Anaconda 和 Jupyter notebook已成为数据分析的标准环境。
简单来说,Anaconda是包管理器和环境管理器,Jupyter notebook 可以将数据分析的代码、图像和文档全部组合到一个web文档中。
接下来我详细介绍下Anaconda,并在最后给出Jupyter notebook:
1.Anaconda是什么?
2.如何安装?
3. 如何管理包?
4.如何管理环境?
5.Jupyter notebook如何快速上手?
不过在开始前我需要强调下,下面的步骤你要亲自跟着敲一遍并在自己的电脑上实践。虽然下面你会遇到很多命令,给了谁都记不住的。但是别怕,也别中途放弃,因为你没必要记住命令,因为当你在后面学习数据分析用的多了,自然就记住了。
记不住也没关系,学会在哪查找就可以了。你只需要跟着上面步骤操作下,并理解了每一步是干什么的就可以了。后面遇到要做的事情,忘记了回头查这个文档就可以了。
刚开始学习的过程就像下面这个图,只要中途不放弃,自己实际操作一遍,我保证你可以熟练上手。


1.Anaconda是什么?
Anaconda在英文中是“蟒蛇”,麻辣鸡(Nicki Minaj妮琪·米娜)有首歌就叫《Anaconda》,表示像蟒蛇一样性感妖娆的身体。
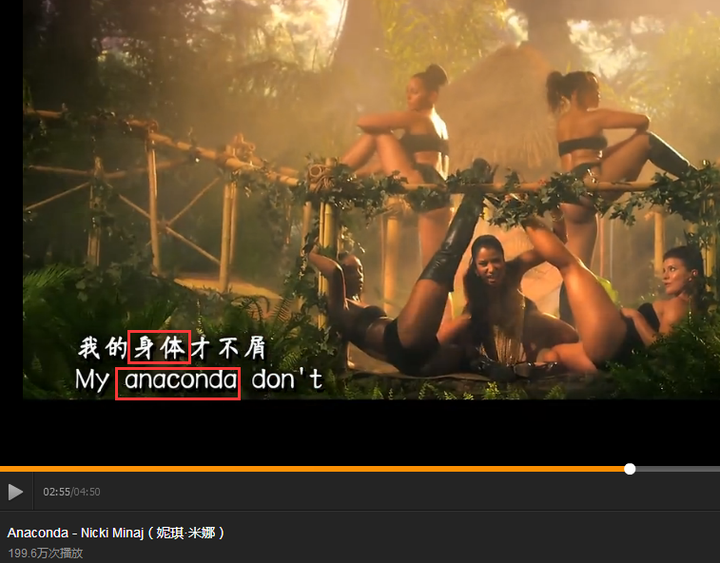
所有你看下面Anaconda的图标就像一个收尾互相咬住的“蟒蛇”。


你可能已经安装了 Python,那么为什么还需要 Anaconda?有以下3个原因:
1)Anaconda 附带了一大批常用数据科学包,它附带了 conda、Python 和 150 多个科学包及其依赖项。因此你可以立即开始处理数据。
2)管理包
Anaconda 是在 conda(一个包管理器和环境管理器)上发展出来的。
在数据分析中,你会用到很多第三方的包,而conda(包管理器)可以很好的帮助你在计算机上安装和管理这些包,包括安装、卸载和更新包。
3)管理环境
为什么需要管理环境呢?
比如你在A项目中用了 Python 2,而新的项目B老大要求使用Python 3,而同时安装两个Python版本可能会造成许多混乱和错误。这时候 conda就可以帮助你为不同的项目建立不同的运行环境。
还有很多项目使用的包版本不同,比如不同的pandas版本,不可能同时安装两个 Numpy 版本,你要做的应该是,为每个 Numpy 版本创建一个环境,然后项目的对应环境中工作。这时候conda就可以帮你做到。
2. 如何安装Anaconda?
Anaconda 可用于多个平台( Windows、Mac OS X 和 Linux)。你可以在下面地址上找到安装程序和安装说明。根据你的操作系统是32位还是64位选择对应的版本下载。
(Anaconda已经不支持Windows XP;同时查看自己电脑是32位还是64位,不要装错了。)
官网地址:https://www.continuum.io/downloads
如果官网地址网速太慢无法下载,可以从我公众号:猴子聊人物,中回复“资料”从网盘下载
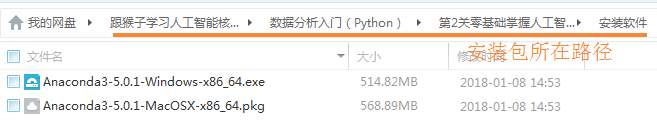



