在实盘交易中,我们在每日盘后更新K线数据、计算扩展指标、筛出候选股票后,需要把新的候选股票数据传递给PTrade,另外需要根据PTrade的实盘交易记录,更新存放在数据库的相关数据,记录哪些股票还需要监测进行交易,哪些股票不需要再监测。本文将完成上述PTrade交易数据的更新过程。
相关库表
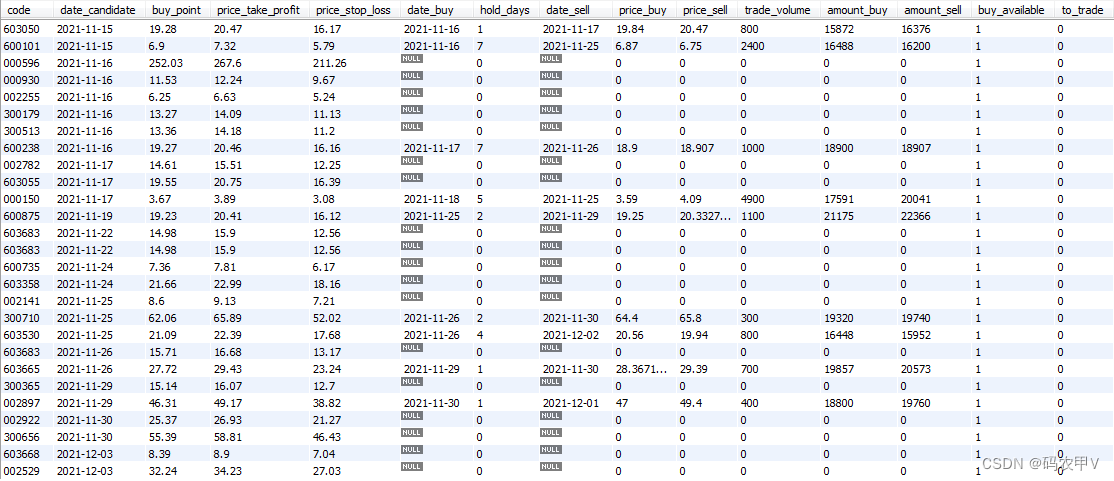
在数据库中,我们保存了ptrade和ptrade_history两张与PTrade交易相关的数据表,两张表的字段完全相同,其中表ptrade保存了待监测交易的数据,表ptrade_history保存了历史监测或交易的数据,表内容示例如下图所示,各字段的含义可参考前文。
主要代码分析
新建源文件,命名为data_center_v13.py,全部内容见文末,主要涉及以下变动:
新增全局变量
首先定义几个全局变量:
g_ptrade_upload_path = 'D:/quant_from_scratch/quant_from_scratch/a-share/data/file_update/trade_data.csv' # 自行设定
这里定义了一个文件的绝对路径,该文件由data_center.py输出,里面包含了待交易的股票数据。我们在下篇文章会介绍如何在PTrade中进行设置,使该文件定时上传到PTrade。
g_ptrade_export_dir = 'D:/quant_from_scratch/quant_from_scratch/a-share/data/file_export/' # 自行设定
这里定义了一个目录的绝对路径,该目录是PTrade算法单功能输出文件的目录,文件内会包含交易数据。我们在下篇文章会介绍如何在PTrade中设置该目录,这样data_center就可以读取到交易数据。
g_take_profit_percent = 0.0618
g_stop_loss_percent = 0.1618
这里定义了止盈和止损比例,所使用的值均有回测程序进行参数优化后得到,当较买点上涨6.18%卖出止盈,较卖点下跌16.18%卖出止损。
新增更新PTrade交易数据函数
def update_ptrade(df):
该函数用于更新PTrade交易数据,其中:
- 参数df为包含当日候选股票日线数据的DataFrame
所有和PTrade进行交易的功能均在该函数内实现。
update_ptrade_candidate(df)
将候选更新到数据库中。
update_ptrade_deal()
从PTrade获取成交信息,在数据库中进行更新。
update_ptrade_hold_days()
盘后更新数据库中持仓股票的持有天数字段。
update_ptrade_to_trade()
盘后更新数据库中股票是否继续日后交易。
output_ptrade_file()
输出ptrade交易所需的文件。
新增更新PTrade候选数据函数
def update_ptrade_candidate(df):
该函数根据当日日线数据,选出候选交易股票,待交易数据写入数据库,其中:
- 参数df为包含当日候选股票日线数据的DataFrame
if not df.shape[0]:
return
如果无新增候选股票,则退出。
out_df = df['68' != df['code'].str[:2]]
因笔者无科创板权限,这里删除科创板数据。
if not out_df.shape[0]:
return
如果此时out_df为空,则直接退出。
table_name = 'ptrade'
ptrade表名。
engine = create_mysql_engine()
创建数据库引擎对象。
date_col = 'date_candidate'
日期列名。
if table_name in sqlalchemy.inspect(engine).get_table_names():
sql_cmd = 'SELECT {0} FROM {1} ORDER BY {0} DESC LIMIT 1;'.format(date_col, table_name)
db_df = pd.read_sql(sql=sql_cmd, con=engine)
获取按时间降序的第1行数据,即获取最新1条记录。
if db_df.shape[0]:
db_date = db_df[date_col].iloc[0]
获取数据库中的最新候选日期。
if db_date >= out_df['date'].iloc[0]:
return
如果数据库中候选日期已为最新,则无需更新,避免重复添加。
out_df = out_df[['code', 'date', 'close']]
buy_point = 'buy_point'
out_df = out_df.rename(columns={'date': 'date_candidate', 'close': buy_point})
out_df['price_take_profit'] = out_df[buy_point].apply(
lambda x: math.floor(x * (1 + g_take_profit_percent) * 100) / 100)
out_df['price_stop_loss'] = out_df[buy_point].apply(lambda x: math.ceil(x * (1 - g_stop_loss_percent) * 100) / 100)
out_df['date_buy'] = None
out_df['hold_days'] = 0
out_df['date_sell'] = None
out_df['price_buy'] = 0.0
out_df['price_sell'] = 0.0
out_df['trade_volume'] = 0
out_df['amount_buy'] = 0.0
out_df['amount_sell'] = 0.0
out_df['buy_available'] = 0
out_df['to_trade'] = 1
设置候选数据各字段的值。
if out_df.shape[0]:
out_df.to_sql(name=table_name, con=engine, if_exists='append', index=False)
将新选出的候选股票数据append到数据库
engine.dispose()
关闭数据库连接。
新增更新PTrade成交信息函数
def update_ptrade_deal():
该函数从ptrade获取成交信息,在数据库中进行更新,这是数据中心从PTrade获取交易数据的方式。PTrade会每个一段时间(该时间可设置)将交易、持仓等数据写入指定文件,可以通过读取这些文件来获取去实盘交易和仓位等数据。
engine = create_mysql_engine()
创建数据库引擎对象。
db_tables = sqlalchemy.inspect(engine).get_table_names()
获取数据库内所有表的表名。
table_name = 'ptrade'
if table_name not in db_tables:
return
判断是否存在表ptrade,不存在则无需更新。
sql_cmd = 'SELECT * FROM {};'.format(table_name)
db_data = pd.read_sql(sql=sql_cmd, con=engine)
读取待交易数据数据。
today = datetime.datetime.today().strftime('%Y-%m-%d')
deal_file = '{}Deal_{}.csv'.format(g_ptrade_export_dir, today.replace('-', ''))
deal_df = pd.DataFrame()
读取ptrade输出的交易文件。
if os.path.exists(deal_file):
deal_df = pd.read_csv(deal_file, encoding='gbk', usecols=['证券代码', '买卖方向', '成交数量', '成交价格', '成交金额'],
converters={'证券代码': str})
else:
print('无交易文件!')
