为学习CVPR 2024的论文,希望能够将论文电子版保存到本地阅读。然而逐个点击下载着实费时费力,因此想到通过网络爬虫的方法对论文的PDF文件和相关附件批量获取下载,遂以此篇笔记记录方法和心得总结。限于理论学习有限,此番操作可能仍存在极大的优化空间。
声明:本文内容仅作学习用,如有侵权或复现等问题,恳请告知,欢迎讨论。资源是官方开源的,因此可以直接访问官网获取: CVPR 2024 open access repository
代码
下载文件需要一段时间,着急的朋友可以先行下载,等待过程中如有兴趣,欢迎再来看这篇记录此后部分的碎碎念…
import requests
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
headers = {
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'}
# Get html from website
if not os.path.exists('./website.html'):
response_html = requests.get(url='https://openaccess.thecvf.com/CVPR2024?day=all', headers=headers)
with open('./website.html', 'w', encoding='utf-8') as web_html:
web_html.write(response_html.text)
# Get the item
driver = webdriver.Chrome()
driver.get(os.path.abspath('./website.html'))
for paper in driver.find_elements(By.CLASS_NAME, 'ptitle'):
# locate
node_ = paper.find_element(By.XPATH, r'following-sibling::dd[2]')
pdf_url = 'https://openaccess.thecvf.com' + node_.find_element(By.XPATH, './a[1]').get_attribute('href')[10:]
print(f'locate pdf from link:\n{pdf_url}')
try:
if node_.find_element(By.LINK_TEXT, 'supp').get_attribute('href')[-4:] == '.zip':
