loonggg
读完需要
7
分钟速读仅需 3 分钟
我之前就说过,我使用各种 AI 大模型一年多以来,ChatGPT 也经常用,给我最大的感觉就是在文本处理方面,国内大模型真的不输!
但是,在国内这些大模型当中,让我没想到的是阿里云的通义千问大模型竟然这么厉害。
①
阿里评测勇夺第一
我相信很多人都看到了这条新闻:
日前,全球著名开源平台 huggingface(笑脸)的联合创始人兼首席执行官 Clem 在社交平台宣布,阿里最新开源的 Qwen2-72B 指令微调版本,成为开源模型排行榜第一名。
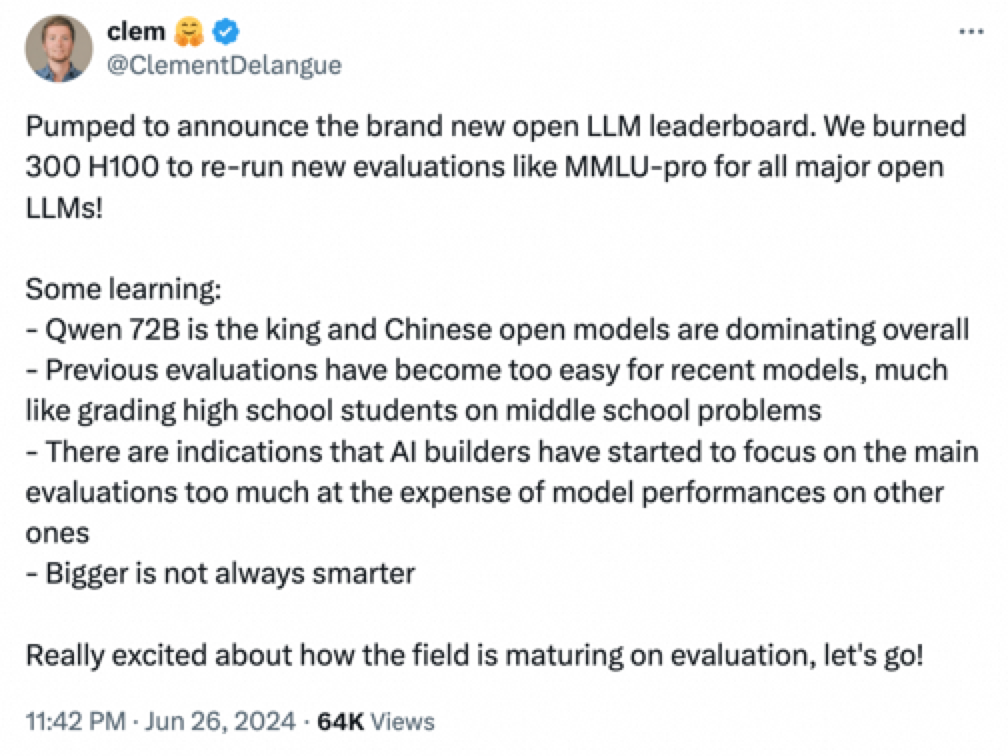
Clem 表示,为了提供全新的开源大模型排行榜,使用了 300 块 H100 对目前全球 100 多个主流开源大模型,例如,Qwen2、Llama-3、mixtral、Phi-3 等,在 BBH、MUSR、MMLU-PRO、GPQA 等基准测试集上进行了全新评估。
重新评估的原因是,目前开发者太注重排行榜的名次,在训练过程中使用了很多评估集的数据,并且之前的评估流程对于那些模型来说太简单了,所以,本次给这些模型加大了难度,想看看它们的真正实力。
结果显示,阿里最新开源的 Qwen2-72B 力压科技、社交巨头 Meta 的 Llama-3、法国著名大模型平台 Mistralai 的 Mixtral 成为新的王者,Clem 更是直接惊呼:中国在全球开源大模型领域处于领导地位!
