一.第一章 欢迎来到transformer的世界
1.解码器-编码器框架
在Transformer出现之前,NLP的最新技术是LSTM等循环架构。这些架 构通过在神经网络连接使用反馈循环,允许信息从一步传播到另一 步,使其成为对文本等序列数据进行建模的理想选择。如RNN接收一些输入(可以是单词或字符),将其馈送给神经网络, 然后输出一个称为隐藏状态的向量。同时,模型通过反馈循环将信息 反馈给自身,然后在下一步中使用。
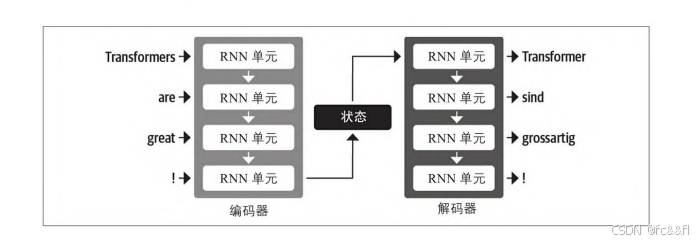
RNN发挥重要作用的一个领域是机器翻译系统,其目标是将一种语言中 的单词序列映射到另一种语言。此类任务通常使用编码器-解码器或序 列到序列架构 来解决,这些架构非常适合输入和输出都是任意长度 序列的情况。编码器将输入序列的信息编码为通常称为最后隐藏状态 的数字表示。然后编码器将该状态传给解码器,解码器生成输出序 列。
通常,编码器和解码器组件可以是能够对序列进行建模的任何类型的 神经网络架构。但这种架构的一个弱点是编码器的最终隐藏状态会产 生信息瓶颈:它必须表示整个输入序列的含义,因为解码器在生成输 出时只能靠它来读取全部内容。从而很难处理长序列,因为当序列过 长时,在将所有内容压缩为单个固定表示的过程中可能会丢失序列开 头的信息。
幸运的是,有一种方法可以摆脱这一瓶颈,就是允许解码器访问编码 器的所有隐藏状态。这种通用机制称为注意力 。它是许多现代神经 网络架构中的关键组件。了解整合了注意力机制的RNN能够帮助我们更 好地理解Transformer架构。
2.注意力机制
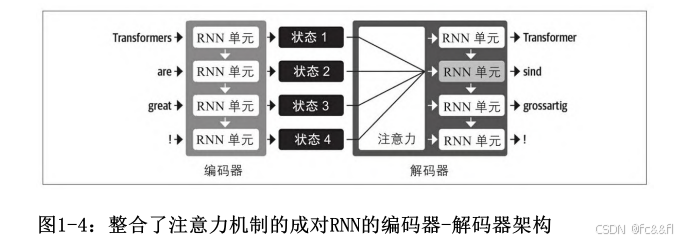
注意力机制的主要思想是,编码器不再像图1-3那样对整个输入序列只 生成一个状态了,而是为每个表示都生成一个状态,即解码器可以访 问编码器所有隐藏状态。但是,同时处理所有状态会给解码器带来巨 大的输入数量,因此需要一些机制来按优先级使用状态。这就是注意 力的用武之地:它让解码器在每个解码时间步为每个编码器状态分配 不同量的权重或“注意力”。
下面是引入注意力机制之前编码器-解码器结构之间的对比
尽管注意力机制能够带来更好的翻译,但在编码器和解码器中使用循 环神经网络模型仍然存在一个重大缺点:计算本质上是顺序的,不能 跨输入序列并行化。
Transformer引入了一种新的建模范式:完全放弃循环,改为使用一种 特殊形式的注意力——自注意力:允许注意力对神经网络同一层 中的所有状态进行操作。如图1-6所示,其中编码器和解码器都有自己 的自注意力机制,其输出被馈送到前馈神经网络(FF NN)。这种架 构的训练速度比循环神经网络模型快得多,从而为NLP许多最新突破铺 平了道路。

3.NLP的迁移学习
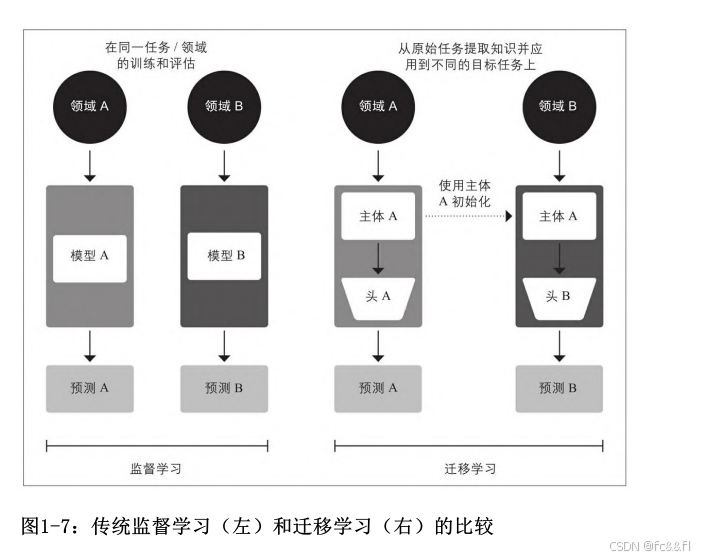
如今,计算机视觉的常见做法是使用迁移学习,即在一项任务上训练 像ResNet这样的卷积神经网络,然后在新任务上对其进行适配或微 调。迁移学习允许网络利用从原始任务中学到的知识。在架构上,这 是指将模型拆分为主体和头,其中头是指针对任务的网络。在训练期 间,主体学习来源于领域的广泛特征,并将学习到的权重用于初始化 新任务的新模型 。与传统的监督学习相比,这种方法通常会产生高 质量的模型,这些模型在各种下游任务中效果更佳,并且使用的标注 数据更少。
