一、Medical概述
MedicalGPT 是一个基于ChatGPT训练流程的医疗行业语言模型项目,主要包括增量预训练、有监督微调和RLHF(奖励建模、强化学习训练)。项目旨在通过不同的训练阶段,优化模型以更好地适应医疗数据,提高问答和文本生成的准确性和质量。此外,该项目还引入了直接偏好优化(DPO),使得模型在无需复杂的强化学习框架下,能够有效学习并适应人类偏好。项目通过多种数据集和训练策略,实现了模型的持续进化和功能扩展。
二、项目地址
注意:模型地址需要通过代理才能访问。
Github地址:https://github.com/shibing624/MedicalGPT/blob/main/README.md
模型地址:https://huggingface.co/shibing624/vicuna-baichuan-13b-chat
github项目地址中文档很详细(包括全阶段串起来的训练示例、训练参数、支持的模型、模型显存)。
三、硬件条件
服务器环境:Linux
操作系统:ubuntu 22.04
架构:x86_64
实例规格:GPU 24G显存 CPU 16+60G
四、MedicalGPT部署步骤
1. 准备工作
(1)安装Anaconda软件
注意:Anaconda无版本要求,主要和Linux的架构保持一致。
① 下载地址:https://repo.anaconda.com/archive/
下载完成并上传到服务器。
② 设置可执行权限
chmod +x Anaconda3-2024.06-1-Linux-x86_64.sh③ 安装Anaconda
说明:如果不指定Anaconda安装目录默认在/root/anaconda3下,可以通过命令指定安装目录
bash Anaconda3-2024.06-1-Linux-x86_64.sh -b -p 安装路径④ 配置环境变量
在/etc/profile 文件中添加anaconda的环境变量
export PATH=/xx/anaconda3/bin:$PATH⑤ 刷新环境变量
source /etc/profile⑥ 验证
conda -V⑦ 初始化anaconda
conda init⑧ 刷新anaconda的配置
source /root/.bashrc(2)创建MedicalGPT需要的python环境并激活
① 创建MedicalGPT环境
conda create -n medicalgpt python=3.10② 激活环境
conda activate medicalgpt2.拉取MedicalGPT项目代码
(1)切换到磁盘挂载目录
cd /data/
(2)拉取代码并切换到对应目录
git clone https://github.com/shibing624/MedicalGPT
cd MedicalGPT(3)下载依赖
pip install -r requirements.txt --upgrade如果下载过程中出现下载不了的情况,可以通过命令 -i 指定下载文件的镜像地址(Simple Index)。
3.下载MedicalGPT模型
说明:如果不能直接通过服务器上下载,可以通过windows上挂载代理软件访问抱脸地址:https://huggingface.co/shibing624/vicuna-baichuan-13b-chat 把Files and versions 下文件全部下载,模型下载时间比较长,耐心等待。

下载完成后并将下载好模型传到服务器的MedicalGPT目录下(上传的位置必须是刚刚拉取克隆下github的目录下新建一个shibing624目录,再在shibing624下创建一个vicuna-baichuan-13b-chat目录)这是因为运行的时候需要指定模型目录。

4. 运行MedicalGPT(GPU)
官方提供的命令如下:
CUDA_VISIBLE_DEVICES=0 python gradio_demo.py --model_type base_model_type --base_model path_to_llama_hf_dir --lora_model path_to_lora_dir
切换到MedicalGPT目录运行如下命令(根据官方提供的运行命令进行修改):
CUDA_VISIBLE_DEVICES=0 python gradio_demo.py --model_type baichuan --base_model shibing624/vicuna-baichuan-13b-chat参数说明:
--model_type {base_model_type}:预训练模型类型,如llama、bloom、chatglm等。
--base_model {base_model}:存放HF格式的LLaMA模型权重和配置文件的目录,也可使用HF Model Hub模型调用名称。
--lora_model {lora_model}:LoRA文件所在目录,也可使用HF Model Hub模型调用名称。若lora权重已经合并到预训练模型,则删除--lora_model参数。
--tokenizer_path {tokenizer_path}:存放对应tokenizer的目录。若不提供此参数,则其默认值与--base_model相同。
--template_name:模板名称,如vicuna、alpaca等。若不提供此参数,则其默认值是vicuna。
--only_cpu: 仅使用CPU进行推理。
--resize_emb:是否调整embedding大小,若不调整,则使用预训练模型的embedding大小,默认不调整。
运行成功如下图所示:

