CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer[2024,8,14]
Diffusers
Github
CogVideoX-2b : 只开源了2B的模型,5B模型目前没有开源.
清华智普最新的T2V模型,目前测试下来在第二梯队左右,相比于快手的可灵,Luma等还要差一点(至于现在没啥消息的Sora是另一回事了).可以生成460x720的6s视频,但是fps只有8.
Method
DiT Architecture
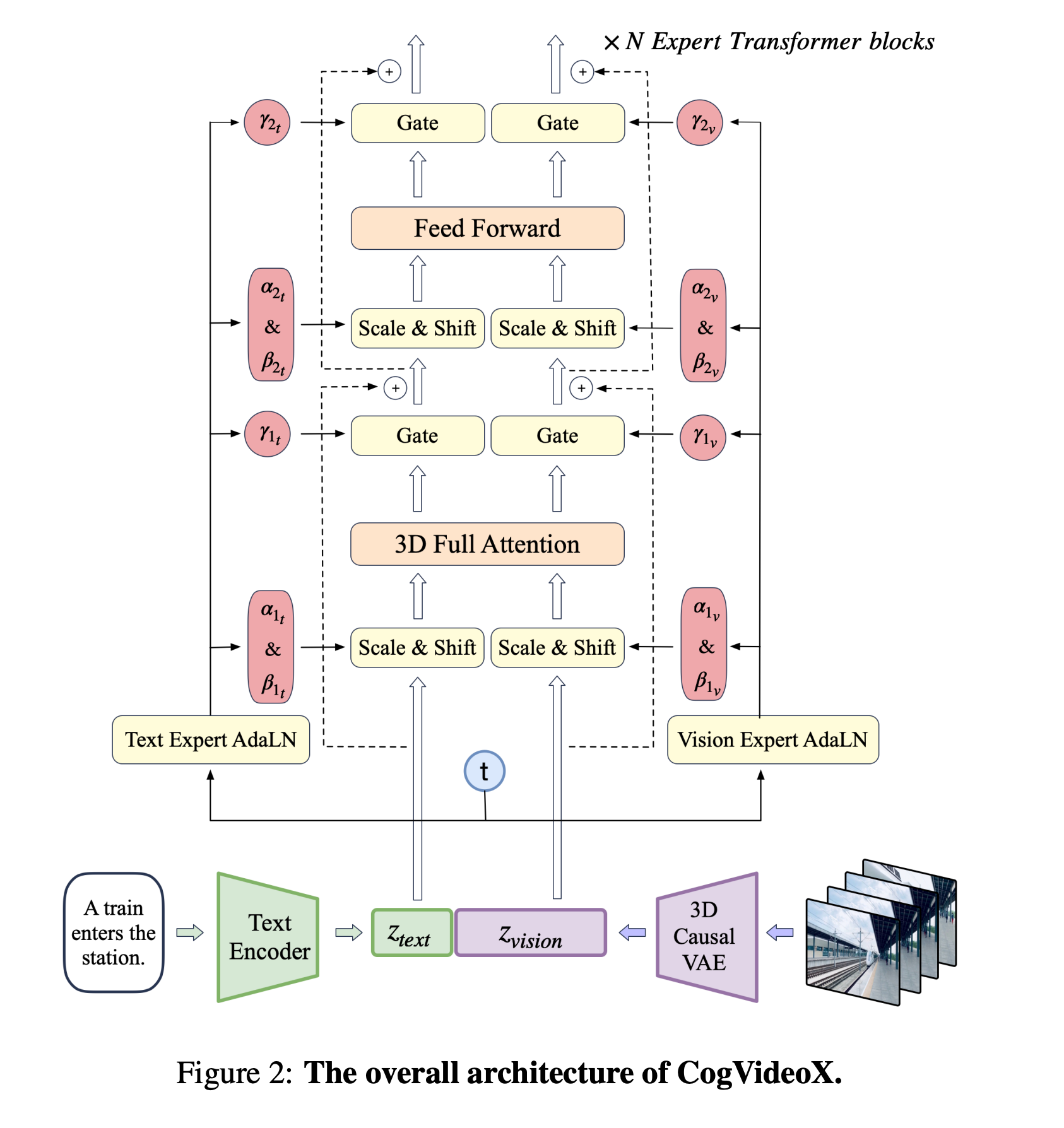
prompt经过T5的到的Embedding和Video经过VAE得到的Embedding在Sequence层面Cat在一起,由于没有经过Norm的操作,这两个embedding完全不一致,利用两个完全独立的AdaLyaer来映射为不同的Scale参数.
Block的设计参看代码,是最直接的方法.