判断交易文件是否存在。
if not deal_df.shape[0]:
return
没有成交,则无需更新。
group = deal_df.groupby(['证券代码', '买卖方向'])
deal_df['总金额'] = group['成交金额'].transform('sum')
deal_df['总数量'] = group['成交数量'].transform('sum')
deal_df['均价'] = deal_df['总金额'] / deal_df['总数量']
deal_df = deal_df.drop_duplicates(['证券代码', '买卖方向'])
合并交易数据,按证券代码和买卖方向对数据分组,求取总成交金额、总成交数量和均价。
for row in deal_df.itertuples():
合并后交易数据按行循环处理。
if '卖出' == getattr(row, '买卖方向'):
idcs = db_data[db_data['code'] == getattr(row, '证券代码')].index
if len(idcs) < 1:
continue
idx = idcs[0]
db_data.loc[idx, 'date_sell'] = today
db_data.loc[idx, 'price_sell'] = getattr(row, '均价')
db_data.loc[idx, 'amount_sell'] = getattr(row, '总金额')
db_data.loc[idx, 'to_trade'] = 0
处理卖出成交数据,填写数据库中该股票的卖出日期、卖出价格、总卖出金额字段,并设置股票为不再交易。
if '买入' == getattr(row, '买卖方向'):
idcs = db_data[db_data['code'] == getattr(row, '证券代码')].index
if len(idcs) < 1:
continue
idx = idcs[0]
db_data.loc[idx, 'date_buy'] = today()
db_data.loc[idx, 'price_buy'] = getattr(row, '均价')
db_data.loc[idx, 'trade_volume'] = getattr(row, '总数量')
db_data.loc[idx, 'amount_buy'] = getattr(row, '总金额')
db_data.loc[idx, 'buy_available'] = 1
处理买入成交数据,填写数据库中该股票的买入日期、买入价格、总买入数量、总买入金额、是否到达买点字段。
db_data.to_sql(name=table_name, con=engine, if_exists='replace', index=False)
将更新后的待交易数据写回数据库。
engine.dispose()
关闭数据库连接。
新增更新数据库中持仓股票的持有天数字段函数
def update_ptrade_hold_days():
该函数用于盘后更新数据库中持仓股票的持有天数字段,我们的策略会在持股达到天数限制后,强制卖出股票。
engine = create_mysql_engine()
创建数据库引擎对象。
db_tables = sqlalchemy.inspect(engine).get_table_names()
获取数据库内所有表的表名。
table_name = 'ptrade'
if table_name not in db_tables:
return
判断是否存在表ptrade,不存在则无需更新。
sql_cmd = 'SELECT * FROM {};'.format(table_name)
db_data = pd.read_sql(sql=sql_cmd, con=engine)
读取待交易数据数据。
for row in db_data.itertuples():
待交易数据循环。
if getattr(row, 'to_trade') and getattr(row, 'date_buy') is not None:
只更新待交易且已买入的股票。
sql_cmd = 'SELECT * FROM {} ORDER BY date DESC LIMIT {};'.format(get_table_name(getattr(row, 'code')), 10)
read_df = pd.read_sql(sql=sql_cmd, con=engine)
if read_df.shape[0] < 1:
continue
查询数据库个股的日线数据,计算hold_days。
after_buy_df = read_df[read_df['date'] > getattr(row, 'date_buy')]
db_data.loc[getattr(row, 'Index'), 'hold_days'] = after_buy_df.shape[0] + 1
选出日期大于买入日期的行,行数+1即为持股的天数。
db_data.to_sql(name='ptrade', con=engine, if_exists='replace', index=False)
将更新后的待交易数据写回数据库。
engine.dispose()
关闭数据库连接。
新增更新数据库中股票是否继续日后交易函数
def update_ptrade_to_trade():
该函数用于盘后更新数据库中股票是否继续日后交易,更新是否继续监测交易字段,如果该字段值为1,表示继续监测交易,如果值0,则表示不再进行监测交易,数据会被移动到表ptrade_history中。
engine = create_mysql_engine()
创建数据库引擎对象。
db_tables = sqlalchemy.inspect(engine).get_table_names()
获取数据库内所有表的表名。
table_name = 'ptrade'
if table_name not in db_tables:
return
判断是否存在表ptrade,不存在则无需更新。
sql_cmd = 'SELECT * FROM {};'.format(table_name)
db_data = pd.read_sql(sql=sql_cmd, con=engine)
读取待交易数据数据。
sql_cmd = 'SELECT * FROM latest;'
latest_df = pd.read_sql(sql=sql_cmd, con=engine)
读取最新一日所有股票的日线数据。
buy_available = 'buy_available'
是否达到买点的字段名称。
for row in db_data.itertuples():
待交易数据循环。
if getattr(row, 'date_candidate') >= datetime.datetime.today().strftime('%Y-%m-%d'):
continue
当日更新选出的候选股票,不更新是否交易字段。
if getattr(row, buy_available) > 0:
continue
已达到买点的股票,不更新是否交易字段。
idcs = latest_df[latest_df['code'] == getattr(row, 'code')].index
if len(idcs) < 1:
continue
在最新日线数据表中,查询对应股票的位置。
if latest_df.loc[idcs[0], 'low'] <= getattr(row, 'buy_point'):
当日最低价小于等于买点价格,表示股票当日达到了买点。
db_data.loc[getattr(row, 'Index'), buy_available] = 1
标记股票已达到买点。
if getattr(row, 'date_buy') is None:
db_data.loc[getattr(row, 'Index'), 'to_trade'] = 0
如果该股票尚未买入,则不再进行交易,标记是否交易字段为0,不再监测交易。
trade_data = db_data[db_data['to_trade'] == 1]
history_data = db_data[db_data['to_trade'] == 0]
选出待交易数据及不再交易数据。
trade_data.to_sql(name='ptrade', con=engine, if_exists='replace', index=False)
history_data.to_sql(name='ptrade_history', con=engine, if_exists='append', index=False)
更新待交易数据,并将不再交易的数据添加到历史数据表中。
engine.dispose()
关闭数据库连接。
新增输出待交易信息函数
def output_ptrade_file():
该函数用于输出PTrade交易所需的文件,文件内包含待监测交易股票数据。我们只能通过文件方式向ptrade传递数据,PTrade提供定时上传文件功能,将交易所需的数据写入指定文件,供PTrade读取使用。
engine = create_mysql_engine()
创建数据库引擎对象。
db_tables = sqlalchemy.inspect(engine).get_table_names()
获取数据库内所有表的表名。
table_name = 'ptrade'
if table_name not in db_tables:
return
判断是否存在表ptrade,不存在则无需更新。
sql_cmd = 'SELECT * FROM {};'.format(table_name)
db_data = pd.read_sql(sql=sql_cmd, con=create_mysql_engine())
