
摘要
大型预训练语言模型已被证明可以在其参数中编码大量的世界知识和常识性知识,这导致了对提取这些知识的方法的极大兴趣。在过去的工作中,知识是通过手动编写查询并使用单独的管道为它们收集释义来提取的。在这项工作中,我们提出一个方法来自动重写查询到“BERTese”,改写查询,直接向更好的优化知识提取。为了鼓励有意义的重写,我们添加了辅助损失函数,以鼓励查询对应于实际的语言标记。我们的经验表明,我们的方法优于竞争基线,避免了复杂管道的需要。此外,BERTese对语言类型提供了一些见解,帮助语言模型执行知识提取。
1 引言
最近的研究表明,用掩模语言建模(MLM)目标训练的大型预训练语言模型(LM) (Devlin等人,2019;Liu et al ., 2019;Lan等人,2019;Sanh等人,2019;Conneau等人,2020)在其参数中编码了大量的世界知识。
这导致了对开发提取这些知识的方法的大量研究(Petroni等人,2019,2020;Jiang等,2020;Bouraoui et al, 2020)。最直接的方法是向模型提供一个手工制作的查询,如“Dante was born in [MASK]”,并检查模型是否预测“Florence”在[MASK]位置。然而,当这种方法失败时,很难确定LM中是否缺少知识,或者模型是否未能理解查询本身。例如,如果查询是“Dante was born in the city of [MASK]”,模型可能会返回正确的答案。
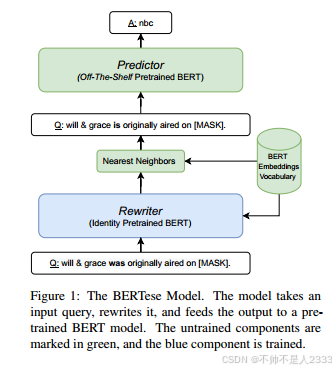
在上述观察的激励下,我们问:我们能自动找到“询问”LM知识的最佳方式吗?我们把这种挑战称为说“BERTese”。特别是,我们询问如何将寻求知识的查询重写为传销更好理解的查询,其中理解通过提供查询的正确答案来体现。之前的工作(Jiang et al, 2020)使用两步管道解决了这个问题,首先使用外部资源收集释义模板的小列表,然后模型通过从输入查询的释义中聚合信息来学习提取知识。在这项工作中,我们提出了一种更通用的方法,其中模型学习重写查询,直接由知识提取的目标驱动。图1概述了我们的方法。我们的模型包含一个基于bert的重写器,它将查询作为输入,并为每个输入位置输出一个新标记,这是它的重写。这个新查询被输入到另一个BERT预测器中,从中提取答案。重要的是,下游预测器BERT是一个固定的预训练模型,因此目标是训练重写器生成查询,从而预测器输出正确的答案。
一个技术挑战是输出离散令牌会导致不可微模型,我们通过添加一个损失项来解决这个问题,该损失项鼓励重写器的输出类似于BERT令牌嵌入。此外,我们必须保证BERTese查询包含将从中读取答案的[MASK]令牌。为了实现这一点,我们首先添加一个辅助损失项,以鼓励模型在查询重写中精确输出一个屏蔽令牌。然后,我们添加一个层来查找与[MASK]最相似的令牌索引,这就是我们期望完成正确答案的地方。这个选择过程的训练是使用直通估计器完成的(Hinton, 2012;Bengio et al, 2013)。
我们在LAMA数据集(Petroni等人,2019)上评估了我们的方法,并表明我们的模型显着提高了知识提取的准确性。此外,许多重写对应于查询措辞的一致更改(例如,时态的更改),因此提供了关于更改类型的信息,这些更改类型有助于从BERT中提取知识。当我们在BERT上进行实验时,我们的方法是通用的,可以应用于任何传销。
综上所述,我们的结果证明了重写语言模型输入的潜力,既可以获得更好的预测,也可以潜在地了解知识在这些模型中是如何表示的。我们的代码可以从https://github.com/ adihaviv/bertese下载。
2 相关工作