zip_url = 'https://openaccess.thecvf.com' + node_.find_element(By.LINK_TEXT, 'supp').get_attribute('href')[10:]
print(f'locate zip from link:\n{zip_url}')
else:
zip_url = None
except:
continue
# download
paper_title = pdf_url[54:-20]
root_ = os.getcwd()
file_root = os.path.join(root_, paper_title)
file_name = paper_title[:35]
os.makedirs(file_root, exist_ok=True)
os.chdir(file_root)
response_pdf = requests.get(url=pdf_url, headers=headers)
if not os.path.exists(file_name+'.pdf'):
with open(file_name+'.pdf', "wb") as pdf_file:
pdf_file.write(response_pdf.content)
print(f"已下载文件: {paper_title}.pdf")
else:
print(f"文件已存在: {paper_title}.pdf")
if zip_url: # if None, no zip file as supp
response_zip = requests.get(url=zip_url, headers=headers)
if not os.path.exists(file_name+'.zip'):
with open(file_name+'.zip', "wb") as zip_file:
zip_file.write(response_pdf.content)
print(f"已下载文件: {paper_title}.zip")
else:
print(f"文件已存在: {paper_title}.zip")
os.chdir(root_)
print(f'资源下载完成: {paper_title}')
思路分析
首先观察网页及其源代码,找到目标信息对应的元素和规律,所幸官网不存在复杂的交互,基本可视为静态网页进行分析。
观察网页
观察页面可知,每篇论文的黑色标题下依次列出作者和[pdf],可能还有[supp]和[bibtex]。只要通过鼠标点击某一篇论文的[pdf],就能跳转到该篇论文的PDF文件下载界面。
