文章目录
内容回顾
1.1 假说表示
h
(
x
)
=
g
(
θ
T
X
)
h(x)=g(\theta ^TX)
h(x)=g(θTX)
g
(
z
)
=
1
1
+
e
−
z
g(z)=\frac{1}{1+e^{-z}}
g(z)=1+e−z1
h
θ
(
x
)
h_\theta(x)
hθ(x)的作用是,对于给定的输入变量,根据选择的参数计算输出变量=1的可能性即
h
θ
(
x
)
=
P
(
y
=
1
∣
x
;
θ
)
h_\theta(x)=P(y=1|x;\theta)
hθ(x)=P(y=1∣x;θ)
假说化简得到
h
(
x
)
=
1
1
+
e
−
θ
T
x
h(x)=\frac{1}{1+e^{-\theta ^Tx}}
h(x)=1+e−θTx1
1.2 判定边界
将区域分开的函数就是模型的分界线。

1.3 代价函数
J
(
θ
)
=
1
m
∑
i
=
1
m
[
−
y
(
i
)
l
o
g
(
h
θ
(
x
(
i
)
)
)
−
(
1
−
y
(
i
)
)
l
o
g
(
1
−
x
(
i
)
)
)
]
J(\theta )=\frac{1}{m}\sum_{i=1}^{m}[-y^{(i)}log(h_\theta (x^{(i)}))-(1-y^{(i)})log(1-x^{(i)}))]
J(θ)=m1i=1∑m[−y(i)log(hθ(x(i)))−(1−y(i))log(1−x(i)))]
∂
J
(
θ
)
∂
θ
j
=