在计算机视觉中,模型首先在包含数百万张图像的ImageNet (https://image-net.org)等大规模数据集上进行训练。这个过程称 为预训练,其主要目的是向模型传授图像的基本特征,例如边或颜 色。然后,这些预训练模型可以在下游任务上进行微调,例如使用相 对较少的标注示例(通常每个类几百个)对花种进行分类。微调模型 通常比在相同数量的标注数据上从头开始训练的监督模型具有更高的 准确率。 尽管迁移学习成为计算机视觉的标准方法,但多年来,人们并不清楚 NLP的类似预训练过程是怎么样的。从而导致NLP应用程序通常需要大 量的标注数据才能实现高性能。即便如此,这种性能也无法与视觉领 域的成就相提并论。
紧随其后的是ULMFiT,它使用预训练LSTM模型构建了一个 可以适用于各种任务的通用框架 。 如图1-8所示,ULMFiT包括以下三个主要步骤:
预训练
对于世界上大多数语言,获得大量数字化文本语料库可能很困难,英 语更是如此。寻找解决这一问题的方法是NLP研究方向的一个活跃领 域。 最初的训练目标非常简单:根据前面的单词预测下一个单词。这类任 务称为语言建模,所生成的模型称为语言模型。这种方法的优雅之处 在于不需要标注数据,并且可以使用来自Wikipedia等来源的大量可用 文本 。
领域适配
在大规模语料库上进行预训练得出语言模型之后,下一步就是将其适 配于业务领域语料库(例如,从Wikipedia迁移到电影评论的IMDb语料 库,如图1-8所示)。这一阶段仍然使用语言建模方法,但现在模型必 须预测目标语料库中的下一个单词。
微调
这一步使用目标任务的分类层对语言模型进行微调(例如,对图1-8中 的电影评论的情感进行分类)
通过引入一个可行的NLP预训练和迁移学习框架,ULMFiT填补了令 Transformer起飞的缺失部分。2018年,发布了两类将自注意力与迁移 学习相结合的Transformer模型:
1)GPT
仅使用Transformer架构的解码器部分,以及与ULMFiT相同的语言建模 方法。GPT在BookCorpus1上进行预训练,该语料库由7000本来自冒 险、幻想和浪漫等各种流派的图书组成。
2)BERT
仅使用Transformer架构的编码器部分,以及一种称为掩码语言建模的 特殊形式的语言建模。掩码语言建模的目的是预测文本中随机掩码的 单词。如,给定一个句子,如 “I looked at my[MASK]and saw that[MASK]was late.”,该 模型需要预测[MASK]所掩码的单词最有可能的候选者。BERT在 BookCorpus和英语Wikipedia上进行预训练。
但是由于各个研究实验室在不同的框架(PyTorch或TensorFlow)上发 布模型,而这些模型无法兼容于其他框架,NLP从业者将这些模型移植 到他们自己的应用程序中经常会遇到困难。于是 Hugging FaceTransformers库(https://oreil.ly/Z79jF)这个能够 跨50多个架构的统一API应运而生。该库催化了Transformer研究的爆 炸式增长,并迅速渗透到NLP从业者中,从而可以轻松地将 Transformer模型集成到当今的许多实际应用中。

4.Hugging Face Transformers库:提供规范化接口
将新颖的机器学习架构应用于新任务可能是一项复杂的任务,通常涉 及以下步骤:
1.将模型架构付诸代码实现(通常基于PyTorch或TensorFlow)。
2.从服务器加载预训练权重(如果有的话)。
3.预处理输入并传给模型,然后应用一些针对具体任务的后处理。
4.实现数据加载器并定义损失函数和优化器来训练模型。
5.Transformer应用概览
5.1文本分类
