SLAB: Efficient Transformers with Simplified Linear Attention and Progressive Re-parameterized Batch Normalizationhttps://github.com/xinghaochen/SLAB
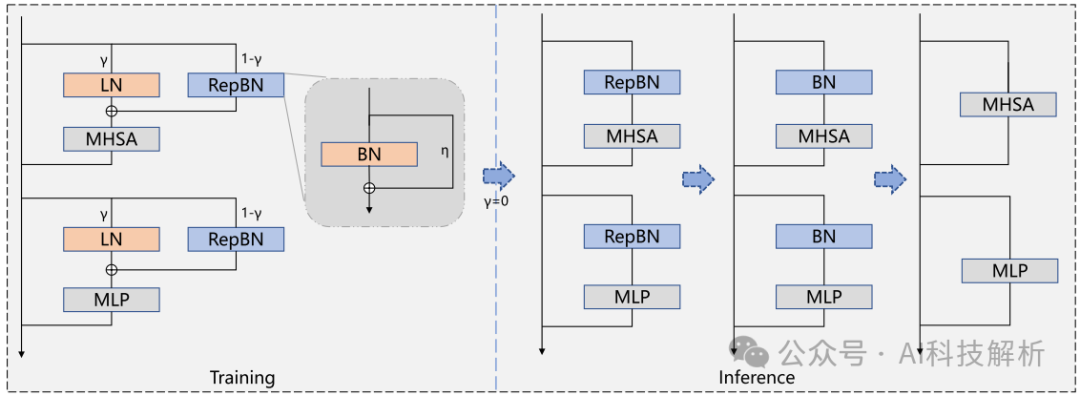
方法
1、LayerNorm需要在每个样本的特征维度上计算均值和标准差,这可能在特征维度非常大时导致较高的计算开销,且LayerNorm可以稳定训练。BatchNorm使用训练时的统计均值和方差数据直接计算,导致较低的推理延迟,但可能导致训练崩溃和较差的性能。
提出了一种PRepBN的新方法,通过使用超参数lamda来控制两个归一化层的比例,在训练中逐步用重新参数化的BatchNorm替换LayerNorm。
