一、项目导读
瑞吉外卖是一个单体架构,整体的业务逻辑也较为简单。如果刚学SpringBoot技术,想要通过项目练手,那这是一个很好的选择,不仅可以练习SpringBoot技术,还可以学习Mybatis-Plus、Redis、项目部署,服务器等相关知识,建议新手跟着教程结合笔记学习,掌握开发流程的梳理,项目中的很多逻辑上的处理还是比较通用的,下次遇到同样的需求也更容易实现出来,作为新手来说,自己探索虽然也是一个锻炼的过程,但由于掌握的技术比较少,所以很多功能的实现只能基于自己掌握的技术,耗费的时间往往很多效果其实也一般并且还容易限制自己的思维,新技术的学习,所以建议看视频以及笔记学习。在本文中将着重讲解项目中的重难点,有些部分也会扩展讲解。
二、软件开发流程
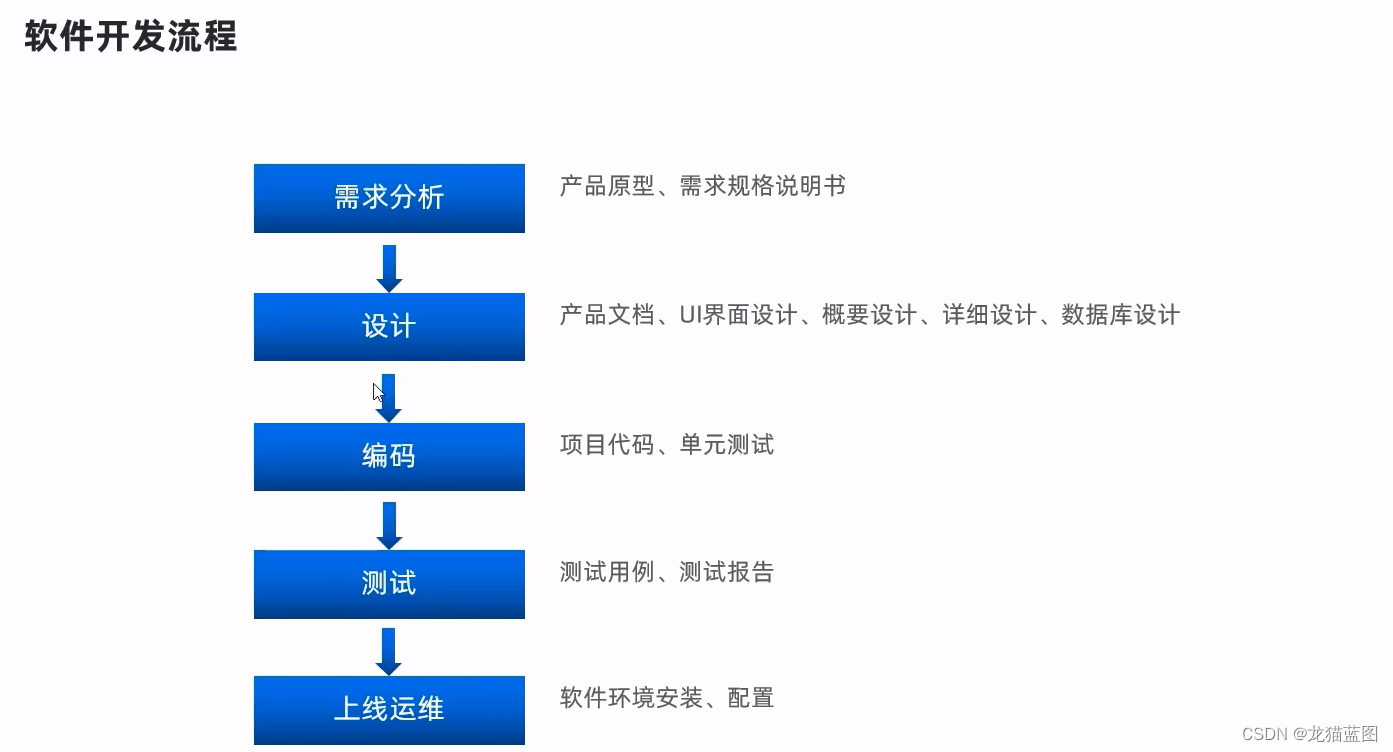
1. 角色分工

2. 软件环境
- 开发环境(development):开发人员在开发阶段使用的环境,一般外部用户无法访问
- 测试环境(testing):专门给测试人员使用的环境,用于测试项目,一般外部用户无法访问
- 生产环境(production):即线上环境,正式提供对外服务的环境
3. 项目介绍
本项目(瑞吉外卖)是专门为餐饮企业(餐厅、饭店)定制的一款软件产品,包括系统管理后台和移动端应用两部分。
其中系统管理后台主要提供给餐饮企业内部员工使用,可以对餐厅的菜品、套餐、订单等进行管理维护。移动端应用主要提供给消费者使用,可以在线浏览菜品、添加购物车、下单等。
本项目共分为3期进行开发:
第一期主要实现基本需求,其中移动端应用通过H5实现,用户可以通过手机浏览器访问。
第二期主要针对移动端应用进行改进,使用微信小程序实现,用户使用起来更加方便。
第三期主要针对系统进行优化升级,提高系统的访问性能。
4. 产品原型展示
产品原型,就是一款产品成型之前的一个简单的框架,就是将页面的排版布局展现出来,使产品的初步构思有一个可视化的展示。通过原型展示,可以更加直观的了解项目的需求和提供的功能。
课程资料中已经提供了产品原型:
【瑞吉外卖后台(管理端)】
【瑞吉外卖前台(用户端)】
注意事项
产品原型主要用于展示项目的功能,并不是最终的页面效果。
5. 技术选型

6. 功能架构

7. 用户角色

三、瑞吉外卖开发
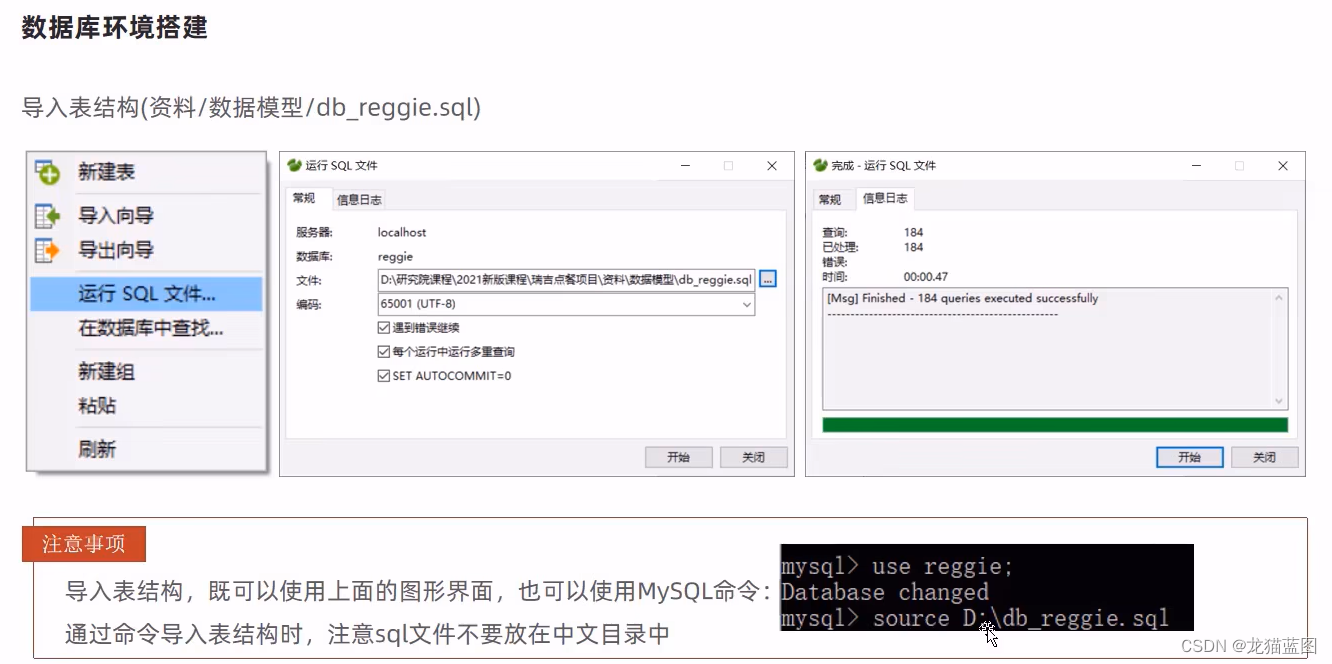
1. 数据库环境搭建
可用使用Navicat或者命令行模式导入sql脚本
2. 项目环境搭建
- 依赖的导入
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!--单元测试-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--web工程-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<scope>compile</scope>
</dependency>
<!--mybatis-plus依赖-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.2</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
</dependency>
<!--将对象转为json-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.76</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.23</version>
</dependency>
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-commons</artifactId>
<version>1.8.2</version>
<scope>compile</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>2.4.5</version>
</plugin>
</plugins>
</build>
3. 配置文件
server:
port: 8080
spring:
application:
name: reggie_take_out #默认为项目名
datasource:
druid:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/reggie?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true
username: root
password: root
mybatis-plus:
configuration:
#在映射实体或者属性时,将数据库中表名和字段名中的下划线去掉,按照驼峰命名法映射,默认为true,可不配置
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
id-type: ASSIGN_ID
4. 静态资源导入
SpringBoot建议我们将静态资源放在resources下的static或者template,如果我们直接将静态资源放在resources下,需要进行静态资源路径访问的配置。我们将静态资源backend和front放在resources下。通过一个配置类设置静态资源的映射,告诉我们的MVC框架,backend和front放的是我们的静态资源直接放行就行了。
配置静态资源映射
@Slf4j
@Configuration
public class WebMvcConfig extends WebMvcConfigurationSupport {
//设置静态资源映射
@Override
protected void addResourceHandlers(ResourceHandlerRegistry registry){
log.info("开始进行静态资源映射。。。");
//当我们的访问路径为/backend我们就去访问类路径下的/backend
registry.addResourceHandler("/backend/**").addResourceLocations("classpath:/backend/");
registry.addResourceHandler("/front/**").addResourceLocations("classpath:/front/");
}
}
5. 项目启动类
- 我们开启了Mapper接口的扫描,就不需要在每个Mapper接口都写上@Mapper注解了
@Slf4j //日志打印
@SpringBootApplication //项目启动类
@MapperScan("com.ldh.reggie.mapper") //扫描Mapper接口
@ServletComponentScan //扫描过滤器
public class ReggieApplication {
public static void main(String[] args) {
SpringApplication.run(ReggieApplication.class,args);
log.info("项目启动成功。。。");
}
}
6.通用返回结果类
此类是一个通过结果类,服务器端响应的所有结果最终都会包装成此种类型返回给前端页面。好处:统一返回数据类型,便于前端人员处理后台响应数据。
package com.ldh.reggie.common;
import lombok.Data;
import java.util.HashMap;
import java.util.Map;
@Data
public class R<T> {
private Integer code; //编码:1成功,0和其它数字为失败
private String msg; //错误信息
private T data; //数据
private Map map = new HashMap(); //动态数据
public static <T> R<T> success(T object) {
R<T> r = new R<T>();
r.data = object;
r.code = 1;
return r;
}
public static <T> R<T> error(String msg) {
R r = new R();
r.msg = msg;
r.code = 0;
return r;
}
public R<T> add(String key, Object value) {
this.map.put(key, value);
return this;
}
}
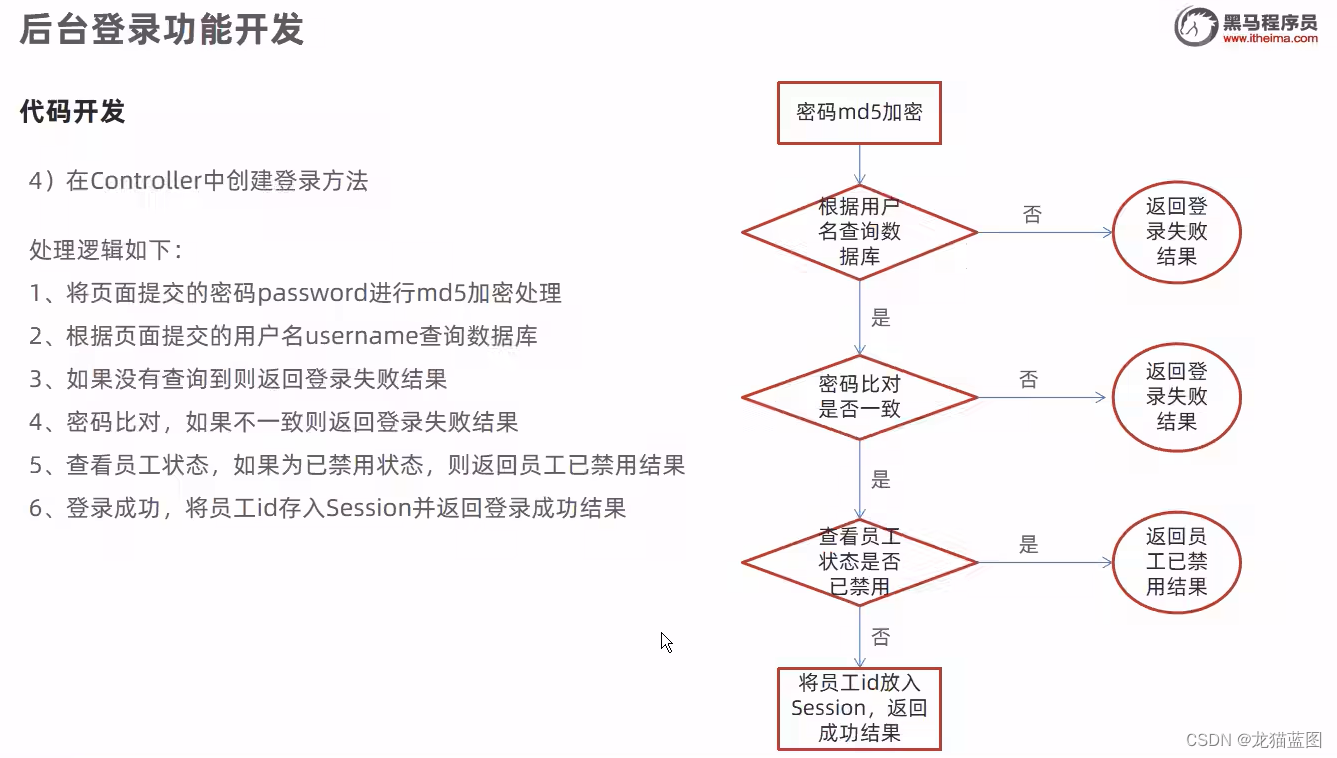
7. 员工登录退出功能开发
开发流程:由于前端已经开发完毕,我们点击登录请求后使用开发者模式查看以下请求的路径是什么,然后创建对应的Controller层–>Service层–>Dao层
- 操作员工表——employee
7.1 员工实体类
@Data
public class Employee implements Serializable {
private static final long serialVersionUID = 1L;
private Long id;
private String username;
private String name;
private String password;
private String phone;
private String sex;
private String idNumber;
private Integer status;
private LocalDateTime createTime;
private LocalDateTime updateTime;
private Long createUser;
private Long updateUser;
}
Mapper层和Service层我们使用Mybatis-Plus,继承对应实现类后就能完成通用的增删改查方法。
7.2 EmployeeMappr
- 我们在项目启动类中进行了Mapper接口的扫描,将Mapper接口加入的IOC容器中进行管理
public interface EmployeeMapper extends BaseMapper<Employee> {
}
7.3 EmployeeService
public interface EmployeeService extends IService<Employee> {
}
7.4 EmployeeServiceImpl
//注意要加注解,表示加入IOC容器中进行管理
@Service
public class EmployeeServiceImpl extends ServiceImpl<EmployeeMapper, Employee>
implements EmployeeService{
}
7.5 EmployeeController
@Slf4j
@RestController
@RequestMapping("/employee")
public class EmployeeController {
@Autowired
private EmployeeService employeeService;
@PostMapping("/login")
public R<Employee> login(HttpServletRequest request, @RequestBody Employee employee){
//1.将页面提交的密码password进行md5加密处理
String password = employee.getPassword();
password = DigestUtils.md5DigestAsHex(password.getBytes());
//2.根据页面提交的用户名username查询数据库
String username = employee.getUsername();
LambdaQueryWrapper<Employee> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(Employee::getUsername,employee.getUsername());
Employee emp = employeeService.getOne(queryWrapper);
//3.如果没有查询到登录用户名到则返回登录失败结果
if(emp==null){
return R.error("登录失败");
}
//4.密码比对,如果不一致则返回登录失败结果
if(!emp.getPassword().equals(password)){
return R.error("登录失败");
}
//5.:查看员工状态,如果为已禁用状态,则返回员工已禁用结果
if(emp.getStatus() == 0){
return R.error("账号已禁用");
}
//6.登录成功,将员工id存入Session并返回登录成功结果
request.getSession().setAttribute("employee",emp.getId());
return R.success(emp);
}
@PostMapping("/logout")
public R<String> logout(HttpServletRequest request){
request.getSession().removeAttribute("employee");
return R.success("退出成功");
}
7.6 完善登录功能
在上面的登录功能中,即使我们跳过登录功能去访问任意一个页面也能访问成功,在此阶段我们要进行登录判断,如果没有登录则访问任意页面都跳转到登录页面。由于是单体项目,所以采用session验证登录状态是最简单的,如果是集群、分布式项目的话就采用token。
具体实现:
使用过滤器或者拦截器,在过滤器或者拦截器中判断用户是否已经完成登录,如果没有登录则跳转到登录页面。
代码实现
- 创建自定义过滤器LoginCheckFilter
- 在启动类上加入注解@ServletComponentScan,才会去扫描过滤器
- 完善过滤器的处理逻辑
LoginCheckFilter
package com.lzk.reggie.filter;
//urlPatterns配置拦截路径,这里表示拦截所有
@WebFilter(filterName="loginCheckFilter",urlPatterns = "/*")
@Slf4j
public class LoginCheckFilter implements Filter {
//路径匹配器,支持通配符
public static final AntPathMatcher PATH_MATCHER = new AntPathMatcher();
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
//1.获取本次请求的URI
String requestURI = request.getRequestURI();
//定义不需要处理的请求路径,下面的*只是字符串,并不是通配符
String[] urls = new String[]{
"/employee/login",
"/employee/logout",
"/backend/**",
"/front/**"
};
//2.判断本次请求是否需要处理
boolean check = check(urls,requestURI);
//3.如果不需要处理,直接放行
if(check){
filterChain.doFilter(request,response);
return;
}
//4.如果需要处理,判断是否登录
if(request.getSession().getAttribute("employee")!=null){
filterChain.doFilter(request,response);
return;
}
//5.方法一:如果未登录则返回未登录结果,通过输出流方式向客户端页面响应数据,因为我们返回的是void,所以不能return R.error("NOTLOGIN")
response.getWriter().write(JSON.toJSONString(R.error("NOTLOGIN")));
//5.方法二:页面重定向,重定向路径为绝对或相对,自己根据项目登录页面的路径写好
response.sendRedirect("login.html");
return;
}
public boolean check(String[] urls,String requestURI){
for(String url:urls){
boolean match = PATH_MATCHER.match(url,requestURI);
if(match){
return true;
}
}
return false;
}
}
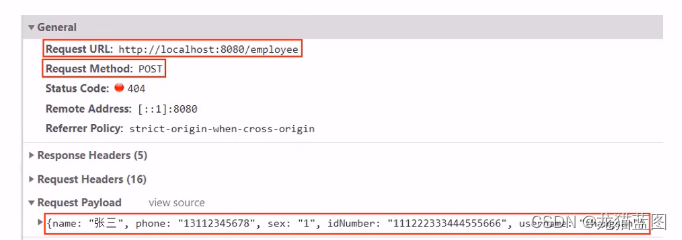
8. 员工增删改查功能开发
开发流程同上,都是根据前端发起的请求编写Controller—>Service—>Dao,我们的EmployeeController层已经创建完毕,功能的增加只需要在原有的EmployeeController层上进行添加。
在开发代码之前,需要梳理一下整个程序的执行过程:
1、页面发送ajax请求,将新增员工页面中输入的数据以json的形式提交到服务端
2、服务端Controller接收页面提交的数据并调用Service将数据进行保存
3、Service调用Mapperi操作数据库,保存数据
-
新增操作
-
查询操作
可以根据员工姓名进行查询
分页插件
只有添加了分页插件,后续的分页查询才能真正实现分页查询。
注意需要在启动类上进行以下相应注解配置,否则会报SQL错误
@ServletComponentScan
@EnableTransactionManagement
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
MybatisPlusInterceptor mybatisPlusInterceptor = new MybatisPlusInterceptor();
mybatisPlusInterceptor.addInnerInterceptor(new PaginationInnerInterceptor());
return mybatisPlusInterceptor;
}
}
员工CRUD操作
package com.lzk.reggie.controller;
@Slf4j
@RestController
@RequestMapping("/employee")
public class EmployeeController {
@Autowired
private EmployeeService employeeService;
//登录操作
@PostMapping("/login")
public R<Employee> login(HttpServletRequest request, @RequestBody Employee employee){
...
