一、配置环境
北京超算平台
参加openmmlab课程的同学可以通过给出的申请二维码扫描,完善信息问卷后等待几个工作日邮箱会发送回复,还可以自己搜索“北京超级云计算中心”微信公众号,关注后回复“2”即可获取申请试算通道
1.客户端安装
收到邮件回复后,邮件中会注明是哪个区的服务器

然后按照邮件要求,点击北京超算链接,下载客户端并登陆,如果不知道密码是啥也是可以在邮件中看到有重置密码的链接


2.创建环境
北京超算是用module来管理应用软件的,module的常用命令有
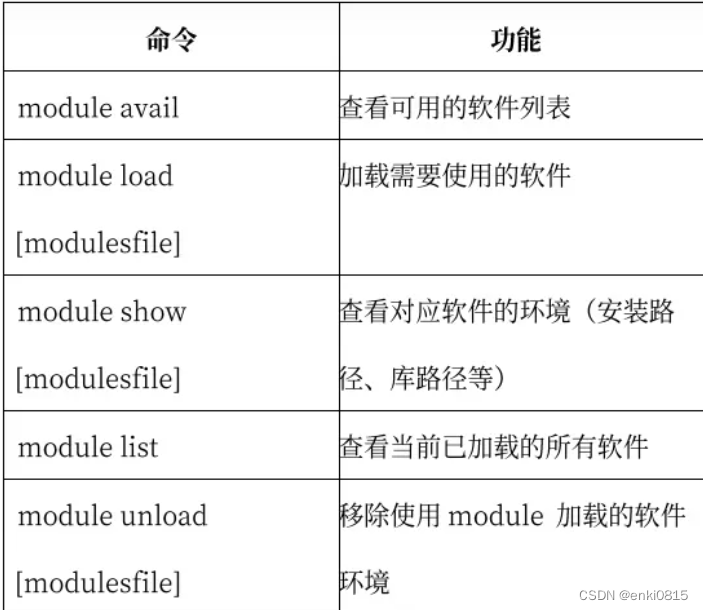
可以用 module avail 命令看平台支持的框架和工具:
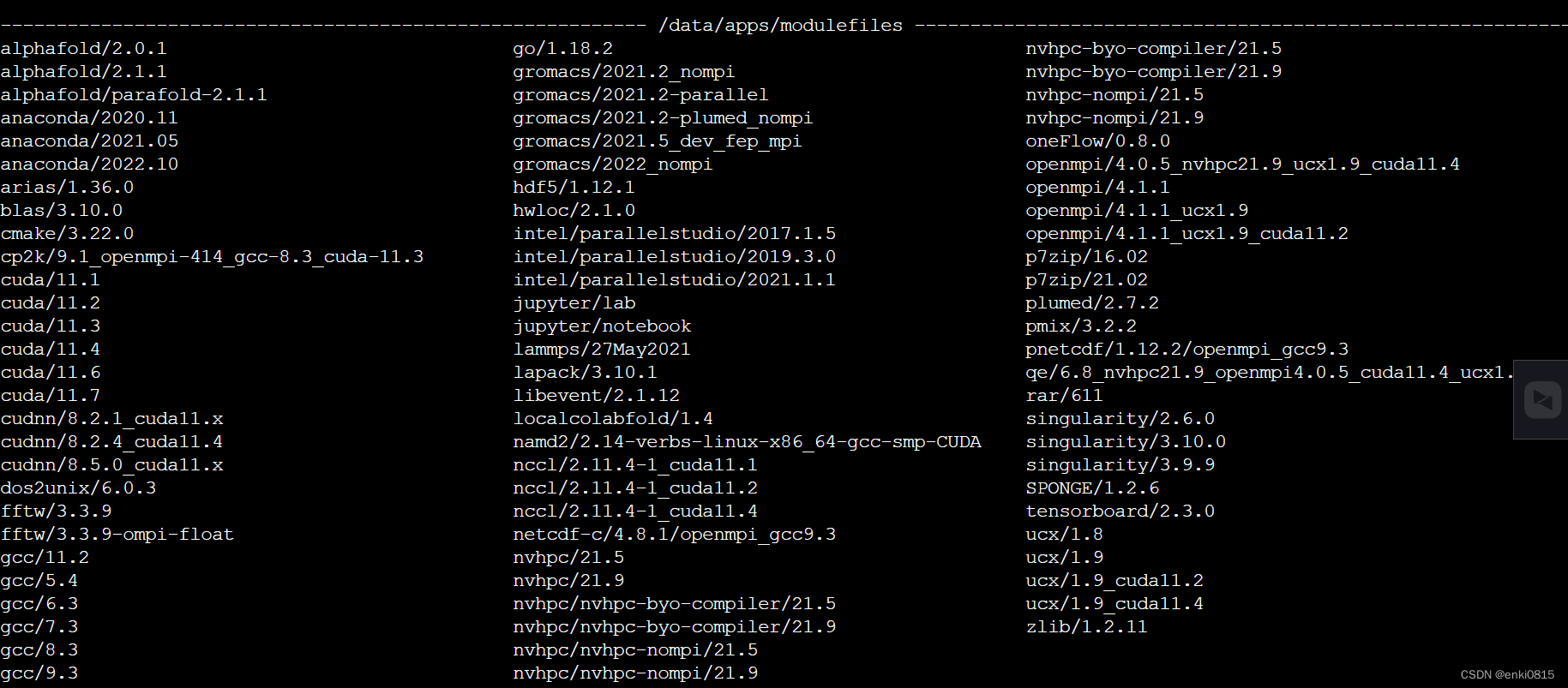
我们使用cuda 11.6和anaconda 2021.05这2个作为基础。
在anaconda环境中新建名为 openmmlab ,Python3.8 版本的环境。
(1)加载cuda
module load cuda/11.6(2)加载anaconda
module load anaconda/2021.05(3)创建环境
conda create --name openmmlab python=3.8
(4)激活新建的openmmlab环境
source activate openmmlab(5)安装pytorch:
打开pytorch链接:https://pytorch.org/get-started/locally/#start-locally
选择对应选项,底下会出来命令:

