文章目录
理解源ip地址和目的ip地址
在IP数据包头部中, 有两个IP地址, 分别叫做源IP地址, 和目的IP地址
ip地址可以确定唯一一台主机
端口号
端口号是传输层协议的内容。端口号可以确定主机上唯一的进程。
一个端口号只能被一个进程占用。一个进程可以有多个端口号
总结:
ip标定全公网内唯一一台主机
port标定特定一台主机上唯一一个进程
IP+PORT:全网内唯一一个进程
端口号和pid
pid和端口号都是进程拥有的编号,它们有什么区别吗?
pid是每个进程都必须有的,但是port不是必须有的,因为不是所有进程都需要联网。
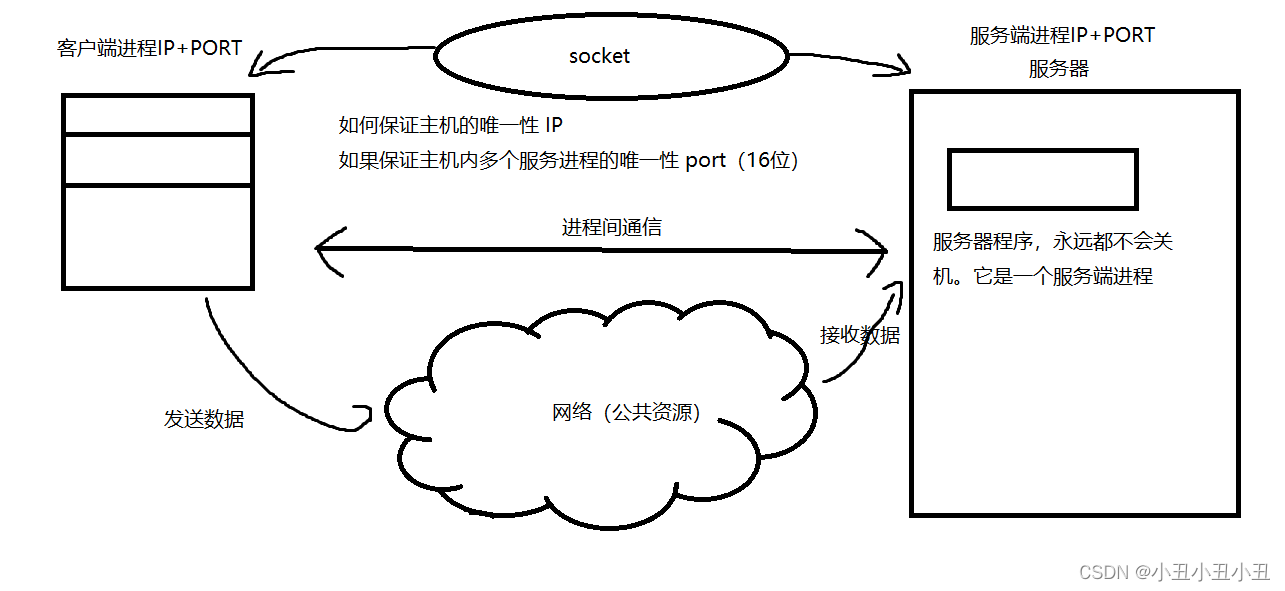
套接字
套接字就是ip + 端口号。套接字本质是进程间通信
进程间通信就要有共享资源,计算机网络就是两个进程的共享资源
网络字节序
内存有大小端。网络也有大小端。
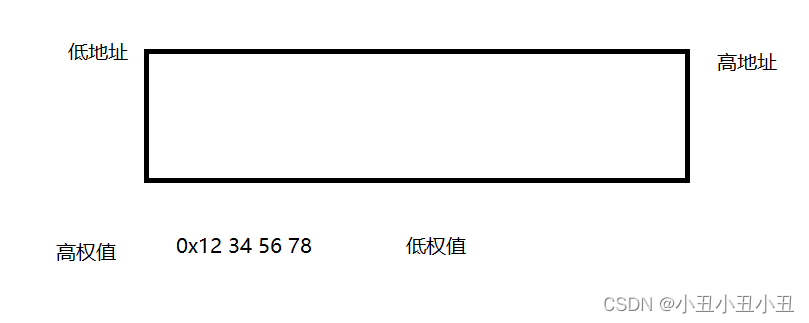
大端:高权值数据放在低地址空间。低权值数据放在高地址空间。
小端:低权值数据放在低地址空间。高权值数据放在高地址空间。
注:不用问为什么低地址为什么写在左边高地址在右边,这没有意义。(很多debug工具都是这么显示的) 。有意义的是指针指向的空间都是低地址向高地址生长。
-
网络数据流的地址发送规定:先发出的数据是低地址,后发出的数据是高地址(这是发送规则)
-
TCP/IP协议规定,网络数据流应采用大端字节序,即低地址高字节.(这是发送的数据的存储格式)
-
不管这台主机是大端机还是小端机, 都会按照这个TCP/IP规定的网络字节序来发送/接收数据;
-
如果当前发送主机是小端, 就需要先将数据转成大端; 否则就忽略, 直接发送即可
比如我的主机是小端机器。我发送0x12345678,由于是小端机器,在低地址存放的是78563412.在发送前先转成大端,变成12345678,然后先发送低地址的数据,也就是12.然后发送34然后56…
为什么默认网络数据流要发射大端的数据,有一个理解:发送大端数据可以一边接收数据一边计算。
比如:发送1234,按照大端存储,低地址到高地址放的是1234.先发出的数据是低地址,也就是1,然后在接收2的时候,可以用1 * 10 + 2,得到12,然后再接收 3的时候,用12 * 10 + 3,得到123…这样就可以提高效率。
如果发送的是小端数据,则不能一边接收数据一边计算。
注:网络数据流发送规则是先发低地址再发高地址。我上面讲的是为什么要发送以大端存储形式的数据,发送规则是定死的,没得改。
有一些接口可以转换网络的字节序和主机字节序。
host to net
net to host
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong); //把uint32_t类型从主机序转换到网络序
uint16_t htons(uint16_t hostshort); //把uint16_t类型从主机序转换到网络序
uint32_t ntohl(uint32_t netlong); //把uint32_t类型从网络序转换到主机序
uint16_t ntohs(uint16_t netshort); //把uint16_t类型从网络序转换到主机序
主机是小端,调用htonl就可以把数据变成大端形式。是大端就原封不动返回。
socket内核本质
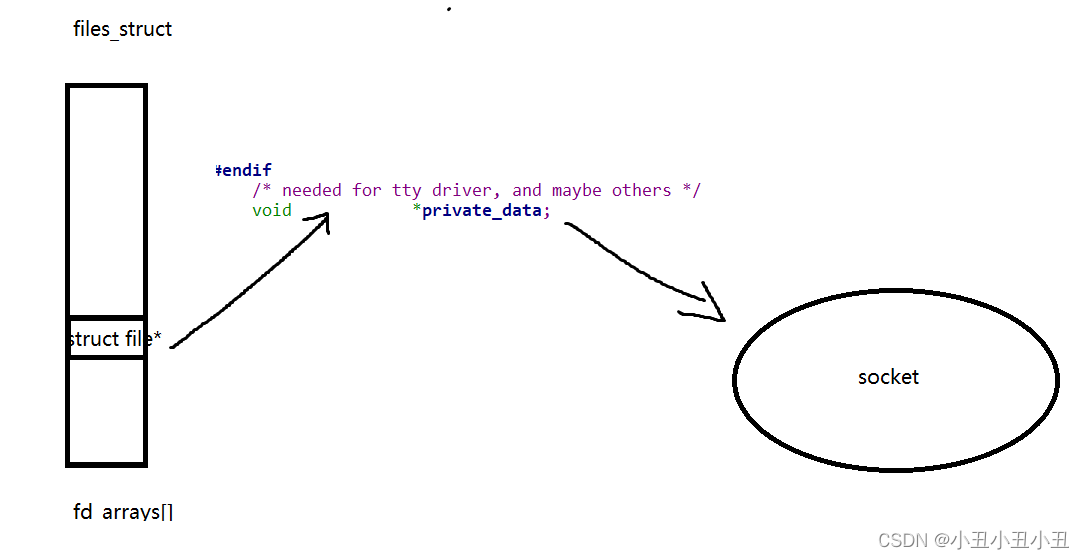
后面有一个函数叫socket,用来创建socket的。它的返回值就是一个files description。
创建一个文件后,file struct里面有一个成员叫private_data,它可以帮助操作系统找到socket这个数据结构
图示:

socket编程接口
常见的接口有:
// 创建 socket 文件描述符 (TCP/UDP, 客户端 + 服务器)
int socket(int domain, int type, int protocol);
// 绑定端口号 (TCP/UDP, 服务器)
int bind(int socket, const struct sockaddr *address,
socklen_t address_len);
// 开始监听socket (TCP, 服务器)
int listen(int socket, int backlog);
// 接收请求 (TCP, 服务器)
int accept(int socket, struct sockaddr* address,
socklen_t* address_len);
// 建立连接 (TCP, 客户端)
int connect(int sockfd, const struct sockaddr *addr,
socklen_t addrlen)
socket API是一层抽象的网络编程接口,适用于各种底层网络协议,如IPv4、IPv6,以及后面要讲的UNIX Domain Socket. 然而, 各种网络协议的地址格式并不相同。
也就是说,用不同的协议就要传不同类型的参数。
为了更好的管理这些不同的协议地址结构体,操作系统又使用了多态。在这些结构体上面封装了一个sockaddr的结构体。
sockaddr结构
比如如果要使用IPv4协议,传参就要传sockaddr_in类型的协议地址结构体。如果要使用IPv6,就要传sockaddr_in6协议地址结构体。