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
(
i
)
\frac{\partial J(\theta )}{\partial \theta _j}=\frac{1}{m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})x^{(i)}
∂θj∂J(θ)=m1i=1∑m(hθ(x(i))−y(i))x(i)
1.4 高级优化
在完成计算代价函数和代价函数的偏导数项的适合可以使用梯度下降。然而还有一些更高级的算法来求解上面二者:局部优化法又称共轭梯度法(BFGS)和有限内存局部优化法(LBFGS)。算法优点:在其中任何一个算法之中都不需要手动选择学习率 α \alpha α,其有一个智能的内部循环,称为线性搜索,可以自动尝试不同的学习速率。
1.5 正则化
添加正则化项解决过拟合问题。
正则化线性回归的代价函数:
J
(
θ
)
=
1
2
m
∑
i
=
1
m
[
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
λ
∑
j
=
1
m
θ
j
2
]
J(\theta )=\frac{1}{2m}\sum_{i=1}^{m}[(h_\theta (x^{(i)})-y^{(i)})^2+\lambda \sum_{j=1}^{m}\theta_j^{2}]
J(θ)=2m1i=1∑m[(hθ(x(i))−y(i))2+λj=1∑mθj2]
θ
j
:
=
θ
j
(
1
−
a
λ
m
)
−
a