在我们国内很多人固有印象中,中国大模型供应商只是“平替版本”,是实在没得用了,勉强能用的。甚至还有人说 GPT 是高铁,国产大模型就是拖拉机,虽然都能跑,但其实不一样。
其实这是偏见,在很多领域国内大模型都已经具有世界级竞争力了。
什么叫具备世界级竞争力的大模型?这里分两种:
一种是每次发布会都号称全面碾压 GPT4 的玩家,参数没输过,评测没赢过,这是自卖自夸,自吹自擂。
还有一类,是在权威榜单上拿到名次的。HuggingFace 是全球最权威的开源模型榜单,它给阿里云的 Qwen2“正名”,或者说给了“权威认证”。
不仅仅只有 HuggingFace 的认证,我查了一下资料:
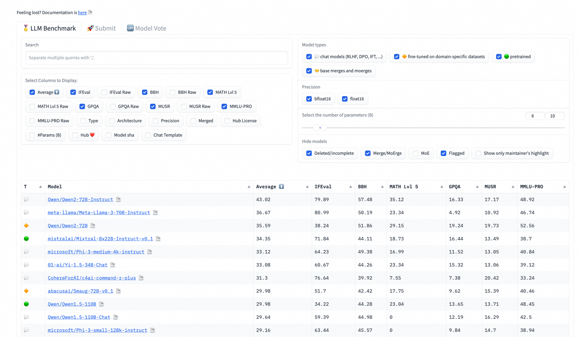
Qwen2-72B 刚发布时,就在 MMLU、GPQA、HumanEval、GSM8K、BBH、MT-Bench、Arena Hard、LiveCodeBench 等国际权威测评中,均获得了评分世界第一的好成绩。
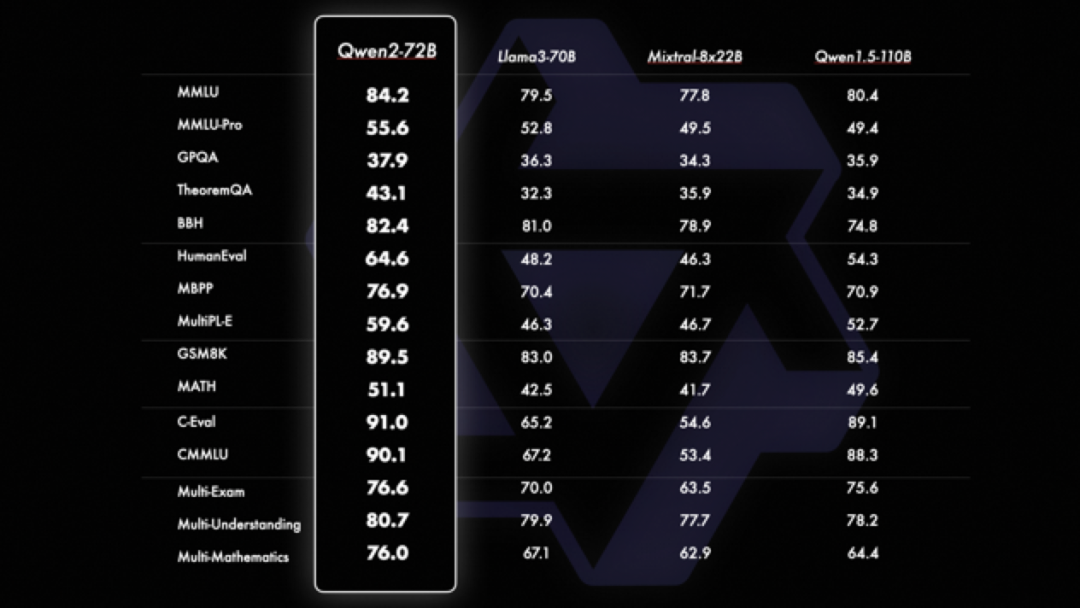
另外,在图灵奖得主、Meta 首席 AI 科学家杨立昆(Yann LeCun)联合 Abacus.AI、纽约大学等机构推出全新的大模型测评基准 LiveBench AI 中,Qwen2-72B 也是排在了开源大模型中的世界第一,也是十榜单中唯一的开源大模型、唯一的中国大模型。
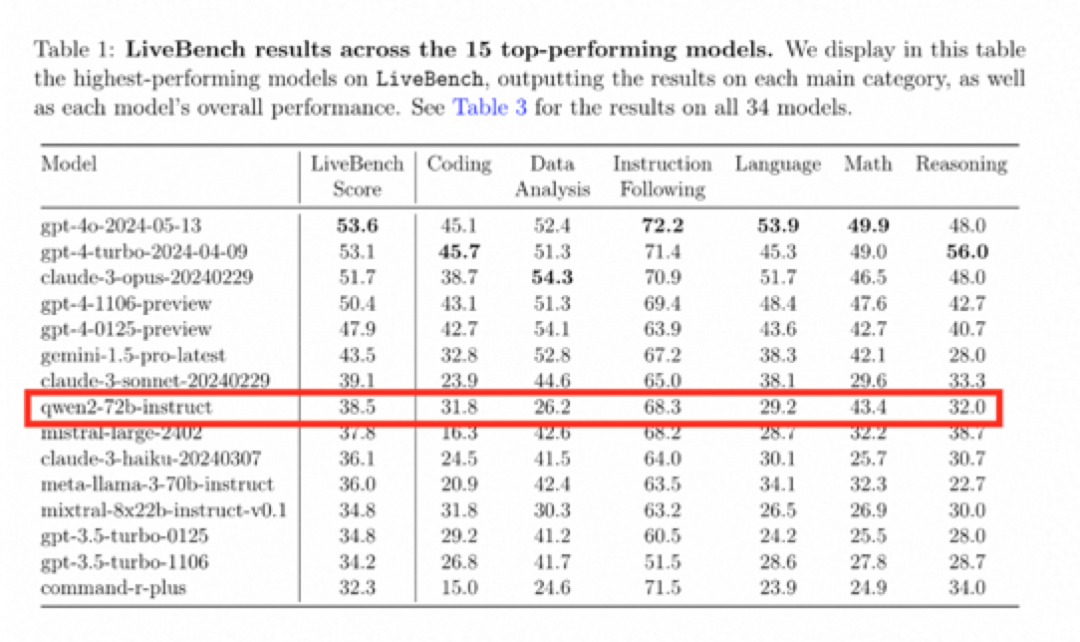
