本文所需文件(Vmware虚拟机、密匙、乌班图系统、JDK、Hadoop)
链接:https://pan.baidu.com/s/1yU5s36Rgl_jE_mAmHsJBfQ?pwd=i5s6
提取码:i5s6
一、Linux操作系统的安装
二、Hadoop的伪分布式安装
1.配置ssh无密登录
(1)安装ssh
sudo apt-get install ssh
(2)产生SSH Key
ssh-keygen -t rsa(3)将公钥放到许可证文件中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys(4)更改权限
chmod 755 ~
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys(5)验证是否可以免密登录本机(下图为登录成功界面)
ssh 本机名
(6)退出ssh连接
exit2.JDK的安装
(1)查看Vmware网络配置(配置IP地址)
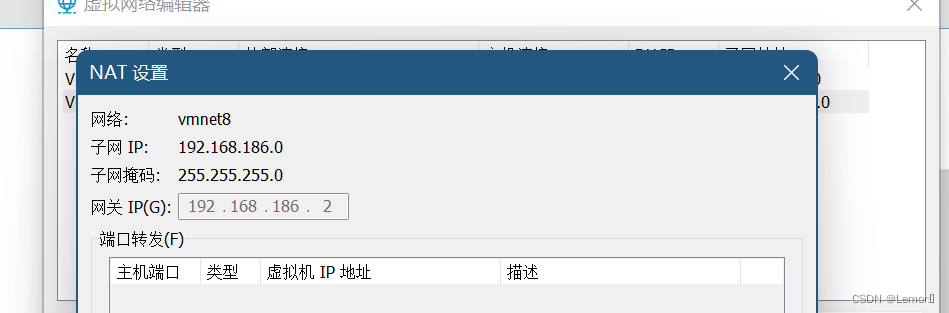
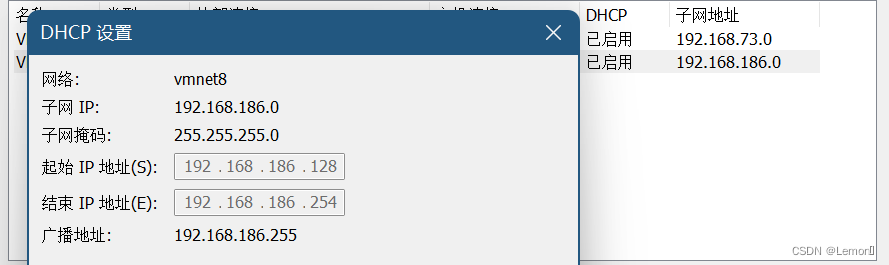
(2) 配置虚拟机静态IP
sudo vi /etc/netplan/01-network-manager-all.yaml依据Vmware网络配置编辑
network:
ethernets:
ens33:
dhcp4: no
dhcp6: no
addresses: [192.168.186.130/24,]
gateway4: 192.168.186.2
nameservers:
addresses: [114.114.114.114, ]
version: 2
renderer: NetworkManager
更新网络配置(若没报错,即配置成功)
sudo netplan apply测试连接
ping www.baidu.com修改主机名(本文修改为master),并把主机名和IP地址写进/etc/hosts配置文件(如图所示)
sudo vi /etc/hostname
sudo vi /etc/hosts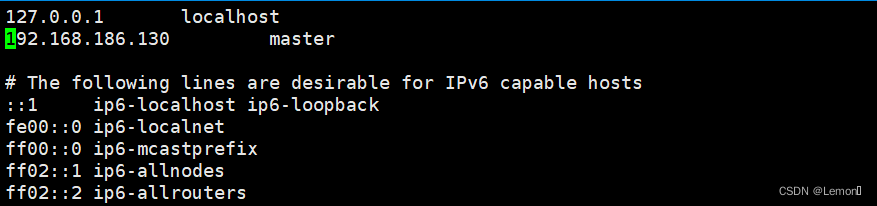
重启虚拟机使配置生效
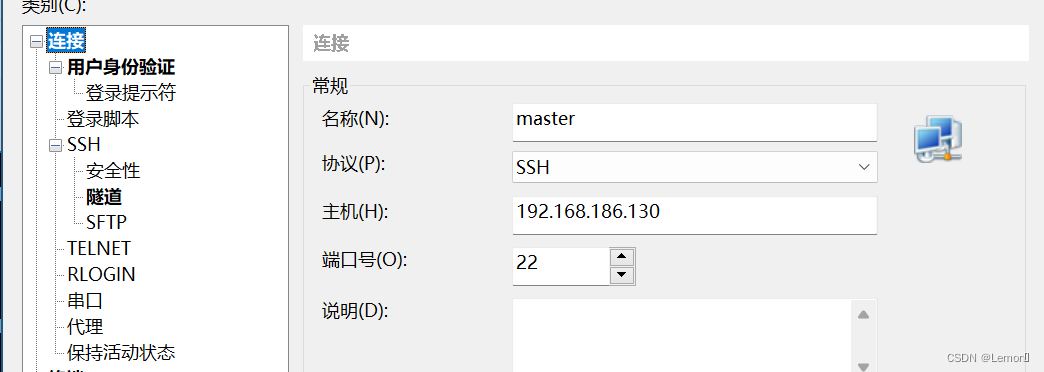
(3)连接xshell (提前安装Xshell、Xftp)