选择正确的语言来从语言模型中提取世界知识最近引起了广泛关注。首先,Petroni等人(2019年)观察到,通过MLM可以完成简单的查询,并提供正确的事实信息。接着,Jiang等人(2020年)和Heinzerling与Inui(2020年)在零样本设置下展示了,对这类查询进行微小的变动可能会导致事实回忆的下降。另一方面,另一项研究专注于标准问答(QA)任务的查询重写。Gan和Ng(2019年)证明了即使是微小的查询修改,也会导致多个QA模型和任务性能的显著降低。
Buck等人(2017年)展示了可以使用强化学习(RL)训练神经网络来重写问题,以优化黑盒QA系统的准确性。同样,Nogueira和Cho(2017年)使用RL创建了一个查询重写系统,以最大化黑盒信息检索引擎的召回率。
Jiang等人(2020年)提出了一种用于从语言模型中重写查询的集成方法,该方法包括:(1)挖掘新查询,(2)使用现成的预训练翻译模型通过回译收集额外的释义查询,以及(3)使用重排器选择一个或多个新查询。然后他们将这些查询输入BERT以获得掩码令牌的预测。
在这项工作中,我们借鉴了Jiang等人(2020年)的想法,并进一步训练了一个模型,以端到端的方式生成重写的查询,这些查询被优化以最大化从MLM中提取知识。
3 The BERTese Model
回顾一下,我们的目标是构建一个模型,它以自然语言中的查询作为输入,并将其重写为将作为输入传递给现有BERT模型的查询。
我们将上述重写模型称为重写器,将现有的BERT模型称为预测器。我们注意到,输入和输出查询都应包含令牌

单个[MASK]丢失:重写器的输出必须包含[MASK]令牌,以便预测器可以从该令牌中提取答案。为了鼓励重写器输出[MASK],我们添加了如下损失。我们定义如下的“softmin”分布在i 2 f1上;:::;j ^问詹(S):

其中β是经过训练的参数。当有一个索引i最接近[MASK]的嵌入时,这个分布的最大值将是最大的(如果有两个最大值,它们都有相等的值)。因此我们考虑的损失是:
预测损失:当给定^Q作为输入时,预测器应该返回黄金答案y。如果没有不可微性,我们可以在^Q中找到[MASK]令牌的指标,并使用该指标中预测器的输出分布与黄金答案y之间的交叉熵损失。为了弥补这一点,我们使用可微公式,结合直通估计器(STE) (Bengio等人,2013):设i为预测器第i位的输出分布,设' (y;p)为对应于y的单热分布与分布p之间的交叉熵。
因此,如果m是[MASK]对应的索引上的1 -hot,则损失将是黄金答案与预测分布之间的期望交叉熵。我们使用STE来优化这个目标。也就是说,在正向传递中,我们将m转换为一个单热向量。
我们最终的训练损失是上述三个损失项的和:
权值λ1;λ2使用交叉验证进行调优。总而言之,主要的挑战是重写器输出需要优化,以预测[MASK]令牌的正确标签(公式4)。然而,[MASK]令牌需要在重写器输出中出现一次。为了执行上述,使用了“单[MASK]损失”(Eq. 3)。此外,为了使重写器输出是一个有效的句子,增加了“有效令牌损失”(Eq. 1)。这鼓励模型输出接近BERT输入嵌入的标记。这是通过最小化每个重写向量到BERT输入嵌入字典中的某个向量之间的距离来实现的。
重写器预训练我们使用基于bert的模型初始化重写器,并对其进行微调以输出作为输入的准确词嵌入(即微调到身份映射)。因此,当训练知识提取时,重写器被初始化为输出它作为输入接收到的查询。
4 实验
我们在LAMA数据集上进行实验(Petroni et al, 2019;Jiang等人,2020),这是最近引入的一种用于预训练lm的无监督知识提取基准。LAMA由一组关于关系事实的封闭型查询组成,这些查询只有一个令牌答案。与Jiang等人(2020)一样,我们将主要实验限制在T-REx (Elsahar等人,2018)子集上。T-REx数据集由41个关系构建而成,每个关系最多关联1000个查询,所有这些查询都是从维基数据中提取的。
为了训练我们的模型,我们使用了一个单独的训练集,由Jiang等人(2020)创建,称为T-RExtrain。该数据集由维基数据构建,与原始的T-REx数据集没有重叠。我们在完整的霸王龙数据集上评估了我们的模型。