读取数据库中待交易表数据。
engine.dispose()
关闭数据库连接。
db_data.to_csv(g_ptrade_upload_path, index=False, encoding='utf-8')
将待交易数据写到指定文件,供ptrade读取。
小结
本文完成了PTrade交易数据的更新,还有一些步骤需要在PTrade软件中配置完成,在下一篇文章会详细介绍。
data_center_v13.py的全部代码如下:
import baostock as bs
import datetime
import time
import sys
import numpy as np
import pandas as pd
import multiprocessing
import sqlalchemy
import matplotlib.pyplot as plt
from pandas.plotting import table
import math
import os
# 可用日线数量约束
g_available_days_limit = 250
# BaoStock日线数据字段
g_baostock_data_fields = 'date,open,high,low,close,preclose,volume,amount,adjustflag,turn,tradestatus,pctChg,peTTM,pbMRQ, psTTM,pcfNcfTTM,isST'
# 定时上传到ptrade的文件路径
g_ptrade_upload_path = 'D:/quant_from_scratch/quant_from_scratch/a-share/data/file_update/trade_data.csv' # 自行设定
# ptrade输出交易数据文件目录
g_ptrade_export_dir = 'D:/quant_from_scratch/quant_from_scratch/a-share/data/file_export/' # 自行设定
# 止盈比例
g_take_profit_percent = 0.0618
# 止损比例
g_stop_loss_percent = 0.1618
def create_mysql_engine():
"""
创建数据库引擎对象
:return: 新创建的数据库引擎对象
"""
# 引擎参数信息
host = 'localhost'
user = 'root'
passwd = '111111'
port = '3306'
db = 'db_quant'
# 创建数据库引擎对象
mysql_engine = sqlalchemy.create_engine(
'mysql+pymysql://{0}:{1}@{2}:{3}'.format(user, passwd, host, port),
poolclass=sqlalchemy.pool.NullPool
)
# 如果不存在数据库db_quant则创建
mysql_engine.execute("CREATE DATABASE IF NOT EXISTS {0} ".format(db))
# 创建连接数据库db_quant的引擎对象
db_engine = sqlalchemy.create_engine(
'mysql+pymysql://{0}:{1}@{2}:{3}/{4}?charset=utf8'.format(user, passwd, host, port, db),
poolclass=sqlalchemy.pool.NullPool
)
# 返回引擎对象
return db_engine
def get_stock_codes(date=None, update=False):
"""
获取指定日期的A股代码列表
若参数update为False,表示从数据库中读取股票列表
若数据库中不存在股票列表的表,或者update为True,则下载指定日期date的交易股票列表
若参数date为空,则返回最近1个交易日的A股代码列表
若参数date不为空,且为交易日,则返回date当日的A股代码列表
若参数date不为空,但不为交易日,则打印提示非交易日信息,程序退出
:param date: 日期,默认为None
:param update: 是否更新股票列表,默认为False
:return: A股代码的列表
"""
# 创建数据库引擎对象
engine = create_mysql_engine()
# 数据库中股票代码的表名
table_name = 'stock_codes'
# 数据库中不存在股票代码表,或者需要更新股票代码表
if table_name not in sqlalchemy.inspect(engine).get_table_names() or update:
# 登录baostock
bs.login()
# 从BaoStock查询股票数据
stock_df = bs.query_all_stock(date).get_data()
# 如果获取数据长度为0,表示日期date非交易日
if 0 == len(stock_df):
# 如果设置了参数date,则打印信息提示date为非交易日
if date is not None:
print('当前选择日期为非交易日或尚无交易数据,请设置date为历史某交易日日期')
sys.exit(0)
# 未设置参数date,则向历史查找最近的交易日,当获取股票数据长度非0时,即找到最近交易日
delta = 1
while 0 == len(stock_df):
stock_df = bs.query_all_stock(datetime.date.today() - datetime.timedelta(days=delta)).get_data()
delta += 1
# 注销登录
bs.logout()
# 筛选股票数据,上证和深证股票代码在sh.600000与sz.39900之间
stock_df = stock_df[(stock_df['code'] >= 'sh.600000') & (stock_df['code'] < 'sz.399000')]
# 将股票代码写入数据库
stock_df.to_sql(name=table_name, con=engine, if_exists='replace', index=False, index_label=False)
# 返回股票列表
return stock_df['code'].tolist()
# 从数据库中读取股票代码列表
else:
# 待执行的sql语句
sql_cmd = 'SELECT {} FROM {}'.format('code', table_name)
# 读取sql,返回股票列表
return pd.read_sql(sql=sql_cmd, con=engine)['code'].tolist()
def create_data(stock_codes, from_date='1990-12-19', to_date=datetime.date.today().strftime('%Y-%m-%d'),
adjustflag='2'):
"""
下载指定日期内,指定股票的日线数据,计算扩展因子
:param stock_codes: 待下载数据的股票代码
:param from_date: 日线开始日期
:param to_date: 日线结束日期
:param adjustflag: 复权选项 1:后复权 2:前复权 3:不复权 默认为前复权
:return: None
"""
# 创建数据库引擎对象
engine = create_mysql_engine()
# 下载股票循环
for index, code in enumerate(stock_codes):
print('({}/{})正在创建{}...'.format(index + 1, len(stock_codes), code))
# 登录BaoStock
bs.login()
# 下载日线数据
out_df = bs.query_history_k_data_plus(code, g_baostock_data_fields, start_date=from_date, end_date=to_date,
frequency='d', adjustflag=adjustflag).get_data()
# 剔除停盘数据
if out_df.shape[0]:
out_df = out_df[(out_df['volume'] != '0') & (out_df['volume'] != '')]
# 如果数据为空,则不创建
if not out_df.shape[0]:
continue
# 删除重复数据
out_df.drop_duplicates(['date'], inplace=True)
# 日线数据少于g_available_days_limit,则不创建
if out_df.shape[0] < g_available_days_limit:
continue
# 将数值数据转为float型,便于后续处理
convert_list = ['open', 'high', 'low', 'close', 'preclose', 'volume', 'amount', 'turn', 'pctChg']
out_df[convert_list] = out_df[convert_list].astype(float)
# 重置索引
out_df.reset_index(drop=True, inplace=True)
# 计算扩展因子
out_df = extend_factor(out_df)
# 写入数据库
table_name = '{}_{}'.format(code[3:], code[:2])
