参考1,笔记
SVM笔记.pdf
参考2:王木头视频
什么是SVM,如何理解软间隔?什么是合叶损失函数、铰链损失函数?SVM与感知机横向对比,挖掘机器学习本质_哔哩哔哩_bilibili
目录
一、SVM模型
SVM基本模型是一个线性模型,即 
二、构建决策函数
接下来就是构建损失函数,为这个度量赋予意义,对度量值乘上 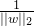
![\frac{1}{||w||_{2}}f_{\theta}^{[G]}(\tilde{X})](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUNmcmFjJTdCMSU3RCU3QiU3QyU3Q3clN0MlN0NfJTdCMiU3RCU3RA%3D%3Df_%7B%5Ctheta%7D%5E%7B%5BG%5D%7D%28%5Ctilde%7BX%7D%29)
![\tilde{Y}f_{\theta}^{[G]}(\tilde{X})\geqslant 0](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUN0aWxkZSU3QlklN0RmXyU3QiU1Q3RoZXRhJTdEJTVFJTdCJTVCRyU1RCU3RCUyOCU1Q3RpbGRlJTdCWCU3RCUyOSU1Q2dlcXNsYW50JTIwMA%3D%3D)
对于 ![\frac{1}{||w||_{2}}f_{\theta}^{[G]}(\tilde{X_{i}})](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUNmcmFjJTdCMSU3RCU3QiU3QyU3Q3clN0MlN0NfJTdCMiU3RCU3RA%3D%3Df_%7B%5Ctheta%7D%5E%7B%5BG%5D%7D%28%5Ctilde%7BX_%7Bi%7D%7D%29)

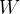
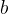
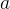

的最小值等于1或-1,这样,距离就变成了
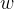
,即目的是最大化
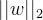
三、Lagrange对偶
上面的损失函数为解决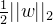
.
即优化问题
注意,这个约束函数看似对于所有的样本都起作用,但这个约束实际上只对约束条件等0的少部分点起作用,因为一部分约束等式等0其他就一定小于0,约束失效。
从Lagrange问题来说,这个为互补松弛性。
原问题的对偶函数为
四、软间隔
对于线性不可分问题,引入软间隔。
相应的优化问题为
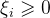
五、合页损失(只有软间隔的情况下才有损失函数)
上面的优化问题为
调换一下顺序为
第一项称为经验损失项,第二项称为正则化项。
六、软间隔下的Lagrange对偶问题
优化问题为
Lagrange对偶问题为
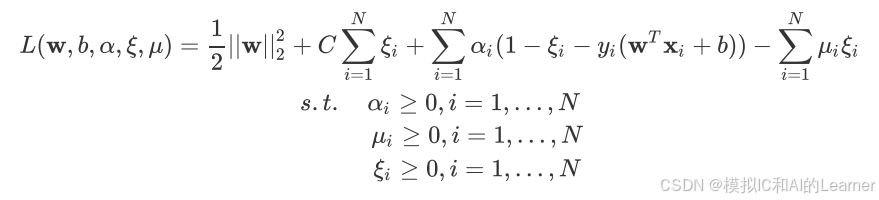