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
\theta_j :=\theta_j(1-a\frac{\lambda }{m})-a\frac{1}{m}\sum_{i=1}^{m}(h_\theta (x^{(i)})-y^{(i)})x_j^{(i)}
θj:=θj(1−amλ)−am1i=1∑m(hθ(x(i))−y(i))xj(i)
正则化的逻辑回归模型:
J
(
θ
)
=
1
m
∑
i
=
1
m
[
−
y
(
i
)
l
o
g
(
h
θ
(
x
(
i
)
)
)
−
(
1
−
y
(
i
)
)
l
o
g
(
1
−
x
(
i
)
)
)
]
+
λ
2
m
∑
i
=
1
m
θ
j
(
i
)
J(\theta )=\frac{1}{m}\sum_{i=1}^{m}[-y^{(i)}log(h_\theta (x^{(i)}))-(1-y^{(i)})log(1-x^{(i)}))]+\frac{\lambda }{2m} \sum_{i=1}^{m}\theta _j^{(i)}
J(θ)=m1i=1∑m[−y(i)log(hθ(x(i)))−(1−y(i))log(1−x(i)))]+2mλi=1∑mθj(i)
ex2 逻辑回归作业
2.1 Part 1: Plotting 绘图
数据集意义:数据集有100位学生的两次考试成绩(存入X中),拟通过逻辑回归(二分类模型),估计每个学生的录取概率(录取表明输出y为1,反之输出y为0)。
Matlab