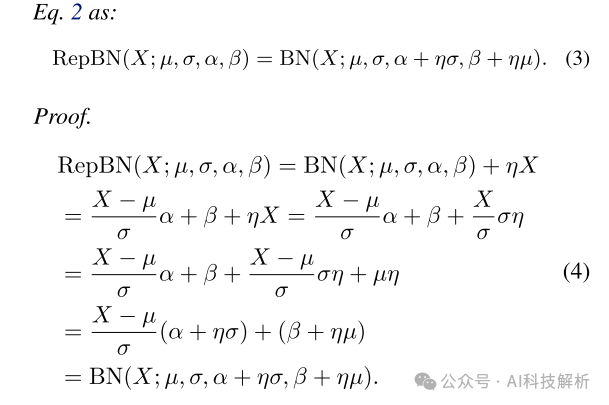

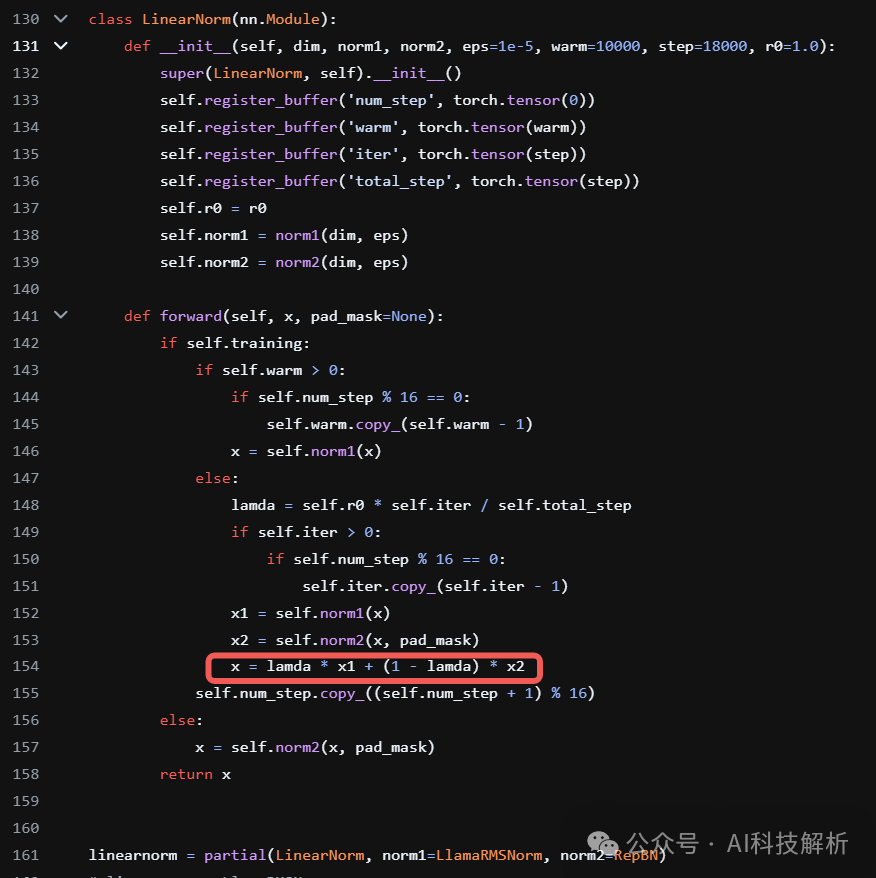
代码实现
https://github.com/xinghaochen/SLAB/blob/main/llama/modeling/llama-350M/modeling_llama.py
2、提出了一个简化的线性注意力(SLA)模块,该模块利用ReLU作为内核函数,并结合了一个深度卷积来执行局部特征增强,简单而有效地实现强大的性能。
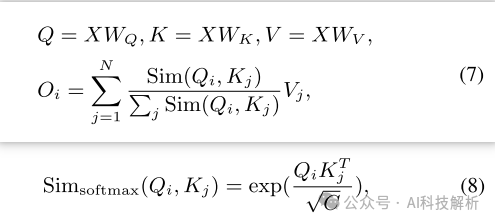
改为
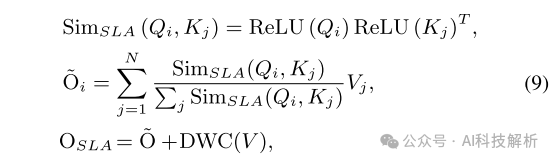
DWC(·)表示深度卷积。
https://github.com/xinghaochen/SLAB/blob/main/detection/mmdet_custom/swin_transformer_slab.py