}
//退出操作
@PostMapping("/logout")
public R<String> logout(HttpServletRequest request){
...
}
//新增操作
@PostMapping
public R<String> save(HttpServletRequest request,@RequestBody Employee employee){
log.info("新增员工,员工信息:{}",employee.toString());
//设置初始化密码,需要进行md5加密处理
employee.setPassword(DigestUtils.md5DigestAsHex("123456".getBytes()));
employee.setCreateTime(LocalDateTime.now());
employee.setUpdateTime(LocalDateTime.now());
Long empId = (Long) request.getSession().getAttribute("employee");
employee.setCreateUser(empId);
employee.setUpdateUser(empId);
employeeService.save(employee);
return R.success("新增员工成功");
}
//查询某一页操作,name表示的是姓名查询
@GetMapping("/page")
public R<Page> page(int page,int pageSize,String name){
log.info("page = {},pageSize = {},name = {}",page,pageSize,name);
Page pageInfo = new Page(page,pageSize);
LambdaQueryWrapper<Employee> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.like(StringUtils.isNotEmpty(name),Employee::getName,name);
queryWrapper.orderByDesc(Employee::getUpdateTime);
employeeService.page(pageInfo,queryWrapper);
return R.success(pageInfo);
}
//修改操作,启用禁用状态的修改也是通过这个方法去操作,通过前端页面修改状态码并发送请求到update方法,我们需要解决精度丢失问题
@PutMapping
public R<String> update(HttpServletRequest request,@RequestBody Employee employee){
log.info(employee.toString());
Long empId = (Long)request.getSession().getAttribute("employee");
employee.setUpdateTime(LocalDateTime.now());
employee.setUpdateUser(empId);
employeeService.updateById(employee);
return R.success("员工信息修改成功");
}
//查询单个员工
@GetMapping("/{id}")
public R<Employee> getById(@PathVariable Long id){
log.info("根据id查询员工信息");
Employee employee = employeeService.getById(id);
if(employee!=null){
return R.success(employee);
}
return R.error("没有查询到对应员工信息");
}
}
全局异常处理器
前面的程序还存在一个问题,就是当我们在新增员工时输入的账号已经存在,由于employee:表中对该字段加入了唯一约束,此时程序会抛出异常:
java.sql.SQLIntegrityConstraintViolationException:Duplicate entry zhangsan'for key idx_username
此时需要我们的程序进行异常捕获,通常有两种处理方式:
- 在Controller方法中加入try、catch进行异常捕获
- 使用异常处理器进行全局异常捕获
若使用try…catch方法则每个Controller层都需要进行try…catch处理service层或者mapper层往上抛出的异常,如果使用全局异常处理器则不用。
//表示拦截RestController,Controller注解标识的类抛出的异常,由该类进行处理
@ControllerAdvice(annotations = {RestController.class, Controller.class})
@ResponseBody
@Slf4j
public class GlobalExceptionHandler {
//捕获到的异常跟括号中的异常类型进行匹配,如果一致则进行处理
@ExceptionHandler(SQLIntegrityConstraintViolationException.class)
public R<String> exceptionHandler(SQLIntegrityConstraintViolationException ex){
log.error(ex.getMessage());
if(ex.getMessage().contains("Duplicate entry")){
String[] split = ex.getMessage().split(" ");
String msg = split[2]+"已存在";
return R.error(msg);
}
return R.error("未知错误");
}
}
解决精度丢失
我们在进行修改操作时,发现修改既不报错也不生效。我们进行排查后发现服务器端将数据返回给前端时没有出错,但是前端js将数据进行处理时却出错了,因为id是Long类型的,而js在处理Long类型的数据时只能处理前16位,后3位进行了四舍五入操作,例如后3位为225->200,所以前端的数据就出错了,在修改后发起请求时携带的数据就是错误的,所以修改并不生效。
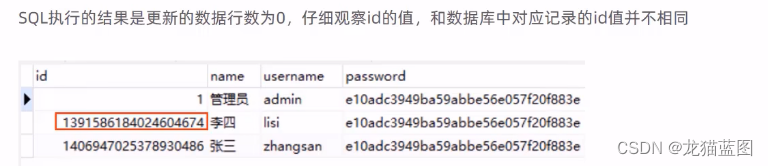
解决方法:
服务器给页面响应json数据时进行处理,将long类型的数据统一为String类型
解决步骤:
对象转换器
- 提供对象转换器JacksonObjectMapper,基于Jackson进行Java对象到json数据的相互转换,同时将long类型转为String类型。
addSerializer(Long.class, ToStringSerializer.instance)
package com.ldh.reggie.common;
/**
* 对象映射器:基于jackson将Java对象转为json,或者将json转为Java对象
* 将JSON解析为Java对象的过程称为 [从JSON反序列化Java对象]
* 从Java对象生成JSON的过程称为 [序列化Java对象到JSON]
*/
public class JacksonObjectMapper extends ObjectMapper {
public static final String DEFAULT_DATE_FORMAT = "yyyy-MM-dd";
public static final String DEFAULT_DATE_TIME_FORMAT = "yyyy-MM-dd HH:mm:ss";
public static final String DEFAULT_TIME_FORMAT = "HH:mm:ss";
public JacksonObjectMapper() {
super();
//收到未知属性时不报异常
this.configure(FAIL_ON_UNKNOWN_PROPERTIES, false);
//反序列化时,属性不存在的兼容处理
this.getDeserializationConfig().withoutFeatures(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES);
SimpleModule simpleModule = new SimpleModule()
.addDeserializer(LocalDateTime.class, new LocalDateTimeDeserializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_TIME_FORMAT)))
.addDeserializer(LocalDate.class, new LocalDateDeserializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_FORMAT)))
.addDeserializer(LocalTime.class, new LocalTimeDeserializer(DateTimeFormatter.ofPattern(DEFAULT_TIME_FORMAT)))
.addSerializer(BigInteger.class, ToStringSerializer.instance)
//将Long类型的数据转为String类型
.addSerializer(Long.class, ToStringSerializer.instance)
.addSerializer(LocalDateTime.class, new LocalDateTimeSerializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_TIME_FORMAT)))
.addSerializer(LocalDate.class, new LocalDateSerializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_FORMAT)))
.addSerializer(LocalTime.class, new LocalTimeSerializer(DateTimeFormatter.ofPattern(DEFAULT_TIME_FORMAT)));
//注册功能模块 例如,可以添加自定义序列化器和反序列化器
this.registerModule(simpleModule);
}
}
消息转换器
- 在WebMvcConfig配置类中扩展Spring mvc的消息转换器,在此消息转换器中使用提供的
对象转换器进行Java对象到json数据的转换,其中特别的是会将long类型数据转为String类型。不扩展配置则默认使用Spring mvc的消息转换器,它也会将Java对象与Json类型之间进行相互转换,这就是为什么我们在CRUD操作中返回return R.success(pageInfo),前端页面获取到的是JSON类型的数据。
package com.ldh.reggie.config;
@Slf4j
@Configuration
public class WebMvcConfig extends WebMvcConfigurationSupport {
//扩展mvc框架的消息转换器
@Override
protected void extendMessageConverters(List<HttpMessageConverter<?>> converters) {
//创建消息转换器对象
MappingJackson2HttpMessageConverter messageConverter = new MappingJackson2HttpMessageConverter();
//设置对象转换器,底层使用Jackson将Java对象转为json
messageConverter.setObjectMapper(new JacksonObjectMapper());
//将上面的消息转换器对象追加到mvc框架的转换器集合中,index为转换器在集合中的顺序,最先才能生效
converters.add(0,messageConverter);
}
}
9. 公共字段自动填充
使用Mybatis Plus提供的公共字段自动填充功能。
前面我们已经完成了后台系统的员工管理功能开发,在新增员工时需要设置创建时间、创建人、修改时间、修改人等字段,在编辑员工时需要设置修改时间和修改人等字段。这些字段属于公共字段,也就是很多表中都有这些字段,如下:
| 字段 | 类型 |
|---|---|
| create_time | datetime |
| update_time | datetime |
| create_user | bigint |
| update_user | bigint |
能不能对于这些公共字段在某个地方统一处理,来简化开发呢?
答案就是使用Mybatis-Plus提供的公共字段自动填充功能。
Mybatis Plus公共字段自动填充,也就是在插入或者更新的时候为指定字段赋予指定的值,使用它的好处就是可以统一对这些字段进行处理,避免了重复代码。
实现步骤:
- 在实体类的属性上加入@TableField注解,指定自动填充的策略
- 按照框架要求编写元数据对象处理器,在此类中统一为公共字段赋值,此类需要实现MetaObjectHandler接口
员工实体类
package com.ldh.reggie.entity;
@Data
public class Employee implements Serializable {
private static final long serialVersionUID = 1L;
private Long id;
private String username;
private String name;
private String password;
private String phone;
private String sex;
private String idNumber;
private Integer status;
@TableField(fill = FieldFill.INSERT) //插入时由元数据对象处理器帮助我们填充字段
private LocalDateTime createTime;
@TableField(fill = FieldFill.INSERT_UPDATE) //插入和更新时填充字段
private LocalDateTime updateTime;
@TableField(fill = FieldFill.INSERT)
private Long createUser;
@TableField(fill = FieldFill.INSERT_UPDATE)
private Long updateUser;
}
自定义元数据对象处理器
当我们执行新增操作时,就会执行元数据对象处理器中的insertFill方法,其中参数:metaObject对象中就存在当前操作的对象,例如执行新增员工操作时就会执行到元数据对象处理器中的insertFill方法,metaObject中就存在当前操作的employee对象,此时我们通过metaObject.setValue为我们需要填充的字段赋值。
package com.lzk.reggie.common;
@Component
@Slf4j
public class MyMetaObjectHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
log.info("公共字段自动填充[insert]...");
log.info(metaObject.toString());
metaObject.setValue("createTime", LocalDateTime.now());
metaObject.setValue("updateTime",LocalDateTime.now());
metaObject.setValue("createUser",BaseContext.getCurrentId());
metaObject.setValue("updateUser",BaseContext.getCurrentId());
}
@Override
public void updateFill(MetaObject metaObject) {
log.info("公共字段自动填充[update]...");
log.info(metaObject.toString());
metaObject.setValue("updateTime",LocalDateTime.now());
metaObject.setValue("updateUser",BaseContext.getCurrentId());
}
}
由于公共字段createUser是根据session中保存的id值进行获取的,而MyMetaObjectHandler不能获取session对象,所以需要通过ThreadLocal来解决这个问题。
ThreadLocal解决session问题
前面我们已经完成了公共字段自动填充功能的代码开发,但是还有一个问题没有解决,就是我们在自动填充createUseri和updateUser时设置的用户id是固定值,现在我们需要改造成动态获取当前登录用户的id。
有的同学可能想到,用户登录成功后我们将用户id存入了HttpSession中,现在我从HttpSession中获取不就行了?
