本专栏主要是介绍QMT的基础用法,常见函数,写策略的方法,也会分享一些量化交易的思路,大概会写100篇左右。
QMT的相关资料较少,在使用过程中不断的摸索,遇到了一些问题,记录下来和大家一起沟通,共同进步,自己淋过雨了,希望大家都有一把伞。
文章目录
相关阅读
小白也能做量化:零门槛QMT、Ptrade免费送
量化交易入门:如何在QMT中配置Python环境,安装第三方依赖包
量化交易策略:多因子选股结合布林带择时
有群友分享了一个轮动etf策略,周末将策略复刻到了QMT平台下,设置的参数和原来可能不一样,近一年年化收益仍然达到了47%,10年的平均年化收益率也有13%。本文将分享基于年化收益和判定系数打分的动量因子核心资产ETF轮动的Python代码。
一、导入必要的库
import pandas as pd
import numpy as np
import talib
import math
import log_util
log = log_util.get_logger()
- pandas:是一个强大的数据分析和操作库,提供了丰富的数据结构和数据处理功能,方便对金融数据进行读取、清洗、分析和处理。
- numpy:主要用于高效的数值计算,特别是在处理大规模数组和矩阵运算时具有很高的性能优势。
- talib:是一个技术分析库,包含了许多常见的技术指标计算函数,可用于对金融数据进行技术分析。
- math:提供了各种数学函数,用于进行数学计算。
- log_util:这是一个自定义的日志记录工具,用于记录程序运行过程中的信息,方便调试和监控程序的执行状态。
二、定义全局变量和参数
m_days = 25 #动量参考天数
period=200
target_num = 1
m_days被设置为25,表示动量参考的天数为25天;period被设置为200,用于指定获取市场数据的周期长度。
三、初始化交易配置
def init(C):
C.trade_code_list= [
'518880.SH', #黄金ETF(大宗商品)
'513100.SH', #纳指100(海外资产)
'159915.SZ', #创业板100(成长股,科技股,中小盘)
'510180.SH', #上证180(价值股,蓝筹股,中大盘)
]
C.set_universe(C.trade_code_list)
C.accID = 'xx'
C.buy = True
C.sell = False
C.acct_type = 'STOCK'
init函数用于初始化交易相关的配置信息。C.trade_code_list是一个包含多个ETF代码的列表,这些ETF分别代表了不同的资产类别,如黄金ETF(大宗商品)、纳指100(海外资产)、创业板100(成长股、科技股、中小盘)和上证180(价值股、蓝筹股、中大盘)。通过调用C.set_universe方法,将这些ETF设置为交易池(即可供选择的交易标的范围)。C.accID设置了账户ID,用于标识具体的交易账户。C.buy和C.sell分别表示买入和卖出的初始状态,这里都设置为True和False。C.acct_type设置为STOCK,表示账户类型为股票账户。
四、计算ETF打分并排序
def get_rank(etf_pool, C):
mkdict = C.get_market_data_ex(fields = ['high','low','close'],stock_code = C.trade_code_list,end_time = C.bar_date,count=int(period)+1)