3D causal VAE
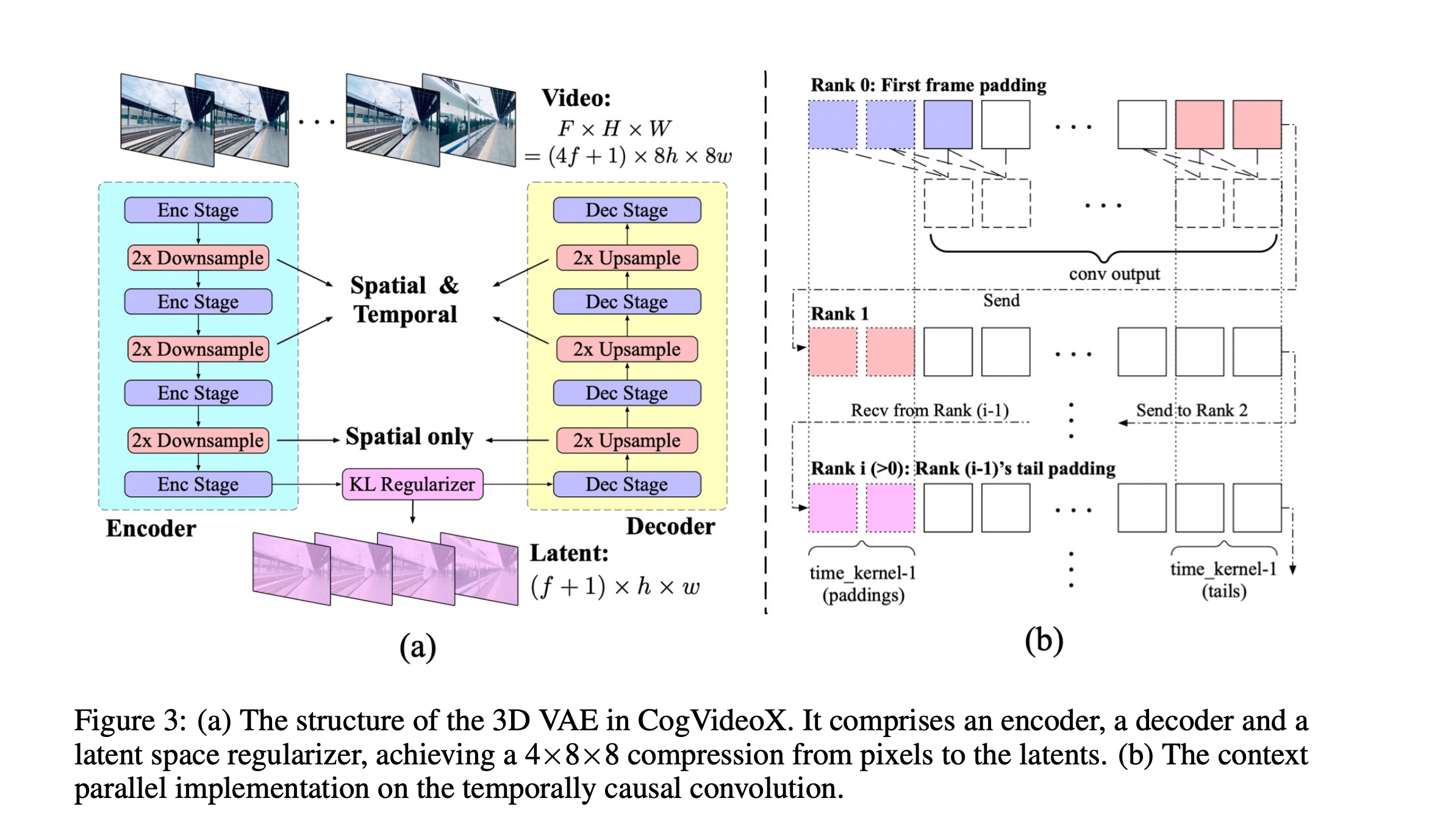
在训练VAE采用了3D causal Conv方式(当前帧只和后面帧进行连接,在h,w上不做限制,类似于NLP中的causal方式),能够压缩 8x8x4 倍.
PE
采用了3D RoPE的方式,在(x,y,t)三个维度上都做了RoPE,并且三个PE在Channel维度上分别占用 3 / 8 , 3 / 8 , 2 / 8 3/8,3/8,2/8 3/8,3/8,2/8
other tricks
- 训练3D VAE的时候加上了L2 Loss ,LPIPS perceptual loss, GAN loss(from 3D discriminator).