主函数
% 提取数据
data = load(‘ex2data1.txt’);
X = data(:, [1, 2]); y = data(:, 3);
% 加载子函数plotData
plotData(X, y);
% 设置x、y轴
hold on;
% Labels and Legend
xlabel(‘Exam 1 score’)
ylabel(‘Exam 2 score’)
% 添加图例
legend(‘Admitted’, ‘Not admitted’)
hold off;
plotData.m
pos = find(y==1); neg = find(y==0);
plot(X(pos, 1),X(pos,2), 'k+', 'LineWidth', 2, 'markersize',7);
plot(X(neg, 1),X(neg,2), 'ko', 'MarkerFaceColor', 'y');
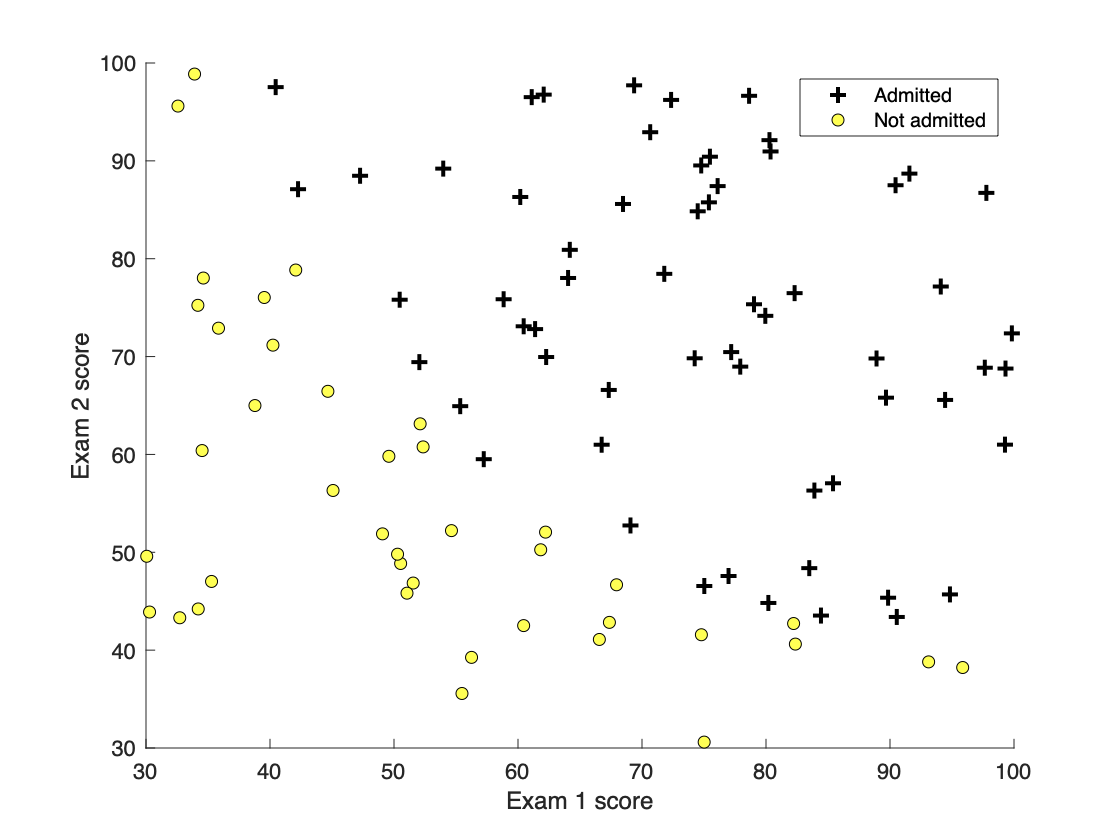
2.2 Part 2: Compute Cost and Gradient 计算代价和梯度
主函数
% 存入X的行/列数
[m, n] = size(X);
% 初始化X、theta
X = [ones(m, 1) X];
initial_theta = zeros(n + 1, 1);
% Compute and display initial cost and gradient
[cost, grad] = costFunction(initial_theta, X, y);
