在win11下使用IDEA进行Spark实践
1.下载包和软件
- IDEA
- spark 3.1.3
- hadoop 3.2.1
- scala 2.12 (注意,spark3.1.2不支持Scala2.13)
- java 1.8
这里面有一部分包https://pan.baidu.com/s/1fFEZmqUWZks-Hh5LkKRVww
1.1 IDEA下载安装
学生用教育邮箱认证后可免费使用,去https://www.jetbrains.com/zh-cn/community/education/
1.2 java环境
首先下载jdk(切记注意jdk和jre的区别,我们要开发所以要下载jdk,jre只是运行环境),java8任意小版本基本都可以
环境变量新建JAVA_HOME
JRE_HOME可有可无
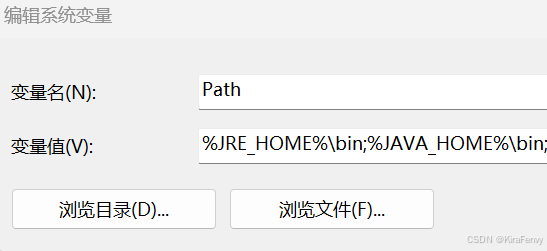
别忘了Path

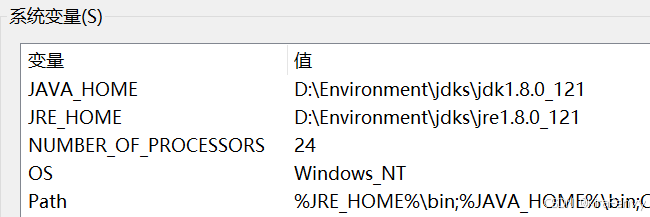
%JRE_HOME%\bin;%JAVA_HOME%\bin;
看一下是否配置成功
java -version

1.3 安装Scala
这边安装scala 2.12.20
选择.msi的文件下载安装,会自动在系统中添加环境变量,检查是否已经安装变量 (查看是否有SCALA_HOME 和path里面是否已经添加变量),如果没有请补充
scala -version

1.4 安装spark
这边安装spark 3.1.3

虽然是tgz文件,但在windows也可以直接解压使用,同样需要配置环境变量SPARK_HOME和Path中的%SPARK_HOME%\bin
1.5 安装hadoop
同Spark,hadoop要安装spark对应的版本,我们这里是3.1.3,tar.gz直接在windows解压然后配置环境变量,但hadoop还需要winutils适配windows系统
https://github.com/cdarlint/winutils中,我们进行下载对应版本(如果没有对应版本就临近版本)
