分布式
如何理解分布式
狭义的分布是指,指多台PC在地理位置上分布在不同的地方。
分布式系统
分布式系**统:**多个能独立运行的计算机(称为结点)组成。各个结点利用计算机网络进行信息传递,从而实现共同的“目标或者任务”。
分布式程序: 运行在分布式系统上的计算机程序。
分布式计算:利用分布式系统解决来计算问题。在分布式计算里,一个问题被细化成多个任务,每个任务可以被一个或者多个计算机来完成。
区分分布式计算和并行计算:共同点都是大任务划分为小任务。不同点: 分布式计算:基于多台PC,每台PC完成同一任务中的不同部分。分布式的计算被分解后的小任务互相之间有独立性,节点之间的结果几乎不互相影响,实时性要求不高。并行计算:基于同一个台PC,利用CPU的多核共同完成一个任务。
-
分布式操作系统:负责管理分布式处理系统资源和控制分布式程序运行。它和集中式操作系统的区别在于资源管理、进程通信和系统结构等方面
-
分布式文件系统:分布式文件系统具有执行远程文件存取得能力,并以透明方式对分布在网络上得文件进行管理和存取
-
分布式程序设计和编译解释系统
分布式事务
事务 事务提供一种“要么什么都不做,要么做全套(All or Nothing)”的机制,她有ACID四大特性 原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。 一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态是指数据库中的数据应满足完整性约束。除此之外,一致性还有另外一层语义,就是事务的中间状态不能被观察到(这层语义也有说应该属于原子性)。 隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行,如同只有这一个操作在被数据库所执行一样。 持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中。在事务结束时,此操作将不可逆转。 单机事务 以mysql的InnoDB存储引擎为例,来了解单机事务是如何保证ACID特性的。

分布式事务 单机事务是通过将操作限制在一个会话内通过数据库本身的锁以及日志来实现ACID,那么分布式环境下该如何保证ACID特性那? 2.2.1 XA协议实现分布式事务
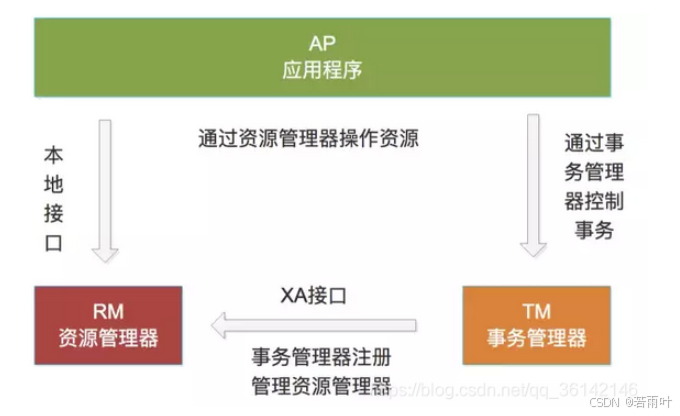
2.2.1.1 XA描述 X/Open DTP(X/Open Distributed Transaction Processing Reference Model) 是X/Open 这个组织定义的一套分布式事务的标准,也就是了定义了规范和API接口,由各个厂商进行具体的实现。 X/Open DTP 定义了三个组件: AP,TM,RM
2PC
二阶段提交
二阶段提交是一种强一致性设计,2PC引入一个事务协调者的角色来协调管理各参与者(各本地资源)的提交和回滚,二阶段分别指的是准备和提交两个阶段
准备阶段:协调者会给各参与者发送准备命令,可以把准备命令理解成除了提交事务之外的事都做完了
同步等待所有资源的响应之后就进入第二阶段即提交阶段(提交阶段不一定是提交事务,也可能是回滚事务)
假如在第一阶段所有参与者都返回准备成功,那么协调者则向所有参与者发送提交事务命令,然后等待所有事务都提交成功之后,返回事务执行成功。
假如在第一阶段有一个参与者返回失败,那么协调者就会向所有参与者发送回滚事务的请求,即分布式事务执行失败
如果第二阶段提交失败
第一种情况:第二阶段执行的是回滚事务操作,那么就是不断重试,直到所有参与者都回滚了。不然那些在第一阶段准备成功的参与者会一直阻塞着
第二种情况:第二阶段执行的是提交事务操作,也是不断重试,因为有可能一些参与者的事务已经提交成功了,这个时候只有一条路,就是不断的重试,直到提交成功。
2PC是一个同步阻塞协议,像第一阶段协调者会等待所有参与者响应了才会进行下一步操作,当然第一阶段的协调者有超时机制,假设因为网络原因没有收到某参与者的响应或某参与者挂了,那么超时之后就会判断事务失败,向所有参与者发送回滚命令
协调者故障分析
协调者是一个单点,存在单点故障问题
假设协调者在发送准备命令之前挂了,就等于事务还没开始
假设协调者在发送准备命令之后挂了,参与者等于都执行了处于事务资源锁定的状态。不仅事务执行不下去,还会因为锁定了一些公共资源而阻塞系统其他操作
假设协调者在发送回滚事务命令之前挂了,事务无法执行,且在第一阶段那些准备成功参与者都阻塞着
假设协调者在发送回滚事务命令之后挂了,至少命令发出去了,很大的概率都会回滚成功,资源都会释放,但是 如果出现网络分区的问题,某些参与者将因为收不到命令而阻塞着。
假设协调者在发送提交事务命令之前挂了,这下所有资源都阻塞了
假设协调者在发送提交事务命令之后挂了,至少命令发出去了,很大概率都会提交成功,然后释放资源,但是如果出现网络分区问题某些参与者将因为收不到命令而阻塞着
协调者故障,通过选举得到新协调者
因为协调者单点问题,因此我们可以通过选举等操作选出一个新协调者来顶替。
如果处于第一阶段,其实影响不大都回滚好了,在第一阶段事务肯定还没提交。
