1.一级指标
TP:True Positive(真阳性)
FP:False Positive(假阳性)
TN:True Negative(假阴性)
FN:False Negative(假阴性)
2.二级指标
准确率
a
c
c
u
r
a
c
y
=
T
P
+
T
N
样本总数
accuracy = \frac{TP+TN}{样本总数}
accuracy=样本总数TP+TN
精确率
p
r
i
c
i
s
e
=
T
P
T
P
+
F
P
pricise=\frac{TP}{TP+FP}
pricise=TP+FPTP
召回率/灵敏度
r
e
c
a
l
l
/
s
e
n
s
i
t
i
v
i
t
y
=
T
P
T
P
+
F
N
recall / sensitivity = \frac{TP}{TP+FN}
recall/sensitivity=TP+FNTP
3.三级指标
F1 score
F 1 s c o r e = 1 F 1 = 2 1 p r i c i s e + 1 r e c a l l = 2 ∗ p r i c i s e ∗ r e c a l l p r i c i s e + r e c a l l F1 score = \frac{1}{F1}= \frac{2}{\frac{1}{pricise}+\frac{1}{recall}} = \frac{2*pricise*recall}{pricise+recall} F1score=F11=pricise1+recall12=pricise+recall2∗pricise∗recall
3.理解一级指标
-
其中的Positive和Negative表示模型预测的结果,即模型预测为正样本或者为负样本。其中的Ture和false表示真实的结果,即通过标签矫正后判断模型当前预测的结果是正确的还是错误的。
- TP:模型预测为正类,通过标签判断后发现确实是这个类,所以这个是好的。
- FP:模型预测的是正类,通过标签判断后发现模型预测的结果不对,应该是一个负类。本次模型预测的结果就是不对的。
- TN:模型预测的是负类,通过标签判断后发现确实是这个类,这个也是好的。
- FN:模型预测的是负类,通过标签判断后发现模型预测的结果不对,应该是一个正类。本次模型预测的结果就是不对的。
-
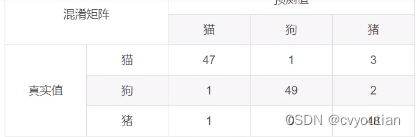
关于多分类的问题的评价基准:在描绘多分类的混淆矩阵的时候,我门可以将当前的目标类别作为positive,其他的类别作为negative。假如在猫狗猪三分类任务中,猫的测试图片51, 狗的测试图片52,猪的测试图片49。结果如下图:
在上图中,我们发现猫的图片为51张,模型识别正确的是47张,这47张我们将其认为是positive, 模型识别成其他类别的有4张,我们将这四张作为negative。这样来计算得到混淆矩阵(如上图对角线位置为识别正确的)
4.理解二级指标
- 准确率:这个概念是模型的一个总的评价指标,就是说模型预测正确的占所有样本的比例。
- 精确率:精确率也叫某一类别的查准率,希望在某一类别中判断的足够准确,当讨论精确率的时候我门通常只针对模型预测的某一个类别的精确率来讨论。比如上述的3分类问题 ,猫的精确率就是指模型所有预测中,预测为positive(预测为猫)的数量中预测正确(为True)的比例是多少。以下是结果。
p r i c i s e c a t = 47 47 + 2 ≈ 95.92 % pricise_{cat} = \frac{47}{47+2}\approx 95.92\% pricisecat=47+247≈95.92% - 召回率/灵敏度:召回率也叫查全率,希望模型的分类全面多样,在三分类的猫的召回率为:
r e c a l l c a t = 47 47 + 1 + 3 ≈ 92.16 % recall_{cat} = \frac{47}{47+1+3}\approx 92.16\% recallcat=47+1+347≈92.16%
5.理解三级指标
F1score:利用上面的Pricise和Recall进行计算。取值范围是0~1, 越接近1越好。
参考资料
[1]. 混淆矩阵 TP TN FP FN 正确率 精准率 召回率
[2]. 分类结果分析指标和方法
[3]. 分类结果分析指标和方法(混淆矩阵、TP、TN、FP、FN、精确率、召回率(带代码)