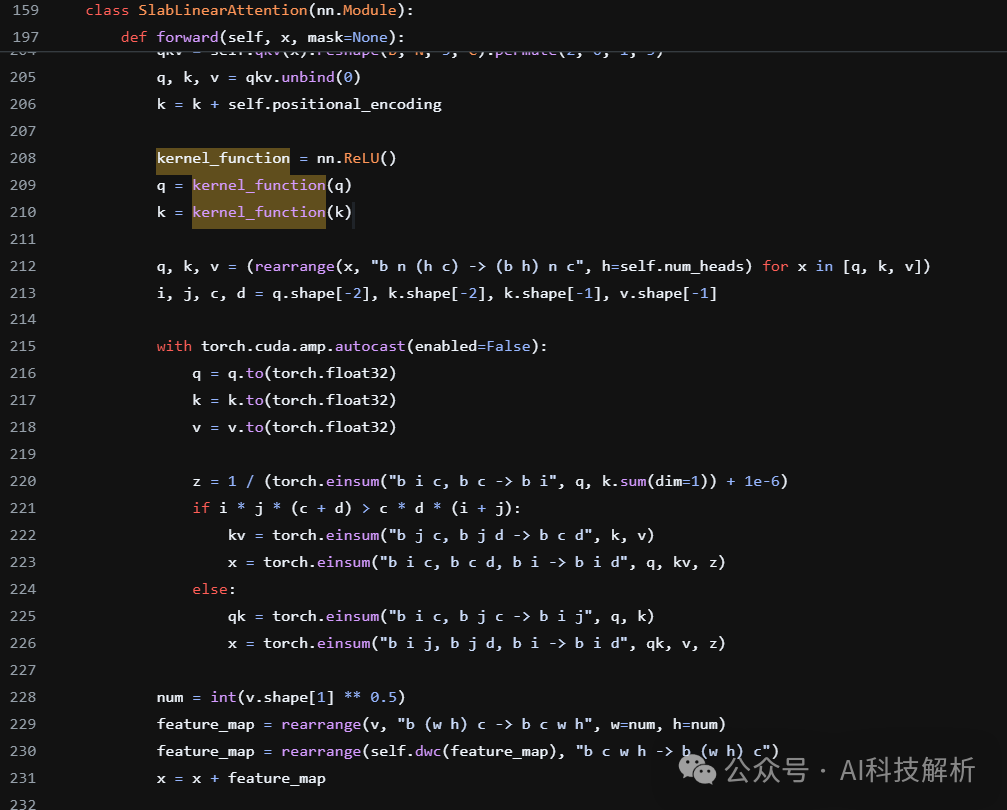
效果评估
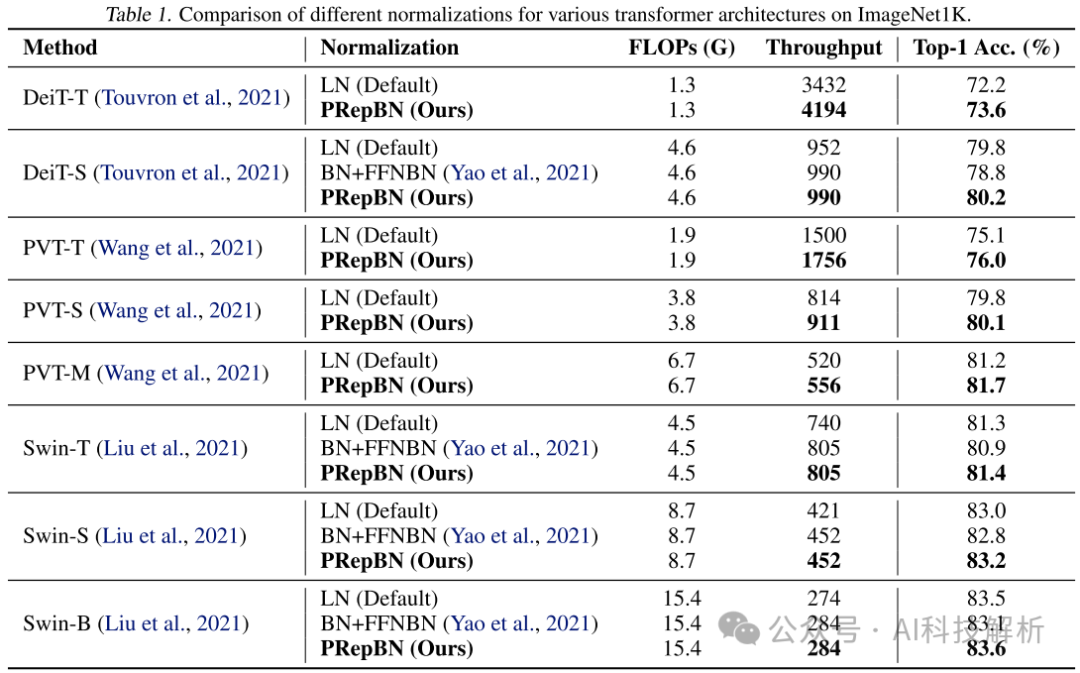
吞吐量和精度都有提升。
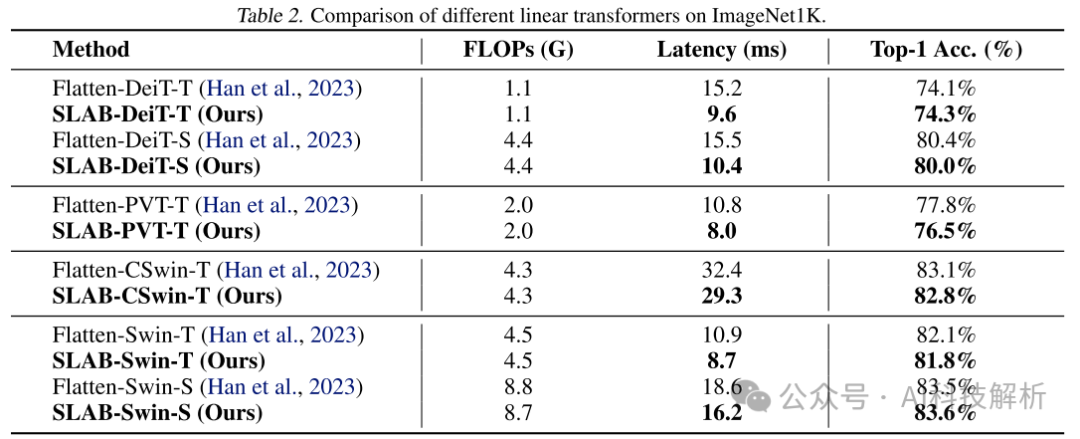
延迟减少。
推理速度优化:稀疏激活Turbo Sparse
Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters
https://huggingface.co/PowerInfer
方法
激活稀疏性可以在不影响性能的情况下显著加速大型语言模型的推理过程。
激活稀疏性是由激活函数决定的,常用的激活函数如SwiGLU和GeGLU表现出有限的稀疏性。简单地用ReLU替换这些函数无法实现足够的稀疏性(将稀疏度从40%增加到70%左右)。
