论文介绍和监督学习(introduction of paper and supervision of learning)
1. 论文介绍和作者介绍
作者:论文作者是2018年图灵奖得主yoshua Bengio, Geoffrey Hinton, Yann LeCun
发表及时间:nature, 2015
2018年度ACM A.M 图灵奖颁给了 yoshua Bengio, Geoffrey Hinton, Yann LeCun,以表彰他们提出的概念和工作使得深度学习社神经网络有了重大突破,如今神经网络已经成为计算机领域的重要组成部分。
Geoffrey Hinton
谷歌副总裁兼工程研究员
vector institute 的首席科学顾问
多伦多大学的名誉教授
重要贡献:
1986年发表反向传播论文“Learning internal Representations by Error Propagation”
1983 年发明波尔兹曼机(Boltzmann Machines)
2012年对卷积神经网络进行改进,并在著名的ImageNet测评中获得了很好的成绩
Yann LeCun
纽约大学教授
Facebook副总裁和首席人工智能科学家
重要贡献
1980年代,LeCun 发明了神经网络
1980年代末期,yan LeCun在多伦多大学和贝尔实验室工作期间,首先将卷积神经网络应用于手写数字识别。
Yoshua Bengio
蒙特利尔大学教授
魁北克人工智能研究所Mila科学主任
著作《深度学习》花书的作者之一
重要贡献:
1990年发表probabilistic models of sequences, 将神经网络和概率模型结合在一起
2000发表划时代论文“A Neural probabilistic Language Model”,使用高纬词向量来表征自然语言
2.论文意义和主要内容
人工智能领域的三位泰斗,总览深度学习理论,模型!展开人工智能壮丽画卷,把握深度学习的前世今生,探究深度学习中最重要的算法和理论。
概念:深度学习允许由多个处理层组成的计算模型来学习具有多个抽象级别的数据表示,这些方法极大的改善了语言识别,视觉对象识别,物体检测以及药物发现和基因组学等许多其他领域的新技术。
原理:深度学习通过使用反向传播算法来指示机器应该如何更改其内部参数(用于从前一层中的表示计算每一个层中的表示)来发现大数据集中的复杂结构。
应用:深度卷积网络CNN在处理图像,视频,语音和音频等方面带来了突破,而循环神经网络则对文本和语音等顺序数据进行了彰显。
论文结构
1.引言
深度学习是具有多级表示的方法,通过组个非线性的模块来获得。每个模块将表示一个级别,从原始的输入开始转换为更高的表示,稍微更多的抽象层次能够足够的组合这种变换,可以学习非常复杂的功能。
用深度学习的方式来找到一个函数,这个函数能学习,最终表示非常复杂的功能,例如:语音识别,图像识别。
多层神经网络的结构
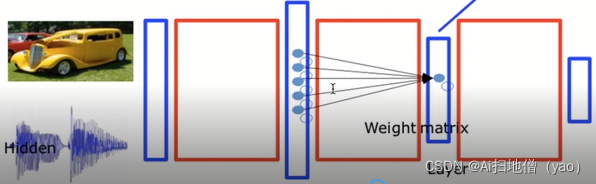
特点:
多层神经元组成