要想下载这些PDF文件,需要先获得每篇论文对应的这个地址。为此,可以通过开发者模式(Ctrl+Shift+I) 观察源代码。
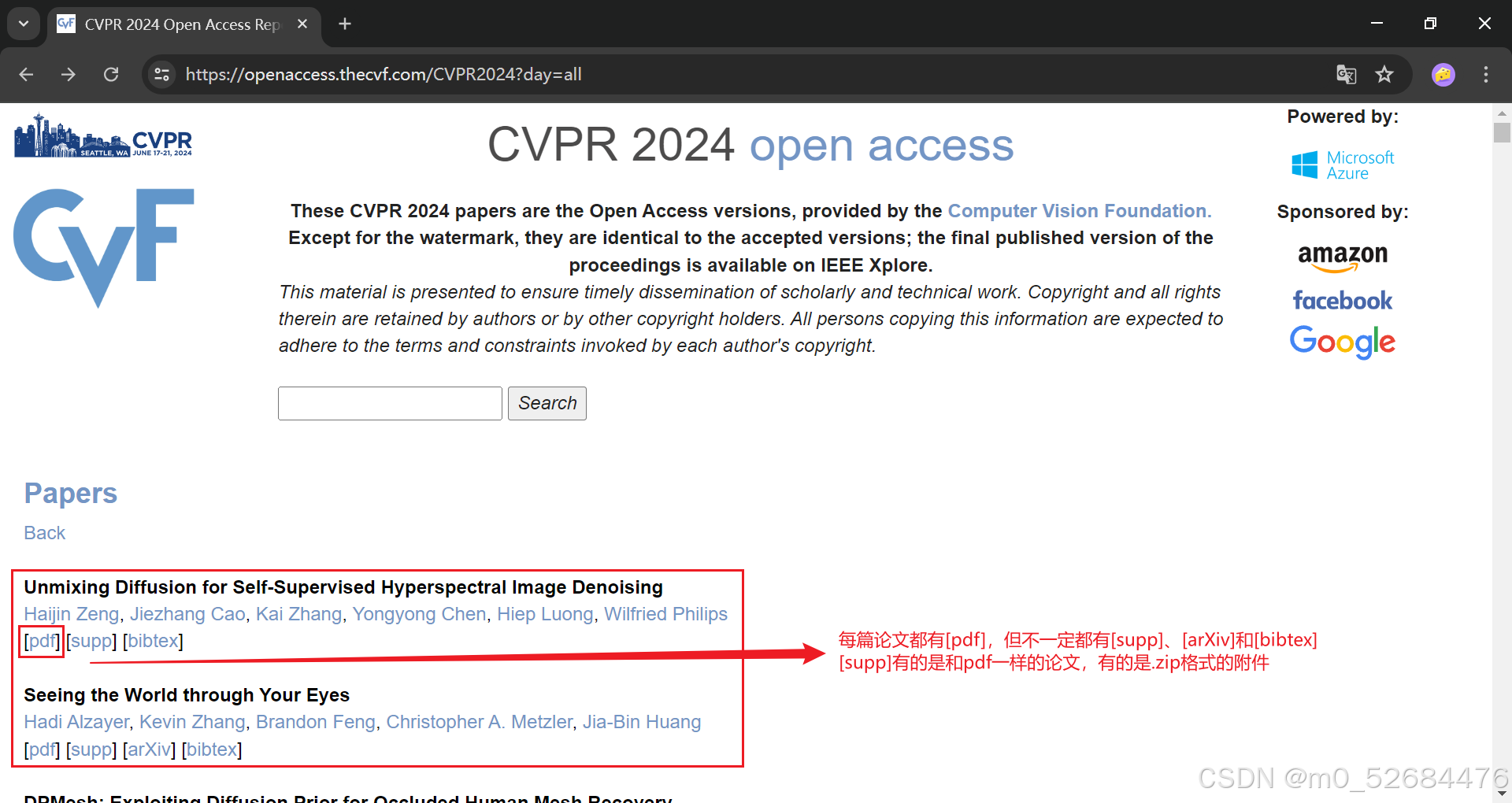
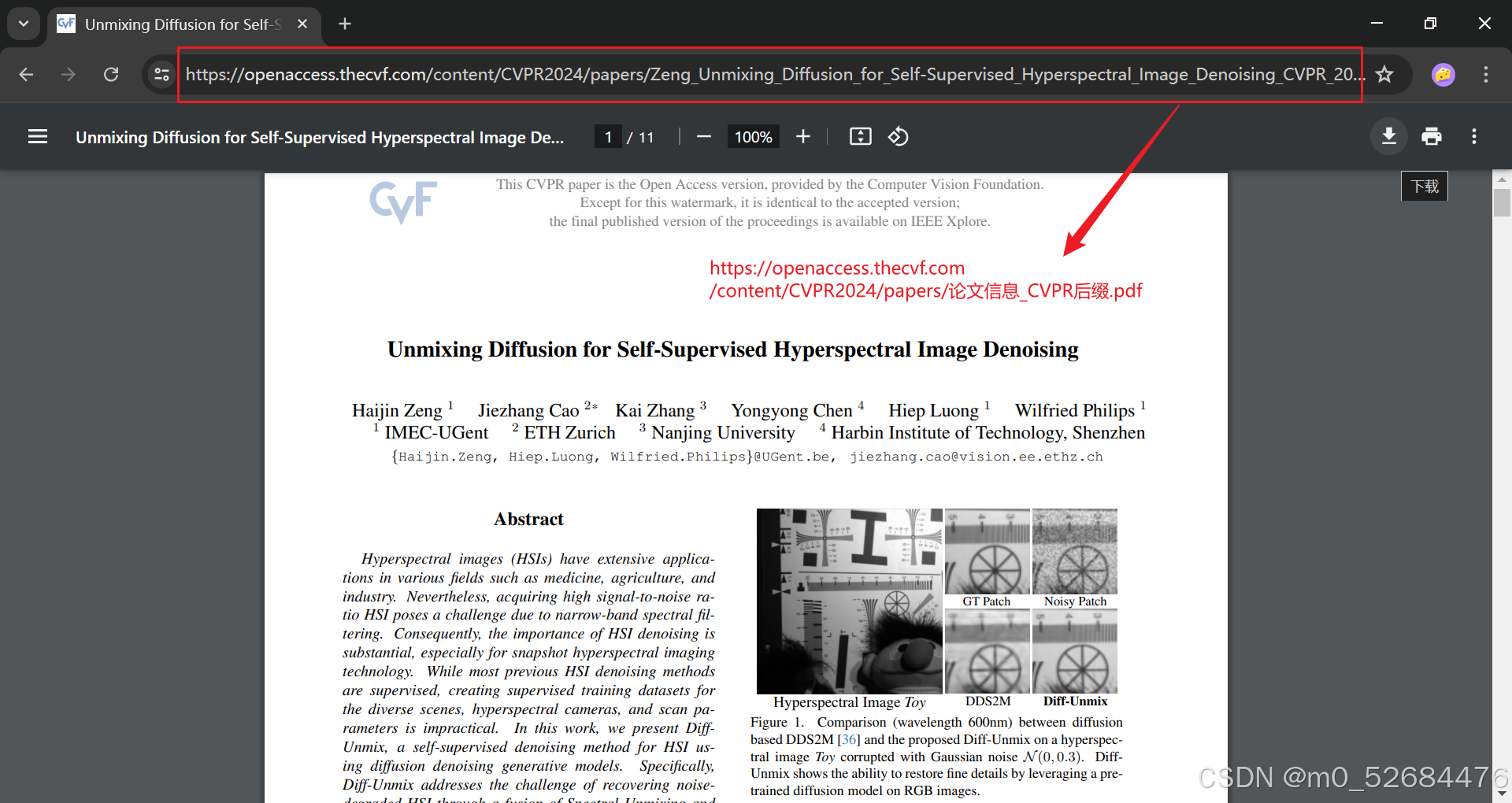
观察源代码
接下来,通过工具定位[pdf]对应的元素。
观察到其他论文也是在一个<a>标签的<href>属性中给出了其对应的 /content/CVPR2024/论文信息_CVPR_2024_paper.pdf。因此只要能够定位带着此类href属性的a标签,再加上https://openaccess.thecvf.com前缀,即可收集每篇论文的地址,然后结合网络爬虫的方法,通过程序自动访问对应的地址,将文件下载至本地文件夹。
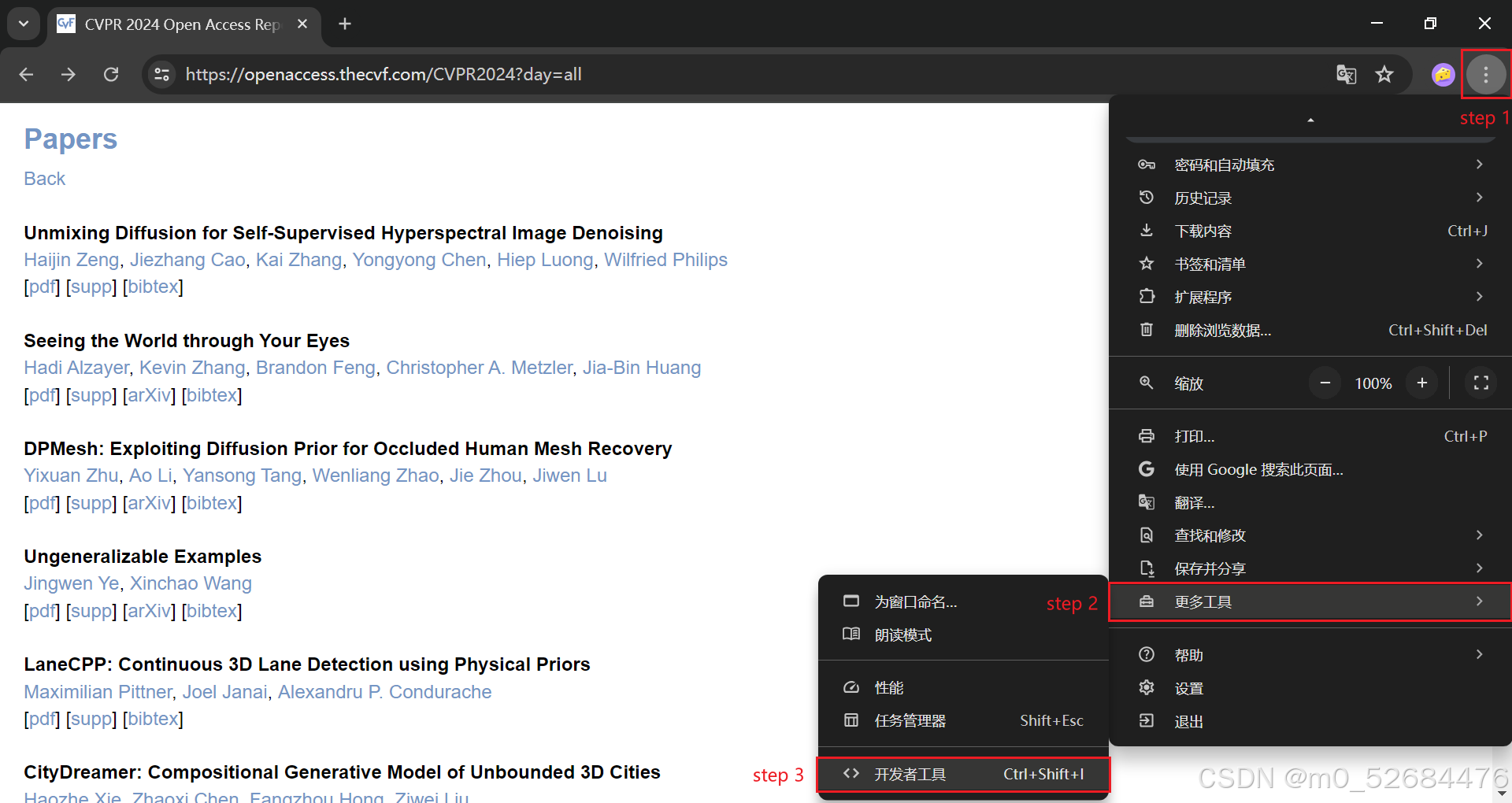
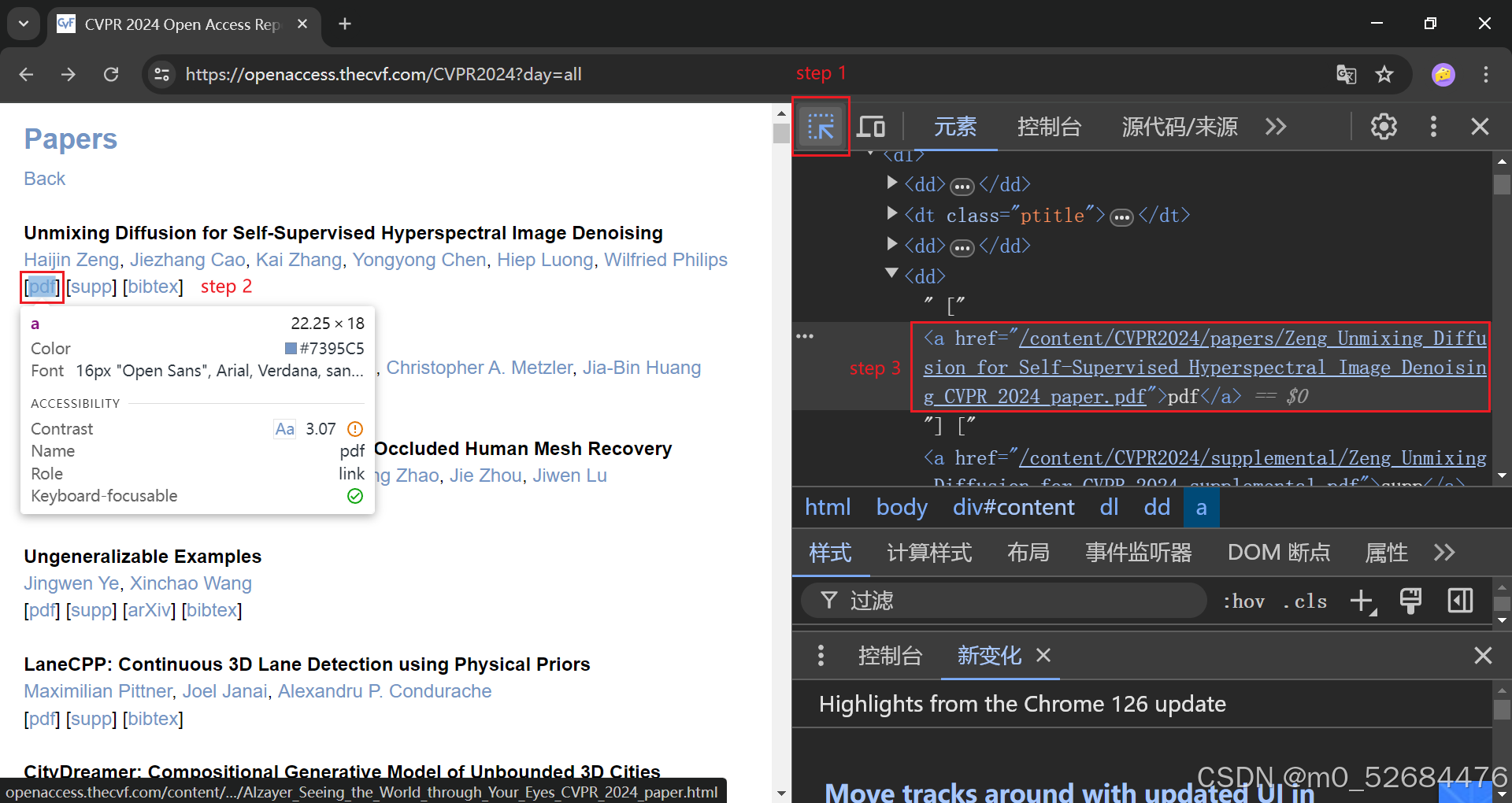
具体实现
对以上分析结果进行小结,所编写的程序应该分为以下几步:
- 访问官网,获取网页源代码。 为了避免后面步骤反复调试,多次访问官网,可以先把源代码保存至本地,之后再对本地的.html文件进行信息提取。
- 从源代码获得其[pdf]和[supp]分别对应的
.pdf和.zip文件的地址。 所有论文都有[pdf],但不一定有[supp],而[supp]有时是.pdf,有时是.zip,前者和[pdf]提供的都是论文的.pdf文件,而后者的压缩包内可能包含着作者开源的代码和数据,以及其他重要学习文件。因此需要判断,在论文存在[supp]的情况下,如果附件是.zip文件,则将该文件下载保存。 - 访问文件对应的地址,将其保存至本地。 为了在阅览论文时方便查找,这里需要对每个下载的文件进行命名,最直接的就是以论文标题信息作为命名依据。
涉及到从静态网页获取内容,可以采用requests库的get()方法,填入参数url和headers即可。
元素定位可以有多种方法,比如通过xpath、通过给定属性名或标签名和通过给定CSS选择器条件等。从Python第三方库来说,可以借助Beautiful Soup、Selenium或者结合lxml等。
对于文件读取和写入,可以采用Python内置的open()和write()函数,但对于编码和模式需要格外注意。此外,文件名的长短和命名规则也是需要慎重的,不过通过源代码找到的地址本身已经将论文标题信息处理成能够适用于文件命名的形式了,因此只需要根据自己的需要设置文件名长短了。(如果希望保留原文件全名,可以使用绝对地址,并且加上前缀’\\?\'1。)