out_df.to_sql(name=table_name, con=engine, if_exists='replace', index=True, index_label='id')
def get_code_group(process_num, stock_codes):
"""
获取代码分组,用于多进程计算,每个进程处理一组股票
:param process_num: 进程数
:param stock_codes: 待处理的股票代码
:return: 分组后的股票代码列表,列表的每个元素为一组股票代码的列表
"""
# 创建空的分组
code_group = [[] for i in range(process_num)]
# 按余数为每个分组分配股票
for index, code in enumerate(stock_codes):
code_group[index % process_num].append(code)
return code_group
def multiprocessing_func(func, args):
"""
多进程调用函数
:param func: 函数名
:param args: func的参数,类型为元组,第0个元素为进程数,第1个元素为股票代码列表
:return: 包含各子进程返回对象的列表
"""
# 用于保存各子进程返回对象的列表
results = []
# 创建进程池
with multiprocessing.Pool(processes=args[0]) as pool:
# 多进程异步计算
for codes in get_code_group(args[0], args[1]):
results.append(pool.apply_async(func, args=(codes, *args[2:],)))
# 阻止后续任务提交到进程池
pool.close()
# 等待所有进程结束
pool.join()
return results
def create_data_mp(stock_codes, process_num=61,
from_date='1990-12-19', to_date=datetime.date.today().strftime('%Y-%m-%d'), adjustflag='2'):
"""
使用多进程创建指定日期内,指定股票的日线数据,计算扩展因子
:param stock_codes: 待创建数据的股票代码
:param process_num: 进程数
:param from_date: 日线开始日期
:param to_date: 日线结束日期
:param adjustflag: 复权选项 1:后复权 2:前复权 3:不复权 默认为前复权
:return: None
"""
multiprocessing_func(create_data, (process_num, stock_codes, from_date, to_date, adjustflag,))
def extend_factor(df):
"""
计算扩展因子
:param df: 待计算扩展因子的DataFrame
:return: 包含扩展因子的DataFrame
"""
# 使用pipe依次计算涨停、双神及是否为候选股票
df = df.pipe(zt).pipe(ss, delta_days=30).pipe(candidate)
return df
def zt(df):
"""
计算涨停因子
若涨停,则因子为True,否则为False
以当日收盘价较前一日收盘价上涨9.8%及以上作为涨停判断标准
:param df: 待计算扩展因子的DataFrame
:return: 包含扩展因子的DataFrame
"""
df['zt'] = np.where((df['close'].values >= 1.098 * df['preclose'].values), True, False)
return df
def shift_i(df, factor_list, i, fill_value=0, suffix='a'):
"""
计算移动因子,用于获取前i日或者后i日的因子
:param df: 待计算扩展因子的DataFrame
:param factor_list: 待移动的因子列表
:param i: 移动的步数
:param fill_value: 用于填充NA的值,默认为0
:param suffix: 值为a(ago)时表示移动获得历史数据,用于计算指标;值为l(later)时表示获得未来数据,用于计算收益
:return: 包含扩展因子的DataFrame
"""
# 选取需要shift的列构成新的DataFrame,进行shift操作
shift_df = df[factor_list].shift(i, fill_value=fill_value)
# 对新的DataFrame列进行重命名
shift_df.rename(columns={x: '{}_{}{}'.format(x, i, suffix) for x in factor_list}, inplace=True)
# 将重命名后的DataFrame合并到原始DataFrame中
df = pd.concat([df, shift_df], axis=1)
return df
def shift_till_n(df, factor_list, n, fill_value=0, suffix='a'):
"""
计算范围移动因子
用于获取前/后n日内的相关因子,内部调用了shift_i
:param df: 待计算扩展因子的DataFrame
:param factor_list: 待移动的因子列表
:param n: 移动的步数范围
:param fill_value: 用于填充NA的值,默认为0
:param suffix: 值为a(ago)时表示移动获得历史数据,用于计算指标;值为l(later)时表示获得未来数据,用于计算收益
:return: 包含扩展因子的DataFrame
"""
for i in range(n):
df = shift_i(df, factor_list, i + 1, fill_value, suffix)
return df
def ss(df, delta_days=30):
"""
计算双神因子,即间隔的两个涨停
若当日形成双神,则因子为True,否则为False
:param df: 待计算扩展因子的DataFrame
:param delta_days: 两根涨停间隔的时间不能超过该值,否则不判定为双神,默认值为30
:return: 包含扩展因子的DataFrame
"""
# 移动涨停因子,求取近delta_days天内的涨停情况,保存在一个临时DataFrame中
temp_df = shift_till_n(df, ['zt'], delta_days, fill_value=False)
# 生成列表,用于后续检索第2天前至第delta_days天前是否有涨停出现
col_list = ['zt_{}a'.format(x) for x in range(2, delta_days + 1)]
# 计算双神,需同时满足3个条件:
# 1、第2天前至第delta_days天前,至少有1个涨停
# 2、1天前不是涨停(否则就是连续涨停,不是间隔的涨停)
# 3、当天是涨停
df['ss'] = temp_df[col_list].any(axis=1) & ~temp_df['zt_1a'] & temp_df['zt']
return df
def ma(df, n=5, factor='close'):
"""
计算均线因子
:param df: 待计算扩展因子的DataFrame
:param n: 待计算均线的周期,默认计算5日均线
:param factor: 待计算均线的因子,默认为收盘价
:return: 包含扩展因子的DataFrame
"""
# 均线名称,例如,收盘价的5日均线名称为ma_5,成交量的5日均线名称为volume_ma_5
name = '{}ma_{}'.format('' if 'close' == factor else factor + '_', n)
# 取待计算均线的因子列
s = pd.Series(df[factor], name=name, index=df.index)
# 利用rolling和mean计算均线数据
s = s.rolling(center=False, window=n).mean()
# 将均线数据添加到原始的DataFrame中
df = df.join(s)
# 均线数值保留两位小数
df[name] = df[name].apply(lambda x: round(x + 0.001, 2))
return df
def mas(df, ma_list, factor='close'):
"""
计算多条均线因子,内部调用ma计算单条均线
:param df: 待计算扩展因子的DataFrame
:param ma_list: 待计算均线的周期列表
:param factor: 待计算均线的因子,默认为收盘价
:return: 包含扩展因子的DataFrame
"""
for i in ma_list:
df = ma(df, i, factor)
return df
def cross_mas(df, ma_list):
"""
计算穿均线因子
若当日最低价不高于均线价格
且当日收盘价不低于均线价格
则当日穿均线因子值为True,否则为False
:param df: 待计算扩展因子的DataFrame
:param ma_list: 均线的周期列表
:return: 包含扩展因子的DataFrame
"""
for i in ma_list:
df['cross_{}'.format(i)] = (df['low'] <= df['ma_{}'.format(i)]) & (