前一层神经元的输入是每一层神经元的输入,每一级互相进行联动。
输入的是一个非线性的函数(激活函数) 一般使用RELU可以避免神经网络中的梯度弥散和梯度消失。
AI可以看懂世界: 无人驾驶领域:车辆识别,路径规划;图片识别领域:图片表示,语义分割。
智能搜索,人机对话,文本摘要,机器翻译;医学图像分析,自动驾驶,制药,人脸识别,机器翻
译,虚拟助理,游戏,安全,异常检测,分析预测。人脸识别,黑白图像上色,下围棋,目标检测
自动驾驶。
t2.监督学习
我们需要计算一个目标函数来测量出分数,和所需分数之间的误差(距离),机器修改其内部的参数减少错误,(BP)就是反向传播的过程,这些可调的参数我们称为权重,是实数,可以看作是定义机器输入与输出功能的旋钮。在典型的机器学习系统中,可能存在数以亿计的可调节旋钮,以及可以训练机器数以亿计训练的事例。
我们知道真正的答案,我们也有数据,要去寻找数据与真正答案之间的规律,这个过程就相当于调节旋钮一样,调节这些参数用的方法是BP方向传播算法。
反向传播是指用了梯度下降的算法。梯度下降就是不断的用梯度对参数进行微调,直到找到相应的位置。
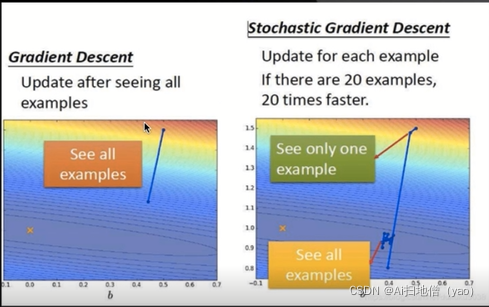
假设在大山中的某一步,做法是走一步看一步,沿着梯度的负方向也就是最陡峭的方向向下走一步,然后继续求解当前梯度的位置,最后一步一步走下去就到了山脚。
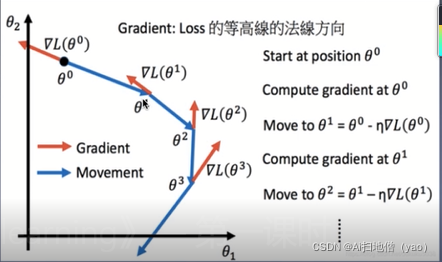

在求参数的时候可以百万个参数一起梯度下降去计算。
梯度下降是十分重要的,在深度学习领域几乎所有的算法的求最小值都用到了梯度下降的算法。
损失函数
![L = \sum_{n}^{}\left [ y^{n}-\left ( b+\sum w_{i}x_{i}^{n} \right ) \right ]^{2}](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9ibG9nX21pZ3JhdGUvYjI4OTgyN2QyMjMzYTczZDIzYzBkMGM0YWEyOTU2ODcuZ2lm)
Loss is the summation over all training examples.
Gradient Descent
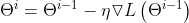
pick an example
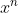
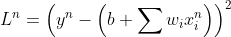
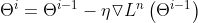
梯度下降不一定求得全局最优解,可能是局部最优解。
3.反向传播算法
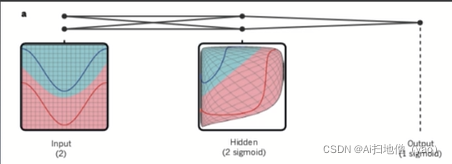
多层神经网络,仅具有两个输入单元,两个隐层单元的说明实例,用于对象识别网络,自然语言处理,包含数十万个神经单元。
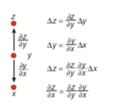