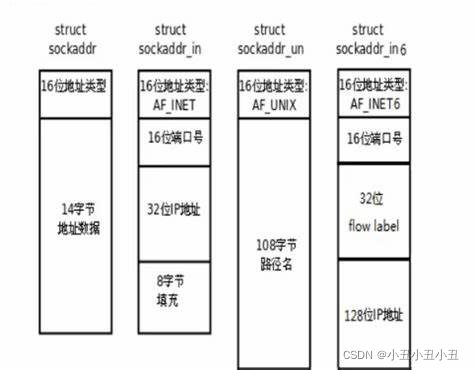
操作系统是怎么区分你传进来的是哪一个类型的地址呢?
IPv4、IPv6地址类型分别定义为常数AF_INET、AF_INET6. 这样,只要取得某种sockaddr结构体的首地址,不需要知道具体是哪种类型的sockaddr结构体,就可以根据地址类型字段确定结构体中的内容。
传进去之后,要使用具体协议的地址时强转回对应类型即可。
用下列命令来查看一下sockaddr_in的实现

我们看一下sockaddr_in在linux头文件下的代码:
第一个sin_family就是协议家族,填的是16位的地址类型。
第二个sin_port是端口号
第三个sin_addr 是IP地址,虽然它的类型是一个结构体,但是我们可以看一下这个结构体是啥:其实就是一个32位的整型
上面几个成员很重要,因为后面初始化sockaddr_in要自己去初始化。(c语言没有构造函数)
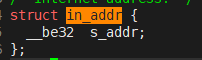
第四个_pad是填充字段
简易udp网络程序(各种函数的讲解)
本地测试版
写网络程序的过程大致如图:
服务端创建socket,并把sockaddr初始化好,绑定socket和sockaddr的信息。
客户端创建socket即可。发送的时候再初始化一下远端的sockaddr。
创建流程:
server端:
1.创建socket
2.bind
3recvfrom
client端:
1.创建socket
2.sendto(不用bind,后面讲原因)
server端代码:
#include <iostream>
#include <sys/types.h>
#include <sys/socket.h>
#include <unistd.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <string>
#include <stdlib.h>
using namespace std;
class udpServer
{
private:
string ip;//server的ip地址
int port;//server的端口号
int sock;//server的sock,sock本质是一个文件而已
public:
udpServer(string _ip = "127.0.0.1", int _port = 8080) :ip(_ip), port(_port) {}
void udpServerInit()
{
//socket通信流程
//第一步创建socket,相当于打开文件,向网卡说明传输的协议和方式
//第二步是把socket和ip和port绑定在一起(bind())
sock = socket(AF_INET, SOCK_DGRAM, 0);
//初始化sockaddr,其实就是初始化socket
struct sockaddr_in local;
socklen_t addrlen = sizeof(local);
//绑定,如果绑定成功就把sockaddr_in里面的成员ip和port赋初值
local.sin_family = AF_INET;//使用ipv4协议
local.sin_port = htons(port);//端口号
local.sin_addr.s_addr = inet_addr(ip.c_str());//ip
bind(sock, (struct sockaddr*)&local, addrlen);//绑定,有可能会绑定失败的,最好加if
}
void start()
{
char msg[100];
while(1)
{
msg[0] = 0;
struct sockaddr_in peer;
socklen_t addrlen = sizeof(peer);
//从远端接收数据, 第一个参数是sockfd, 第二个参数是接收信息的缓冲区,第三个信息是希望接收的长度
//第四个参数是接收不到信息时阻塞等待还是其他等待(0是阻塞等待)
//第五个参数是远端的socket地址,是一个输出型参数,因为要获取远端socket地址的时候要先创建再传,不需要就给nullptr即可
//第6个参数是远端socket地址的结构体大小
ssize_t s = recvfrom(sock, msg, sizeof(msg) - 1, 0, (struct sockaddr*)&peer, &addrlen);
if(s > 0)
{
msg[s] = 0;
cout << "client在说: " << msg << endl;
string echo_string = msg;
echo_string += " [echo server]";
sendto(sock, echo_string.c_str(), echo_string.size() , 0 , (struct sockaddr*)&peer, addrlen);
}
}
}
~udpServer()
{
close(sock);
}
};
注意事项
有几个点要讲一下:
0.socket函数是创建一个套接字(先不要管怎么创建的,反正它可以让你上网)
- socket的参数第一个是遵守的协议,比如AF_INET就是ipv4.
