
连玉君 (中山大学岭南学院金融系)
Stata连享会 主页 || 视频 || 推文

连享会-知乎推文列表
Note: 助教招聘信息请进入「课程主页」查看。
因果推断-内生性 专题 ⌚ 2020.11.12-15 主讲:王存同 (中央财经大学);司继春(上海对外经贸大学) 课程主页: https://gitee.com/arlionn/YG | 微信版
http://qr32.cn/BlTL43 (二维码自动识别)
空间计量 专题 ⌚ 2020.12.10-13 主讲:杨海生 (中山大学);范巧 (兰州大学) 课程主页: https://gitee.com/arlionn/SP | 微信版
https://gitee.com/arlionn/DSGE (二维码自动识别)
2018.4.11更新:该文已发表
连玉君, 廖俊平, 2017, 如何检验分组回归后的组间系数差异?, 郑州航空工业管理学院学报 35, 97-109. [PDF 原文下载] [PDF-万方]
2020.4.19 更新:[本文最新版]
问题:实证分析中,经常需要对比分析两个子样本组的系数是否存在差异。
例如,在公司金融领域,研究薪酬激励是否有助于提升业绩时,模型设定为:![]()
关注的重点是系数。
我们经常把样本组分成“国有企业(SOE)”和“民营企业(PRI)”两个样本组,继而比较和
是否存在差异。通常认为,民营企业的薪酬激励更有效果,即
。
如果两个样本组中的模型设定是相同的,则两组之间的系数大小是可以比较的,而且这种比较在多数实证分析中都是非常必要的。
举几个例子,让诸位对这类问题有点感觉:
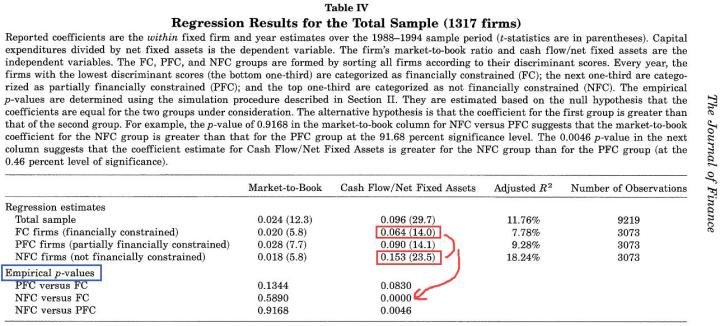
Cleary, S., 1999, The relationship between firm investment and financial status, Journal of Finance, 54 (2): 673-692. Tabel IV
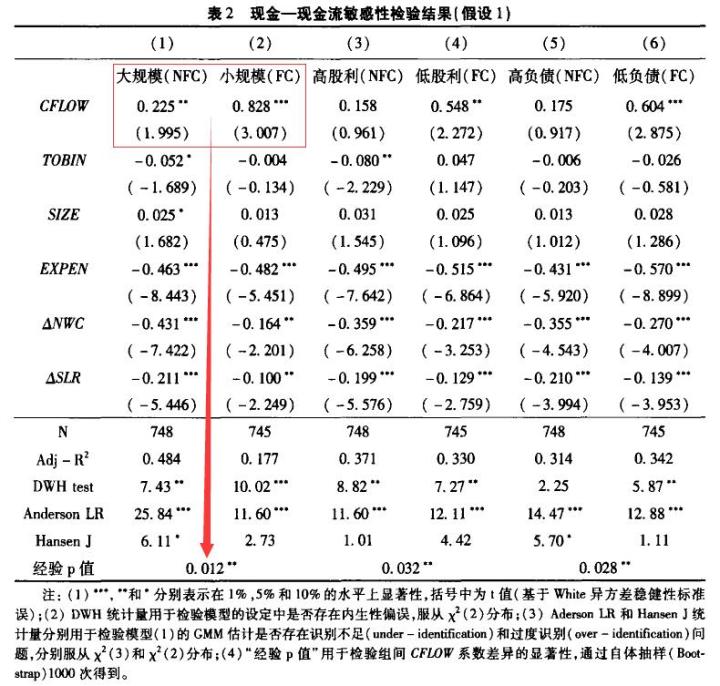
连玉君, 彭方平, 苏治, 2010, 融资约束与流动性管理行为, 金融研究, (10): 158-171. 表2.