Anaconda 的下载文件比较大(约 500 MB),因为它附带了 Python 中最常用的数据科学包。
如果计算机上已经安装了 Python,安装不会对你有任何影响。实际上,脚本和程序使用的默认 Python 是 Anaconda 附带的 Python。
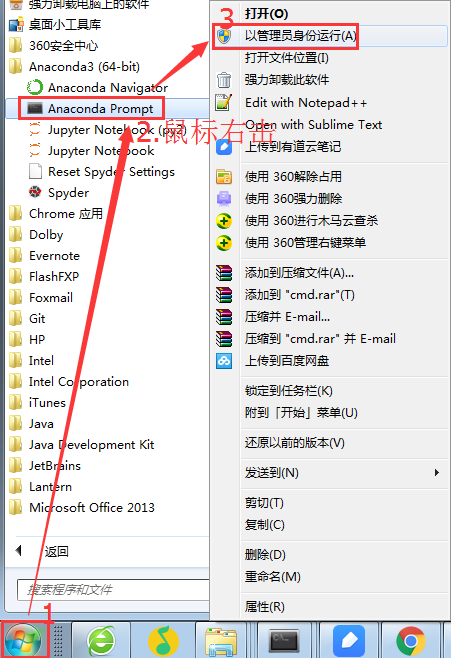
注意:如果你是windows 10系统,注意在安装Anaconda软件的时候,右击安装软件→选择以管理员的身份运行。
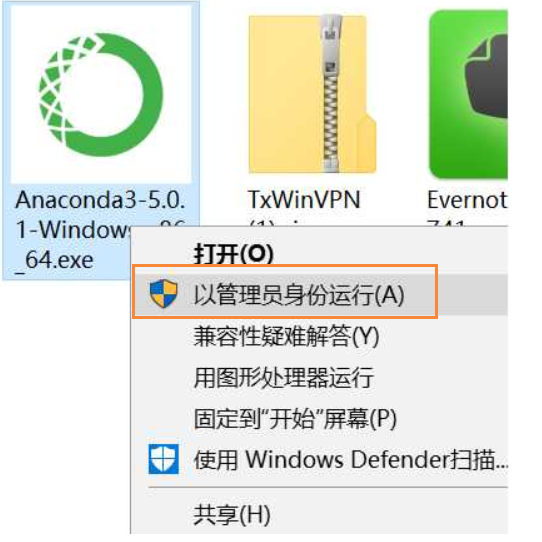
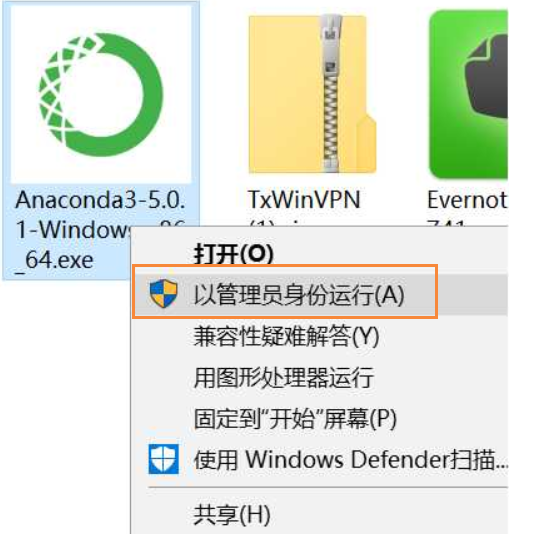
完成安装后,如果你是在windows上操作,按下面图打开 Anaconda Prompt (或者 Mac 下的终端),后面我会将Anaconda Prompt统一称为“终端”。
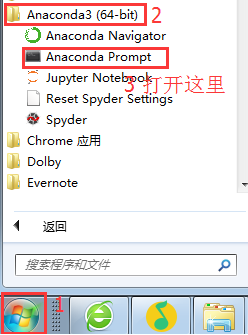
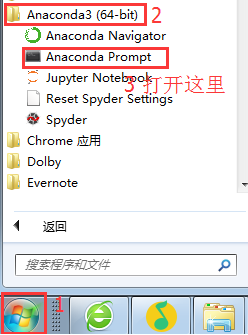
注意:如果你是windows 10系统,按下图操作
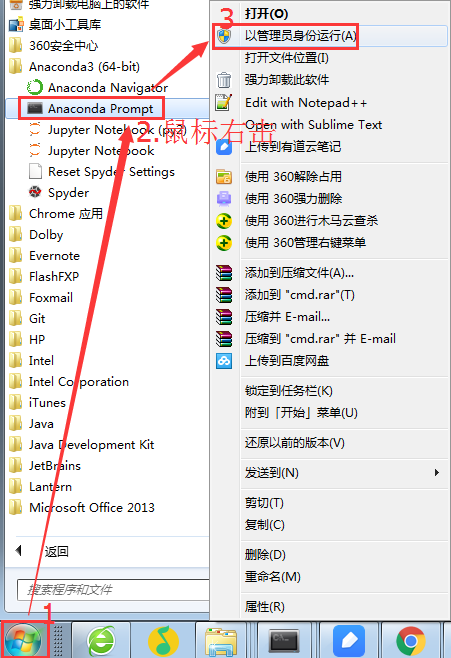
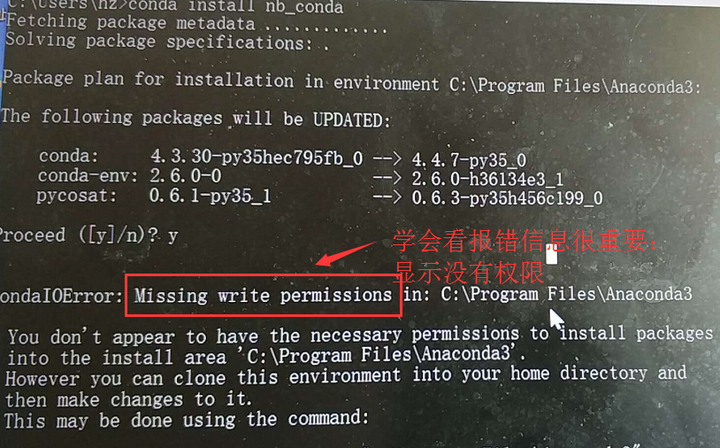
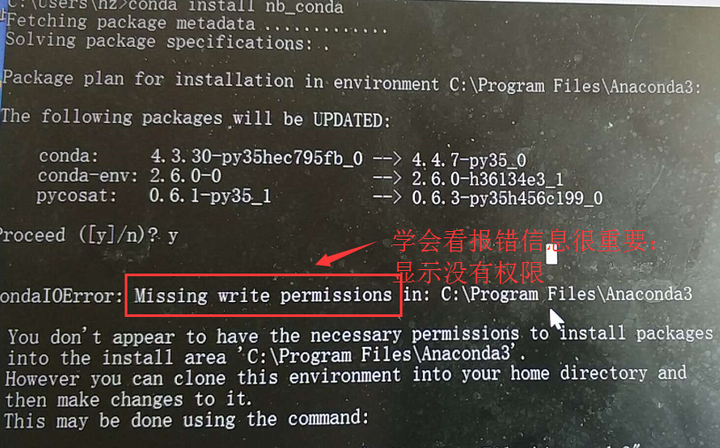
如果win10系统没有按上述操作,后面会报下面的错误信息:
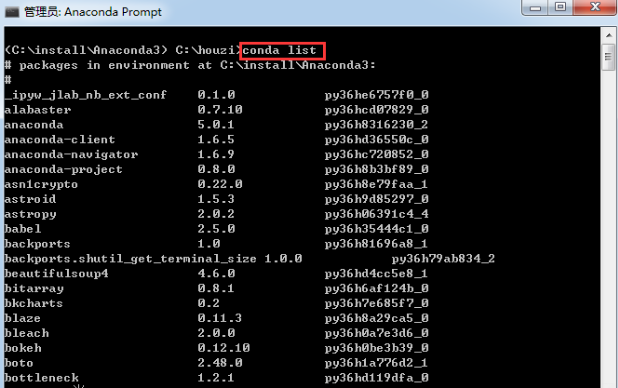
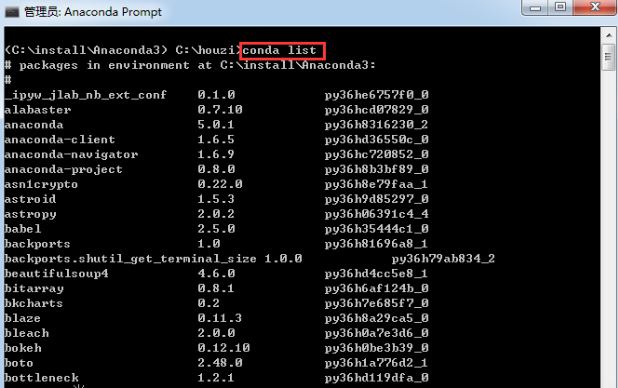
可以在终端或命令提示符中键入 conda list,以查看你安装的内容。
如果安装后,在Anaconda Prompt中都无法使用Conda命令,解决方法在这里:
猴子:Python管理包工具anaconda安装过程常见问题解决办法
如果Anaconda Prompt中可以使用conda命令,接着下面继续操作。
为了避免后面使用报错,你需要先更新下所有包。在终端输入更新所有包的命令:
conda upgrade --all
并在提示是否更新的时候输入 y(Yes)让更新继续。初次安装下的软件包版本一般都比较老旧,因此提前更新可以避免未来不必要的问题。
如果以上命令运行后报错,参考这里的解决办法:
猴子:Python管理包工具anaconda安装过程常见问题解决办法
3. 如何管理包?
安装了 Anaconda 之后,就可以很方便的管理包了(安装,卸载,更新)。
1)安装包
在终端中键入:
conda install package_name
例如,要安装 pandas,在终端中输入:
conda install pandas
你还可以同时安装多个包。类似 conda install pandas numpy 的命令会同时安装所有这些包。还可以通过添加版本号(例如 conda install numpy=1.10)来指定所需的包版本。
conda 还会自动为你安装依赖项。例如,scipy 依赖于 numpy,因为它使用并需要 numpy。如果你只安装 scipy (conda install scipy),则 conda 还会安装 numpy(如果尚未安装的话)。
2)卸载包
在终端中键入 :
conda remove package_names
上面命令中的package_names是指你要卸载包的名称,例如你想卸载pandas包:conda remove pandas
3)更新包
在终端中键入:
conda update package_name
如果想更新环境中的所有包(这样做常常很有用),使用:conda update --all。
4)列出已安装的包
#列出已安装的包
conda list
例如我已经成功安装了numpy和pandas这两个常用的包。