在本章中,我 们将从pipeline开始,pipeline把将原始文本转换为微调模型的一组 预测所需的所有步骤都抽象出来。 我们可以通过调用Hugging Face Transformers库的pipeline()函数 并提供我们感兴趣的任务名称来实例化pipeline:
本例的预测结果是模型非常确信输入文本具有正面情感
5.2命名实体识别
现在我们能够预测客户反馈的情感,但你经常还想知道反馈是否与特 定项目或服务有关。在NLP中,产品、地点和人等现实世界的对象称为 命名实体,从文本中提取它们称为命名实体识别(NER)。我们可以通 过加载以下pipeline并将我们的客户评论提供给它来应用NER:
你可以看到pipeline检测出所有实体,并且还为每个实体分配了一个 类别,例如ORG(组织)、LOC(位置)或PER(人)。在这里,我们使 用aggregation strategy参数根据模型的预测对单词进行分组。例 如,实体“Optimus Prime”由两个单词组成,但被分配到一个类 别:MISC(杂项)。score列告诉我们模型对其识别的实体的信心(概 率)。我们可以看到,它对“Decepticons”和第一个“Megatron”最 没有信心(概率最低),两者都未能作为一个实体分在同一组。
看到上表word列中那些奇怪的哈希符号(#)了吗?这些符号是模型的 词元分析器生成的,词元分析器将单词划分成称为词元的原子单元。 我们将在第2章讲述词元分析器的详细信息。
现在我们已经把文本中的所有命名实体提取出来了,但有时我们想问 更有针对性的问题。于是我们就需要问答pipeline。
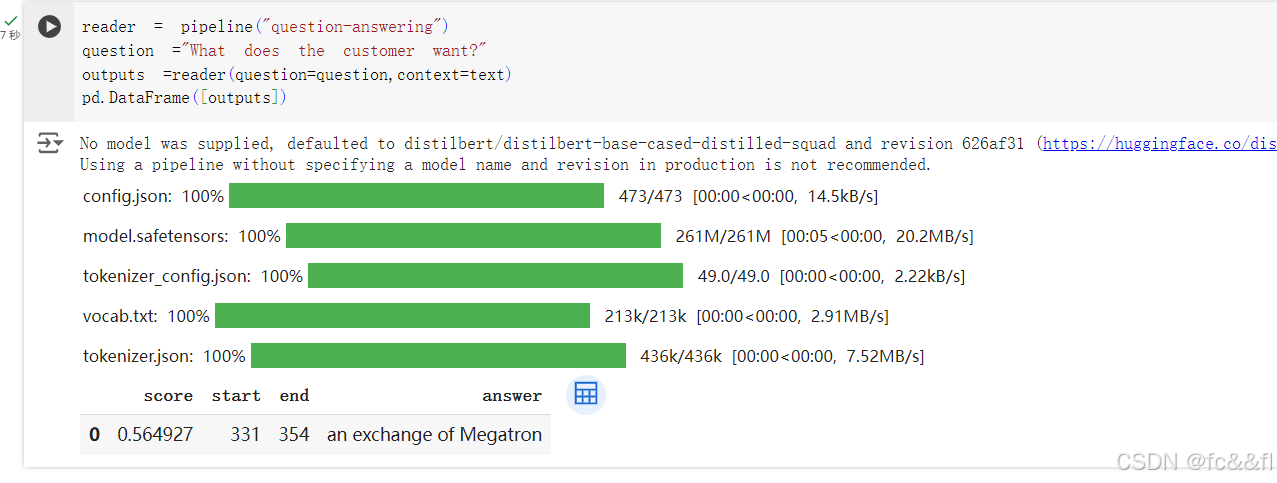
5.3问答
我们通过下面的context参数把问答的上下文(即本节开头提到的文 本)提供给模型,通过question参数把问题提供给模型。模型将返回 回答。现在我们看看当询问客户反馈的相关问题时,会得到什么回 答:
我们可以看到,除了回答之外,pipeline还返回回答在上下文中的位 置,即start和end(就像NER标注一样)。我们将在第7章研究好几种 类型的问答,但本节这种特殊的类型称为提取式问答,因为答案是直 接从文本提取出来的。
5.4 文本摘要
文本摘要的目标是输入一段长文本,然后生成包含所有相关事实的简 短版本。这是一项比前面所讲任务复杂得多的任务,因为它需要模型 生成连贯的文本。我们通过以下熟悉的模式实例化文本摘要:
得出的摘要还不错!尽管其只是简单地复制粘贴部分原始文本,但该 模型能够捕捉到问题的根源,并正确识别“Bumblebee”(出现在输入 文本的末尾)是投诉者。
5.5 文本翻译
我们看到,模型同样生成了一个非常好的翻译,正确使用了德语的代 词,如“Ihrem”和“Sie”。在以上示例代码中,我们还展示了如何 通过model参数指定模型来替换默认模型,从而可以为你的应用程序选 择最佳模型,你可以在Hugging Face Hub上找到数千种语言对模 型。接下来我们看看最后一个应用,然后再开始介绍Hugging Face生 态系统。
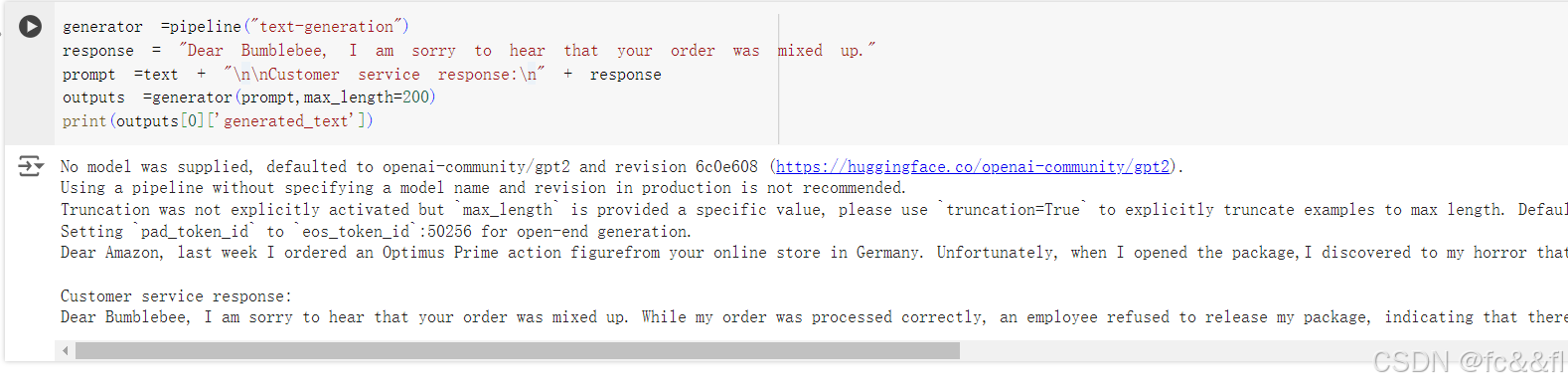
假设你希望通过自动完成功能来撰写答复,从而更快地回复客户。你 可以按如下方式使用text-generation pipeline:
现在我们已经讲述了Transformer模型一些很酷的应用,你可能想知道 训练在哪里进行。我们在本章使用的所有模型都是公开可用的,并且 已经针对以上任务微调过了。一般来说,无论如何,你都会想根据自 己的数据微调模型,在后面的章节中,你将学习如何做到这一点。 但是,训练模型只是任何NLP项目的一小部分——能够有效地处理数 据、与同事共享结果,以及使你的工作可重复也是项目的关键组成部 分。幸运的是,围绕着Hugging Face Transformers库有一个由一整 套工具组成的大型生态系统,从而可以支持大部分现代机器学习工作 流程。我们一起看看这个生态系统吧。