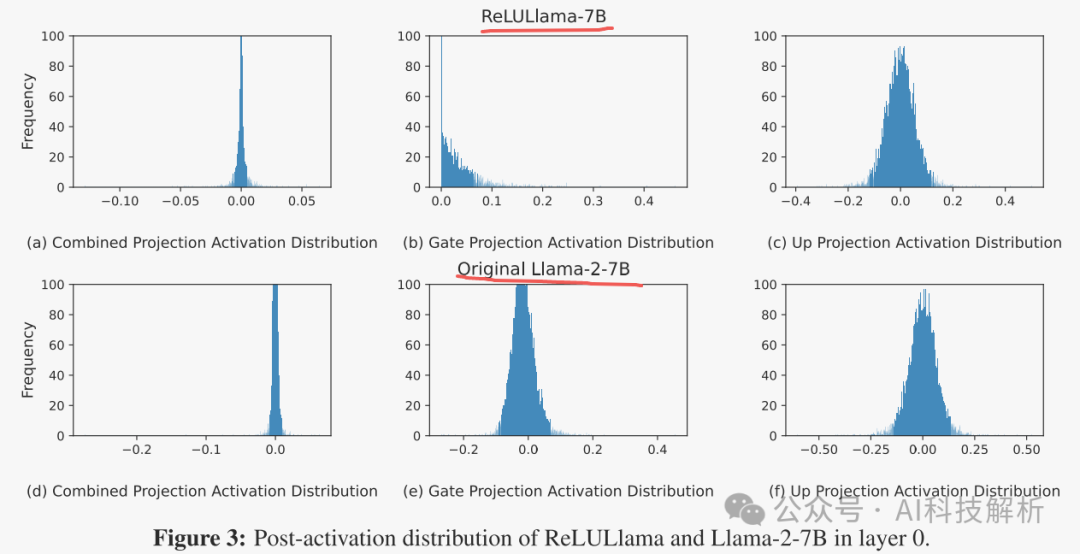

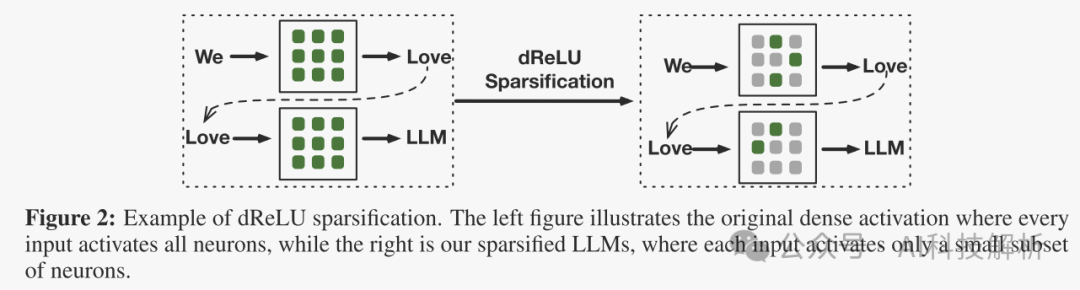
提出了一种新的dReLU函数,该函数旨在提高LLM激活稀疏性(实现了接近90%的稀疏性)。
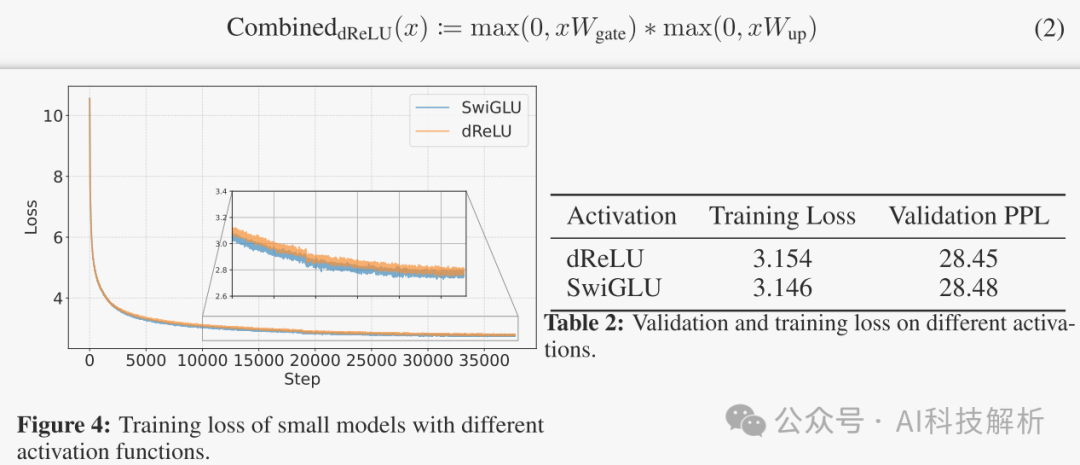
dReLU公式和效果如下
效果测试
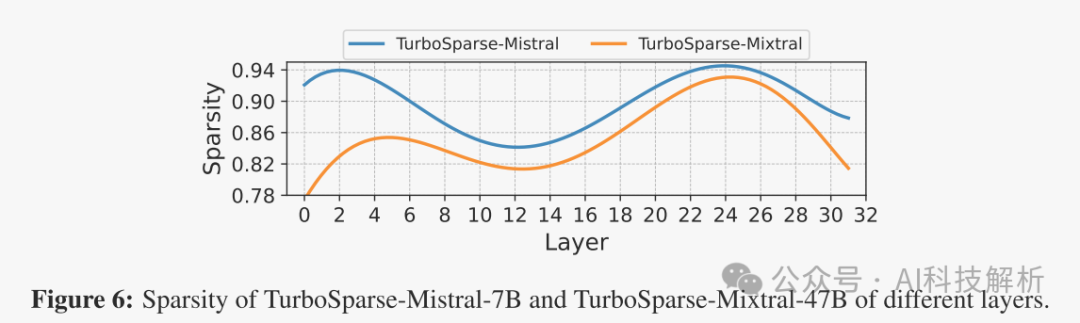
使用一个通用数据集分析每一层的零值激活比例。考虑值为零的激活,对于TurboSparse-Mistral-7 B,平均每层中有90%的神经元不活动。对于TurboSparse-Mixtral-47 B,每个专家FFN的平均百分比略低,为85%。最初,Mixtral-47 B将激活每层8个专家中的2个,引入75%的稀疏度,这意味着只需要计算25%的FLOP。在ReLUfication之后,每个专家只会激活15%的神经元。结合这些,在推断中,每个莫伊层中只有3%的参数将被激活。