把bin中的文件复制粘贴到hadoop的bin下
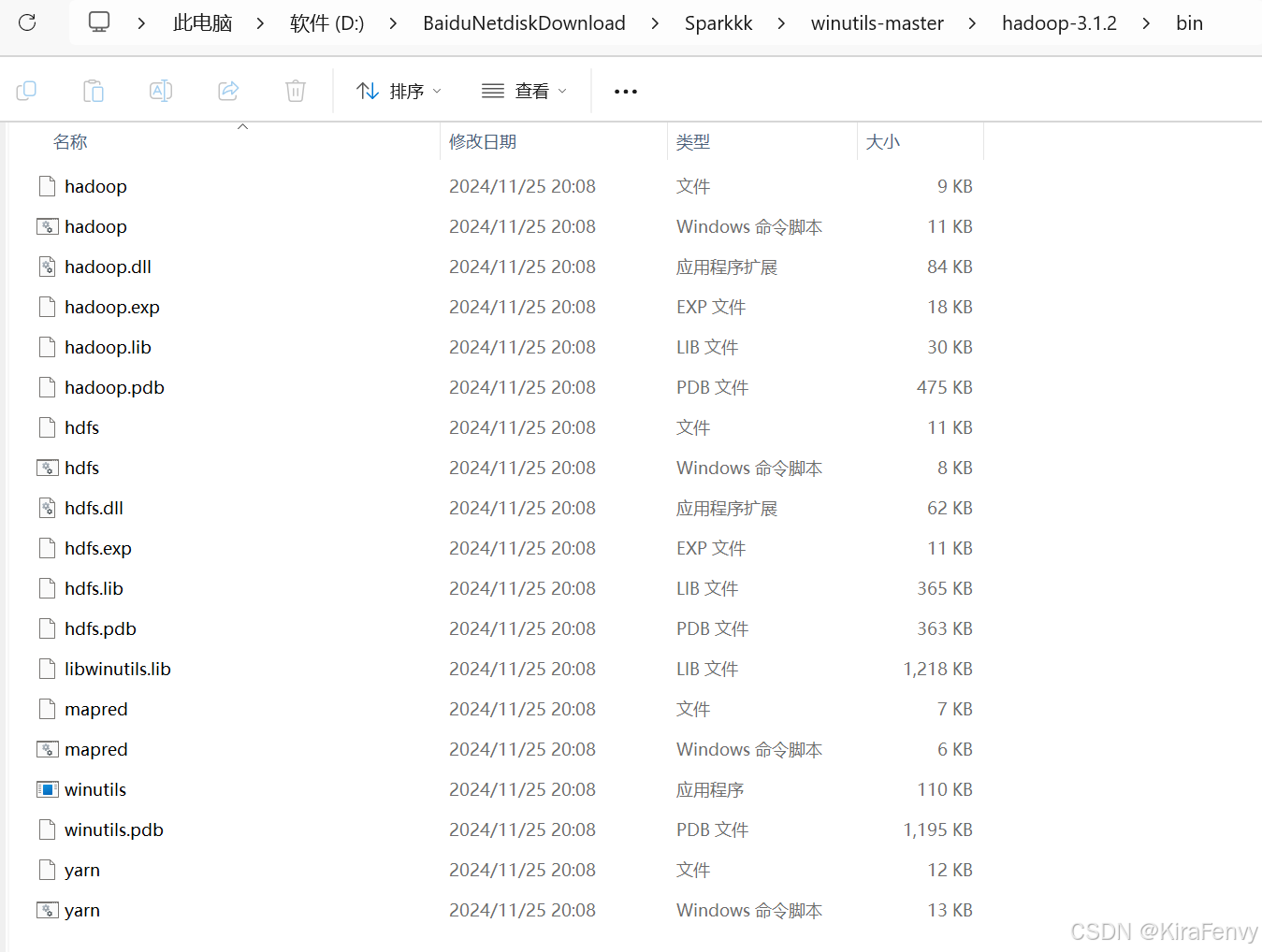
输入hadopp version测试,注意有没有横杠差别很大,这里应为没有横杠

打开cmd
输入 spark-shell测试
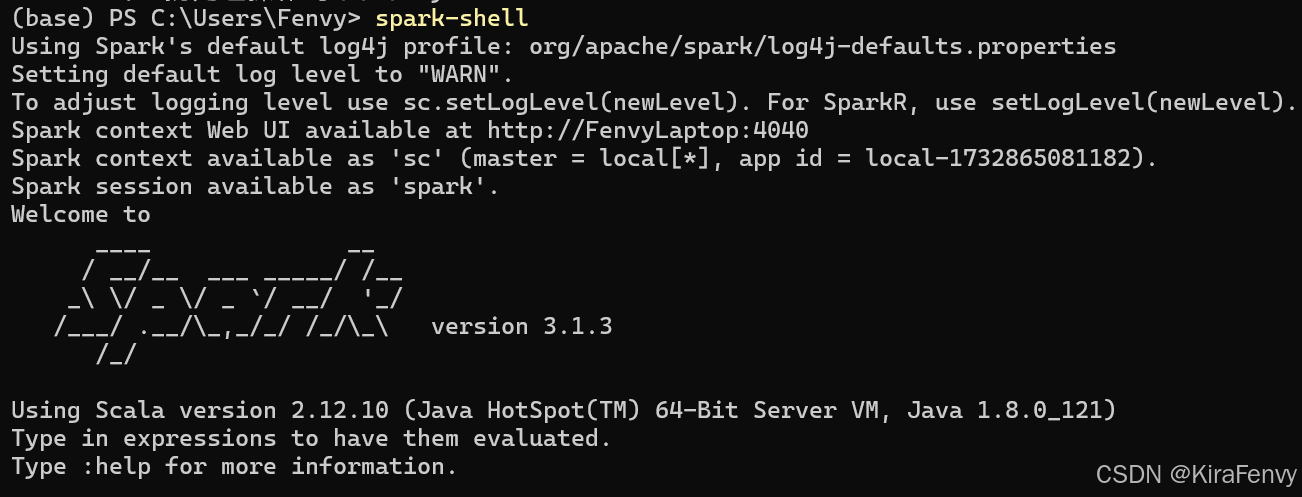
注意这里显示的Scala是2.12.10,如果先安装了 Scala,然后安装了 Spark,Spark Shell 会使用它自己的 Scala 版本。相反,如果你先安装了 Spark,然后安装了 Scala,你可以通过设置环境变量来让 Spark Shell 使用你安装的 Scala 版本,但是这里不影响我们后面的操作
2.IDEA中的配置
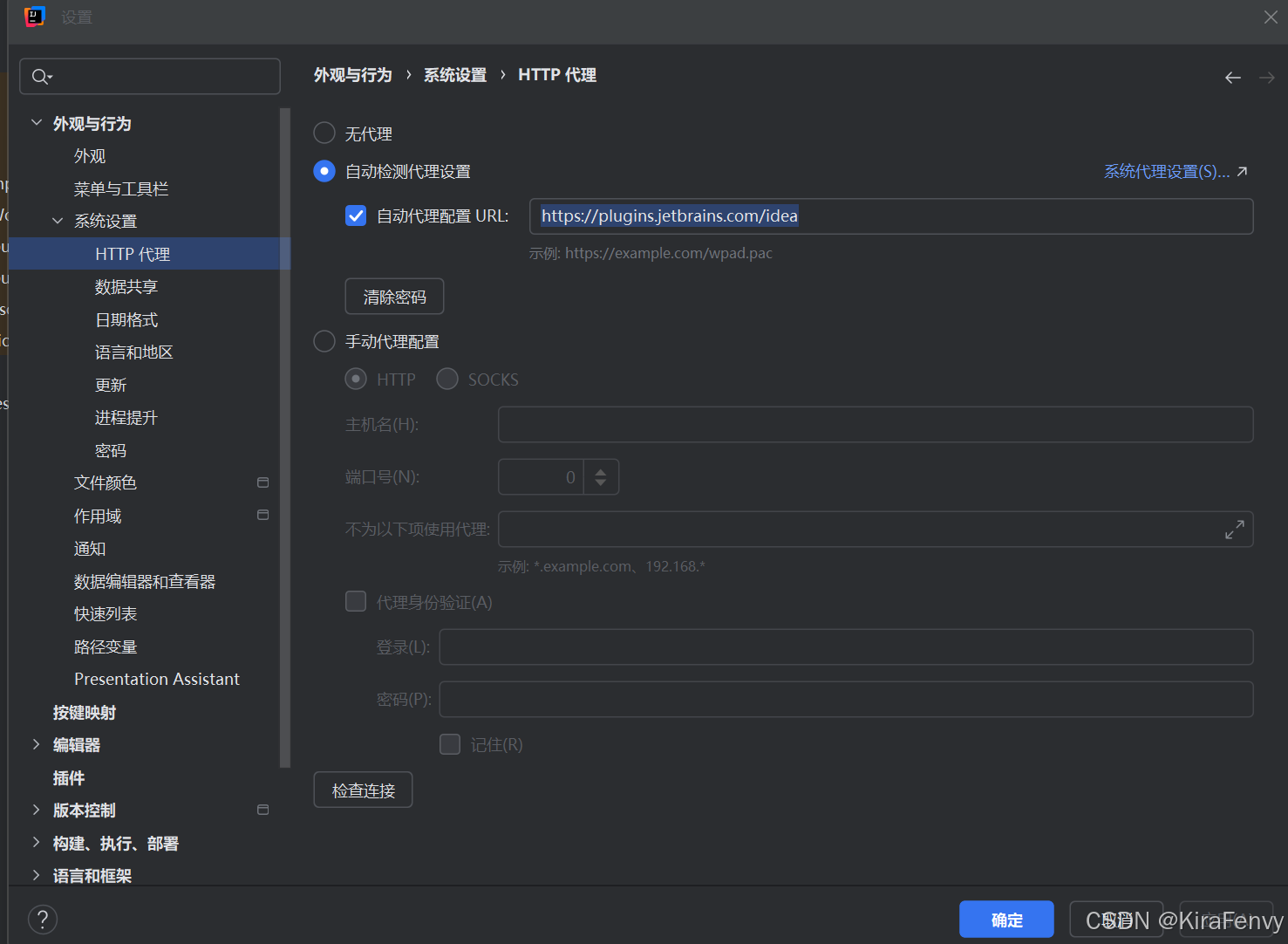
- IDEA 我这边是 2024.3 需要安装Scala的插件,我遇到了插件无法安装的问题,参考https://blog.csdn.net/qq_43571809/article/details/135937424解决,在IDEA设置自动代理配置URL[https://plugins.jetbrains.com/idea](https://plugins.jetbrains.com/idea
然后安装插件
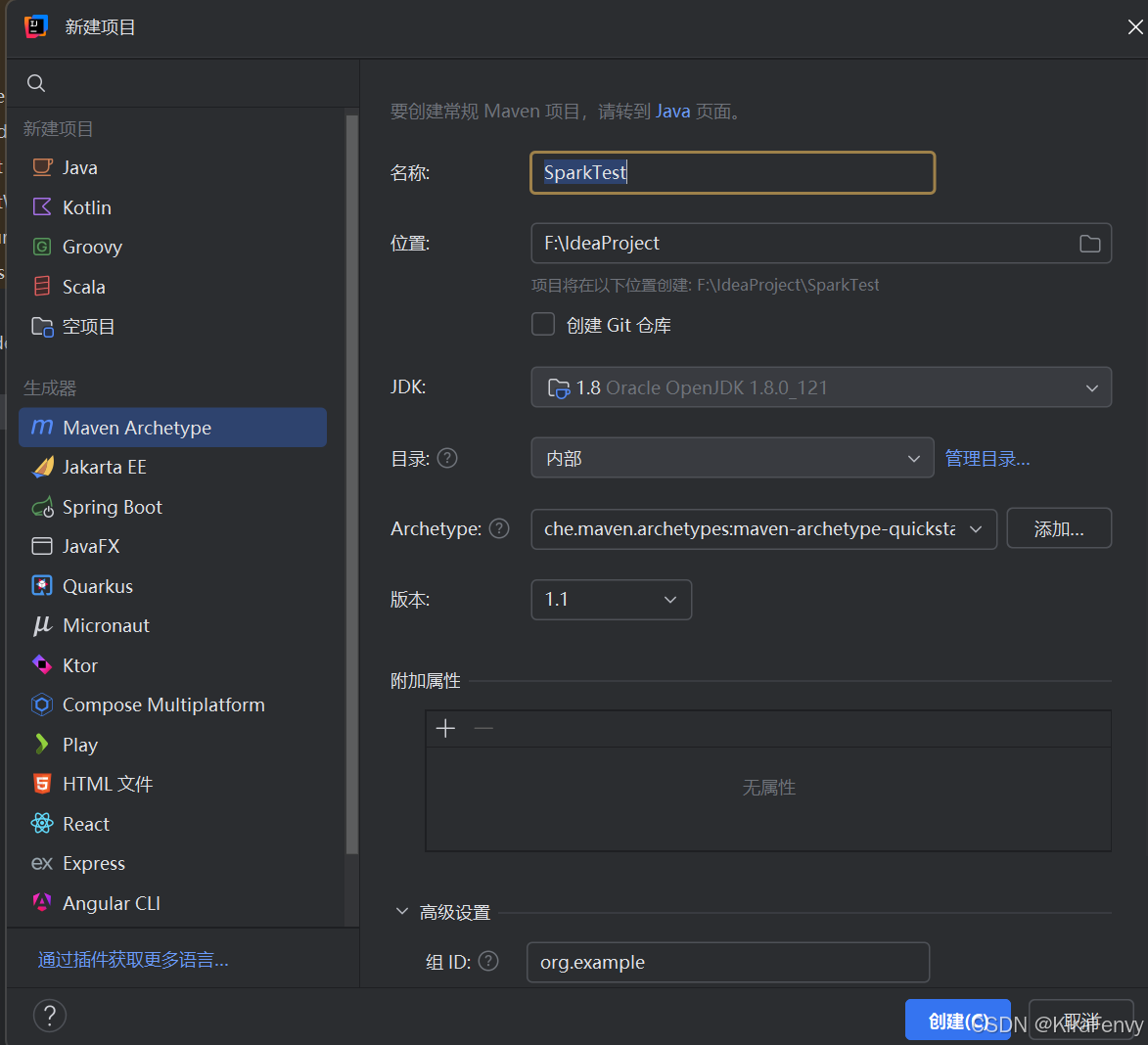
用maven Archetype构建的话,可以这样选择
如果右键新建不了Scala类,需要
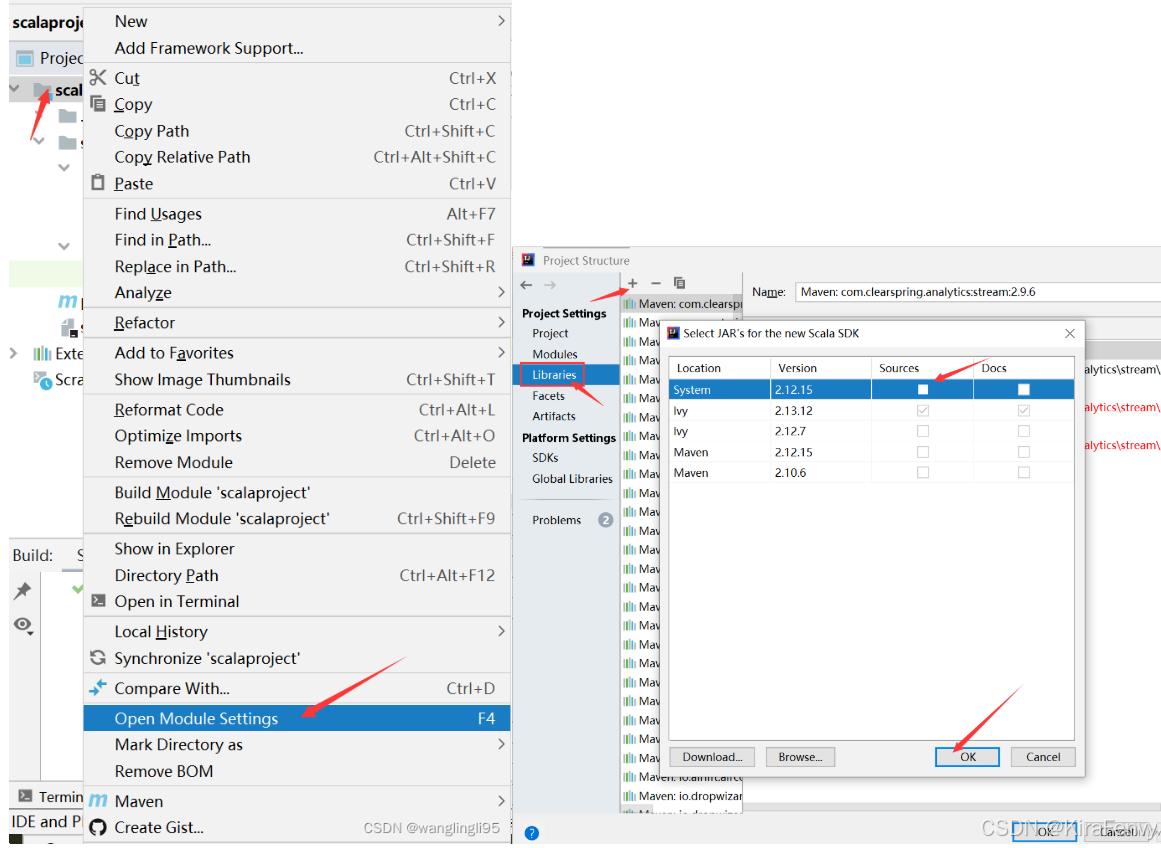
修改pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>SparkTest</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>SparkTest</name>
