一、引言
Redis Search 是 Redis 的一个模块,用于提供全文搜索和二级索引功能。它允许在 Redis 数据库中执行复杂的搜索查询,并支持多种数据类型和查询操作。以下是 Redis Search 的一些关键特性:
- 全文搜索:支持对文本字段进行全文搜索,包括分词、词干提取和高亮显示等功能。
- 多字段索引:可以对多个字段进行索引,包括文本、数值、地理位置等。
- 排序和分页:支持对搜索结果进行排序和分页,方便处理大数据量的查询结果。
- 聚合查询:支持对数据进行聚合操作,如分组、计数、求和等。
- 高性能:利用 Redis 的内存存储特性,提供高性能的搜索和索引功能。
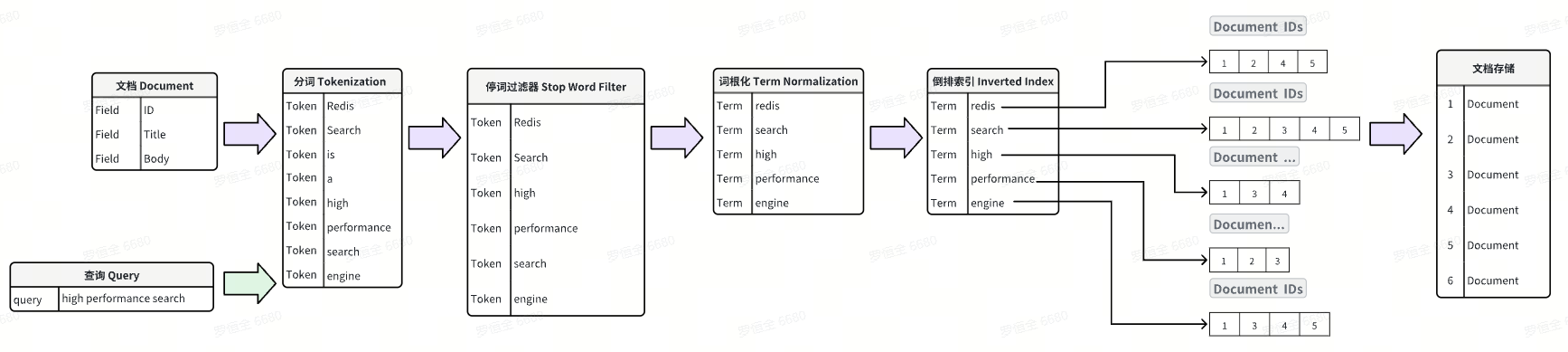
二、全文检索基本概念
在全文检索(full-text search)中,以下术语是关键概念:
-
Index:索引是一个数据结构,用于快速查找包含特定词的文档。它通常是一个倒排索引(inverted index),其中存储了每个词及其在文档中的位置。
-
Document:文档是索引中的基本单位。它可以是任何形式的文本数据,如网页、文章、电子邮件等。在索引中,每个文档都有一个唯一的标识符。
-
Field:字段是文档中的一个部分或属性。例如,一个文档可能有标题字段、正文字段、作者字段等。字段可以单独索引和搜索。
-
Token:词元是从文本中提取的最小单位,通常是单词或词组。词元化(tokenization)是将文本分割成词元的过程。
-
Term:术语是索引中的一个条目,表示一个唯一的词元。术语是词元的规范化形式,通常经过词干提取(stemming,比如复数变单数、动词过去式变回原形)和小写转换。
-
Stop Word:停用词是指在索引和搜索过程中被忽略的常见词,如 “the”、“is”、“and” 等。停用词通常对搜索结果的相关性没有显著影响,因此被过滤掉以减少索引大小和提高搜索效率。
三、创建索引
创建索引后,Redis Stack会自动索引存储在数据库中的任何现有的、修改的或新创建的JSON文档。
- 对于现有文档,索引在后台异步运行,因此文档可用可能需要一段时间。
- 修改已有的文档和新创建的文档是同步索引的,因此在添加或修改命令完成时,文档将可用。
创建索引FT.CREATE命令语法:
FT.CREATE index
[ON HASH | JSON]
[PREFIX count prefix [prefix ...]]
[FILTER {filter}]
[LANGUAGE default_lang]
[LANGUAGE_FIELD lang_attribute]
[SCORE default_score]
[SCORE_FIELD score_attribute]
[PAYLOAD_FIELD payload_attribute]
[MAXTEXTFIELDS]
[TEMPORARY seconds]
[NOOFFSETS]
[NOHL]
[NOFIELDS]
[NOFREQS]
[STOPWORDS count [stopword ...]]