% Compute and display cost and gradient with non-zero theta
test_theta = [-24; 0.2; 0.2];
[cost, grad] = costFunction(test_theta, X, y);
computeCost.m
J = (1/m)*(-y'*log(sigmoid(X*theta))-(1-y)'*log(1-sigmoid(X*theta)));
grad =(1/m)*X'*(sigmoid(X*theta)-y);
2.3 Part 3: Optimizing using fminunc利用fminuc函数优化
该部分不需要填写代码,根据fminuc函数和plot函数绘制决策边界线。
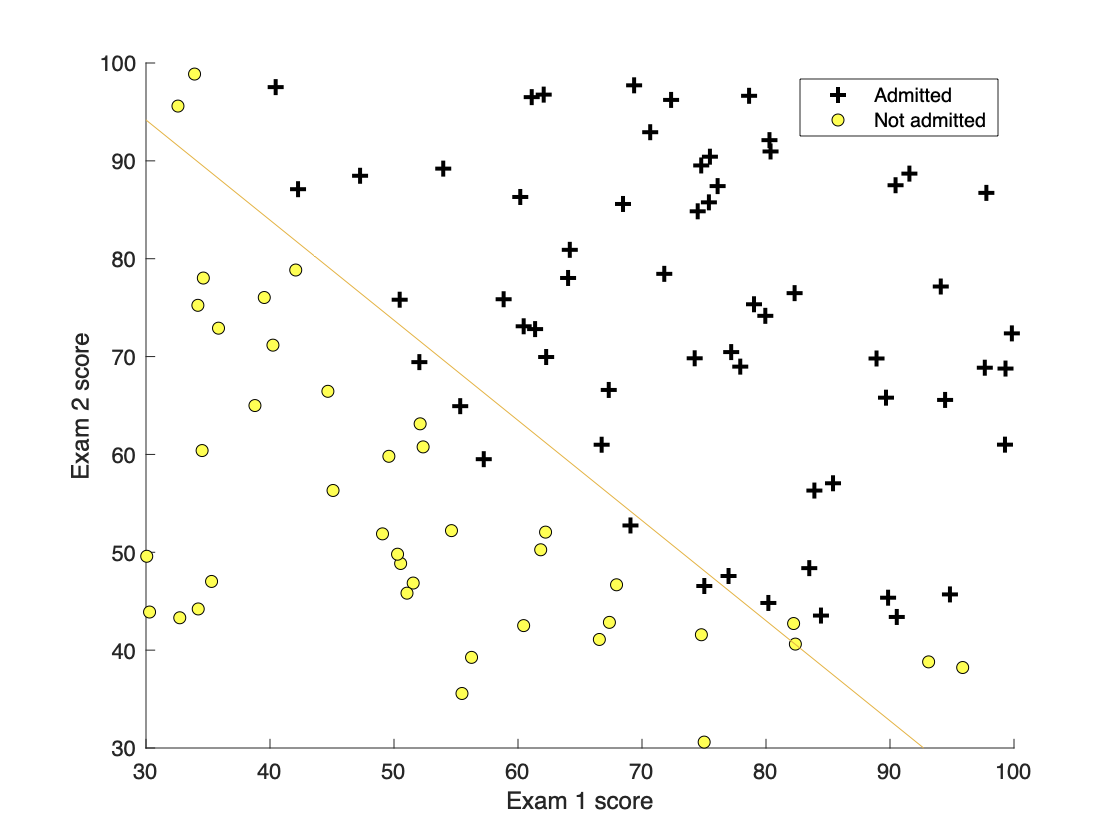
2.4 Part 4: Predict and Accuracies 预测和准确度计算
主函数
prob = sigmoid([1 45 85] * theta);
p = predict(theta, X);
fprintf(‘Train Accuracy: %f\n’, mean(double(p == y)) * 100);
predict.m
G =sigmoid(X*theta);
for i= 1 :m
if G(i)<0.5
G(i)=0;
else
G(i)=1;
end
end
ex2 正则化的逻辑回归