链式规则:如何组成两个小的影响,即X对Y的变化,以及Y对Z的变化之间的联系。
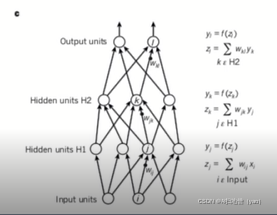
计算两个隐藏层和一个输出层神经网络的前向通道的等式,正向传播从输入到输出的正向传播。
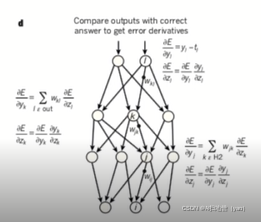
用于计算后向传播的方程式也就是反向传播,在每个隐藏层计算每个单元输出的误差导数,从最开始(输入层)的误差导数开始算起。将相对于误差的导数转换为输入误差的导数,方法为乘以函数的梯度,在输出层对成本函数的微分计算对输出误差的导数。
单位一的成本函数0.5,则给出Y1-t1,误差是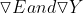
链式法则:
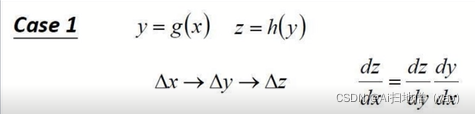
就是X的微小变化影响到Y的微小变化,Y的微小变化影响到Z的微小变化

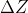
前向传递和反向传递的过程:
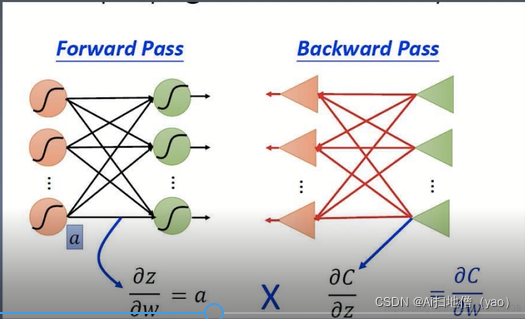
前向传播就是从前往后的过程(计算),反向传播就是从后往前的过程(误差传递),误差传递的过程也就是学习的过程,通过反向传播的过程达到学习的目的。
4.卷积神经网络
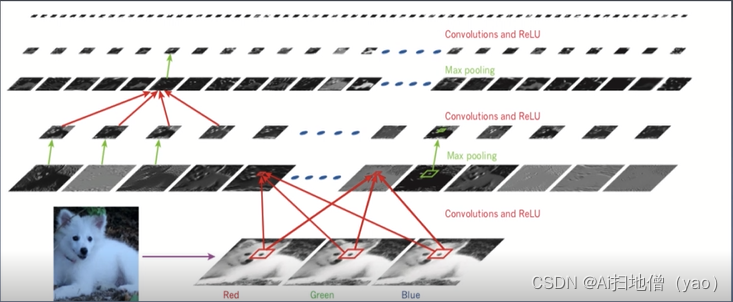
该图是典型的神经网络的架构,应用于萨摩耶犬的图像识别,每一个矩形的图像是在每一个图像的位置处检测到一个学习的特征的输出进行对应特征图的表示,信息从下而上的流动,较低级别的特征充当边缘的检测器,并输出每一个图像类别的计算分数,萨摩耶的图像有RGB三个图片组成,它们通过不同的层来进行特征的提取,逐层的进行信息传递,最终识别出图片到底是萨摩耶还是狼狗。
究竟什么是CNN?
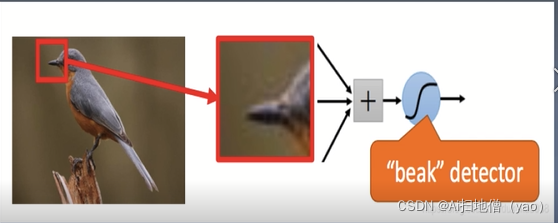
一个神经元无法看到整张图片。
能够联系到小的区域,并且参数更少
图片压缩像素不改变图片内容是卷积神经网络的特征。
整个神经网络的过程
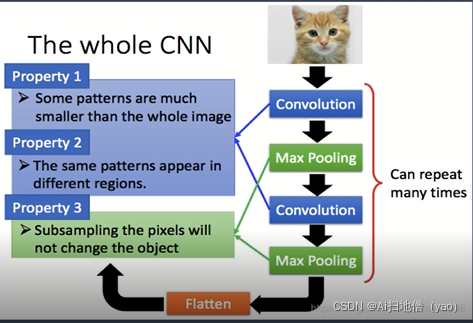
整个过程分为四部分,第一部分的数据预处理用于卷积的计算,加上偏置得到局部的特征
其卷积核的尺度以及个数对模型的效果有一定影响,第二将前面卷积的结果通过非线性激活函数的
处理,目前常用的激活函数是Relu激活函数,第三激活函数对结果进行池化操作,池化操作就是取
区域的平均值或者最大值保证其显著的特征,来提升对激变的容忍能力,第四全链接层,进行输
出,表示对结果的输出和确认。
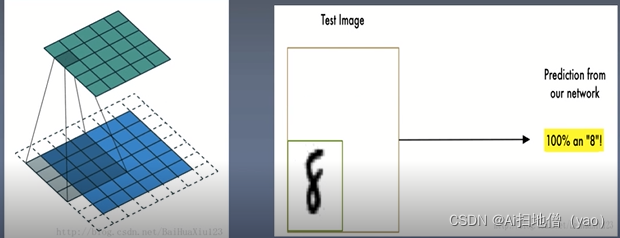
手写数字识别过程,卷积神经网络就是用卷积核在不断扫描这张图片中相关的内容,真正扫描到它感兴趣的内容之后会输出一个结果,CNN对图片的重点区域进行循环扫描最终得到一个结果。
CNN到底牛在哪里?
