内存
JMM
内存模型
Java 内存模型是 Java Memory Model(JMM),本身是一种抽象的概念,实际上并不存在,描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式
JMM 作用:
- 屏蔽各种硬件和操作系统的内存访问差异,实现让 Java 程序在各种平台下都能达到一致的内存访问效果
- 规定了线程和内存之间的一些关系
根据 JMM 的设计,系统存在一个主内存(Main Memory),Java 中所有变量都存储在主存中,对于所有线程都是共享的;每条线程都有自己的工作内存(Working Memory),工作内存中保存的是主存中某些变量的拷贝,线程对所有变量的操作都是先对变量进行拷贝,然后在工作内存中进行,不能直接操作主内存中的变量;线程之间无法相互直接访问,线程间的通信(传递)必须通过主内存来完成

主内存和工作内存:
- 主内存:计算机的内存,也就是经常提到的 8G 内存,16G 内存,存储所有共享变量的值
- 工作内存:存储该线程使用到的共享变量在主内存的的值的副本拷贝
JVM 和 JMM 之间的关系:JMM 中的主内存、工作内存与 JVM 中的 Java 堆、栈、方法区等并不是同一个层次的内存划分,这两者基本上是没有关系的,如果两者一定要勉强对应起来:
- 主内存主要对应于 Java 堆中的对象实例数据部分,而工作内存则对应于虚拟机栈中的部分区域
- 从更低层次上说,主内存直接对应于物理硬件的内存,工作内存对应寄存器和高速缓存
内存交互
Java 内存模型定义了 8 个操作来完成主内存和工作内存的交互操作,每个操作都是原子的
非原子协定:没有被 volatile 修饰的 long、double 外,默认按照两次 32 位的操作

- lock:作用于主内存,将一个变量标识为被一个线程独占状态(对应 monitorenter)
- unclock:作用于主内存,将一个变量从独占状态释放出来,释放后的变量才可以被其他线程锁定(对应 monitorexit)
- read:作用于主内存,把一个变量的值从主内存传输到工作内存中
- load:作用于工作内存,在 read 之后执行,把 read 得到的值放入工作内存的变量副本中
- use:作用于工作内存,把工作内存中一个变量的值传递给执行引擎,每当遇到一个使用到变量的操作时都要使用该指令
- assign:作用于工作内存,把从执行引擎接收到的一个值赋给工作内存的变量
- store:作用于工作内存,把工作内存的一个变量的值传送到主内存中
- write:作用于主内存,在 store 之后执行,把 store 得到的值放入主内存的变量中
参考文章:https://github.com/CyC2018/CS-Notes/blob/master/notes/Java%20%E5%B9%B6%E5%8F%91.md
三大特性
可见性
可见性:是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值
存在不可见问题的根本原因是由于缓存的存在,线程持有的是共享变量的副本,无法感知其他线程对于共享变量的更改,导致读取的值不是最新的。但是 final 修饰的变量是不可变的,就算有缓存,也不会存在不可见的问题
main 线程对 run 变量的修改对于 t 线程不可见,导致了 t 线程无法停止:
static boolean run = true; //添加volatile
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while(run){
// ....
}
});
t.start();
sleep(1);
run = false; // 线程t不会如预想的停下来
}
原因:
- 初始状态, t 线程刚开始从主内存读取了 run 的值到工作内存
- 因为 t 线程要频繁从主内存中读取 run 的值,JIT 编译器会将 run 的值缓存至自己工作内存中的高速缓存中,减少对主存中 run 的访问,提高效率
- 1 秒之后,main 线程修改了 run 的值,并同步至主存,而 t 是从自己工作内存中的高速缓存中读取这个变量的值,结果永远是旧值

原子性
原子性:不可分割,完整性,也就是说某个线程正在做某个具体业务时,中间不可以被分割,需要具体完成,要么同时成功,要么同时失败,保证指令不会受到线程上下文切换的影响
定义原子操作的使用规则:
- 不允许 read 和 load、store 和 write 操作之一单独出现,必须顺序执行,但是不要求连续
- 不允许一个线程丢弃 assign 操作,必须同步回主存
- 不允许一个线程无原因地(没有发生过任何 assign 操作)把数据从工作内存同步会主内存中
- 一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(assign 或者 load)的变量,即对一个变量实施 use 和 store 操作之前,必须先自行 assign 和 load 操作
- 一个变量在同一时刻只允许一条线程对其进行 lock 操作,但 lock 操作可以被同一线程重复执行多次,多次执行 lock 后,只有执行相同次数的 unlock 操作,变量才会被解锁,lock 和 unlock 必须成对出现
- 如果对一个变量执行 lock 操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量之前需要重新从主存加载
- 如果一个变量事先没有被 lock 操作锁定,则不允许执行 unlock 操作,也不允许去 unlock 一个被其他线程锁定的变量
- 对一个变量执行 unlock 操作之前,必须先把此变量同步到主内存中(执行 store 和 write 操作)
有序性
有序性:在本线程内观察,所有操作都是有序的;在一个线程观察另一个线程,所有操作都是无序的,无序是因为发生了指令重排序
CPU 的基本工作是执行存储的指令序列,即程序,程序的执行过程实际上是不断地取出指令、分析指令、执行指令的过程,为了提高性能,编译器和处理器会对指令重排,一般分为以下三种:
源代码 -> 编译器优化的重排 -> 指令并行的重排 -> 内存系统的重排 -> 最终执行指令
现代 CPU 支持多级指令流水线,几乎所有的冯•诺伊曼型计算机的 CPU,其工作都可以分为 5 个阶段:取指令、指令译码、执行指令、访存取数和结果写回,可以称之为五级指令流水线。CPU 可以在一个时钟周期内,同时运行五条指令的不同阶段(每个线程不同的阶段),本质上流水线技术并不能缩短单条指令的执行时间,但变相地提高了指令地吞吐率
处理器在进行重排序时,必须要考虑指令之间的数据依赖性
- 单线程环境也存在指令重排,由于存在依赖性,最终执行结果和代码顺序的结果一致
- 多线程环境中线程交替执行,由于编译器优化重排,会获取其他线程处在不同阶段的指令同时执行
补充知识:
- 指令周期是取出一条指令并执行这条指令的时间,一般由若干个机器周期组成
- 机器周期也称为 CPU 周期,一条指令的执行过程划分为若干个阶段(如取指、译码、执行等),每一阶段完成一个基本操作,完成一个基本操作所需要的时间称为机器周期
- 振荡周期指周期性信号作周期性重复变化的时间间隔
cache
缓存机制
缓存结构
在计算机系统中,CPU 高速缓存(CPU Cache,简称缓存)是用于减少处理器访问内存所需平均时间的部件;在存储体系中位于自顶向下的第二层,仅次于 CPU 寄存器;其容量远小于内存,但速度却可以接近处理器的频率
CPU 处理器速度远远大于在主内存中的,为了解决速度差异,在它们之间架设了多级缓存,如 L1、L2、L3 级别的缓存,这些缓存离 CPU 越近就越快,将频繁操作的数据缓存到这里,加快访问速度

| 从 CPU 到 | 大约需要的时钟周期 |
|---|---|
| 寄存器 | 1 cycle (4GHz 的 CPU 约为 0.25ns) |
| L1 | 3~4 cycle |
| L2 | 10~20 cycle |
| L3 | 40~45 cycle |
| 内存 | 120~240 cycle |
缓存使用
当处理器发出内存访问请求时,会先查看缓存内是否有请求数据,如果存在(命中),则不用访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器
缓存之所以有效,主要因为程序运行时对内存的访问呈现局部性(Locality)特征。既包括空间局部性(Spatial Locality),也包括时间局部性(Temporal Locality),有效利用这种局部性,缓存可以达到极高的命中率
伪共享
缓存以缓存行 cache line 为单位,每个缓存行对应着一块内存,一般是 64 byte(8 个 long),在 CPU 从主存获取数据时,以 cache line 为单位加载,于是相邻的数据会一并加载到缓存中
缓存会造成数据副本的产生,即同一份数据会缓存在不同核心的缓存行中,CPU 要保证数据的一致性,需要做到某个 CPU 核心更改了数据,其它 CPU 核心对应的整个缓存行必须失效,这就是伪共享

解决方法:
-
padding:通过填充,让数据落在不同的 cache line 中
-
@Contended:原理参考 无锁 → Adder → 优化机制 → 伪共享
Linux 查看 CPU 缓存行:
- 命令:
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size64 - 内存地址格式:[高位组标记] [低位索引] [偏移量]
缓存一致
缓存一致性:当多个处理器运算任务都涉及到同一块主内存区域的时候,将可能导致各自的缓存数据不一样

MESI(Modified Exclusive Shared Or Invalid)是一种广泛使用的支持写回策略的缓存一致性协议,CPU 中每个缓存行(caceh line)使用 4 种状态进行标记(使用额外的两位 bit 表示):
-
M:被修改(Modified)
该缓存行只被缓存在该 CPU 的缓存中,并且是被修改过的,与主存中的数据不一致 (dirty),该缓存行中的内存需要写回 (write back) 主存。该状态的数据再次被修改不会发送广播,因为其他核心的数据已经在第一次修改时失效一次
当被写回主存之后,该缓存行的状态会变成独享 (exclusive) 状态
-
E:独享的(Exclusive)
该缓存行只被缓存在该 CPU 的缓存中,是未被修改过的 (clear),与主存中数据一致,修改数据不需要通知其他 CPU 核心,该状态可以在任何时刻有其它 CPU 读取该内存时变成共享状态 (shared)
当 CPU 修改该缓存行中内容时,该状态可以变成 Modified 状态
-
S:共享的(Shared)
该状态意味着该缓存行可能被多个 CPU 缓存,并且各个缓存中的数据与主存数据一致,当 CPU 修改该缓存行中,会向其它 CPU 核心广播一个请求,使该缓存行变成无效状态 (Invalid),然后再更新当前 Cache 里的数据
-
I:无效的(Invalid)
该缓存是无效的,可能有其它 CPU 修改了该缓存行
解决方法:各个处理器访问缓存时都遵循一些协议,在读写时要根据协议进行操作,协议主要有 MSI、MESI 等
处理机制
单核 CPU 处理器会自动保证基本内存操作的原子性
多核 CPU 处理器,每个 CPU 处理器内维护了一块内存,每个内核内部维护着一块缓存,当多线程并发读写时,就会出现缓存数据不一致的情况。处理器提供:
- 总线锁定:当处理器要操作共享变量时,在 BUS 总线上发出一个 LOCK 信号,其他处理器就无法操作这个共享变量,该操作会导致大量阻塞,从而增加系统的性能开销(平台级别的加锁)
- 缓存锁定:当处理器对缓存中的共享变量进行了操作,其他处理器有嗅探机制,将各自缓存中的该共享变量的失效,读取时会重新从主内存中读取最新的数据,基于 MESI 缓存一致性协议来实现
有如下两种情况处理器不会使用缓存锁定:
-
当操作的数据跨多个缓存行,或没被缓存在处理器内部,则处理器会使用总线锁定
-
有些处理器不支持缓存锁定,比如:Intel 486 和 Pentium 处理器也会调用总线锁定
总线机制:
-
总线嗅探:每个处理器通过嗅探在总线上传播的数据来检查自己缓存值是否过期了,当处理器发现自己的缓存对应的内存地址的数据被修改,就将当前处理器的缓存行设置为无效状态,当处理器对这个数据进行操作时,会重新从内存中把数据读取到处理器缓存中
-
总线风暴:当某个 CPU 核心更新了 Cache 中的数据,要把该事件广播通知到其他核心(写传播),CPU 需要每时每刻监听总线上的一切活动,但是不管别的核心的 Cache 是否缓存相同的数据,都需要发出一个广播事件,不断的从主内存嗅探和 CAS 循环,无效的交互会导致总线带宽达到峰值;因此不要大量使用 volatile 关键字,使用 volatile、syschonized 都需要根据实际场景