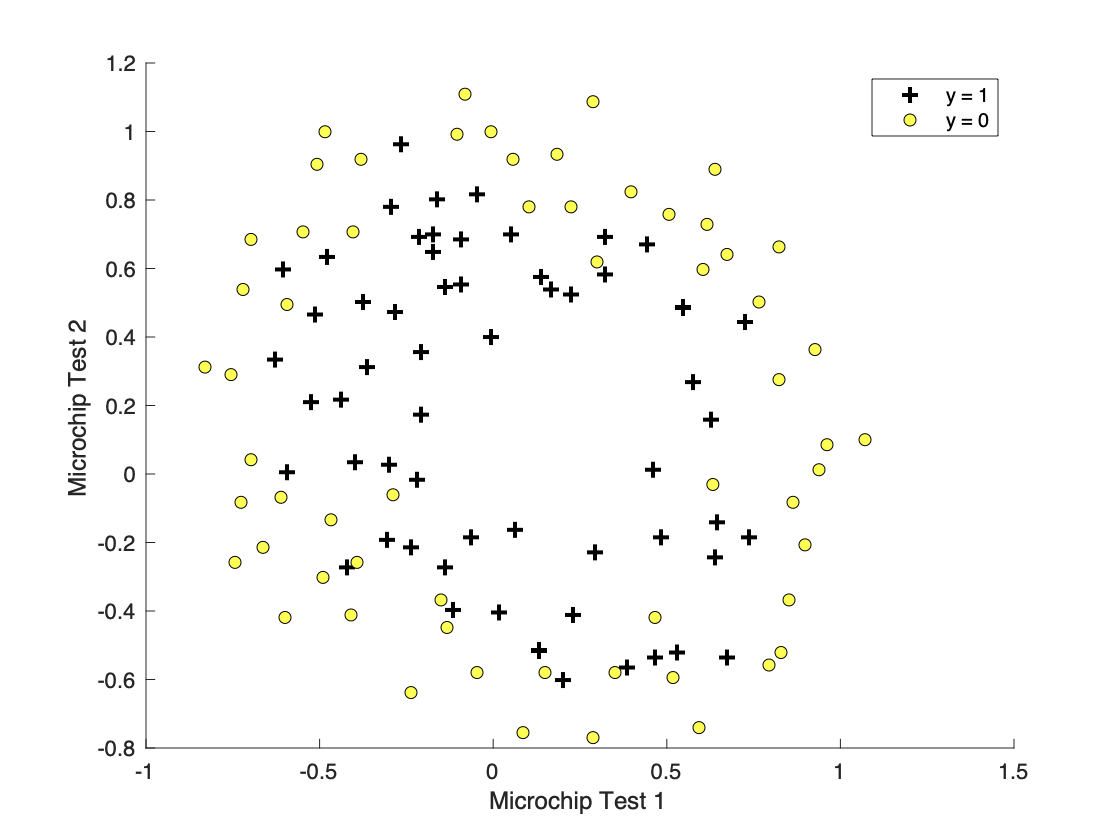
实际意义:手里有一批芯片两次测试及合格与否的数据,希望建立一个逻辑回归模型,根据新芯片的测试数据来预测合格与否。
3.1 Part 1: Regularized Logistic Regression正则化逻辑回归
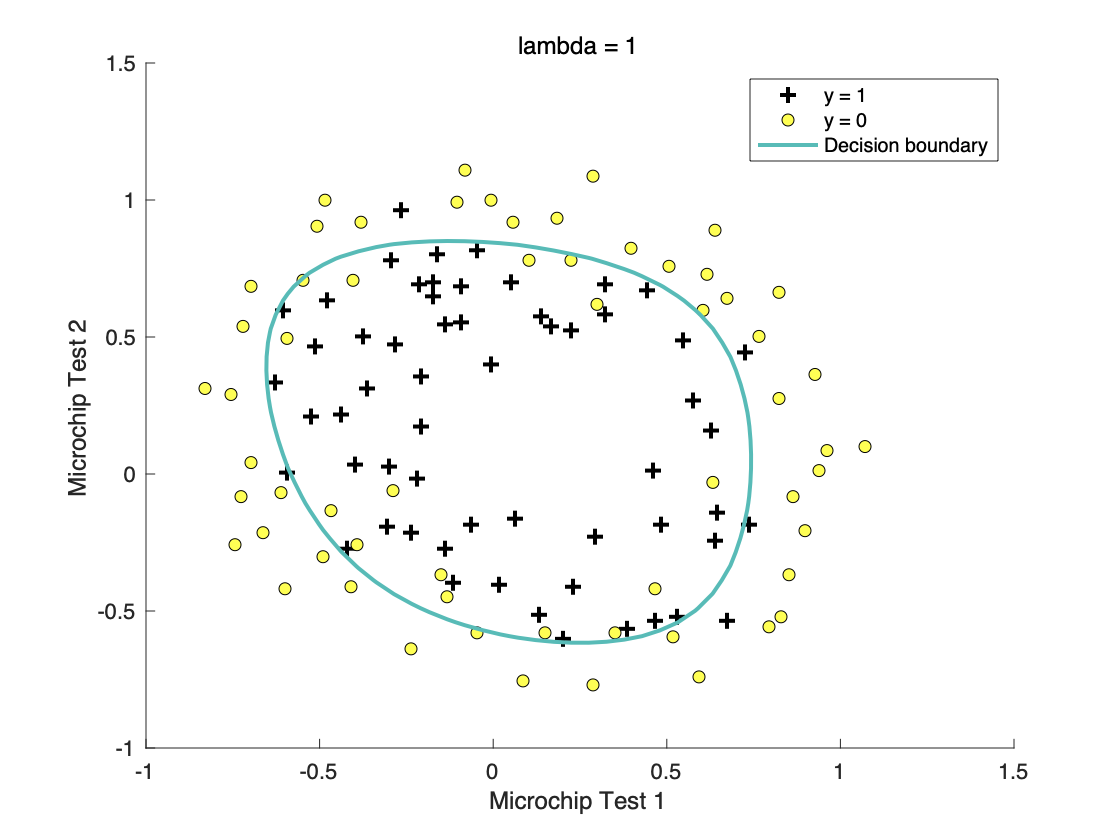
首先数据假造,其次加载了正则化系数
λ
\lambda
λ的代价函数,得到下图:
决策边界不再是直线的时候,则需要一个复杂的多项式来表示,而随着多项式越复杂,拟合程度越高,则会达到过拟合现象,此时可以加入正则项利用
λ
\lambda
λ来减小
θ
\theta
θ参数的影响。
J
(
θ
)
=
1
m
∑
i
=
1
m
[
−
y
(
i
)
l
o
g
(
h
θ
(
x
(
i
)
)
)
−
(
1
−
y
(
i
)
)
l
o
g
(
1
−
x
(
i
)
)
)
]
+
λ
2
m
∑
i
=
1
m
θ
j
(
i
)
J(\theta )=\frac{1}{m}\sum_{i=1}^{m}[-y^{(i)}log(h_\theta (x^{(i)}))-(1-y^{(i)})log(1-x^{(i)}))]+\frac{\lambda }{2m} \sum_{i=1}^{m}\theta _j^{(i)}
J(θ)=m1i=1∑m[−y(i)log(hθ(x(i)))−(1−y(i))log(1−x(i)))]+2mλi=1∑mθj(i)
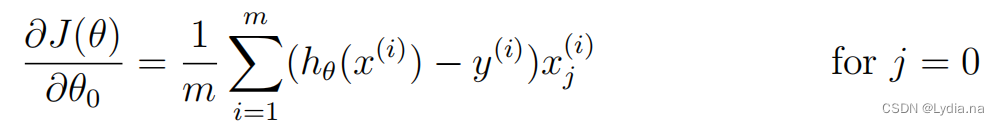