print(f'行情数据:{mkdict}')
score_list = []
for etf in etf_pool:
df = mkdict[etf]
y = df['log'] = np.log(df.close)
x = df['num'] = np.arange(df.log.size)
slope, intercept = np.polyfit(x, y, 1)
annualized_returns = math.pow(math.exp(slope), 250) - 1
r_squared = 1 - (sum((y - (slope * x + intercept))**2) / ((len(y) - 1) * np.var(y, ddof=1)))
score = annualized_returns * r_squared
score_list.append(score)
df = pd.DataFrame(index=etf_pool, data={'score':score_list})
df = df.sort_values(by='score', ascending=False)
rank_list = list(df.index)
print(f'打分{df}')
return rank_list
(一)获取市场数据
mkdict = C.get_market_data_ex(fields = ['high','low','close'],stock_code = C.trade_code_list,end_time = C.bar_date,count=int(period)+1)
通过调用C.get_market_data_ex方法,获取指定ETF池中每个ETF的高、低和收盘价数据,存储在mkdict字典中,其中键为ETF代码,值为包含相应价格数据的DataFrame对象。
(二)计算打分
-
线性回归拟合
for etf in etf_pool: df = mkdict[etf] y = df['log'] = np.log(df.close) x = df['num'] = np.arange(df.log.size) slope, intercept = np.polyfit(x, y, 1)对于每个ETF,首先将其收盘价取对数得到
y,然后创建一个与数据长度相同的等差数列作为自变量x。接着使用np.polyfit函数进行一元线性回归拟合,得到斜率slope和截距intercept。 -
计算年化收益率
annualized_returns = math.pow(math.exp(slope), 250) - 1根据线性回归得到的斜率
slope,通过公式math.pow(math.exp(slope), 250) - 1计算该ETF的年化收益率。这里的250表示一年按照250个交易日计算。 -
计算判定系数
r_squared = 1 - (sum((y - (slope * x + intercept))**2) / ((len(y) - 1) * np.var(y, ddof=1)))判定系数
r_squared用于衡量线性回归模型对数据的拟合程度。它的计算公式为1 - (残差平方和 / 总离差平方和),其中残差平方和表示观测值与拟合值之间的差异的平方和,总离差平方和表示观测值与均值之间的差异的平方和。通过计算判定系数,可以评估模型对数据的解释能力。 -
计算打分