volatile
同步机制
volatile 是 Java 虚拟机提供的轻量级的同步机制(三大特性)
- 保证可见性
- 不保证原子性
- 保证有序性(禁止指令重排)
性能:volatile 修饰的变量进行读操作与普通变量几乎没什么差别,但是写操作相对慢一些,因为需要在本地代码中插入很多内存屏障来保证指令不会发生乱序执行,但是开销比锁要小
synchronized 无法禁止指令重排和处理器优化,为什么可以保证有序性可见性
- 加了锁之后,只能有一个线程获得到了锁,获得不到锁的线程就要阻塞,所以同一时间只有一个线程执行,相当于单线程,由于数据依赖性的存在,单线程的指令重排是没有问题的
- 线程加锁前,将清空工作内存中共享变量的值,使用共享变量时需要从主内存中重新读取最新的值;线程解锁前,必须把共享变量的最新值刷新到主内存中(JMM 内存交互章节有讲)
指令重排
volatile 修饰的变量,可以禁用指令重排
指令重排实例:
-
example 1:
public void mySort() { int x = 11; //语句1 int y = 12; //语句2 谁先执行效果一样 x = x + 5; //语句3 y = x * x; //语句4 }执行顺序是:1 2 3 4、2 1 3 4、1 3 2 4
指令重排也有限制不会出现:4321,语句 4 需要依赖于 y 以及 x 的申明,因为存在数据依赖,无法首先执行
-
example 2:
int num = 0; boolean ready = false; // 线程1 执行此方法 public void actor1(I_Result r) { if(ready) { r.r1 = num + num; } else { r.r1 = 1; } } // 线程2 执行此方法 public void actor2(I_Result r) { num = 2; ready = true; }情况一:线程 1 先执行,ready = false,结果为 r.r1 = 1
情况二:线程 2 先执行 num = 2,但还没执行 ready = true,线程 1 执行,结果为 r.r1 = 1
情况三:线程 2 先执行 ready = true,线程 1 执行,进入 if 分支结果为 r.r1 = 4
情况四:线程 2 执行 ready = true,切换到线程 1,进入 if 分支为 r.r1 = 0,再切回线程 2 执行 num = 2,发生指令重排
底层原理
缓存一致
使用 volatile 修饰的共享变量,底层通过汇编 lock 前缀指令进行缓存锁定,在线程修改完共享变量后写回主存,其他的 CPU 核心上运行的线程通过 CPU 总线嗅探机制会修改其共享变量为失效状态,读取时会重新从主内存中读取最新的数据
lock 前缀指令就相当于内存屏障,Memory Barrier(Memory Fence)
- 对 volatile 变量的写指令后会加入写屏障
- 对 volatile 变量的读指令前会加入读屏障
内存屏障有三个作用:
- 确保对内存的读-改-写操作原子执行
- 阻止屏障两侧的指令重排序
- 强制把缓存中的脏数据写回主内存,让缓存行中相应的数据失效
内存屏障
保证可见性:
-
写屏障(sfence,Store Barrier)保证在该屏障之前的,对共享变量的改动,都同步到主存当中
public void actor2(I_Result r) { num = 2; ready = true; // ready 是 volatile 赋值带写屏障 // 写屏障 } -
读屏障(lfence,Load Barrier)保证在该屏障之后的,对共享变量的读取,从主存刷新变量值,加载的是主存中最新数据
public void actor1(I_Result r) { // 读屏障 // ready 是 volatile 读取值带读屏障 if(ready) { r.r1 = num + num; } else { r.r1 = 1; } }
-
全能屏障:mfence(modify/mix Barrier),兼具 sfence 和 lfence 的功能
保证有序性:
- 写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
- 读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
不能解决指令交错:
-
写屏障仅仅是保证之后的读能够读到最新的结果,但不能保证其他线程的读跑到写屏障之前
-
有序性的保证也只是保证了本线程内相关代码不被重排序
volatile i = 0; new Thread(() -> {i++}); new Thread(() -> {i--});i++ 反编译后的指令:
0: iconst_1 // 当int取值 -1~5 时,JVM采用iconst指令将常量压入栈中 1: istore_1 // 将操作数栈顶数据弹出,存入局部变量表的 slot 1 2: iinc 1, 1
交互规则
对于 volatile 修饰的变量:
- 线程对变量的 use 与 load、read 操作是相关联的,所以变量使用前必须先从主存加载
- 线程对变量的 assign 与 store、write 操作是相关联的,所以变量使用后必须同步至主存
- 线程 1 和线程 2 谁先对变量执行 read 操作,就会先进行 write 操作,防止指令重排
双端检锁
检锁机制
Double-Checked Locking:双端检锁机制
DCL(双端检锁)机制不一定是线程安全的,原因是有指令重排的存在,加入 volatile 可以禁止指令重排
public final class Singleton {
private Singleton() { }
private static Singleton INSTANCE = null;
public static Singleton getInstance() {
if(INSTANCE == null) { // t2,这里的判断不是线程安全的
// 首次访问会同步,而之后的使用没有 synchronized
synchronized(Singleton.class) {
// 这里是线程安全的判断,防止其他线程在当前线程等待锁的期间完成了初始化
if (INSTANCE == null) {
INSTANCE = new Singleton();
}
}
}
return INSTANCE;
}
}
不锁 INSTANCE 的原因:
- INSTANCE 要重新赋值
- INSTANCE 是 null,线程加锁之前需要获取对象的引用,设置对象头,null 没有引用
实现特点:
- 懒惰初始化
- 首次使用 getInstance() 才使用 synchronized 加锁,后续使用时无需加锁
- 第一个 if 使用了 INSTANCE 变量,是在同步块之外,但在多线程环境下会产生问题
DCL问题
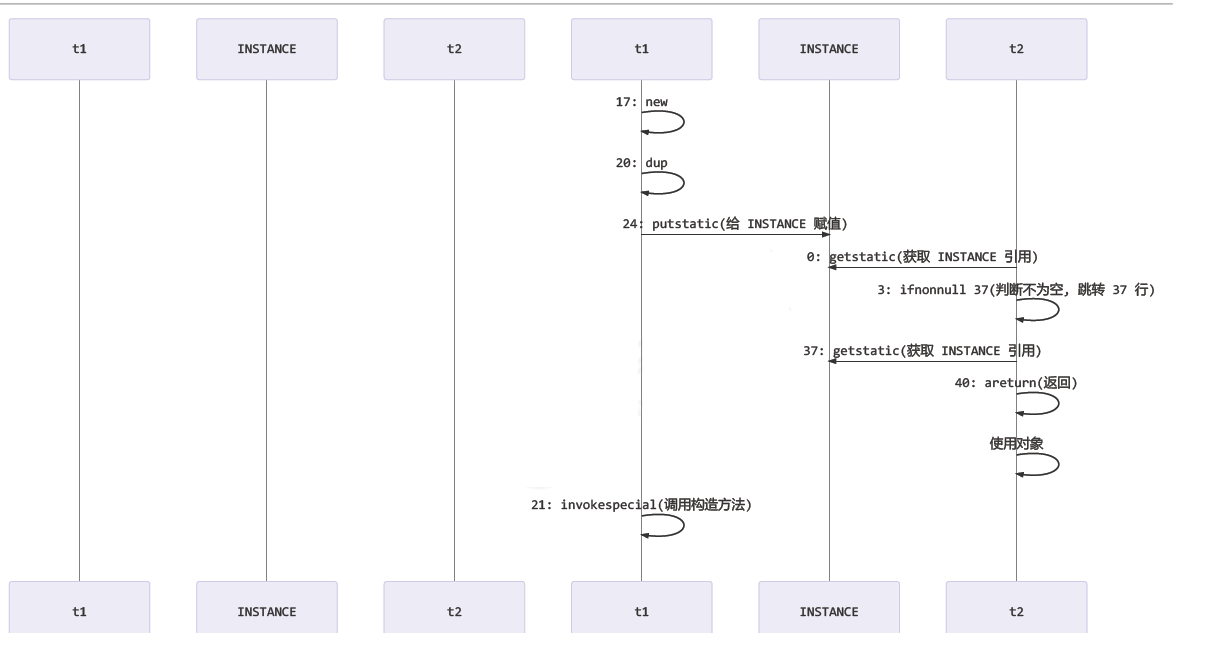
getInstance 方法对应的字节码为:
0: getstatic #2 // Field INSTANCE:Ltest/Singleton;
3: ifnonnull 37
6: ldc #3 // class test/Singleton
8: dup
9: astore_0
10: monitorenter
11: getstatic #2 // Field INSTANCE:Ltest/Singleton;
14: ifnonnull 27
17: new #3 // class test/Singleton
20: dup
21: invokespecial #4 // Method "<init>":()V
24: putstatic #2 // Field INSTANCE:Ltest/Singleton;
27: aload_0
28: monitorexit
29: goto 37
32: astore_1
33: aload_0
34: monitorexit
35: aload_1
36: athrow
37: getstatic #2 // Field INSTANCE:Ltest/Singleton;
40: areturn
- 17 表示创建对象,将对象引用入栈
- 20 表示复制一份对象引用,引用地址
- 21 表示利用一个对象引用,调用构造方法初始化对象
- 24 表示利用一个对象引用,赋值给 static INSTANCE
步骤 21 和 24 之间不存在数据依赖关系,而且无论重排前后,程序的执行结果在单线程中并没有改变,因此这种重排优化是允许的
- 关键在于 0:getstatic 这行代码在 monitor 控制之外,可以越过 monitor 读取 INSTANCE 变量的值
- 当其他线程访问 INSTANCE 不为 null 时,由于 INSTANCE 实例未必已初始化,那么 t2 拿到的是将是一个未初始化完毕的单例返回,这就造成了线程安全的问题
解决方法
指令重排只会保证串行语义的执行一致性(单线程),但并不会关系多线程间的语义一致性
引入 volatile,来保证出现指令重排的问题,从而保证单例模式的线程安全性:
private static volatile SingletonDemo INSTANCE = null;
ha-be
happens-before 先行发生
Java 内存模型具备一些先天的“有序性”,即不需要通过任何同步手段(volatile、synchronized 等)就能够得到保证的安全,这个通常也称为 happens-before 原则,它是可见性与有序性的一套规则总结
不符合 happens-before 规则,JMM 并不能保证一个线程的可见性和有序性
-
程序次序规则 (Program Order Rule):一个线程内,逻辑上书写在前面的操作先行发生于书写在后面的操作 ,因为多个操作之间有先后依赖关系,则不允许对这些操作进行重排序
-
锁定规则 (Monitor Lock Rule):一个 unlock 操作先行发生于后面(时间的先后)对同一个锁的 lock 操作,所以线程解锁 m 之前对变量的写(解锁前会刷新到主内存中),对于接下来对 m 加锁的其它线程对该变量的读可见
-
volatile 变量规则 (Volatile Variable Rule):对 volatile 变量的写操作先行发生于后面对这个变量的读
-
传递规则 (Transitivity):具有传递性,如果操作 A 先行发生于操作 B,而操作 B 又先行发生于操作 C,则可以得出操作 A 先行发生于操作 C
-
线程启动规则 (Thread Start Rule):Thread 对象的 start()方 法先行发生于此线程中的每一个操作
static int x = 10;//线程 start 前对变量的写,对该线程开始后对该变量的读可见 new Thread(()->{ System.out.println(x); },"t1").start(); -
线程中断规则 (Thread Interruption Rule):对线程 interrupt() 方法的调用先行发生于被中断线程的代码检测到中断事件的发生
-
线程终止规则 (Thread Termination Rule):线程中所有的操作都先行发生于线程的终止检测,可以通过 Thread.join() 方法结束、Thread.isAlive() 的返回值手段检测到线程已经终止执行
-
对象终结规则(Finaizer Rule):一个对象的初始化完成(构造函数执行结束)先行发生于它的 finalize() 方法的开始
设计模式
终止模式
终止模式之两阶段终止模式:停止标记用 volatile 是为了保证该变量在多个线程之间的可见性
class TwoPhaseTermination {
// 监控线程
private Thread monitor;
// 停止标记
private volatile boolean stop = false;;
// 启动监控线程
public void start() {
monitor = new Thread(() -> {
while (true) {
Thread thread = Thread.currentThread();
if (stop) {
System.out.println("后置处理");
break;
}
try {
Thread.sleep(1000);// 睡眠
System.out.println(thread.getName() + "执行监控记录");
} catch (InterruptedException e) {
System.out.println("被打断,退出睡眠");
}
}
});
monitor.start();