- 图像和视频混合训练,并且不固定视频和图像出现的位置,论文表示之前图像的视频混合训练都是前固定帧数为图像,后面固定帧数为视频,这样等同于训练了两个独立的模型,对于模型的理解能力不能得到有效提高.

- t采样方式,之前关于时间步t的采样都是均匀随机从[1,T]中采样,但是这种方式在模型每一步更新中不能保证是均匀采样的,论文认为这种方式会对模型训练具有一定影响.因此论文为每一张卡设定了一个采样区间 [ t i , t i + 1 ] [t_i,t_{i+1}] [ti,ti+1],这样能够保证每次模型更新都是均匀采样得到的.Loss更加稳定,结果如下(d).
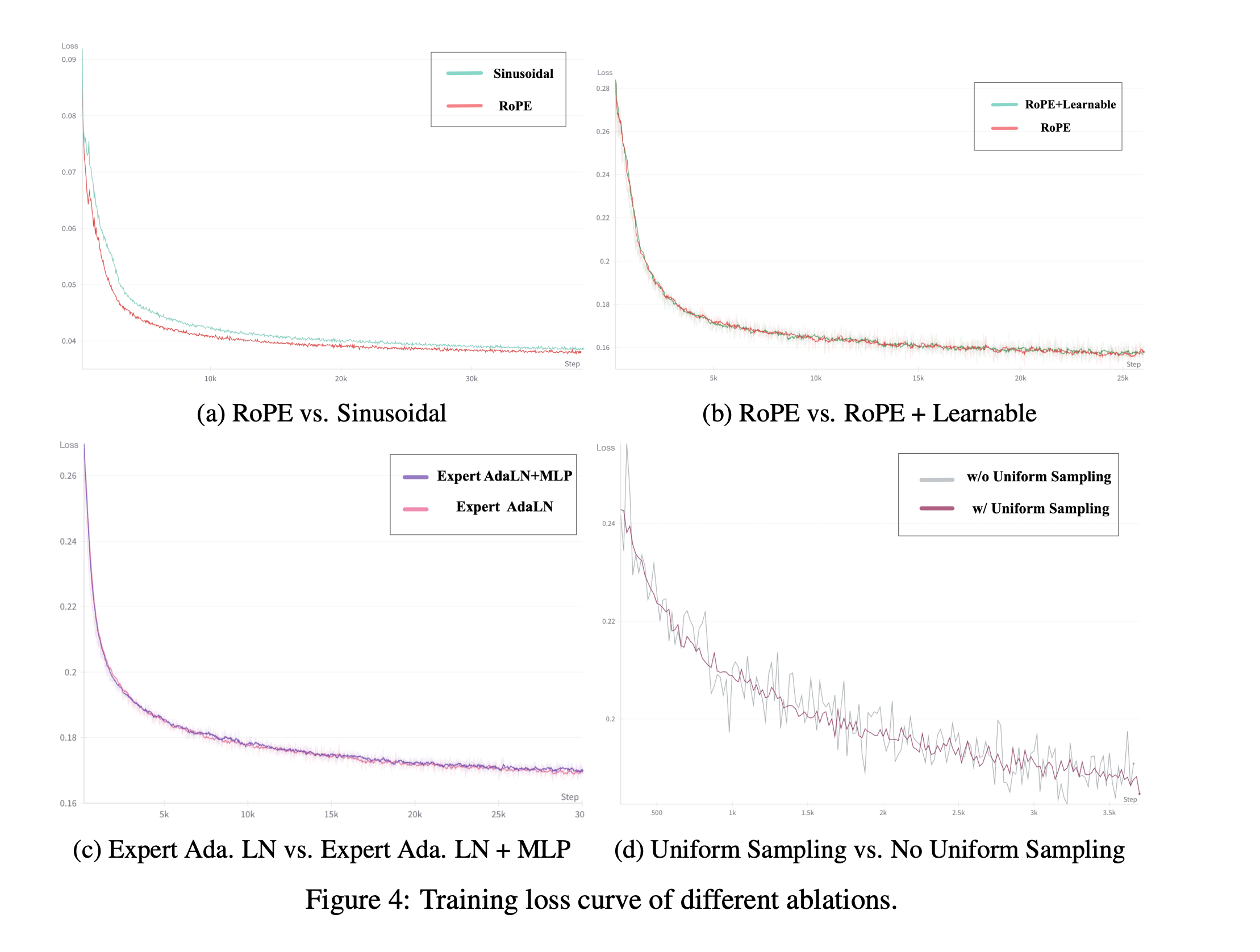
- 模型训练方式也是采用在LQ视频下预训练,在HQ视频下微调的方式,最后在高质量的文本-视频对下进行微调.