目前主流开源的大模型发展迅速,许多模型经过优化后可以在个人电脑(甚至CPU或消费级GPU)上运行。以下是当前主流的开源大模型及其在个人设备上的部署可行性总结:
一、主流开源大模型
1.DeepSeek系列
DeepSeek大语言模型算法:以Transformer架构为基础,自主研发的深度神经网络模型。模型基于注意力机制,通过海量语料数据进行预训练,并经过监督微调、人类反馈的强化学习等进行对齐,构建形成深度神经网络,并增加审核、过滤等安全机制,使算法模型部署后能够根据人类的指令或者提示,实现语义分析、计算推理、问答对话、篇章生成、代码编写等任务。
主要产品:包括DeepSeek LLM、DeepSeek-Coder、DeepSeekMath、DeepSeek-VL、DeepSeek-V2、DeepSeek-Coder-V2、DeepSeek-V3等多个系列模型。其中,DeepSeek-V3在推理速度上相较历史模型有了大幅提升,在开源模型中位列榜首。
官网地址是:DeepSeek
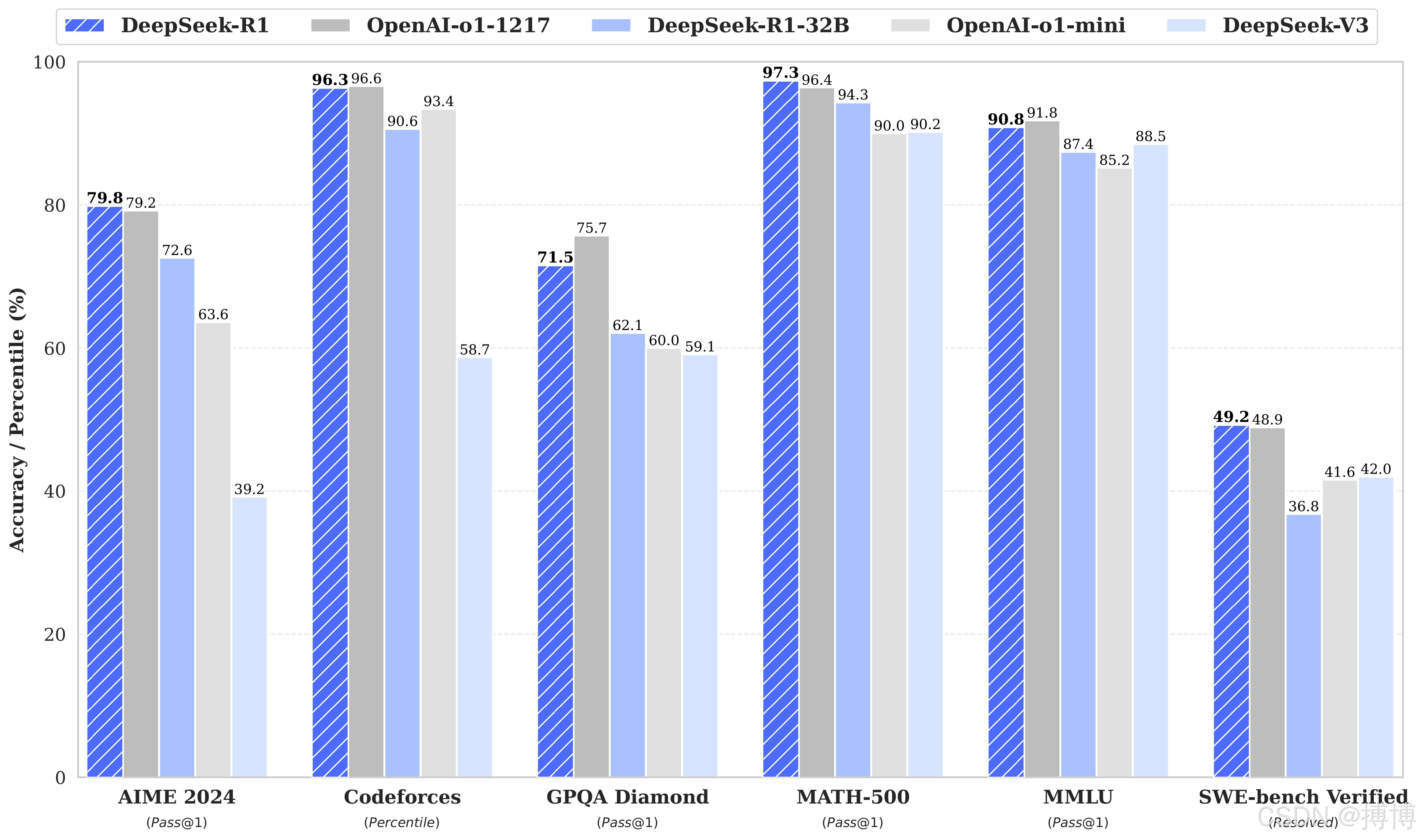
与其他大模型对比结果:
DeepSeek-R1大模型下载地址:https://www.modelscope.cn/models/deepseek-ai/DeepSeek-R1
2.OpenAI GPT系列
GPT-5:作为GPT系列的最新成员,GPT-5支持多模态输入(文本、图像、音频等),拥有数万亿参数,具有更高的语言生成质量。它融合了Transformer与新型神经网络架构,在语言理解和生成上表现卓越。此外,GPT-5还注重安全性和伦理性,加强了可解释性,并提供了轻量化版本以适用于边缘设备部署。然而,由于其庞大的参数规模和计算需求,GPT-5在个人电脑上的部署可能较为困难,除非使用高性能的硬件和专门的优化技术。同时国内使用也有很多条件限制,不建议使用。
3.Stable Diffusion系列
Stable-Diffusion-v1-4:该模型在图像生成和处理方面表现出色,为艺术创作和设计领域带来了革命性的变化。其后续版本如Stable-Diffusion-xl-base-1.0在图像识别和生成方面的表现更加出色。这些模型在图像生成领域具有广泛的应用前景,且相对较轻量,因此有可能在个人电脑上进行部署,但具体还需考虑硬件资源和优化技术。
开源项目地址:GitCode - 全球开发者的开源社区,开源代码托管平台
安装前准备
在开始安装 Stable Diffusion v1-4 之前,你需要确保你的系统和硬件满足以下要求:
(1)操作系统:Windows、macOS 或 Linux
(2)硬件:至少 4GB 的 GPU RAM(推荐使用 NVIDIA GPU)
(3)软件和依赖项:Python、PyTorch和Diffusers库。如果你还没有安装这些依赖项,你可以使用以下命令进行安装:
pip install --upgrade diffusers transformers scipy
具体可以查看这篇文章:https://blog.csdn.net/gitblog_02875/article/details/144419640
4.FLUX.1-dev
该模型以其创新的架构和强大的功能成为了近年来备受欢迎的开源AI大模型。它在处理复杂任务时展现出了卓越的能力,无论是在科学研究还是商业应用中都能提供强大的支持。然而,由于其高性能和复杂性,FLUX.1-dev在个人电脑上的部署可能需要一定的硬件资源和优化。
开源项目地址:魔搭社区
5.Qwen系列
Qwen中文名称为“通义千问”,是阿里云推出的一个超大规模的语言模型,该模型在遵循指令和生成自然语言方面的能力使其在聊天机器人和智能助手领域备受欢迎。其巨大的模型规模和强大的语言理解能力为其赢得了广泛的关注。然而,由于其规模庞大,Qwen2.5-1.5B-Instruct在个人电脑上的部署可能较为困难,需要高性能的硬件和专门的优化技术。官网地址是:通义大模型_企业拥抱 AI 时代首选-阿里云