}
// 停止监控线程
public void stop() {
stop = true;
monitor.interrupt();// 让线程尽快退出Timed Waiting
}
}
// 测试
public static void main(String[] args) throws InterruptedException {
TwoPhaseTermination tpt = new TwoPhaseTermination();
tpt.start();
Thread.sleep(3500);
System.out.println("停止监控");
tpt.stop();
}
Balking
Balking (犹豫)模式用在一个线程发现另一个线程或本线程已经做了某一件相同的事,那么本线程就无需再做了,直接结束返回
public class MonitorService {
// 用来表示是否已经有线程已经在执行启动了
private volatile boolean starting = false;
public void start() {
System.out.println("尝试启动监控线程...");
synchronized (this) {
if (starting) {
return;
}
starting = true;
}
// 真正启动监控线程...
}
}
对比保护性暂停模式:保护性暂停模式用在一个线程等待另一个线程的执行结果,当条件不满足时线程等待
例子:希望 doInit() 方法仅被调用一次,下面的实现出现的问题:
- 当 t1 线程进入 init() 准备 doInit(),t2 线程进来,initialized 还为f alse,则 t2 就又初始化一次
- volatile 适合一个线程写,其他线程读的情况,这个代码需要加锁
public class TestVolatile {
volatile boolean initialized = false;
void init() {
if (initialized) {
return;
}
doInit();
initialized = true;
}
private void doInit() {
}
}
无锁
CAS
原理
无锁编程:Lock Free
CAS 的全称是 Compare-And-Swap,是 CPU 并发原语
- CAS 并发原语体现在 Java 语言中就是 sun.misc.Unsafe 类的各个方法,调用 UnSafe 类中的 CAS 方法,JVM 会实现出 CAS 汇编指令,这是一种完全依赖于硬件的功能,实现了原子操作
- CAS 是一种系统原语,原语属于操作系统范畴,是由若干条指令组成 ,用于完成某个功能的一个过程,并且原语的执行必须是连续的,执行过程中不允许被中断,所以 CAS 是一条 CPU 的原子指令,不会造成数据不一致的问题,是线程安全的
底层原理:CAS 的底层是 lock cmpxchg 指令(X86 架构),在单核和多核 CPU 下都能够保证比较交换的原子性
-
程序是在单核处理器上运行,会省略 lock 前缀,单处理器自身会维护处理器内的顺序一致性,不需要 lock 前缀的内存屏障效果
-
程序是在多核处理器上运行,会为 cmpxchg 指令加上 lock 前缀。当某个核执行到带 lock 的指令时,CPU 会执行总线锁定或缓存锁定,将修改的变量写入到主存,这个过程不会被线程的调度机制所打断,保证了多个线程对内存操作的原子性
作用:比较当前工作内存中的值和主物理内存中的值,如果相同则执行规定操作,否则继续比较直到主内存和工作内存的值一致为止
CAS 特点:
- CAS 体现的是无锁并发、无阻塞并发,线程不会陷入阻塞,线程不需要频繁切换状态(上下文切换,系统调用)
- CAS 是基于乐观锁的思想
CAS 缺点:
- 执行的是循环操作,如果比较不成功一直在循环,最差的情况某个线程一直取到的值和预期值都不一样,就会无限循环导致饥饿,使用 CAS 线程数不要超过 CPU 的核心数,采用分段 CAS 和自动迁移机制
- 只能保证一个共享变量的原子操作
- 对于一个共享变量执行操作时,可以通过循环 CAS 的方式来保证原子操作
- 对于多个共享变量操作时,循环 CAS 就无法保证操作的原子性,这个时候只能用锁来保证原子性
- 引出来 ABA 问题
乐观锁
CAS 与 synchronized 总结:
- synchronized 是从悲观的角度出发:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程),因此 synchronized 也称之为悲观锁,ReentrantLock 也是一种悲观锁,性能较差
- CAS 是从乐观的角度出发:总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。如果别人修改过,则获取现在最新的值,如果别人没修改过,直接修改共享数据的值,CAS 这种机制也称之为乐观锁,综合性能较好
Atomic
常用API
常见原子类:AtomicInteger、AtomicBoolean、AtomicLong
构造方法:
public AtomicInteger():初始化一个默认值为 0 的原子型 Integerpublic AtomicInteger(int initialValue):初始化一个指定值的原子型 Integer
常用API:
| 方法 | 作用 |
|---|---|
| public final int get() | 获取 AtomicInteger 的值 |
| public final int getAndIncrement() | 以原子方式将当前值加 1,返回的是自增前的值 |
| public final int incrementAndGet() | 以原子方式将当前值加 1,返回的是自增后的值 |
| public final int getAndSet(int value) | 以原子方式设置为 newValue 的值,返回旧值 |
| public final int addAndGet(int data) | 以原子方式将输入的数值与实例中的值相加并返回 实例:AtomicInteger 里的 value |
原理分析
AtomicInteger 原理:自旋锁 + CAS 算法
CAS 算法:有 3 个操作数(内存值 V, 旧的预期值 A,要修改的值 B)
- 当旧的预期值 A == 内存值 V 此时可以修改,将 V 改为 B
- 当旧的预期值 A != 内存值 V 此时不能修改,并重新获取现在的最新值,重新获取的动作就是自旋
分析 getAndSet 方法:
-
AtomicInteger:
public final int getAndSet(int newValue) { /** * this: 当前对象 * valueOffset: 内存偏移量,内存地址 */ return unsafe.getAndSetInt(this, valueOffset, newValue); }valueOffset:偏移量表示该变量值相对于当前对象地址的偏移,Unsafe 就是根据内存偏移地址获取数据
valueOffset = unsafe.objectFieldOffset (AtomicInteger.class.getDeclaredField("value")); //调用本地方法 --> public native long objectFieldOffset(Field var1); -
unsafe 类:
// val1: AtomicInteger对象本身,var2: 该对象值得引用地址,var4: 需要变动的数 public final int getAndSetInt(Object var1, long var2, int var4) { int var5; do { // var5: 用 var1 和 var2 找到的内存中的真实值 var5 = this.getIntVolatile(var1, var2); } while(!this.compareAndSwapInt(var1, var2, var5, var4)); return var5; }var5:从主内存中拷贝到工作内存中的值(每次都要从主内存拿到最新的值到本地内存),然后执行
compareAndSwapInt()再和主内存的值进行比较,假设方法返回 false,那么就一直执行 while 方法,直到期望的值和真实值一样,修改数据 -
变量 value 用 volatile 修饰,保证了多线程之间的内存可见性,避免线程从工作缓存中获取失效的变量
private volatile int valueCAS 必须借助 volatile 才能读取到共享变量的最新值来实现比较并交换的效果
分析 getAndUpdate 方法:
-
getAndUpdate:
public final int getAndUpdate(IntUnaryOperator updateFunction) { int prev, next; do { prev = get(); //当前值,cas的期望值 next = updateFunction.applyAsInt(prev);//期望值更新到该值 } while (!compareAndSet(prev, next));//自旋 return prev; }函数式接口:可以自定义操作逻辑
AtomicInteger a = new AtomicInteger(); a.getAndUpdate(i -> i + 10); -
compareAndSet:
public final boolean compareAndSet(int expect, int update) { /** * this: 当前对象 * valueOffset: 内存偏移量,内存地址 * expect: 期望的值 * update: 更新的值 */ return unsafe.compareAndSwapInt(this, valueOffset, expect, update); }
原子引用
原子引用:对 Object 进行原子操作,提供一种读和写都是原子性的对象引用变量
原子引用类:AtomicReference、AtomicStampedReference、AtomicMarkableReference
AtomicReference 类:
-
构造方法:
AtomicReference<T> atomicReference = new AtomicReference<T>() -
常用 API:
public final boolean compareAndSet(V expectedValue, V newValue):CAS 操作public final void set(V newValue):将值设置为 newValuepublic final V get():返回当前值
public class AtomicReferenceDemo {
public static void main(String[] args) {
Student s1 = new Student(33, "z3");
// 创建原子引用包装类
AtomicReference<Student> atomicReference = new AtomicReference<>();
// 设置主内存共享变量为s1
atomicReference.set(s1);
// 比较并交换,如果现在主物理内存的值为 z3,那么交换成 l4
while (true) {
Student s2 = new Student(44, "l4");
if (atomicReference.compareAndSet(s1, s2)) {
break;
}
}
System.out.println(atomicReference.get());
}
}
class Student {
private int id;
private String name;
//。。。。
}
原子数组
原子数组类:AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray
AtomicIntegerArray 类方法:
/**
* i the index
* expect the expected value
* update the new value
*/
public final boolean compareAndSet(int i, int expect, int update) {
return compareAndSetRaw(checkedByteOffset(i), expect, update);
}
原子更新器
原子更新器类:AtomicReferenceFieldUpdater、AtomicIntegerFieldUpdater、AtomicLongFieldUpdater