- 第二个参数是套接字种类,不同的套接字用不同的协议。比如tcp用流式套接字,udp用数据包套接字
1.这里写的ip地址127.0.0.1是本机环回地址,通常用来进行网络通信代码的本地测试。
2.有个bind函数,这个函数是用来绑定socket和socket地址的关系的。因此要先初始化好socket地址。
- 这种写法基本是固定的了。
由于是本地的port有可能要考虑大小端的问题。因此要用接口htons来变成大端上传到网上。
ip地址也是同理,这里的ip地址是个字符串,传上去应该是一个4字节整型。这里有接口可以直接使用
它的作用就是将字符串的ip地址直接转换成大端的4字节整形
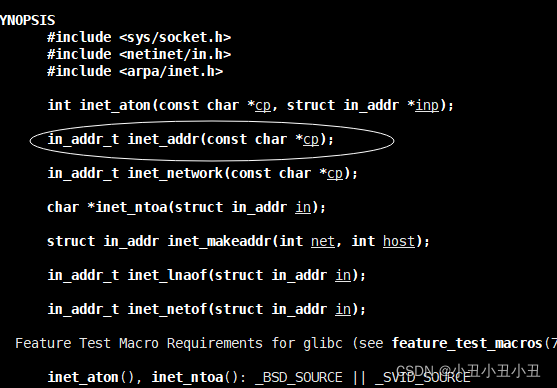
struct sockaddr_in local;
socklen_t addrlen = sizeof(local);
//绑定,如果绑定成功就把sockaddr_in里面的成员ip和port赋初值
local.sin_family = AF_INET;//使用ipv4协议
local.sin_port = htons(port);//端口号
local.sin_addr.s_addr = inet_addr(ip.c_str());//ip
bind(sock, (struct sockaddr*)&local, addrlen);//绑定,有可能会绑定失败的,最好加if
3.ssize_t和size_t,一个是有符号(signed)整形和无符号整型。
4.从远端读取数据要使用recvfrom这个函数。
第一个参数是本地的sockfd,第二个参数是读取到的缓冲区,第三个参数是读取的大小,第四个参数是没有数据的时候等待的方式,一般是阻塞等待,也就是填0.第五个参数就是远端socket的地址sockaddr和sockaddr结构体的大小
第五个和第六个参数是输出型参数,也就是说,如果你传入了这两个参数。在你接收到数据之后,你也就获取到了远端sockaddr了,你就可以发送信息给远端了。(如果你不想发送数据给远端,你也可以不传这两个参数)
5.要发送数据的话要使用sendto这个函数
-
前面几个参数不讲了
最重要的是最后两个参数。
一个是要发送到的目标socket的sockaddr,一个是sockaddr的大小。 -
问题是我们怎么获取目标socket1的sockaddr?
还是像之前初始化sockaddr一样,只不过这次我们不像服务器那样自己初始自己的,由于socket已经被绑定到了服务器端,因此我们只需要在本地创建一个临时的sockaddr,它的ip和port和服务器端的socket一样即可。(这是针对客户端说的,服务端读取数据的时候就已经可以通过输出型参数获取了远端的sockaddr了)
客户端代码:
#include <iostream>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
using namespace std;
class udpClient
{
private:
int sock;
string ip;
int port;
public:
udpClient(string _ip = "127.0.0.1", int _port = 8080) :ip(_ip), port(_port){}
void udpClientInit()
{
//客户端不需要绑定
sock = socket(AF_INET, SOCK_DGRAM, 0);
}
void start()
{
string s;
//远端sockaddr就是服务端的sockaddr,初始化一下就可以发送数据了
struct sockaddr_in peer;
peer.sin_family = AF_INET;
peer.sin_port = htons(port);
peer.sin_addr.s_addr = inet_addr(ip.c_str());
socklen_t addrlen = sizeof peer;
char buf[200];
while(1)
{
buf[0] = 0;
cout << "please enter : ";
cin >> s;
if(s == "quit") break;
sendto(sock, s.c_str(), s.size(), 0, (struct sockaddr*)&peer, addrlen);
ssize_t s = recvfrom(sock, buf, sizeof(buf) - 1, 0, nullptr, nullptr);//从服务端中读取数据,我已经知道它的sockaddr了,不用传了。
if(s > 0)
{
buf[s] = 0;
cout << "server echo : " << buf << endl;
}
}
}
~udpClient()
{
close(sock);
}
};
为什么客户端不需要绑定呢?
1.绑定的意思就是这个ip和端口号只属于我自己的了。客户端如果要绑定一个ip和端口号,很容易出错,因为有可能其他客户端拥有了这个ip和端口号,从而冲突
2.之前说过每一个进程的端口号都是唯一的,但是客户端进程不需要一个固定的端口号,它只要是唯一的即可。选择唯一的ip和端口号是操作系统帮我们做好的。
3.服务器要绑定的原因是服务器很稳定,基本不会退出,它一直在运行。
绑定的初步认识
所谓绑定,其实是将用户区的数据导入到内核区。
这就是用户区的初始化了一下socket,内核并没有拿到这些数据,也没办法给你处理。
struct sockaddr_in local;
socklen_t addrlen = sizeof(local);
//绑定,如果绑定成功就把sockaddr_in里面的成员ip和port赋初值
local.sin_family = AF_INET;//使用ipv4协议
local.sin_port = htons(port);//端口号
local.sin_addr.s_addr = inet_addr(ip.c_str());//ip
这一句代码才是让内核知道了这个socket的信息
bind(sock, (struct sockaddr*)&local, addrlen);
为什么又称udp是无链接的传输。很简单,就是因为客户端不需要绑定,没有绑定,内核就没有拿到socket的信息。也就没有链接
内核代码:绑定其实就是往sock里面填数据。
netstat命令查看端口
可以用
netstat -ntlp //查看当前所有tcp端口·
netstat -nulp //查看当前所有udp端口

网络版
实际上服务端的ip地址不会自己填,一般会写成INADDR_ANY
网络地址为INADDR_ANY,这个宏表示本地(server端)的任意IP地址,因为服务器可能有多个网卡,每个网卡也可能绑定做个IP地址,这样设置可以在所有的IP地址上监听,直到与某个客户端建立了链接时才确定下来到底用哪个IP地址。
其实就是把IP改了就可以了。

tcp
tcp和udp的区别:
- udp是无链接的服务器,tcp是有链接的服务器。因此tcp的接口也更多一点。
可能有这个疑惑?udp不是也用了server的ip和port吗,为什么是无链接的。
答:udp确实用了,但是它只是根据这个ip和port确定自己要发给哪个进程而已,并没有connect - udp是数据包类型的套接字SOCK_DGRAM,tcp是SOCK_STREAM类型的套接字。
- 流式就是像流水一样一直不断地输出输入数据,数据包就是像寄快递一样,一样一样寄过去。
- 由于tcp是流式套接字,因此它的读取和写入可以直接用read和write。(因为文件也是流式结构),但是一般我们选择用recv和send,但本质是一样地,man手册也是这么描述地。

创建流程
创建流程:
server端:
1.创建socket
2.bind
3.listen(监听客户端)
4.accept(获取客户端的链接),一个客户端只能获取一次,重复获取会导致通信失败。
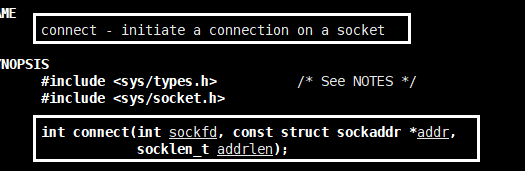
client端:
和udp唯一的差别就是tcp的client需要connect。为什么成tcp是有链接的传输,原因就是这个connect。connect就是获取链接的。
1.创建socket
2.connect
tcp的server端有很多个socket,它们负责的工作是不同的。第一个socket叫做listen_socket,负责监听。在服务器初始化的时候就开始监听了。
它有两个参数,第一个参数是当前服务器的监听sockfd。第二个参数是监听最大的等待队列长度。
什么是监听的时候的等待队列?