访问官网,获取源代码
把代码中相关的部分先放出来:
import requests
# 给出送入requests.get()的参数headers,老套路
headers = {
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'}
# 如果本地还没存网页,就把源代码写入当前工作目录下的website.html文件内
if not os.path.exists('./website.html'):
response_html = requests.get(url='https://openaccess.thecvf.com/CVPR2024?day=all', headers=headers)
with open('./website.html', 'w', encoding='utf-8') as web_html:
web_html.write(response_html.text)
注意到这里在写入website.html文件时,指定的模式是'w'(覆盖写),编码方式为’utf-8’,因为如果指定为’gbk’,或者其他,可能会产生错误比如:UnicodeEncodeError: 'gbk' codec can't encode character '\xdf' in position 17971: illegal multibyte sequence。
总的来说,套路就是:
①用requests.get()获取静态网页
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'}
response = requests.get(url='你的网址', headers=headers)
②将内容写入文件
with open('文件所存放的上级目录+文件名(含后缀)', '写的模式', encoding='编码方式') as file:
file.write('写入内容')
从源代码获得文件地址
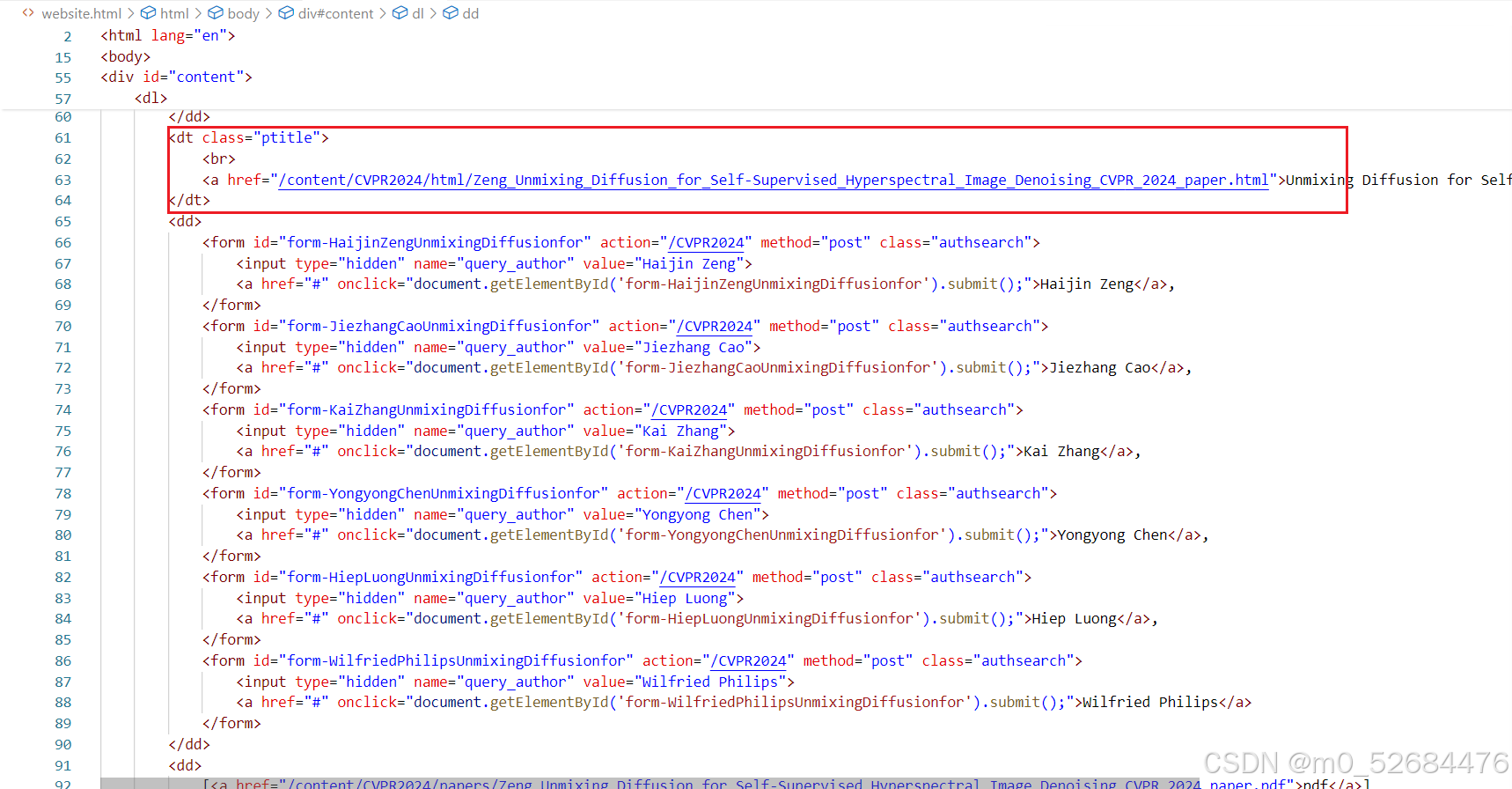
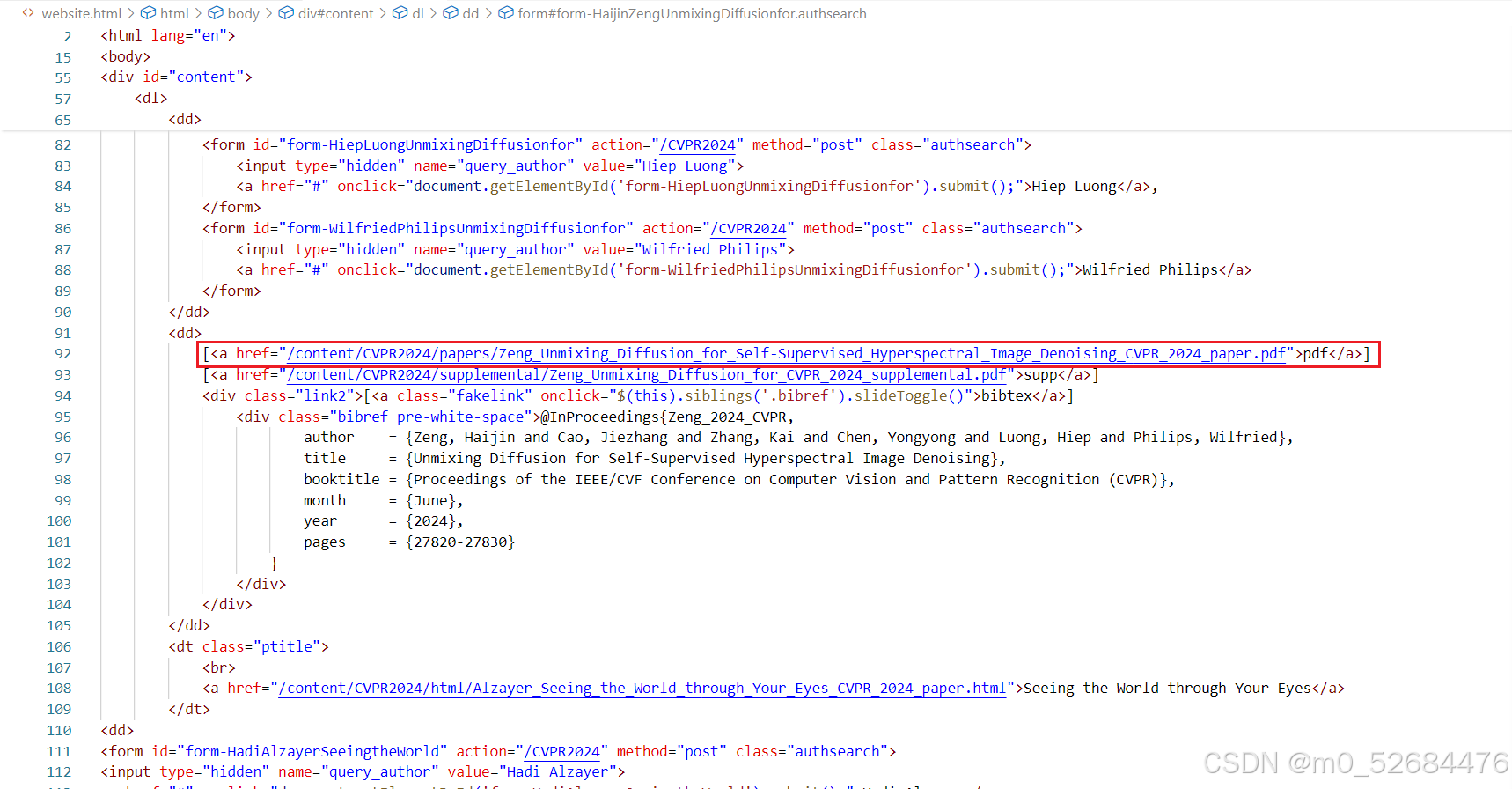
先把源代码大致的框架搬出来看看,全部内容可以在网页上看,这里只截相关部分,我们先定位第一篇论文,还记得它吗?…《Unmixing Diffusion for Self-Supervised Hyperspectral Image Denoising》:
找到它了!定位在一个class为'ptitle'的上下文,并且这种class只在每篇论文中以这独有的方式出现,换句话说,我们可以用这种方式准确定位到一篇论文所在的大致位置。然后去找.pdf和.zip,他们应该是在一个链接里的,那么需要找形如<a href=''xxx.pdf">pdf</a>和<a href=''xxx.zip">supp</a>这样的部分。
它就在上一个部分所在的<dd>...</dd>紧邻的下一个<dd>...</dd>里,而且确实在<a>标签里,href属性里写着相对地址。然而,这篇论文就是先前说到的,存在[supp],但附件是和论文一样的.pdf文件,因此,对于这篇论文只需要下载[pdf]里的即可。对此,代码是这样实现的:
from selenium import webdriver
from selenium.webdriver.common.by import By
# 实例化谷歌浏览器的driver
driver = webdriver.Chrome()
# 让driver分析保存到本地的网页
driver.get(os.path.abspath('./website.html'))
# 定位以'ptitle'为class的节点
for paper in driver.find_elements(By.CLASS_NAME, 'ptitle'):
# 用xpath来定位当前节点之后的第二个dd节点,记为node_
node_ = paper.find_element(By.XPATH, r'following-sibling::dd[2]')
# 结合前缀,加上node_节点下第一个a元素的href属性值,自第11个字符的内容拼出网址
pdf_url = 'https://openaccess.thecvf.com' + node_.find_element(By.XPATH, './a[1]').get_attribute('href')[10:]
print(f'locate pdf from link:\n{pdf_url}')
当然,如果你想用Beautiful Soup,也可以在结合lxml.etree的情况下这样做:
from bs4 import BeautifulSoup
from lxml import etree
# 打开文件
with open('./website.html', 'r') as file:
# 读取文件内容
content = file.read()
# 创建Beautiful Soup对象
soup = BeautifulSoup(content, 'html.parser')
print(soup.prettify()) # 更直观地看到网页源码的层次
url = []