<url>http://maven.apache.org</url>
<properties>
<!-- 声明scala的版本 -->
<scala.version>2.12.20</scala.version>
<!-- 声明linux集群搭建的spark版本,如果没有搭建则不用写 -->
<spark.version>3.1.3</spark.version>
<!-- 声明linux集群搭建的Hadoop版本 ,如果没有搭建则不用写-->
<hadoop.version>3.1.3</hadoop.version>
</properties>
<dependencies>
<!--scala-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.1.3</version>
<scope>provided</scope>
</dependency>
</dependencies>
</project>
然后刷新maven
3.WordCount代码实践
新建words.txt放一些英语文章进去
然后新建几个Scala类尝试
WordCount.scala
import org.apache.spark.sql.SparkSession
object WordCount {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[*]")
.appName("word count")
.getOrCreate()
val sc = spark.sparkContext
val rdd = sc.textFile("data/input/words.txt")
val counts = rdd.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
counts.collect().foreach(println)
println("全部的单词数:"+counts.count())
counts.saveAsTextFile("data/output/word-count")
}
}
WordCountWithTiming.scala
import org.apache.spark.sql.SparkSession
object WordCountWithTiming {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[*]")
.appName("Word Count with Timing")
.getOrCreate()
val sc = spark.sparkContext
// 记录开始时间
val startTime = System.currentTimeMillis()
// 读取文本数据
val rdd = sc.textFile("data/input/words.txt")
// 数据处理:map-reduce 操作
val counts = rdd
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
// 收集并打印结果
val collectStartTime = System.currentTimeMillis()
counts.collect().foreach(println)
// 打印统计信息
println("全部的单词数:" + counts.count())
val endTime = System.currentTimeMillis()
println(s"总执行时间:${endTime - startTime} ms")
println(s"Collect 阶段时间:${endTime - collectStartTime} ms")
// 阻塞程序以保持运行
// println("程序已完成,Spark UI 保持运行中。按 Enter 退出程序...")
// scala.io.StdIn.readLine() // 等待用户输入以终止程序
// 延迟 1 分钟 (60000 毫秒)