一个客户端肯定不允许没有上限的客户端一直连接,因此当达到backlog长度后,后面再连接的客户端都不能再连接了。
accept函数
accept函数是获取一个客户端链接的。它的返回值就是一个sockfd,用来存着这个链接关系。因此获取之后我们就知道对面客户端的套接字了,可以给对面发信息了。
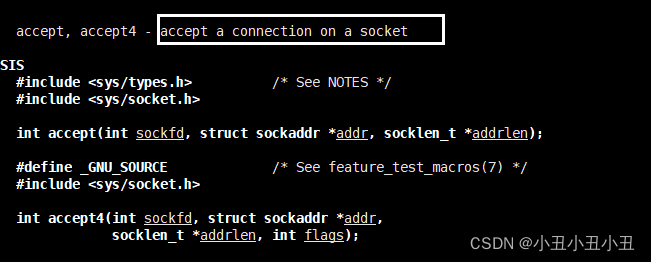
accept对于一个客户端只能获取一次,因此写代码地时候特别要注意不要重复accept相同的客户端。
listen和accept是捆绑出现的,有listen_socket才可以accept
除了listen和accept,tcp的服务端和udp是一样的。
单进程版
单进程没什么实际价值,但是可以先搭出来框架。
server端代码:
#include <iostream>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <cstring>
using namespace std;
#define BACKLOGSIZE 5
class tcpServer
{
private:
int listen_sock;
int port;
public:
tcpServer(int _port = 8080) :port(_port) {}
void tcpServerInit()
{
listen_sock = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in local;
local.sin_family = AF_INET;
local.sin_port = htons(port);
local.sin_addr.s_addr = htonl(INADDR_ANY);
socklen_t addrlen = sizeof local;
if(bind(listen_sock, (struct sockaddr*)&local, addrlen) < 0)
{
cerr << "bind error" << endl;
exit(-1);
}
if(listen(listen_sock, BACKLOGSIZE) < 0)
{
cerr << "listen error" << endl;
exit(-2);
}
}
void service(int sock)
{
char buf[100];
while(1)
{
buf[0] = 0;
ssize_t s = recv(sock, buf, sizeof buf - 1, 0);
if(s > 0)
{
buf[s] = 0;
send(sock, buf, strlen(buf), 0);
cout << "client : " << buf << endl;
}
else if(s == 0)
{
cout << "client quit" << endl;
break;
}
else
{
cout << "recv client data error" << endl;
}
}
}
void start()
{
char buf[100];
while(1)
{
struct sockaddr_in peer;
socklen_t addrlen = sizeof peer;
int sock = accept(listen_sock, (struct sockaddr*)&peer, &addrlen);
if(sock < 0)
{
cerr << "connect fail" << endl;
continue;
}
else
{
cout << "get a new link" << endl;
}
service(sock);
}
}
};
和udp唯一的差别就是tcp的client需要connect。为什么成tcp是有链接的传输,原因就是这个connect。connect就是获取链接的。
#include <iostream>
#include <sys/types.h>
#include <arpa/inet.h>
#include <string>
#include <netinet/in.h>
#include <sys/socket.h>
#include <unistd.h>
using namespace std;
class tcpClient
{
private:
string ip;
int port;
int sock;
public:
tcpClient(string _ip = "172.0.0.1", int _port = 8080) :ip(_ip), port(_port) {}
void tcpClientInit()
{
sock = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in peer;
peer.sin_family = AF_INET;
peer.sin_port = htons(port);
peer.sin_addr.s_addr = inet_addr(ip.c_str());
if(connect(sock, (sockaddr*)&peer, sizeof(peer)) < 0)
{
cout << "connect error" << endl;