[SKIPINITIALSCAN]
SCHEMA field_name [AS alias] TEXT | TAG | NUMERIC | GEO | VECTOR | GEOSHAPE [ SORTABLE [UNF]]
[NOINDEX] [ field_name [AS alias] TEXT | TAG | NUMERIC | GEO | VECTOR | GEOSHAPE [ SORTABLE [UNF]] [NOINDEX] ...]
FT.CREATE命令参数说明:
| 索引参数 | 说明 |
|---|---|
| index | 要创建的索引名称。如果该索引已存在,则返回错误回复(错误)“Index already exists”。 |
| SCHEMA | 在 SCHEMA关键字之后,声明要索引的字段: field_name [AS alias] field_name:对于HASH则哈希中的字段名称,对于 JSON则为JSON Path表达式 alias:定义field的别名,可使用此功能将复杂的 JSONPath 表达式与更易记住(且更易输入)的名称关联 |
| ON {data_type} | HASH (默认) 或JSON,即支持索引的Redis数据类型, 若值为JSON则需要安装 RedisJSON模块 |
| PREFIX {count} {prefix} | 需要被索引的key前缀,支持设置多个前缀,支持通配符*,默认*(表示全部) |
| FILTER {filter} | filter过滤表达式,如使用@__key表示新增或修改(just added/changed)的key,TODO A field can be used to set field name by passing ‘FILTER @indexName==“myindexname”’. |
| LANGUAGE {default_lang} | 文档索引的默认语言,默认值为:english, 可选值:[arabic, armenian, danish, dutch, english, finnish, french, german, hungarian, italian, norwegian, portuguese, romanian, russian, serbian, spanish, swedish, tamil, turkish, yiddish, chinese] |
| LANGUAGE_FIELD {lang_attribute} | 设置文档中的某个field表示具体的LANGUAGE |
| SCORE {default_score} | 文档的默认分值score,默认值:1.0 |
| SCORE_FIELD {score_attribute} | 设置文档中的某个field表示具体的SCORE,此field的值范围为:[0.0, 1.0],如不设置默认为1 |
| PAYLOAD_FIELD {payload_attribute} | 设置文档的某个属性用于存储文档的二进制安全负载字符串,可在查询时由自定义评分函数或重新返回给客户端。TODO is document attribute that you use as a binary safe payload string to the document that can be evaluated at query time by a custom scoring function or retrieved to the client. |
| MAXTEXTFIELDS | 强制Redis Search索引编码超过32个文本属性,这允许您使用FT.ALTER添加其他属性(超过32个)。为了提高效率,如果索引的文本属性少于32个,Redi Search会对索引进行不同的编码 |
| NOOFFSETS | 不存储文档的term偏移量,可以节省内存,但不允许精确搜索或高亮显示, 使用此选项则意味着NOHL |
| TEMPORARY {seconds} | 临时索引,设置超过n秒 - 未被搜索或新增 - 即删除该索引及其关联的数据 注: 普通索引删除(FT.DROPINDEX)时并不删除数据,需使用DD标志才可级联删除 |
| NOHL | 不支持高亮highlighting,可以节约存储和内存, 使用此选项则意味着NOOFFSETS |
| NOFIELDS | 不存储每个term的属性位,可以节省内存,但不允许按特定属性进行过滤 |
| NOFREQS | 避免在索引中保存term频率,可以节省内存,但不允许基于文档中给定term的频率进行排序 |
| STOPWORDS {count} | 使用自定义停词(stop word)列表设置索引,在索引和搜索时忽略这些词。{count} 是停用词的数量,后面是长度正好为 {count} 的停词参数列表。 如果未设置,FT.CREATE 将使用默认的停词列表。 如果 {count} 设置为 0,则索引没有停用词。 |
| SKIPINITIALSCAN | 创建索引时忽略扫描及索引已有数据 |
注意事项