对 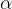
七、核函数相关
略
八、SVM与其他机器学习模型的联系——分析机器学习的本质
1、根本目标
对于二分问题,假设存在一个上帝目标函数 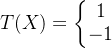
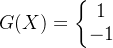
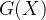
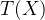
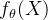
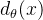
模型函数示例:
线性模型:
非线性模型:
决策函数示例:
线性形式:
核形式:
然后要比较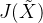
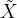
所以机器学习问题就可以分为两部分:
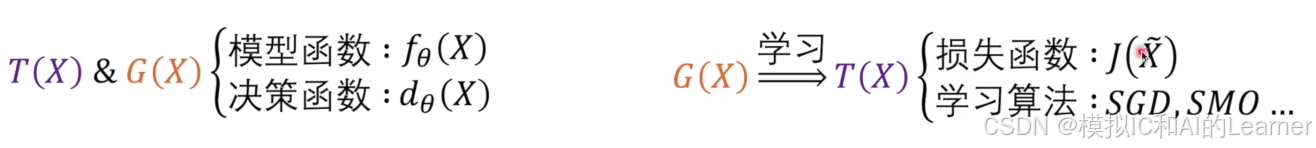
(1)上帝目标函数和学习的目标函数有同样的结构,结构是模型函数和决策函数。
(2)为了让学习的模型函数与上帝函数的模型函数解决,需要损失函数和最优化损失函数的算法。损失函数就是挑选的策略,即挑选两个模型之间差异的策略。
一些资料上说,机器学习分为三部分:模型、策略(损失函数)、算法。
可以说,模型函数是在为数据赋予度量,无论模型是一次的,二次的还是高次的,都相当于通过这个模型函数,为数据空间中的数据提供了一个度量,对在模型函数上的点的度量是0,模型函数曲线相当于一个锚点。即模型函数可以为全空间的数据都赋予一个度量,对模型函数上的数据的度量是0。总结来说,
而损失函数在为度量赋予现实意义:
(1)最小二乘法分类中损失函数为度量赋予意义
在最小二乘法分类的例子中,训练的模型对样本的度量与上帝模型对样本的度量之间有一个服从高斯分布的误差,即
损失函数即度量为
![\left( f_{\theta}^{[G]}(\tilde{X}) - f_{\theta}^{[T]}(\tilde{X}) \right)^2\rightarrow \sigma^2](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUNsZWZ0JTI4JTIwZl8lN0IlNUN0aGV0YSU3RCU1RSU3QiU1QkclNUQlN0QlMjglNUN0aWxkZSU3QlglN0QlMjklMjAtJTIwZl8lN0IlNUN0aGV0YSU3RCU1RSU3QiU1QlQlNUQlN0QlMjglNUN0aWxkZSU3QlglN0QlMjklMjAlNUNyaWdodCUyOSU1RTIlNUNyaWdodGFycm93JTIwJTVDc2lnbWElNUUy)
即为这个度量之间的差异赋予了一个方差的实际意义。
这里还有一个问题,即样本数据在上帝模型函数值 ![f_{\theta}^{[T]}(\tilde{X})](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9mXyU3QiU1Q3RoZXRhJTdEJTVFJTdCJTVCVCU1RCU3RCUyOCU1Q3RpbGRlJTdCWCU3RCUyOQ%3D%3D)
![\left( tanh(f_{\theta}^{[G]}(\tilde{X})) - f_{\theta}^{[T]}(\tilde{X}) \right)^2\rightarrow \sigma^2](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUNsZWZ0JTI4JTIwdGFuaCUyOGZfJTdCJTVDdGhldGElN0QlNUUlN0IlNUJHJTVEJTdEJTI4JTVDdGlsZGUlN0JYJTdEJTI5JTI5JTIwLSUyMGZfJTdCJTVDdGhldGElN0QlNUUlN0IlNUJUJTVEJTdEJTI4JTVDdGlsZGUlN0JYJTdEJTI5JTIwJTVDcmlnaHQlMjklNUUyJTVDcmlnaHRhcnJvdyUyMCU1Q3NpZ21hJTVFMg%3D%3D)
双曲正切处理过后其实这个 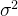
总结一下:最小二乘分类是通过模型函数对样本数据进行度量,然后再对度量之间的差异进行一些修饰,修饰之后,变成了方差,默认方差最小时,![f_{\theta}^{[G]}(\tilde{X}) = f_{\theta}^{[T]}(\tilde{X})](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9mXyU3QiU1Q3RoZXRhJTdEJTVFJTdCJTVCRyU1RCU3RCUyOCU1Q3RpbGRlJTdCWCU3RCUyOSUyMCUzRCUyMGZfJTdCJTVDdGhldGElN0QlNUUlN0IlNUJUJTVEJTdEJTI4JTVDdGlsZGUlN0JYJTdEJTI5)
![f_{\theta}^{[G]}(X) = f_{\theta}^{[T]}(X)](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9mXyU3QiU1Q3RoZXRhJTdEJTVFJTdCJTVCRyU1RCU3RCUyOFglMjklMjAlM0QlMjBmXyU3QiU1Q3RoZXRhJTdEJTVFJTdCJTVCVCU1RCU3RCUyOFglMjk%3D)
(2)最大似然估计法
对度量通过sigmoid进行修饰,修饰的结果为概率值,这个概率值在于标签(上帝模型函数值),进行比较,求差异,这里的差异是似然值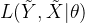
(3)SVM
对度量进行修饰,这里的修饰是乘上