如果不知道要找的包的确切名称,可以尝试使用 conda search search_term 进行搜索。例如,我知道我想安装numpy,但我不清楚确切的包名称。我可以这样尝试:conda search num。
4.如何管理环境?
conda 可以为你不同的项目建立不同的运行环境。
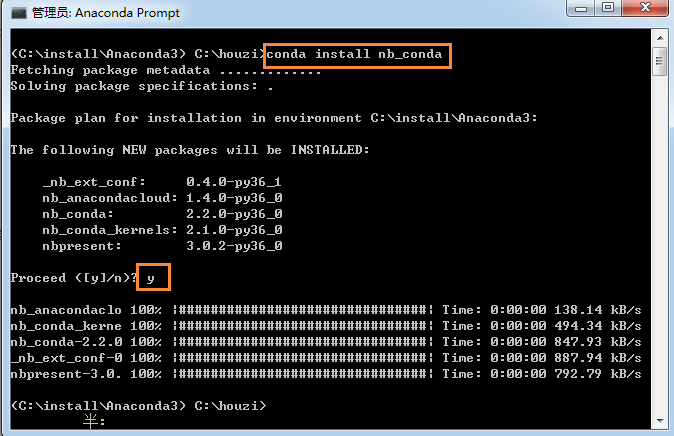
0)安装nb_conda用于notebook自动关联nb_conda的环境。
1)创建环境
在终端中使用:
conda create -n env_name package_names
上面的命令中,env_name 是设置环境的名称(-n 是指该命令后面的env_name是你要创建环境的名称),package_names 是你要安装在创建环境中的包名称。
例如,要创建环境名称为 py3 的环境并在其中安装 numpy,在终端中输入 conda create -n py3 pandas。

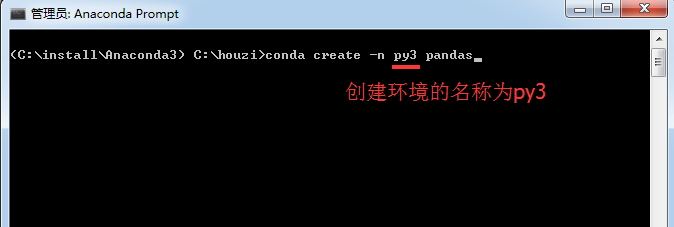
2)创建环境时,可以指定要安装在环境中的 Python 版本
当你同时使用 Python 2.x 和 Python 3.x 中的代码时这很有用。要创建具有特定 Python 版本的环境,例如创建环境名称为py3,并安装最新版本的Python3在终端中输入:
conda create -n py3 python=3
或也可以这样创建环境名称为py2,并安装最新版本的Python2:
conda create -n py2 python=2
因为我做的项目不同,有时候会用到Python2,还有时候会用到Python3。所以我在自己的计算机上创建了这两个环境,并分别取了这样的环境名称:py2,py3。这样我可以根据不同的项目轻松使用不同版本的python。
如果你要安装特定版本(例如 Python 3.6),请使用 conda create -n py python=3.6
3)进入环境
在 Windows 上,你可以使用 activate my_env进入。在 OSX/Linux 上使用 source activate my_env 进入环境。
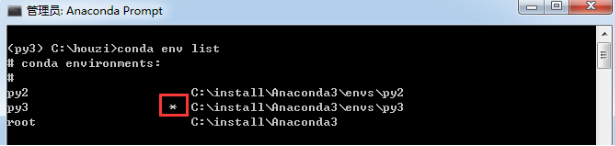
进入环境后,你会在终端提示符中看到环境名称,下面图片是我进入py3的环境(这里的py3是我上面创建环境时自己起的名称,你可以起个自己喜欢的名称)。