5.6 Hugging Face生态系统
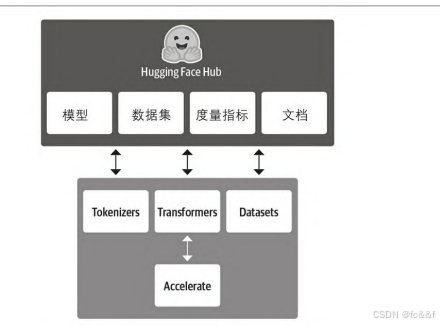
以Hugging Face Transformers库为基础,Hugging Face已经迅速 发展成一个完整的生态系统,它由许多库和工具组成,以加速你的NLP 和机器学习项目。Hugging Face生态系统主要由一系列库和Hub组 成,如图1-9所示。库提供相关代码,而Hub提供预训练的模型权重、 数据集、度量指标脚本等。
除了预训练模型之外,Hub还托管了用于度量指标的数据集和脚本,使 你可以重现已发布的结果或为应用程序利用其他数据。
Hub还提供Models(模型)和Datasets(数据集)卡片,用于记录模型 和数据集相关内容,以帮助你就它们是否适合你做出明智的决定。Hub 最酷的功能之一是,你可以直接通过各种特定于任务的交互式小部件 试用任何模型,如图1-11所示。
Hugging Face Tokenizers库
我们在本章看到的每个pipeline示例背后都有一个词元化 (tokenization)步骤,该步骤将原始文本拆分为称为词元的更小部 分。我们将在第2章详细介绍这个过程,但现在只需要知道词元可以是 单词、单词的一部分或只是标点符号等字符就足够了。Transformer模 型是在这些词元的数字表示上训练的,因此正确执行这一步对于整个 NLP项目非常重要!
Hugging Face Datasets库
Hugging Face Datasets库(https://oreil.ly/959YT)通过为可在 Hub(https://oreil.ly/Rdhcu)上找到的数千个数据集提供标准界面 来简化这个过程。它还提供智能缓存(因此你不需要每次运行代码时 都重复预处理工作),并通过利用称为内存映射的特殊机制来突破内 存限制,该机制将文件的内容存储到虚拟内存中,并使多个进程能够 更有效地修改文件。该库还可以与Pandas和NumPy等流行框架进行互操 作,因此你不必离开自己喜欢的数据整理工具。
Hugging Face Accelerate库
如果你曾经不得不用PyTorch编写自己的训练脚本,那么在尝试将笔记 本电脑上运行的代码移植到组织集群上运行的代码时,你可能会遇到 一些麻烦。Hugging Face Accelerate库 (https://oreil.ly/iRfDe)为常规训练操作增加了一个抽象层以负 责训练基础设施所需的所有逻辑。这可以通过在必要时简化基础架构 的更改来加速工作流。
Transformer的主要挑战
语言
NLP研究以英语为主。有一些支持其他语言的模型,但很难找到稀有或 资源少的语言的预训练模型。我们将在第4章探讨多语言Transformer 及其执行零样本学习跨语言迁移的能力。
数据可用性
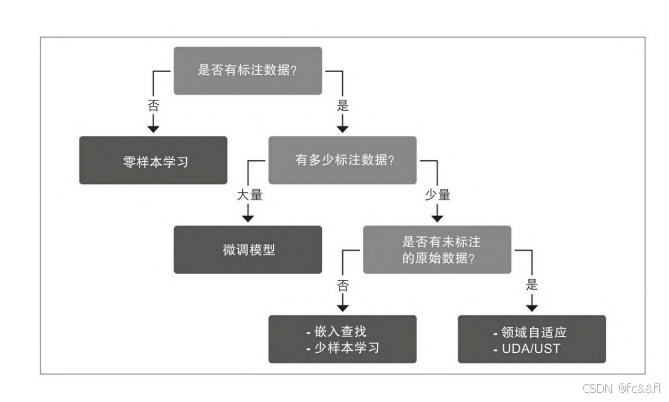
尽管我们可以通过迁移学习来显著减少模型所需的标注训练数据量, 但与人类执行任务所需的量相比,依然差很多。我们将在第9章探讨如 何处理几乎没有标注数据可用的场景。
处理长文本
自注意力在段落长度的文本上效果非常好,但是在处理整个文档这样 长度的文本时,将变得非常昂贵。第11章将讨论缓解这种情况的方 法。
不透明度