df['ma_{}'.format(i)] <= df['close'])
return df
def candidate(df):
"""
计算是否为候选
若当日日线同时穿过5、10、20、30日均线
且30日均线在60日均线上方
且当日形成双神
则当日作为候选,该因子值为True,否则为False
:param df: 待计算扩展因子的DataFrame
:return: 包含扩展因子的DataFrame
"""
# 均线周期列表
ma_list = [5, 10, 20, 30, 60]
# 计算均线的因子,保存到临时的DataFrame中
temp_df = mas(df, ma_list)
# 计算穿多线的因子,保存到临时的DataFrame中
temp_df = cross_mas(temp_df, ma_list)
# 穿多线因子的列名列表
column_list = ['cross_{}'.format(x) for x in ma_list[:-1]]
# 计算是否为候选
df['candidate'] = temp_df[column_list].all(axis=1) & (temp_df['ma_30'] >= temp_df['ma_60']) & df['ss']
return df
def profit_loss_statistic(stock_codes, hold_days=10):
"""
盈亏分布统计,计算当日candidate为True,持仓hold_days天的收益分布
:param stock_codes: 待分析的股票代码
:param hold_days: 持仓天数
:return: 筛选出符合买入条件的股票DataFrame
"""
# 创建数据库引擎对象
engine = create_mysql_engine()
# 创建空的DataFrame
candidate_df = pd.DataFrame()
# 计算收益分布循环
for code in stock_codes:
print('正在处理{}...'.format(code))
# 股票数据在数据库中的表名
table_name = '{}_{}'.format(code[3:], code[:2])
# 如果数据库中没有该股票数据则跳过
if table_name not in sqlalchemy.inspect(engine).get_table_names():
continue
# 从数据库读取特定字段数据
cols = 'date, open, high, low, close, candidate'
sql_cmd = 'SELECT {} FROM {} ORDER BY date DESC'.format(cols, table_name)
df = pd.read_sql(sql=sql_cmd, con=engine)
# 移动第2日开盘价、最低价,以及hold_days的最高价、最低价数据
df = shift_i(df, ['open'], 1, suffix='l')
df = shift_till_n(df, ['high', 'low'], hold_days, suffix='l')
# 丢弃最近hold_days日的数据
df = df.iloc[hold_days: df.shape[0] - g_available_days_limit, :]
# 选取出现买点的股票
df = df[(df['candidate'] > 0) & (df['low_1l'] <= df['close'])]
# 将数据添加到候选池中
if df.shape[0]:
df['code'] = code
candidate_df = candidate_df.append(df)
if candidate_df.shape[0]:
# 计算最大盈利
# 买入当天无法卖出,因此计算最大收益时,从第2日开始
cols = ['high_{}l'.format(x) for x in range(2, hold_days + 1)]
candidate_df['max_high'] = candidate_df[cols].max(axis=1)
candidate_df['max_profit'] = candidate_df['max_high'] / candidate_df[['open_1l', 'close']].min(axis=1) - 1
# 计算最大亏损
cols = ['low_{}l'.format(x) for x in range(2, hold_days + 1)]
candidate_df['min_low'] = candidate_df[cols].min(axis=1)
candidate_df['max_loss'] = candidate_df['min_low'] / candidate_df[['open_1l', 'close']].min(axis=1) - 1
return candidate_df
def multiprocessing_func_df(func, args):
"""
多进程调用函数,收集返回各子进程返回的DataFrame
:param func: 函数名
:param args: func的参数,类型为元组,第0个元素为进程数,第1个元素为股票代码列表
:return: 包含各子进程返回值的DataFrame
"""
# 多进程调用函数func,获取子进程返回对象的列表
results = multiprocessing_func(func, args)
# 构建空DataFrame
df = pd.DataFrame()
# 收集各进程返回值
for i in results:
df = df.append(i.get())
return df
def profit_loss_statistic_mp(stock_codes, process_num=61, hold_days=10):
"""
多进程盈亏分布统计,计算当日candidate为True,持仓hold_days天的收益分布
输出数据分布表格及图片文件
:param stock_codes: 待分析的股票代码
:param process_num: 进程数
:param hold_days: 持仓天数
:return: None
"""
# 多进程计算获得候选股票数据
candidate_df = multiprocessing_func_df(profit_loss_statistic, (process_num, stock_codes, hold_days,))
# 将收益分布数据保存到excel文件
candidate_df[['date', 'code', 'max_profit', 'max_loss']].to_excel(
'profit_loss_{}.xlsx'.format(hold_days), index=False, encoding='utf-8')
# 重置索引,方便后面绘图
candidate_df.reset_index(inplace=True)
# 设置绘图格式并绘图
fig, ax = plt.subplots(1, 1)
table(ax, np.round(candidate_df[['max_profit', 'max_loss']].describe(), 4), loc='upper right',
colWidths=[0.2, 0.2, 0.2])
candidate_df[['max_profit', 'max_loss']].plot(ax=ax, legend=None)
# 保存图表
fig.savefig('profit_loss_{}.png'.format(hold_days))
# 显示图表
plt.show()
def update_data(stock_codes, query_days=60, adjustflag='2'):
"""
更新日线数据,计算相关因子
:param stock_codes: 待更新数据的股票代码
:param query_days: 在数据库中查询历史日线数据的天数,用于计算扩展因子,需要根据扩展因子设置,这里要计算60日均线,所以最小设置为60
:param adjustflag: 复权选项 1:后复权 2:前复权 3:不复权 默认为前复权
:return: 包含所有待处理股票的最新日线数据及扩展因子的DataFrame
"""
# 创建数据库引擎对象
engine = create_mysql_engine()
# 创建空DataFrame,存储最新一日的数据
latest_df = pd.DataFrame()
# 更新数据循环
for index, code in enumerate(stock_codes):
print('({}/{})正在更新{}...'.format(index + 1, len(stock_codes), code))
# 登录BaoStock
bs.login()
# 股票数据在数据库中的表名
table_name = '{}_{}'.format(code[3:], code[:2])
# 判断是否存在该表,不存在则跳过
if table_name not in sqlalchemy.inspect(engine).get_table_names():
continue
# 获取按时间排序的最后query_days行数据
sql_cmd = 'SELECT * FROM {} ORDER BY date DESC LIMIT {};'.format(table_name, query_days)
read_df = pd.read_sql(sql=sql_cmd, con=engine)
# 如果数据少于query_days,则不更新
if read_df.shape[0] < query_days:
continue