# 使用xpath
dom = etree.HTML(response.text)
for i in range(3, 5432, 2):
xpath_ = '/html/body/div[3]/dl/dd[' + str(i) + ']/a[1]/@href'
pdf_ = dom.xpath(xpath_)
url = 'https://openaccess.thecvf.com' + pdf_[0]
urls.append(url)
这里我们的xpath换一种写法,它从官网源代码上可以直接复制,然后粘过来。我们看到,仅对论文.pdf文件来说,在dd[]这里的迭代是有规律的,从3开始,一直到5431中间的每个奇数:
/html/body/div[3]/dl/dd[3]/a[1]
/html/body/div[3]/dl/dd[5]/a[1]
…
/html/body/div[3]/dl/dd[5431]/a[1]
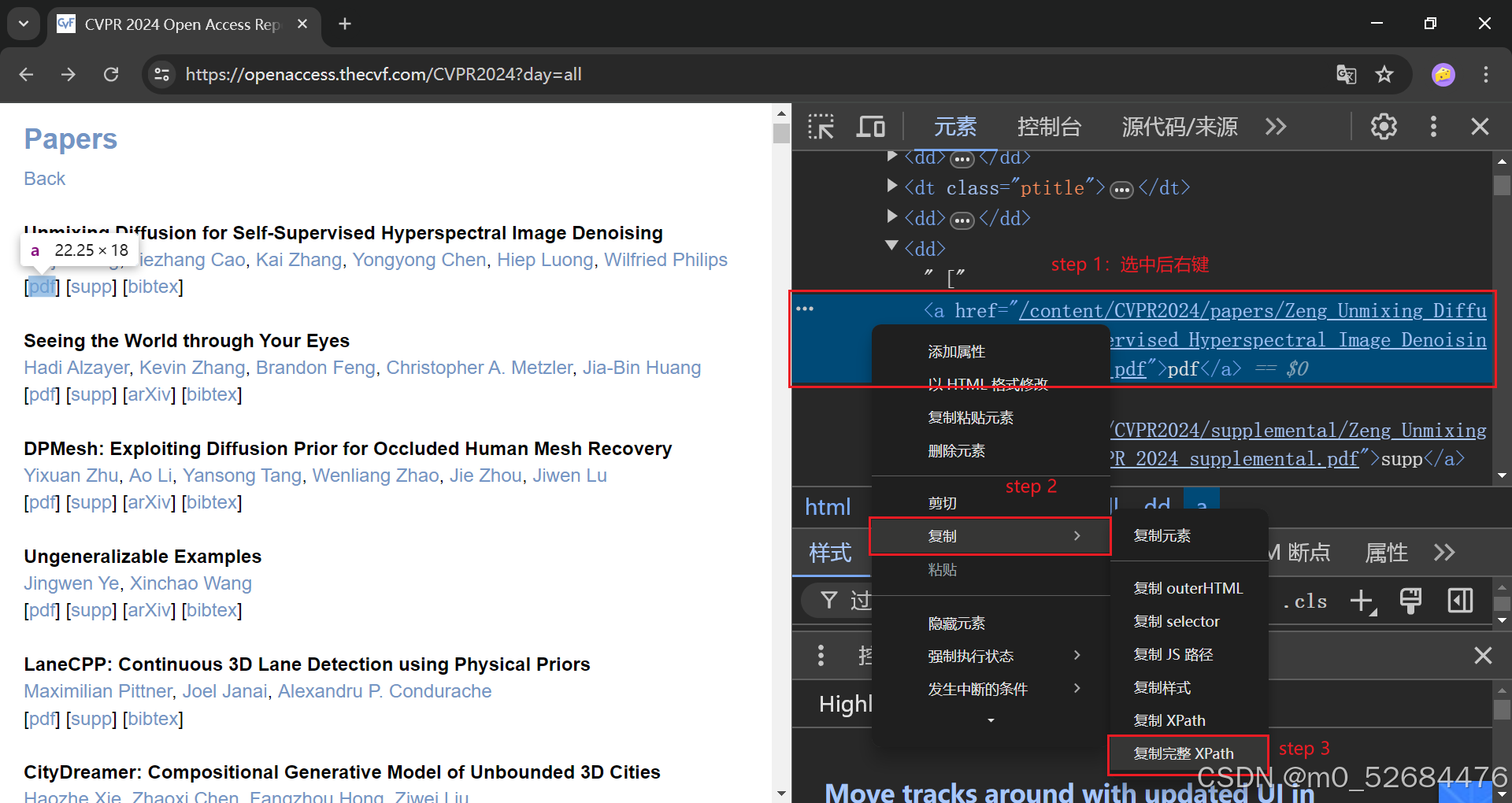
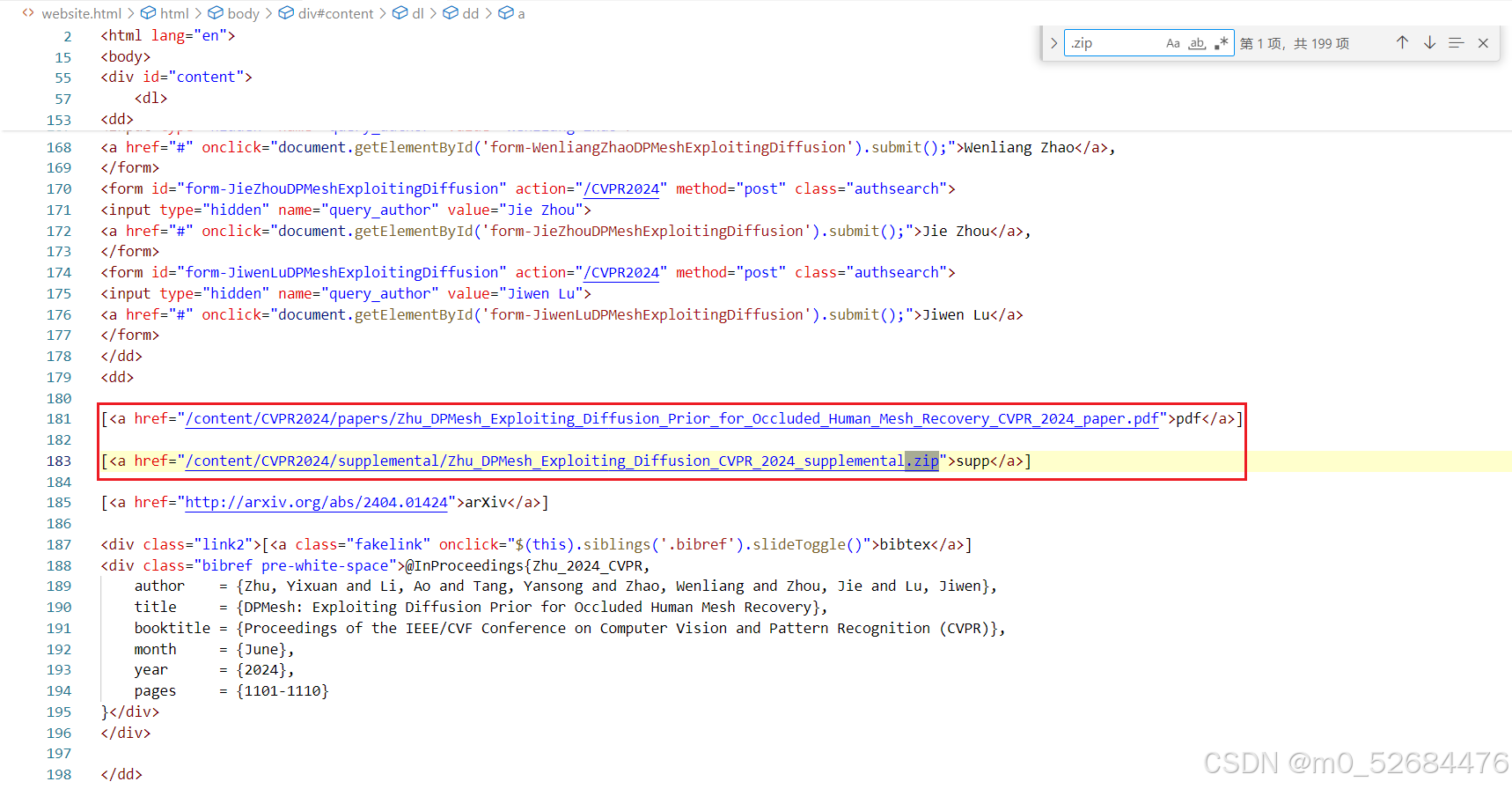
我们再来看看.zip文件的定位,比如长这样:
延续使用的selenium,我们可以这样写:
from selenium import webdriver
from selenium.webdriver.common.by import By
# 实例化谷歌浏览器的driver
driver = webdriver.Chrome()
# 让driver分析保存到本地的网页
driver.get(os.path.abspath('./website.html'))
# 定位以'ptitle'为class的节点
for paper in driver.find_elements(By.CLASS_NAME, 'ptitle'):
# 用xpath来定位当前节点之后的第二个dd节点,记为node_
node_ = paper.find_element(By.XPATH, r'following-sibling::dd[2]')
# 不是所有论文都有[supp]因此,需要用到try-except防止程序崩溃
try:
# 匹配内容是'supp'的链接节点,并且判断href属性的附件是否为.zip文件
if node_.find_element(By.LINK_TEXT, 'supp').get_attribute('href')[-4:] == '.zip':