score = annualized_returns * r_squared score_list.append(score)将年化收益率和判定系数相乘得到该ETF的打分,并将所有ETF的打分存储在
score_list列表中。
(三)排序并返回结果
df = pd.DataFrame(index=etf_pool, data={'score':score_list})
df = df.sort_values(by='score', ascending=False)
rank_list = list(df.index)
print(f'打分{df}')
return rank_list
将打分结果转换为一个以ETF代码为索引、打分为数据的DataFrame对象df,然后按照打分从高到低进行排序。最后将排序后的ETF代码列表rank_list返回,表示按照打分高低排列的ETF顺序。
五、交易操作逻辑
def handle_bar(C):
bar_date = timetag_to_datetime(C.get_bar_timetag(C.barpos), '%Y%m%d%H%M%S')
C.bar_date = bar_date
target_list = get_rank(C.trade_code_list, C)[:target_num]
# 卖出
#持仓
position = get_trade_detail_data(C.accID, C.acct_type, 'position')
holdings = {i.m_strInstrumentID + '.' + i.m_strExchangeID : i.m_nVolume for i in position}
log.info(f'[{bar_date}] - 查询当前持仓:{holdings}')
hold_list = {i.m_strInstrumentID + '.' + i.m_strExchangeID for i in position}
for etf in hold_list:
if etf not in target_list:
passorder(24, 1101, C.accID, etf, 5, -1,holdings[etf],C)
print('卖出' + str(etf))
else:
print('继续持有' + str(etf))
# 买入
if len(hold_list) < target_num:
# 获取可用资金
account = get_trade_detail_data(C.accID, C.acct_type, 'account')[0]
log.info(f'可用资金{account}')
per_cash = account.m_dAvailable / (target_num - len(hold_list))
for etf in target_list:
if not holdings or (etf in holdings and holdings[etf] == 0):
passorder(23, 1102, C.accID, etf, 5, -1,per_cash,C)
print('买入' + str(etf))
(一)获取当前k线日期和时间
C.bar_date = timetag_to_datetime(C.get_bar_timetag(C.barpos), '%Y%m%d%H%M%S')
print('当前k线日期:', C.bar_date)
