目录
初识IO
什么是IO流
I/O 实际上是input和output,也就是输入和输出。而流其实是一种抽象的概念,它表示的是数据的无结构化传递。
IO流的作用
就是输入流(读数据),O就是输出流(写数据)。当我们需要从硬盘,内存或者网络中读写数据时,数据的传输量可能很大,而我们的内存和带宽有限,无法一次性获取大数据量时,就可以通过IO流来解决问题。而流,就像河流中的水一样,缓缓地流入大海。
IO流的分类
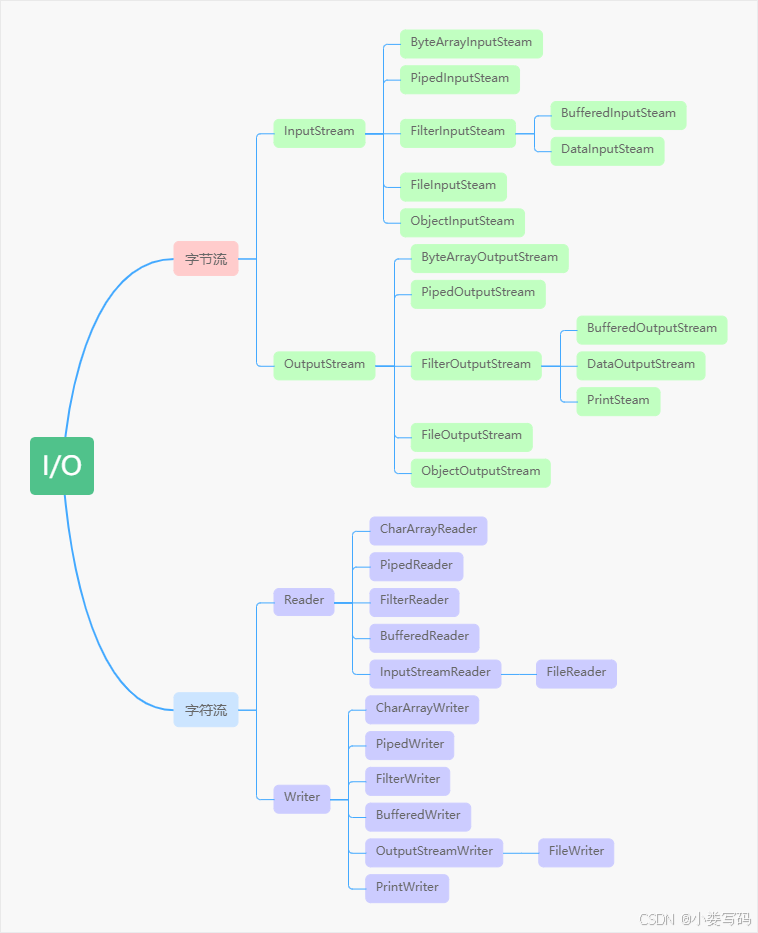
-
从传输数据类型分为:字节流和字符流
-
从传输方向分为:输入流和输出流
-
从IO操作对象划分:
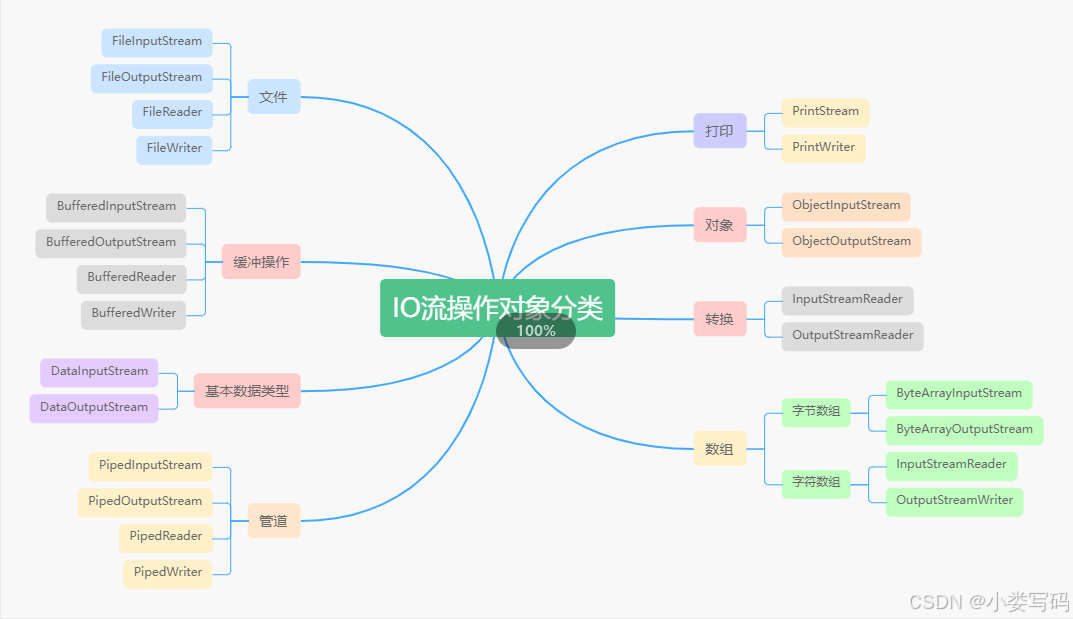
IO流实战应用
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class FileInputStreamDemo {
public static void main(String[] args) {
try {
FileInputStream is = new FileInputStream("E:/test.txt");
int i = 0;
i = is.read();
System.out.println((char)i);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果:Jimport java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class FileInputStreamDemo {
public static void main(String[] args) {
try {
FileInputStream is = new FileInputStream("E:/test.txt");
int len = 0;
byte bur[] = new byte[1024];
while((len = is.read(bur)) != -1) {
System.out.println(new String(bur, 0, len));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果:
Java IO 流
Hello World!深入分析Java中的IO流
IO流的数据来源
-
硬盘
import java.io.FileInputStream;
public class FileInputStreamDemo {
public static void main(String[] args) throws Exception {
FileInputStream is = new FileInputStream("E:/test.txt");
int len = 0;
byte bur[] = new byte[1024];
while((len = is.read(bur)) != -1) {
System.out.println(new String(bur, 0, len));
}
}
}-
内存
import java.io.FileInputStream;
public class FileInputStreamDemo {
public static void main(String[] args) throws IOException {
String str = "Java IO 流";
ByteArrayInputStream is = new ByteArrayInputStream(str.getBytes());
int len = 0;
byte bur[] = new byte[1024];
while((len = is.read(bur)) != -1) {
System.out.println(new String(bur, 0, len));
}
}
}-
键盘
import java.io.FileInputStream;
public class FileInputStreamDemo
public static void main(String[] args) throws IOException {
InputStream is = System.in;
int len = 0;
byte bur[] = new byte[1024];
while((len = is.read(bur)) != -1) {
System.out.println(new String(bur, 0, len));
}
}
}-
网络
服务器端
import java.io.*;
import java.net.*;
public class Server {
public static void main(String[] args) {
try {
ServerSocket ss = new ServerSocket(8888);
System.out.println("[启动服务器......]");
Socket s = ss.accept();
System.out.println("[客服端:]" + s.getInetAddress().getHostAddress() + " 已连接到服务器");
BufferedReader br = new BufferedReader(new InputStreamReader(s.getInputStream()));
// 读取客户端发送来的消息
String msg = br.readLine();
System.out.println("[客户端:]" + msg);
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(s.getOutputStream()));
bw.write(msg + "\n");
bw.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
}客服端
import java.io.*;
import java.net.Socket;
public class Client {
public static void main(String[] args) {
try {
Socket s = new Socket("127.0.0.1", 8888);
// 构建IO
InputStream is = s.getInputStream();
OutputStream os = s.getOutputStream();
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(os));
// 向服务器端发送一条消息
bw.write("测试客户端和服务器端通信,服务器收到消息返回到客户端\n");
bw.flush();
// 读取服务器返回的消息
BufferedReader br = new BufferedReader(new InputStreamReader(is));
String msg = br.readLine();
System.out.println("[服务器:]" + msg);
} catch (IOException e) {
e.printStackTrace();
}
}
}服务器端执行结果:
[启动服务器......]
[客服端:]127.0.0.1 已连接到服务器
[客户端:]测试客户端和服务器端通信,服务器收到消息返回到客户端
客服端执行结果:
[服务器:]测试客户端和服务器端通信,服务器收到消息返回到客户端
本地磁盘文件操作之File类
File类是Java中为文件进行创建、删除、重命名、移动等操作而设计的一个类。它是属于Java.io包下的类。
File类基本操作
// 通过给定的父抽象路径名和子路径名字符串创建一个新的File实例。
File(File parent, String child);
// 通过将给定路径名字符串转换成抽象路径名来创建一个新 File 实例。
File(String pathname);
// 根据 parent 路径名字符串和 child 路径名字符串创建一个新 File 实例。
File(String parent, String child);
// 通过将给定的 file: URI 转换成一个抽象路径名来创建一个新的 File 实例。
File(URI uri);遍历目录
import java.io.File;
public class FileUtil {
public static void main(String[] args) {
showDir(1, new File("D:\\Java"));
}
static void showDir(int indent, File file) {
for (int i = 0; i < indent; i++) {
System.out.print('-');
}
System.out.println(file.getName());
if(file.isDirectory()) {
File[] files = file.listFiles();
for (int i = 0; i < files.length; i++) {
showDir(indent + 4, files[i]);
}
}
}
}文件的字节输入输出流
import java.io.*;
public class InputStreamDemo {
public static void main(String[] args) throws Exception {
File file = new File("E:\\gupao_logo.png");
FileInputStream fileInputStream = new FileInputStream(file);
FileOutputStream fileOutputStream = new FileOutputStream("E:\\gupao_logo_cp.png");
int len = 0;
byte[] buffer = new byte[1024];
while((len=fileInputStream.read(buffer)) != -1 ) {
fileOutputStream.write(buffer, 0, len);
}
fileInputStream.close();
fileOutputStream.close();
}
}基于内存的字节输入输出流
import java.io.*;
public class MemoryDemo {
static String str = "hello world!";
public static void main(String[] args) {
// 从内存中读取数据
ByteArrayInputStream inputStream = new ByteArrayInputStream(str.getBytes());
// 写入到内存中
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
int len = 0;
while((len = inputStream.read()) != -1) {
char c = (char)len;
outputStream.write(Character.toUpperCase(c));
}
System.out.println(outputStream.toString());
}
}基于缓存流的输入输出
import java.io.*;
public class BufferedDemo {
public static void main(String[] args) {
try {
BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("E:\\test.txt"));
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream("E:\\tst.txt"));
int len = 0;
byte[] bytes = new byte[1024];
while((len = bufferedInputStream.read(bytes)) != -1) {
System.out.println(new String(bytes, 0, len));
bufferedOutputStream.write(bytes, 0, len);
bufferedOutputStream.flush();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}flush方法
flush()这个东西,其实在很久以前的网络传输中就有了,那个时候为了效率,服务器和客户端传输数据的时候不会每产生一段数据就传一段数据,而是会建一个缓冲区,在缓冲区满之后再往客户端传输数据。有时候会有这样的问题,当数据不足以填充缓冲区,而又需要往客户端传数据,为了解决这个问题,就有了 flush的概念,将缓冲区的数据强迫发送。
如果把 flush换成 close是否可行呢?
答案是可以的。
public class BufferedOutputStream extends FilterOutputStream {
......
}
BufferedOutputStream没有实现 close()方法,所以会直接调用 FilterOutputStream的 close(),而 FilterOutputStream的 close()方法会调用 flush()来输出缓冲区数据。
实际开发中关于IO操作的,都强调最后要调用 close()方法。
序列化和反序列化
序列化与反序列化的概念
-
Java 序列化是指:将对象转化成一个字节序列(二进制数据)的过程。
-
将序列化对象写入文件之后,可以从文件中读取出来,并且对它进行反序列化。
-
Java 反序列化是指:将一个对象的字节序列恢复成 Java 对象的过程。
-
一个平台中序列化的对象,可以在另一个平台中进行反序列化,因为这个过程是在 JVM 中独立完成的,可以依赖于 Java 的可移植性。
核心类与关键字
-
ObjectOutputStream:IO 类,包含序列化对象的方法,writeObject()
-
ObjectInputStream:IO 类,包含反序列化对象的方法,readObject()
-
上面两个 IO 流类是高层次的数据库,需要借助文件流进行序列化与反序列化操作。
-
Serializable ,接口,是一个标志性接口,标识可以在 JVM 中进行序列化,JVM 会为该类自动生成一个序列化版本号。参与序列化与反序列化的类必须实现 Serializable 接口。
-
serialVersionUID,类属性,序列化版本号,用于给 JVM 区别同名类,没有提供版本号,JVM会默认提供序列化版本号。
-
transient,关键字,当序列化时,不希望某些属性参与,则可以使用这个关键字标注该属性。
序列化与反序列化的过程
-
内存中的数据信息被拆分成一小块一小块的部分,为每个小块设置编号,然后存放到硬盘文件中,也就是将 Java 对象的状态保存下来存储到文件中的过程就叫做序列化。
-
将硬盘中保存了 Java 对象状态的字节序列按照编号组装成对象恢复到内存中,这个过程称为反序列化。
应用示例
参与序列化和反序列化的 Java 类
public class Student implements Serializable {
private String name;
private int age;
// 以下省略有参构造、无参构造、set、get、toString
}参与序列化和反序列化的类必须实现 Serializable 接口。
序列化操作
public static void main(String[] args) throws Exception {
// 创建 Java 对象
Student student = new Student("张三",22);
// 对象输出流
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("student"));
// 使用 writeObject 序列化对象
oos.writeObject(student);
// 刷新
oos.flush();
// 关闭流
oos.close();
}序列化后的二进制文件会被保存到文件输出流指定的路径。
反序列化操作
public static void main(String[] args) throws Exception {
// 对象输入流
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("student"));
// 使用 readObject() 反序列化
Object obj = ois.readObject();
// 使用对象
System.out.println(obj);
// 关闭流
ois.close();
}序列化版本号的作用 serialVersionUID
-
JVM 首先会通过类名来区分 Java 类,类名不同,则不是同一个类。当类名相同时,JVM 就会通过序列化版本号来区分 Java 类,如果序列化版本号相同就为同一个类,序列化版本号不同就为不同的类。
-
在序列化一个对象时,如果没有指定序列化版本号,后期对该类的源码进行修改并重新编译后,会导致修改前后的序列化版本号不一致,因为 JVM 会提供一个新的序列化版本号给该类对象。
-
此时再用以往的反序列化代码去反序列化该类的对象,就会抛出异常 java.io.InvalidClassException ,所以序列化一个类时最好指定一个序列化版本号,或者永远不修改此类。
public class Student implements Serializable {
private static final Long serialVersionUID = 1L;
}-
由 JVM 提供序列化版本号的好处是,同名却不同功能的类,会有两个不同的序列化版本号,JVM 可以通过序列化版本号加以区分,缺点是一旦修改源码,会重新提供序列化版本号,导致修改前后的序列化版本号不一致,进行反序列化时会出现运行出现异常。
-
由 开发人员 手动提供序列化版本号的好处是,当修改了被序列化类的源码后,以往写的反序列化代码依然可以使用,如 JDK 中的 String 类。以便后期进行增强和维护不会影响使用。
transient 关键字
-
这个关键字表示游离的,不参与序列化的。
-
在序列化一个对象时,如果不希望某个属性参加序列化,可以使用
transient修饰该属性。 -
被该关键字修饰的属性不会参与到序列化中。
public class Student implements Serializable {
private static final Long serialVersionUID = 1L;
private String name;
private transient int age;
}如上类,在序列化时就不会保存 age 属性,在反序列化时就不能会付出该属性,默认恢复成 null 或 0 ,由属性类型决定。
序列化的好处及应用场景
-
序列化会将内存中对象的状态转换成二进制文件保存到磁盘当中,当再次使用时会从磁盘中读取该二进制文件,将 Java 对象的状态恢复到内存中。
-
当你想把内存中的对象保存到磁盘文件或数据库中时可以使用序列化。
-
当你想在网络传输中传送 Java 对象时,可以使用序列化。
-
当你想通过 RMI 传输对象时,可以使用序列化。
序列化注意事项
-
序列化只会保存对象的属性状态,不会保存对象中的方法。
-
父类实现了 Serializable 接口,则其子类也自动实例化了该接口,也就是说子类不用显式实现 Serializable 接口也能参与序列化和反序列化。
-
一个对象 A 的实例变量引用了其他对象 B,在 A 对象实例化的过程中 ,也会序列化 B ,前提是 A、B 两个类都实现了 Serializable 接口。
-
当一个类实现 Serializable 接口时,最好手动指定一个序列化版本号(serialVersionUID),避免修改源代码后导致反序列化出现异常。
-
当一个类对象会被多次重复使用,且一般不会对其属性做修改,就可以对其进行序列化。例如数据库操作中的实体类。
Java IO流原理
-
I/O是Input和Output的缩写,I/O技术是非常实用的技术,用于处理数据传输。如:读写文件,网络通讯等。
-
Java程序中,对于数据的输入/输出操作以流(Stream)的方式进行。
-
java.io包下提供了各种”流“类和接口,用以获取不同种类的数据,并通过方法输入或输出数据。
-
输入Input:读取外部数据(磁盘、光盘等存储设备的数据)到程序(内存)中。
-
输出Output:将程序(内存)数据输出到磁盘、光盘等存储设备中。