注意,我们在MyMetaObjectHandler类中是不能获得HttpSession.对象的,所以我们需要通过其他方式来获取登录用户id。
可以使用ThreadLocal来解决此问题,它是JDK中提供的一个类。
原因
在学习ThreadLocal之前,我们需要先确认一个事情,就是客户端发送的每次http请求,对应的在服务端都会分配一个的线程来处理,在处理过程中涉及到下面类中的方法都属于相同的一个线程:
- LoginCheckFilter的doFilter方法
- EmployeeController的update方法
- MyMetaObjectHandler的updateFill方法
可以在上面的三个方法中分别加入下面代码(获取当前线程id):
long id = Thread.currentThread().getId(:
log.info("线程id:{}",id):

什么是ThreadLocal
ThreadLocal并不是一个Thread,而是Thread的局部变量。当使用ThreadLocal维护变量时,ThreadLocal为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。
ThreadLocal为每个线程提供单独一份存储空间,具有线程隔离的效果,只有在线程内才能获取到对应的值,线程外则不能访问。
ThreadLocal常用方法:
public void set(T value) //设置当前线程的线程局部变量的值
public T get() //返回当前线程所对应的线程局部变量的值
我们可以在LoginCheckFilter的doFilter方法中获取当前登录用户id,并调用ThreadLocal的set方法来设置当前线程的线程局部变量的值(用户id),然后在MyMetaObjectHandler的updateFill方法中调用ThreadLocal的get方法来获得当前线程所对应的线程局部变量的值(用户id)。
代码解决
实现步骤:
- 编写BaseContext.工具类,基于ThreadLocal封装的工具类
- 在LoginCheckFilter的doFilter,方法中调用BaseContext来设置当前登录用户的id
- 在MyMetaObjectHandler的方法中调用BaseContext获取登录用户的id
public class BaseContext {
private static ThreadLocal<Long> threadLocal = new ThreadLocal<>();
public static void setCurrentId(Long id){
threadLocal.set(id);
}
public static Long getCurrentId(){
return threadLocal.get();
}
}
由于我们一次请求对应一个线程处理,而每一次请求的过程为过滤器LoginCheckFilter→Controller层→MyMetaObjectHandler,所以需要在LoginCheckFilter设置线程id,因为我们是想要获取当前登录用户id,所以线程id就为用户id,而MyMetaObjectHandler就可以通过获取线程id从而获取到当前登录用户id值。
修改LoginCheckFilter
只需要将登录成功后的用户id放入到当前线程id中去,而后就可以在MyMetaObjectHandler中通过metaObject.setValue(“updateUser”,BaseContext.getCurrentId())获取登录用户id值了。
//4.如果需要处理,判断是否登录
if(request.getSession().getAttribute("employee")!=null){
Long empId = (Long) request.getSession().getAttribute("employee");
BaseContext.setCurrentId(empId);
filterChain.doFilter(request,response);
return;
}
10. 分类CRUD开发
操作流程同员工增删改查一致,有一个不同点就是删除操作,由于我们的分类分为:菜品分类和套餐分类。
category表
其中,type表示类别:1为菜品,2为套餐。sort表示排序,主要体现在移动端点餐时在用户界面的排序。

dish表
主要关注category_id字段,表示菜品所属分类,如辣子鸡的category_id等于category表中的湘菜id,所以它属于湘菜。但是在表设计中并没有设计主外键关联关系,这是因为外键关联会降低查询效率。但是我们在实际业务中是需要体现出他们的主外键关联关系的,因为菜品的展示需要我们通过某个分类来展示,例如点击湘菜时辣子鸡便会出现。所以分类中的删除操作就不能仅仅根据id删除某个分类,这样做会导致菜品展示不出来,所以我们在进行删除操作之前需要判断某个分类下有没有关联的菜品。套餐也是如此。
注意一:此处如果我们将dish表中的category_id和category表中的id进行主外键关联后,当我们进行删除操作时,我们并不需要自己判断category中的某个分类是否有其他菜品关联,因为如果有主外键关联的情况下,从表的数据存在,主表的数据也删除不了。例如:dish表中的辣子鸡存在,category表中的湘菜便删除不了。
注意二:忽略这个场景下的业务需求,category表和dish表进行了主外键关联,而我们想要删除湘菜这个字段时,需要先将dish表中的辣子鸡这个数据删除后才能操作成功,这属于物理删除,但我们也可以使用逻辑删除,就是在category表中添加一个字段is_deleted(1表示删除,0表示存在),如果我们想要删除某条数据,我们可以将这条数据的is_deleted字段设置为1,后续对数据的查询总是需要判断is_deleted=0,才是可以展示给用户的数据。
CategoryServiceImpl
下面重写删除分类方法,删除前先判断菜品表dish中和套餐表Setmeal中是否存在有与这个id值一致的category_id数据,若有则不能删除,同时抛出一个异常用于作为数据的展示。
package com.ldh.reggie.service.impl;
@Service
public class CategoryServiceImpl extends ServiceImpl<CategoryMapper, Category> implements CategoryService {
@Autowired
private DishService dishService;
@Autowired
private SetmealService setmealService;
@Override
public void remove(Long id) {
LambdaQueryWrapper<Dish> dishLambdaQueryWrapper = new LambdaQueryWrapper<>();
//添加查询条件,根据分类进行查询
dishLambdaQueryWrapper.eq(Dish::getCategoryId,id);
int count1 = dishService.count(dishLambdaQueryWrapper);
//查询当前分类是否已经关联了菜品,如果已经关联,抛出一个业务异常
if(count1 > 0){
//已经关联菜品,抛出一个业务异常
throw new CustomException("当前分类下关联的菜品,不能删除");
}
//查询当前分类是否已经关联了套餐,如果已经关联,抛出一个业务异常
LambdaQueryWrapper<Setmeal> setmealLambdaQueryWrapper = new LambdaQueryWrapper<>();
//添加查询条件,根据分类进行查询
setmealLambdaQueryWrapper.eq(Setmeal::getCategoryId,id);
int count2 = setmealService.count(setmealLambdaQueryWrapper);
//查询当前分类是否已经关联了菜品,如果已经关联,抛出一个业务异常
if(count2 > 0){
//已经关联菜品,抛出一个业务异常
throw new CustomException("当前分类下关联的套餐,不能删除");
}
//正常删除
super.removeById(id);
}
}
自定义异常
package com.ldh.reggie.common;
public class CustomException extends RuntimeException{
public CustomException(String message){
super(message);
}
}
修改GlobalExceptionHandler
添加多一个方法
//表示拦截RestController,Controller注解标识的类抛出的异常由该类进行处理
@ControllerAdvice(annotations = {RestController.class, Controller.class})
@ResponseBody
@Slf4j
public class GlobalExceptionHandler {
...
@ExceptionHandler(CustomException.class)
public R<String> exceptionHandler(CustomException ex){
log.error(ex.getMessage());
return R.error(ex.getMessage());
}
}
11. 文件上传下载
文件上传
文件上传,也称为upload,是指将本地图片、视频、音频等文件上传到服务器上,可以供其他用户浏览或下载的过程。
文件上传在项目中应用非常广泛,我们经常发微博、发微信朋友圈都用到了文件上传功能。
文件上传时,对页面的form表单有如下要求:
| 要求 | 说明 |
|---|---|
| method=“post” | 采用post方式提交数据 |
| enctype=“multipart/form-data” | 采用multipart格式上传文件 |
| type=“file” | 使用inputi的file控件上传 |
举例:
<form method="post" action="/common/upload" enctype="multipart/form-data">
<input name="myFile" type="file"/>
<input type="submit" value="提交"/>
</form≥
服务端要接收客户端页面上传的文件,通常都会使用Apache的两个组件:
- commons-fileupload
- commons-io
Spring框架在spring-web包中对文件上传进行了封装,大大简化了服务端代码,我们只需要在Controller的方法中声明一个MultipartFile类型的参数即可接收上传的文件,例如:
PostMapping (value="/upload")
public R<String> upload (MultipartFile file){
System.out.println(file);
return null;
}
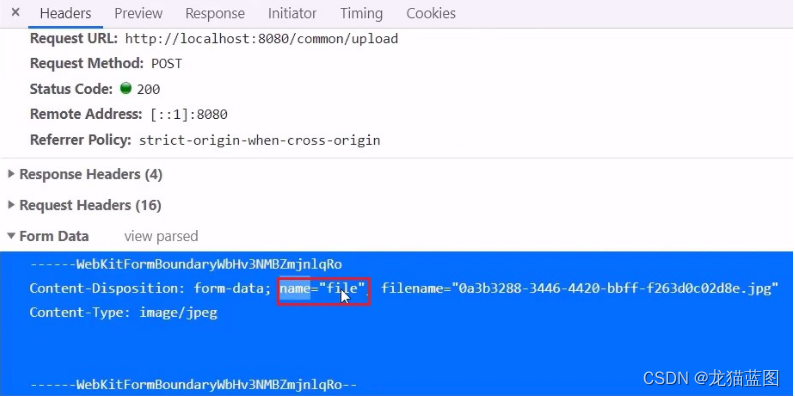
由于在页面的请求中name="file",这也是固定的,所以服务器端的MultipartFile类型的参数名也需为file。
前端代码
使用element-ui页面上传图片:只是对样式做了美化,本质上还是满足post请求,格式为Multipart,类型为file
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>文件上传</title>
<!-- 引入样式 -->
<link rel="stylesheet" href="../../plugins/element-ui/index.css" />
<link rel="stylesheet" href="../../styles/common.css" />
<link rel="stylesheet" href="../../styles/page.css" />
</head>
<body>
<div class="addBrand-container" id="food-add-app">
<div class="container">
<el-upload class="avatar-uploader"
action="/common/upload"
:show-file-list="false"
:on-success="handleAvatarSuccess"
:before-upload="beforeUpload"
ref="upload">
<img v-if="imageUrl" :src="imageUrl" class="avatar"></img>
<i v-else class="el-icon-plus avatar-uploader-icon"></i>
</el-upload>
</div>
</div>
<!-- 开发环境版本,包含了有帮助的命令行警告 -->
<script src="../../plugins/vue/vue.js"></script>
<!-- 引入组件库 -->
<script src="../../plugins/element-ui/index.js"></script>
<!-- 引入axios -->
<script src="../../plugins/axios/axios.min.js"></script>
<script src="../../js/index.js"></script>
<script>
new Vue({
el: '#food-add-app',
data() {
return {
imageUrl: ''
}
},
methods: {
handleAvatarSuccess (response, file, fileList) {
this.imageUrl = `/common/download?name=${response.data}`
},
beforeUpload (file) {
if(file){
const suffix = file.name.split('.')[1]
const size = file.size / 1024 / 1024 < 2
if(['png','jpeg','jpg'].indexOf(suffix) < 0){
this.$message.error('上传图片只支持 png、jpeg、jpg 格式!')
this.$refs.upload.clearFiles()
return false
}
if(!size){
this.$message.error('上传文件大小不能超过 2MB!')
return false
}
return file
}
}
}
})
</script>
</body>
</html>
后端代码
配置文件添加
reggie:
path: D:\img\
package com.ldh.reggie.controller;
import com.lzk.reggie.common.R;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletResponse;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.UUID;
@RestController
@RequestMapping("/common")
@Slf4j
public class CommonController {
@Value("${reggie.path}")
private String basePath;
@PostMapping("/upload")
public R<String> upload(MultipartFile file){
//file是一个临时文件,需要转换到指定位置,否则本次请求完成后临时文件会删除,上传的文件也就不见了
log.info(file.toString());
//原始文件名,我们通过原始文件名去获取上传文件后缀,注意不要使用原始文件名作为保存名,
// 因为不同用户可能上传同名文件,会覆盖
String originalFilename = file.getOriginalFilename();
String suffix = originalFilename.substring(originalFilename.lastIndexOf("."));
//使用UUID重新生成文件名,防止文件名称重复造成文件覆盖
String fileName = UUID.randomUUID().toString() + suffix;
//创建一个目录对象
File dir = new File(basePath);
//判断目录是否存在
if(!dir.exists()){
dir.mkdirs();
}
try{
//将临时文件转存到指定位置
file.transferTo(new File(basePath + fileName));
}catch (IOException e){
e.printStackTrace();
}
return R.success(fileName);
}
@GetMapping("/download")
public void download(String name, HttpServletResponse response){