如果处于第二阶段,假设参与者都没挂,此时新协调者可以向所有参与者确认它们自身情况来推断下一步的操作。
假设有个别参与者挂了!这就有点僵硬了,比如协调者发送了回滚命令,此时第一个参与者收到了并执行,然后协调者和第一个参与者都挂了。
此时其他参与者都没收到请求,然后新协调者来了,它询问其他参与者都说OK,但它不知道挂了的那个参与者到底O不OK,所以它傻了。
问题其实就出在每个参与者自身的状态只有自己和协调者知道,因此新协调者无法通过在场的参与者的状态推断出挂了的参与者是什么情况。
虽然协议上没说,不过在实现的时候我们可以灵活的让协调者将自己发过的请求在哪个地方记一下,也就是日志记录,这样新协调者来的时候不就知道此时该不该发了?
但是就算协调者知道自己该发提交请求,那么在参与者也一起挂了的情况下没用,因为你不知道参与者在挂之前有没有提交事务。
如果参与者在挂之前事务提交成功,新协调者确定存活着的参与者都没问题,那肯定得向其他参与者发送提交事务命令才能保证数据一致。
如果参与者在挂之前事务还未提交成功,参与者恢复了之后数据是回滚的,此时协调者必须是向其他参与者发送回滚事务命令才能保持事务的一致。
所以说极端情况下还是无法避免数据不一致问题
协调者:
write START_2PC to local log; //开始事务
multicast VOTE_REQUEST to all participants; //广播通知参与者投票
while not all votes have been collected {
wait for any incoming vote;
if timeout { //协调者超时
write GLOBAL_ABORT to local log; //写日志
multicast GLOBAL_ABORT to all participants; //通知事务中断
exit;
}
record vote;
}
//如果所有参与者都ok
if all participants sent VOTE_COMMIT and coordinator votes COMMIT {
write GLOBAL_COMMIT to local log;
multicast GLOBAL_COMMIT to all participants;
} else {
write GLOBAL_ABORT to local log;
multicast GLOBAL_ABORT to all participants;
}
参与者:
write INIT to local log; //写日志
wait for VOTE_REQUEST from coordinator;
if timeout { //等待超时
write VOTE_ABORT to local log;
exit;
}
if participant votes COMMIT {
write VOTE_COMMIT to local log; //记录自己的决策
send VOTE_COMMIT to coordinator;
wait for DECISION from coordinator;
if timeout {
multicast DECISION_REQUEST to other participants; //超时通知
wait until DECISION is received; /* remain blocked*/
write DECISION to local log;
}
if DECISION == GLOBAL_COMMIT
write GLOBAL_COMMIT to local log;
else if DECISION == GLOBAL_ABORT
write GLOBAL_ABORT to local log;
} else {
write VOTE_ABORT to local log;
send VOTE_ABORT to coordinator;
}
每个参与者维护一个线程处理其它参与者的DECISION_REQUEST请求:
while true {
wait until any incoming DECISION_REQUEST is received;
read most recently recorded STATE from the local log;
if STATE == GLOBAL_COMMIT
send GLOBAL_COMMIT to requesting participant;
else if STATE == INIT or STATE == GLOBAL_ABORT;
send GLOBAL_ABORT to requesting participant;
else
skip; /* participant remains blocked */
}
2PC是一种尽量保证强一致性的分布式事务,因此他是同步阻塞的,而同步阻塞就导致长久的资源锁定问题,总体而言效率低,并且存在单点故障问题,在极端条件下存在数据不一致的风险
3PC
相比于2PC它在参与者中也引入了超时机制,并且新增了一个阶段使得参与者可以利用这一个阶段统一各自的状态