与其他深度学习模型一样,Transformer在很大程度上是不透明的。人 们很难或不可能解开模型做出某种预测的“原因”。当需要通过这些 模型来做出关键决策时,这是一个特别艰巨的挑战。我们将在第2章和 第4章探讨一些探测Transformer模型误差的方法。


二.第二章,文本分类
现在想象一下,你是一名数据科学家,需要构建一个系统,可以自动 识别人们在Twitter上对你公司产品表达的情感状态,例如愤怒或喜 悦。在本章中,我们将使用一种名为DistilBERT 的BERT变体来解决 这个任务。该模型的主要优点是,在实现与BERT相当的性能的同时, 体积更小、效率更高。这使我们能够在几分钟内训练一个分类器,如 果你想训练一个更大的BERT模型,则只需更改预训练模型的 checkpoint。checkpoint对应于加载到给定Transformer架构中的权重 集。

1.数据集
为了构建我们的情感检测器,我们将使用一篇论文 中提供的数据 集,该论文探讨了英语推文所表示的情感。与大多数情感分析数据集 只涉及“正面”和“负面”这两种极性不同的是,这个数据集包含六 种基本情感:anger(愤怒)、disgust(厌恶)、fear(恐惧)、joy (喜悦)、sadness(悲伤)和surprise(惊讶)。我们的任务是训练 一个模型,将给定推文按其中一种情感进行分类。
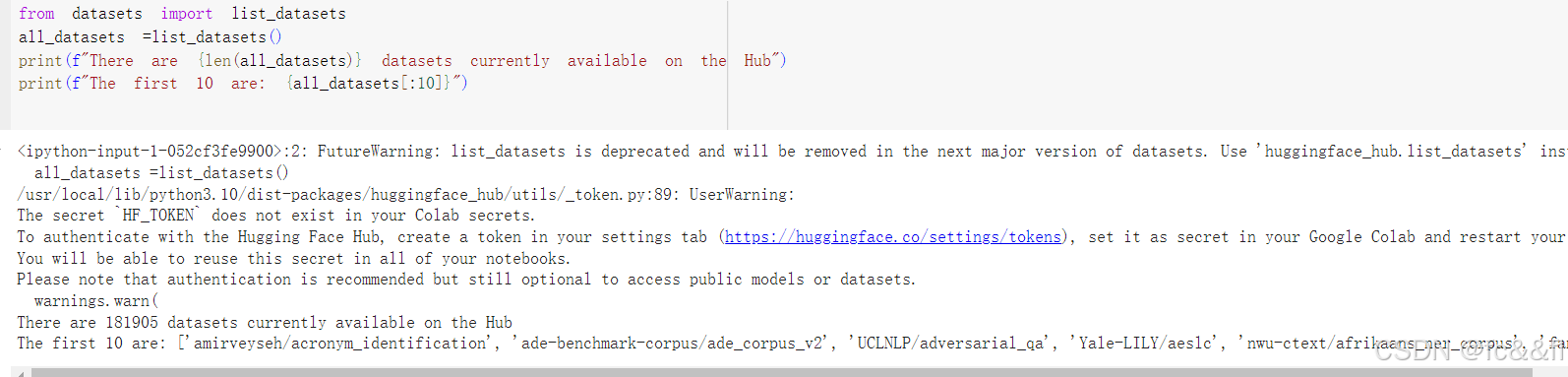
我们将使用Hugging Face Datasets库从Hugging Face Hub (https://oreil.ly/959YT)下载数据。我们可以使用 list_datasets()函数查看Hub上有哪些可用数据集。
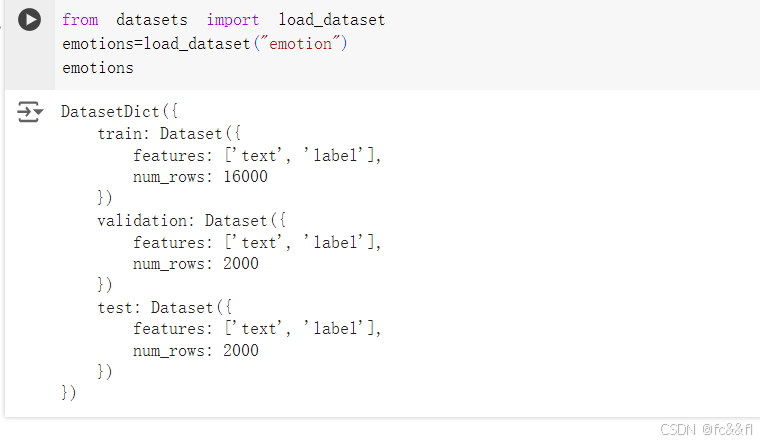
我们可以看到每个数据集都有一个名称,因此让我们使用 load_dataset()函数加载情感数据集:
我们可以看到它类似于Python字典,每个键对应不同的数据集分割
以上代码返回一个Dataset类的实例。Dataset对象是 Hugging Face Datasets库的核心数据结构之一,在本书中我们将探 索它的许多特性。
在本例中,text列的数据类型为字符串,而label列是一个特殊的 ClassLabel对象,它包含有关类名称及其映射到整数的信息。
如果我的数据集不在Hub上那该怎么办? 在本书的大部分示例中,我们将使用Hugging Face Hub库下载数据 集。但在许多情况下,你会发现自己处理的数据要么存储在你的笔记 本电脑上,要么存储在你的组织的远程服务器上。Datasets提供了多 个加载脚本来处理本地和远程数据集。最常见数据格式的示例参见表 2-1。
data_files参数可以为文件路径或者url
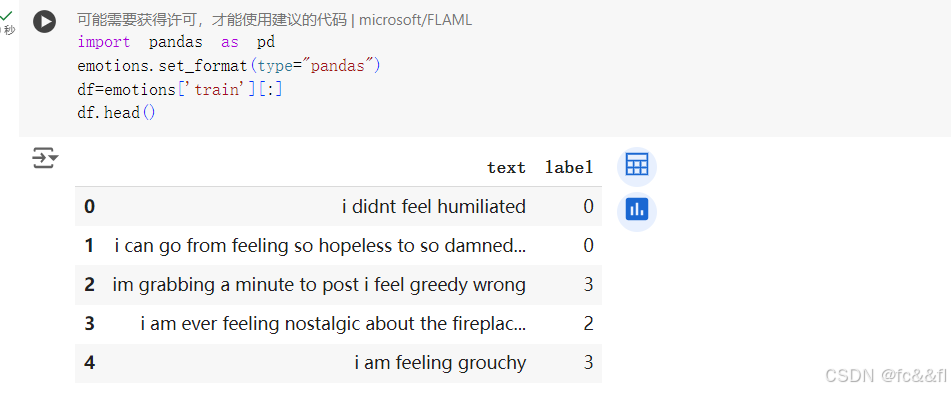
从Datasets到DataFrame
尽管Hugging Face Datasets库提供了许多底层的功能供我们切分和 处理数据,但我们通常将Dataset对象转换为Pandas DataFrame,这 样我们就可以使用高级API来进行可视化,这样做将非常方便。 Hugging Face Datasets库提供了set_format()方法,该方法允许我 们更改数据集的输出格式以进行转换。请注意,它不会改变底层的数 据格式(Arrow表),并且你可以随时切换到另一种格式。
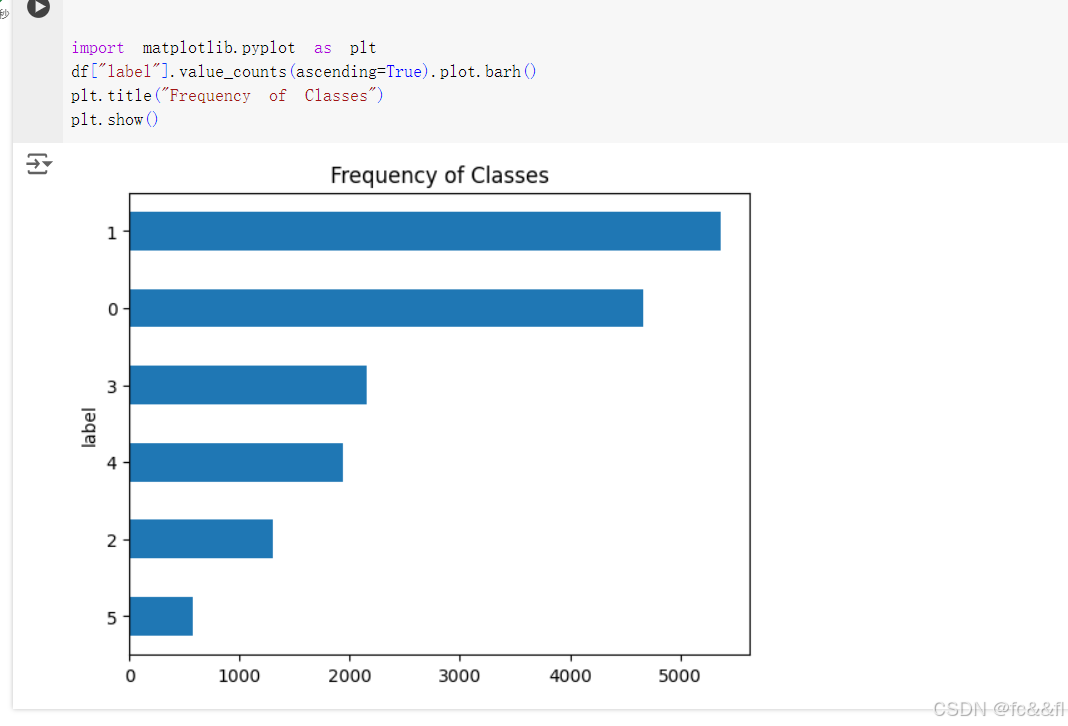
查看类分布