try{
//输入流,通过输入流读取文件内容
FileInputStream fileInputStream = new FileInputStream(new File(basePath+name));
//输出流,通过输出流将文件写回浏览器,在浏览器展示图片
ServletOutputStream outputStream = response.getOutputStream();
response.setContentType("image/jpeg");
int len = 0;
byte[] bytes = new byte[1024];
while((len = fileInputStream.read(bytes))!= -1){
outputStream.write(bytes,0,len);
outputStream.flush();
}
//关闭资源
outputStream.close();
fileInputStream.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
文件下载
文件下载,也称为download,是指将文件从服务器传输到本地计算机的过程。通过浏览器进行文件下载,通常有两种表现形式:
- 以附件形式下载,弹出保存对话框,将文件保存到指定磁盘目录
- 直接在浏览器中打开
通过浏览器进行文件下载,本质上就是服务端将文件以流的形式写回浏览器的过程。
由于我们菜品图片的展示只是通过浏览器,所以选择直接在浏览器中打开的方式即可。
以下代码表示上传后img标签的src属性就会去访问imgUrl,从而访问到一个请求路径进而展示在浏览器展示图片
前后端代码均看文件上传部分。
12. 菜品增删改查功能开发
本节都涉及到多表问题
菜品的分类通过Ajax发起一个异步请求请求数据库中存储的菜品分类。
后台系统中可以管理菜品信息,通过新增功能来添加一个新的菜品,在添加菜品时需要选择当前菜品所属的菜品分类,并且需要上传菜品图片,在移动端会按照菜品分类来展示对应的菜品信息。
新增菜品,其实就是将新增页面录入的菜品信息插入到dish表,如果添加了口味做法,还需要向dish flavor:表插入数据。
所以在新增菜品时,涉及到两个表:
- dish 菜品表
- dish flavor 菜品口味表
dish菜品表:
dish_flavor菜品口味表:可以看到辣子鸡对应的口味,若有两种口味则在表中对应两条数据。


新增流程
- 获取菜品分类
//由于是get请求所以不需要@RequestBody,获取Post请求请求体中的数据才需要这个注解
@GetMapping("/list")
public R<List<Category>> list(Category category){
//条件构造器
LambdaQueryWrapper<Category> queryWrapper = new LambdaQueryWrapper<>();
//添加条件
queryWrapper.eq(category.getType()!=null,Category::getType,category.getType());
queryWrapper.orderByAsc(Category::getSort).orderByDesc(Category::getUpdateTime);
List<Category> list = categoryService.list(queryWrapper);
return R.success(list);
}
-
添加操作
由于需要操作两张表,菜品名,价格部分的信息是添加到dish表中的,而口味方面的信息则是添加到dishflavor表中的。所以获取信息时,需要通过一个新的实体类
DishDto来获取两者的信息。类名后为Dto结尾的,表示Data Transfer Object(数据传输对象)。用于前后端数据之前的传递,这些以Dto结尾的类可以很明确的知道其作用,当然有些数据传递可以使用数据模型层中的实体类,因为本身就能够满足需求了,此处需要使用DishDto是因为前端需要的数据Dish不能完全满足,所以DishDto在继承了Dish类的基础上还额外增加了两个字段。
DishDto
@Data
public class DishDto extends Dish {
private List<DishFlavor> flavors = new ArrayList<>();
private String categoryName;
private Integer copies;
}
DishServiceImpl
在接口层添加该方法saveWithFlavor,接口实现类再去实现。
由于前端封装的数据没有菜品Id,需要将菜品保存到数据库时通过雪花算法自动生成,所以在进行菜品口味添加时要先将菜品Id值赋给菜品口味实体类
其实SpringBoot默认就开启了事务,所以可以不加此注解,只是了解如何开注解而已,添加该注解后要在启动类上添加注解@EnableTransactionManagement
@Service
@Transactional
public class DishServiceImpl extends ServiceImpl<DishMapper, Dish> implements DishService {
@Autowired
private DishFlavorService dishFlavorService;
public void saveWithFlavor(DishDto dishDto) {
//保存菜品的基本信息到到菜品表dish
this.save(dishDto);
//save后菜品Id由雪花算法自动生成
Long dishId = dishDto.getId();
//菜品口味,口味对应菜品id设置
List<DishFlavor> flavors = dishDto.getFlavors();
flavors = flavors.stream().map((item)->{
item.setDishId(dishId);
return item;
}).collect(Collectors.toList());
//保存菜品口味数据到菜品口味表
dishFlavorService.saveBatch(dishDto.getFlavors());
}
}
DishController
@RestController
@RequestMapping("/dish")
public class DishController {
@Autowired
private DishService dishService;
@Autowired
private DishFlavorService dishFlavorService;
@PostMapping
public R<String> save(@RequestBody DishDto dishDto){
dishService.saveWithFlavor(dishDto);
return R.success("新增菜品成功");
}
}
菜品查询
我们可以看到在分页中有图片信息也有菜品分类,但是菜品分类名和菜品信息存在于两张表中。图片的查询则是通过Ajax发起的异步请求,上面的文件下载已经写好了。
代码流程开发梳理:
在开发代码之前,需要梳理一下菜品分页查询时前端页面和服务端的交互过程:
- 页面(backend/page/food/list.html)发送ajax请求,将分页查询参数(page、pageSize、name)提交到服务端,获取分页数据
- 页面发送请求,请求服务端进行图片下载,用于页面图片展示
- 开发菜品信息分页查询功能,其实就是在服务端编写代码去处理前端页面发送的这2次请求即可。
DishController
由于Dish表中没有菜品分类的名称,只有Id,所以只能通过遍历每个菜品用其Id值去查询菜品名再将其封装到dishDto中,但是感觉速率降低了。这就是时间换空间,通过牺牲查询效率去节省存储空间。
@RestController
@RequestMapping("/dish")
public class DishController {
@Autowired
private DishService dishService;
@Autowired
private DishFlavorService dishFlavorService;
@Autowired
private CategoryService categoryService;
@PostMapping
public R<String> save(@RequestBody DishDto dishDto){
dishService.saveWithFlavor(dishDto);
return R.success("新增菜品成功");
}
@GetMapping("/page")
public R<Page> page(int page,int pageSize,String name){
//构造分页构造器对象,查询到Dish实体类封装成的Page对象
Page<Dish> pageInfo = new Page<>(page,pageSize);
//由于Dish表中中没有菜品对应的分类名,只有分类ID,所以需要先查询Dish对象
// 再根据Dish对象中的分类ID值获取分类名
Page<DishDto> dishDtoPage = new Page<>();
//条件构造器
LambdaQueryWrapper<Dish> queryWrapper = new LambdaQueryWrapper<>();
//添加过滤条件
queryWrapper.like(name!=null,Dish::getName,name);
//添加排序条件
queryWrapper.orderByDesc(Dish::getUpdateTime);
//执行分页查询
dishService.page(pageInfo,queryWrapper);
//对象拷贝,忽略pageInfo中的records属性,因为原有的缺少分类名属性,
// 所以需要通过下面的操作添加records数据
BeanUtils.copyProperties(pageInfo,dishDtoPage,"records");
List<Dish> records = pageInfo.getRecords();
//为每一条数据添加分类名
List<DishDto> list = records.stream().map((item) ->{
DishDto dishDto = new DishDto();
BeanUtils.copyProperties(item,dishDto);
Long categoryId = item.getCategoryId();
Category category = categoryService.getById(categoryId);
if(category!=null){
String categoryName = category.getName();
dishDto.setCategoryName(categoryName);
}
return dishDto;
}).collect(Collectors.toList());
dishDtoPage.setRecords(list);
return R.success(dishDtoPage);
}
}
修改菜品
要先进行数据回显在进行修改操作。
请求数据DishController
@GetMapping("/{id}")
public R<DishDto> get(@PathVariable Long id){
DishDto dishDto = dishService.getByIdWithFlavor(id);
return R.success(dishDto);
}
DishServiceImpl
先将菜品数据获取到后根据菜品Id获取菜品口味表中的口味信息。
public DishDto getByIdWithFlavor(Long id) {
//查询菜品基本信息,从dish表中查询
Dish dish = this.getById(id);
DishDto dishDto = new DishDto();
BeanUtils.copyProperties(dish,dishDto);
LambdaQueryWrapper<DishFlavor> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(DishFlavor::getDishId,dish.getId());
List<DishFlavor> flavors = dishFlavorService.list(queryWrapper);
dishDto.setFlavors(flavors);
return dishDto;
}
修改操作DishController
@PutMapping
public R<String> update(@RequestBody DishDto dishDto){
dishService.updateWithFlavor(dishDto);
return R.success("新增菜品成功");
}
DishServiceImpl
由于数据是存在两张表中而且一种菜品可能对应口味表中的多条数据,如果修改是要减少某种口味,那么修改操作就不能实现业务功能。所以我们对口味的修改是先删除后添加。
public void updateWithFlavor(DishDto dishDto) {
//更新dish表基本信息
this.updateById(dishDto);
//清理当前菜品对应口味数据--dish_flavor表的delete操作
LambdaQueryWrapper<DishFlavor> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(DishFlavor::getDishId,dishDto.getId());
dishFlavorService.remove(queryWrapper);
//添加当前提交过来的口味数据--dish_flavor表的insert操作
List<DishFlavor> flavors = dishDto.getFlavors();
flavors = flavors.stream().map((item) ->{
item.setDishId(dishDto.getId());
return item;
}).collect(Collectors.toList());
dishFlavorService.saveBatch(flavors);
}
13. 套餐增删改查功能开发
本节同菜品开发都是多表操作
新增操作
套餐就是菜品的集合。
后台系统中可以管理套餐信息,通过新增套餐功能来添加一个新的套餐,在添加套餐时需要选择当前套餐所属的套餐分类和包含的菜品,并且需要上传套餐对应的图片,在移动端会按照套餐分类来展示对应的套餐。
新增套餐,其实就是将新增页面录入的套餐信息插入到setmeal表,还需要向setmeal_dish表插入套餐和菜品关联数据。
所以在新增套餐时,涉及到两个表:
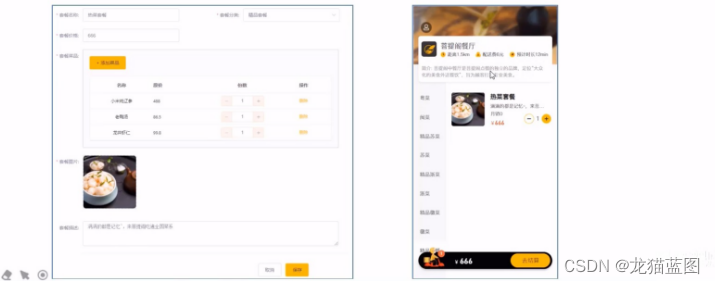
- setmeal 套餐表
- setmeal_dish套餐菜品关系表
套餐表中只有套餐名,套餐id,价格,状态1表示在售,0表示停售。
套餐菜品关系表中的setmeal_id表示该菜品对应哪个套餐。


在开发代码之前,需要梳理一下新增套餐时前端页面和服务端的交互过程:
- 页面(backend./page/combo/add.html)发送ajax请求,请求服务端获取套餐分类数据并展示到下拉框中
- 页面发送ajax请求,请求服务端获取菜品分类数据并展示到添加菜品窗口中
- 页面发送ajax请求,请求服务端,根据菜品分类查询对应的菜品数据并展示到添加菜品窗口中
- 页面发送请求进行图片上传,请求服务端将图片保存到服务器
- 页面发送请求进行图片下载,将上传的图片进行回显
- 点击保存按钮,发送ajax请求,将套餐相关数据以json形式提交到服务端
1,2操作之前已经开发完毕,有前端封装的type数据决定请求的是套餐分类还是菜品分类。
3操作如下:
@GetMapping("/list")
public R<List<Dish>> lsit(Dish dish){
LambdaQueryWrapper<Dish> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(dish.getCategoryId()!=null,Dish::getCategoryId,dish.getCategoryId())
.eq(Dish::getStatus,1);
queryWrapper.orderByAsc(Dish::getSort).orderByDesc(Dish::getUpdateTime);
List<Dish> list = dishService.list(queryWrapper);
return R.success(list);
}
前端发起的数据如下:由于套餐表或套餐菜品分类表中都不能存下这些数据,所以借助新的实体类

@Data
public class SetmealDto extends Setmeal {
private List<SetmealDish> setmealDishes;
private String categoryName;
}
SetmealController
@PostMapping
public R<String> save(@RequestBody SetmealDto setmealDto){