exit(-1);
}
}
void start()
{
string msg;
while(1)
{
cout << "please enter : ";
fflush(stdout);
getline(cin, msg);
send(sock, msg.c_str(), msg.size(), 0);
}
}
};
多进程版
刚刚的单进程版本我们稍加思考一下就能发现,这个服务器是不能让两个客户端同时连接上的。因为当客户端在输入的时候,服务端在接收的时候,一个执行流是不能又跑去执行accept的。
要让多个客户端可以连接上这个服务端,可以让子进程去recv信息,父进程一直accept即可。
就加上这几句代码就好了。
pid_t pid = fork();
if(pid == 0)
{
close(listen_sock);
service(sock);
exit(0);
}
close(sock);
有几点要说的:
- 子进程close监听套接字的原因是子进程不需要监听,它只需要accept得到的socket就可以接收信息了。
- 子进程接收完信息就可以退出进程了,剩下的事情它不需要参与了。
- 父进程最后关闭accept得到的socket的原因是:由于子进程的文件描述符表是根据父进程模板拷贝得到的(管道那里讲过),因此子进程已经获取了对应客户端的socket了,父进程就不需要了,可以关闭。如果不关闭,父进程的可用的文件描述符只会越来越少。
- 可能会有这个疑惑:为什么父进程不用wait子进程,这样不会造成僵死吗?答案是会的,因此我们要避免这个问题。之前信号那一节讲过,子进程退出的时候会给父进程发送SIGCHLD信号,如果把这个信号的默认处理行为改为SIG_IGN,子进程退出就不会变成僵尸,而且这个性质是linux系统特有的。因此在serverInit开头加上即可
signal(SIGCHLD, SIG_IGN)
多进程版还有一种写法:
是通过创建孙子进程,让孙子进程进行读取数据的操作。
代码:
pid_t pid = fork();
if(pid > 0)
{
if(fork() > 0) exit(0);//子进程退出
close(listen_sock);
service(sock);//孙子进程执行
exit(0);
}
close(sock);
父进程是不用等待孙子进程的,这样孙子进程就变成孤儿了,由系统管理。(我认为不好)
这种进程管理方式不好,因为要fork多一个进程,开销太大了。
运行中可以去观察一下进程的数量。有几个命令,在多线程版那里讲。
多进程版本的特点:健壮性比较好,但是比较吃资源,效率底下
多线程版
既然fork进程开销那么大,我们也可以使用light weight proccess来处理。
代码也很简单,加上几句就可以了。
创建线程
pthread_t tid;
pthread_create(&tid, nullptr, thread_run, (void*)&sock);
线程的代码,注意要加static,原因是成员函数里面自带this指针。
注意:之前写的service成员函数由于里面没有使用到成员变量,可以设计成静态的,这样线程代码就能直接用了。
static void* thread_run(void* arg)
{
int sock = *(int*)arg;
pthread_detach(pthread_self());
service(sock);
}
注意:由于之间讲过,主线程如果不等待其他线程,会造成内存泄漏。因此必须要pthread_join一下,但是join了之后就会造成堵塞。我们可以让这个新线程自己分离就不会有内存泄漏的问题了。(pthread_detach)
命令检测是否可以一个服务器跑多个客户端
我们知道&可以把程序放到后台运行,但是同一个程序是没有办法开两个然后放到后台运行的,必须要让其中一个停止才可以。因此我们可以先让它在前台运行,然后按ctrl + Z,让它跑到后台停止。此时这个客户端并没有退出,它相当于一直不输入的客户端而已。
我们放多几个这样的客户端进后台,可以用jobs命令查看后台的进程。
然后我们可以去用ps -aL来看线程(多线程那里讲过)。我们发现有四个线程在跑,其中一个是主线程,其他三个是创建出来的线程。
要想把刚刚那些stop的后台进程拿到前台终止,可以用fg(front ground) + 序列号


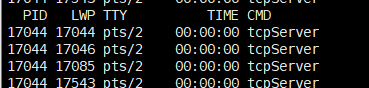
健壮性不强(原因:一个线程发生错误,可能会导致系统直接发信号给进程终止掉整个进程)
不那么吃资源,效率相对较高。
大量客户端会导致系统会存在大量执行流,pcb切换有可能成为效率底下的重要原因。
因此这三种方案都不怎么样
线程池版本
线程池这里写的功能是一次英译中翻译,翻译完客户端就退出了。和前面有点不同。
这个写的时候真的细节满满,稍不留神就出bug了。
注:之前的线程池写的还是有点问题的,不太适用来写服务器,要改一改。
线程池对比多线程好处在于:它可以提前创建线程,减少创建线程的时间,而且可以防止恶意连接。有可能有人一直向服务器发送连接,服务器可能就顶不住了。线程池有最大线程数的上限。
先贴代码再讲注意事项:
threadpool.hpp代码:
#pragma once
#include <iostream>