CNN减少了参数
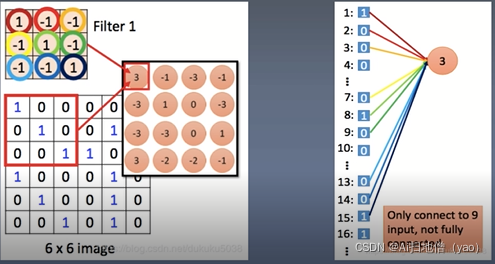
一般来讲单层神经网络可以表示任何的函数,数学上已经在2017年进行证明。为什么不用全链接的神经网络而去使用卷积神经网络,原因就在于卷积神经网络CNN能够大量的减少参数,提高效率,降低计算复杂度,在上图所示中卷积神经网络对矩阵进行运算,将6*6的图片拆成全连接网络的时候可以极大的降低全连接层参数的数量。
5.基于深度卷积神经网络的图片理解
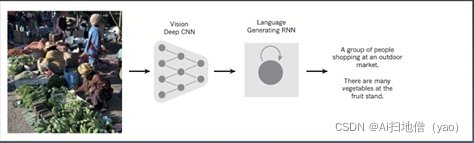
CNN是提取图片的信息,通过RNN进行训练,将图片的高级表示翻译成字幕,RNN有能力集中输入图像的不同的位置来生成单词。
j

看图写话。所以说卷积神经网络能够看懂图像的特征,然后输入到RNN最终生成一个单词,或者一段话。
6.分布表示和语言模型
word Embedding(词向量)

词向量:现有的机器学习方法往往无法直接处理文本数据,因此需要找到一个合适的方法将文本数据转换成数值数据,其过程就是将文本空间的某个word通过一定的方法映射或者是嵌入到另一个数值的向量空间。
传统的word是 1 of Embedding,在词典中词的位置表示词的含义,但是仅表示词的特殊的位置,并不代表词真正的意思。Word Embedding就可以进行词的向量空间的映射,在向量空间中离得比较近的词其意思是比较接近的,比如说run,jump都有跳的意思,dog,rabbit,cat都是动物的意思所以说Word embedding可以准确的表示词的含义。而且1 of Embedding词典的个数是比较多的,个数可能有几万或者几十万,它的维度也可能在几万到几十万,但word embedding就可能到300-500维。
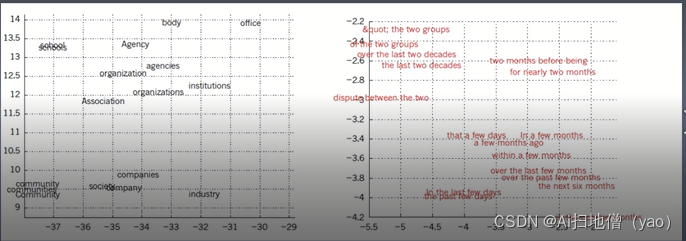
机器可以通过阅读大量的文档来获取词的意思,这就是word embedding的过程。一个词汇也可以被上下文所理解,左图使用建模语言的单词表示,人们可以观察到语义相近的单词,通过反向传播算法,能获得单词意思的表示,句子也可以embedding的表示,两个句子如果意思差不多,通过上下句进行sentence embedding,这都是embedding的过程。
word embedding具体的算法word2vec算法
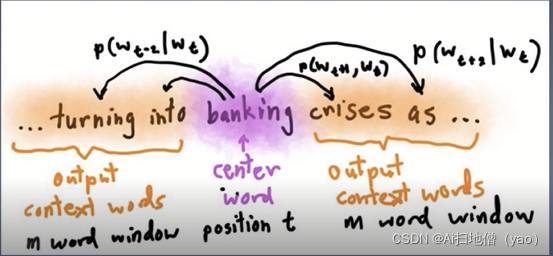
word2vec的一个算法Skip-Gram,就是给定input来预测上下文,例如给定banking来预测上下文,上下文词的个数都是M,就会得到两组数据,一组是input word,另一组是output word来进行不断的训练,最后得到word embedding的向量,该算法于2013年提出。
7.循环神经网络
RNN
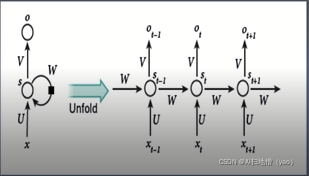
循环神经网络难理解,概念的特点RNN在每个时间点连接参数值,参数只有一份。
神经网络除了输出以外,还会建立在以前的“记忆”的基础上
内存的要求与输入的规模有关。(抽闲)
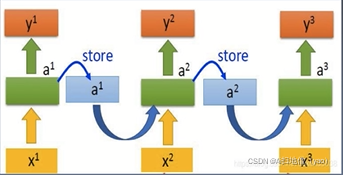
RNN就是普通的神经网络,但是它也有输入层,隐藏层和输出层,不同之处在于它是时间序列,的,它的输入随着不同的时间点进行变换,它的隐藏层会保存以前的输入隐藏层的数据,它会随着时间进行变化调整,参数是仅有一份,RNN可以理解为带有存储功能的神经网络。RNN可以记忆以前的事迹,所以循环的过程对时间序列预测事情比较容易产生好的结果。