速度上有巨大提升
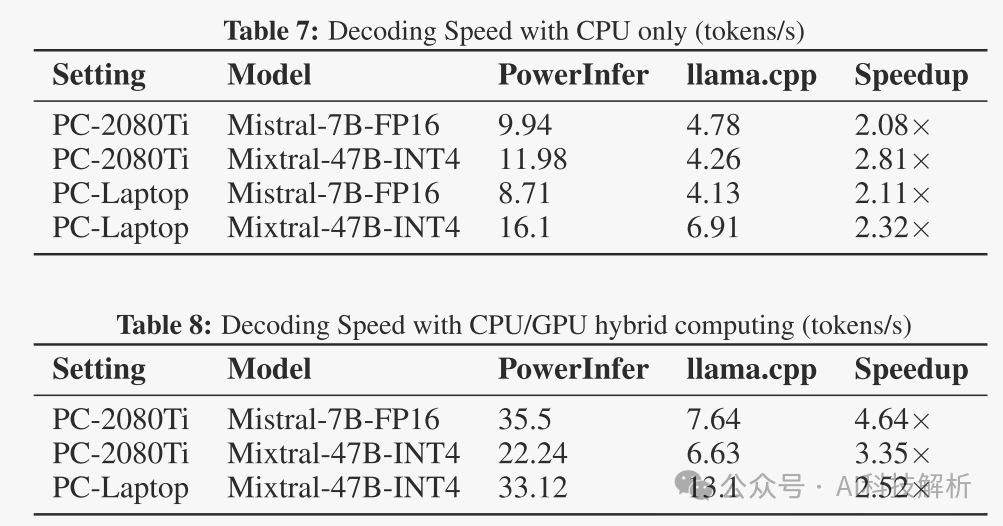
经过实际代码测试。全为0的权重和随机正态分布初始化的权重相比,全0乘法速度确实快了点,但好像也不是很多。。。
速度优化之矩阵乘法->加法—基于BitNet量化的MatMul-free
Scalable MatMul-free Language Modeling
https://github.com/ridgerchu/matmulfreellm
1、AdderNet在卷积神经网络中用符号加法取代乘法。2、采用二进制或三进制量化,将MatMul简化为在累加之前翻转或清零值的操作。开发了第一个可扩展的MatMul-free语言模型(Matmul-free LM),通过使用密集层和元素的Hadamard产品的自注意函