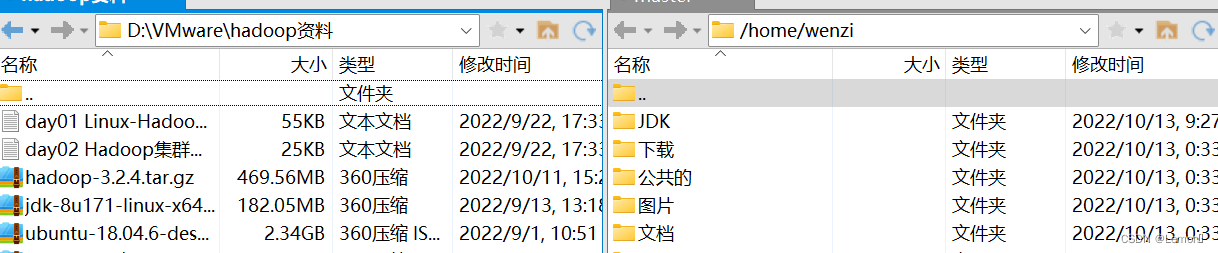
(4)新建文件传输(导入JDK、hadoop压缩包)

(5)解压jdk
tar -zxvf jdk-8u171-linux-x64.tar.gz
(6)配置环境变量
sudo vi /etc/profile
在文本末添加以下命令(添加的命令如下图所示)
export JAVA_HOME=./jdk1.8.0_171
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}lib
export PATH=${JAVA_HOME}/bin:$PATH
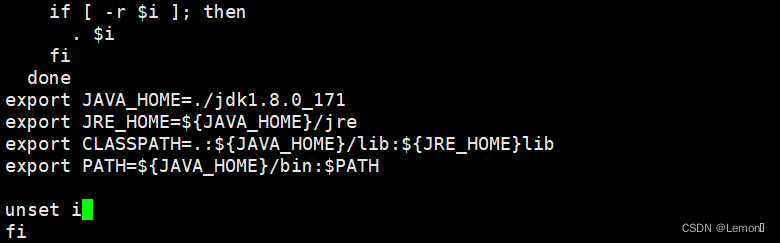
(7)重新加载配置文件,验证jdk配置是否成功(下图即为配置成功)
source /etc/profile
java -version
3.Hadoop的安装
(1)解压hadoop安装包
tar -zxvf hadoop-3.2.4.tar.gz
(2)配置hadoop环境变量
sudo vi ~/.bashrc在文尾添加以下代码
export JAVA_HOME=/home/wenzi/jdk1.8.0_171
export HADOOP_HOME=/home/wenzi/hadoop-3.2.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
更新配置
source ~/.bashrc(3)测试是否配置成功(下图即配置成功)
hadoop version
4.修改Hadoop配置文件
(1)修改hadoop-env.sh
sudo vi ./hadoop-3.2.4/etc/hadoop/hadoop-env.sh找到以下命令进行修改(如图)


sudo vi ./hadoop-3.2.4/etc/hadoop/core-site.xml<configuration>
<!-- 配置HDFS的主节点,nameNode -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.186.130:9000</value>
</property>
<!-- 配置HADOOP运行时产生文件的储存目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/wenzi/hadoop-3.2.4/dataNode_1_dir</value>