setmealService.saveWithDish(setmealDto);
log.info("新增的值为:{}",setmealDto);
return R.success("新增套餐成功");
}
SetmealServiceImpl
由于添加套餐分类时,套餐需存入数据库中才有ID值,而套餐菜品表需借助这个Id值存储菜品才知道菜品对应的套餐。
@Service
public class SetmealServiceImpl extends ServiceImpl<SetmealMapper, Setmeal> implements SetmealService {
@Autowired
private SetmealDishService setmealDishService;
@Override
public void saveWithDish(SetmealDto setmealDto) {
this.save(setmealDto);
List<SetmealDish> setmealDishes = setmealDto.getSetmealDishes();
setmealDishes.stream().map((item)->{
item.setSetmealId(setmealDto.getId());
return item;
}).collect(Collectors.toList());
setmealDishService.saveBatch(setmealDishes);
}
}
分页查询
在开发代码之前,需要梳理一下套餐分页查询时前端页面和服务端的交互过程:
- 页面(backend/page/combo/list.html)发送ajax请求,将分页查询参数(page、pageSize、name)提交到服务端,获取分页数据
- 页面发送请求,请求服务端进行图片下载,用于页面图片展示
开发套餐信息分页查询功能,其实就是在服务端编写代码去处理前端页面发送的这2次请求即可。
由于套餐表中只有套餐分类Id没有对应的套餐分类名(存储在分类表中),所以我们需要将查询出来的套餐分类id再去查询分类表中对应的数据,就可以获取到分类名了。
--SetmealController--
@GetMapping("/page")
public R<Page> page(int page,int pageSize,String name){
Page<Setmeal> pageInfo = new Page<>(page,pageSize);
Page<SetmealDto> dtoPage = new Page<>();
LambdaQueryWrapper<Setmeal> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.like(name!=null,Setmeal::getName,name)
.orderByDesc(Setmeal::getUpdateTime);
setmealService.page(pageInfo,queryWrapper);
BeanUtils.copyProperties(pageInfo,dtoPage,"records");
List<Setmeal> records = pageInfo.getRecords();
List<SetmealDto> list = records.stream().map((item)->{
SetmealDto setmealDto = new SetmealDto();
BeanUtils.copyProperties(item,setmealDto);
Long categoryId = item.getCategoryId();
Category category = categoryService.getById(categoryId);
if(category != null) {
String categoryName = category.getName();
setmealDto.setCategoryName(categoryName);
}
return setmealDto;
}).collect(Collectors.toList());
dtoPage.setRecords(list);
return R.success(dtoPage);
}
删除操作
在套餐管理列表页面点击删除按钮,可以刷除对应的套餐信息。也可以通过复选框选择多个套餐,点击批量除按钮一次删除多个套餐。注意,对于状态为售卖中的套餐不能删除,需要先停售,然后才能删除。
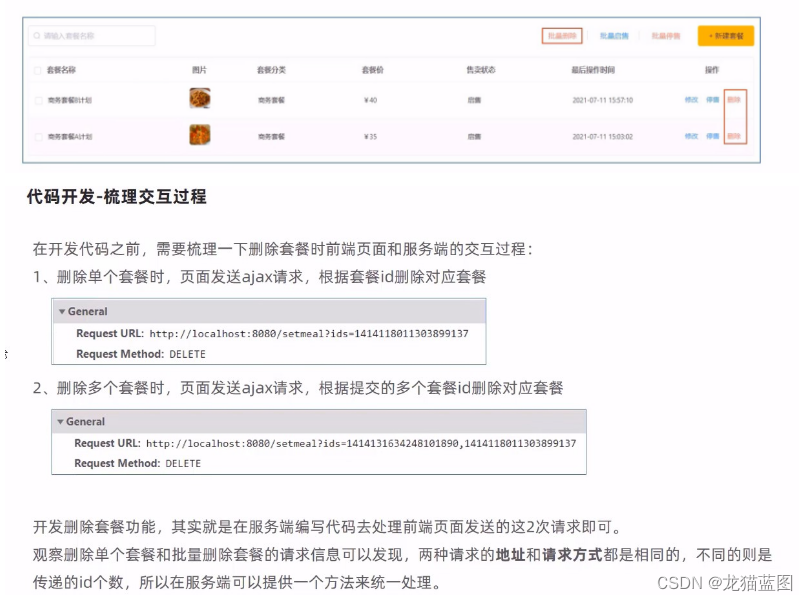
--SetmealController---
@DeleteMapping
public R<String> delete(@RequestParam List<Long> ids){
setmealService.removeWithDish(ids);
return R.success("删除套餐成功");
}
--SetmealServiceImpl---
@Override
public void removeWithDish(List<Long> ids) {
//删除套餐之前要查看套餐状态是否为在售,若是则不能删除,
// 删除套餐里面后其对应的套餐菜品也要删除
//select count(*) from setmeal where id in (1,2,3) and status =1;
LambdaQueryWrapper<Setmeal> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.in(Setmeal::getId,ids);
queryWrapper.eq(Setmeal::getStatus,1);
int count = this.count(queryWrapper);
if(count > 0){
throw new CustomException("套餐正在售卖中,不能删除");
}
//可以删除则删除套餐表中对应的数据
this.removeByIds(ids);
//接着删除每个套餐对应的菜品数据
LambdaQueryWrapper<SetmealDish> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.in(SetmealDish::getSetmealId,ids);
setmealDishService.remove(lambdaQueryWrapper);
}
14. 用户端登录
阿里云短信服务简介
阿里云短信服务(Short Message Service)是广大企业客户快速触达手机用户所优选使用的通信能力。调用API或用群发助手,即可发送验证码、通知类和营销类短信;国内验证短信秒级触达,到达率最高可达99%;国际/港澳台短信覆盖200多个国家和地区,安全稳定,广受出海企业选用。
由于开通短信服务需要上传业务方面的信息,如果没有公司或者注册的商铺信息是申请不了的,所以此处选用短信测试。但是功能比较局限,我们只能为绑定的手机发送短信服务。所以只能使用我的手机号进行验证,如果发送失败检查一下前端是否出错。
短信验证码
为了方便用户登录,移动端通常都会提供通过手机验证码登录的功能。
手机验证码登录的优点:
- 方便快捷,无需注册,直接登录
- 使用短信验证码作为登录凭证,无需记忆密码
- 安全
登录流程:
输入手机号>获取验证码>输入验证码>点击登录>登录成功
注意:通过手机验证码登录,手机号是区分不同用户的标识。
通过手机验证码登录时,涉及的表为user表,即用户表。结构如下:
梳理开发流程:
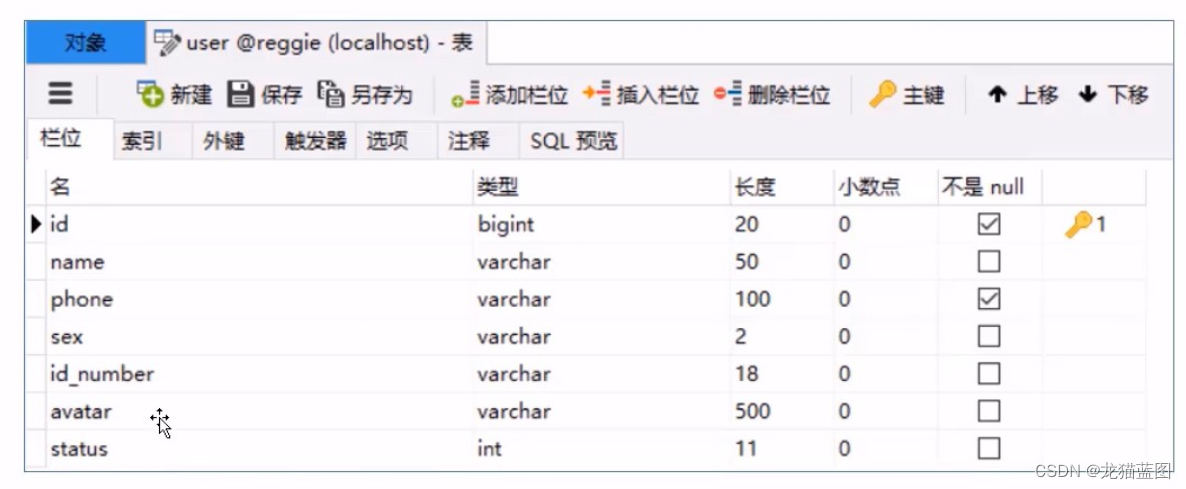
在开发代码之前,需要梳理一下登录时前端页面和服务端的交互过程:
1、在登录页面(front/,page/login.html)输入手机号,点击【获取验证码】按钮,页面发送ajax请求,在服务端调用短信服务API给指定手机号发送验证码短信
2、在登录页面输入验证码,点击【登录】按钮,发送ajax请求,在服务端处理登录请求
开发手机验证码登录功能,其实就是在服务端编写代码去处理前端页面发送的这2次请求即可。
首先需要导入maven坐标:
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>aliyun-java-sdk-core</artifactId>
<version>4.5.16</version>
</dependency>
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>aliyun-java-sdk-dysmsapi</artifactId>
<version>2.1.0</version>
</dependency>
然后使用以下两个工具类进行验证码生成:
SMSUtils
这个类是用于调用阿里云短信服务为我们所填的手机号进行验证码发送的。其中param即为验证码,需要我们自己生成,此处我们使用ValidateCodeUtils随机生成验证码。
注意:xxx,xxx部分要修改为AccessKey,由于暴露有风险,可在阿里云禁用后失效。
package com.ldh.reggie.utils;
/**
* 短信发送工具类
*/
public class SMSUtils {
/**
* 发送短信
* @param signName 签名
* @param templateCode 模板
* @param phoneNumbers 手机号
* @param param 参数
*/
public static void sendMessage(String signName, String templateCode,String phoneNumbers,String param){
DefaultProfile profile = DefaultProfile.getProfile("cn-hangzhou", "xxxx", "xxx");
IAcsClient client = new DefaultAcsClient(profile);
SendSmsRequest request = new SendSmsRequest();
request.setSysRegionId("cn-hangzhou");
request.setPhoneNumbers(phoneNumbers);
request.setSignName(signName);
request.setTemplateCode(templateCode);
request.setTemplateParam("{\"code\":\""+param+"\"}");
try {
SendSmsResponse response = client.getAcsResponse(request);
System.out.println("短信发送成功");
}catch (ClientException e) {
e.printStackTrace();
}
}
}
ValidateCodeUtils
随机生成验证码
package com.ldh.reggie.utils;
import java.util.Random;
/**
* 随机生成验证码工具类
*/
public class ValidateCodeUtils {
/**
* 随机生成验证码
* @param length 长度为4位或者6位
* @return
*/
public static Integer generateValidateCode(int length){
Integer code =null;
if(length == 4){
code = new Random().nextInt(9999);//生成随机数,最大为9999
if(code < 1000){
code = code + 1000;//保证随机数为4位数字
}
}else if(length == 6){
code = new Random().nextInt(999999);//生成随机数,最大为999999
if(code < 100000){
code = code + 100000;//保证随机数为6位数字
}
}else{
throw new RuntimeException("只能生成4位或6位数字验证码");
}
return code;
}
/**
* 随机生成指定长度字符串验证码
* @param length 长度
* @return
*/
public static String generateValidateCode4String(int length){
Random rdm = new Random();
String hash1 = Integer.toHexString(rdm.nextInt());
String capstr = hash1.substring(0, length);
return capstr;
}
}
User
该类为用户类,存储用户信息。
实现其Mapper接口,UserService,UserServiceImpl
UserController
输入http://localhost:8080/front/page/login.html即可进入用户界面登录,验证码发送。但是需要先修改过滤器中的未登录即可访问数组:
String[] urls = new String[]{
"/employee/login",
"/employee/logout",
"/backend/**",
"/front/**",
"/common/**",
"/user/sendMsg",
"/user/login"
};
package com.ldh.reggie.controller;
@RestController
@RequestMapping("/user")
@Slf4j
public class UserController {
@Autowired
private UserService userService;
@PostMapping("/sendMsg")
public R<String> sendMsg(@RequestBody User user, HttpSession session){
//获取手机号
String phone = user.getPhone();
if(StringUtils.isNotEmpty(phone)){
//生成随机的4为验证码
String code = ValidateCodeUtils.generateValidateCode(4).toString();
log.info("code={}",code);
//调用阿里云提供的短信服务API来完成发送短信
//个人用户只能使用这个模板,第一个参数为签名,第二个为模板,两个要匹配
SMSUtils.sendMessage("阿里云短信测试","SMS_154950909",phone,code);
session.setAttribute(phone,code);
return R.success("手机验证码短信发送成功");
}
return R.error("短信发送失败");
}
@PostMapping("/login")
public R<User> login(@RequestBody Map map, HttpSession session){
//获取手机号
String phone = map.get("phone").toString();
//获取验证码
String code = map.get("code").toString();
//从Session获取保存的验证码
Object codeInSession = session.getAttribute(phone);
//进行验证码比对
if (codeInSession != null && codeInSession.equals(code)) {
//如果对比成功就说明登录成功
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(User::getPhone,phone);
User user = userService.getOne(queryWrapper);
if(user==null){
//为空证明当前用户尚未注册,此时自动进行注册
user = new User();
user.setPhone(phone);
user.setStatus(1); //状态为1表示未被禁用
userService.save(user);
}
session.setAttribute("user",user.getId());
return R.success(user);
}
return R.error("登录失败");
}
}
15. 移动端用户地址
地址簿,指的是移动端消费者用户的地址信息,用户登录成功后可以维护自己的地址信息。同一个用户可以有多个地址信息,但是只能有一个默认地址。
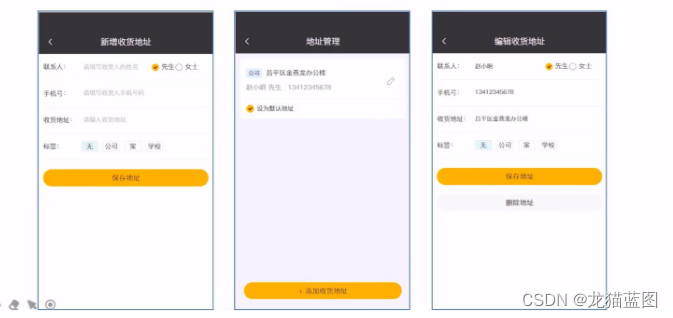
用户地址部分实现了用户对地址的操作,由于只有一个地址为默认地址,所以若设为默认地址则先将所有地址的地址状态设为0,即都不是默认地址而后在对某个地址进行默认地址设置。
16. 移动端菜品展示
代码开发-梳理交互过程
在开发代码之前,需要梳理一下前端页面和服务端的交互过程:
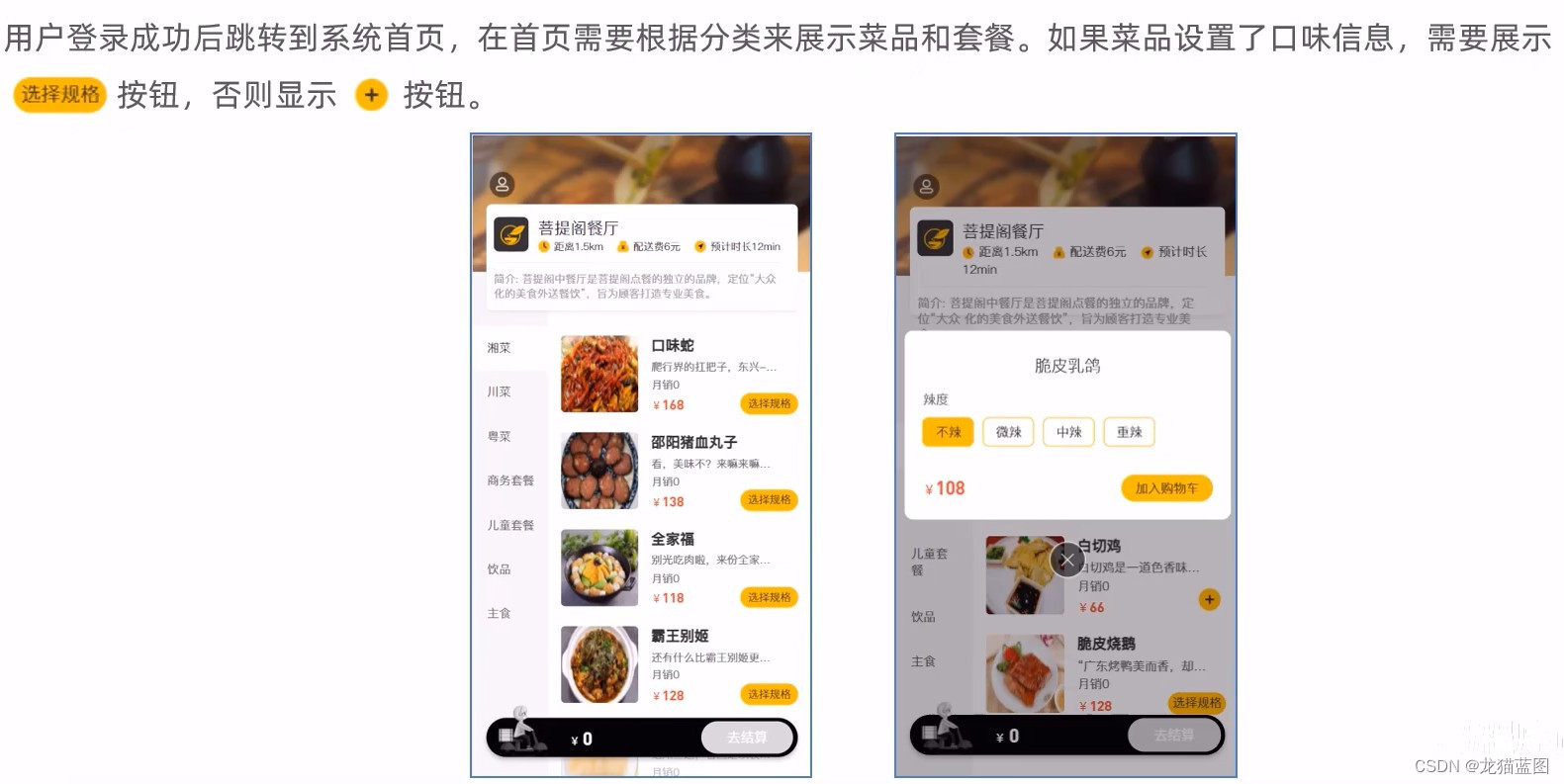
- 页面(front/index.html)发送ajax请求,获取分类数据(菜品分类和套餐分类)
- 页面发送ajax请求,获取第一个分类下的菜品或者套餐
开发菜品展示功能,其实就是在服务端编写代码去处理前端页面发送的这2次请求即可。