三个阶段:准备阶段、预提交阶段和提交阶段
准备阶段 不会直接执行事务,而是先询问此时的参与者是否有条件接这个任务,因此不会一来就干活直接锁资源,使得在某些资源不可用的情况下所有参与者都阻塞着
预提交阶段的引入起到了一个统一状态的作用,它像一道栅栏,表明在预提交阶段前所有参与者其实还未都回应,在预处理阶段表明所有参与者都已经回应了
假如你是一位参与者,你知道自己进入了预提交状态那你就可以推断出来其他参与者也都进入了预提交状态。
但是多引入一个阶段也多一个交互,因此性能会差一些,而且绝大部分的情况下资源应该都是可用的,这样等于每次明知可用执行还得询问一次。
2PC 是同步阻塞的,上面我们已经分析了协调者挂在了提交请求还未发出去的时候是最伤的,所有参与者都已经锁定资源并且阻塞等待着。
那么引入了超时机制,参与者就不会傻等了,如果是等待提交命令超时,那么参与者就会提交事务了,因为都到了这一阶段了大概率是提交的,如果是等待预提交命令超时,那该干啥就干啥了,反正本来啥也没干。
然而超时机制也会带来数据不一致的问题,比如在等待提交命令时候超时了,参与者默认执行的是提交事务操作,但是有可能执行的是回滚操作,这样一来数据就不一致了。 3PC 的引入是为了解决提交阶段 2PC 协调者和某参与者都挂了之后新选举的协调者不知道当前应该提交还是回滚的问题。
新协调者来的时候发现有一个参与者处于预提交或者提交阶段,那么表明已经经过了所有参与者的确认了,所以此时执行的就是提交命令。
所以说 3PC 就是通过引入预提交阶段来使得参与者之间的状态得到统一,也就是留了一个阶段让大家同步一下。
但是这也只能让协调者知道该如果做,但不能保证这样做一定对,这其实和上面 2PC 分析一致,因为挂了的参与者到底有没有执行事务无法断定。
所以说 3PC 通过预提交阶段可以减少故障恢复时候的复杂性,但是不能保证数据一致,除非挂了的那个参与者恢复。
让我们总结一下, 3PC 相对于 2PC 做了一定的改进:引入了参与者超时机制,并且增加了预提交阶段使得故障恢复之后协调者的决策复杂度降低,但整体的交互过程更长了,性能有所下降,并且还是会存在数据不一致问题。
所以 2PC 和 3PC 都不能保证数据100%一致,因此一般都需要有定时扫描补偿机制。
提交阶段和2PC的一样
无论哪一个阶段有参与者返回失败都会宣布事务失败
TCC
2PC和3PC都是数据库层面的,而TCC是业务层面的分布式事务
TCC指的是Try confirm Cancel
-
try指的是预留,即资源的预留和锁定
-
confirm 指的是确认操作,这一步其实就是真正的执行了
-
cancel指的是撤销操作,可以理解为把预留阶段的的动作撤销了
其实从思想上看和 2PC 差不多,都是先试探性的执行,如果都可以那就真正的执行,如果不行就回滚。
比如说一个事务要执行A、B、C三个操作,那么先对三个操作执行预留动作。如果都预留成功了那么就执行确认操作,如果有一个预留失败那就都执行撤销动作。
TCC对业务的侵入比较大和业务紧耦合,需要根据特定的场景和业务逻辑来设计相应的操作
撤销和确认操作的执行可能需要重试,因此还需要保证操作的幂
相对于 2PC、3PC ,TCC 适用的范围更大,但是开发量也更大,毕竟都在业务上实现,而且有时候你会发现这三个方法还真不好写。不过也因为是在业务上实现的,所以TCC可以跨数据库、跨不同的业务系统来实现事务。
本地消息表
本地消息表其实就是利用了 各系统本地的事务来实现分布式事务。
本地消息表顾名思义就是会有一张存放本地消息的表,一般都是放在数据库中,然后在执行业务的时候 将业务的执行和将消息放入消息表中的操作放在同一个事务中,这样就能保证消息放入本地表中业务肯定是执行成功的。
然后再去调用下一个操作,如果下一个操作调用成功了好说,消息表的消息状态可以直接改成已成功。
如果调用失败也没事,会有 后台任务定时去读取本地消息表,筛选出还未成功的消息再调用对应的服务,服务更新成功了再变更消息的状态。
这时候有可能消息对应的操作不成功,因此也需要重试,重试就得保证对应服务的方法是幂等的,而且一般重试会有最大次数,超过最大次数可以记录下报警让人工处理。
可以看到本地消息表其实实现的是最终一致性,容忍了数据暂时不一致的情况。
消息事务
RocketMQ就很好的支持了消息事务
第一步先给Broker发送事务消息即半消息,半消息不是说一般消息,而是这个消息对消费者来说不可见,然后发送成功后发送方在执行本地事务
再根据本地事务的结果向Broker发送Commit或者RollBack命令
并且RocketMQ的发送方会提供一个反查事务状态接口,如果一段时间内半消息没有收到任何操作请求,那么Broker会通过反查接口得知发送方事务是否执行成功,然后执行Commit或者RollBack命令
如果是Commit那么订阅方就能收到这条消息,然后再做对应的操作,做完了之后再消费这条消息即可
如果是RollBack那么订阅方收不到这条消息,等于事务就没执行过
可以看到通过 RocketMQ 还是比较容易实现的,RocketMQ 提供了事务消息的功能,我们只需要定义好事务反查接口即可。