主要模型版本如下:
(1)通义千问1.0版本:这是通义千问的初始版本,为后续版本的发展奠定了基础。不过,关于1.0版本的具体功能和性能提升细节,可能因时间久远而难以详细追溯。
(2)通义千问2.0版本:
2023年10月31日,阿里云在杭州正式发布了通义千问2.0。这个版本拥有千亿级参数,综合性能超过GPT-3.5,并正在加速追赶GPT-4。
相比4月发布的1.0版本,2.0版本在复杂指令理解、文学创作、通用数学、知识记忆、幻觉抵御等能力上均有显著提升。
在具体能力方面,中英文理解、数学计算、代码推理能力是大语言模型的基本功。以英语任务为例,通义千问2.0在MMLU基准中仅次于GPT-4;在HumanEval测试中,其得分也紧跟GPT-4和GPT-3.5。
通义千问2.1版本:这是2.0版本之后的一个更新,虽然具体发布时间可能因官方公告而有所变化,但2.1版本在理解和性能上相对于2.0版本有所提升。
(3)通义千问2.5版本:
2024年5月9日,在阿里云AI峰会现场,阿里云正式发布通义千问2.5。这个版本在多项能力上实现了显著提升。
在中文语境下,通义千问2.5在文本理解、文本生成、知识问答及生活建议、闲聊及对话和安全风险等多项能力上赶超GPT-4。
同时,通义千问最新开源的1100亿参数模型在多个基准测评收获最佳成绩,超越Meta的Llama-3-70B。
相比通义千问2.1版本,2.5版本的理解能力、逻辑推理、指令遵循、代码能力分别提升9%、16%、19%、10%。
在权威基准OpenCompass上,通义千问2.5得分追平GPT-4 Turbo,是该基准首次录得国产大模型取得如此出色的成绩。
6.LLaMA系列
LLaMA,全称为Large Language Model Family of AI,直译为“大语言模型元AI”。LLaMA系列是由Meta AI(前身为Facebook AI Research,FAIR)开发的一系列大型语言模型(LLMs)。这个系列的模型以庞大的训练数据和先进的神经网络架构为基础,能够理解和生成自然语言文本。Llama这个单词本身是指美洲大羊驼,所以社区也将这个系列的模型昵称为羊驼系模型。如LLaMA2等模型在自然语言处理领域具有出色的表现。这些模型相对较轻量,且提供了多种分支以适应不同的硬件需求。因此,它们有可能在个人电脑上进行部署,但具体还需考虑硬件资源和优化技术。模型版本如下:
(1)LLaMA 1:
发布时间:2023年2月。
模型特点:作为初代模型,LLaMA 1是一个纯粹的基座语言模型,设计目标是提供一个开放且高效的通用语言理解与生成平台。
参数规模:共有7B、13B、33B、65B(650亿)四种版本。
训练数据:来源都是公开数据集,无任何定制数据集,保证了其工作与开源兼容和可复现。整个训练数据集在token化之后大约包含1.4T的token。其中,LLaMA-65B和LLaMA-33B是在1.4万亿个token上训练的,而最小的模型LLaMA-7B是在1万亿个token上训练的。
模型性能:在大多数基准上可以胜过GPT-3(参数量达1750亿),而且可以在单块V100 GPU上运行。最大的650亿参数的LLaMA模型可以媲美谷歌的Chinchilla-70B和PaLM-540B。
(2)LLaMA 2:
发布时间:2023年7月。
模型特点:旨在挑战大型科技竞争对手的限制性做法,Meta免费发布LLaMA 2背后的代码和数据,使世界各地的研究人员能够利用和改进该技术。
参数规模:Meta训练并发布了三种模型大小的Llama 2,分别为70亿、130亿和700亿个参数。随附的预印本还提到了一个具有34B参数的模型,该模型可能在未来满足安全目标后发布。
