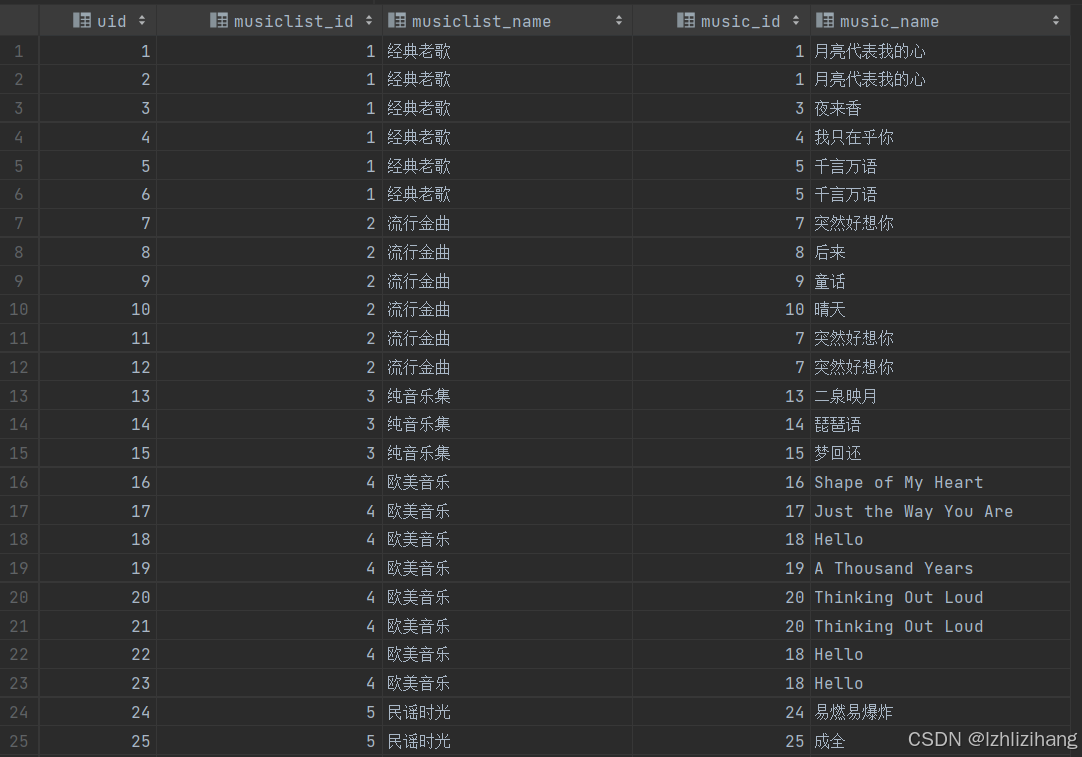
表数据如下:
1 1 经典老歌 1 月亮代表我的心
2 1 经典老歌 1 月亮代表我的心
3 1 经典老歌 3 夜来香
4 1 经典老歌 4 我只在乎你
5 1 经典老歌 5 千言万语
6 1 经典老歌 5 千言万语
7 2 流行金曲 7 突然好想你
8 2 流行金曲 8 后来
9 2 流行金曲 9 童话
10 2 流行金曲 10 晴天
11 2 流行金曲 7 突然好想你
12 2 流行金曲 7 突然好想你
13 3 纯音乐集 13 二泉映月
14 3 纯音乐集 14 琵琶语
15 3 纯音乐集 15 梦回还
16 4 欧美音乐 16 Shape of My Heart
17 4 欧美音乐 17 Just the Way You Are
18 4 欧美音乐 18 Hello
19 4 欧美音乐 19 A Thousand Years
20 4 欧美音乐 20 Thinking Out Loud
21 4 欧美音乐 20 Thinking Out Loud
22 4 欧美音乐 18 Hello
23 4 欧美音乐 18 Hello
24 5 民谣时光 24 易燃易爆炸
25 5 民谣时光 25 成全
26 5 民谣时光 25 成全
27 5 民谣时光 25 成全
将数据上传到 linux 并将其加载到hive 表中
建表和加载数据:
create table music(
uid int,
musiclist_id int,
musiclist_name string,
music_id int,
music_name string
)
row format delimited
fields terminated by '\t';
load data local inpath '/home/hivedata/music.txt' into table music;
解题思路和答案
思路:
核心:
先求出 Top3 歌单,再求出 每个Top3 歌单下面的 Top3 歌曲
1、根据歌单(musiclist_name)分组 count() ,然后拿到次数最多的三个歌单,就是 Top3 歌单
2、将 Top3 歌单与 最开始的music 关联起来,就能拿到 Top3 歌单下面的所有歌曲
3、将关联起来的表通过歌单(musiclist_name)和歌曲(music_name)分组 count() ,就可以拿到每个歌单下的每个歌曲播放次数
4、将播放次数排名( row_number() )
5、根据歌曲排名过滤(where),筛选排名小于等于 3 的,就是 Top3 歌曲
代码:
with t1 as (
-- 思路第一步形成 t1 表
select musiclist_name,count(*) from music group by musiclist_name order by count(*) desc limit 3
),t2 as (
-- 思路第二步形成 t2 表
select music.musiclist_name,music.music_name from t1 join music on t1.musiclist_name = music.musiclist_name
),t3 as (
-- 思路第三步形成 t3 表
select musiclist_name,music_name,count(*) count from t2 group by musiclist_name,music_name
),t4 as (
-- 思路第四步形成 t4 表
select *,row_number() over (partition by musiclist_name order by count desc) rowNum from t3
)
-- 思路第五步拿到结果
select musiclist_name,music_name from t4 where rowNum <= 3;
有人可能没有用过 with t1 as()的用法:
就是将查询出来的结果,变成临时表 t ,提供给下面的查询语句使用