println("程序已完成,Spark UI 将在 1 分钟后停止...")
Thread.sleep(60000)
spark.stop()
}
}
WordCountWithShuffleConfig.scala
package org.example
import org.apache.spark.sql.SparkSession
object WordCountWithShuffleConfig {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[*]")
.appName("Word Count with Shuffle Config")
.config("spark.default.parallelism", "2") // 修改并行度
.config("spark.sql.shuffle.partitions", "4") // 修改shuffle分区数
.config("spark.hadoopRDD.ignoreEmptySplits", "false") // 处理空分区
.config("spark.hadoop.mapreduce.input.fileinputformat.split.minsize", "1048576") // 设置最小分片大小为1MB
.config("spark.sql.file.maxPartitionBytes", "134217728") // 设置单个分区的最大大小为128MB
.config("spark.sql.adaptive.enabled", "true") // 启用自适应查询执行
.config("spark.sql.adaptive.shuffle.targetPostShuffleInputSize", "67108864") // 自适应shuffle目标大小为64MB
.config("spark.reducer.maxSizeInFlight", "96m") // 调整reducer缓冲区大小
.config("spark.reducer.maxReqsInFlight", "5") // 限制同时请求数
.config("spark.reducer.maxBlocksInFlightPerAddress", "2") // 限制每个地址的最大请求数
.getOrCreate()
val sc = spark.sparkContext
// 记录开始时间
val startTime = System.currentTimeMillis()
// 读取文本数据
val rdd = sc.textFile("data/input/words.txt")
// 引入多次shuffle操作
val counts = rdd
.flatMap(_.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _) // 第一次shuffle
val sortedCounts = counts
.map { case (word, count) => (count, word) }
.sortByKey(ascending = false) // 第二次shuffle
// 收集并打印结果
val collectStartTime = System.currentTimeMillis()
sortedCounts.collect().foreach(println)
// 打印统计信息
println("全部的单词数:" + counts.count())
val endTime = System.currentTimeMillis()
println(s"总执行时间:${endTime - startTime} ms")
println(s"Collect 阶段时间:${endTime - collectStartTime} ms")
// println("程序已完成,Spark UI 将在 1 分钟后停止...")
// Thread.sleep(60000)
spark.stop()
}
}