对于处理文本分类问题,检查类的样本分布无论何时都是一个好主 意。相对于类平衡的数据集来说,一个类分布不平衡的数据集可能需 要在训练损失和度量指标方面采取不同的处理方法。 我们可以使用Pandas和Matplotlib快速地可视化类分布:
我们可以看到数据集严重不平衡;joy和sadness类频繁出现,大约是 love和surprise类的5~10倍。处理不平衡数据的方法包括: ●随机对少数类进行过采样(oversample)。 ●随机对多数类进行欠采样(undersample)。 ●收集更多来自未被充分表示的类的标注数据。 为了保持本章简单,我们不使用以上的任何方法,而将使用原始的、 不平衡的类。如果你想了解更多关于这些采样技术的内容,我们建议 你查看Imbalanced-learn库(https://oreil.ly/5XBhb)。需要注意 的是,在将数据集分割成训练/测试集之前不要应用采样方法,否则会 在两者之间造成大量泄漏!
2.将文本转换成词元
像DistilBERT这样的Transformer模型不能接收原始字符串作为输入。 它假定文本已经被词元化并编码为数字向量。词元化 (tokenization)是指将字符串分解为给模型使用的原子单元的步 骤。词元化的策略有好几种,具体哪种最佳通常需要从语料库中学 习。在讨论DistilBERT使用的Tokenizer之前,我们先讨论两种极端情 况:字符词元化和单词词元化。
1)字符词元化 最简单的词元化方案是按每个字符单独馈送到模型中。在Python中, str对象实际上是一组数据,这使我们可以用一行代码快速实现字符词 元化:
这是一个很好的开始,但我们还没有完成任务。我们的模型希望把每 个字符转换为一个整数,有时这个过程被称为数值化 (numericalization)。一个简单的方法是用一个唯一的整数来编码 每个唯一的词元(在这里为字符):
我们可以看到,我们得到了一个包括了每个字符到一个唯一性整数的 映射,即词元分析器的词表。我们现在可以使用token2idx将词元化的 文本转换成一个整数列表:
现在,每个词元都已映射到唯一的数字标识符(因此称为 input_ids)。最后一步是将input_ids转换为独热向量(onehot vector)的二维张量。在机器学习中,独热向量常常用于编码分 类数据(包括有序和无序数据)。
我们可以为每个类别创建一个新列,在 该类别为true时分配1,否则分配0。在Pandas中,可以使用 get_dummies()函数实现这点:
以上DataFrame中的每行是一个独热向量,一整行只有一个1,其他都 是0。现在,看看我们的input_ids,我们有类似的问题:这些元素的 取值之间引入了虚假的顺序关系。因为这个关系是虚假的,所以对两 个ID进行加减是一个没意义的操作。 如果我们将input_ids改成独热编码,结果就很容易解释:“热”的两 个条目表明是相同的两个词元。在PyTorch中,我们可以使用 one_hot()函数对input_ids进行独热编码:
本例共有38个输入词元,我们得到了一个20维的独热向量,因为我们 的词表包含了20个唯一字符。
2)单词词元化
与字符词元化相比,单词词元化将文本细分为单词,并将每个单词映 射到一个整数。单词词元化使模型跳过从字符学习单词的步骤,从而 降低训练过程的复杂性。
词表太大是一个问题,因为它导致了神经网络需要大量的参数。举例 来说,假设词表中有100万个唯一词项,并按照大多数NLP架构中的标 准步骤将100万维输入向量压缩到第一层神经网络中的1000维向量。这 样就导致了第一层的权重矩阵将包含100万×1千=10亿个权重。这已经 可以与最大的GPT-2模型 看齐了,该模型总计拥有大约15亿个参数!