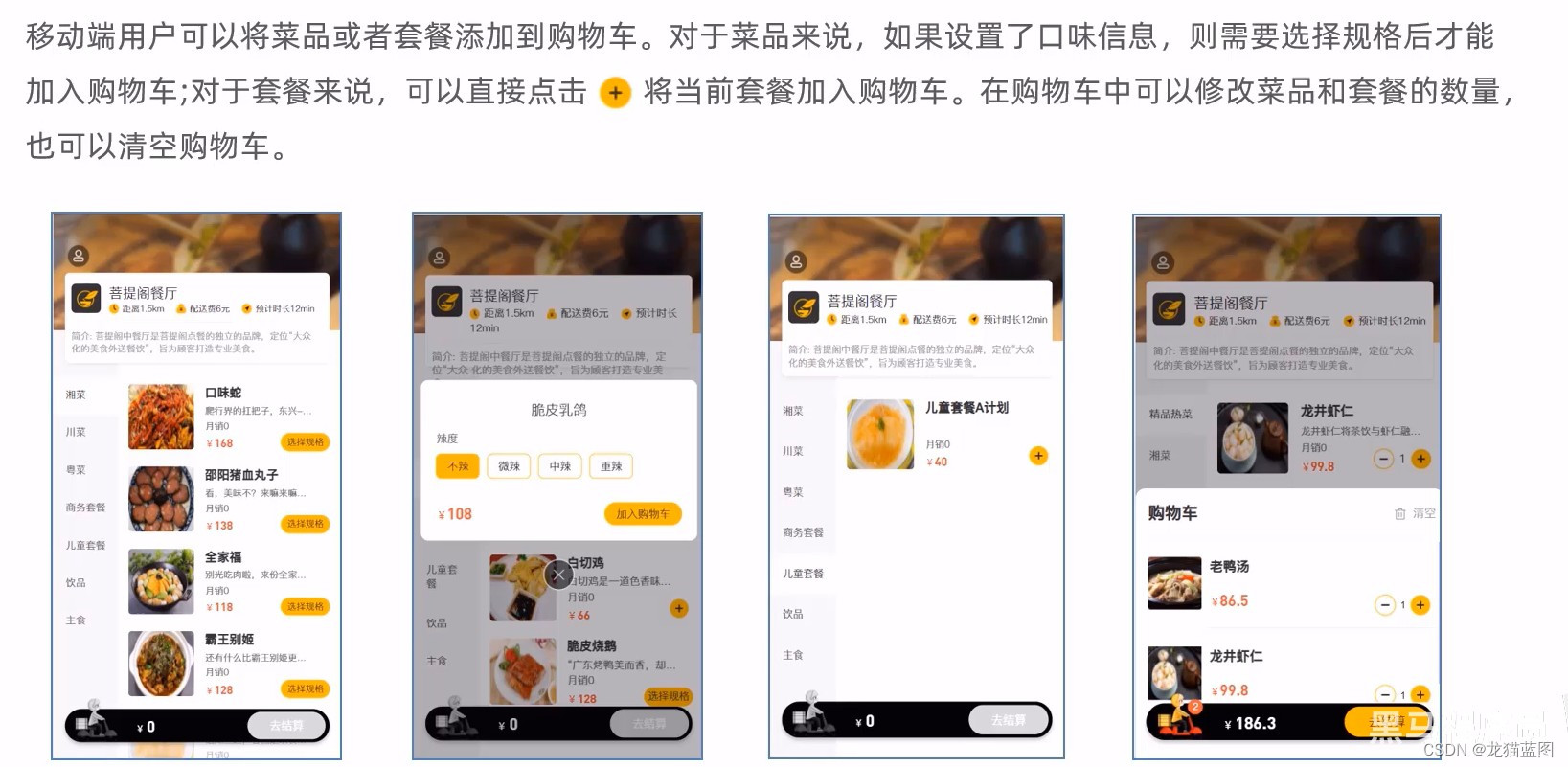
17. 移动端购物车

18. 订单提交
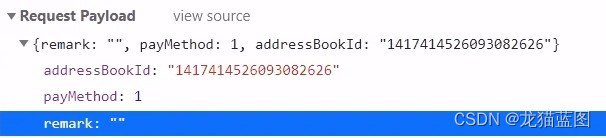
前端提交过来的数据只有这三个,因为订单的数据可以用用户id进行查询,而传递地址值过来是因为一个用户可以有多个地址,地址需要指定唯一一个。
用户下单业务对应的数据表为orders表和order_detail表,就是将每一个订单对应一个orders,而订单中的数据则封装到order_detail表中,订单表和订单明细表中的数据要通过查询其他表中的数据进行封装。
19. 使用git管理
如果你是刚接触SpringBoot或者是Github,这一部分了解即可,因为国内访问GitHub速度较慢,体验感并不好,当然你可以采用其他方式提示访问速度,现在GitHub速度比之前好像是快了,也可以采用安装加速插件的方式,学生阶段的项目基本都是自己维护开发,对版本管理的需求并不高,使用GitHub的频率也较低,当然git是非常重要的,越熟悉越好,后续我会发布讲解IDEA如何配置GitHub仓库的教程,这里是默认你已经配置好git环境,将项目交由git进行管理。
创建远程仓库
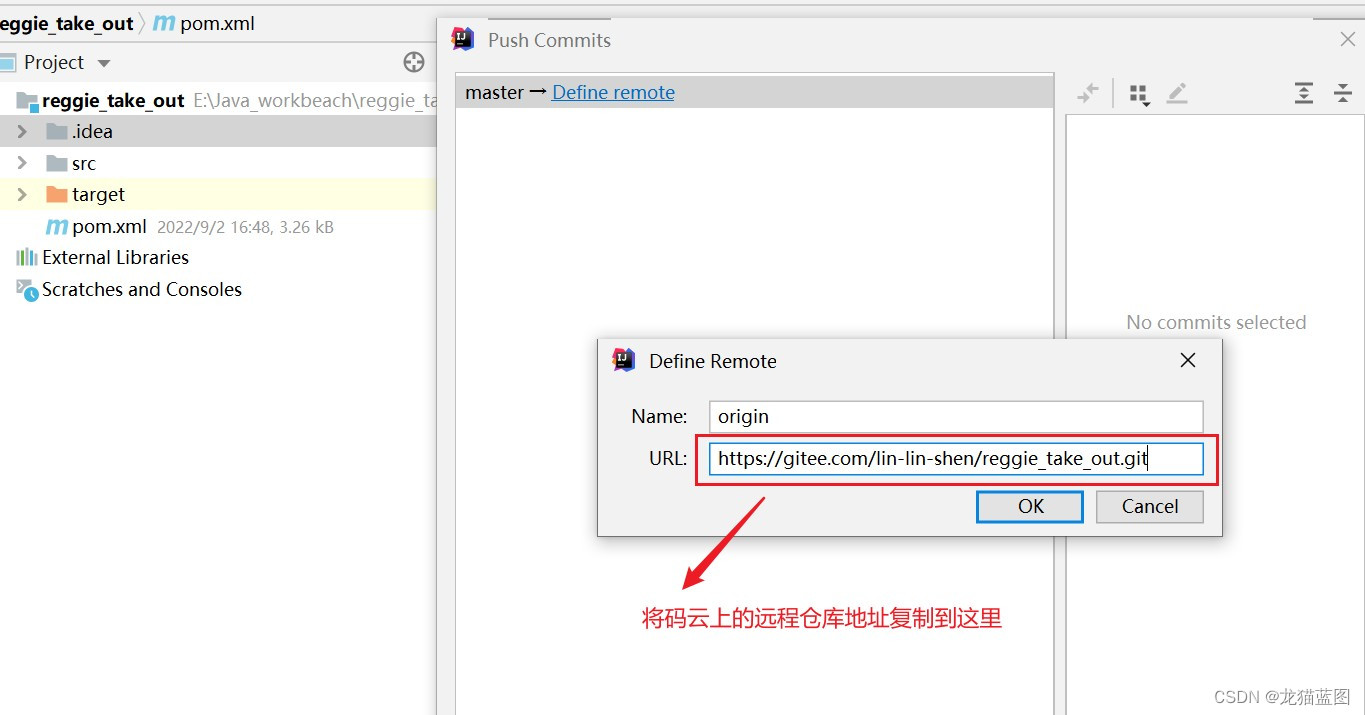
使用码云或者GitHub创建远程仓库,将远程仓库的地址复制下来。
创建本地仓库
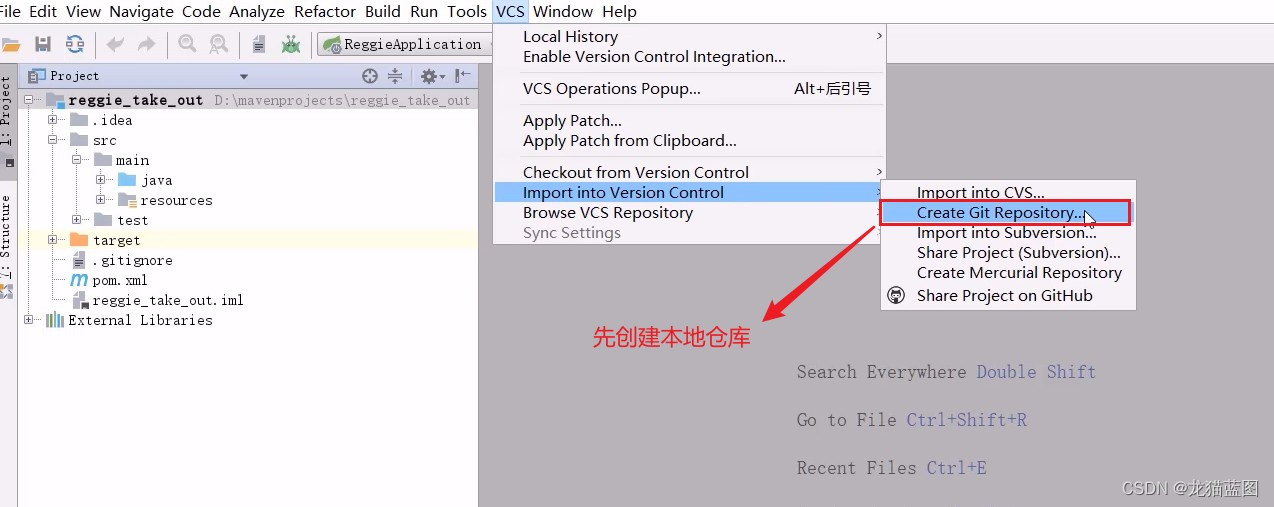
将代码添加到暂存区后提交
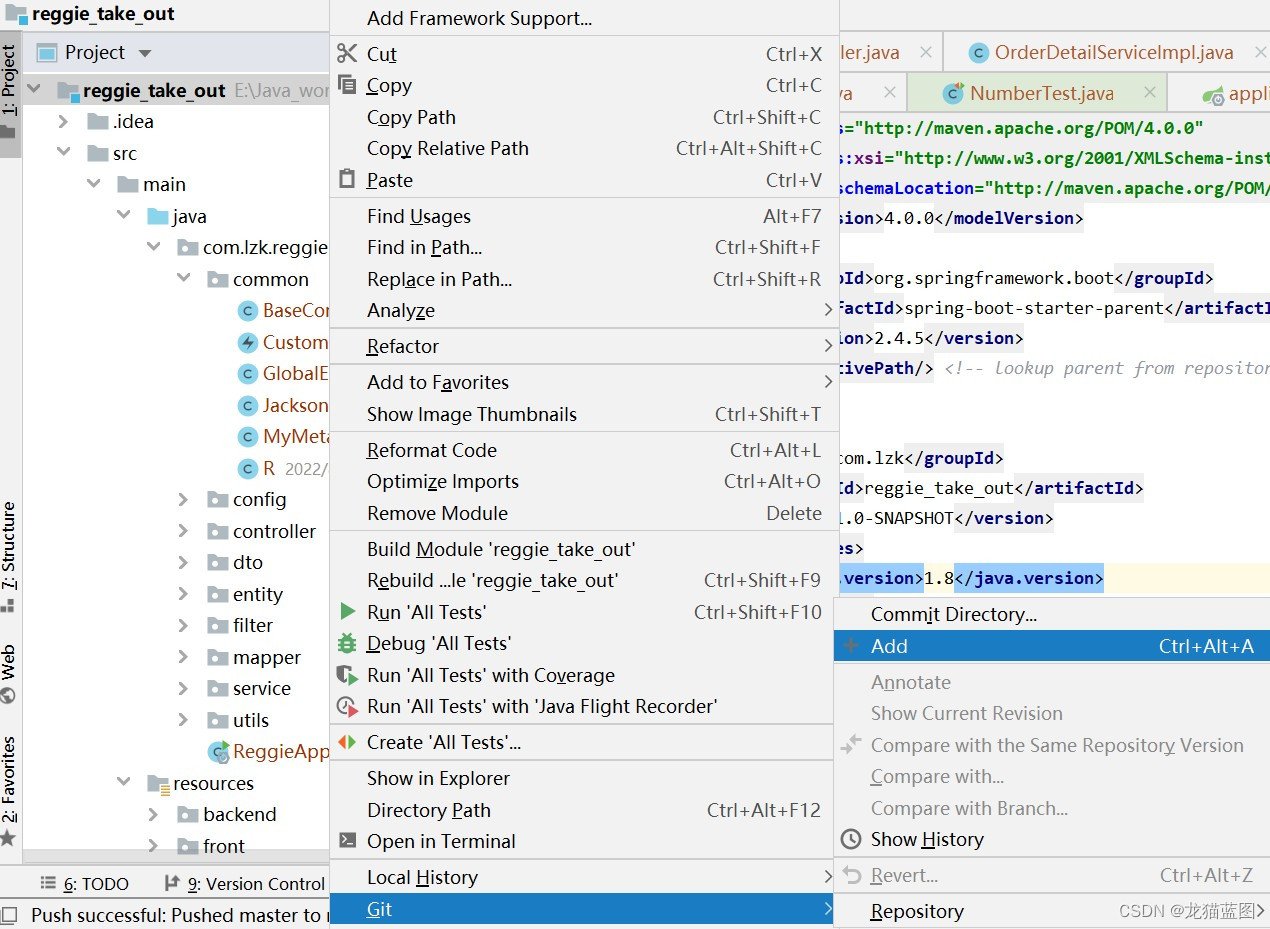
- 先选中整个项目然后选择git-add,添加到暂存区
- 然后继续选中整个项目git-commit,添加到本地仓库
以上操作均为与远程库进行连接,下面这个操作就是使本地仓库与远程仓库建立连接。
创建分支
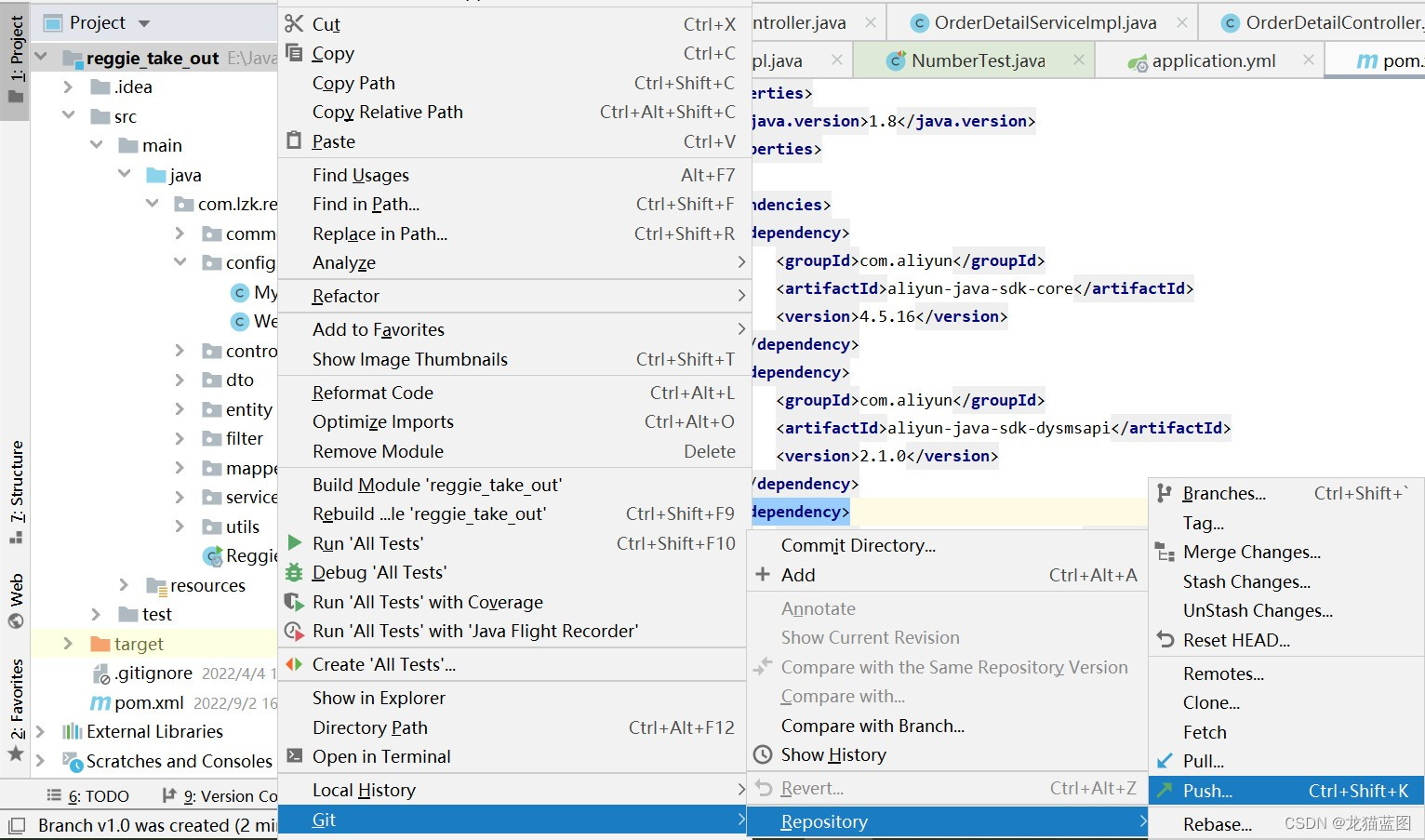
在idea右下角点击new branch后新建一个分支,然后根据下图提交分支到远程库
20. 使用Redis缓存技术
首先将对应的坐标导入:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
在配置文件中进行redis的相关配置:
spring:
application:
name: springdataredis_demo
#Redis相关配置
redis:
host: localhost
port: 6379
password: 123456
database: 0 #操作的是0号数据库
jedis:
#Redis连接池配置
pool:
max-active: 8 #最大连接数
max-wait: 1ms #连接池最大阻塞等待时间
max-idle: 4 #连接池中的最大空闲连接
min-idle: 0 #连接池中的最小空闲连接
RedisTemplate
Spring Data Redis中提供了一个高度封装的类:RedisTemplate,针对jedis客户端中大量api进行了归类封装,将同一类型操作封装为operation接口,具体分类如下:
- ValueOperations:简单K-V操作
- SetOperations:set类型数据操作
- ZSetOperations:Zset类型数据操作
- HashOperations:针对map类型的数据操作
- ListOperations:针对list类型的数据操作
注意:当我们使用缓存技术时,对应的类要实现Serializable接口,否则无法存储到Redis中。
Redis配置类:RedisConfig
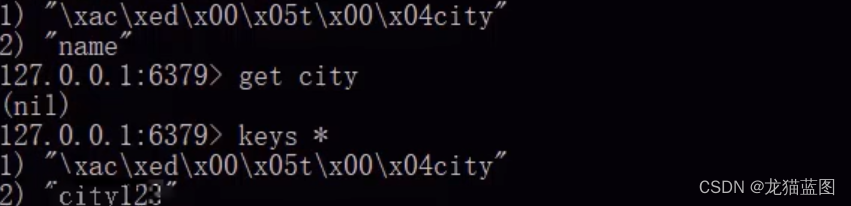
作用:如果我们通过RedisTemplate将数据保存到Redis中,默认使用的是key序列化器是JdkSerializationRedisSerializer,这样产生的问题就是我们在其他方式下(如Redis控制台命令)查询该key是通过序列化后的,结果跟我们通过RedisTemplate操作不一致,当然这只是影响其他方式查询,并不影响RedisTemplate方式查询,因为它自己在查询时会通过反序列化的方式将其还原成我们赋值时的字符串。value也是同理,但value一般不设置。
总结:不设置也没有关系,只是会影响我们在非RedisTemplate方式下key的查询结果。
例如通过RedisTemplate方式设置一个key为city,通过本地客户端方式连接后查询到的键为\xac\xed\x00\x05…
通过本地的方式我们就查不到该key
@Configuration
public class RedisConfig extends CachingConfigurerSupport {
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
//默认的Key序列化器为:JdkSerializationRedisSerializer
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setConnectionFactory(connectionFactory);
return redisTemplate;
}
}
缓存验证码
使用Redis进行缓存,我们将原先的UserController进行改造
前面我们已经实现了移动端手机验证码登录,随机生成的验证码我们是保存在HttpSession中的。
现在需要改造为将验证码缓存在Redis中,具体的实现思路如下:
1、在服务端UserController中注入RedisTemplate对象,用于操作Redis
2、在服务端UserController的sendMsg方法中,将随机生成的验证码缓存到Redis中,并设置有效期为5分钟
3、在服务端JserController的login方法中,从Redis中获取缓存的验证码,如果登录成功则删除Redis中的验证码
将验证码存储到Redis中可以更好地管理验证码的失效时间,而且也避免了项目集群部署时,验证码未失效但验证失败的问题。因为session存储验证码,作用域只在当前项目中,生成验证码是在服务器A生成的,验证码验证却是在服务器B进行的,这时候验证就会失败。但采用Redis就不会存在这个问题,因为Redis的作用域是全局的。
UserController
@RestController
@RequestMapping("/user")
@Slf4j
public class UserController {
@Autowired
private UserService userService;
@Autowired
private RedisTemplate redisTemplate;
@PostMapping("/sendMsg")
public R<String> sendMsg(@RequestBody User user, HttpSession session){
//获取手机号
String phone = user.getPhone();
if(StringUtils.isNotEmpty(phone)){
//生成随机的4为验证码,如果没有开通阿里云的短信服务可以使用这个
String code = ValidateCodeUtils.generateValidateCode(4).toString();
log.info("code={}",code);
//调用阿里云提供的短信服务API来完成发送短信
SMSUtils.sendMessage("阿里云短信测试","SMS_154950909",phone,code);
//将验证码加入到缓存中,时间设置为5分钟
redisTemplate.opsForValue().set(phone,code,5, TimeUnit.MINUTES);
// session.setAttribute(phone,code);
return R.success("手机验证码短信发送成功");
}
return R.error("短信发送失败");
}
@PostMapping("/login")
public R<User> login(@RequestBody Map map, HttpSession session){
//获取手机号
String phone = map.get("phone").toString();
//获取验证码
String code = map.get("code").toString();
//2.从缓存中获取验证码进行匹配
Object codeInSession = redisTemplate.opsForValue().get(phone);
//从Session获取保存的验证码
//Object codeInSession = session.getAttribute(phone);
//进行验证码比对
if (codeInSession != null && codeInSession.equals(code)) {
//如果对比成功就说明登录成功
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(User::getPhone,phone);
User user = userService.getOne(queryWrapper);
if(user==null){
//为空证明当前用户尚未注册,此时自动进行注册
user = new User();
user.setPhone(phone);
user.setStatus(1); //状态为1表示未被禁用
userService.save(user);
}
session.setAttribute("user",user.getId());
//登录成功则删除该验证码
redisTemplate.delete(phone);
return R.success(user);
}
return R.error("登录失败");
}
}
菜品缓存
前面我们已经实现了移动端菜品查看功能,对应的服务端方法为DishController的list方法,此方法会根据前端提交的查询条件进行数据库查询操作。在高并发的情况下,频繁查询数据库会导致系统性能下降,服务端响应时间增长。现在需要对此方法进行缓存优化,提高系统的性能,将查询后的菜品信息保存到Redis中,由于Redis是基于内存读写的,性能方面要极大地优于MySQL,这样就能减少菜品查询时频繁查询MySQL数据库带来地性能损耗。
具体的实现思路如下:
1、改造DishController的list方法,先从Redis中获取菜品数据,如果有则直接返回,无需查询数据库;如果没有则查询数据库,并将查询到的菜品数据放入Redis。
2、改造DishController的save和update方法,因为更新数据后,之前查询出的保存到Redis中的商品数据就是旧的,即过期数据,需要在增加和更新方法中加入清理缓存的逻辑。
@RestController
@RequestMapping("/dish")
public class DishController {
@Autowired
private DishService dishService;
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private DishFlavorService dishFlavorService;
@Autowired
private CategoryService categoryService;
@GetMapping("/list")
public R<List<DishDto>> list(Dish dish){
String key = "dish_"+dish.getCategoryId()+"_"+dish.getStatus();
List<DishDto> dishDtoList = null;
dishDtoList = (List<DishDto>) redisTemplate.opsForValue().get(key);
if(dishDtoList!=null){
return R.success(dishDtoList);
}
LambdaQueryWrapper<Dish> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(dish.getCategoryId()!=null,Dish::getCategoryId,dish.getCategoryId())
.eq(Dish::getStatus,1);
queryWrapper.orderByAsc(Dish::getSort).orderByDesc(Dish::getUpdateTime);
List<Dish> list = dishService.list(queryWrapper);
dishDtoList = list.stream().map((item)->{
DishDto dishDto = new DishDto();
BeanUtils.copyProperties(item,dishDto);
Long categoryId = item.getCategoryId();
Category category = categoryService.getById(categoryId);
if(categoryId!=null){
String categoryName =category.getName();
dishDto.setCategoryName(categoryName);
}
Long dishId = item.getId();
return dishDto;
}).collect(Collectors.toList());
redisTemplate.opsForValue().set(key,dishDtoList,60, TimeUnit.MINUTES);
return R.success(dishDtoList);
}
}
修改时清理缓存
所有菜品缓存都清理
在DishController中的update方法中进行修改:
@PutMapping
public R<String> update(@RequestBody DishDto dishDto){
dishService.updateWithFlavor(dishDto);
//清理所有彩屏的缓存数据,菜品的键前缀都是dish_
Set keys = redisTemplate.keys("dish_*");
redisTemplate.delete(keys);
return R.success("新增菜品成功");
}
清理修改菜品所对应的分类
@PutMapping
public R<String> update(@RequestBody DishDto dishDto){
dishService.updateWithFlavor(dishDto);
String key = "dish_" + dishDto.getCategoryId() + "_1";
redisTemplate.delete(key);
return R.success("新增菜品成功");
}
21. Spring Cache缓存技术讲解
作用同Redis缓存,使用Spring Cache只需要通过注解的方式控制缓存数据使得开发更加便捷。
如果导入redis等第三方缓存技术,默认使用的就是spring context下自带的缓存技术,将数据存储到Map中去。
Spring Cache是一个框架,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能。
Spring Cache提供了一层抽象,底层可以切换不同的cache实现。具体就是通过CacheManager接口来统一不同的缓存技术。
CacheManager是Spring提供的各种缓存技术抽象接口。针对不同的缓存技术需要实现不同的CacheManager:
| CacheManager | 描述 |
|---|---|
| EhCacheCacheManager | 使用EhCache作为缓存技术 |
| GuavaCacheManager | 使用Google的GuavaCache作为缓存技术 |
| RedisCacheManager | 使用Redis作为缓存技术 |
注解说明:
| 注解 | 说明 |
|---|---|
| @EnableCaching | 开启缓存注解功能 |
| @Cacheable | 在方法执行前spring先查看缓存中是否有数据,如果有数据,则直接返回缓存数据;若没有数据,调用方法并将方法返回值放到缓存中 |
| @CachePut | 将方法的返回值放到缓存中 |
| @CacheEvict | 将一条或多条数据从缓存中删除 |
在springboot项目中,使用缓存技术只需在项目中导入相关缓存技术的依赖包,并在启动类上使用@EnableCaching开启缓存支持即可。
例如,使用Redis作为缓存技术,只需要导入Spring data Redis的maven坐标即可。
CachePut说明
作用:将方法的返回值放入缓存中。
CachePut注解的两个参数:
- value:表示一类注解,一类注解下可以使用多个键进行区分,例如这里的value是用户缓存,而具体每个用户的缓存对应key的不同。
- key:表示每个大类下的每个小类,一般通过动态方式赋值才可以使其不同,我们通过spring的表达式,将user的id作为key,写作:
key="#user.id"。也可以将返回结果作为key,写作:key="#result.id"。将第一个参数的id作为key:p0.id,root.args[0].id.