</property>
</configuration>
(3)修改yarn-site.xml文件
sudo vi ./hadoop-3.2.4/etc/hadoop/yarn-site.xml<configuration>
<!--配置ReourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.186.130</value>
</property>
<!--配置NodeManager执行任务的方式shuffle:洗牌 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>(4)修改mapred-site.xml文件
sudo vi ./hadoop-3.2.4/etc/hadoop/mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>(5)修改hdfs-site.xml文件
sudo vi ./hadoop-3.2.4/etc/hadoop/hdfs-site.xml<configuration>
<!-- 指定HDFS储存数据的副本数目,默认情况下时3份 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 指定namenode数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/wenzi/hadoop-3.2.4/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/wenzi/hadoop-3.2.4/hadoop_data/hdfs/datanode</value>
</property>
<property>
<name>dfs.http.address</name>
<value>wenzi:50070</value>
</property>
</configuration>
(6)修改/etc/profile文件
sudo vi /etc/profile:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HAOOP_HOME=./hadoop-3.2.4
修改成如图所示

(7)创建并格式化文件系统
mkdir -p ./hadoop-3.2.4/hadoop_data/hdfs/namenode
mkdir -p ./hadoop-3.2.4/hadoop_data/hdfs/datanode
mkdir -p ./hadoop-3.2.4/dataNode_1_dir/datanode
hdfs namenode -format
5.启动Hadoop
(1)启动
start-all.sh(2)查看hadoop全部的守护进程(全部启动即为成功)

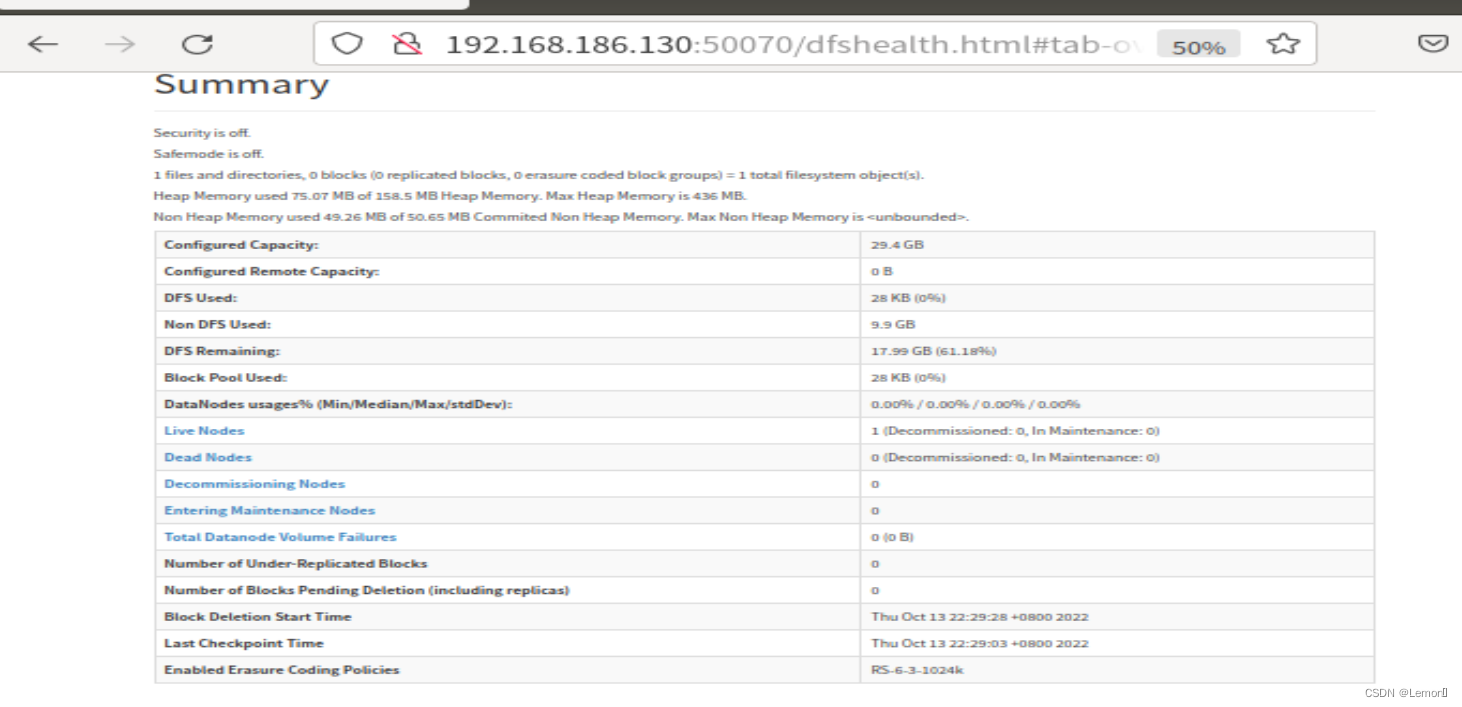
(3)查看HDFS WEB 页面
打开火狐浏览器输入:192.168.186.130:50070
如图所示:
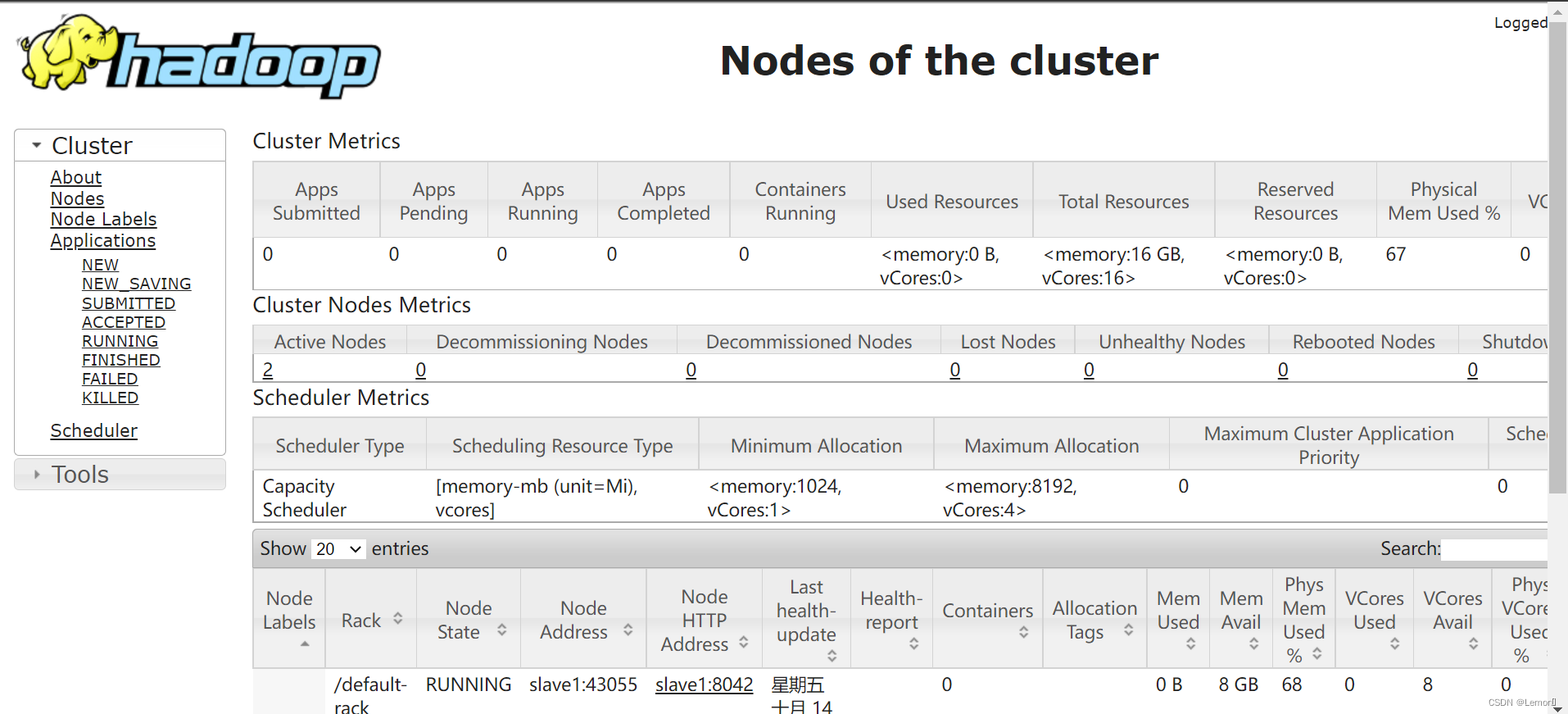
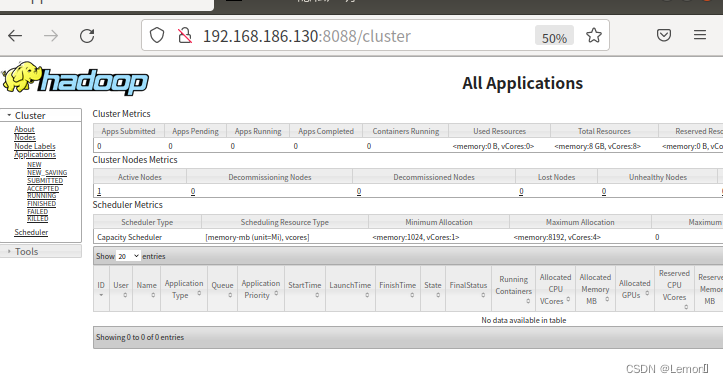
(4)查看YARN WEB页面
打开火狐浏览器输入:192.168.186.130:8088
如图所示:
三、Hadoop集群的搭建与配置
1.修改配置文件
(1)修改hdfs-site.xml文件(对照以下代码进行修改)
sudo vi ./hadoop-3.2.4/etc/hadoop/hdfs-site.xml<configuration>
<!-- 指定HDFS储存数据的副本数目,默认情况下时3份 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 指定namenode数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/wenzi/hadoop-3.2.4/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.http.address</name>
<value>master:50070</value>
</property>
</configuration>
(2)修改core-site.xml文件(对照以下代码进行修改)
sudo vi ./hadoop-3.2.4/etc/hadoop/core-site.xml<configuration>