3)子词词元化(既可 以保留输入信息又能保留文本结构)
子词词元化背后的基本思想是将字符和单词词元化的优点结合起来。 一方面,我们希望将生僻单词拆分成更小的单元,以使模型能够处理 复杂单词和拼写错误。另一方面,我们希望将常见单词作为唯一实体 保留下来,以便我们将输入长度保持在可管理的范围内。子词词元化 (以及单词词元化)是使用统计规则和算法从预训练语料库中学习 的。
在NLP中常用的子词词元化算法有几种,我们先从WordPiece 算法开 始,这是BERT和DistilBERT词元分析器使用的算法。了解WordPiece如 何工作最简单的方法是看它的运行过程。 Hugging Face Transformers库提供了一个很方便的AutoTokenizer 类,它能令你快速加载与预训练模型相关联的词元分析器——只需要 提供模型在Hub上的ID或本地文件路径,然后调用它的 from_pretrained()方法即可。我们先加载DistilBERT的词元分析器:
from transformers import AutoTokenizer model_ckpt="distilbert-base-uncased" tokenizer = AutoTokenizer.from_pretrained(model_ckpt)AutoTokenizer类是“auto”类的一种(https://oreil.ly/h4YPz), 其任务是根据checkpoint的名称自动检索模型的配置、预训练权重或 词表。使用以上代码的优点是可以快速切换模型,但是你也可以手动 加载特定类。
和字符词元化一样,我们可以看到,单词映射成input_ids字段中的唯 一整数。
中的唯 一整数。我们将在2.2.4节中讨论attention mask字段的作用。现在 我们有了input_ids,我们可以通过使用词元分析器的 convert_ids_to_tokens()方法将它们转换回词元:
我们可以观察到三件事情。首先,序列的开头和末尾多了一些特殊的 词元:[CLS]和[SEP]。这些词元具体因模型而异,它们的主要作用是 指示序列的开始和结束。其次,词元都小写了,这是该checkpoint的 特性。最后,我们可以看到tokenizing和NLP都被拆分为两个词元,这 是有道理的,因为它们不是常用的单词。##前缀中的##izing和##p意 味着前面的字符串不是空白符,将带有这个前缀的词元转换回字符串 时,应当将其与前一个词元合并。AutoTokenizer类有一个 convert_tokens_to_string()方法可以做到这一点,所以让我们将它 应用到我们的词元:
对整个数据集进行词元化
我们将使用DatasetDict对象的map()方法来对整个语料库进行词元 化。
1)将我们的样本进行词元化的处理函 数:
这个函数将词元分析器应用于一个批量样本。padding=True表示以零 填充样本,以达到批量中最长样本的长度,truncation=True表示将样 本截断为模型的最大上下文大小。
此外,除了将编码后的推文返回为input_ids外,词元分析器还返回一 系列attention_mask数组。这是因为我们不希望模型被额外的填充词 元所困惑:注意力掩码(attention mask)允许模型忽略输入的填充 部分。图












3.训练文本分类器
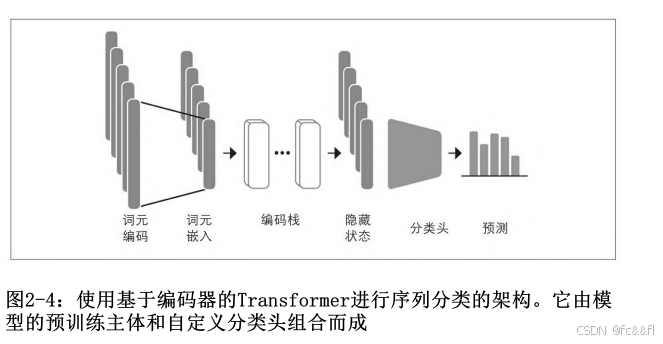
如第1章所述,像DistilBERT这样的模型被预训练用于预测文本序列中 的掩码单词。然而,这些语言模型不能直接用于文本分类,我们需要 稍微修改它们。为了理解需要做哪些修改,我们来看一下基于编码器 的模型(如DistilBERT)的架构,如图2-4所示。
在DistilBERT的情况下,它在猜测掩码词元。
首先,文本会被词元化并表示为称为词元编码的独热向量。词元编码 的维度由词元分析器词表的大小决定,通常包括两万到二十万个唯一 性词元。接下来,这些词元编码会被转换为词元嵌入,即存在于低维 空间中的向量。然后,这些词元嵌入会通过编码器块层传递,以产生 每个输入词元的隐藏状态。对于语言建模的预训练目标 ,每个隐藏 状态都被馈送到一个层,该层预测掩码输入词元。对于分类任务,我 们将语言建模层替换为分类层。
实际上,PyTorch在实现中跳过了为词元编码创建独热向量的步骤,因 为将矩阵与独热向量相乘等同于从矩阵中选择一列。这可以通过直接 从矩阵中获取词元ID对应的列来完成。当我们使用nn.Embedding类 时,我们将在第3章中看到这一点。
我们有以下两种选择来基于Twitter数据集进行模型训练:
特征提取
我们将隐藏状态用作特征,只需训练分类器,而无须修改预训练模 型。