5. 运行MedicalGPT(CPU)
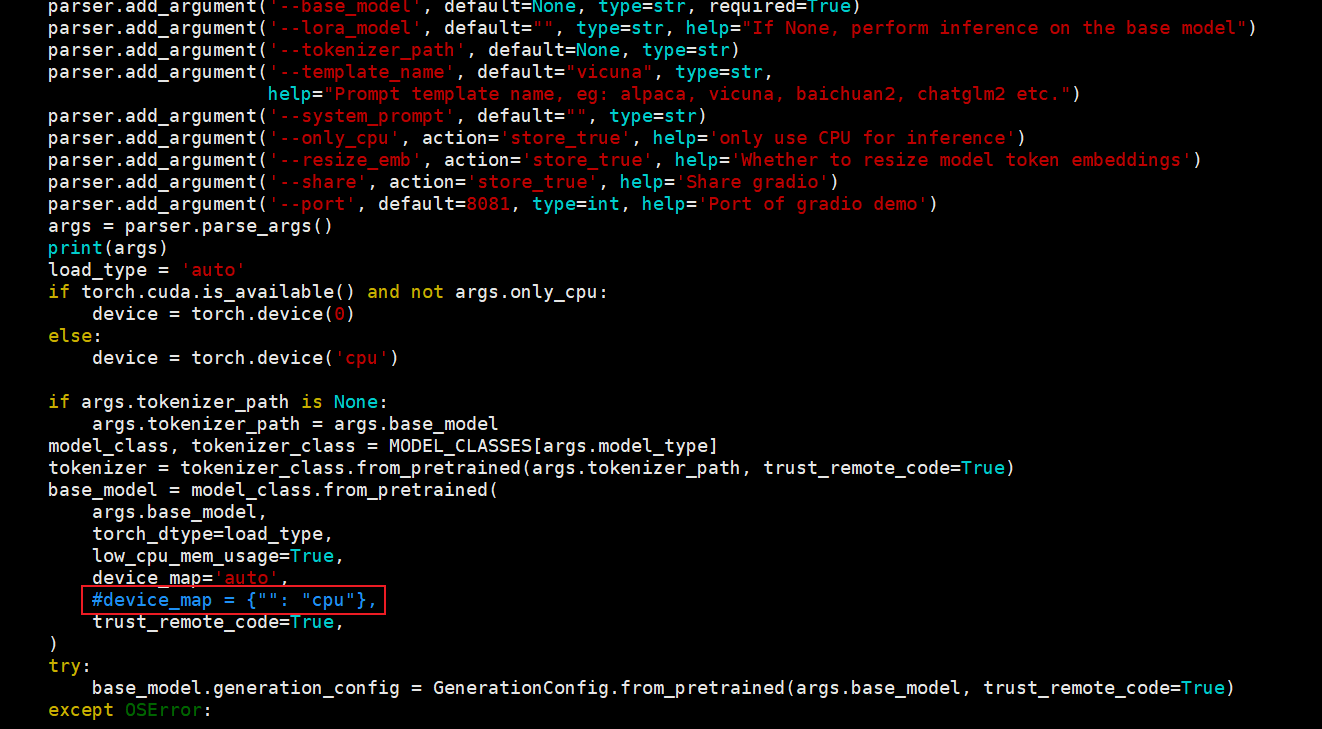
注意:修改gradio_demo.py中,由于模型是默认采用GPU运行,因此需要调整gradio_demo.py中的 device_map='auto' 改为 device_map = {"": "cpu"}
如果不修改可能会报错:ValueError: The current `device_map` had weights offloaded to the disk. Please provide an `offload_folder` for them. Alternatively, make sure you have `safetensors` installed if the model you are using offers the weights in this format.
切换到MedicalGPT目录运行如下命令(根据官方提供的运行命令进行修改):
python gradio_demo.py --only_cpu --model_type baichuan --base_model shibing624/vicuna-baichuan-13b-chat
6. 成果展示
注意:开放8081端口。

推理速度较慢(应该和硬件环境有关),在GPU显存为24G的机器上,大概一分钟多种推理完成,GPU显存占到22G左右。
7.问题
(1)找不到gradio库
解决方案:下载gradio 命令:pip install gradio
(2)找不到transforms生成器

解决方案:下载 transforms 生成器 命令:pip install transformers_stream_generator