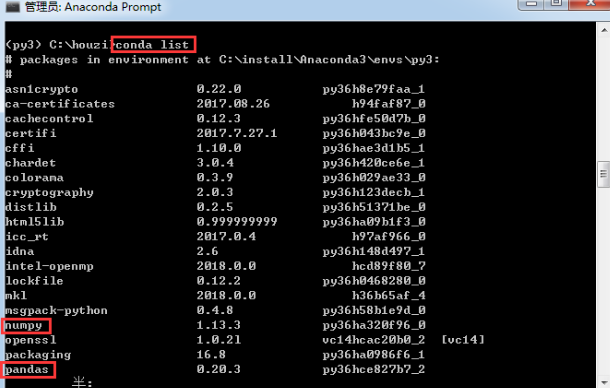
进入环境后,我可以用conda list 查看环境中默认安装的几个包:
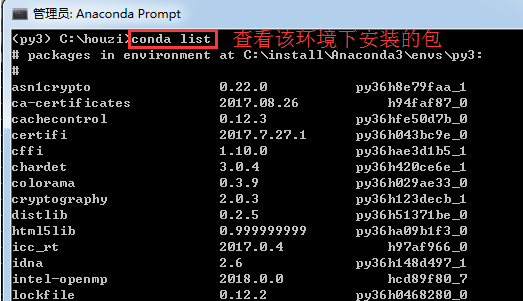
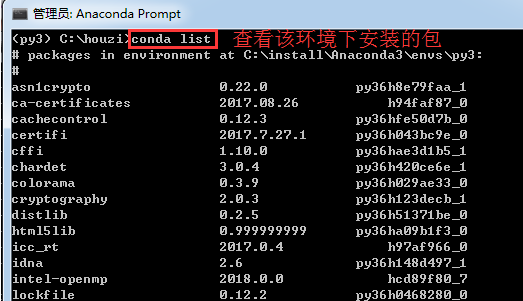
在环境中安装包的命令与前面一样:conda install package_name。
不过,这次你安装的特定包仅在你进入环境后才可用。
3)离开环境
在 Windows 上,终端中输入:
deactivate
在 OSX/Linux 上 输入:
source deactivate
4)共享环境
共享环境非常有用,它能让其他人安装你的代码中使用的所有包,并确保这些包的版本正确。比如你开发了一个药店数据分析系统,你要提交给项目部署系统的王二狗来部署你的项目,但是王二狗并不知道你当时开发时使用的是哪个python版本,以及使用了哪些包和包的版本。这怎么办呢?
你可以在你当前的环境中终端中使用 conda env export > environment.yaml 将你当前的环境保存到文件中包保存为YAML文件(包括Pyhton版本和所有包的名称)。
命令的第一部分 conda env export 用于输出环境中的所有包的名称(包括 Python 版本)。


在“notebook工作文件夹”下(及你在终端中上图的路径)可以看到导出的环境文件:
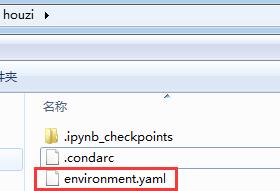
在 GitHub 上共享代码时,最好同样创建环境文件并将其包括在代码库中。这能让其他人更轻松地安装你的代码的所有依赖项。
导出的环境文件,在其他电脑环境中如何使用呢?
首先在conda中进入你的环境,比如activate py3
然后在使用以下命令更新你的环境:
#其中-f表示你要导出文件在本地的路径,所以/path/to/environment.yml要换成你本地的实际路径
conda env update -f=/path/to/environment.yml
对于不使用 conda 的用户,我通常还会使用 pip freeze > environment.txt 将一个 txt文件导出并包括在其中。
具体见这里:https://pip.pypa.io/en/stable/reference/pip_freeze/
举个例子你可能更容易理解这个使用场景:
首先,我在自己的电脑上在conda中将项目的包导出成environment.txt 文件:


然后我将该文件包含在项目的代码库中,其他项目成员即使在他的电脑上没有安装conda也可以使用该文件来安装和我一样的开发环境:
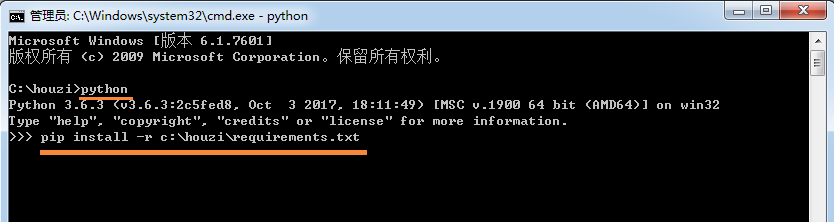
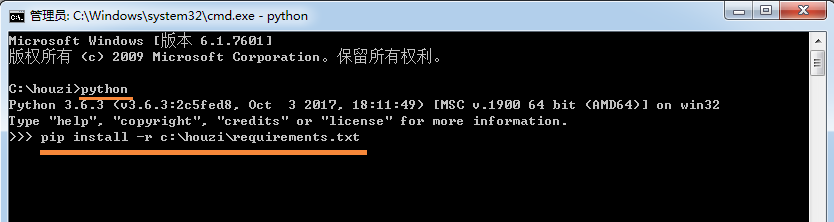
他在自己的电脑上进入python命令环境,然后运行以下命令就可以安装该项目需要的包:
pip install -r /path/requirements.txt
其中/path/requirements.txt是该文件在你电脑上的实际路径。
5)列出环境
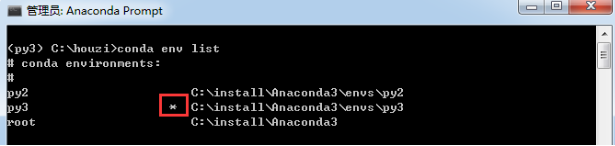
我有时候会忘记自己创建的环境名称,这时候用 conda env list 就可以列出你创建的所有环境。
你会看到环境的列表,而且你当前所在环境的旁边会有一个星号。默认的环境(即当你不在选定环境中时使用的环境)名为 root。
6)删除环境
如果你不再使用某个环境,可以使用 conda env remove -n env_name 删除指定的环境(在这里环境名为 env_name)。
最后重新再强调下,不要被上面的命令吓到。虽然上述命令多,给了谁都记不住的。后面你跟着我在知乎上多做项目,用的多了自然记住了。你只需要跟着上面步骤操作下,并理解了每一步是干什么的就可以了。后面遇到要做的事情,忘记了回头查这个文档就可以了。
conda的官方文档:https://conda.io/docs/user-guide/tasks/index.html
按照上面的步骤你亲自操作一遍后,你已经学会了Anaconda,并安装好你的数据分析Pyhton环境了,接下来你就可以愉快的使用Jupyter notebook来做数据分析了:
其他常见问题,见这里:
猴子:Python管理包工具anaconda安装过程常见问题解决办法链接:https://www.zhihu.com/question/46309360/answer/254638807
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我会从下面4个方面详细聊聊,记得实践每一步,你将不仅了解什么是Jupyter notebook,而且还能轻松使用这个神器。
1.Jupyter notebook 是什么?
2.如何安装 Jupyter notebook?
3.如何启动Jupyter notebook?
4.新手如何快速使用notebook?

1.Jupyter notebook 是什么?
在没有notebook之前,在IT领域工作的我都是这样工作的:
在普通的 Python shell 或者在IDE(集成开发环境)如Pycharm中写代码,然后在word中写文档来说明你的项目。
这个过程很反锁,通常是写完代码,再写文档的时候我还的重头回顾一遍代码。最蛋疼的地方在于,有些数据分析的中间结果,我还的重新跑代码,然后把结果弄到文档里给客户看。
有了notebook之后,我的世界突然美好了许多,因为notebook 可以直接在代码旁写出叙述性文档,而不是另外编写单独的文档。也就是它可以能将代码、文档等这一切集中到一处,让用户一目了然。
例如,我的数据分析社群小伙伴就用Jupyter notebook写出了他的学习笔记,长这样,是不是很酷:

所以,你现在明白了这句话是在说什么了:
Jupyter notebook( http://jupyter.org/) 是一种 Web 应用,能让用户将说明文本、数学方程、代码和可视化内容全部组合到一个易于共享的文档中。

Jupyter Notebook 已迅速成为数据分析,机器学习的必备工具。因为它可以让数据分析师集中精力向用户解释整个分析过程。
Jupyter这个名字是它要服务的三种语言的缩写:Julia,PYThon和R,这个名字与“木星(jupiter)”谐音。
如果看了以上对Jupyter Notebook的介绍你还是拿不定主意究竟是否适合你,那么不要担心,你可以先免安装试用体验一下,戳这里,然后再做决定。(感谢
提供的试用经验)值得注意的是,官方提供的同时试用是有限的,如果你点击链接之后进入的页面如下图所示,那么不要着急,过会儿再试试看吧。
 试用满线
试用满线
如果你足够幸运,那么你将看到如下界面,就可以开始体验啦。
 主界面
主界面
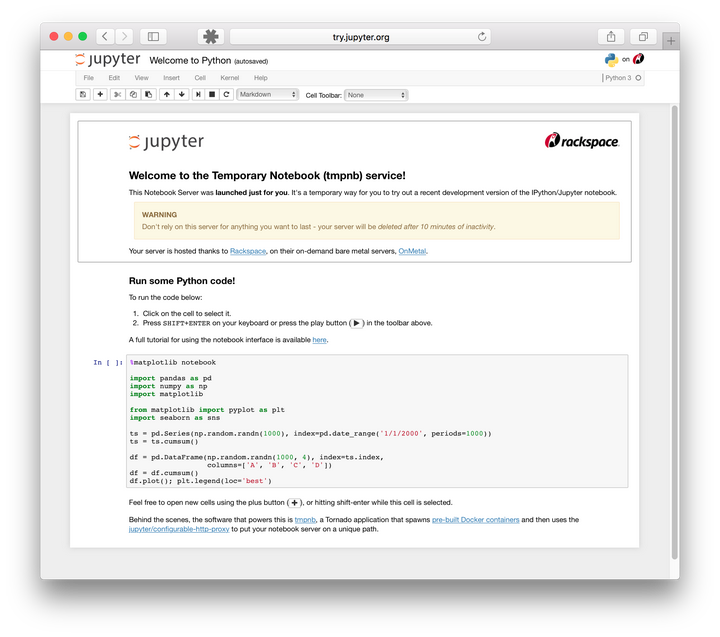
2.如何安装 Jupyter notebook?
对于做数据分析这么有用的神器,不安装使用下是不是很遗憾?
安装 Jupyter 的最简单方法是使用 Anaconda。该发行版附带了 Jupyter notebook。你能够在默认环境下使用 notebook。
确保你已经安装了Anaconda,如果不知道如何安装的,可以看我之前写的:
初学python者自学anaconda的正确姿势是什么??
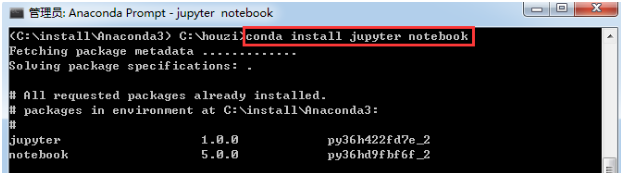
要在 conda 环境中安装 Jupyter notebook,在conda终端使用命令(以下所有命令是指conda的终端Anaconda Prompt):
conda install jupyter notebook
也可以通过python shell的 pip 来安装:pip install jupyter notebook。
3.如何启动Jupyter notebook?
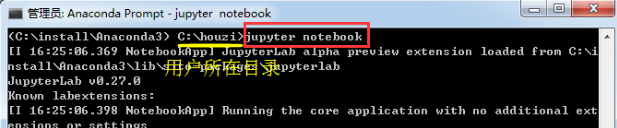
启动 notebook 服务器,在终端中输入: jupyter notebook。
服务器会在你运行此命令的“notebook工作文件夹”中启动。也就是说后面你操作的任何 notebook 文件都会保存在该文件夹下,类似于你用优酷下载视频,优酷都会放到自己的下载目录一样。例如我在下面的C:\houzi 下面启动目录后,会在该目录下看到我后面运行的文件。
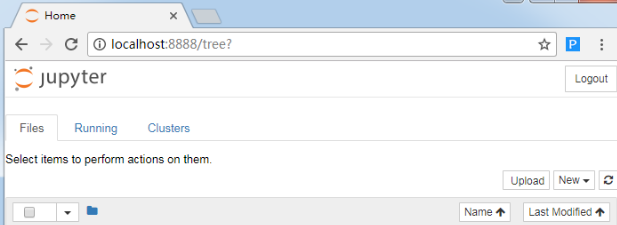
启动notebook 服务器后,在浏览器中打开notebook页面地址:http://localhost:8888
(其中localhost 表示你的计算机,而 8888 是服务器的默认端口)
如果你同时启动了另一个 notebook 服务器,新服务器会尝试使用端口 8888,但由于此端口已被占用,因此新服务器会在端口 8889 上运行。之后,你可以通过 http://localhost:8889 连接到新服务器。以此类推。
如果启动后遇到问题,参考这里的解决方案:
猴子:jupyter notebook常见问题解决办法

4.新手如何快速使用notebook?
1)确保你在Anaconda终端中安装了以下包:
- 安装环境自动关联包
conda install nb_conda
该包可以将conda中创建的环境自动关联到你的notebook中。
我们可以对应conda中的环境,就知道这些环境对应conda中的环境列表。用 conda env list 就可以列出你创建的所有环境。
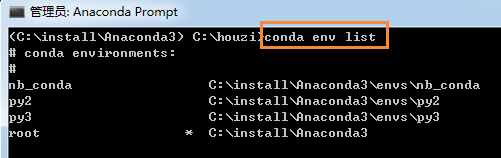
其中py2是我在conda中创建的Python2环境名称,
root和default一样是默认环境,因为我安装的是Anaconda3,所以默认环境是Python3。
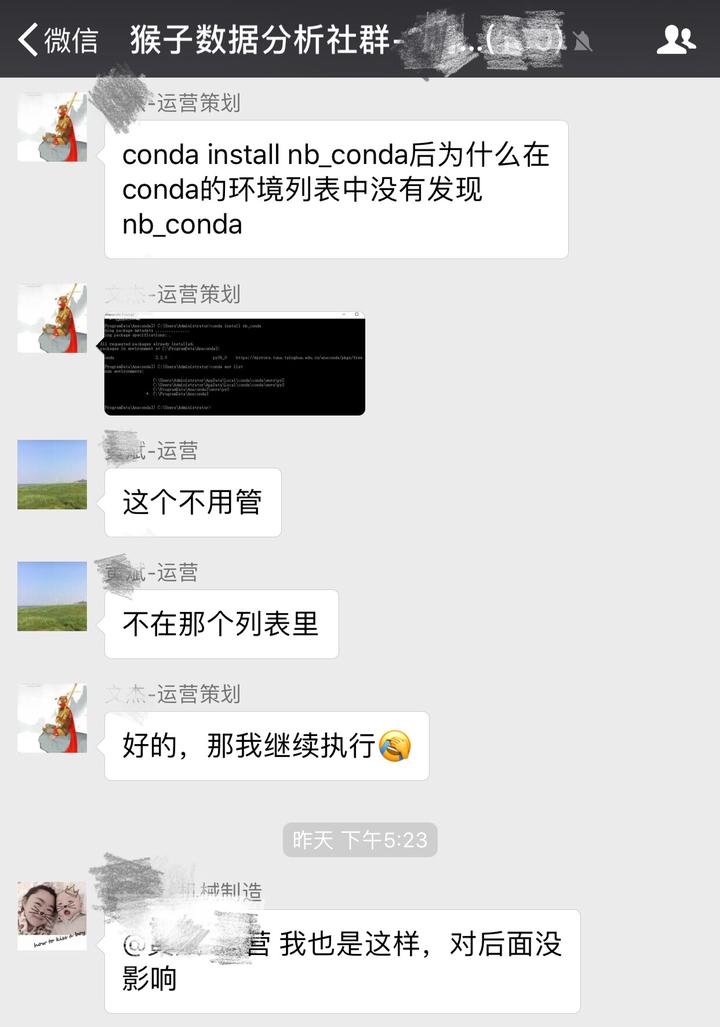
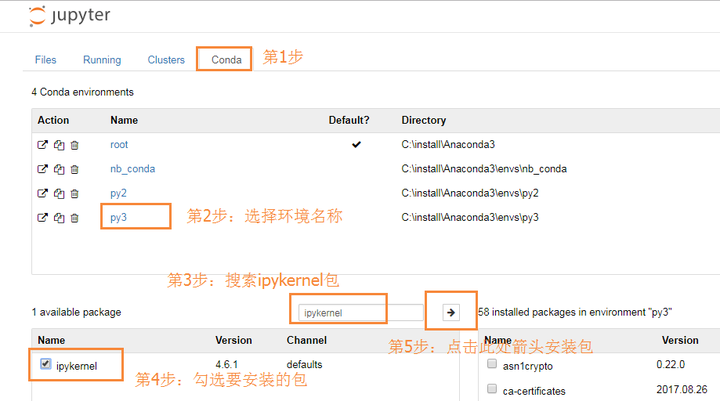
你会发现环境名称py3没有出现在notebook中。解决办法是按下图步骤安装包ipykernel。
(同样的,在你的py2环境下也要像刚才步骤那样安装一次这个包)
完成上面安装步骤,回到标签页“Files”,再新建notebook时,会发现已经关联了环境名称py2和py3:
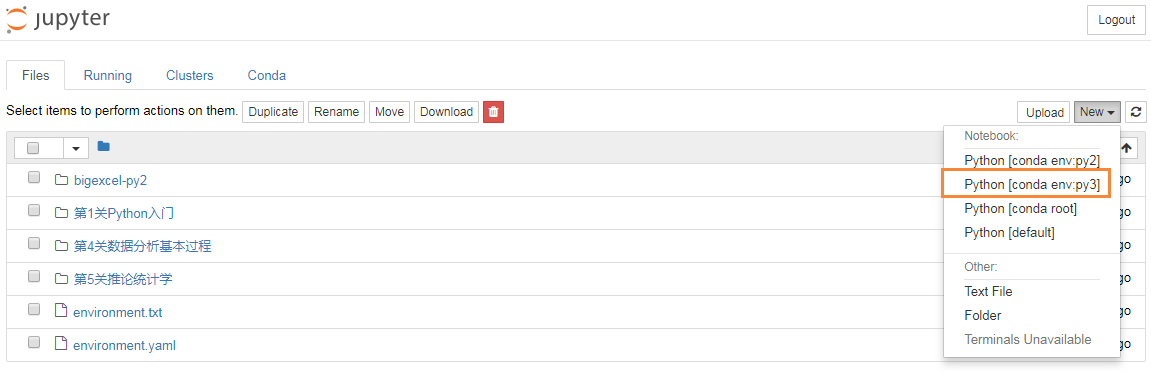
这样你在notebook中可以轻松切换Python2和Python3环境了。
ps:感谢
的经验分享:经过上面步骤后,notebook的首页右上角,在新建的时候没有显示py3和py2两个环境的关联,这个时候,你可以尝试重启浏览器,注意!是重启浏览器,不是notebook!刷新浏览器有时候是没有用滴(因为缓存的原因),而然我刷了两个小时。。。
- 在Anaconda终端安装代码自动补全包
conda install pyreadline
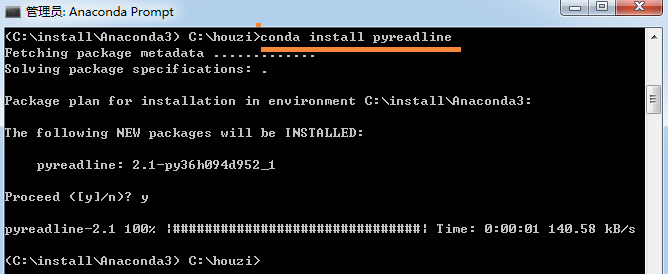
什么是代码自动补全呢?
后面会介绍,您就等好吧。
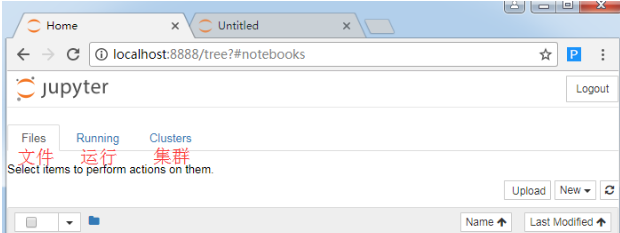
1)顶部的3个选项卡
顶部的3个选项卡是:Files(文件)、Running(运行)和 Cluster(集群)。
Files(文件)显示当前“notebook工作文件夹”中的所有文件和文件夹。
点击 Running(运行)选项卡会列出所有正在运行的 notebook。可以在该选项卡中管理这些 notebook。
Clusters一般不会用到。因为过去在 Clusters(集群)中创建多个用于并行计算的内核。现在,这项工作已经由 ipyparallel 接管。
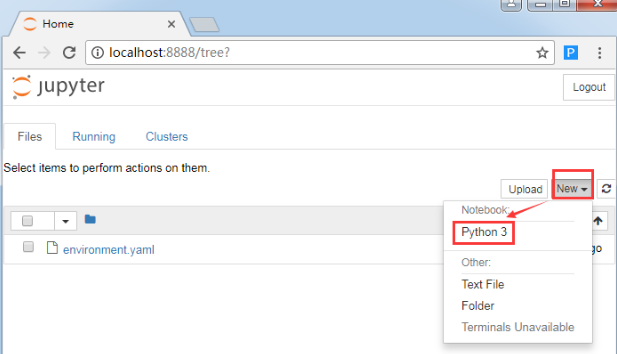
2)如何创建一个新的notebook?
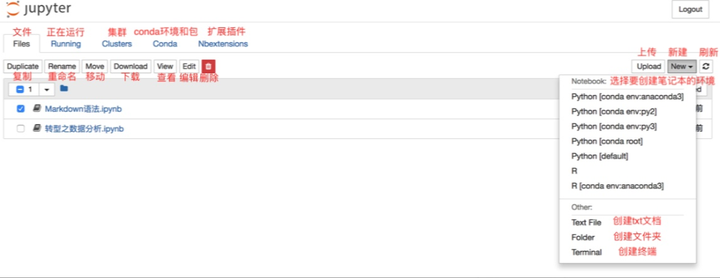
像下面图片中一样,在右侧点击“New”(新建),创建新的 notebook、文本文件、文件夹或终端。
“Notebooks”下的列表显示了你已安装的内核。由于我在 Python 3 环境中运行服务器,因此列出了 Python 3 内核。你在这里看到的可能是 Python 2。这里我点击Python3。
这样你就打开了下面的页面,你会看到外框为绿色的一个小方框。它称为单元格。单元格是你编写和运行代码的地方。以后你就可以在这里写你的数据分析代码了。
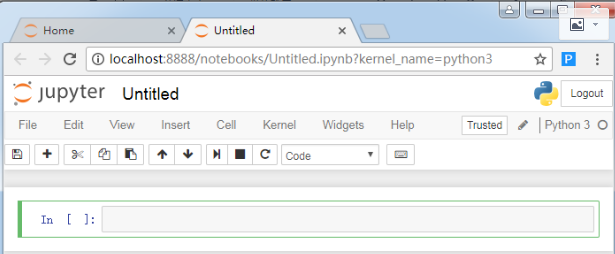
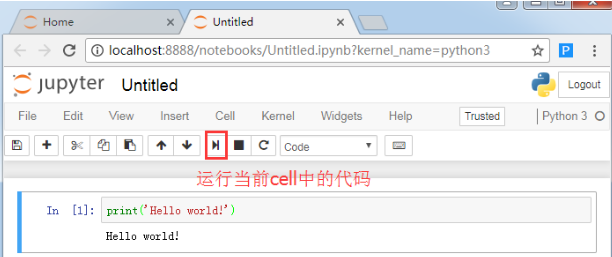
在这里你可以输入自己人生中的第一行Python代码Hello world。然后点击图中的运行按钮,会执行你当前所在的代码,其实我更喜欢用快捷键(键盘上同时按住ctrl+enter键)来执行代码。
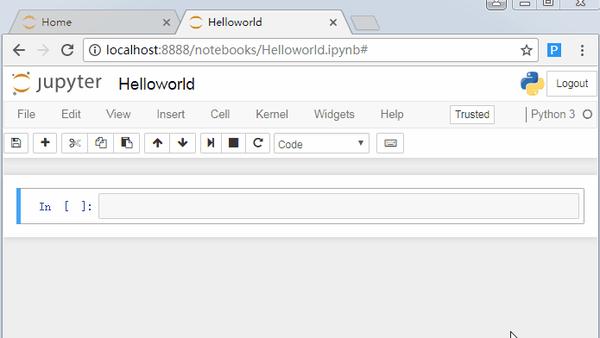
这句代码的意思是在界面输出字符串"Hello world!",所以你会看到在下面与输出结果出来。
运行代码单元格时,单元格下方会显示输出。单元格还会被编号(左侧会显示 In [1]:)。如果运行了多个单元格的话(也就是多块代码),这能让你知道运行的代码和运行顺序。
notebook 中的大部分工作均在代码单元格中完成。这是编写和执行代码的地方。在代码单元格中可以执行多种操作,例如编写代码、给变量赋值、导入包,展示数据分析结果等。在一个单元格中执行的任何代码在所有其他单元格中均可用。
+ 按钮用于创建新的单元格

还记得一开始我提到代码自动补全功能吗?那么,什么是代码自动补全呢?
比如 我定义了下面的变量。

在后面代码中用到这个变量是,我只要输入第一个变量的第一个字母p,然后按下Tab键,边会自动查找到代码中以p开头的变量名称,这可以大幅度提供你写代码的效率。

但是要注意:如果你定义的变量想出现在代码补全里,需要你先把定义该变量的cell运行以后,notebook才能识别它。
当Cell前出现*,表示当前cell程序正在运行,或者它前面的cell正在运行。
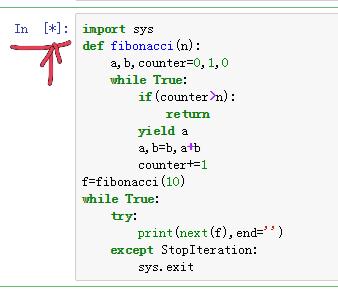
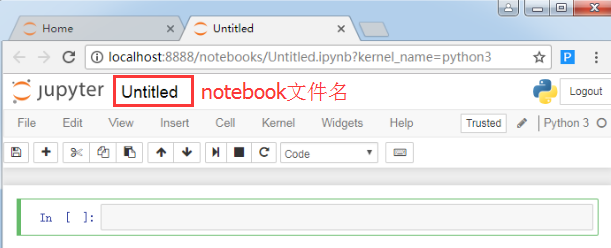
2)重命名notebook
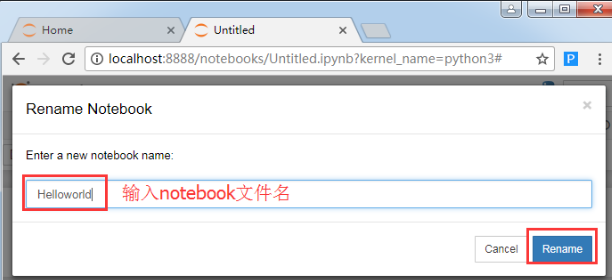
你会看到刚才我建的notebook文件名是下面这样默认的,我想修改成自己喜欢的文件名如何办呢?
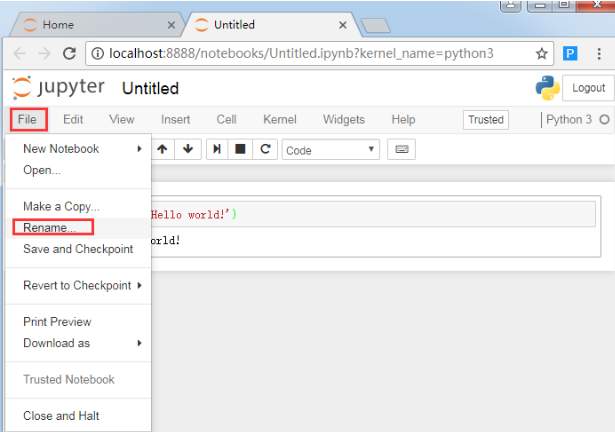
点击“File”->Rename,可以对notebook文件进行重命名,这里我命名成‘Helloworld’
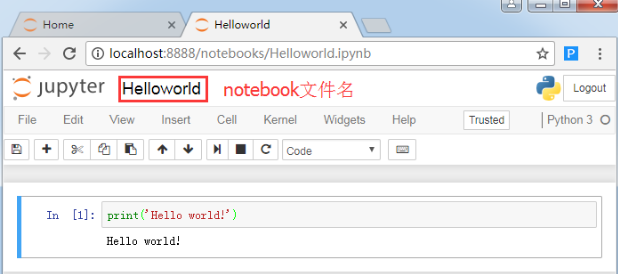
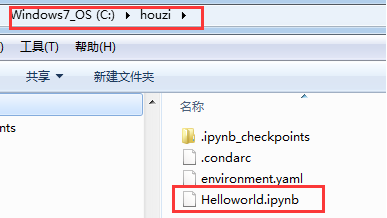
同时,你可以在当前运行notebook服务器的“notebook工作文件夹”下看到创建的notebook,文件名后缀是ipynb。
(其实Notebook 就是个扩展名为 .ipynb 的大型 JSON 文件。)
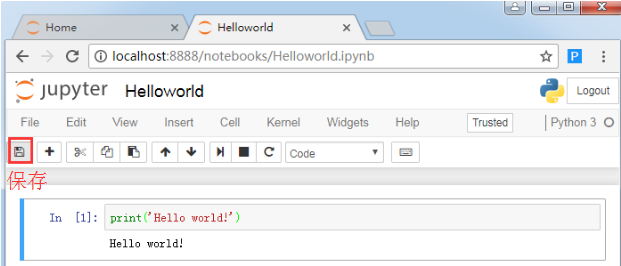
点击下面的保存按钮,可以保存你的notebook文件。但 notebook 也会定期自动保存。
3)重新运行所有单元格里的代码

4)关闭 notebook文件
通过在服务器主页上选中 notebook 旁边的复选框,然后点击“Shutdown”(关闭),你就可以关闭各个 notebook。
但是,在这样做之前,请确保你保存了工作!否则,在你上次保存后所做的任何更改都会丢失。同时如果不保存,你下次运行 notebook 时,你还需要重新运行代码。

5)如何共享你的notebook?
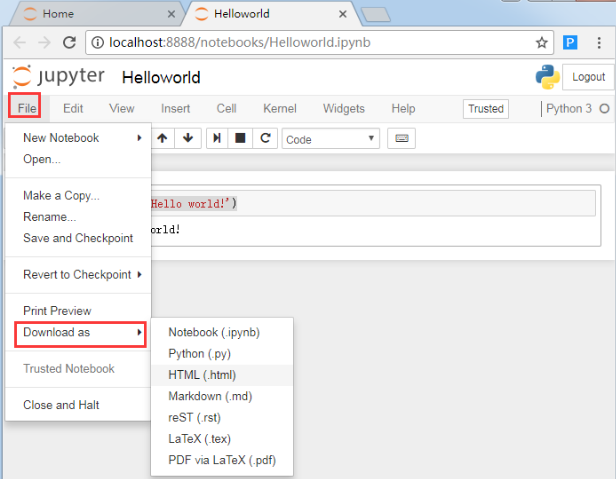
点击File->Download as,你可以选择多种格式下载你的notebook。一般我都会根据下面的用途来选择不同的下载格式:
1)如果我想和客户分享我的数据分析成果,我会选择将notebook下载为HTML文件。
2)如果我希望将自己的数据分析成果和代码嵌入到项目中,比如为药店管理系统做个数据分析子模块,我就会选择Python(.py)模块,这可以将我的代码融入项目中,成为子模块,方便和其他开发人员共同完成任务。
3)如果要在博客或文档中使用 notebook,我就选择Markdown格式。
6)关闭Jupler notebook服务器
通过在终端中按两次 Ctrl + C,可以关闭整个服务器。再次提醒,这会立即关闭所有运行中的 notebook,因此,请确保你保存了工作!
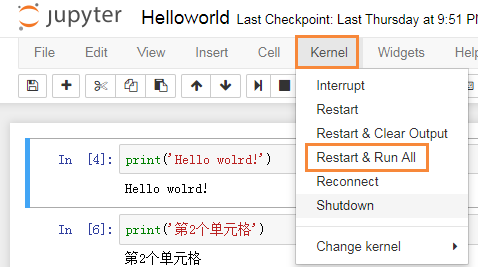
关闭notebook服务器后,下次启动再打开notebook,当你继续在该notebook中写代码时,发现之前的变量无法访问了。需要你在该notebook的Kernerl选项卡中选择“Run All”重新编译下之前的代码。
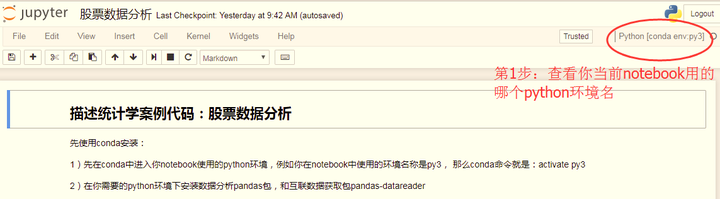
7)安装的包在notebook中不可使用的问题:
是因为安装包的时候,不在当前notebook所在的python环境下安装了包,所以在这个python环境下找不到包。解决办法如下:
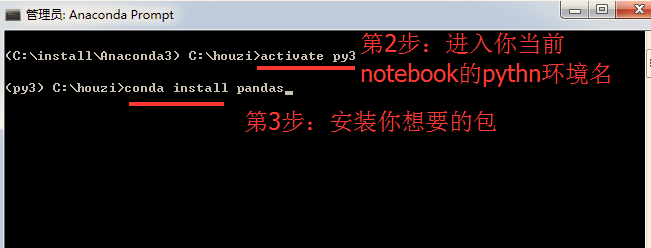
如果你实践了上面的每一步,恭喜你,已经入门学会了 notebook。上面的命令也不需要你记住,只有你后面经常使用notebook,自然就熟练了。想想,你每天说话,会记住每个单词吗?当然不会,用的多了自然在大脑中就形成了记忆,而所谓的新技能学习,无非也是熟能生巧。
后期可以进一步学习Python:
零基础掌握人工智能(AI)核心语言:Python