通过调用方法获取当前k线的时间戳,并将其转换为日期格式存储在C.bar_date中。然后打印当前k线的日期。
(二)获取动量最高的ETF并打印排名
target_num = 1
etf_pool = get_rank(C.trade_code_list, C)
print(f'排名:{etf_pool[:target_num]}')
调用前面定义的get_rank函数获取ETF打分并排序后的结果etf_pool,然后打印排名前target_num(这里为1)的ETF代码。
(三)卖出操作逻辑
-
查询持仓
position = get_trade_detail_data('position', C.accID, C.acct_type) hold_list = {i['volume']: i['instrument'] for i in position} print(f'持有{hold_list}')使用
get_trade_detail_data函数查询当前账户的持仓情况,将结果存储在position中。然后通过字典推导式将持仓数据转换为以持有数量为键、ETF代码为值的字典hold_list,并打印持有的ETF信息。 -
判断是否卖出
for etf in hold_list: if etf not in target_list: passorder(24, 1101, C.accID, etf, 5, -1,holdings[etf],C) print('卖出' + str(etf)) else: print('继续持有' + str(etf))如果目标ETF在持仓中,则打印“继续持有”的信息;否则,执行卖出操作。最后通过调用
passorder函数下达卖出订单。这里的passorder函数是一个模拟的下单函数,实际开发中需要替换为真实的交易接口函数。
(四)买入操作逻辑
-
判断是否需要买入
if len(hold_list) < target_num: # 获取可用资金 account = get_trade_detail_data(C.accID, C.acct_type, 'account')[0] log.info(f'可用资金{account}') per_cash = account.m_dAvailable / (target_num - len(hold_list)) for etf in target_list: if not holdings or (etf in holdings and holdings[etf] == 0): passorder(23, 1102, C.accID, etf, 5, -1,per_cash,C) print('买入' + str(etf))如果持有数量小于目标数量,则执行买入操作。首先获取账户的可用资金并打印,然后计算每个目标ETF的买入金额
cash(将可用资金平均分配到每个目标ETF上),最后通过调用passorder函数下达买入订单。六、回测结果
回测最近一年,年化收益达到了47%,主要是因为纳指和黄金的表现较好,具体结果如下:
回测10年结果如下穿越了15年和21年的大跌,平均年化收益率有13%:
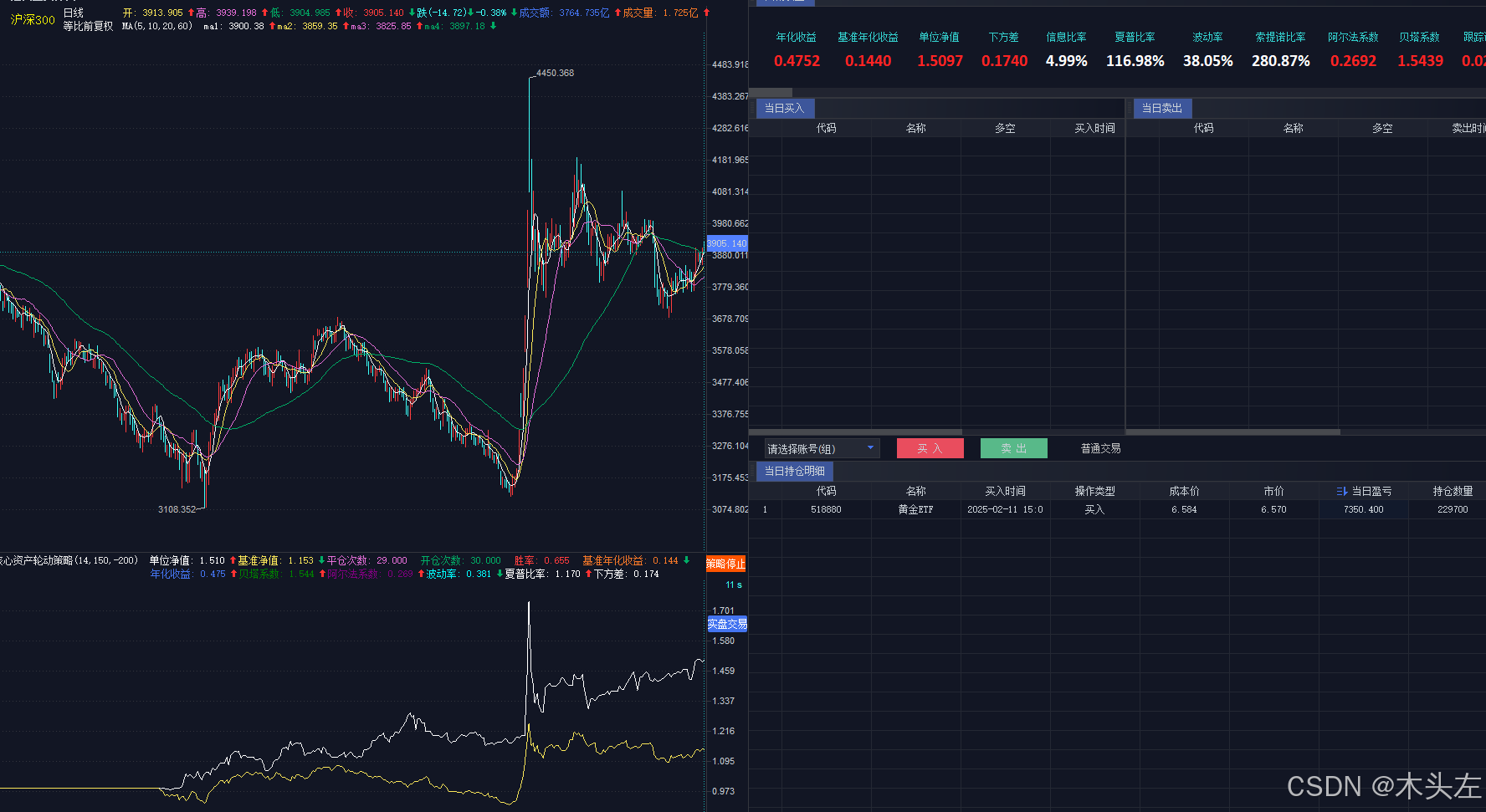
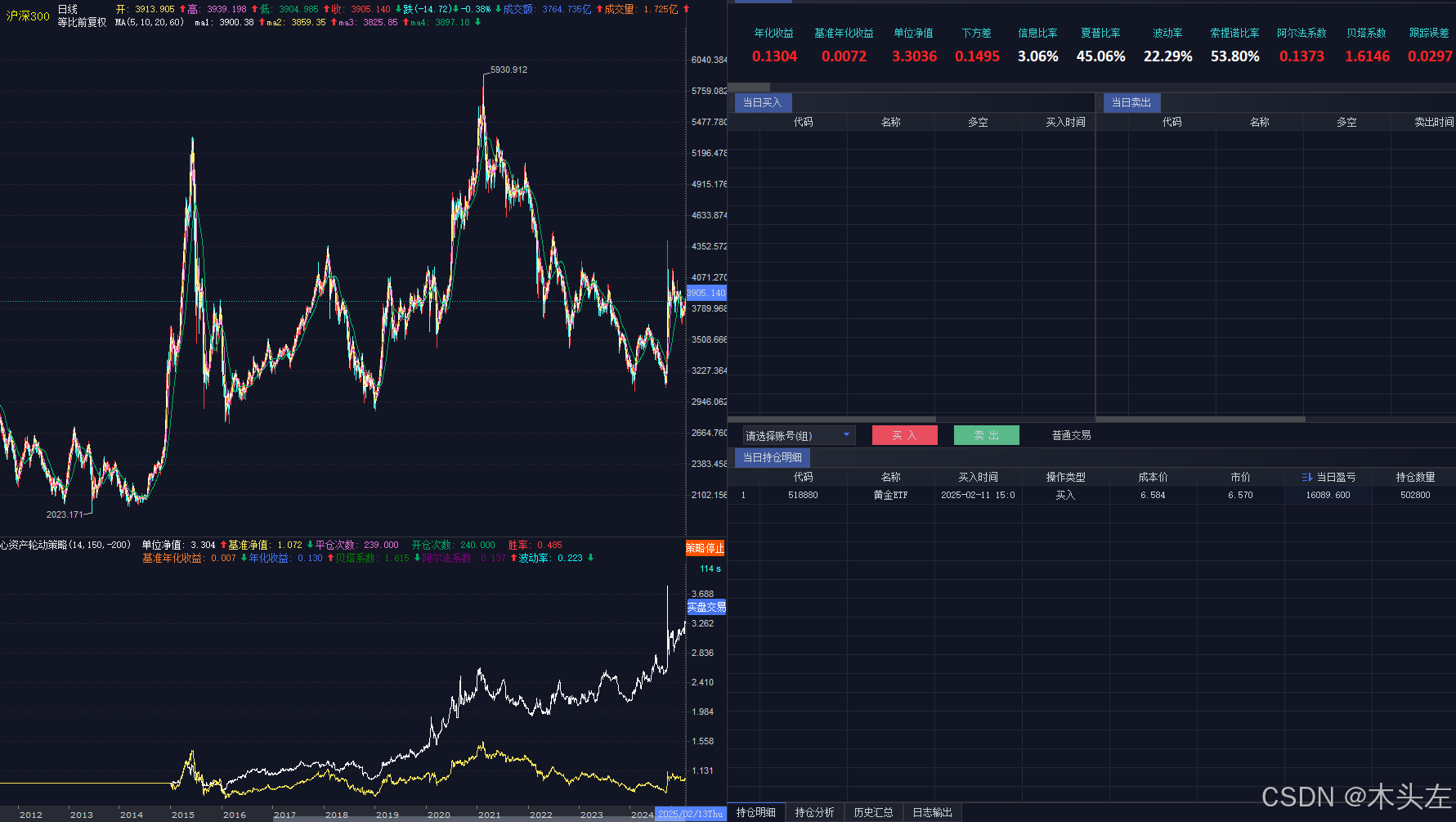
这个策略最出彩的地方除了打分算法设计得好,更好的是标的选的好,几个ETF之间的相关性比较低,自己建ETF池也要考虑这个。从降低风险和回撤的角度,可以考虑扩大标的池。