#include <stdio.h>
#include <pthread.h>
#include <queue>
#include <unistd.h>
#include <map>
#include <string>
#include <sys/types.h>
#include <sys/socket.h>
#include <errno.h>
#include <stdio.h>
#include <string.h>
using namespace std;
struct dict
{
map<string, string> dictionary;
dict()
{
dictionary["apple"] = "苹果";
dictionary["banana"] = "香蕉";
dictionary["pineapple"] = "菠萝";
}
~dict()
{
dictionary.clear();
}
};
class Task
{
public:
int sock;
public:
Task(int _sock) :sock(_sock) {}
Task() {}
~Task() {
cout << "close the sock" << endl;
close(sock);
}
void run()
{
cout << "Task is running" << ' ' << "sock : " << sock << endl;
dict dictionary;
char buffer[100];
ssize_t s = recv(sock, buffer, sizeof(buffer) - 1, 0);
if(s > 0)
{
buffer[s] = 0;
string key = buffer;
send(sock, dictionary.dictionary[key].c_str(), dictionary.dictionary[key].size(), 0);
}
else
{
cout << "recv failed" << endl;
cerr << strerror(errno);
}
}
};
template<class T>
class ThreadPool
{
private:
//int quit;
queue<T*> q;
pthread_cond_t cond;//队列为空的时候消费者等待的条件
pthread_mutex_t lock;
public:
ThreadPool()
{
//quit = 0;
ThreadPoolInit();
}
bool IsEmpty()
{
return q.size() == 0;
}
static void* consumer(void* arg)
{
ThreadPool<T> *p = (ThreadPool<T>*) arg;
while(/*!p->quit*/true)
{
pthread_mutex_lock(&p->lock);
while(/*!p->quit &&*/ p->IsEmpty())
pthread_cond_wait(&p->cond, &p->lock);
T* t;
p->Get(&t);
pthread_mutex_unlock(&(p->lock));
t->run();
delete t;
}
}
void Get(T** out)
{
*out = q.front();
q.pop();
}
void Put(T &in)
{
pthread_mutex_lock(&lock);
q.push(&in);
pthread_mutex_unlock(&lock);
pthread_cond_signal(&cond);
}
void ThreadPoolInit()
{
pthread_cond_init(&cond, nullptr);
pthread_mutex_init(&lock, nullptr);
for(int i = 0; i < 5; i++)
{
pthread_t tid;
pthread_create(&tid, nullptr, consumer, (void*)this);
}
}
~ThreadPool()
{
pthread_mutex_destroy(&lock);
pthread_cond_destroy(&cond);
}
};
注
- 线程池里面的队列一定要写成
queue<T*> q,不仅仅是为了节约空间,还和任务的析构有关系。线程池里面有一个get函数,get之后就要执行q.pop(), 如果queue里面放的是已经创建好的对象,q.pop()之后对象就会自动析构,即使你拿到了那个对象(sock),这个对象也已经释放了(sock被关闭了,会照成bad file descriptor错误)。 - 任务里面放sock,任务的run()函数写读取发送信息即可。拿到sock就可以读取发送信息了
- 这里的get是输出型参数,因此如果要让一个一级指针变成输出型参数,参数的类型就要是二级指针
server端代码:
#include <iostream>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <cstring>
#include <signal.h>
#include <unistd.h>