# 数据按id(date)升序排序
read_df = read_df.sort_values(by='id', ascending=True)
# 获取数据库中最新数据日期及id
last_id = read_df['id'].iloc[-1]
from_date = read_df['date'].iloc[-1]
# 如果数据库中已包含最新一日数据
if from_date >= datetime.date.today().strftime('%Y-%m-%d'):
# 将最新一日数据,添加code字段,append到latest_df中,并进行下一只股票更新
latest_series = read_df.iloc[-1].copy()
latest_series['code'] = code[3:]
latest_df = latest_df.append(latest_series)
print('{}当前已为最新数据'.format(code))
continue
# 计算待更新数据的开始日期
from_date = (datetime.datetime.strptime(
from_date, '%Y-%m-%d') + datetime.timedelta(days=1)).strftime('%Y-%m-%d')
# 下载日线数据
out_df = bs.query_history_k_data_plus(code, g_baostock_data_fields, start_date=from_date,
end_date=datetime.date.today().strftime('%Y-%m-%d'),
frequency='d', adjustflag=adjustflag).get_data()
# 剔除停盘数据
if out_df.shape[0]:
out_df = out_df[(out_df['volume'] != '0') & (out_df['volume'] != '')]
# 如果数据为空,则不更新
if not out_df.shape[0]:
continue
# 将数值数据转为float型,便于后续处理
convert_list = ['open', 'high', 'low', 'close', 'preclose', 'volume', 'amount', 'turn', 'pctChg']
out_df[convert_list] = out_df[convert_list].astype(float)
# 新添加行数
new_rows = out_df.shape[0]
# 获取下载字段,拼接DataFrame,用于后续计算扩展指标
out_df = read_df[list(out_df)].append(out_df)
# 重置索引
out_df.reset_index(drop=True, inplace=True)
# 计算扩展因子
out_df = extend_factor(out_df)
# 取最后new_rows行
out_df = out_df.iloc[-new_rows:]
# 判读是否有字段缺失
if np.any(out_df.isnull()):
print('{}有缺失字段!!!'.format(code))
# 更新id
out_df['id'] = pd.Series(np.arange(last_id + 1, last_id + 1 + new_rows), index=out_df.index)
# 将更新数据写入数据库
out_df.to_sql(name=table_name, con=engine, if_exists='append', index=False)
# 将更新的最后一行添加code字段,append到latest_df中
latest_series = out_df.iloc[-1].copy()
latest_series['code'] = code[3:]
latest_df = latest_df.append(latest_series)
# 返回包含最新一日股票日线数据的DataFrame
return latest_df
def update_data_mp(stock_codes, process_num=61, query_days=60, adjustflag='2'):
"""
使用多进程更新日线数据,计算扩展因子
:param stock_codes: 待更新数据的股票代码
:param process_num: 进程数
:param query_days: 在数据库中查询历史日线数据的天数,用于计算扩展因子
:param adjustflag: 复权选项 1:后复权 2:前复权 3:不复权 默认为前复权
:return: 包含所有待处理股票的最新日线数据的DataFrame
"""
# 多进程更新数据,获取最新日线数据的DataFrame
latest_df = multiprocessing_func_df(update_data, (process_num, stock_codes, query_days, adjustflag,))
# 将所有股票最新日线数据写入数据库表latest
if latest_df.shape[0]:
latest_df.to_sql(name='latest', con=create_mysql_engine(), if_exists='replace', index=False)
return latest_df
def update_latest_table(stock_codes):
"""
更新数据库中最新日线数据表
从数据库中读取每只股票的最新一天数据并返回
:param stock_codes: 待更新数据的股票代码
:return: 包含所有待处理股票的最新日线数据的DataFrame
"""
# 创建数据库引擎对象
engine = create_mysql_engine()
# 创建空的DataFrame
latest_df = pd.DataFrame()
# 更新数据循环
for index, code in enumerate(stock_codes):
print('({}/{})正在更新{}...'.format(index + 1, len(stock_codes), code))
# 股票数据在数据库中的表名
table_name = '{}_{}'.format(code[3:], code[:2])
# 判断是否存在该表,不存在则跳过
if table_name not in sqlalchemy.inspect(engine).get_table_names():
continue
# 从数据库中读取股票的最新一天数据
sql_cmd = 'SELECT * FROM {} ORDER BY date DESC LIMIT 1;'.format(table_name)
df = pd.read_sql(sql=sql_cmd, con=engine)
# 有缺失字段就不参与候选
if np.any(df.isnull()):
print('{}有缺失字段!!!'.format(code))
continue
# 添加code字段,并append到latest_df中
df['code'] = code[3:]
latest_df = latest_df.append(df)
return latest_df
def update_latest_table_mp(stock_codes, process_num=61):
"""
多进程更新数据库中最新日线数据表
从各个进程收集每只股票的最新一天数据并返回
:param stock_codes: 待更新数据的股票代码
:param process_num: 进程数
:return: 包含所有待处理股票的最新日线数据的DataFrame
"""
# 多进程更新最新日线数据表,获取该表数据的DataFrame
latest_df = multiprocessing_func_df(update_latest_table, (process_num, stock_codes,))
# 将所有股票最新日线数据写入数据库表latest
if latest_df.shape[0]:
latest_df.to_sql(name='latest', con=create_mysql_engine(), if_exists='replace', index=False)
return latest_df
def query_latest_table(stock_codes, by_latest_table=True):
"""
查询最新日线数据表
:param stock_codes: 待获取最新日线数据的股票代码
:param by_latest_table: 是否通过表latest查询,为True(默认)时,直接从表latest中查询,否则从各个股票数据表中分别读取
:return: 包含所有待处理股票的最新日线数据的DataFrame
"""
# 创建数据库引擎对象
engine = create_mysql_engine()
# 如果设置直接从表latest查询,且表latest存在,则直接从数据库读取数据返回
if by_latest_table and 'latest' in sqlalchemy.inspect(engine).get_table_names():
sql_cmd = 'SELECT * FROM latest;'
return pd.read_sql(sql=sql_cmd, con=engine)
# 否则从各股票数据表中分别读取最新一日数据再返回(过程中会更新表latest)
else:
return update_latest_table_mp(stock_codes)
def update_trade(stock_codes):
"""
更新交易数据
