本文基于Docker在ubuntu容器搭建hadoop集群,并进行配置。
查找ubuntu容器
sudo docker search ubuntu下载ubuntu16.04版本镜像
sudo docker pull ubuntu:16.04如果需要查看已经下载的镜像 sudo docker images
启动容器
sudo docker run -it ubuntu:16.04 /bin/bash启动容器后就会默认进入容器,如果需要退出容器,输入exit即可。
使用exit退出容器后,容器的状态为exit,并没有运行,如果需要运行容器,输入sudo docker start 容器ID
同样,需要停止已给容器,输入sudo docker stop 容器ID
重新进入容器:sudo docker exec -it 容器ID /bin/bash可以输入docker ps -a获取容器ID
配置单个容器,作为模板
配置单个容器,首先需要进入容器,在这之后的操作都是默认是进入容器内部的操作,所以你一定要进入容器,不要在外面自己一通瞎几把输入,然后发现配置了半天是在配置服务器本身而不是在配置容器,你将原地气哭。
敲黑板:sudo docker exec -it 容器ID /bin/bash进入容器,然后再进行后面的操作。
安装JDK1.8
更换源
由于这个ubuntu16.04的镜像是刚刚得到的,其中的apt源需要更换,此处将其更换为阿里源。 备份源,以防翻车:
cp /etc/apt/sources.list /etc/apt/sources_backup.list删除源文件
rm /etc/apt/sources.list使用echo命令将源写入到新文件中
echo "
## 20.04
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal main restricted
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-updates main restricted
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-updates universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-updates multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-backports main restricted universe multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-security main restricted
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-security universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-security multiverse
## 163.com
deb http://mirrors.163.com/ubuntu/ focal main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ focal-security main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ focal-updates main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ focal-proposed main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ focal-backports main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ focal main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ focal-security main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ focal-updates main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ focal-proposed main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ focal-backports main restricted universe multiverse
## aliyun
deb http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse
## 22.04
## 163
deb http://mirrors.163.com/ubuntu/ jammy main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ jammy-security main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ jammy-updates main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ jammy-proposed main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ jammy-backports main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ jammy main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ jammy-security main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ jammy-updates main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ jammy-proposed main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ jammy-backports main restricted universe multiverse
## ali
deb http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse
" > /etc/apt/sources.list之后,输入
apt update来更新
好了,现在可以放开手脚使用apt install了。
安装JDK1.8
apt install openjdk-8-jdk测试安装是否成功
java -version
root@iZ2ze8dsxce9ufrpvxlluxZ:~# java -version
openjdk version "1.8.0_242"
OpenJDK Runtime Environment (build 1.8.0_242-8u242-b08-0ubuntu3~16.04-b08)
OpenJDK 64-Bit Server VM (build 25.242-b08, mixed mode)安装Hadoop
安装vim和net-tools网络工具包
apt install vim
apt install net-tools补充一下后面会用到的vim的相关操作:
- 编辑一个文件可以直接:vim 文件名
- 然后会进入到文件中,这时你还不能直接在文件中写东西,因为当前处于命令模式,编辑文本要进入编辑模式才行。
- 你要按键盘的i键(insert),才能进入编辑模式。
- 按下i键后,你就可以在文件中输入内容了;
- vim也不支持鼠标点击,只可以通过鼠标滚轮上下移动行或者方向键来操控光标位置。
- 编辑完毕后按ESC退出编辑模式重新回到命令模式,此时文件并没有保存。
- 输入键盘中的冒号":"这时你在冒号后面可输入命令了
- 然后输入"wq!"回车,就保存退出了。"w"表示保存(write);"q"表示退出(quite);"!"表示强制。
- 如果你不想保存,或者担心文件改错了,想直接退出,那把"wq!"换成"q!"就可以了,表示直接退出,不保存修改。
安装SSH
apt-get install openssh-server
apt-get install openssh-client要配置SSH的免密登录,然后后面的容器都是根据这个镜像启动的,就是一个模板出来的,具有相同的密钥,这样他们互相可以免密通信了。
配置SSH免密通信
进入用户根目录:
cd ~生成公钥,输入一下指令后,一直回车,不用输入其他内容,这样生成的密钥文件会保存在默认位置 一定要复制这个指令,因为指令里面的P是大写,要是小写会报错。
ssh-keygen -t rsa -P ""将公钥追加到authorized_keys中
cat .ssh/id_rsa.pub >> .ssh/authorized_keys启动SSH服务
service ssh start免密登录自己
ssh 127.0.0.1修改.bashrc文件,启动shell的时候,自动启动SSH服务。打开文件vim ~/.bashrc追加如下代码在末尾。
service ssh start补充:SSH基本知识
第一次登录主机的时候会提示:
The authenticity of host 'host (12.18.429.21)' can't be established.