利用字段更新器,可以针对对象的某个域(Field)进行原子操作,只能配合 volatile 修饰的字段使用,否则会出现异常 IllegalArgumentException: Must be volatile type
常用 API:
static <U> AtomicIntegerFieldUpdater<U> newUpdater(Class<U> c, String fieldName):构造方法abstract boolean compareAndSet(T obj, int expect, int update):CAS
public class UpdateDemo {
private volatile int field;
public static void main(String[] args) {
AtomicIntegerFieldUpdater fieldUpdater = AtomicIntegerFieldUpdater
.newUpdater(UpdateDemo.class, "field");
UpdateDemo updateDemo = new UpdateDemo();
fieldUpdater.compareAndSet(updateDemo, 0, 10);
System.out.println(updateDemo.field);//10
}
}
原子累加器
原子累加器类:LongAdder、DoubleAdder、LongAccumulator、DoubleAccumulator
LongAdder 和 LongAccumulator 区别:
相同点:
- LongAddr 与 LongAccumulator 类都是使用非阻塞算法 CAS 实现的
- LongAddr 类是 LongAccumulator 类的一个特例,只是 LongAccumulator 提供了更强大的功能,可以自定义累加规则,当accumulatorFunction 为 null 时就等价于 LongAddr
不同点:
-
调用 casBase 时,LongAccumulator 使用 function.applyAsLong(b = base, x) 来计算,LongAddr 使用 casBase(b = base, b + x)
-
LongAccumulator 类功能更加强大,构造方法参数中
- accumulatorFunction 是一个双目运算器接口,可以指定累加规则,比如累加或者相乘,其根据输入的两个参数返回一个计算值,LongAdder 内置累加规则
- identity 则是 LongAccumulator 累加器的初始值,LongAccumulator 可以为累加器提供非0的初始值,而 LongAdder 只能提供默认的 0
Adder
优化机制
LongAdder 是 Java8 提供的类,跟 AtomicLong 有相同的效果,但对 CAS 机制进行了优化,尝试使用分段 CAS 以及自动分段迁移的方式来大幅度提升多线程高并发执行 CAS 操作的性能
CAS 底层实现是在一个循环中不断地尝试修改目标值,直到修改成功。如果竞争不激烈修改成功率很高,否则失败率很高,失败后这些重复的原子性操作会耗费性能(导致大量线程空循环,自旋转)
优化核心思想:数据分离,将 AtomicLong 的单点的更新压力分担到各个节点,空间换时间,在低并发的时候直接更新,可以保障和 AtomicLong 的性能基本一致,而在高并发的时候通过分散减少竞争,提高了性能
分段 CAS 机制:
- 在发生竞争时,创建 Cell 数组用于将不同线程的操作离散(通过 hash 等算法映射)到不同的节点上
- 设置多个累加单元(会根据需要扩容,最大为 CPU 核数),Therad-0 累加 Cell[0],而 Thread-1 累加 Cell[1] 等,最后将结果汇总
- 在累加时操作的不同的 Cell 变量,因此减少了 CAS 重试失败,从而提高性能
自动分段迁移机制:某个 Cell 的 value 执行 CAS 失败,就会自动寻找另一个 Cell 分段内的 value 值进行 CAS 操作
伪共享
Cell 为累加单元:数组访问索引是通过 Thread 里的 threadLocalRandomProbe 域取模实现的,这个域是 ThreadLocalRandom 更新的
// Striped64.Cell
@sun.misc.Contended static final class Cell {
volatile long value;
Cell(long x) { value = x; }
// 用 cas 方式进行累加, prev 表示旧值, next 表示新值
final boolean cas(long prev, long next) {
return UNSAFE.compareAndSwapLong(this, valueOffset, prev, next);
}
// 省略不重要代码
}
Cell 是数组形式,在内存中是连续存储的,64 位系统中,一个 Cell 为 24 字节(16 字节的对象头和 8 字节的 value),每一个 cache line 为 64 字节,因此缓存行可以存下 2 个的 Cell 对象,当 Core-0 要修改 Cell[0]、Core-1 要修改 Cell[1],无论谁修改成功都会导致当前缓存行失效,从而导致对方的数据失效,需要重新去主存获取,影响效率
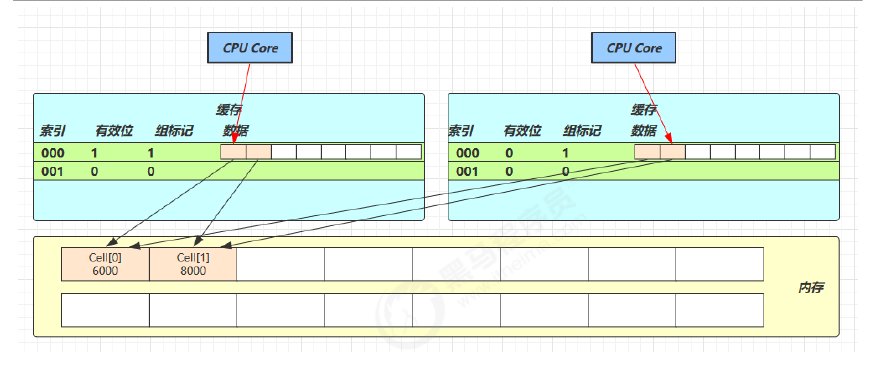
@sun.misc.Contended:防止缓存行伪共享,在使用此注解的对象或字段的前后各增加 128 字节大小的 padding,使用 2 倍于大多数硬件缓存行让 CPU 将对象预读至缓存时占用不同的缓存行,这样就不会造成对方缓存行的失效
源码解析
Striped64 类成员属性:
// 表示当前计算机CPU数量
static final int NCPU = Runtime.getRuntime().availableProcessors()
// 累加单元数组, 懒惰初始化
transient volatile Cell[] cells;
// 基础值, 如果没有竞争, 则用 cas 累加这个域,当 cells 扩容时,也会将数据写到 base 中
transient volatile long base;
// 在 cells 初始化或扩容时只能有一个线程执行, 通过 CAS 更新 cellsBusy 置为 1 来实现一个锁
transient volatile int cellsBusy;
工作流程:
-
cells 占用内存是相对比较大的,是惰性加载的,在无竞争或者其他线程正在初始化 cells 数组的情况下,直接更新 base 域
-
在第一次发生竞争时(casBase 失败)会创建一个大小为 2 的 cells 数组,将当前累加的值包装为 Cell 对象,放入映射的槽位上
-
分段累加的过程中,如果当前线程对应的 cells 槽位为空,就会新建 Cell 填充,如果出现竞争,就会重新计算线程对应的槽位,继续自旋尝试修改
-
分段迁移后还出现竞争就会扩容 cells 数组长度为原来的两倍,然后 rehash,数组长度总是 2 的 n 次幂,默认最大为 CPU 核数,但是可以超过,如果核数是 6 核,数组最长是 8
方法分析:
-
LongAdder#add:累加方法
public void add(long x) { // as 为累加单元数组的引用,b 为基础值,v 表示期望值 // m 表示 cells 数组的长度 - 1,a 表示当前线程命中的 cell 单元格 Cell[] as; long b, v; int m; Cell a; // cells 不为空说明 cells 已经被初始化,线程发生了竞争,去更新对应的 cell 槽位 // 进入 || 后的逻辑去更新 base 域,更新失败表示发生竞争进入条件 if ((as = cells) != null || !casBase(b = base, b + x)) { // uncontended 为 true 表示 cell 没有竞争 boolean uncontended = true; // 条件一: true 说明 cells 未初始化,多线程写 base 发生竞争需要进行初始化 cells 数组 // fasle 说明 cells 已经初始化,进行下一个条件寻找自己的 cell 去累加 // 条件二: getProbe() 获取 hash 值,& m 的逻辑和 HashMap 的逻辑相同,保证散列的均匀性 // true 说明当前线程对应下标的 cell 为空,需要创建 cell // false 说明当前线程对应的 cell 不为空,进行下一个条件【将 x 值累加到对应的 cell 中】 // 条件三: 有取反符号,false 说明 cas 成功,直接返回,true 说明失败,当前线程对应的 cell 有竞争 if (as == null || (m = as.length - 1) < 0 || (a = as[getProbe() & m]) == null || !(uncontended = a.cas(v = a.value, v + x))) longAccumulate(x, null, uncontended); // 【uncontended 在对应的 cell 上累加失败的时候才为 false,其余情况均为 true】 } } -
Striped64#longAccumulate:cell 数组创建
// x null false | true final void longAccumulate(long x, LongBinaryOperator fn, boolean wasUncontended) { int h; // 当前线程还没有对应的 cell, 需要随机生成一个 hash 值用来将当前线程绑定到 cell if ((h = getProbe()) == 0) { // 初始化 probe,获取 hash 值 ThreadLocalRandom.current(); h = getProbe(); // 默认情况下 当前线程肯定是写入到了 cells[0] 位置,不把它当做一次真正的竞争 wasUncontended = true; } // 表示【扩容意向】,false 一定不会扩容,true 可能会扩容 boolean collide = false; //自旋 for (;;) { // as 表示cells引用,a 表示当前线程命中的 cell,n 表示 cells 数组长度,v 表示 期望值 Cell[] as; Cell a; int n; long v; // 【CASE1】: 表示 cells 已经初始化了,当前线程应该将数据写入到对应的 cell 中 if ((as = cells) != null && (n = as.length) > 0) { // CASE1.1: true 表示当前线程对应的索引下标的 Cell 为 null,需要创建 new Cell if ((a = as[(n - 1) & h]) == null) { // 判断 cellsBusy 是否被锁 if (cellsBusy == 0) { // 创建 cell, 初始累加值为 x Cell r = new Cell(x); // 加锁 if (cellsBusy == 0 && casCellsBusy()) { // 创建成功标记,进入【创建 cell 逻辑】 boolean created = false; try { Cell[] rs; int m, j; // 把当前 cells 数组赋值给 rs,并且不为 null if ((rs = cells) != null && (m = rs.length) > 0 && // 再次判断防止其它线程初始化过该位置,当前线程再次初始化该位置会造成数据丢失 // 因为这里是线程安全的判断,进行的逻辑不会被其他线程影响 rs[j = (m - 1) & h] == null) { // 把新创建的 cell 填充至当前位置 rs[j] = r; created = true; // 表示创建完成 } } finally { cellsBusy = 0; // 解锁 } if (created) // true 表示创建完成,可以推出循环了 break; continue; } } collide = false; } // CASE1.2: 条件成立说明线程对应的 cell 有竞争, 改变线程对应的 cell 来重试 cas else if (!wasUncontended) wasUncontended = true; // CASE 1.3: 当前线程 rehash 过,如果新命中的 cell 