@CachePut(value = "userCache", key = "result.id")
@CachePut(value = "userCache", key = "user.id")
@CachePut(value = "userCache", key = "p0.id")
@CachePut(value = "userCache", key = "root.args[0].id")
@PostMapping
public User save(User user){
userService.save(user);
return user;
}
CacheEvict注解
根据id删除userCache中的缓存数据,由于原先的userCache就是将id作为key进行缓存的,所以我们就可以在删除的时候使用id进行删除。【修改或删除后数据不一致,需要将缓存中的数据进行删除,】
@CacheEvict(value = "userCache", key = "result.id")
@CacheEvict(value = "userCache", key = "user.id")
@CacheEvict(value = "userCache", key = "p0.id")
@CacheEvict(value = "userCache", key = "root.args[0].id")
@PutMapping
public User update(User user){
userService.updateById(user);
return user;
}
Cacheable注解
说明:在方法执行前spring先查看缓存中是否有数据,如果有数据则直接返回缓存数据,如果没有数据,调用该方法并将返回值放入缓存中。
- unless:不满足条件就缓存
- condition:满足条件才缓存,该表达式中没有result,不能使用condition=“#result==null”
@Cacheable(value = "userCache", key = "#id",unless = "#result==null")
@Cacheable(value = "userCache", key = "#id",condition = "#id > 0")
@GetMapping("/{id}")
public User update(@PathVariable Long id){
User user = userService.getById(id);
return user;
}
使用unless意思为user不为空就将其缓存到UserCache缓存中去,使用condition意思是传入id大于0时才执行缓存。
结合redis使用spring cache
在Spring Boot项目中使用Spring Cache的操作步骤(使用redis缓存技术):
- 导入maven坐标
spring-boot-starter-data-redis、spring-boot-starter-cache
- 配置application.yml
spring:
cache:
redis:
time-to-1ive: 1800000 #设置缓存有效期
为什么要设置缓存有效期?不是说缓存可以提高访问的效率,有效期过后,缓存中的数据就失效了,此时就需要再次访问MySQL数据库去重新建立缓存,降低了查询性能。其实我们之前已经介绍过了Redis之所以比MySQL有着更好的读写性能,是因为它是基于内存读写的,而MySQL是基于磁盘读写的,现在磁盘的空间小的都有几十个G,而内存大的就几个G,非常有限,如果不经常清理,很容易导致内存空间不足,服务器宕机,并且缓存中的数据并不需要长期存在,一般都是缓存高频访问的数据即可,如果是低频访问的数据其实数据库就完全可以承受这些访问量。我们上面使用Redis缓存菜品数据就是基于他是项目中高频访问的数据。
- 在启动类上加入@EnableCaching注解,开启缓存注解功能
A、在Controller的方法上加入@Cacheable、@CacheEvict等注解,进行缓存操作
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
spring:
application:
name: reggie_take_out
redis:
host: 127.0.0.1
port: 6379
password: 123456
database: 0
cache:
redis:
time-to-live: 1800000
22. 使用Spring Cache缓存套餐
前面我们已经实现了移动端套餐查看功能,对应的服务端方法为SetmealController的list方法,此方法会根据前端提交的查询条件进行数据库查询操作。在高并发的情况下,频繁查询数据库会导致系统性能下降,服务端响应时间增长。
现在需要对此方法进行缓存优化,提高系统的性能。
具体的实现思路如下:
1、导入Spring Cache和Redis相关maven坐标
2、在application.yml中配置缓存数据的过期时间
3、在启动类上加入@EnableCaching注解,开启缓存注解功能
4、在SetmealController的list方法上加入@Cacheable注解
5、在SetmealController的save和delete方法上加入CacheEvict注解
步骤1,2我们可在上面获取操作流程。
注意使用Spring Cache时返回值需要实现序列化接口。
@Data
public class R<T> implements Serializable {
}
@RestController
@RequestMapping("/setmeal")
@Slf4j
public class SetmealController {
@Autowired
private SetmealDishService setmealDishService;
@Autowired
private CategoryService categoryService;
@Autowired
private SetmealService setmealService;
@PostMapping
//allEntries = true表示将所有setmealCache下的缓存都清除
@CacheEvict(value = "setmealCache",allEntries = true)
public R<String> save(@RequestBody SetmealDto setmealDto){
setmealService.saveWithDish(setmealDto);
log.info("新增的值为:{}",setmealDto);
return R.success("新增套餐成功");
}
@GetMapping("/page")
public R<Page> page(int page,int pageSize,String name){
Page<Setmeal> pageInfo = new Page<>(page,pageSize);
Page<SetmealDto> dtoPage = new Page<>();
LambdaQueryWrapper<Setmeal> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.like(name!=null,Setmeal::getName,name)
.orderByDesc(Setmeal::getUpdateTime);
setmealService.page(pageInfo,queryWrapper);
BeanUtils.copyProperties(pageInfo,dtoPage,"records");
List<Setmeal> records = pageInfo.getRecords();
List<SetmealDto> list = records.stream().map((item)->{
SetmealDto setmealDto = new SetmealDto();
BeanUtils.copyProperties(item,setmealDto);
Long categoryId = item.getCategoryId();
Category category = categoryService.getById(categoryId);
if(category != null) {
String categoryName = category.getName();
setmealDto.setCategoryName(categoryName);
}
return setmealDto;
}).collect(Collectors.toList());
dtoPage.setRecords(list);
return R.success(dtoPage);
}
@DeleteMapping
@CacheEvict(value = "setmealCache",allEntries = true)
public R<String> delete(@RequestParam List<Long> ids){
setmealService.removeWithDish(ids);
return R.success("删除套餐成功");
}
@GetMapping("/list")
@Cacheable(value = "setmealCache",key = "#setmeal.categoryId+'_'+#setmeal.status")
public R<List<Setmeal>> list(Setmeal setmeal){
LambdaQueryWrapper<Setmeal> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(setmeal.getCategoryId()!=null,Setmeal::getCategoryId,setmeal.getCategoryId());