RSA key fingerprint is 98:2e:d7:e0:de:9f:ac:67:28:c2:42:2d:37:16:58:4d.
Are you sure you want to continue connecting (yes/no)?
这是因为第一次登录的时候,无法确认远程主机的主机的真实性,只知道他的公钥指纹,询问连接是否继续,
输入yes即可。
用户经过风险衡量以后决定接受这个远程主机的公钥,在下面提示中输入yes即可:
Are you sure you want to continue connecting (yes/no)? yes
当系统出现如下提示,表示主机已经得到认可:
Warning: Permanently added 'host,12.18.429.21' (RSA) to the list of known hosts.
然后,会要求输入密码。
Password: (enter password)
当远程主机的公钥被接受后,就会保存在本地文件$HOME/.ssh/known_hosts之中。
下次再连接这台主机,系统就会认出它的公钥已经保存在本地了,从而跳过警告部分,直接提示输入密码。
每个SSH用户都有自己的known_hosts文件,此外系统也有一个这样的文件,
通常是/etc/ssh/ssh_known_hosts,保存一些对所有用户都可信赖的远程主机的公钥。
公钥登录:
所谓"公钥登录",原理很简单,就是用户将自己的公钥储存在远程主机上。
登录的时候,远程主机会向用户发送一段随机字符串,用户用自己的私钥加密后,再发回来。
远程主机用事先储存的公钥进行解密,如果成功,就证明用户是可信的,直接允许登录shell,不再要求密码。
生成公钥:要想实现公钥登录,用户就必须提供自己的公钥,可以直接使用ssh-keygen生成一个
ssh-keygen -t rsa -P ""
运行上面的命令以后,系统会出现一系列提示,可以一路回车。
其中有一个问题是,要不要对私钥设置口令(passphrase),如果担心私钥的安全,可以设置一个,此处就没有设置。
运行结束以后,在$HOME/.ssh/目录下,会新生成两个文件:id_rsa.pub和id_rsa。
前者是你的公钥,后者是你的私钥。
如果是要实现远程公钥登录,就可以使用ssh-copy-id user@host将公钥传送到远程主机host上面,这里不需要。
authorized_keys文件:
远程主机将用户的公钥,保存在登录后的用户主目录的$HOME/.ssh/authorized_keys文件中。
公钥就是一段字符串,只要把它追加在authorized_keys文件的末尾就行了。
写入authorized_keys文件后,公钥登录的设置就完成了。
用户如何知道远程主机的公钥?