不为空,就尝试累加,false 说明新命中也有竞争 else if (a.cas(v = a.value, ((fn == null) ? v + x : fn.applyAsLong(v, x)))) break; // CASE 1.4: cells 长度已经超过了最大长度 CPU 内核的数量或者已经扩容 else if (n >= NCPU || cells != as) collide = false; // 扩容意向改为false,【表示不能扩容了】 // CASE 1.5: 更改扩容意向,如果 n >= NCPU,这里就永远不会执行到,case1.4 永远先于 1.5 执行 else if (!collide) collide = true; // CASE 1.6: 【扩容逻辑】,进行加锁 else if (cellsBusy == 0 && casCellsBusy()) { try { // 线程安全的检查,防止期间被其他线程扩容了 if (cells == as) { // 扩容为以前的 2 倍 Cell[] rs = new Cell[n << 1]; // 遍历移动值 for (int i = 0; i < n; ++i) rs[i] = as[i]; // 把扩容后的引用给 cells cells = rs; } } finally { cellsBusy = 0; // 解锁 } collide = false; // 扩容意向改为 false,表示不扩容了 continue; } // 重置当前线程 Hash 值,这就是【分段迁移机制】 h = advanceProbe(h); } // 【CASE2】: 运行到这说明 cells 还未初始化,as 为null // 判断是否没有加锁,没有加锁就用 CAS 加锁 // 条件二判断是否其它线程在当前线程给 as 赋值之后修改了 cells,这里不是线程安全的判断 else if (cellsBusy == 0 && cells == as && casCellsBusy()) { // 初始化标志,开始 【初始化 cells 数组】 boolean init = false; try { // 再次判断 cells == as 防止其它线程已经提前初始化了,当前线程再次初始化导致丢失数据 // 因为这里是【线程安全的,重新检查,经典 DCL】 if (cells == as) { Cell[] rs = new Cell[2]; // 初始化数组大小为2 rs[h & 1] = new Cell(x); // 填充线程对应的cell cells = rs; init = true; // 初始化成功,标记置为 true } } finally { cellsBusy = 0; // 解锁啊 } if (init) break; // 初始化成功直接跳出自旋 } // 【CASE3】: 运行到这说明其他线程在初始化 cells,当前线程将值累加到 base,累加成功直接结束自旋 else if (casBase(v = base, ((fn == null) ? v + x : fn.applyAsLong(v, x)))) break; } } -
sum:获取最终结果通过 sum 整合,保证最终一致性,不保证强一致性
public long sum() { Cell[] as = cells; Cell a; long sum = base; if (as != null) { // 遍历 累加 for (int i = 0; i < as.length; ++i) { if ((a = as[i]) != null) sum += a.value; } } return sum; }
ABA
ABA 问题:当进行获取主内存值时,该内存值在写入主内存时已经被修改了 N 次,但是最终又改成原来的值
其他线程先把 A 改成 B 又改回 A,主线程仅能判断出共享变量的值与最初值 A 是否相同,不能感知到这种从 A 改为 B 又 改回 A 的情况,这时 CAS 虽然成功,但是过程存在问题
-
构造方法:
public AtomicStampedReference(V initialRef, int initialStamp):初始值和初始版本号
-
常用API:
public boolean compareAndSet(V expectedReference, V newReference, int expectedStamp, int newStamp):期望引用和期望版本号都一致才进行 CAS 修改数据public void set(V newReference, int newStamp):设置值和版本号public V getReference():返回引用的值public int getStamp():返回当前版本号
public static void main(String[] args) {
AtomicStampedReference<Integer> atomicReference = new AtomicStampedReference<>(100,1);
int startStamp = atomicReference.getStamp();
new Thread(() ->{
int stamp = atomicReference.getStamp();
atomicReference.compareAndSet(100, 101, stamp, stamp + 1);
stamp = atomicReference.getStamp();
atomicReference.compareAndSet(101, 100, stamp, stamp + 1);
},"t1").start();
new Thread(() ->{
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (!atomicReference.compareAndSet(100, 200, startStamp, startStamp + 1)) {
System.out.println(atomicReference.getReference());//100
System.out.println(Thread.currentThread().getName() + "线程修改失败");
}
},"t2").start();
}
Unsafe
Unsafe 是 CAS 的核心类,由于 Java 无法直接访问底层系统,需要通过本地(Native)方法来访问
Unsafe 类存在 sun.misc 包,其中所有方法都是 native 修饰的,都是直接调用操作系统底层资源执行相应的任务,基于该类可以直接操作特定的内存数据,其内部方法操作类似 C 的指针
模拟实现原子整数:
public static void main(String[] args) {
MyAtomicInteger atomicInteger = new MyAtomicInteger(10);
if (atomicInteger.compareAndSwap(20)) {
System.out.println(atomicInteger.getValue());
}
}
class MyAtomicInteger {
private static final Unsafe UNSAFE;
private static final long VALUE_OFFSET;
private volatile int value;
static {
try {
//Unsafe unsafe = Unsafe.getUnsafe()这样会报错,需要反射获取
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
UNSAFE = (Unsafe) theUnsafe.get(null);
// 获取 value 属性的内存地址,value 属性指向该地址,直接设置该地址的值可以修改 value 的值
VALUE_OFFSET = UNSAFE.objectFieldOffset(
MyAtomicInteger.class.getDeclaredField("value"));
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
throw new RuntimeException();
}
}
public MyAtomicInteger(int value) {
this.value = value;
}
public int getValue() {
return value;
}
public boolean compareAndSwap(int update) {
while (true) {
int prev = this.value;
int next = update;
// 当前对象 内存偏移量 期望值 更新值
if (UNSAFE.compareAndSwapInt(this, VALUE_OFFSET, prev, update)) {
System.out.println("CAS成功");
return true;
}
}
}
}
final
原理
public class TestFinal {
final int a = 20;
}
字节码:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: aload_0
5: bipush 20 // 将值直接放入栈中
7: putfield #2 // Field a:I
<-- 写屏障
10: return
final 变量的赋值通过 putfield 指令来完成,在这条指令之后也会加入写屏障,保证在其它线程读到它的值时不会出现为 0 的情况
其他线程访问 final 修饰的变量
- 复制一份放入栈中直接访问,效率高
- 大于 short 最大值会将其复制到类的常量池,访问时从常量池获取
不可变
不可变:如果一个对象不能够修改其内部状态(属性),那么就是不可变对象
不可变对象线程安全的,不存在并发修改和可见性问题,是另一种避免竞争的方式
String 类也是不可变的,该类和类中所有属性都是 final 的
-
类用 final 修饰保证了该类中的方法不能被覆盖,防止子类无意间破坏不可变性
-
无写入方法(set)确保外部不能对内部属性进行修改
-
属性用 final 修饰保证了该属性是只读的,不能修改
public final class String implements java.io.Serializable, Comparable<String>, CharSequence { /** The value is used for character storage. */ private final char value[]; //.... } -
更改 String 类数据时,会构造新字符串对象,生成新的 char[] value,通过创建副本对象来避免共享的方式称之为保护性拷贝
State
无状态:成员变量保存的数据也可以称为状态信息,无状态就是没有成员变量
Servlet 为了保证其线程安全,一般不为 Servlet 设置成员变量,这种没有任何成员变量的类是线程安全的
Local
基本介绍
ThreadLocal 类用来提供线程内部的局部变量,这种变量在多线程环境下访问(通过 get 和 set 方法访问)时能保证各个线程的变量相对独立于其他线程内的变量,分配在堆内的 TLAB 中
ThreadLocal 实例通常来说都是 private static 类型的,属于一个线程的本地变量,用于关联线程和线程上下文。每个线程都会在 ThreadLocal 中保存一份该线程独有的数据,所以是线程安全的
ThreadLocal 作用:
-
线程并发:应用在多线程并发的场景下
-
传递数据:通过 ThreadLocal 实现在同一线程不同函数或组件中传递公共变量,减少传递复杂度
-
线程隔离:每个线程的变量都是独立的,不会互相影响
对比 synchronized:
| synchronized | ThreadLocal | |
|---|---|---|
| 原理 | 同步机制采用以时间换空间的方式,只提供了一份变量,让不同的线程排队访问 | ThreadLocal 采用以空间换时间的方式,为每个线程都提供了一份变量的副本,从而实现同时访问而相不干扰 |
| 侧重点 | 多个线程之间访问资源的同步 | 多线程中让每个线程之间的数据相互隔离 |
基本使用
常用方法
| 方法 | 描述 |
|---|---|
| ThreadLocal<>() | 创建 ThreadLocal 对象 |
| protected T initialValue() | 返回当前线程局部变量的初始值 |