训练数据:用于训练基础模型的数据增加了40%,使用的token数量翻倍至2万亿,这增强了模型对广泛语言现象的理解和生成能力。
模型性能:被描述为新的state-of-the-art(SOTA)开源大型语言模型,意味着在发布时其性能在相关基准测试或实际应用中处于业界领先水平。
商业许可证:虽然LLaMA 2是开源的,但使用它可能需要遵循特定的许可条款,可能是为了确保模型的合理使用并保护知识产权。
(3)LLaMA 3:
发布时间:2024年4月18日。
模型特点:展现了显著的技术进步和战略意义,距离Llama 2的发布仅过去了9个月,表明Meta AI在短时间内快速推进了技术研发。
参数规模:提供了不同规模的版本,包括最小的80亿参数版本和最大规划中的4050亿参数版本。即使最小版本与Llama 2最大版本(700亿参数)的性能处于同一量级,也显示出Llama 3在模型效率上的提升。
训练数据:基于超过15万亿个token的公开数据预训练,数据量是Llama 2的七倍,反映了Meta AI对于大规模数据驱动模型性能提升的重视。
训练效率:相较于Llama 2提升了三倍,这可能得益于算法优化、硬件加速或分布式训练策略的进步,使得在相同时间内能够完成更多的训练迭代或处理更大规模的数据。
集成与应用:将被整合到Meta的虚拟助手服务中,成为Facebook、Instagram、WhatsApp、Messenger等平台上免费使用的最先进AI应用程序之一,增强了这些社交平台的智能化交互体验。同时,也得到了主流云服务商的支持,便于开发者和研究人员便捷地部署和利用。
(4)LLaMA 3.2:
作为AI大模型的里程碑版本,新增了视觉推理功能。
提供了1B、3B、11B和90B轻量级模型,其中11B和90B支持图片视觉推理功能。
可通过oLLama在Windows、Mac和Linux上部署运行。
二、个人电脑可安装主流开源大模型列表
1. Meta系列
(1)LLaMA / LLaMA 2
参数量:7B、13B、70B
特点:基座模型,需申请访问权限,支持英文和多语言。
部署可行性:
17B模型:通过量化(4-bit或8-bit)可在24GB显存的GPU或高端CPU(如Apple M2)运行。
213B及以上:需高性能GPU(如RTX 3090+)或分布式内存优化。
(2)Alpaca / Vicuna
基于LLaMA的微调版本,优化对话能力。
部署可行性:同LLaMA,需量化或内存优化。
2. Mistral AI
(1)Mistral 7B
参数量:7B
特点:性能接近LLaMA 13B,支持长上下文(8k tokens),Apache 2.0协议。
部署可行性:量化后(4-bit)可在消费级GPU(如RTX 3060 12GB)或Apple Silicon芯片运行。
3. Falcon
(1)Falcon-7B / Falcon-40B
参数量:7B、40B
特点:Apache 2.0协议,支持多语言,训练数据质量高。
部署可行性:
17B模型:量化后可在16GB显存的GPU运行(如RTX 4080)。
240B模型:需多卡或高性能服务器。
4. 中文友好模型
(1)ChatGLM3-6B(清华)
参数量:6B
特点:专为中文优化,支持中英双语,可商用。
部署可行性:量化后可在RTX 3060(12GB显存)或Mac M2(16GB内存)运行。
(2)Qwen-7B(阿里)
参数量:7B
特点:支持中英日代码,上下文长度8k。
部署可行性:同ChatGLM3。
(3)Baichuan2-7B(百川)
参数量:7B
特点:中英双语,支持商用。
部署可行性:量化后可在消费级GPU部署。
5. 轻量级模型
(1)Phi-2(微软)
参数量:2.7B
特点:小体积高性能,适合推理和微调。
部署可行性:无需量化,直接运行在8GB显存的GPU或CPU。