没有什么好办法,远程主机必须在自己的网站上贴出自己的公钥,以便用户核对。
中间人攻击:
SSH的连接过程为:1).远程主机接收到用户的登录请求;
2).远程主机把公钥发送给用户,用户使用这个公钥将 登录密码进行加密,然后发送给远程主机;
3).远程主机使用自己的私钥,解密登录密码,如果密码正确就同意用户登录。
这个过程本身是安全的,但是实施的过程中有一个风险,如果有人截获了登录请求,然后冒充远程主机给用户发送一个伪造的公钥,
用户在不知情的情况下使用这个伪造的公钥将密码发送给伪造者,然后伪造者收到加密报文,解密后就知道了用户的远程登录密码和账户,这就是中间人攻击。
解释一下公钥私钥:
一台机器为了保证与其他机器通信过程中的可靠性和安全性,有公钥和私钥两把钥匙。
其中公钥是对外开放的,私钥是自己私有的。
外面的机器想要发送信息,就用公钥对信息进行加密,本机收到后,使用私钥对信息进行解密即可。
本机向外面机器发送信息,首先使用Hash函数,生成信件的摘要(Digest);然后使用私钥对摘要进行加密,
生成数字签名(Signature);然后将数字签名附在要发送信息的后面发送给对方。
对方收到后,首先取下数字签名,使用公钥对Signature进行解密,得到摘要Digest;然后再对信息本身使用
Hash函数,将得到的结果与解密得到的摘要Digest对比,如果两者一致,就证明信息没有被修改过。
为了防止公钥被人篡改,可以到证书中心CA(certificate authority)验证,但是有些协议没有CA(比如SSH)SSH的配置非常重要,在后面的集群启动中,遇到了错误Host key verification failed.,具体的解决方案为,使用ssh 172.19.0.x逐个连接容器,然后在启动集群,在遇到是否继续连接是,每个都输入yes,随后就启动成功。
安装Hadoop
拉取Hadoop安装文件,你可以更换其他的镜像源,或其他的版本。
wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz解压到/usr/local
tar -zxvf hadoop-3.2.0.tar.gz -C /usr/local/
补充:tar指令参数-C为切换到指定的目录,格式为:-C<目的目录>或--directory=<目的目录>输入cd /usr/local进入到目录下,将解压后的文件重命名,方便使用
mv hadoop-3.2.0 hadoop在/etc/profile中修改环境变量vim /etc/profile,追加如下内容:
#java
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#hadoop
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME
export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoop
export HDFS_DATANODE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root要使环境变量生效,还需要source一下:
source /etc/profile配置Hadoop
进入Hadoop配置目录
cd /usr/local/hadoop/etc/hadoop正常启动需要配置五个文件,slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml。

- core-site.xml:核心配置文件,定义了集群是分布式,还是本机运行。Hadoop 的核心配置文件,有默认的配置项 core-default.xml。 core-default.xml 与 core-site.xml 的功能是一样的,如果在 core-site.xml 里没有配置的属性,则会自动会获取 core-default.xml 里的相同属性的值。
- hdfs-site.xml:分布式文件系统的核心配置,决定了数据存放路径,数据的副本,数据的block块大小等等。HDFS 的核心配置文件,主要配置 HDFS 相关参数,有默认的配置项 hdfs-default.xml。 hdfs-default.xml 与 hdfs-site.xml 的功能是一样的,如果在 hdfs-site.xml 里没有配置的属性,则会自动会获取 hdfs-default.xml 里的相同属性的值。
- mapred-site.xml:定义了mapreduce运行的一些参数。MapReduce 的核心配置文件,Hadoop 默认只有一个模板文件 mapred-site.xml.template,需要使用该文件复制出来一份 mapred-site.xml 文件
- yarn-site.xml:定义yarn集群。YARN 的核心配置文件
- slaves:定义了从节点是哪些机器datanode,nodemanager运行在哪些机器上
- hadoop-env.sh:文件中设置的是 Hadoop 运行时需要的环境变量。JAVA_HOME 是必须设置的,即使我们当前的系统中设置了 JAVA_HOME,它也是不认识的,因为 Hadoop 即使是在本机上执行,它也是把当前的执行环境当成远程服务器。
配置mapred-site.xml
默认没有mapred-site.xml文件,但是有个mapred-site.xml.template配置模板文件。复制模板生成mapred-site.xml。
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml修改mapred-site.xml为:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/usr/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>- mapreduce.framework.name:指定mapreduce运行框架
- mapred.job.tracker:运行jobtracker的主机名和端口号
- mapred.local.dir:存储作业中间数据的目录,作业终止时,目录被清空,以逗号分隔多个目
- mapred.system.dir:作业运行期间存储共享文件的位置,相对于fs.default.name,默认是${hadoop.tmp.dir}/mapred/system
- mapred.tasktracker.map.tasks.maximum:同一时间允许运行的最大map任务数,默认为2
- mapred.tasktracker.reduce.tasks.maximum:同一时间允许运行的最大map任务数,默认为2