| public void set( T value) | 设置当前线程绑定的局部变量 |
| public T get() | 获取当前线程绑定的局部变量 |
| public void remove() | 移除当前线程绑定的局部变量 |
public class MyDemo {
private static ThreadLocal<String> tl = new ThreadLocal<>();
private String content;
private String getContent() {
// 获取当前线程绑定的变量
return tl.get();
}
private void setContent(String content) {
// 变量content绑定到当前线程
tl.set(content);
}
public static void main(String[] args) {
MyDemo demo = new MyDemo();
for (int i = 0; i < 5; i++) {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
// 设置数据
demo.setContent(Thread.currentThread().getName() + "的数据");
System.out.println("-----------------------");
System.out.println(Thread.currentThread().getName() + "--->" + demo.getContent());
}
});
thread.setName("线程" + i);
thread.start();
}
}
}
应用场景
ThreadLocal 适用于下面两种场景:
- 每个线程需要有自己单独的实例
- 实例需要在多个方法中共享,但不希望被多线程共享
ThreadLocal 方案有两个突出的优势:
- 传递数据:保存每个线程绑定的数据,在需要的地方可以直接获取,避免参数直接传递带来的代码耦合问题
- 线程隔离:各线程之间的数据相互隔离却又具备并发性,避免同步方式带来的性能损失
ThreadLocal 用于数据连接的事务管理:
public class JdbcUtils {
// ThreadLocal对象,将connection绑定在当前线程中
private static final ThreadLocal<Connection> tl = new ThreadLocal();
// c3p0 数据库连接池对象属性
private static final ComboPooledDataSource ds = new ComboPooledDataSource();
// 获取连接
public static Connection getConnection() throws SQLException {
//取出当前线程绑定的connection对象
Connection conn = tl.get();
if (conn == null) {
//如果没有,则从连接池中取出
conn = ds.getConnection();
//再将connection对象绑定到当前线程中,非常重要的操作
tl.set(conn);
}
return conn;
}
// ...
}
用 ThreadLocal 使 SimpleDateFormat 从独享变量变成单个线程变量:
public class ThreadLocalDateUtil {
private static ThreadLocal<DateFormat> threadLocal = new ThreadLocal<DateFormat>() {
@Override
protected DateFormat initialValue() {
return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
}
};
public static Date parse(String dateStr) throws ParseException {
return threadLocal.get().parse(dateStr);
}
public static String format(Date date) {
return threadLocal.get().format(date);
}
}
实现原理
底层结构
JDK8 以前:每个 ThreadLocal 都创建一个 Map,然后用线程作为 Map 的 key,要存储的局部变量作为 Map 的 value,达到各个线程的局部变量隔离的效果。这种结构会造成 Map 结构过大和内存泄露,因为 Thread 停止后无法通过 key 删除对应的数据
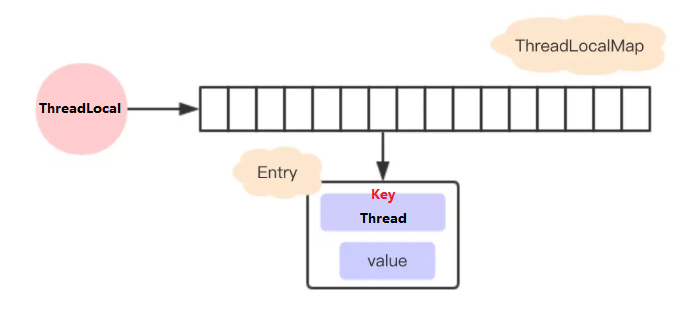
JDK8 以后:每个 Thread 维护一个 ThreadLocalMap,这个 Map 的 key 是 ThreadLocal 实例本身,value 是真正要存储的值
- 每个 Thread 线程内部都有一个 Map (ThreadLocalMap)
- Map 里面存储 ThreadLocal 对象(key)和线程的私有变量(value)
- Thread 内部的 Map 是由 ThreadLocal 维护的,由 ThreadLocal 负责向 map 获取和设置线程的变量值
- 对于不同的线程,每次获取副本值时,别的线程并不能获取到当前线程的副本值,形成副本的隔离,互不干扰

JDK8 前后对比:
- 每个 Map 存储的 Entry 数量会变少,因为之前的存储数量由 Thread 的数量决定,现在由 ThreadLocal 的数量决定,在实际编程当中,往往 ThreadLocal 的数量要少于 Thread 的数量
- 当 Thread 销毁之后,对应的 ThreadLocalMap 也会随之销毁,能减少内存的使用,防止内存泄露
成员变量
-
Thread 类的相关属性:每一个线程持有一个 ThreadLocalMap 对象,存放由 ThreadLocal 和数据组成的 Entry 键值对
ThreadLocal.ThreadLocalMap threadLocals = null -
计算 ThreadLocal 对象的哈希值:
private final int threadLocalHashCode = nextHashCode()使用
threadLocalHashCode & (table.length - 1)计算当前 entry 需要存放的位置 -
每创建一个 ThreadLocal 对象就会使用 nextHashCode 分配一个 hash 值给这个对象:
private static AtomicInteger nextHashCode = new AtomicInteger() -
斐波那契数也叫黄金分割数,hash 的增量就是这个数字,带来的好处是 hash 分布非常均匀:
private static final int HASH_INCREMENT = 0x61c88647
成员方法
方法都是线程安全的,因为 ThreadLocal 属于一个线程的,ThreadLocal 中的方法,逻辑都是获取当前线程维护的 ThreadLocalMap 对象,然后进行数据的增删改查,没有指定初始值的 threadlcoal 对象默认赋值为 null
-
initialValue():返回该线程局部变量的初始值
- 延迟调用的方法,在执行 get 方法时才执行
- 该方法缺省(默认)实现直接返回一个 null
- 如果想要一个初始值,可以重写此方法, 该方法是一个
protected的方法,为了让子类覆盖而设计的
protected T initialValue() { return null; } -
nextHashCode():计算哈希值,ThreadLocal 的散列方式称之为斐波那契散列,每次获取哈希值都会加上 HASH_INCREMENT,这样做可以尽量避免 hash 冲突,让哈希值能均匀的分布在 2 的 n 次方的数组中
private static int nextHashCode() { // 哈希值自增一个 HASH_INCREMENT 数值 return nextHashCode.getAndAdd(HASH_INCREMENT); } -
set():修改当前线程与当前 threadlocal 对象相关联的线程局部变量
public void set(T value) { // 获取当前线程对象 Thread t = Thread.currentThread(); // 获取此线程对象中维护的 ThreadLocalMap 对象 ThreadLocalMap map = getMap(t); // 判断 map 是否存在 if (map != null) // 调用 threadLocalMap.set 方法进行重写或者添加 map.set(this, value); else // map 为空,调用 createMap 进行 ThreadLocalMap 对象的初始化。参数1是当前线程,参数2是局部变量 createMap(t, value); }// 获取当前线程 Thread 对应维护的 ThreadLocalMap ThreadLocalMap getMap(Thread t) { return t.threadLocals; } // 创建当前线程Thread对应维护的ThreadLocalMap void createMap(Thread t, T firstValue) { // 【这里的 this 是调用此方法的 threadLocal】,创建一个新的 Map 并设置第一个数据 t.threadLocals = new ThreadLocalMap(this, firstValue); } -
get():获取当前线程与当前 ThreadLocal 对象相关联的线程局部变量
public T get() { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); // 如果此map存在 if (map != null) { // 以当前的 ThreadLocal 为 key,调用 getEntry 获取对应的存储实体 e ThreadLocalMap.Entry e = map.getEntry(this); // 对 e 进行判空 if (e != null) { // 获取存储实体 e 对应的 value值 T result = (T)e.value; return result; } } /*有两种情况有执行当前代码 第一种情况: map 不存在,表示此线程没有维护的 ThreadLocalMap 对象 第二种情况: map 存在, 但是【没有与当前 ThreadLocal 关联的 entry】,就会设置为默认值 */ // 初始化当前线程与当前 threadLocal 对象相关联的 value return setInitialValue(); }private T setInitialValue() { // 调用initialValue获取初始化的值,此方法可以被子类重写, 如果不重写默认返回 null T value = initialValue(); Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); // 判断 map 是否初始化过 if (map != null) // 存在则调用 map.set 设置此实体 entry,value 是默认的值 map.set(this, value); else // 调用 createMap 进行 ThreadLocalMap 对象的初始化中 createMap(t, value); // 返回线程与当前 threadLocal 关联的局部变量 return value; } -
remove():移除当前线程与当前 threadLocal 对象相关联的线程局部变量
public void remove() { // 获取当前线程对象中维护的 ThreadLocalMap 对象 ThreadLocalMap m = getMap(Thread.currentThread()); if (m != null) // map 存在则调用 map.remove,this时当前ThreadLocal,以this为key删除对应的实体 m.remove(this); }
LocalMap
成员属性
ThreadLocalMap 是 ThreadLocal 的内部类,没有实现 Map 接口,用独立的方式实现了 Map 的功能,其内部 Entry 也是独立实现
// 初始化当前 map 内部散列表数组的初始长度 16
private static final int INITIAL_CAPACITY = 16;
// 存放数据的table,数组长度必须是2的整次幂。
private Entry[] table;
// 数组里面 entrys 的个数,可以用于判断 table 当前使用量是否超过阈值
private int size = 0;
// 进行扩容的阈值,表使用量大于它的时候进行扩容。
private int threshold;
存储结构 Entry:
- Entry 继承 WeakReference,key 是弱引用,目的是将 ThreadLocal 对象的生命周期和线程生命周期解绑
- Entry 限制只能用 ThreadLocal 作为 key,key 为 null (entry.get() == null) 意味着 key 不再被引用,entry 也可以从 table 中清除
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
Entry(ThreadLocal<?> k, Object v) {
// this.referent = referent = key;
super(k);
value = v;
}
}
构造方法:延迟初始化的,线程第一次存储 threadLocal - value 时才会创建 threadLocalMap 对象
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
// 初始化table,创建一个长度为16的Entry数组
table = new Entry[INITIAL_CAPACITY];
// 【寻址算法】计算索引
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
// 创建 entry 对象,存放到指定位置的 slot 中
table[i] = new Entry(firstKey, firstValue);
// 数据总量是 1
size = 1;
// 将阈值设置为 (当前数组长度 * 2)/ 3。
setThreshold(INITIAL_CAPACITY);
}
成员方法
-
set():添加数据,ThreadLocalMap 使用线性探测法来解决哈希冲突
-
该方法会一直探测下一个地址,直到有空的地址后插入,若插入后 Map 数量超过阈值,数组会扩容为原来的 2 倍
假设当前 table 长度为16,计算出来 key 的 hash 值为 14,如果 table[14] 上已经有值,并且其 key 与当前 key 不一致,那么就发生了 hash 冲突,这个时候将 14 加 1 得到 15,取 table[15] 进行判断,如果还是冲突会回到 0,取 table[0],以此类推,直到可以插入,可以把 Entry[] table 看成一个环形数组
-
线性探测法会出现堆积问题,可以采取平方探测法解决
-
在探测过程中 ThreadLocal 会复用 key 为 null 的脏 Entry 对象,并进行垃圾清理,防止出现内存泄漏
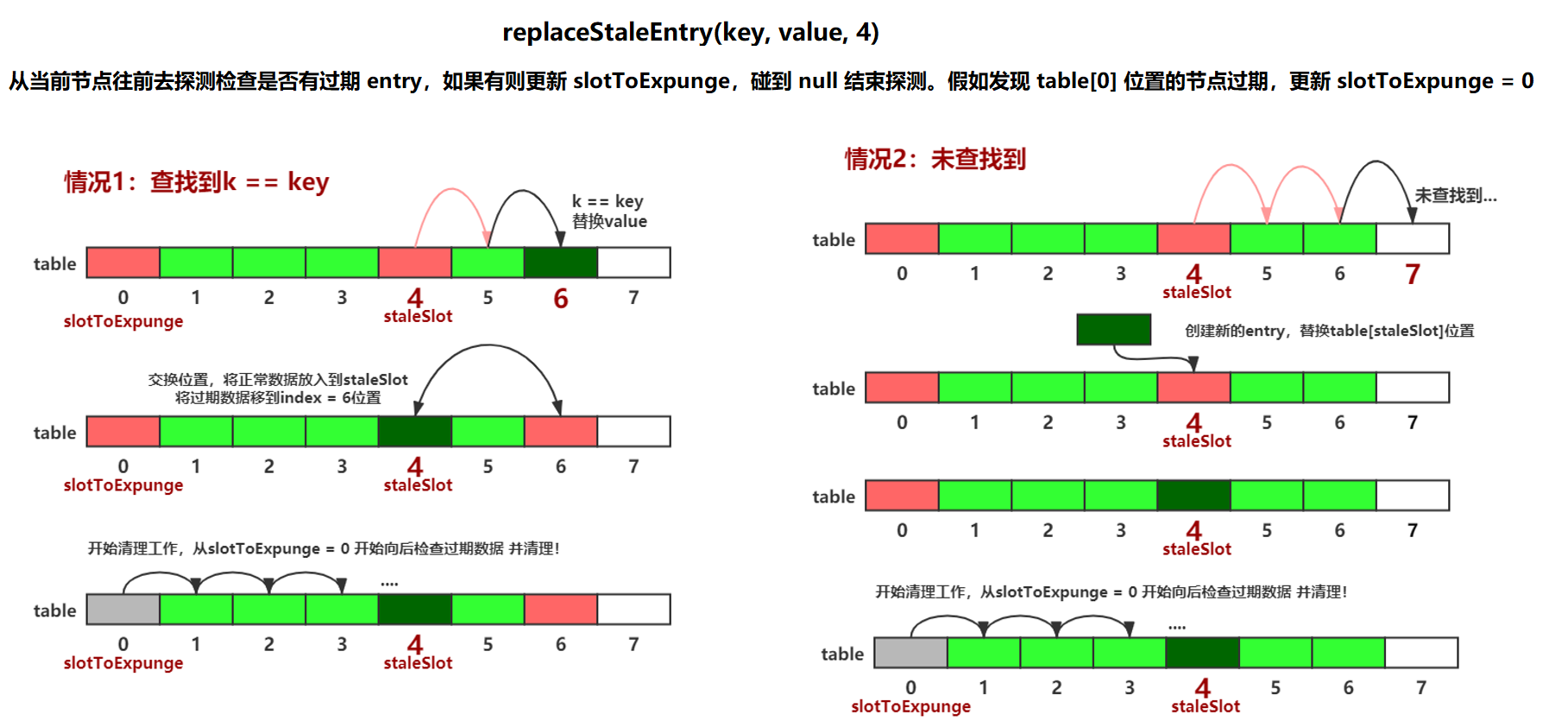
private void set(ThreadLocal<?> key, Object value) { // 获取散列表 ThreadLocal.ThreadLocalMap.Entry[] tab = table; int len = tab.length; // 哈希寻址 int i = key.threadLocalHashCode & (len-1); // 使用线性探测法向后查找元素,碰到 entry 为空时停止探测 for (ThreadLocal.ThreadLocalMap.Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { // 获取当前元素 key ThreadLocal<?> k = e.get(); // ThreadLocal 对应的 key 存在,【直接覆盖之前的值】 if (k == key) { e.value = value; return; } // 【这两个条件谁先成立不一定,所以 replaceStaleEntry 中还需要判断 k == key 的情况】 // key 为 null,但是值不为 null,说明之前的 ThreadLocal 对象已经被回收了,当前是【过期数据】 if (k == null) { // 【碰到一个过期的 slot,当前数据复用该槽位,替换过期数据】 // 这个方法还进行了垃圾清理动作,防止内存泄漏 replaceStaleEntry(key, value, i); return; } } // 逻辑到这说明碰到 slot == null 的位置,则在空元素的位置创建一个新的 Entry tab[i] = new Entry(key, value); // 数量 + 1 int sz = ++size; // 【做一次启发式清理】,如果没有清除任何 entry 并且【当前使用量达到了负载因子所定义,那么进行 rehash if (!cleanSomeSlots(i, sz) && sz >= threshold) // 扩容 rehash(); }// 获取【环形数组】的下一个索引 private static int nextIndex(int i, int len) { // 索引越界后从 0 开始继续获取 return ((i + 1 < len) ? i + 1 : 0); }// 在指定位置插入指定的数据 private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) { // 获取散列表 Entry[] tab = table; int len = tab.length; Entry e; // 探测式清理的开始下标,默认从当前 staleSlot 开始 int slotToExpunge = staleSlot; // 以当前 staleSlot 开始【向前迭代查找】,找到索引靠前过期数据,找到以后替换 slotToExpunge 值 // 【保证在一个区间段内,从最前面的过期数据开始清理】 for (int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex(i, len)) if (e.get() == null) slotToExpunge = i; // 以 staleSlot 【向后去查找】,直到碰到 null 为止,还是线性探测 for (int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { // 获取当前节点的 key ThreadLocal<?> k = e.get(); // 条件成立说明是【替换逻辑】 if (k == key) { e.value = value; // 因为本来要在 staleSlot 索引处插入该数据,现在找到了i索引处的key与数据一致 // 但是 i 位置距离正确的位置更远,因为是向后查找,所以还是要在 staleSlot 位置插入当前 entry // 然后将 table[staleSlot] 这个过期数据放到当前循环到的 table[i] 这个位置, tab[i] = tab[staleSlot]; tab[staleSlot] = e; // 条件成立说明向前查找过期数据并未找到过期的 entry,但 staleSlot 位置已经不是过期数据了,i 位置才是 if (slotToExpunge == staleSlot) slotToExpunge = i; // 【清理过期数据,expungeStaleEntry 探测式清理,cleanSomeSlots 启发式清理】 cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); return; } // 条件成立说明当前遍历的 entry 是一个过期数据,并且该位置前面也没有过期数据 if (k == null && slotToExpunge == staleSlot) // 探测式清理过期数据的开始下标修改为当前循环的 index,因为 staleSlot 会放入要添加的数据 slotToExpunge = i; } // 向后查找过程中并未发现 k == key 的 entry,说明当前是一个【取代过期数据逻辑】 // 删除原有的数据引用,防止内存泄露 tab[staleSlot].value = null; // staleSlot 位置添加数据,【上面的所有逻辑都不会更改 staleSlot 的值】 tab[staleSlot] = new Entry(key, value); // 条件成立说明除了 staleSlot 以外,还发现其它的过期 slot,所以要【开启清理数据的逻辑】 if (slotToExpunge != staleSlot) cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); }private static int prevIndex(int i, int len) { // 形成一个环绕式的访问,头索引越界后置为尾索引 return ((i - 1 >= 0) ? i - 1 : len - 1); } -
-
getEntry():ThreadLocal 的 get 方法以当前的 ThreadLocal 为 key,调用 getEntry 获取对应的存储实体 e
private Entry getEntry(ThreadLocal<?> key) { // 哈希寻址 int i = key.threadLocalHashCode & (table.length - 1); // 访问散列表中指定指定位置的 slot Entry e = table[i]; // 条件成立,说明 slot 有值并且 key 就是要寻找的 key,直接返回 if (e != null && e.get() == key) return e; else // 进行线性探测 return getEntryAfterMiss(key, i, e); } // 线性探测寻址 private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) { // 获取散列表 Entry[] tab = table; int len = tab.length; // 开始遍历,碰到 slot == null 的情况,搜索结束 while (e != null) { // 获取当前 slot 中 entry 对象的 key ThreadLocal<?> k = e.get(); // 条件成立说明找到了,直接返回 if (k == key) return e; if (k == null) // 过期数据,【探测式过期数据回收】 expungeStaleEntry(i); else // 更新 index 继续向后走 i = nextIndex(i, len); // 获取下一个槽位中的 entry e = tab[i]; } // 说明当前区段没有找到相应数据 // 【因为存放数据是线性的向后寻找槽位,都是紧挨着的,不可能越过一个 空槽位 在后面放】,可以减少遍历的次数 return null; } -
rehash():触发一次全量清理,如果数组长度大于等于长度的
2/3 * 3/4 = 1/2,则进行 resizeprivate void rehash() { // 清楚当前散列表内的【所有】过期的数据 expungeStaleEntries(); // threshold = len * 2 / 3,就是 2/3 * (1 - 1/4) if (size >= threshold - threshold / 4) resize(); }private void expungeStaleEntries() { Entry[] tab = table; int len = tab.length; // 【遍历所有的槽位,清理过期数据】 for (int j = 0; j < len; j++) { Entry e = tab[j]; if (e != null && e.get() == null) expungeStaleEntry(j); } }Entry 数组为扩容为原来的 2 倍 ,重新计算 key 的散列值,如果遇到 key 为 null 的情况,会将其 value 也置为 null,帮助 GC