# 结合前缀,加上该匹配节点href属性值,自第11个字符的内容拼出网址
zip_url = 'https://openaccess.thecvf.com' + node_.find_element(By.LINK_TEXT, 'supp').get_attribute('href')[10:]
print(f'locate zip from link:\n{zip_url}')
else:
zip_url = None # 这里将没有.zip的zip_url标记为None,便于后续规范下载
except:
continue # 如果这篇论文没有supp节点,那就去找下一篇,并不跳出for遍历
当然,如果你还想坚持Beautiful Soup,它甚至可以更简单:
# 查找href中包含".zip"的所有a标签
links = soup.find_all('a', href=lambda href: href and '.zip' in href)
for link in links:
zip_url = 'https://openaccess.thecvf.com'+link.get('href')
然而,这样做的结果就是,无法直接拿着这个.zip和它对应的论文.pdf直接匹配了,在后期整理下载环境会比较麻烦。
对此,我想到的一种办法如下:
你可以把所有的.pdf和.zip先分别保存到当前工作目录下的Papers和Supps文件夹。然后写一个匹配程序,把Supps文件夹里,标题和Papers文件夹里匹配上的文件移动到Papers里,然后再重命名或者不改变Papers文件夹的名字。
import os
import shutil
# 设置源文件夹和目标文件夹
source_folder = './Supps'
target_folder = './Papers'
# 获取目标文件夹中所有文件名
target_filenames = [os.path.basename(f) for f in os.listdir(target_folder)]
print(target_filenames)
# 遍历源文件夹中的文件
for filename in os.listdir(source_folder):
print(filename[:-4])
for target_filename in target_filenames:
if filename[:-4] in target_filename:
print(f'match: \n {filename} \n for {target_filenames}')
source_path = os.path.join(source_folder, filename)
target_path = os.path.join(target_folder+'/'+target_filename, filename)