#include <pthread.h>
#include "threadpool.hpp"
using namespace std;
#define BACKLOGSIZE 5
class tcpServer
{
private:
int listen_sock;
int port;
ThreadPool<Task>* tp;
public:
tcpServer(int _port = 8080) :port(_port), tp(nullptr) {}
void tcpServerInit()
{
signal(SIGCHLD, SIG_IGN);
listen_sock = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in local;
local.sin_family = AF_INET;
local.sin_port = htons(port);
local.sin_addr.s_addr = htonl(INADDR_ANY);
socklen_t addrlen = sizeof local;
if(bind(listen_sock, (struct sockaddr*)&local, addrlen) < 0)
{
cerr << "bind error" << endl;
exit(-1);
}
if(listen(listen_sock, BACKLOGSIZE) < 0)
{
cerr << "listen error" << endl;
exit(-2);
}
tp = new ThreadPool<Task>;
tp->ThreadPoolInit();
}
static void service(int sock)
{
char buf[100];
while(1)
{
buf[0] = 0;
ssize_t s = recv(sock, buf, sizeof buf - 1, 0);
if(s > 0)
{
buf[s] = 0;
send(sock, buf, strlen(buf), 0);
cout << "client : " << buf << endl;
}
else if(s == 0)
{
cout << "client quit" << endl;
break;
}
else
{
cout << "recv error" << endl;
break;
}
}
}
// static void* thread_run(void* arg)
// {
// int sock = *(int*)arg;
// pthread_detach(pthread_self());
// service(sock);
// }
void start()
{
while(1)
{
struct sockaddr_in peer;
socklen_t addrlen = sizeof peer;
int sock = accept(listen_sock, (struct sockaddr*)&peer, &addrlen);
if(sock < 0)
{
cerr << "connect fail" << endl;
continue;
}
else
{
cout << "get a new link" << endl;
}
//多进程写法
//pid_t pid = fork();
//if(pid == 0)
//{
// close(listen_sock);
// service(sock);
// exit(0);
//}
//close(sock);
//多线程
//pthread_t tid;
//pthread_create(&tid, nullptr, thread_run, (void*)&sock);
//线程池
//这里不能写成局部变量了,不然一下就析构了,放进去也没用,还会造成野指针。
Task* t = new Task(sock);
tp->Put(*t);
}
}
};
服务端不用怎么改,
- 在init服务端的时候把线程池初始化好即可。
- 在运行期间新建一些Task**(堆上开辟)**然后不断地放进线程池让他处理就好了。
客户端和上面的都是一样的,唯一一点区别就是发送完一次信息就算了,不用加死循环了。
inet_ntoa的一些问题
这个函数是用来将4字节的ip地址转换成点分十进制的ip地址。
我们可以看到,我们传入的参数是sockaddr_in.sin_addr,它的类型就是in_addr。但并没有出现一个缓冲区来存放这个字符串。那这个字符串放在哪里了?我们要不要手动释放?

man手册是这么说的,这个字符串被存在了一块在静态区申请的空间上(statically allocated buffer)里面。因此不用手动释放。
所有inet_ntoa出来的字符串都是放在那里的。由于多线程共享进程地址空间,因此这个statically allocated buffer 是临界资源,有可能发生线程安全问题。

当多个线程调用这个函数,最后这个区域存放的字符串是最后转换的ip地址。(但不一定,和环境有关系,centos7就没有这个问题,可能加了锁)
简易谈三次握手四次挥手
先讲一下上面我们调用的那一堆接口到底是干嘛用的。
这张图是基于TCP协议的客户端/服务器程序的一般流程