private void resize() { Entry[] oldTab = table; int oldLen = oldTab.length; // 新数组的长度是老数组的二倍 int newLen = oldLen * 2; Entry[] newTab = new Entry[newLen]; // 统计新table中的entry数量 int count = 0; // 遍历老表,进行【数据迁移】 for (int j = 0; j < oldLen; ++j) { // 访问老表的指定位置的 entry Entry e = oldTab[j]; // 条件成立说明老表中该位置有数据,可能是过期数据也可能不是 if (e != null) { ThreadLocal<?> k = e.get(); // 过期数据 if (k == null) { e.value = null; // Help the GC } else { // 非过期数据,在新表中进行哈希寻址 int h = k.threadLocalHashCode & (newLen - 1); // 【线程探测】 while (newTab[h] != null) h = nextIndex(h, newLen); // 将数据存放到新表合适的 slot 中 newTab[h] = e; count++; } } } // 设置下一次触发扩容的指标:threshold = len * 2 / 3; setThreshold(newLen); size = count; // 将扩容后的新表赋值给 threadLocalMap 内部散列表数组引用 table = newTab; } -
remove():删除 Entry
private void remove(ThreadLocal<?> key) { Entry[] tab = table; int len = tab.length; // 哈希寻址 int i = key.threadLocalHashCode & (len-1); for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { // 找到了对应的 key if (e.get() == key) { // 设置 key 为 null e.clear(); // 探测式清理 expungeStaleEntry(i); return; } } }
清理方法
-
探测式清理:沿着开始位置向后探测清理过期数据,沿途中碰到未过期数据则将此数据 rehash 在 table 数组中的定位,重定位后的元素理论上更接近
i = entry.key & (table.length - 1),让数据的排列更紧凑,会优化整个散列表查询性能// table[staleSlot] 是一个过期数据,以这个位置开始继续向后查找过期数据 private int expungeStaleEntry(int staleSlot) { // 获取散列表和数组长度 Entry[] tab = table; int len = tab.length; // help gc,先把当前过期的 entry 置空,在取消对 entry 的引用 tab[staleSlot].value = null; tab[staleSlot] = null; // 数量-1 size--; Entry e; int i; // 从 staleSlot 开始向后遍历,直到碰到 slot == null 结束,【区间内清理过期数据】 for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal<?> k = e.get(); // 当前 entry 是过期数据 if (k == null) { // help gc e.value = null; tab[i] = null; size--; } else { // 当前 entry 不是过期数据的逻辑,【rehash】 // 重新计算当前 entry 对应的 index int h = k.threadLocalHashCode & (len - 1); // 条件成立说明当前 entry 存储时发生过 hash 冲突,向后偏移过了 if (h != i) { // 当前位置置空 tab[i] = null; // 以正确位置 h 开始,向后查找第一个可以存放 entry 的位置 while (tab[h] != null) h = nextIndex(h, len); // 将当前元素放入到【距离正确位置更近的位置,有可能就是正确位置】 tab[h] = e; } } } // 返回 slot = null 的槽位索引,图例是 7,这个索引代表【索引前面的区间已经清理完成垃圾了】 return i; }

-
启发式清理:向后循环扫描过期数据,发现过期数据调用探测式清理方法,如果连续几次的循环都没有发现过期数据,就停止扫描
// i 表示启发式清理工作开始位置,一般是空 slot,n 一般传递的是 table.length private boolean cleanSomeSlots(int i, int n) { // 表示启发式清理工作是否清除了过期数据 boolean removed = false; // 获取当前 map 的散列表引用 Entry[] tab = table; int len = tab.length; do { // 获取下一个索引,因为探测式返回的 slot 为 null i = nextIndex(i, len); Entry e = tab[i]; // 条件成立说明是过期的数据,key 被 gc 了 if (e != null && e.get() == null) { // 【发现过期数据重置 n 为数组的长度】 n = len; // 表示清理过过期数据 removed = true; // 以当前过期的 slot 为开始节点 做一次探测式清理工作 i = expungeStaleEntry(i); } // 假设 table 长度为 16 // 16 >>> 1 ==> 8,8 >>> 1 ==> 4,4 >>> 1 ==> 2,2 >>> 1 ==> 1,1 >>> 1 ==> 0 // 连续经过这么多次循环【没有扫描到过期数据】,就停止循环,扫描到空 slot 不算,因为不是过期数据 } while ((n >>>= 1) != 0); // 返回清除标记 return removed; }
参考视频:https://space.bilibili.com/457326371/
内存泄漏
Memory leak:内存泄漏是指程序中动态分配的堆内存由于某种原因未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果,内存泄漏的堆积终将导致内存溢出
-
如果 key 使用强引用:使用完 ThreadLocal ,threadLocal Ref 被回收,但是 threadLocalMap 的 Entry 强引用了 threadLocal,造成 threadLocal 无法被回收,无法完全避免内存泄漏

-
如果 key 使用弱引用:使用完 ThreadLocal ,threadLocal Ref 被回收,ThreadLocalMap 只持有 ThreadLocal 的弱引用,所以threadlocal 也可以被回收,此时 Entry 中的 key = null。但没有手动删除这个 Entry 或者 CurrentThread 依然运行,依然存在强引用链,value 不会被回收,而这块 value 永远不会被访问到,也会导致 value 内存泄漏

-
两个主要原因:
- 没有手动删除这个 Entry
- CurrentThread 依然运行
根本原因:ThreadLocalMap 是 Thread的一个属性,生命周期跟 Thread 一样长,如果没有手动删除对应 Entry 就会导致内存泄漏
解决方法:使用完 ThreadLocal 中存储的内容后将它 remove 掉就可以
ThreadLocal 内部解决方法:在 ThreadLocalMap 中的 set/getEntry 方法中,通过线性探测法对 key 进行判断,如果 key 为 null(ThreadLocal 为 null)会对 Entry 进行垃圾回收。所以使用弱引用比强引用多一层保障,就算不调用 remove,也有机会进行 GC
变量传递
基本使用
父子线程:创建子线程的线程是父线程,比如实例中的 main 线程就是父线程
ThreadLocal 中存储的是线程的局部变量,如果想实现线程间局部变量传递可以使用 InheritableThreadLocal 类
public static void main(String[] args) {
ThreadLocal<String> threadLocal = new InheritableThreadLocal<>();
threadLocal.set("父线程设置的值");
new Thread(() -> System.out.println("子线程输出:" + threadLocal.get())).start();
}
// 子线程输出:父线程设置的值
实现原理
InheritableThreadLocal 源码:
public class InheritableThreadLocal<T> extends ThreadLocal<T> {
protected T childValue(T parentValue) {
return parentValue;
}
ThreadLocalMap getMap(Thread t) {
return t.inheritableThreadLocals;
}
void createMap(Thread t, T firstValue) {
t.inheritableThreadLocals = new ThreadLocalMap(this, firstValue);
}
}
实现父子线程间的局部变量共享需要追溯到 Thread 对象的构造方法:
private void init(ThreadGroup g, Runnable target, String name, long stackSize, AccessControlContext acc,
// 该参数默认是 true
boolean inheritThreadLocals) {
// ...
Thread parent = currentThread();
// 判断父线程(创建子线程的线程)的 inheritableThreadLocals 属性不为 null
if (inheritThreadLocals && parent.inheritableThreadLocals != null) {
// 复制父线程的 inheritableThreadLocals 属性,实现父子线程局部变量共享
this.inheritableThreadLocals = ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
}
// ..
}
// 【本质上还是创建 ThreadLocalMap,只是把父类中的可继承数据设置进去了】
static ThreadLocalMap createInheritedMap(ThreadLocalMap parentMap) {
return new ThreadLocalMap(parentMap);
}
private ThreadLocalMap(ThreadLocalMap parentMap) {
// 获取父线程的哈希表
Entry[] parentTable = parentMap.table;
int len = parentTable.length;
setThreshold(len);
table = new Entry[len];
// 【逐个复制父线程 ThreadLocalMap 中的数据】
for (int j = 0; j < len; j++) {
Entry e = parentTable[j];
if (e != null) {
ThreadLocal<Object> key = (ThreadLocal<Object>) e.get();
if (key != null) {
// 调用的是 InheritableThreadLocal#childValue(T parentValue)
Object value = key.childValue(e.value);
Entry c = new Entry(key, value);
int h = key.threadLocalHashCode & (len - 1);
// 线性探测
while (table[h] != null)
h = nextIndex(h, len);
table[h] = c;
size++;
}
}
}
}
参考文章:https://blog.csdn.net/feichitianxia/article/details/110495764