输入命令:
conda install pytorch torchvision torchaudio pytorch-cuda=11.6 -c pytorch -c nvidia等待安装完成后,可以通过如下命令查看当前torch版本
python -c 'import torch;print(torch.__version__)'1.13.1查看pytorch版本:
import torch
print(torch.__version__) # 查看torch当前版本号
print(torch.version.cuda) # 编译当前版本的torch使用的cuda版本号
print(torch.cuda.is_available()) # 查看当前cuda是否可用于当前版本的Torch,如果输出True,则表示可用注意:最好是把CUDA_HOME也设置好
CUDA_HOME='/data/apps/cuda/11.6'3.利用SSH配置本地Vscode
1、在超算平台点击控制台

2、点击右边的SSH直连管理
3、点击“创建密码/公钥”
4、根据“如何查看/添加公钥”创建公钥,并复制到下面的公钥区

5、粘贴自己的公钥:

6、打开VSCode,左下角Open a Remote Window
选择Connect to Host->选择Add New SSH Host->粘贴->选择本地的配置文件->选择Linux然后点Continue,连接成功。
二、MMClassification初探
1 加载gcc/9.3
module load gcc/9.32 克隆mmclassification
git clone https://github.com/open-mmlab/mmclassification.git3 编译安装
cd mmclassification
mim install mmcv-full4 下载数据集
flower 数据集包含 5 种类别的花卉图像:雏菊 daisy 588张,蒲公英 dandelion 556张,玫瑰 rose 583张,向⽇ 葵 sunflower 536张,郁⾦⾹ tulip 585张。 数据集下载链接:
国际⽹:https://www.dropbox.com/s/snom6v4zfky0flx/flower_dataset.zip?dl=0
国内⽹:https://pan.baidu.com/s/1RJmAoxCD_aNPyTRX6w97xQ 提取码: 9x5u5 划分数据集
将数据集按照 8:2 的⽐例划分成训练和验证⼦数据集,并将数据集整理成 ImageNet的格式 。将训练⼦集和验证⼦集放到 train 和 val ⽂件夹下。
文件结构如下:
```
flower_dataset
|--- classes.txt
|--- train.txt
|--- val.txt
| |--- train
| | |--- daisy
| | | |--- NAME1.jpg
| | | |--- NAME2.jpg
| | | |--- ...
| | |--- dandelion
| | | |--- NAME1.jpg
| | | |--- NAME2.jpg
| | | |--- ...
| | |--- rose
| | | |--- NAME1.jpg
| | | |--- NAME2.jpg
| | | |--- ...
| | |--- sunflower
| | | |--- NAME1.jpg
| | | |--- NAME2.jpg
| | | |--- ...
| | |--- tulip
| | | |--- NAME1.jpg
| | | |--- NAME2.jpg
| | | |--- ...
| |--- val
| | |--- daisy
| | | |--- NAME1.jpg
| | | |--- NAME2.jpg
| | | |--- ...
| | |--- dandelion
| | | |--- NAME1.jpg
| | | |--- NAME2.jpg
| | | |--- ...
| | |--- rose
| | | |--- NAME1.jpg
| | | |--- NAME2.jpg
| | | |--- ...
| | |--- sunflower
| | | |--- NAME1.jpg
| | | |--- NAME2.jpg
| | | |--- ...
| | |--- tulip
| | | |--- NAME1.jpg
| | | |--- NAME2.jpg
| | | |--- ...
```
6 创建并编辑标注⽂件将所有类别的名称写到 classes.txt 中,每⾏代表⼀个类别。
dandelion
daisy
sunflower
rose
tulip7 ⽣成训练(可选)和验证⼦集标注列表 train.txt 和 val.txt ,每⾏应包含⼀个⽂件名和其对应的标签。如下,可将处 理好的数据集迁移到 mmclassification/data ⽂件夹下。
```
...
daisy/NAME**.jpg 0
daisy/NAME**.jpg 0
...
dandelion/NAME**.jpg 1
dandelion/NAME**.jpg 1
...
rose/NAME**.jpg 2
rose/NAME**.jpg 2
...
sunflower/NAME**.jpg 3
sunflower/NAME**.jpg 3
...
tulip/NAME**.jpg 4
tulip/NAME**.jpg 4
```注:把数据集下载到mmclassification/data目录下,同时新建data_split.py文件。
数据集划分代码 data_split.py 如下,执⾏:
import os
import sys
import shutil
import numpy as np
def load_data(data_path):
count=0
data={}
for dir_name in os.listdir(data_path):
dir_path = os.path.join(data_path,dir_name)
if not os.path.isdir(dir_path):
continue
data[dir_name]=[]
for file_name in os.listdir(dir_path):
file_path = os.path.join(dir_path,file_name)
if not os.path.isfile(file_path):
continue
data[dir_name].append(file_path)
count+=len(data[dir_name])
print("{} :{}".format(dir_name,len(data[dir_name])))
print("total of image : {}".format(count))
return data
def copy_dataset(src_img_list, data_index, target_path):
target_img_list = []
for index in data_index:
src_img = src_img_list[index]
img_name = os.path.split(src_img)[-1]
shutil.copy(src_img, target_path)
target_img_list.append(os.path.join(target_path, img_name))
return target_img_list
def write_file(data, file_name):
if isinstance(data, dict):
write_data = []
for lab, img_list in data.items():