配置slaves
文件slaves,将作为DataNode的主机名写入该文件,每行一个,默认为localhost,所以在伪分布式配置时,节点即作为NameNode也作为DataNode。分布式配置可以保留localhost,也可以删掉,让Master节点仅作为NameNode使用。此处让Master节点仅作为NameNode使用,因此将文件中原来的localhost删除。
- masters记录的是需要启动secondary namenode的节点, 不是namenode,它也和mapreduce没任何关系。
- slaves记录的是执行start-all.sh(或相关命令)时,需要远程启动tasktracker与datanode的节点。
- 这2个文件不需要分发至各个工作节点。
- 哪个机器执行启动脚本,那它就是jobtracke与namenode,再根据masters确定secondary namenode, 根据slaves文件确定tasktracker与datanode,并远程启动这些守护进程。
此处只是给主机取一个名字而已,后面启动容器的时候将对应的容器命名为h01,h02,,,h05就是。
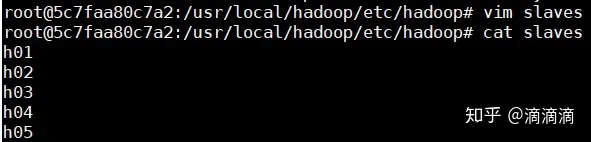
配置core-site.xml
configuration内修改为:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://h01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop3/hadoop/tmp</value>
</property>
</configuration>- fs.defaultFS.name:默认文件系统,配置的地址就是java代码访问的时候的路径,需要配置在java代码中,代码中要用IP:9000不能用localhost
- hadoop.tmp.dir:配置临时文件存放位置。默认是/tmp/hadoop-$user,此位置有可能在重启时被清空,因此必须另外配置。这个属性会影响namenode/secondary namenode中的元数据与datanode中的数据文件存放位置。
配置hdfs-site.xml
修改为:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop3/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>/home/hadoop3/hadoop/hdfs/data</value>
</property>
</configuration>- dfs.data.dir:保存datanode数据文件的位置,可以指定多个目录,这多个目录位于不同的磁盘可以提高IO使用率。默认是${hadoop.tmp.dir}/dfs/data
- dfs.replication:hdfs的冗余复本数量,默认为3
- dfs.namenode.name.dir:保存namenode元数据的位置,也就是namenode元数据存放的地方,记录了hdfs系统中文件的元数据。可以指定多个目录,元数据文件会同时写入这几个目录,从而支持冗余备份。最好有一个是NFS网络硬盘。
配置yarn-site.xml
修改为:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>h01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>配置hadoop-env.sh
在文件末尾添加:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root- JAVA_HOME必须设置,其余均为可选项
- HADOOP_HEAPSIZE:分配给各个守护进程的内存大小,默认为1000M。另外,可以使用HADOOP_NAMENODE_OPTS等单独设置某一守护进行的内存大小。大型集群一般设置2000M或以上,开发环境中设置500M足够了。
- HADOOP_LOG_DIR:日志文件的存放目录,可以设置为/var/log/hadoop
至此,hadoop配置基本可以了,接下来就将这个容器导出为镜像,然后依次启动
在docker中启动集群
首先将容器导出为镜像
sudo docker commit -m "haddop" -a "hadoop" fab4da838c2f newuhadoop可以输入docker images查看镜像列表

随后,分别启动五个节点,
首先是启动h01作为主节点
由于是主节点,所以打开端口,提供web页面访问。
sudo docker run -it --network hadoop -h "h01" --name "h01" -p 9870:9870 -p 8088:8088 newuhadoop /bin/bash--network hadoop将当前容器加入到名为hadoop的虚拟桥接网络中,此网站提供自动的DNS解析功能。
然后`Ctrl+P+Q`退出当前容器补充:如果使用exit退出容器,后续可能出现无法运行的情况,可以docker ps -a查看容器状态,如果为exit状态,需要输入如下指令启动容器: docker start 容器id 这是由于输入exit退出容器后,容器就停止运行了。 这里exit后,容器的状态为exit;但是start启动之后,进入容器再exit退出,容器还是会继续运行,我也不知道这是为啥!!! 后续查了一下docker的运行机制,docker容器在后台运行,必须要有一个前台进程,不知道是不是这个原因。如果有大佬知道,希望大佬不吝赐教
启动其余四个从节点
从节点的启动命令相同,只需要更改一下容器名称h02,h03,h04,h05
sudo docker run -it --network hadoop -h "h02" --name "h02" newuhadoop /bin/bash
然后Ctrl+P+Q退出当前容器
sudo docker run -it --network hadoop -h "h03" --name "h03" newuhadoop /bin/bash
Ctrl+P+Q退出
sudo docker run -it --network hadoop -h "h04" --name "h04" newuhadoop /bin/bash
Ctrl+P+Q退出
sudo docker run -it --network hadoop -h "h05" --name "h05" newuhadoop /bin/bash
Ctrl+P+Q退出启动hadoop集群:
要进入到h01主机中,首先需要找到h01的ID:
docker ps -a