重写器和预测器都是基于Huggingface (Wolf et al, 2020)平台的默认设置的BERTbase。我们使用AdamW优化BERTese,初始学习率为1e-5。我们在单个32GB的NVIDIA V100上训练模型5次,批处理大小为64。对于损耗系数(见式(5)),我们设λ1 = 0:3, λ2 = 0:5。
我们将我们的方法与三个基线进行比较:(a) BERT -未经任何微调的BERTbase模型,如Petroni等人所评估的那样(2019)。(b) LPAQA——Jiang等人(2020)提出的基于挖掘附加释义查询的模型。我们只报告一次结果(c) FT-BERT:端到端可微分的BERTbase模型,在T-REx-train上明确微调以输出正确答案。与我们的模型一样,这个模型是为知识提取而训练的,但它是在内部完成的,而没有暴露可解释的中间文本重写。
我们使用与Petroni等人(2019)相同的评估指标,并在一个(P@1)宏观平均关系上报告精度(我们首先在关系内平均,然后在关系之间平均)。如表1所示,BERTese优于所有三个基线。与零样本设置相比,BERT没有在任何额外数据上进行训练,我们的性能提高了31:1 !38:3。我们的模型也优于BERT模型对与我们的模型相同的数据进行了知识提取(36 !38:3)。最后,我们比BERTbase版本的LPAQA高出4分以上。

表2给出了我们的模型输出的重写示例。可以看出,重写通常在语义上是合理的,并且进行对人类没有意义的小更改,但似乎有助于从BERT中提取信息,例如was !是和是!的。在某些情况下,重写可以被解释,例如,将单词airfield替换为更常见的单词airport。

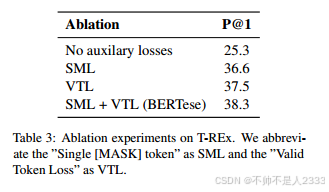
在表3中,我们给出了在T-REx测试集上烧蚀损失函数不同部分后的P@1结果。我们保留了相同的标签损失、相同的重写器预训练方案、超参数和推理过程。我们表明,在T-REx数据集上,去除所有辅助损失会显著影响性能。接下来,我们评估了移除“Single [MASK] Loss”的影响,并报告了从38:3到37:3的下降。此外,当进一步观察模型产生的重写时,我们发现这些重写在某些情况下会有多个[MASK]令牌。总的来说,结果表明,只使用其中一个丢失项可以大大提高性能(“有效令牌丢失”或“单个[MASK]丢失”),但同时使用这两个丢失项可以进一步提高准确性。
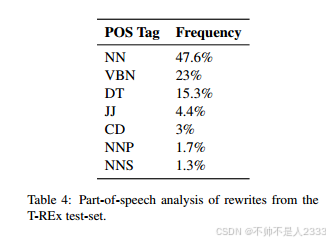
为了更好地理解重写器执行了哪些类型的更改,表4显示了被重写器替换的词性标签的分布。我们显示了频率高于1%的所有词性标签。超过70%的替换词是名词和动词,它们承载着大量的语义内容。有趣的是,15%的替换词是限定词,它们几乎没有语义内容。
5 结论
我们提出了一种修改BERT模型输入的方法,这样可以更准确地提取事实信息。我们的方法使用经过训练的重写模型,当用作BERT的输入时,该模型被优化以最大限度地提高其重写的准确性。我们的重写方案确实比基线产生更准确的结果。有趣的是,我们的重写是相当小的修改,突出了BERT模型对这些编辑不是不变的事实。我们的方法并不局限于知识提取。原则上,它可以应用于BERT中的一般问答数据集,甚至是语言建模。在前者中,我们可以将预测器更改为多选题QA预训练BERT,并排除单个[MASK]令牌损失。在后一种情况下,我们可以设想这样一种情况,重写一个句子可以更容易地完成一个被掩盖的单词。我们的经验设置侧重于LAMA数据集,其中需要单个掩码令牌预测。有几个可能的扩展到多个遮罩,我们把它们留给未来的工作。最后,在其他屏蔽语言模型(如RoBERTa (Liu et al ., 2019)和ERNIE (Zhang et al ., 2019)上测试该方法将会很有趣,ERNIE是一种使用外部实体表示增强的传销。