一开始服务器初始化:
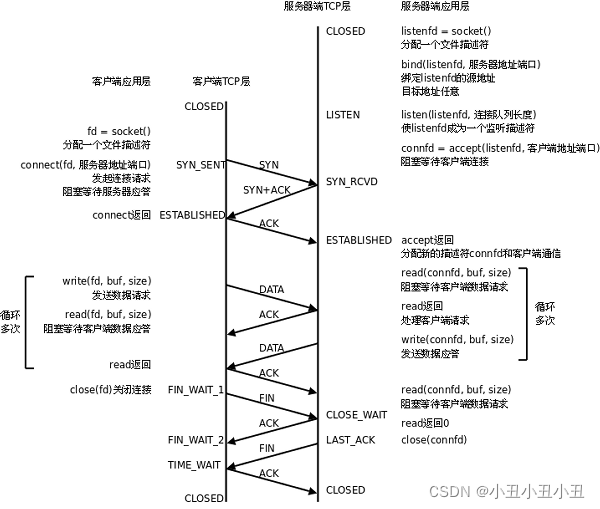
- socket 创建套接字,其实就是创建文件描述符
- 初始化sockaddr_in,其实就相当于往文件里面填入ip和port(用户层面)
- bind 将当前的文件描述符和ip/port绑定在一起(内核层面); 如果这个端口已经被其他进程占用了, 就会bind失败
- 调用listen, 声明当前这个文件描述符作为一个服务器的文件描述符, 为后面的accept做好准备;
- 调用accecpt, 并阻塞, 等待客户端连接过来
然后客户端开始试图连接服务器
- 调用socket, 创建文件描述符;
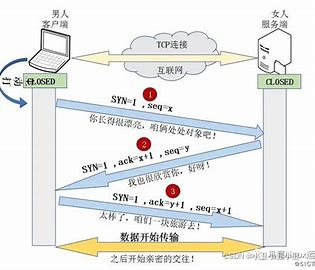
- 调用connect, 向服务器发起连接请求;connect会发出SYN段并阻塞等待服务器应答; (第一次)服务器收到客户端的SYN, 会应答一个SYN-ACK段表示"同意建立连接"; (第二次)客户端收到SYN-ACK后会从connect()返回, 同时应答一个ACK段; (第三次)。这叫三次挥手
三次挥手就是客户端连接服务器(创建链接)的过程。
这个过程和下面这张图的过程很像。先请求,对方回应,我再确定
数据传输的时候:
-
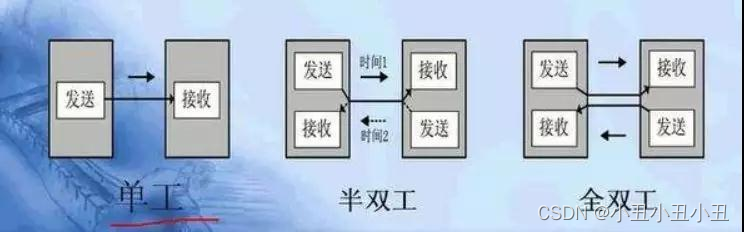
建立连接后,TCP协议提供全双工的通信服务; 所谓全双工的意思是, 在同一条连接中, 同一时刻, 通信双方可以同时写数据; 相对的概念叫做半双工, 同一条连接在同一时刻, 只能由一方来写数据;(管道就是半双工,其实管道可以说是单工的了,因为管道永远只能单向通信)
-
-
服务器从accept()返回后立刻调 用read(), 读socket就像读管道一样, 如果没有数据到达就阻塞等待;
-
这时客户端调用**write()(send函数)发送请求给服务器, 服务器收到后从read()(recv函数)**返回,对客户端的请求进行处理, 在此期间客户端调用read()阻塞等待服务器的应答;(全双工服务,其实tcp也可以做半双工)
-
循环这个过程
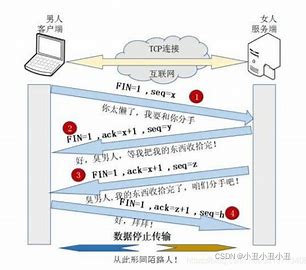
断开连接的过程(四次挥手):
- 如果客户端没有更多的请求了, 就调用close()关闭连接, 客户端会向服务器发送FIN段(第一次); 此时服务器收到FIN后, 会回应一个ACK, 同时read会返回0 (第二次);read返回之后, 服务器就知道客户端关闭了连接, 也调用close关闭连接, 这个时候服务器会向客户端发送一个FIN; (第三次)客户端收到FIN, 再返回一个ACK给服务器; (第四次)
- 这就对应于我们写的close(sock),服务端close一遍,客户端close一遍
四次挥手的过程很像下面这副图。
tcp和udp的对比
- tcp是可靠传输,udp是不可靠传输。udp很容易丢包。
tcp在connect的时候相当于创建了链接,链接是有对应的数据结构来管理的,因此tcp其实是有成本的。udp是无链接的,因此可能会更简单一些,更快一些。有些应用场景是可以允许丢包的因此不要单纯的认为tcp就比udp好 - tcp是有链接的,udp是没有链接的。tcp要connect,udp不用
3.tcp是字节流的,udp是数据报的。字节流就是数据是像流水一样的,用户收数据的时候有可能只读取了一半或者三分之一。数据报是像包裹一样,用户收数据的时候要么不读,要么读完。
文件描述符如何和socket联系起来
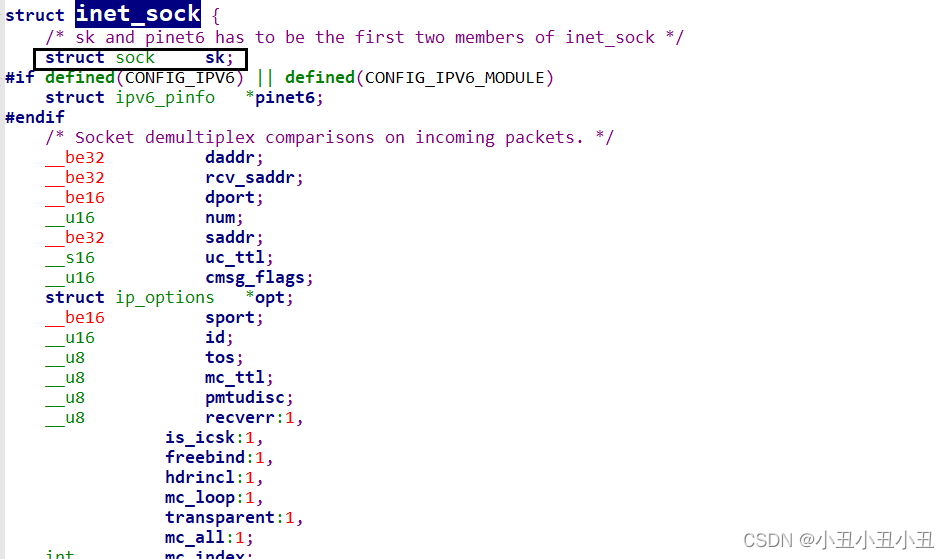
本质socket里面还有一些数据结构
struct file里面还有一个叫做private_data的成员可以指向socket结构体,可以通过sock_attach_fd函数来实现.
这样就能把文件和socket关联起来了。
socket里面还有两个重要的成员,一个是struct file*,一个是struct sock*,proto_ops*是套接字的一些函数。
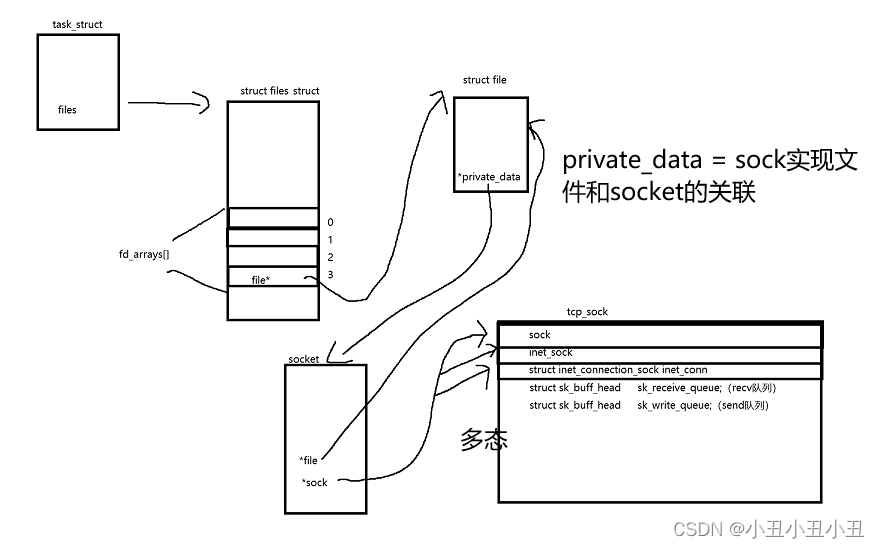
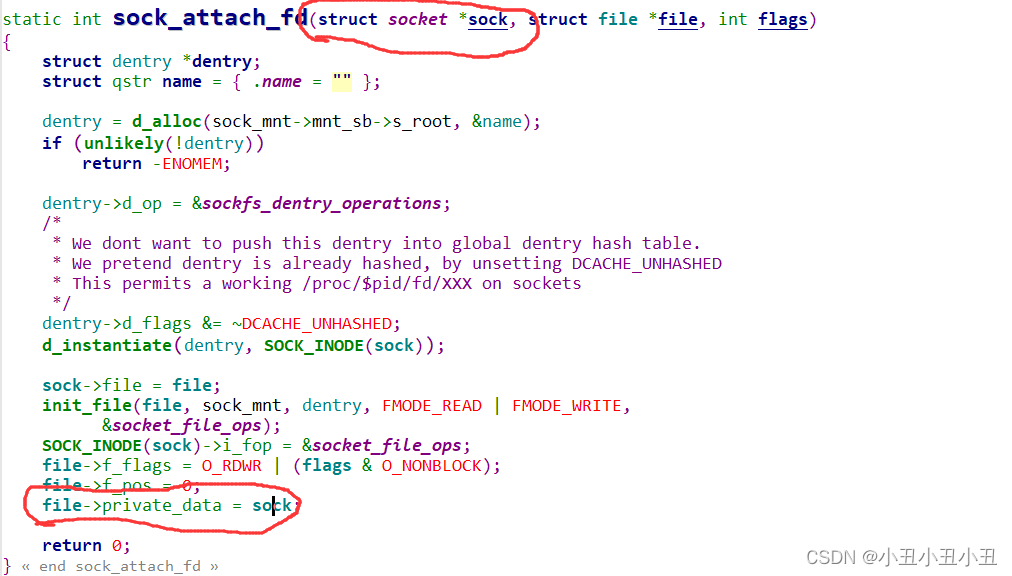
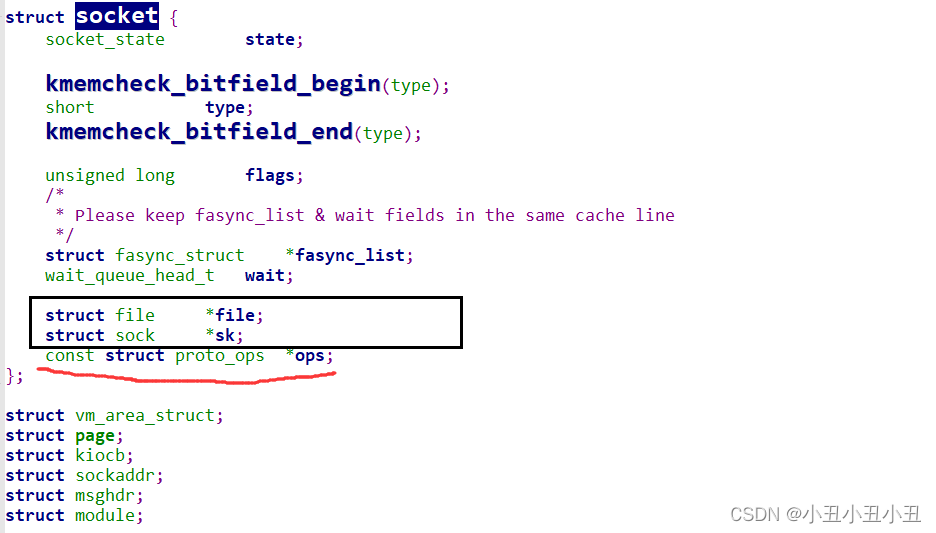
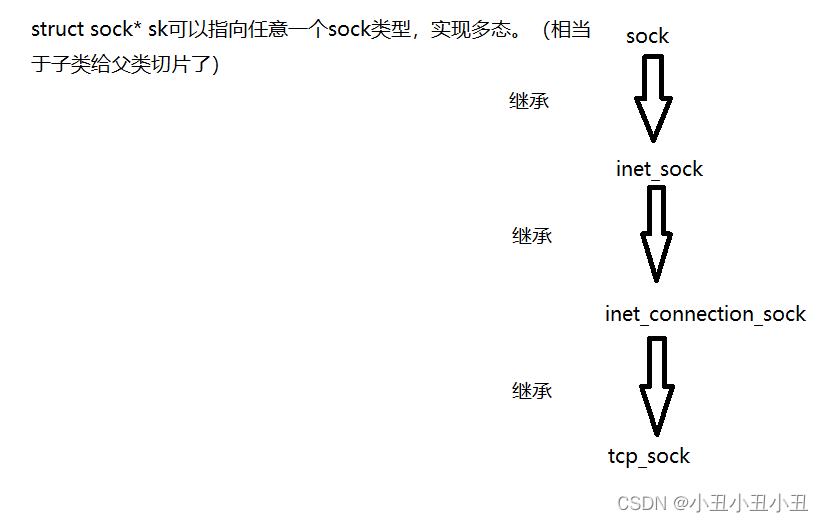
struct file* 是指向对应之前的那个文件的。sock*是指向具体的一种sock的。sock算是所有sock的祖先,后面的sock都是继承前面的sock的属性的基础上加上自己的成员。
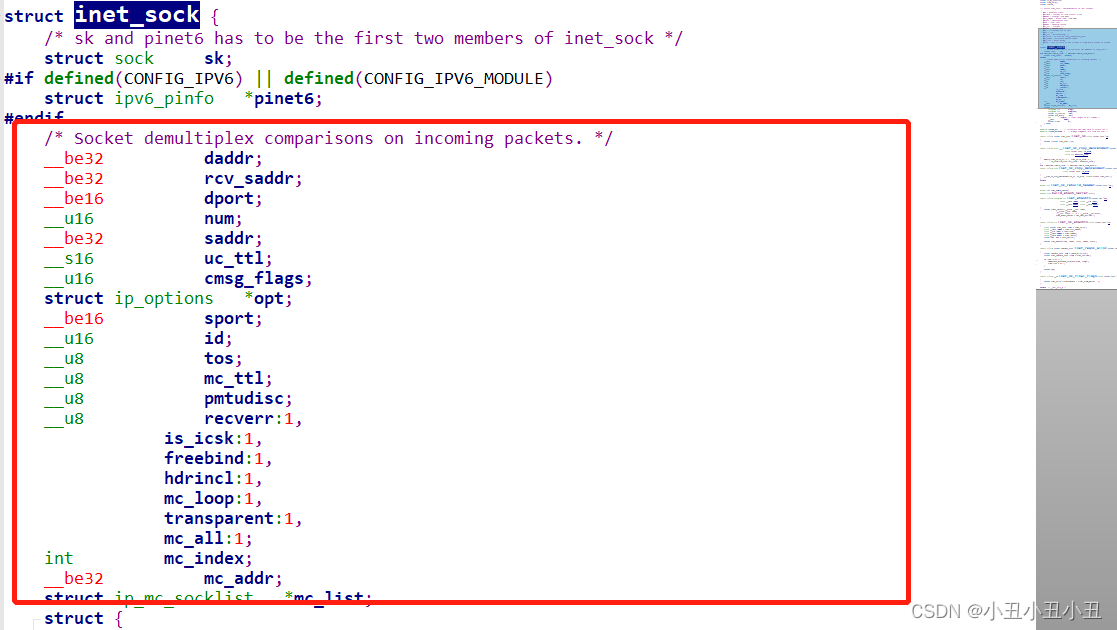
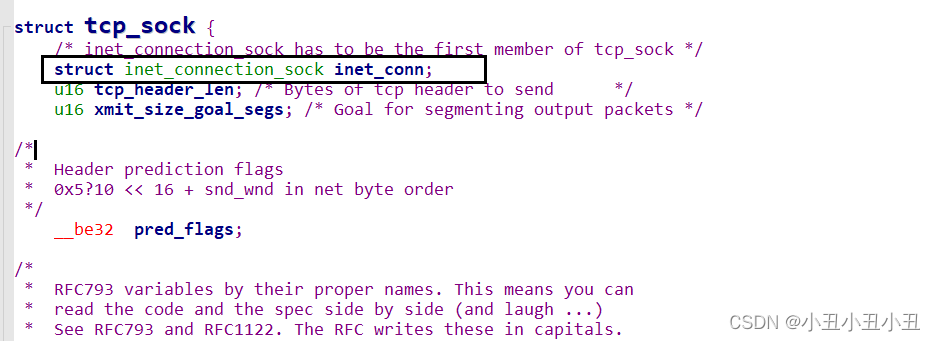
比如下面的这三个sock。
它们是继承关系。
关系如下:
最后再说一下sock里面的重要成员接收队列和发送队列。recv是从sock里面的接收队列里面拿数据,send是把数据写到发送队列里面,然后发送。

再对应一下socket()和bind()究竟干了什么?
socket就是创建了这一堆数据结构,bind就是往sock里面填sockaddr的数据。