问题背景:
下面使用我在stata初级班讲座(http://www.peixun.net/view/307_detail.html;连玉君课程_视频在线学习 - 讲师介绍 - Peixun.net - Peixun.net)中的例子,列举几种方法。
调入 stata 自带的数据集 nlsw88.dta。
这份数据包含了1988年采集的 2246 个妇女的资料,包括:小时工资 wage,每周工作时数 hours, 种族 race 等变量。
我们想研究的是妇女的工资决定因素。
最为关注的是白人和黑人(相当于把原始数据分成了两个样本组:白人组和黑人组)的工资决定因素是否存在差异。
分析的重点集中于工龄(ttl_exp)和婚姻状况(married) 这两个变量的系数在两组之间是否存在显著差异。
下面是分组执行 OLS 回归的命令和结果:
sysuse "nlsw88.dta", clear
gen agesq = age*age
*-分组虚拟变量
drop if race==3
gen black = 2.race
tab black
*-删除缺漏值
global xx "ttl_exp married south hours tenure age* i.industry"
reg wage $xx i.race
keep if e(sample)
*-分组回归
global xx "ttl_exp married south hours tenure age* i.industry"
reg wage $xx if black==0
est store White
reg wage $xx if black==1
est store Black
*-结果对比
local m "White Black"
esttab `m', mtitle(`m') b(%6.3f) nogap drop(*.industry) ///
s(N r2_a) star(* 0.1 ** 0.05 *** 0.01) 结果:
------------------Table 1-------------------
(1) (2)
White Black
--------------------------------------------
ttl_exp 0.251*** 0.269***
(6.47) (4.77)
married -0.737** 0.091
(-2.31) (0.23)
south -0.813*** -2.041***
(-2.71) (-4.92)
hours 0.051*** 0.037
(3.81) (1.39)
tenure 0.025 -0.004
(0.77) (-0.09)
age 0.042 0.995
(0.03) (0.54)
agesq -0.001 -0.015
(-0.09) (-0.66)
_cons 3.333 -14.098
(0.14) (-0.39)
--------------------------------------------
N 1615.000 572.000
r2_a 0.112 0.165
--------------------------------------------
t statistics in parentheses
* p<0.1, ** p<0.05, *** p<0.01可以看到,ttl_exp 变量在 [white 组] 和 [black 组] 的系数分别为 0.251 和 0.269, 二者都在 1% 水平上显著异于零。
问题在于:我们能说 0.269 比 0.251 大吗?
从统计意义上来看,答案显然没有那么明确(小学五年级的小朋友会觉得这根本不是个问题!)。
相对而言,若把注意力放在 married 这个变量上,或许更容易判断二者的差异是否显著。因为,_b[married]_white (白人组的 married 估计系数) 为 -0.737**,而 _b[married]_black 为 0.091 —— 前者在 5% 水平上显著为负,而后者不显著。
即便如此,我们仍然无法直接作出结论:_b[married]_white < _b[married]_black,因为二者的置信区间尚有重叠:
*----------------------------------------
* White Black
*----------------------------------------
* ttl_exp
*---------
* beta 0.251*** 0.269***
* 95% CI [0.17, 0.33] [0.16, 0.38]
*----------------------------------------
* married
*---------
* beta -0.737** 0.091
* 95% CI [-1.36, -0.11] [-0.69, 0.87]
*----------------------------------------下面我们介绍三种检验组间系数差异的方法:
- 方法1:引入交叉项(Chow 检验)
- 方法2:基于似无相关模型的检验方法 (suest)
- 方法3:费舍尔组合检验(Permutation test)
连享会 最新专题 直播
方法 1: 引入交叉项
这是文献中最常用的方法,执行起来也最简单。以检验 ttl_exp 在两组之间的系数是否存在显著差异为例。引入一个虚拟变量
这是最基本的包含虚拟变量,以及虚拟变量与一个连续变量交乘项的情形。
显然,对于白人组而言,
对于黑人组, (1) 式可以写为:
由此可见,在 (1) 式中,参数
dropvars ttl_x_black marr_x_black
global xx "ttl_exp married south hours tenure age* i.ind