:param stock_codes: 更新股票范围
:return: None
"""
# 查询最新日线数据
df = query_latest_table(stock_codes)
# 筛选出候选股票
df = df[df['candidate'] > 0]
if df.shape[0]:
df = df.sort_values(by='turn')
print(df['code'].tolist())
# 更新ptrade交易数据
update_ptrade(df)
def update_ptrade(df):
"""
更新ptrade交易数据
:param df: 包含当日候选股票日线数据的DataFrame
:return: None
"""
# 将候选更新到数据库中
update_ptrade_candidate(df)
# 从ptrade获取成交信息,在数据库中进行更新
update_ptrade_deal()
# 盘后更新数据库中持仓股票的持有天数字段
update_ptrade_hold_days()
# 盘后更新数据库中股票是否继续日后交易
update_ptrade_to_trade()
# 输出ptrade交易所需的文件
output_ptrade_file()
def update_ptrade_candidate(df):
"""
根据当日日线数据,选出候选交易股票,待交易数据写入数据库
:param df: 包含当日候选股票日线数据的DataFrame
:return: None
"""
if not df.shape[0]:
return
# 删除科创板数据
out_df = df['68' != df['code'].str[:2]]
# out_df为空,则直接退出
if not out_df.shape[0]:
return
# ptrade表名
table_name = 'ptrade'
# 创建数据库引擎对象
engine = create_mysql_engine()
# 日期列名
date_col = 'date_candidate'
# 获取按时间降序的第1行数据
if table_name in sqlalchemy.inspect(engine).get_table_names():
sql_cmd = 'SELECT {0} FROM {1} ORDER BY {0} DESC LIMIT 1;'.format(date_col, table_name)
db_df = pd.read_sql(sql=sql_cmd, con=engine)
if db_df.shape[0]:
# 获取数据库中的最新候选日期
db_date = db_df[date_col].iloc[0]
# 如果数据库中候选日期已为最新,则无需更新,避免重复添加
if db_date >= out_df['date'].iloc[0]:
return
# 设置候选数据各字段的值
out_df = out_df[['code', 'date', 'close']]
buy_point = 'buy_point'
out_df = out_df.rename(columns={'date': 'date_candidate', 'close': buy_point})
out_df['price_take_profit'] = out_df[buy_point].apply(
lambda x: math.floor(x * (1 + g_take_profit_percent) * 100) / 100)
out_df['price_stop_loss'] = out_df[buy_point].apply(lambda x: math.ceil(x * (1 - g_stop_loss_percent) * 100) / 100)
out_df['date_buy'] = None
out_df['hold_days'] = 0
out_df['date_sell'] = None
out_df['price_buy'] = 0.0
out_df['price_sell'] = 0.0
out_df['trade_volume'] = 0
out_df['amount_buy'] = 0.0
out_df['amount_sell'] = 0.0
out_df['buy_available'] = 0
out_df['to_trade'] = 1
# 将新选出的候选股票数据append到数据库
if out_df.shape[0]:
out_df.to_sql(name=table_name, con=engine, if_exists='append', index=False)
# 关闭数据库连接
engine.dispose()
def update_ptrade_deal():
"""
从ptrade获取成交信息,在数据库中进行更新
!!!从ptrade获取交易数据的方式!!!
ptrade会每个一段时间(该时间可设置)将交易、持仓等数据写入指定文件
可以通过读取这些文件来获取去实盘交易和仓位等数据
:return: None
"""
# 创建数据库引擎对象
engine = create_mysql_engine()
# 获取数据库内所有表的表名
db_tables = sqlalchemy.inspect(engine).get_table_names()
# 判断是否存在表ptrade,不存在则无需更新
table_name = 'ptrade'
if table_name not in db_tables:
return
# 读取待交易数据数据
sql_cmd = 'SELECT * FROM {};'.format(table_name)
db_data = pd.read_sql(sql=sql_cmd, con=engine)
# 目录是否存在,不存在则创建
if not os.path.exists(g_ptrade_export_dir):
os.makedirs(g_ptrade_export_dir)
# 读取ptrade输出的交易文件
today = datetime.datetime.today().strftime('%Y-%m-%d')
deal_file = '{}Deal_{}.csv'.format(g_ptrade_export_dir, today.replace('-', ''))
deal_df = pd.DataFrame()
# 判断交易文件是否存在
if os.path.exists(deal_file):
deal_df = pd.read_csv(deal_file, encoding='gbk', usecols=['证券代码', '买卖方向', '成交数量', '成交价格', '成交金额'],
converters={'证券代码': str})
else:
print('无交易文件!')
# 没有成交,则无需更新
if not deal_df.shape[0]:
return
# 合并交易数据,按证券代码和买卖方向对数据分组,求取总成交金额、总成交数量和均价
group = deal_df.groupby(['证券代码', '买卖方向'])
deal_df['总金额'] = group['成交金额'].transform('sum')
deal_df['总数量'] = group['成交数量'].transform('sum')
deal_df['均价'] = deal_df['总金额'] / deal_df['总数量']
deal_df = deal_df.drop_duplicates(['证券代码', '买卖方向'])
# 合并后交易数据按行循环
for row in deal_df.itertuples():
# 处理卖出成交数据,填写数据库中该股票的卖出日期、卖出价格、总卖出金额字段,并设置股票为不再交易
if '卖出' == getattr(row, '买卖方向'):
idcs = db_data[db_data['code'] == getattr(row, '证券代码')].index
if len(idcs) < 1:
continue
idx = idcs[0]
db_data.loc[idx, 'date_sell'] = today
db_data.loc[idx, 'price_sell'] = getattr(row, '均价')
db_data.loc[idx, 'amount_sell'] = getattr(row, '总金额')
db_data.loc[idx, 'to_trade'] = 0
# 处理买入成交数据,填写数据库中该股票的买入日期、买入价格、总买入数量、总买入金额、是否到达买点字段
if '买入' == getattr(row, '买卖方向'):
idcs = db_data[db_data['code'] == getattr(row, '证券代码')].index
if len(idcs) < 1:
continue
idx = idcs[0]
db_data.loc[idx, 'date_buy'] = today()
db_data.loc[idx, 'price_buy'] = getattr(row, '均价')
db_data.loc[idx, 'trade_volume'] = getattr(row, '总数量')
db_data.loc[idx, 'amount_buy'] = getattr(row, '总金额')
db_data.loc[idx, 'buy_available'] = 1
# 将更新后的待交易数据写回数据库
db_data.to_sql(name=table_name, con=engine, if_exists='replace', index=False)
# 关闭数据库连接
engine.dispose()
print('完成ptrade订单信息更新!')