LSTM(Long Short-term Memory)长短记忆神经网络
LSTM是一个较难理解的网络结构,有4个输入(3个Gate),1个输出

是一种特殊RNN,也是门限RNN,主要用于解决长序列训练过程中梯度消失和梯度爆炸的问题,简单说比普通RNN具有更好的表现,LSTM可以处理长序列,能够记忆更多以前的隐藏层的数据还有中间结果。它有forget gate(遗忘门)input gate(输入门)output gate(输出门),对这些门都进行限制来保障到底需要什么数据,需要丢弃什么数据,进行选择,实际上也是一种RNN。
8.深度学习的未来(future)
非监督学习

理解发生的事情最简单的做法就是测试,例如在学校参加考试,有问题就有答案,但是要是没有答案该如评价,这就是非监督学习。一般讲AI的发展,deep learning的发展在监督学习的基础上,但是近几年突破性的进展比如说对抗网络,都是用非监督学习的方法来做,大量的数据是没有标记,让机器自己去寻找规律并不是人来指导。
强化学习
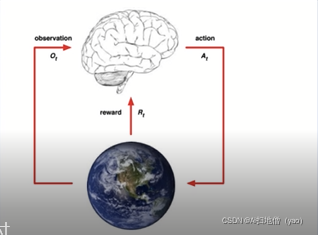
强化学习并不需要出现正确的输入、标签对的数据,它更加专注于在线规划,需要在探索(未知领域)和遵循(现有知识)之间找到平衡,其学习过程是智能体不断的和环境进行交互,不断进行试错的反复练习过程。
强化学习不同于监督学习在于其中没有监督者,只有一个奖励信号(reward),并且反馈是延迟的,不是立即生成的,因此时间(序列)在强化学习中具有重要的意义。
强化学习是阿尔法go的基础算法。
GAN(生成对抗网络)
generative adversarial network
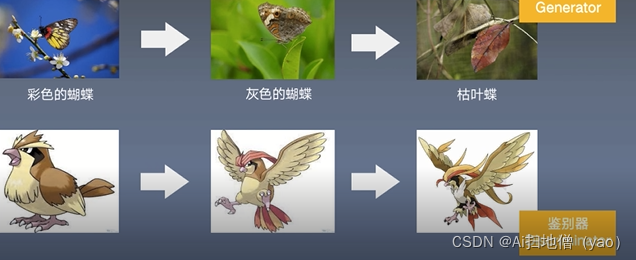
GAN核心思想来自于博弈论,和纳什均衡,规定参与游戏的双方有一个生成器(generator)有一个鉴别器(DIscriminator)生成器是尽量去学习真实的数据分布,而判别器就是去判读数据是否来源于真实的数据分布,为了取得游戏的胜利,两个游戏的参与者要不断优化来提升自己的生存能力和判别能力,这个学习优化的过程就是寻找二者之间的纳什均衡,GAN的流程图如图所示,彩色的蝴蝶很有可能被吃掉,所以它会进化变成灰色,而鸟会发现越来越难以发现食物,它就会去进化出发达的视力,它能看到灰色的蝴蝶,灰色的蝴蝶就会进化成枯叶蝶,鸟进化成鹰。
GAN被称为近十年来最重要的算法核心思想之一。在2014年提出,最近发展特别快。
自监督学习(self supervised learning)

一切都在预测,现在预测未来,部分预测整体,未来预测现在。用现在的数据预测未来的数据,用部分的数据预测整体的数据,未来的数据反过来预测现在的数据,不断的调整预测系统的参数,如此准确性会大大提高,2018年底的bert模型也是由于自监督学习的过程不断提升达到了NLP的里程碑。
3.前期准备知识
机器学习:了解基本的机器学习算法 (BP,反向传播算法,预测,线性回归 分类 逻辑回归)
RNN:了解循环神经网络(RNN)的结构,掌握RNN的基本工作原理
CNN:了解卷积神经网络的结构和工作原理
4.学习准备
泛读论文,阅读标注重点
精度论文,写分析笔记
精读经典论文->跟进最新论文->整理关注论文->复现领域论文->写作论文