# 移动文件
shutil.move(source_path, target_path)
我必须声明,这段代码是在百度自动输出的代码基础上改的,并且它确实奏效了。
文件下载与保存
言归正传, 如果延续最开始给出大家的代码的风格,我该在遍历里直接执行文件获取和保存,如下:
for paper in driver.find_elements(By.CLASS_NAME, 'ptitle'):
'''
已知pdf_url和zip_url的情况下
'''
# 首先定义好论文标题、工作目录以及文件名
paper_title = pdf_url[54:-20]
root_ = os.getcwd()
file_root = os.path.join(root_, paper_title)
file_name = paper_title[:35] # 这个35可以调整,但太长可能会受到限制
os.makedirs(file_root, exist_ok=True) # 如果不存在,就创建文件夹
os.chdir(file_root) # 切换到属于这篇论文的文件夹
response_pdf = requests.get(pdf_url)
if not os.path.exists(file_name+'.pdf'):
with open(file_name+'.pdf', "wb") as pdf_file:
pdf_file.write(response_pdf.content)
print(f"已下载文件: {paper_title}.pdf")
else:
print(f"文件已存在: {paper_title}.pdf")
if zip_url:
response_zip = requests.get(zip_url)
if not os.path.exists(file_name+'.zip'):
with open(file_name+'.zip', "wb") as zip_file:
zip_file.write(response_pdf.content)
print(f"已下载文件: {paper_title}.zip")
else:
print(f"文件已存在: {paper_title}.zip")
os.chdir(root_) # 切回最开始的工作目录,否则你下篇论文也在这篇论文的文件夹里
print(f'Done: {paper_title}') # 提示自己,学习资料已经下好,工作目录已经切好
套路已经在先前总结好了,只是将①和②做了融合。至此,就大功告成了。