for img in img_list:
write_data.append("{} {}".format(img, lab))
else:
write_data = data
with open(file_name, "w") as f:
for line in write_data:
f.write(line + "\n")
print("{} write over!".format(file_name))
def split_data(src_data_path, target_data_path, train_rate=0.8):
src_data_dict = load_data(src_data_path)
classes = []
train_dataset, val_dataset = {}, {}
train_count, val_count = 0, 0
for i, (cls_name, img_list) in enumerate(src_data_dict.items()):
img_data_size = len(img_list)
random_index = np.random.choice(img_data_size, img_data_size,replace=False)
train_data_size = int(img_data_size * train_rate)
train_data_index = random_index[:train_data_size]
val_data_index = random_index[train_data_size:]
train_data_path = os.path.join(target_data_path, "train", cls_name)
val_data_path = os.path.join(target_data_path, "val", cls_name)
os.makedirs(train_data_path, exist_ok=True)
os.makedirs(val_data_path, exist_ok=True)
classes.append(cls_name)
train_dataset[i] = copy_dataset(img_list, train_data_index,train_data_path)
val_dataset[i] = copy_dataset(img_list, val_data_index, val_data_path)
print("target {} train:{}, val:{}".format(cls_name,len(train_dataset[i]), len(val_dataset[i])))
train_count += len(train_dataset[i])
val_count += len(val_dataset[i])
print("train size:{}, val size:{}, total:{}".format(train_count, val_count,train_count + val_count))
write_file(classes, os.path.join(target_data_path, "classes.txt"))
write_file(train_dataset, os.path.join(target_data_path, "train.txt"))
write_file(val_dataset, os.path.join(target_data_path, "val.txt"))
def main():
src_data_path = sys.argv[1]
target_data_path = sys.argv[2]
split_data(src_data_path, target_data_path, train_rate=0.8)
if __name__ == '__main__':
main()8 在configs目录下新建自己的。比如resnet18文件夹,新建 resnet18_b32_flower.py ,内容如下
_base_ = ['../_base_/models/resnet18.py', '../_base_/datasets/imagenet_bs32.py','../_base_/default_runtime.py']
model = dict(
head=dict(
num_classes=5,
topk=(1,)
))
data =dict(
samples_per_gpu=32,
workers_per_gpu=2,
train = dict (
data_prefix= 'data/flower/train',
ann_file='data/flower/train.txt',
classes='data/flower/classes.txt'
),
val=dict(
data_prefix= 'data/flower/val',
ann_file='data/flower/val.txt',
classes='data/flower/classes.txt'
)
)
optimizer = dict(type='SGD', lr=0.001, momentum=0.9,weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
lr_config = dict(
policy='step',
step=[1]
)
runner = dict (type = 'EpochBasedRunner', max_epochs=100)
load_from = '/HOME/scz4239/run/mmclassification/configs/resnet18/checkpoints/resnet18_batch256_imagenet_20200708-34ab8f90.pth'9 下载预训练模型:
模型库:
https://mmclassification.readthedocs.io/zh_CN/latest/modelzoo_statistics.html
在自己新建的resnet18目录下,新建checkpoints文件夹,同时找到对应的模型下载:

mkdir checkpoints
wget
https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_batch256_imag
enet_20200708-34ab8f90.pth -P checkpoints10 在mmclassification根目录新建run.sh文件:
#!/bin/bash
module load anaconda/2021.05
module load cuda/11.6
module load gcc/9.3
source activate openmmlab
export PYTHONUNBUFFERED=1
python tools/train.py \
configs/resnet18/resnet18_b32_flower.py \
--work-dir work/resnet18_b32_flower11 打开 北京超算平台终端,输入
sbatch --gpus=1 run.sh
12 结束后,在mmclassification/work目录下,会有Log日志、模型文件等。可以从log日志看到最后的acc:
2023-02-04 11:41:55,152 - mmcls - INFO - Saving checkpoint at 100 epochs
2023-02-04 11:41:56,124 - mmcls - INFO - Epoch(val) [100][18] accuracy_top-1: 95.4545, accuracy_top-5: 100.0000