<!-- 配置HDFS的主节点,nameNode -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 配置HADOOP运行时产生文件的储存目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/wenzi/hadoop-3.2.4/dataNode_1_dir</value>
</property>
</configuration>
(3)修改yarn-site.xml文件(对照以下代码进行修改)
sudo vi ./hadoop-3.2.4/etc/hadoop/yarn-site.xml<configuration>
<!--配置ReourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!--配置NodeManager执行任务的方式shuffle:洗牌 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
(4)修改mapred-site.xml文件(对照以下代码进行修改)
sudo vi ./hadoop-3.2.4/etc/hadoop/mapred-site.xml<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:54311</value>
</property>
</configuration>
(5)修改/etc/hosts文件(内容如图所示)
sudo vi /etc/hosts两个slave节点IP需要与后面保持一致
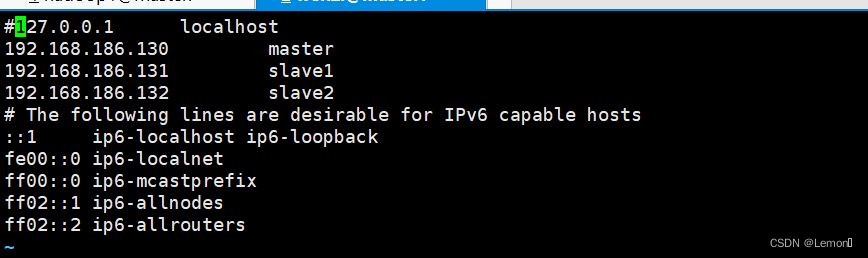
(6) 编辑masters文件(在文件中输入主机名master)
sudo vi ./hadoop-3.2.4/etc/hadoop/masters
(7)编辑workers文件(删除local host添加slave1、slave2)
sudo vi ./hadoop-3.2.4/etc/hadoop/workers
(8)删除临时文件夹
rm -rf ./hadoop-3.2.4/dataNode_1_dir
rm -rf ./hadoop-3.2.4/logs
2.复制虚拟机
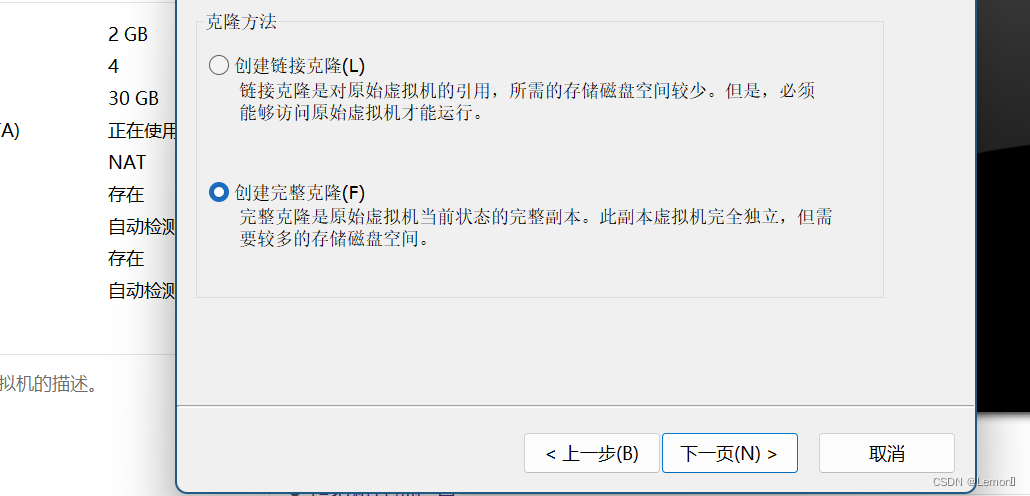
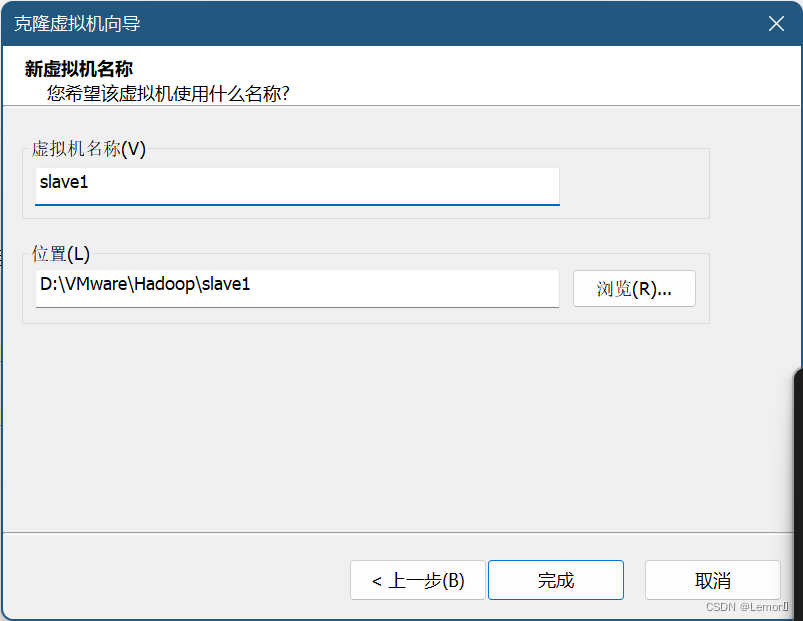
(1)复制主机master到slave1、slave2(下图为复制步骤)