其实在与 OpenAI、Anthropic 这两家著名闭源大模型平台进行 PK 时,Qwen2-72B 指令微调版本也丝毫不落下风,也是中国唯一进入美国评估标准前 10 的国内公司。
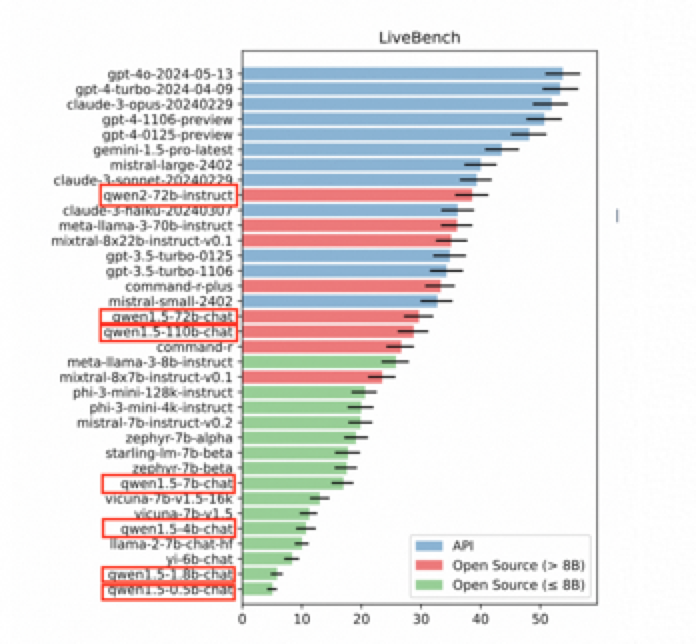
所以,你看,阿里巴巴的开源大模型真的是很厉害。
尤其是,AI 这种东西,都是数据喂出来的,用户越用越厉害,我们没必要崇洋媚外。
更何况,几天后,OpenAI 就将限制不支持的区域的 APl 访问,这也就是意味着我们中国大陆地区将无法使用 GPT 大模型的 API 服务了。
在 OpenAI 拒绝中国开发者的当口,阿里巴巴的这个 “第一名” 来得非常及时。
我感觉这恰恰是我们国内各种大模型的机会所在。
②
便宜又好用
6 月 25 日,就在 OpenAI 宣布将终止对我们中国提供 API 服务,阿里云百炼第一时间宣布,将为 OpenAI API 用户提供最具性价比的中国大模型替代方案,并为中国开发者提供 2200 万免费 tokens 和专属迁移服务。
国内大模型其实比国外卷的多,前一段时间国内大模型的 API 价格一直下调,都快卷成白菜价了。
就以通义千问为例,此前其实刚刚就进行了一轮大规模降价,共覆盖 9 款商业化及开源系列模型。
Qwen-plus:通义千问 GPT4 级主力模型,在阿里云百炼上的调用价格为 0.004 元/千 tokens,仅 GPT-4 的 50 分之一。
Qwen-Long:性价比之王,通义千问 GPT-4 级主力模型。API 输入价格降至 0.0005 元/千 tokens。这意味着,1 块钱可以买 200 万 tokens,相当于 5 本《新华字典》的文字量。这款模型最高支持 1 千万 tokens 长文本输入,价格约为 GPT-4 价格的 1/400。
Qwen-Max:通义千问旗舰款大模型。API 输入价格降至 0.04 元/千 tokens。Qwen-Max 是目前业界表现最好的中文大模型,在权威基准 OpenCompass 上性能追平 GPT-4-Turbo,并在大模型竞技场 Chatbot Arena 中跻身全球前 15。
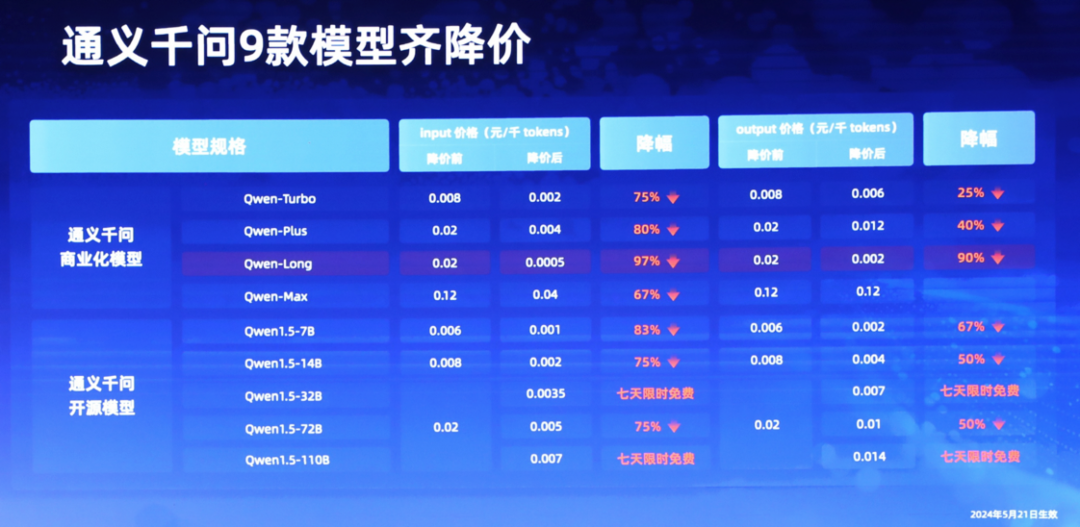
所以,国内大模型真的是便宜又好用。
③
开源或许才是未来
我们经常听到开源大模型和闭源大模型之争,尤其是,红衣大叔周鸿祎,每天都在网上说大模型开源才是未来。
其实,从目前来看,开源的未来可能确实比闭源更清晰,更有发展。
毕竟,现在的通用大模型从算力和电力上确实遇到自己的局限性了。而根据开源大模型去微调适合自己的应用场景,可能更节省算力和电力。
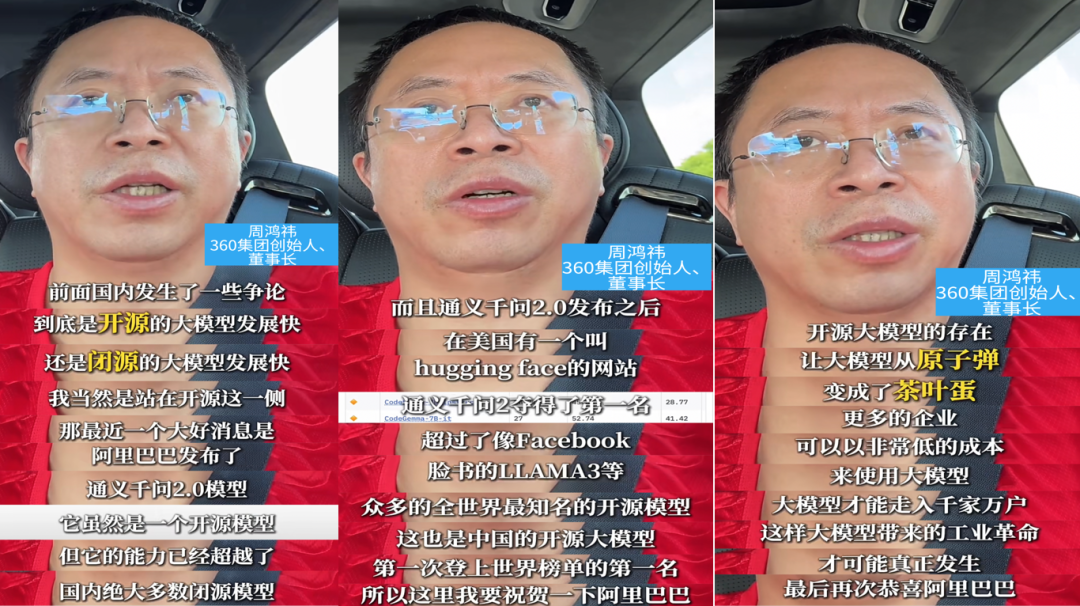
周鸿祎在阿里巴巴登顶开源大模型宝座的时候,发视频说:
点赞开源的存在,让大模型从原子弹变成了茶叶蛋,让企业低成本使用,让大模型时代的工业革命能够发生。
猎豹移动的 CEO 傅盛也是这么认为的,他说:
开源不是简单地做雷锋,而是结合自己的商业模式,结合能够形成社区反馈能力的战略部署。

我挺认可傅盛的观点的。
开源的大模型可以形成社区的反馈,群策群力,可以玩出更好的花样,找到更多的应用场景,尤其是开源大模型如果还背靠大公司的话,更有服务保障,就像是李开复所说:
阿里云的平台上汇聚了众多开发者,并配备了完善的工具链,还能充分保障客户的数据安全。