(2)TinyLlama-1.1B
参数量:1.1B
特点:轻量版Llama,训练数据丰富。
部署可行性:可在手机或树莓派运行。
6. 其他
(1)BLOOM(BigScience)
参数量:7B、176B
特点:多语言支持,需高性能硬件。
部署可行性:仅7B可在高端个人设备运行。
(2)StableLM(Stability AI)
参数量:3B、7B
特点:透明数据集,Apache 2.0协议。
部署可行性:7B量化后可行。
三、个人电脑部署方案
1. 硬件需求
| 模型规模 | 最低配置 | 推荐配置 |
| 1B-3B | CPU(8GB内存)或GPU(4GB显存) | GPU(RTX 3060 12GB) |
| 7B | GPU(10GB显存 + 量化) | GPU(RTX 3090 24GB)或Apple M2 |
| 13B+ | 需多卡或云计算 | 服务器集群 |
2. 部署工具
(1)llama.cpp
支持CPU/GPU推理,兼容LLaMA、Mistral等模型。
bash示例代码:
# 量化模型(转为GGML格式)
./llama.cpp/quantize model.gguf model_q4_0.gguf q4_0
# CPU推理
./llama.cpp/main -m model_q4_0.gguf -p "你好"(2)Ollama
一键部署工具,支持Mac/Linux/Windows,内置Mistral、Llama 2等模型。
bash示例:
ollama run mistral # 直接运行Mistral 7B(3)Hugging Face Transformers
使用4-bit量化加载模型:
python代码:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-v0.1",
load_in_4bit=True, # 4-bit量化
device_map="auto"
)(4)GPTQ(GPU优化)
使用AutoGPTQ库加速:
python代码:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"TheBloke/Llama-2-7B-Chat-GPTQ",
device_map="auto"
)3. 量化技术
(1)4-bit量化:减少显存占用至1/4,性能损失较小(如GPTQ、GGML)。
(2)8-bit量化:兼容性更好,适合低端设备(如bitsandbytes库)。
四、推荐个人部署的模型
| 模型 | 参数量 | 部署难度 | 硬件需求 | 适用场景 |
| Mistral 7B | 7B | 低 | RTX 3060(量化) | 通用对话、写作 |
| Llama-2-7B-Chat | 7B | 中 | RTX 3080(16GB显存) | 多轮对话 |
| ChatGLM3-6B | 6B | 低 | Mac M2(16GB内存) | 中文任务 |
| Phi-2 | 2.7B | 极低 | CPU或低端GPU | 教育、代码生成 |
| TinyLlama-1.1B | 1.1B | 极低 | 树莓派/手机 | 简单问答 |
五、部署示例:在Mac M2上运行Mistral 7B
bash安装Ollama
curl -fsSL https://ollama.ai/install.sh | shbash运行模型
ollama run mistral输入提示(文本text)
>>> 用中文写一首关于秋天的诗六、注意事项
(1)模型协议:部分模型(如LLaMA)需申请商用许可,Falcon/Mistral可免费商用。
(2)显存优化:优先使用量化(4-bit)和device_map="auto"自动分配设备。
(3)中文支持:优先选择ChatGLM3、Qwen或Baichuan等针对中文优化的模型。