- 属性数量限制:RediSearch 支持每个模式最多 1024 个属性,其中最多 128 个可以是 TEXT 属性。在 32 位构建中,最多 64 个属性可以是 TEXT 属性。属性越多,索引越大,因为每增加 8 个属性,每个索引记录需要额外一个字节进行编码。如果不需要按文本属性进行过滤,可以始终使用 NOFIELDS 选项,不将属性信息编码到索引中,以节省空间。这仍然允许按数值和地理属性进行过滤。
- 在集群数据库中运行:在集群数据库中有多个索引时,需要确保要索引的文档与索引位于同一分片上。可以通过按索引名称标记文档来实现这一点,例如:
- HSET doc:1{idx}
- FT.CREATE idx … PREFIX 1 doc: …
- 当在集群数据库中运行Redi搜索时,您可以使用RSCoordinator跨分片跨索引。在这种情况下,上述规定不适用。
在SCHEMA中field支持的类型:
| Field类型 | 说明 |
|---|---|
| TEXT | 允许全文(full-text)检索(会被分词、倒排索引) |
| TAG | 由逗号分隔的多标签文本,允许精准匹配(exact-match),如分类、主键、标签等的精确匹配 |
| NUMERIC | 数字范围检索 |
| GEO | 地址位置(Point),格式:经度,纬度,允许圆周范围检索 |
| VECTOR | 向量(多值数组)相似度检索,需要dialect 2及以上(introduced in RediSearch v2.4) , 关于VECTOR的详细说明可参见:Vectors |
| GEOSHAPE | 允许多边形(polygon)检索,需使用WKT格式:POLYGON((x1 y1, x2 y2, …) , 支持的坐标系:
|
在SCHEMA中field支持的参数说明:
| 参数 | 说明 |
|---|---|
| SORTABLE | NUMERIC、TAG、TEXT 或 GEO 属性可以有一个可选的 SORTABLE 参数。 当用户按此属性的值排序结果时,结果可用的延迟非常低。 请注意,这会增加内存开销,因此请考虑不要在大型文本属性上声明它。 可以在没有 SORTABLE 选项的情况下对属性进行排序,但延迟不如使用 SORTABLE 时好。 |
| UNF | 默认情况下,对于哈希(不适用于 JSON),SORTABLE 会对索引值进行规范化(字符设置为小写,去除变音符号)。使用未规范化形式(UNF)时,可以禁用规范化并保留值的原始形式。 对于 JSON,UNF 在 SORTABLE 时是隐式的(禁用规范化)。 |
| NOSTEM | 索引值时禁用词干提取(stemming)。这对于诸如专有名称之类的内容可能是理想的。 |
| NOINDEX | 设置属性不被索引, 修改NOINDEX属性不会导致文档的完全重新索引。 有NOINDEX 且 没有 SORTABLE,则属性将被索引忽略。 |
| PHONETIC {matcher} | 将文本属性声明为 PHONETIC 将在搜索中默认执行语音匹配。强制性的 {matcher} 参数指定使用的语音算法和语言。支持以下匹配器: dm:en - 英语的双重音码 dm:fr - 法语的双重音码 dm:pt - 葡萄牙语的双重音码 dm:es - 西班牙语的双重音码 有关更多信息,请参见:Phonetic matching |
| WEIGHT {weight} | 适用于 TEXT 属性,声明在计算结果准确性时此属性的重要性。这是一个乘数因子,如果未指定,则默认为 1。 |
| SEPARATOR {sep} | 适用于 TAG 属性,指示属性中包含的文本如何拆分为单个标签。默认值为,且参数值必须是单个字符。 |
| CASESENSITIVE | 适用于TAG 属性,保留标签的原始字母大小写。如果未指定,则字符将转换为小写。 |
| WITHSUFFIXTRIE | 对于 TEXT 和 TAG 属性,保留一个包含所有匹配后缀的术语的后缀字典树。 它用于优化包含(foo)和后缀(*foo)查询。否则,将对字典树进行暴力搜索。 如果某些字段存在后缀字典树,则检索时会忽略其他字段 |
| INDEXEMPTY | 对于 TEXT 和 TAG 属性,在 v2.10 中引入, 允许您索引和搜索 空字符串。默认情况下,空字符串不会被索引, 更多使用说明参见:Index missing or empty values |
| INDEXMISSING | 对于所有字段类型,在 v2.10 中引入, 允许您搜索 缺失值,即不包含特定字段的文档。注意: 字段为空值与文档缺少值之间的区别。 默认情况下,缺失值不会被索, 更多使用说明参见:Index missing or empty values |
FT.CREATE命令示例:
# 创建JSON索引
FT.CREATE itemIdx
ON JSON
PREFIX 1 item:
SCHEMA
$.name AS name TEXT
$.description as description TEXT
$.price AS price NUMERIC
$.colors.* AS colors TAG
$.location AS loc GEO