可以看到h01容器的id为42998fcef962,输入如下指令进入容器:
docker exec -it 42998fcef962 /bin/bash
友情提示:这里的容器id要换成你主机上自己的。格式化hdfs
切记:一定是先格式化hdfs再启动hadoop集群;如果是先启动了然后在格式化,会报错,那就需要停止所有./stop-all.sh,然后格式化之后再启动参考链接 进入h01主机后,首先要进行格式化操作,不格式化hdfs系统启动不起来。 进入目录:
cd /usr/local/hadoop/bin格式化hdfs:
./hadoop namenode -format
补充:把hadoop命令设置为全局命令。
安装完Hadoop后,为了使用方便,需要将Hadoop命令加到系统命令中,
如果在没有添加到环境变量之前,执行“hadoop fs”命令时,
则会提示命令不存在的错误:'hadoop: command not found'。
**使用方法三**
方法一:此方法设置后只对当前用户有效,因为~/.bash_profile文件表示的是当前用户的环境变量。
vim ~/.bash_profile
在文件末尾添加:
export PATH=$PATH:/usr/local/hadoop/bin
然后执行source命令:
source ~/.bash_profile
方法二:此方法对所有用户都有效,修改的是系统的环境变量文件。
vim /etc/profile
在文件末尾追加:
export PATH=$PATH:/usr/local/hadoop/bin
然后执行source命令:
source /etc/profile
注意:$PATH变量前的"$"千万不要漏掉,我在改的时候手贱漏掉了,把环境变量改崩了。
**方法三:将环境变量设置在/root/.bashrc中(强烈推荐这个方法)**
我用方法二配置好环境变量后,每次退出容器重新进入环境变量就失效了,必须要重新输入"source /etc/profile"才行,日了狗了。
查找资料发现,这是由于/etc/profile中的变量不是自动export的,完整的os在启动的过程中
会有自动启动程序依次读取系统和用户的配置文件,但是在容器中就没有这一步了。所以要自己导出才可以。
解决的方法可以写一个entrypoint脚本,在脚本中export那些基本不发生变化的环境变量。
我最后采用的方法是将环境变量配置到/root/.bashrc中,重新进入服务器,环境变量也生效。
所以,再来一次,把一下代码添加到/root/.bashrc中。。。。。然后source /root/.bashrc
#java
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#hadoop
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME
export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoop
export HDFS_DATANODE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root启动
进入hadoop的sbin目录
cd /usr/local/hadoop/sbin启动
./start-all.sh
报错:
root@h01:/usr/local/hadoop/sbin# ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Error: Cannot find configuration directory: /etc/hadoop
starting yarn daemons
Error: Cannot find configuration directory: /etc/hadoop
解决:
这是因为使用了 hadoop-env.sh 默认的关于 hadoop 配置文件所在目录的配置,这里需要根据你自己的安装路径重新设置。
修改 hadoop-env.sh:
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop/
然后:source hadoop-env.sh现在可以通过8088端口访问到集群了,地址为IP地址:8088如下所示:

查看分布式文件系统的状态:
查看状态
hdfs dfsadmin -report
输出如下:
root@h01:/usr/local/hadoop# hdfs dfsadmin -report
Configured Capacity: 126421438464 (117.74 GB)
Present Capacity: 88464736256 (82.39 GB)
DFS Remaining: 88463831040 (82.39 GB)
DFS Used: 905216 (884 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (3):
Name: 172.19.0.2:50010 (h01)
Hostname: h01
Decommission Status : Normal
Configured Capacity: 42140479488 (39.25 GB)
DFS Used: 401408 (392 KB)
Non DFS Used: 10702790656 (9.97 GB)
DFS Remaining: 29487943680 (27.46 GB)
DFS Used%: 0.00%
DFS Remaining%: 69.98%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Fri Apr 03 15:34:37 UTC 2020
Last Block Report: Fri Apr 03 15:10:28 UTC 2020
Name: 172.19.0.3:50010 (h02.hadoop)
Hostname: h02
Decommission Status : Normal
Configured Capacity: 42140479488 (39.25 GB)
DFS Used: 77824 (76 KB)
Non DFS Used: 10703114240 (9.97 GB)
DFS Remaining: 29487943680 (27.46 GB)
DFS Used%: 0.00%
DFS Remaining%: 69.98%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Fri Apr 03 15:34:36 UTC 2020