(2)设置slave服务器
下面为设置slave1、同理设置salve2,
1、修改IP地址(IP与上文保持一致,slave1:192.168.186.131 slave2:192.168.186.132)
打开slave1虚拟机进行以下配置
sudo vi /etc/netplan/01-network-manager-all.yamlnetwork:
ethernets:
ens33:
dhcp4: no
dhcp6: no
addresses: [192.168.186.131/24,]
gateway4: 192.168.186.2
nameservers:
addresses: [114.114.114.114, ]
version: 2
renderer: NetworkManager
sudo netplan apply2、修改主机名(分别把master改为slave1、slave2)
sudo vi /etc/hostname
3、重启虚拟机使配置生效
sudo reboot4.修改hdfs-site.xml文件
sudo vi ./hadoop-3.2.4/etc/hadoop/hdfs-site.xml<configuration>
<!-- 指定HDFS储存数据的副本数目,默认情况下时3份 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 指定namenode数据存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/wenzi/hadoop-3.2.4/hadoop_data/hdfs/datanode</value>
</property>
<property>
<name>dfs.http.address</name>
<value>master:50070</value>
</property>
</configuration>
5.格式化文件系统
hdfs namenode -format3.启动Hadoop集群
start-all.sh
(1)分别查看三个虚拟机进程
jps

ssh slave2jps
ssh slave1jps
(1)查看HDFS WEB 页面
打开火狐浏览器输入:http://master:50070
如图所示:

(2)查看YARN WEB页面
打开火狐浏览器输入:http://master:8088
如图所示: