN2U0NjNiYTI0MTdjZmYxMDYzM2I0My5wbmc%3D)
之前在目标检测领域已经讲述过Mask RCNN的相关原理,此处不再赘述。
Mask RCNN之所以能够实现图像分割在于其新增了FCN分支(ROIAlign实现了对齐),我们应该注意到和全卷积类型的网络不同,Mask RCNN是对每个Proposal进行分类和分割的,而非对像元,因此变相的实现了实例分割。
应当注意,当我们实现图像分割后,也很容易扩展到关键点检测领域,只要将关键点位置建模为一个单独的one-hot mask,每个目标预测K个关键点mask即可。
实现细节方面:对于一个实例的每个关键点,Mask RCNN的训练目标是一个m×m大小的二进制mask,其中只有一个像素标记为前景(一个关键点对应一个mask,mask中只有关键点的位置设置为1其它设置为0)。训练时采用交叉熵损失函数。
MS RNN
MS RCNN提出一个问题,那就是对实例分割掩膜(Mask)的质量评估不准确。
详细来说,在大多数实例分割算法中,如Mask R-CNN和MaskLab,实例掩码的分数与边框分类置信度一致,而该置信度由应用于候选区(Proposal)特征的分类器预测。使用边框分类置信度来衡量分割掩码质量是不合适的,因为它只用于区分Proposal的语义类别,而不知道实例掩码的实际质量和完整性。
边框分类置信度和掩码质量之间的偏差如下图所示。其中实例分割假设获得了准确的边框定位结果和高分类分数,但相应的掩码是不准确的。显然,使用这种分类得分对掩模进行评分往往会降低评估结果。
![![[Pasted image 20240404165227.png]]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuL2RpcmVjdC9mOTJjODhiZWY3ZjI0MDk5YjEzYzNhM2QyYzQxYjM1Yi5wbmc%3D)
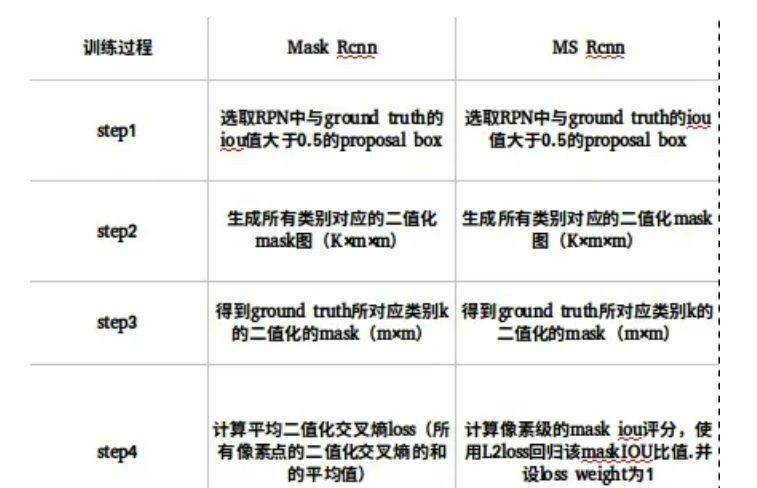
其实上述问题归根结底还是损失函数的问题,分类损失函数不能表明Mask质量,因此MS RCNN采用Mask IoU+回归损失L2 Loss来计算Mask质量,如下图所示:
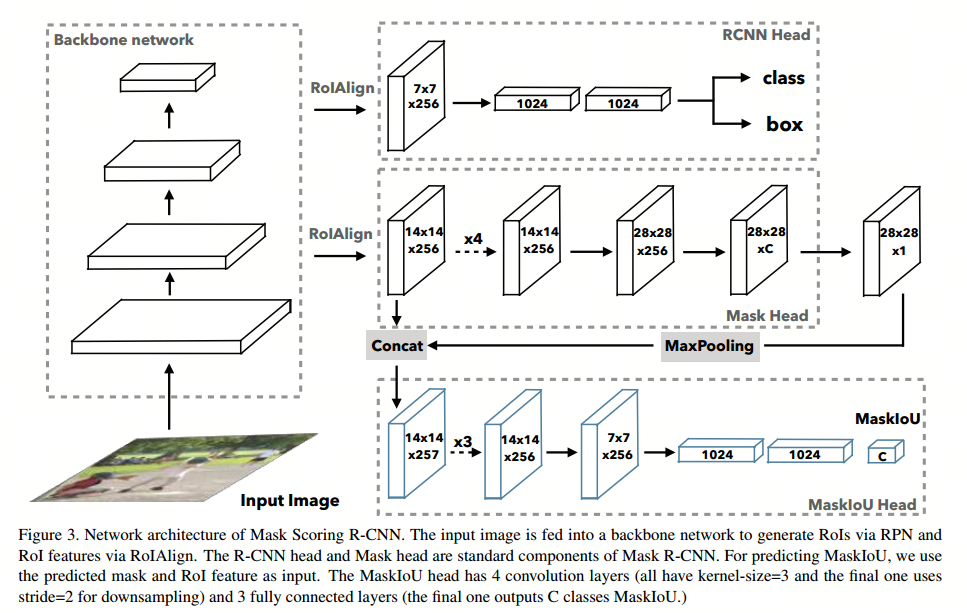
针对损失函数的改进,网络结构也要相应变化,MS RCNN在Mask R-CNN结构基础上做出了改进,在Mask Head后面新增了MaskIoU Head。
基于GAN
对于语义分割任务来说,保持分割目标的轮廓完整性和平滑性往往是必要的,而原始的分割框架有时候可能难以保证这一点,可以利用GAN优良的图像生成能力来进行对抗学习,增强分割掩膜的质量。
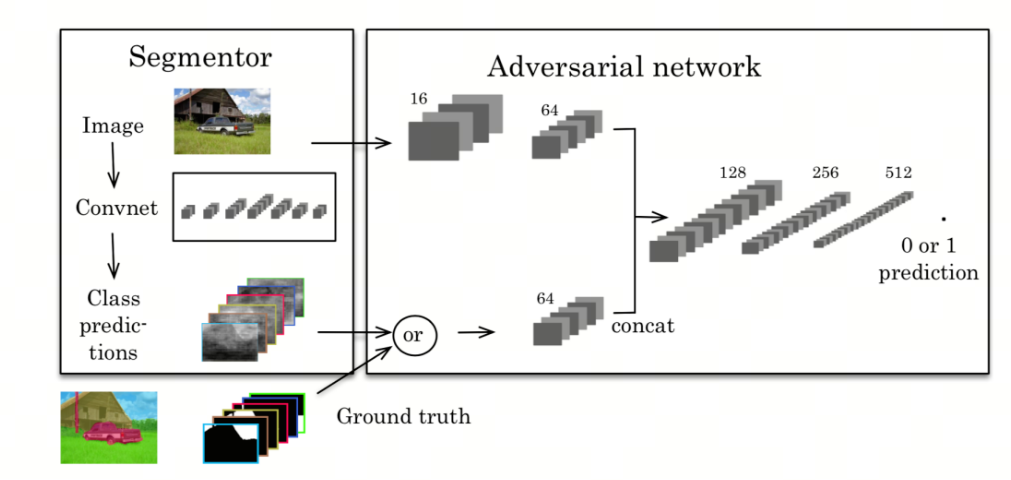
基于RNN
ReSeg
和CNN相比,RNN( Recurrent Neural Network,RNN )能够进行长距离的关系建模,更好的处理上下文依赖,理解语义,因此在自然语言处理( NLP )领域得到广泛应用。
基于RNN的这一优点,为了表示图像中不同区域尤其是远距离区域之间的依赖关系,获取它们之间的语义相关性,RNN开始被应用到计算机视觉中,并在语义分割方面取得了较好的成果。
RNN可以对像素之间的短期依赖关系进行建模,将像素连接起来,并依次进行处理,建立了全局的上下文关系。Visin等在ReNet的基础上提出了ReSeg网络,每个ReNet层由四个RNN组成,它们在两个方向上水平和垂直扫描图像,对patch或激活进行编码,并提供相关的全局信息。ReNet层堆叠在预先训练的卷积层之上,受益于通用局部特征,最后通过上采样层恢复最终预测中的原始图像分辨率。
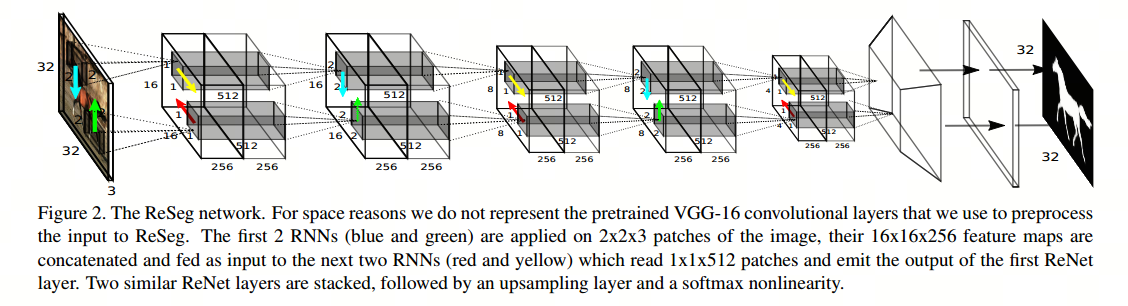
当然,RNN虽然能进行上下文建模,但在长距离建模方面不足,也难以训练,因此也有学者尝试将LSTM应用于语义分割。
ViT
但是LSTM计算量大,并且仍具备传统RNN的缺陷:不能并行,长距离依赖捕获能力仍不足。随着注意力机制于2014年在计算机视觉领域首次被提出。Google Mind团队采用RNN模型将注意力机制应用于图像分类,使得注意力机制在图像处理任务中逐渐流行起来。2017年,Transformer的自注意力机制更是解决了并行计算的问题,成为自CNN之后有力的新框架。2020年,ViT(Vision Transformer,ViT )的提出,证明了Transformer可以替代CNN对图像块序列进行分类和预测,开启了基于Transformer的计算机视觉研究的热潮。
ViT可以替代CNN作为CV领域新的backbone。关于ViT结构,在目标检测系列中已经说明,不再赘述。
Swin Transformer
2021 ICCV最佳论文,屠榜了各大CV任务,性能优于DeiT、ViT和EfficientNet等主干网络,已经替代经典的CNN架构,成为了计算机视觉领域通用的backbone。
Transformer在CV领域应用存在两种问题,本质上是由于模态差异造成的:
-
与语言Transformers中充当处理基本要素的单词tokens不同,视觉元素可以在尺度上发生很大变化。换句话说,token都是固定尺度的,这一性质不适合这些视觉元素。
-
图像中的像素比文本段落中的单词具有更高的分辨率。存在许多视觉任务,如语义分割,需要在像素级别进行密集预测,这对于高分辨率图像上的Transformer来说是难以解决的,因为如果将每个像素值算作一个token,其自注意力的计算复杂度将是图像大小的二次方(每个token都要与其他token计算QK值)。
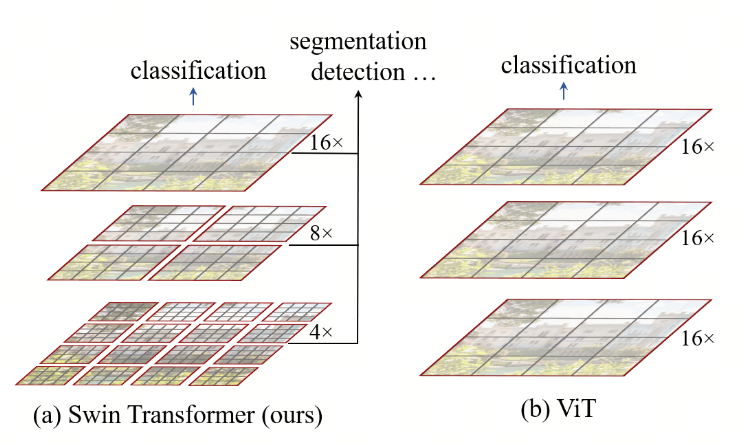
针对上述,Swin Transformer提出了层次化 (Hierarchical) 的概念。
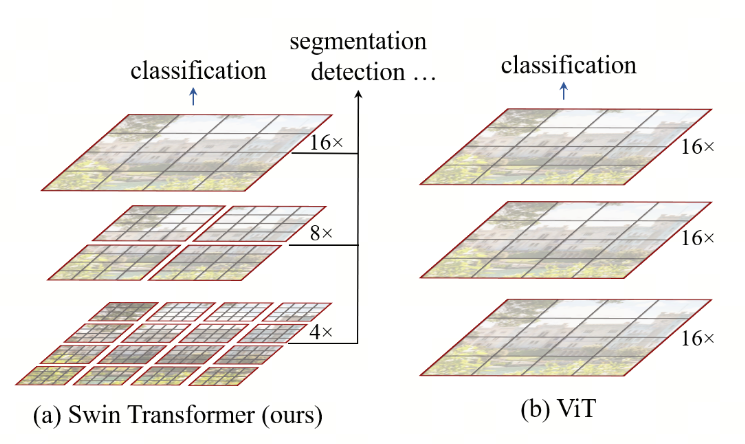
如下图所示,Swin Transformer从小尺寸的patches(用灰色勾画)开始,在更深的Transformer层中逐步合并相邻patches,从而构建分层表示。通过这些层次化的特征图,Swin Transformer模型可以方便地利用先进的密集预测技术,如特征金字塔网络( FPN ) 或U - Net。线性计算复杂度是通过在分割图像(用红色勾画)的非重叠窗口(window)内局部计算自注意力来实现的。每个窗口内的图像块(patches)数量固定,因此复杂度与图像大小成线性关系。这些优点使得Swin Transformer与之前的Transform相比,更适合作为各种视觉任务的通用骨干。
虽然降低了计算复杂度,但这样仍存在问题,这样计算,只能计算windows之间的依赖关系,缺乏对各windows内部patches之间关系的建模。因此Swin Transformer进一步提出了移位窗口 (Shifted Windows)。即重构窗口,新窗口中的自注意力计算跨越了上一层中前面窗口的边界,使原来不同窗口内的patches产生了关联。
Swin Transformer的网络结构解读
![![[Pasted image 20231218104753.png]]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuL2RpcmVjdC85NGEzNTFkNTZkODA0ZTQzYTI3NjA5M2MwNGNkYjBmMi5wbmc%3D)
Swin Transformer结构为分块(Patch Partition)后接4个Stage模块,其中Stage1为Linear Embedding接Swin Transformer Block,Stage2-4为Patch Merging接Swin Transformer Block
-
Patch Partition: 将像素分辨率图像转换为patches分辨率(图像分辨率224 * 224,patch_size = 4,patches_resolution = 56 * 56)的图像,每个patch展平后视为一个token,则token_feature=3 * 4 * 4 =48,一幅图像的token个数为56 * 56。
-
Linear Embedding: 将token_feature转换为需要的维度,即(batch_size,56 * 56,48)->(batch_size,56 * 56,96)。
-
Patch Merging: 用于减少计算量、产生层次化表征,Patch Merging类似Yolov2的PassThrough和Yolov5的Focus,结果将patches_resolution缩减为原来的一半、token_feature翻倍,(batch_size,56,56,96)->(batch_size,28,28,192)。
-
Swin Transformer Block: 相比于Transformer,将标准多头自注意力模块(MSA)替换为基于窗口的多头自注意力模块(W-MSA)和基于移位窗口的多头自注意力模块(SW-MSA),W-MSA / SW-MSA是成对出现了,这也意味着Swin Transformer Block数量是偶数。
- 基于窗口的自注意力W_MSA以窗口大小内的tokens计算注意力,显著缩减了计算复杂度,但是缺少窗口间的关联。
- 因此基于平移窗口的自注意力SW-MSA,重构窗口(向下取整分割+cyclic shift),使原来不同窗口内的tokens产生了关联。
-
注意力层计算softmax分数的过程中加入了新的可学习参数:相对位置偏置(B),实验表明使用相对位置嵌入的效果显著优于不使用位置嵌入或使用绝对位置嵌入。
![![[Pasted image 20240404175730.png]]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuL2RpcmVjdC80NGZhYjVlMDg5YzI0NWM2YjVjMWU0ZGFjNWRlZjFmNy5wbmc%3D)
SAM(Segment Anything Model)
2023年 ICCV 最佳论文荣誉提名奖
NLP领域的大语言模型(LLMs)已经”百花齐放“,但由于模态的不同,CV领域的基础模型尚未成熟。2023年,Meta建立一个图像分割的基础模型SMA,开辟了视觉基础模型的新篇章。
在NLP和最近的计算机视觉中,基础模型是一个很有前途的发展,它可以通过使用"提示"技术来对新的数据集和任务进行零样本和少样本学习。受此启发,SMA提出了可提示的分割任务,其目标是在给定任何分割提示的情况下,返回一个有效的分割掩码。提示符只是简单地指定在图像中分割什么,例如,提示符可以包含识别对象的空间(点、目标框、mask)或文本信息。有效输出掩码的要求是指即使一个提示是模糊的,可以指代多个对象(例如,衬衫上的一个点既可以表示衬衫,也可以表示穿着它的人),输出也应该是其中至少一个对象的合理掩码。
SMA使用可提示的分割任务作为预训练目标,并通过提示工程解决一般的下游分割任务。
![![[Pasted image 20240404180648.png]]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuL2RpcmVjdC9hNWZkODg1ZDgzZWY0YTZjOGM1NzFjNjRjYWUxNGVkYi5wbmc%3D)
-
模型结构
根据上面的任务构建的模型需要满足以下约束:支持灵活的提示,需要以摊销的方式实时计算掩码以允许交互使用,并且必须是模糊感知的。
论文作者发现一个简单的设计满足所有的三个约束:一个强大的图像编码器(ViT)计算一个图像嵌入,一个提示编码器嵌入提示,然后将两个信息源组合在一个轻量级的掩码解码器中,预测分割掩码。作者称这种模型为Segment Anything Model,简称SAM。见上图b。
通过将SAM分离为图像编码器和快速提示编码器/掩码解码器,相同的图像嵌入可以以不同的提示重复使用(并对其成本进行摊销)。给定一个图像嵌入和提示,提示符编码器和掩码解码器在网络浏览器中能够以50ms延迟预测一个掩码。采用的Prompt为点、框和mask,也用自由形式的文本提示呈现初步结果。为了使SAM具有歧义感知能力,预测了单个提示的多个掩码,使SAM能够自然地处理歧义,例如衬衫vs人的例子。
Image encoder:映射待分割的图像到图像特征空间。采用预训练ViT,输入1024 * 1024,如果是16 * 16的patch,输出为64 * 64 * 256。
prompt encoder:负责映射输入的prompt到prompt的特征空间。两类:sparse (points, boxes, text) 和 dense (masks)- mask: convolutions,64 * 64 * 256
- point: position embedding + pos/neg
- box(两个输出): position embedding + left top 和 position embedding + right bottom
- text: text embedding from CLIP
Mask decoder:合并image encoder和prompt encoder分别输出的两个embedding,然后从这个embedding的feature map解码出最终的分割mask。结构如下图。 - output token = mask token(掩膜) + iou token(掩膜分数)
- 通过自注意力深度融合提示嵌入 (prompt tokens)和输出tokens(output tokens)获得最终的token
- 然后通过交叉注意力(cross-attention)建模image embedding和上一步获得的token间的关系
- 更新后的image embedding 2x上采样为最终image embedding;从更新后的token中分离mask token和iou token
- iou token经过mlp得到IoU分数
- mask token经过mlp和最终image embedding点乘后得到最终掩膜
ps:为了保持位置信息始终不丢失,每做一次attention运算,不管是self-attention还是cross-attention,tokens都叠加一次初始的tokens,image embedding都叠加一次它自己的位置编码,并且每个attention后边都接一个layer_norm。
![![[Pasted image 20240404183057.png]]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuL2RpcmVjdC8zODI1OGNmZTFhM2M0MTg5YTg3Y2FiZDc5NDNjMzAyNC5wbmc%3D)
![![[Pasted image 20240404184037.png|900]]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuL2RpcmVjdC84MTg5MGY2ZWRiMGI0ZmMwYmE3MTg1NGNhODQ5NmY0Zi5wbmc%3D)
-
数据集问题
为了获得强大的zero-shot and few-shot,必然要有一个庞大的数据集预训练,论文制作了SA-1B, 包括110万张图像和10亿masks。但是我们要注意到,要标注如此庞大的数据集需要的成本是巨大的,因此论文提出了数据引擎辅助制作数据集,分为三个阶段:辅助手动、半自动和全自动。在第一阶段,SAM辅助标注者对掩码进行标注,类似于经典的交互式分割设置。在第二阶段,SAM可以通过提示对象可能的位置来自动为对象子集生成掩码,并且注释器专注于注释剩余的对象,有助于增加掩码多样性。在最后阶段,我们用前景点的规则网格提示SAM,平均每幅图像产生100个高质量的掩码。
SA - 1B使用数据引擎的最后阶段完全自动收集,比任何现有的分割数据集多了400倍掩码,并且经过广泛的验证,这些掩码具有高质量和多样性。