def update_ptrade_hold_days():
"""
盘后更新数据库中持仓股票的持有天数字段
:return: None
"""
# 创建数据库引擎对象
engine = create_mysql_engine()
# 获取数据库内所有表的表名
db_tables = sqlalchemy.inspect(engine).get_table_names()
# 判断是否存在表ptrade,不存在则无需更新
table_name = 'ptrade'
if table_name not in db_tables:
return
# 读取待交易数据数据
sql_cmd = 'SELECT * FROM {};'.format(table_name)
db_data = pd.read_sql(sql=sql_cmd, con=engine)
# 待交易数据循环
for row in db_data.itertuples():
# 只更新待交易且已买入的股票
if getattr(row, 'to_trade') and getattr(row, 'date_buy') is not None:
# 查询数据库个股的日线数据,计算hold_days
sql_cmd = 'SELECT * FROM {} ORDER BY date DESC LIMIT {};'.format(get_table_name(getattr(row, 'code')), 10)
read_df = pd.read_sql(sql=sql_cmd, con=engine)
if read_df.shape[0] < 1:
continue
# 选出日期大于买入日期的行,行数+1即为持股的天数
after_buy_df = read_df[read_df['date'] > getattr(row, 'date_buy')]
db_data.loc[getattr(row, 'Index'), 'hold_days'] = after_buy_df.shape[0] + 1
# 将更新后的待交易数据写回数据库
db_data.to_sql(name='ptrade', con=engine, if_exists='replace', index=False)
# 关闭数据库连接
engine.dispose()
print('完成持有天数更新!')
def update_ptrade_to_trade():
"""
盘后更新数据库中股票是否继续日后交易
:return: None
"""
# 创建数据库引擎对象
engine = create_mysql_engine()
# 获取数据库内所有表的表名
db_tables = sqlalchemy.inspect(engine).get_table_names()
# 判断是否存在表ptrade,不存在则无需更新
table_name = 'ptrade'
if table_name not in db_tables:
return
# 读取待交易数据数据
sql_cmd = 'SELECT * FROM {};'.format(table_name)
db_data = pd.read_sql(sql=sql_cmd, con=engine)
# 读取最新一日所有股票的日线数据
sql_cmd = 'SELECT * FROM latest;'
latest_df = pd.read_sql(sql=sql_cmd, con=engine)
# 是否达到买点的字段名称
buy_available = 'buy_available'
# 待交易数据循环
for row in db_data.itertuples():
# 当日更新选出的候选股票,不更新是否交易字段
if getattr(row, 'date_candidate') >= datetime.datetime.today().strftime('%Y-%m-%d'):
continue
# 已达到买点的股票,不更新是否交易字段
if getattr(row, buy_available) > 0:
continue
# 在最新日线数据表中,查询对应股票的位置
idcs = latest_df[latest_df['code'] == getattr(row, 'code')].index
if len(idcs) < 1:
continue
# 当日最低价小于等于买点价格,表示股票当日达到了买点
if latest_df.loc[idcs[0], 'low'] <= getattr(row, 'buy_point'):
# 标记股票已达到买点
db_data.loc[getattr(row, 'Index'), buy_available] = 1
# 如果该股票尚未买入,则不再进行交易,标记是否交易字段为0
if getattr(row, 'date_buy') is None:
db_data.loc[getattr(row, 'Index'), 'to_trade'] = 0
# 选出待交易数据及不再交易数据
trade_data = db_data[db_data['to_trade'] == 1]
history_data = db_data[db_data['to_trade'] == 0]
# 更新待交易数据,并将不再交易的数据添加到历史数据表中
trade_data.to_sql(name='ptrade', con=engine, if_exists='replace', index=False)
history_data.to_sql(name='ptrade_history', con=engine, if_exists='append', index=False)
# 关闭数据库连接
engine.dispose()
print('完成可交易股票更新!')
def output_ptrade_file():
"""
输出ptrade交易所需的文件
!!!向ptrade传递数据的唯一方式!!!
ptrade提供定时上传文件功能,将交易所需的数据写入指定文件,供ptrade读取使用
:return: None
"""
# 创建数据库引擎对象
engine = create_mysql_engine()
# 获取数据库内所有表的表名
db_tables = sqlalchemy.inspect(engine).get_table_names()
# 判断是否存在表ptrade,不存在则无需更新
table_name = 'ptrade'
if table_name not in db_tables:
return
# 读取数据库中待交易表数据
sql_cmd = 'SELECT * FROM {};'.format(table_name)
db_data = pd.read_sql(sql=sql_cmd, con=create_mysql_engine())
# 关闭数据库连接
engine.dispose()
# 如果不存在目录则创建
upload_dir = g_ptrade_upload_path[:g_ptrade_upload_path.rfind('/')]
if not os.path.exists(upload_dir):
os.makedirs(upload_dir)
# 将待交易数据写到指定文件,供ptrade读取
db_data.to_csv(g_ptrade_upload_path, index=False, encoding='utf-8')
if __name__ == '__main__':
start_time = time.time()
stock_codes = get_stock_codes()
update_data_mp(stock_codes)
update_trade(stock_codes)
end_time = time.time()
print('程序运行时间:{}s'.format(end_time - start_time))
博客内容只用于交流学习,不构成投资建议,盈亏自负!
个人博客:http://coderx.com.cn/(优先更新)
项目最新代码:https://gitee.com/sl/quant_from_scratch
欢迎大家转发、留言。有微信群用于学习交流,感兴趣的读者请扫码加微信!
如果认为博客对您有帮助,可以扫码进行捐赠,感谢!
| 微信二维码 | 微信捐赠二维码 |
|---|---|
 |  |