Last Block Report: Fri Apr 03 15:10:24 UTC 2020
Name: 172.19.0.4:50010 (h03.hadoop)
Hostname: h03
Decommission Status : Normal
Configured Capacity: 42140479488 (39.25 GB)
DFS Used: 425984 (416 KB)
Non DFS Used: 10702766080 (9.97 GB)
DFS Remaining: 29487943680 (27.46 GB)
DFS Used%: 0.00%
DFS Remaining%: 69.98%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Fri Apr 03 15:34:36 UTC 2020
Last Block Report: Fri Apr 03 15:10:24 UTC 2020运行内置WordCount实例
用本地的licence.txt文件做统计文件。 首先新建input文件夹:
hadoop fs -mkdir /input将licence.txt文件拷贝到hdfs文件夹中:
hadoop fs -put ../licence.txt /input查看是否拷贝到/input文件夹下了
hadoop fs -ls /input运行内置的wordcount程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /input /output
等待时间长短取决于服务器性能。
输出如下:
20/04/03 15:19:44 INFO mapreduce.JobSubmitter: number of splits:1
20/04/03 15:19:44 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
20/04/03 15:19:44 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1585925475976_0001
20/04/03 15:19:45 INFO impl.YarnClientImpl: Submitted application application_1585925475976_0001
20/04/03 15:19:45 INFO mapreduce.Job: The url to track the job: http://h01:8088/proxy/application_1585925475976_0001/
20/04/03 15:19:45 INFO mapreduce.Job: Running job: job_1585925475976_0001
20/04/03 15:19:58 INFO mapreduce.Job: Job job_1585925475976_0001 running in uber mode : false
20/04/03 15:19:58 INFO mapreduce.Job: map 0% reduce 0%
20/04/03 15:20:08 INFO mapreduce.Job: map 100% reduce 0%
20/04/03 15:20:18 INFO mapreduce.Job: map 100% reduce 100%
20/04/03 15:20:18 INFO mapreduce.Job: Job job_1585925475976_0001 completed successfully
20/04/03 15:20:18 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=36735
FILE: Number of bytes written=471793
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=106306
HDFS: Number of bytes written=27714
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=7250
Total time spent by all reduces in occupied slots (ms)=6419
Total time spent by all map tasks (ms)=7250
Total time spent by all reduce tasks (ms)=6419
Total vcore-milliseconds taken by all map tasks=7250
Total vcore-milliseconds taken by all reduce tasks=6419
Total megabyte-milliseconds taken by all map tasks=7424000
Total megabyte-milliseconds taken by all reduce tasks=6573056
Map-Reduce Framework
Map input records=1975
Map output records=15433
Map output bytes=166257
Map output materialized bytes=36735
Input split bytes=96
Combine input records=15433
Combine output records=2332
Reduce input groups=2332
Reduce shuffle bytes=36735
Reduce input records=2332
Reduce output records=2332
Spilled Records=4664
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=248
CPU time spent (ms)=1450
Physical memory (bytes) snapshot=368164864
Virtual memory (bytes) snapshot=3870294016
Total committed heap usage (bytes)=170004480
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=106210
File Output Format Counters
Bytes Written=27714至此,基于docker的hadoop集群安装就差不多了。