queryWrapper.eq(setmeal.getStatus()!=null,Setmeal::getStatus,setmeal.getStatus());
List<Setmeal> list = setmealService.list(queryWrapper);
return R.success(list);
}
}
23. 实现数据库主从分离
了解即可,对项目功能没有影响。
如果只使用一台数据库,读和写操作都由一台数据库承担,压力大,如果数据库服务器磁盘损坏则数据丢失,单点故障。
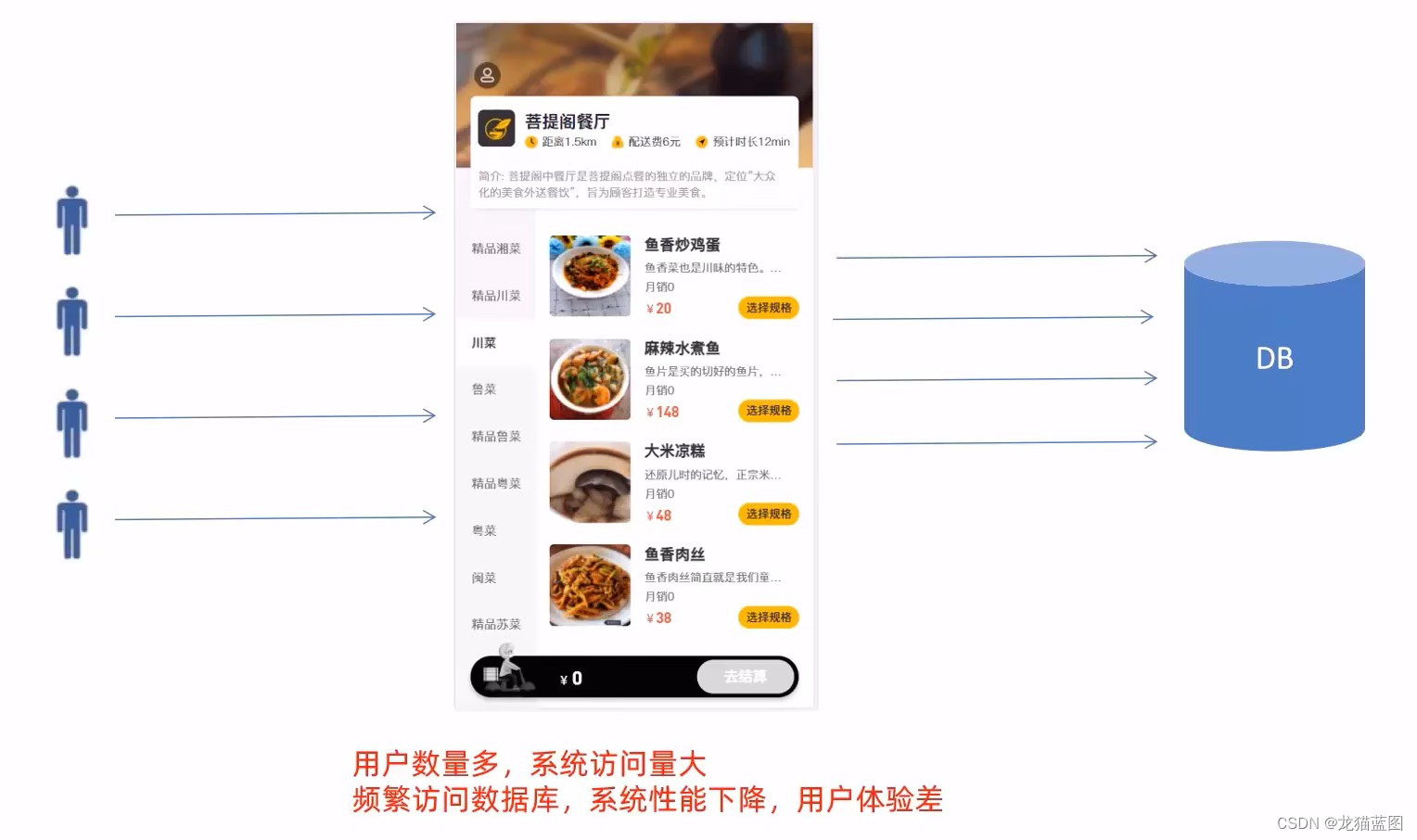
基于上面这种情况,我们实现了主从分离。
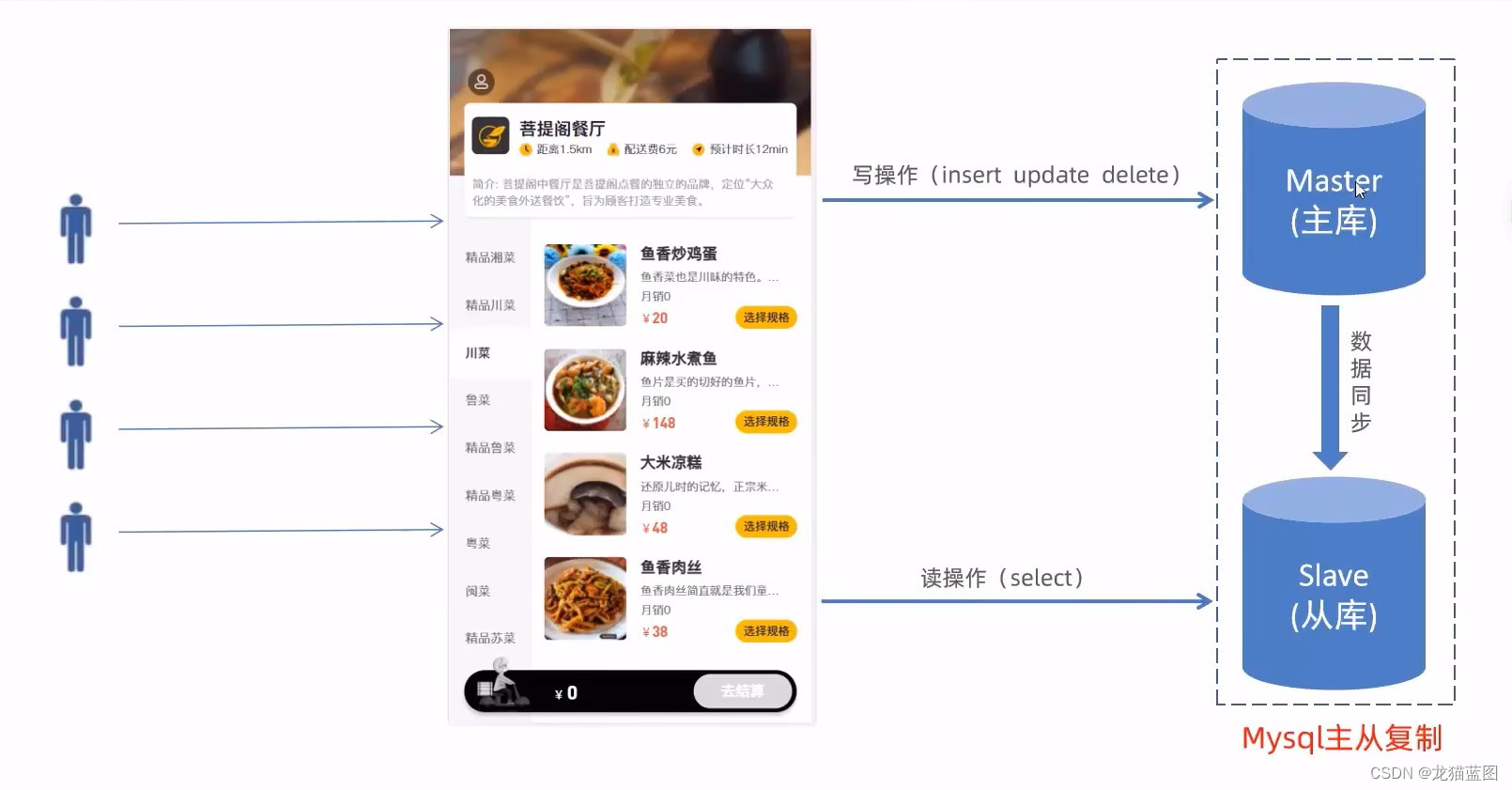
主从复制介绍
MySQL主从复制是一个异步的复制过程,底层是基于Mysql数据库自带的二进制日志功能。就是一台或多台MySOL数据库(slave,即从库)从另一台MySQL数据库(master,即主库)进行日志的复制然后再解析日志并应用到自身,最终实现从库的数据和主库的数据保持一致。MySQL主从复制是MySQL数据库自带功能,无需借助第三方工具。
MySQL复制过程分成三步:
- master将改变记录到二进制日志(binary log)
- slave将master的binary log拷贝到它的中继日志(relay log)
- slave重做中继日志中的事件,将改变应用到自己的数据库中
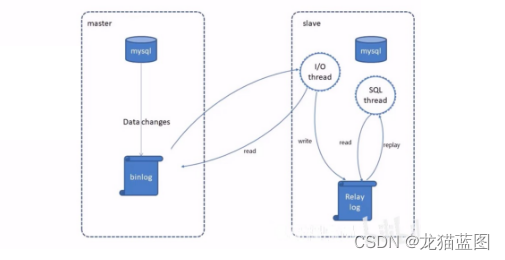
主从复制实现
提前准备好两台服务器,分别安装Mysql并启动服务成功
- 主库Master:192.168.138.100
- 从库Slave:192.168.138.101
配置主库
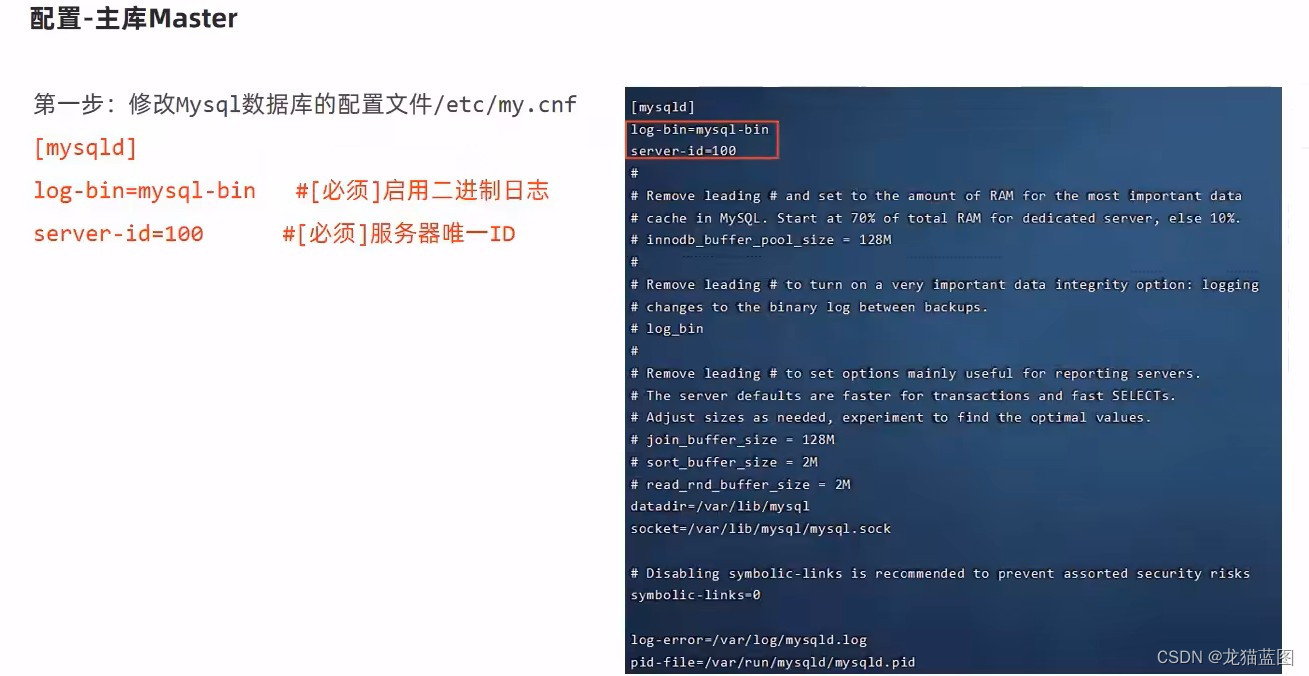
第二步:重启Mysql服务
systemctl restart mysql
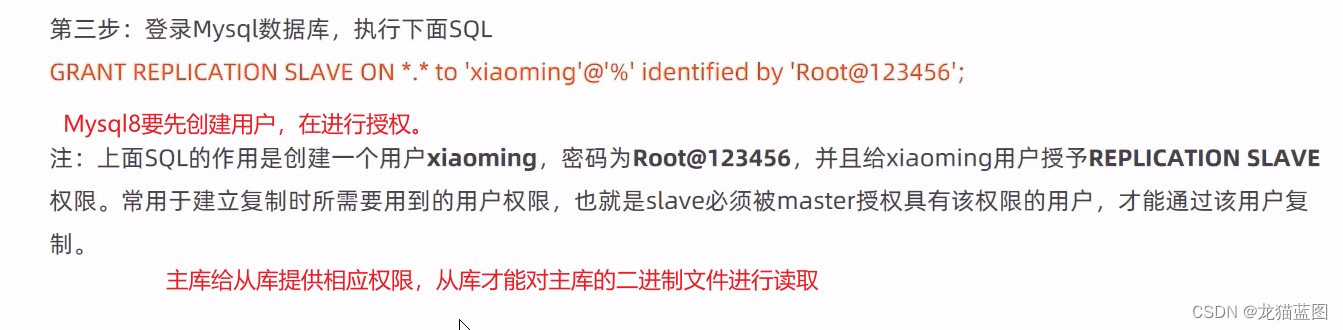

配置从库
第二步:重启Mysql服务

systemctl restart mysql
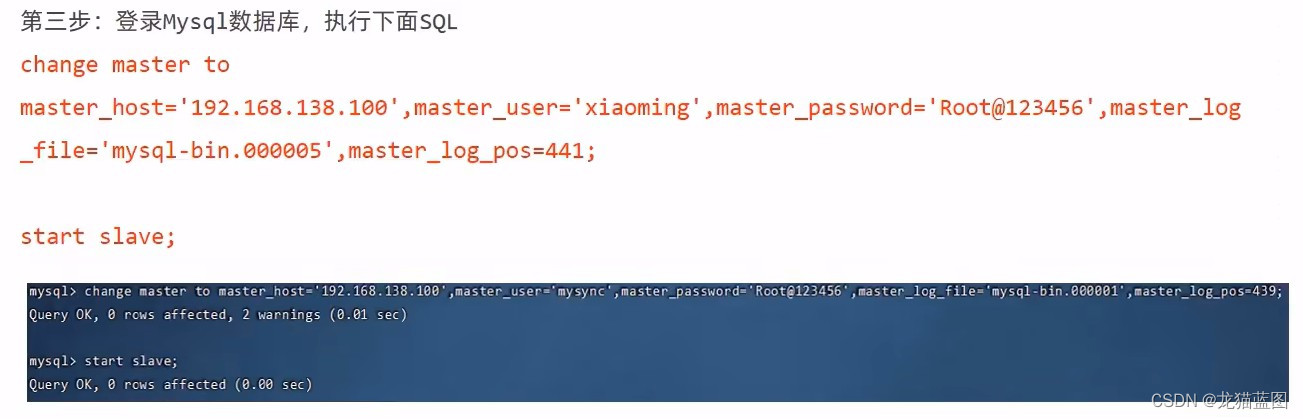
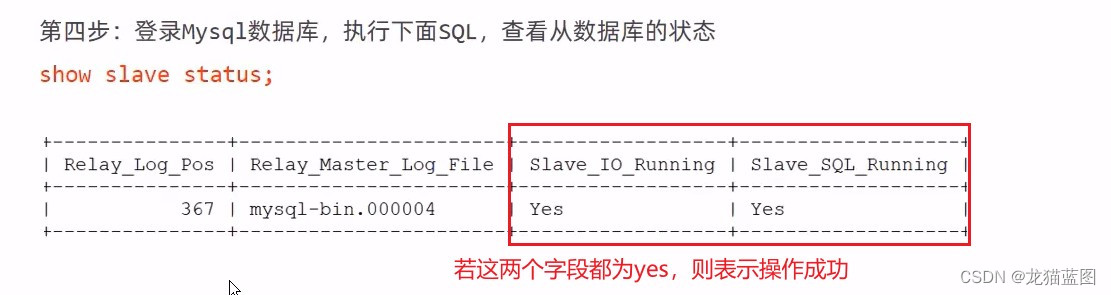
我们可以在Navicate上进行效果查看,当我们在主库创建表时,刷新从库就能看到新创建出来的表。
使用Sharding-JDBC实现操作时主从分离
我们上面只是实现了数据库层的主从复制,但是当我们进行增删改操作时要能对应主库,查询时要对应从库,就需要使用sharding-JDBC了。
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
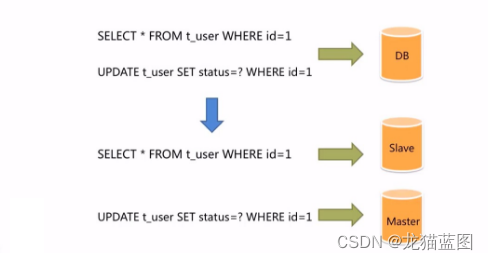
Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
使用Sharding-JDBC可以在程序中轻松实现数据库读写分离。
- 适用于任何基于JDBC的ORM框架,如:JPA,Hibernate,Mybatis,Spring JDBC Template或直接使用JDBC
- 支持任何第三方的数据库连接池,如:DBCP,C3P0,BoneCP,Druid,HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
Sharding-JDBC实现读写分离操作步骤
- 导入maven坐标
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
2.在配置文件中配置读写分离规则
server:
port: 8080
spring:
shardingsphere:
datasource:
names:
master,slave
#主数据源
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.138.100:3306/reggie?characterEncoding=utf-8
username: root
password: root
#从数据源
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.138.100:3306/reggie?characterEncoding=utf-8
username: root
password: root
#读写分离配置
masterslave:
#使用round_robin:表示读取操作是采用轮转的方式读取,第一次请求读第一个,以此类推
load-balance-algorithm-type: round_robin
#最终的数据源名称
name: dataSource
#主库数据源名称
master-data-source-name: master
#从库数据源名称列表,多个逗号分割
slave-data-source-name: slave
props:
sql:
show: true #开启SQL显示,默认false
main:
allow-bean-definition-overriding: true #数据源覆盖,若不覆盖,springBoot中自带的数据源也会开启,不覆盖情况下同时开启两个数据源将会报错。
24. 项目部署
一个项目分为前端部分和后端部分,我们将前端部分部署到Nginx服务器上,而后端部分选择部署到tomcat服务器上。以下为两台服务器,而我只有一台,所以使用一台服务器完成相同的功能。具体怎么实现下面进行讲解:
这里是有多台服务器,服务器安装对应的软件,不同服务器提供功能不同,对应需安装的软件也不相同。
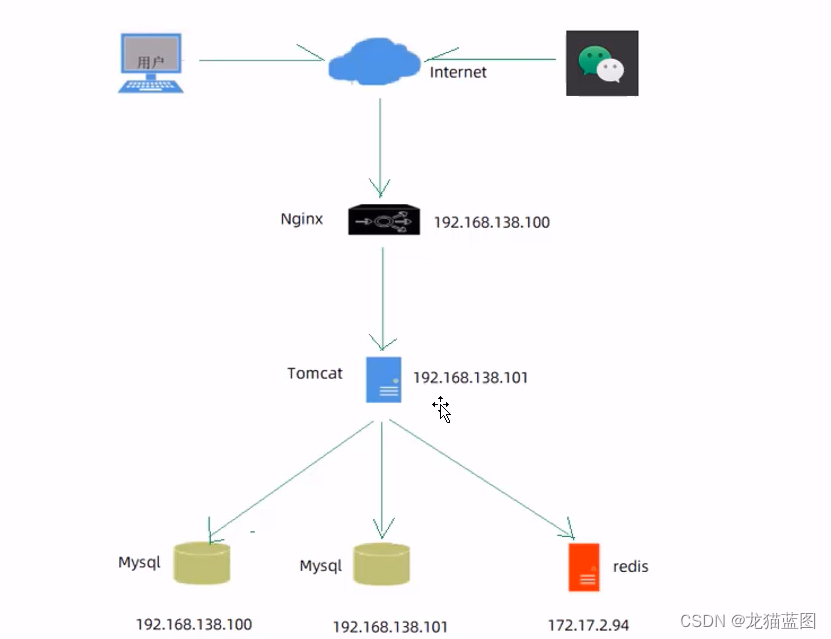
- 服务器A用于部署静态资源,即我们的前端代码,需要Nginx,由于设置了主从分离,服务器数量较少,所以安装了Mysql数据库,用于从库服务。
用户在页面上进行请求的发送,由部署到前端的静态资源进行请求的发送,而具体的请求路径可由Nginx进行配置。下面进行讲解。
- 服务器B用于部署后端代码,需要Java的运行环境JDK,数据存储所需的Mysql,maven用于管理项目jar包依赖。git主要用于从远程库拉取代码,也可以使用手动打包的方式就不需要git了。
- 服务器C主要用于数据缓存的存储。
由于我只有一台,所以使用一台服务器替代三台。

操作流程
注意:这里的dist文件夹是经过webpack将前端资源打包后的生成的,就相当于Java代码在maven中执行package命令一样,但是也可以直接将前端资源部署到Nginx中,只是效率会变慢而已而且占空间,但Java代码不执行构建打包操作就无法部署,这是二者的区别。
配置:反向代理,修改Nginx配置文件nginx.conf
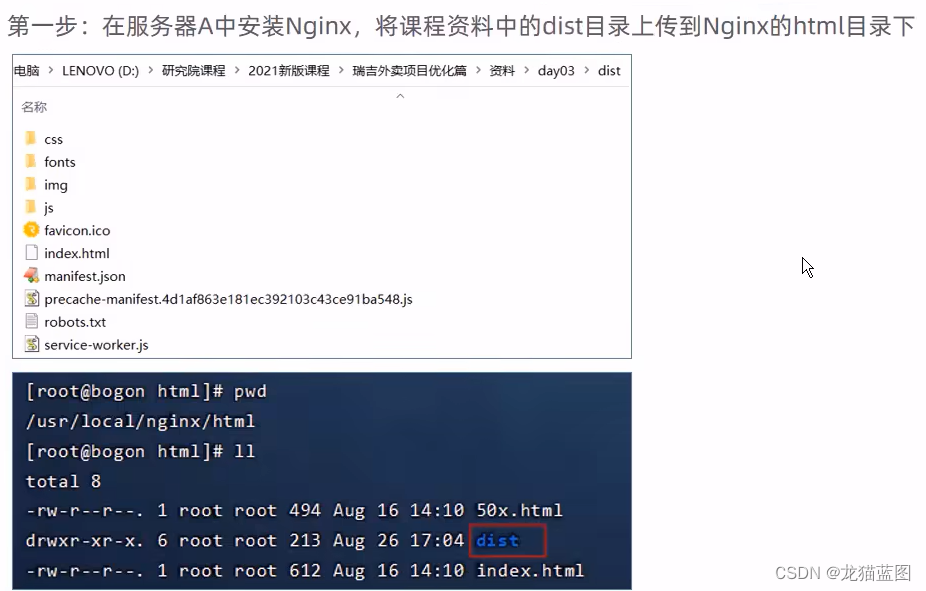
server {
listen 80;
server_name localhost;
location / {
rooot html/dist;
index index.html;
}
#反向代理配置
location ^~ /api/ {
rewrite ^/api/(.*)$ /$1 break;
proxy_pass http://192.168.138.101:8080
}
}
修改nginx.conf下的location的root属性为:html/dist;表示访问http://127.0.0.1:80时默认访问我们的项目。
配置反向代理:
-
进行反向处理,说明请求需要到其他服务器,所以需要向请求指明路径,即另一个服务器所在位置。
-
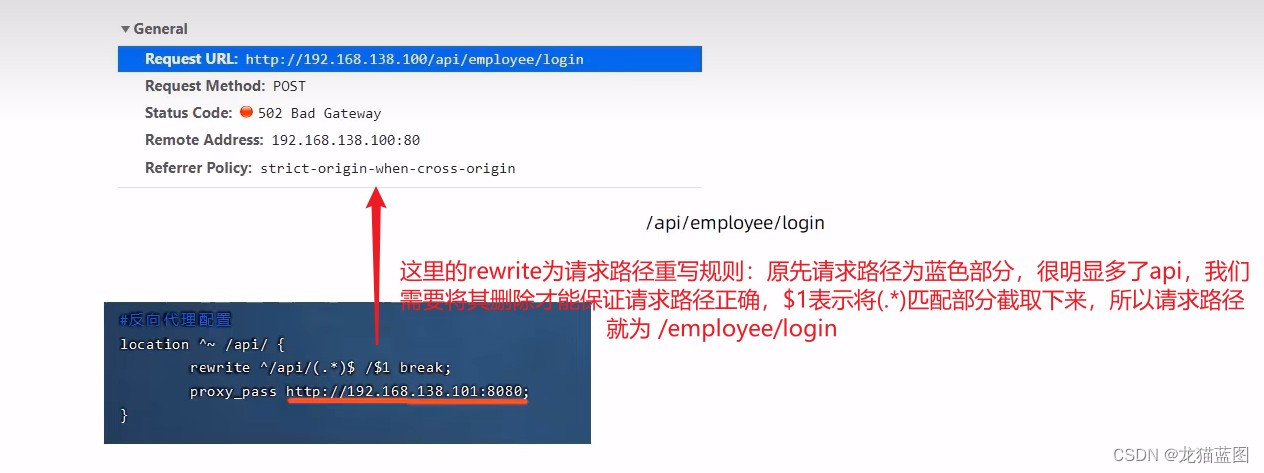
由于将项目部署到Nginx后,前端发起请求自动添加了/api,与我们后端的请求路径不匹配,所以需要进行截取处理,获取api后面的路径进行代理。
location ^~ /api/{
rewrite ^/api/(.*)$ /$1 break;
proxy_pass http://192.168.138.101:8080;
}
后端部分使用自动部署方式,需要脚本以及git将项目从远程库中拉取下来。我觉得比较麻烦,直接使用了手动打包方式。后台方式启动,可以保证项目在关闭命令行窗口时仍处于启动状态。
第一步:由于我只有一台服务器,所以还是在服务器A中安装jdk、maven、MySQL、Redis服务。
第二步:通过maven手动打包Java项目将打包后的jar文件上传到Linux服务器上。通过后台方式启动即可,详细教程可以查看Linux如何部署SpringBoot项目
nohup java -jar 打包jar名.jar &> reggie.log
通过访问项目前台以及后台登录页面路径判断是否能成功登录。
25. 总结
到了这里项目中所有的重难点部分就已经讲解完毕了,相信各位同学也已经对SpringBoot项目的学习有了一个更好的掌握,也能发现相较于之前的JavaWeb、自己搭建SSM框架来说,SpringBoot进行网页项目开发有多便捷,结合Mybatis-Plus后,开发效率更高。学完了这个项目的同学,回顾一下刚学习JavaWeb技术时的练手项目——学生管理系统,是不是就能快速地完成后端接口开发了。有些同学可能会想怎么学会了SpringBoot还是进行CRUD操作,确实,在这个项目中没有花里胡哨的功能,就是带领同学们学习新的技术,或是巩固新学习到的技术,如果这是你的第一个SpringBoot项目,相信你能学到很多新技术的,例如MyBatis-Plus、SpringBoot、Redis等,还有一些逻辑上的处理。其实我们一个项目最重要的就是对数据进行处理,而数据的处理不就是增删改查吗,这个项目虽然也是增删改查,但逻辑上其实比你最开始接触的项目要复杂,这其实也是一个很好地锻炼过程。如果觉得简单或者时间不够充足的同学可以了解功能点后自行开发,遇到不懂的看看这篇笔记,或者视频教程。新手还是建议跟着视频1.5倍速,遇到不懂的看下我的笔记就可以完成项目的开发以及知识点的掌握了。看到这里觉得不错的同学可以在一键三连,评论区发一句:“完结撒花”。