costFunctionReg.m
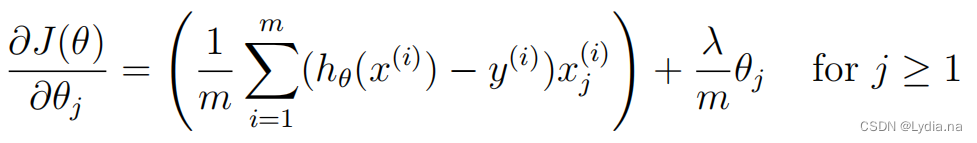
theta_1 =[0;theta(2:end)];
reg=lambda/(2*m)*theta_1'*theta_1;
J=1/m*(-y'*log(sigmoid(X*theta))-(1-y)'*log(1-sigmoid(X*theta)))+reg;
grad=1/m*X'*(sigmoid(X*theta)-y)+lambda/m*theta_1;
3.2 Part 2: Regularization and Accuracies正则化和准确度
与上面逻辑回归类似,通过fminunc得到最小代价函数的theta值,将决策边界绘制到图上。

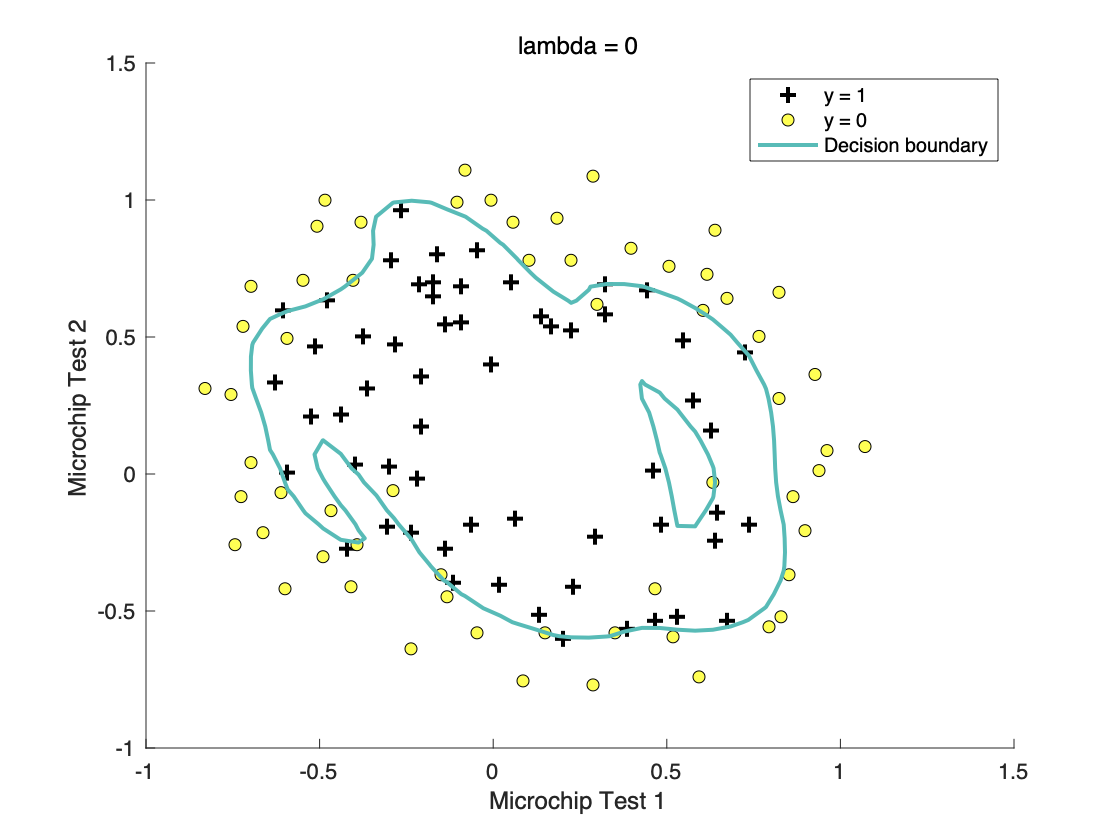
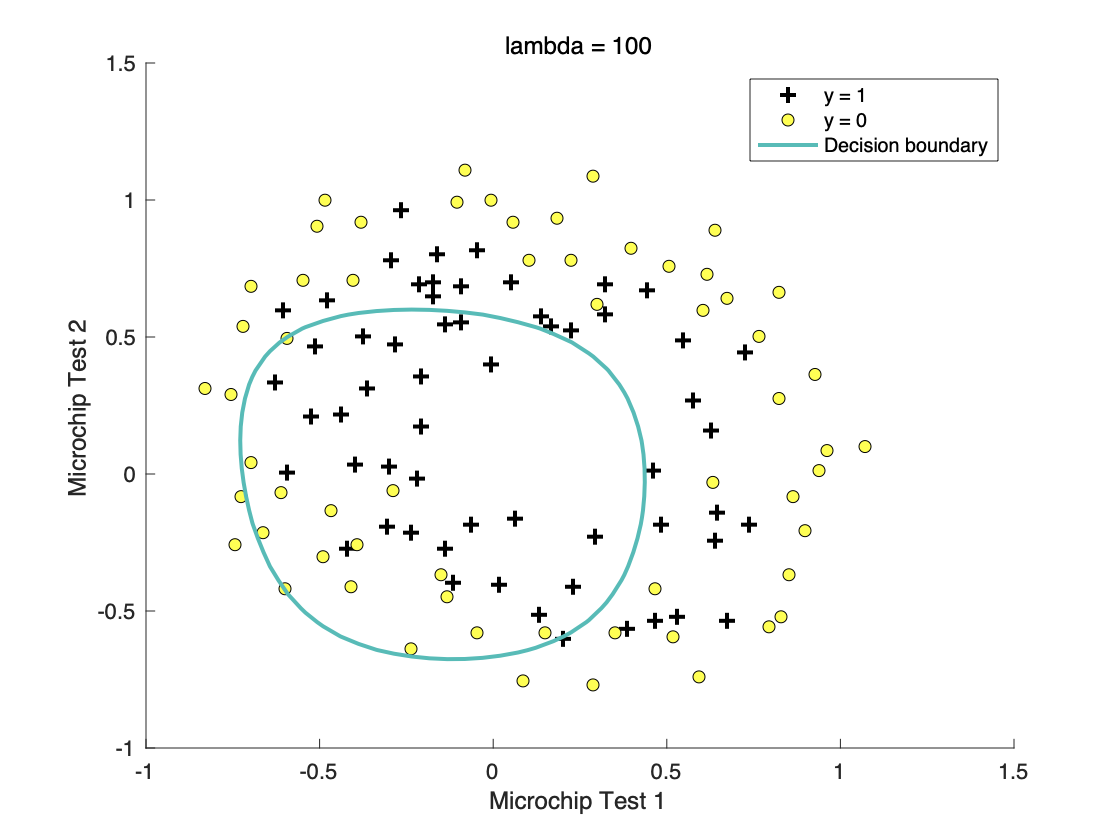
3.3 比较不同正则化参数
l
a
m
b
d
a
=
0
lambda=0
lambda=0
l
a
m
b
d
a
=
100
lambda=100
lambda=100
由此可以得出合适的
l
a
m
b
d
a
lambda
lambda可以有效避免过拟合问题同时又可以保证测试集数据的拟合程度。
参考文章:
机器学习编程作业ex2(matlab/octave实现)-吴恩达coursera
Matlab吴恩达机器学习编程练习ex2:逻辑回归Logistic Regression