微调
我们对整个模型进行端到端的训练,这样还会更新预训练模型的参 数。 接下来我们将讲述基于DistilBERT的以上两种选择,以及这两种选择 的权衡取舍。
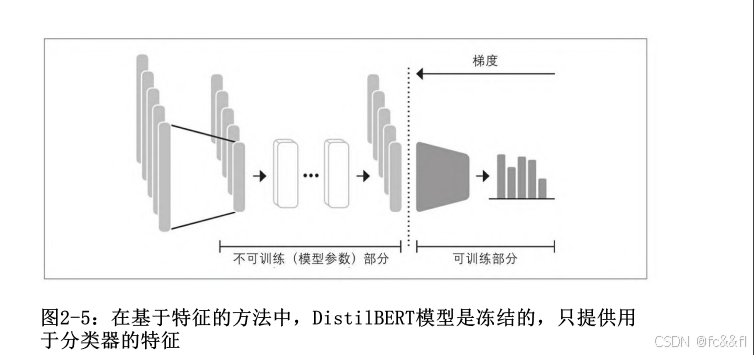
使用Transformer作为特征提取器
使用Transformer作为特征提取器相当简单。如图2-5所示,我们在训 练期间冻结主体的权重,并将隐藏状态用作分类器的特征。这种方法 的优点是,我们可以快速训练一个小型或浅层模型。这样的模型可以 是神经分类层或不依赖于梯度的方法,例如随机森林。这种方法特别 适用于没有GPU的场景,因为隐藏状态只需要预计算一次。
加载预训练模型
我们将使用Hugging Face Transformers库中另一个很方便的自动类 AutoModel。与AutoTokenizer类似,AutoModel具有 from_pretrained()方法,可用于加载预训练模型的权重。现在我们使 用该方法来加载DistilBERT checkpoint:

这里我们使用PyTorch来检查GPU是否可用(即代码 torch.cuda.is available()),然后将PyTorch的nn.Module.to()方 法与模型加载器链接起来(即代码to(device))。这确保了如果有 GPU,模型将在GPU上运行。如果没有,模型将在CPU上运行,不过这样 可能会慢很多。
AutoModel类将词元编码转换为嵌入向量,然后将它们馈送到编码器栈 中以返回隐藏状态。我们看一下如何从语料库中提取这些状态。

提取最终隐藏状态
作为预热,我们检索一个字符串的最终隐藏状态。我们需要做的第一 件事是对字符串进行编码并将词元转换为PyTorch张量。可以通过向词 元分析器提供return_tensors=”pt”参数来实现。具体如下:

我们可以看到,生成的张量形状为[batch size,n_tokens]。现在我 们已经将编码作为张量获取,最后一步是将它们放置在与模型相同的 设备上,并按以下方式传输入:
现在我们知道如何针对单个字符串获取最终隐藏状态。我们通过创建 一个新的hidden_state列来对整个数据集执行相同的操作,以存储所 有这些向量。就像我们在词元分析器中所做的那样,我们将使用 DatasetDict的map()方法一次性提取所有隐藏状态。我们需要做的第 一件事是将先前的步骤封装在一个处理函数中:

这个函数和我们之前的逻辑的唯一不同在于最后一步,即将最终的隐 藏状态作为NumPy数组放回CPU。当我们使用批量输入时,map()方法要 求处理函数返回Python或NumPy对象。 由于我们的模型期望输入张量,下一步需要将input_ids和 attention_mask列转换为torch格式,具体如下:

现在我们已经得到了与每个推文相关联的隐藏状态,下一步是基于它 们训练一个分类器。为了做到这一点,我们需要一个特征矩阵,我们 来看一下。
创建特征矩阵

可视化训练集
由于在768维度中可视化隐藏状态是个艰难的任务,因此我们将使用强 大的UMAP算法将向量投影到2D平面上 。由于UMAP在特征缩放到[0, 1]区间内时效果最佳,因此我们将首先应用一个MinMaxScaler,然后 使用umap-learn库的UMAP实现来缩放隐藏状态:


训练一个简单的分类器
我们已经看到,不同情感的隐藏状态是不同的,尽管其中一些情感并 没有明显的界限。现在让我们使用这些隐藏状态来训练一个逻辑回归 模型(使用Scikit-learn)。训练这样一个简单的模型速度很快,而 且不需要GPU:

从准确率上看,我们的模型似乎只比随机模型稍微好一点,但由于我 们处理的是一个不平衡的多分类数据集,它实际上会显著地表现更 好。我们可以通过将其与简单基准进行比较来检查我们的模型是否良 好。在Scikit-learn中,有一个DummyClassifier可以用于构建具有简 单启发式的分类器,例如始终选择多数类或始终选择随机类。在这种 情况下,表现最佳的启发式是始终选择最常见的类,这会产生约35%的 准确率:
因此,使用DistilBERT嵌入的简单分类器明显优于我们的基线。我们 可以通过查看分类器的混淆矩阵来进一步研究模型的性能,该矩阵告 诉我们真实标注和预测标注之间的关系:

这里我们可以看到,anger和fear最常与sadness混淆,这与我们可视 化嵌入时所观察到的一致。此外,love和surprise经常与joy混淆。 接下来我们将探究微调方法,这种方法可以带来更好的分类效果。但 是,重要的是要注意,微调需要更多的计算资源,比如GPU,而你的组 织可能没有GPU。在这种情况下,基于特征的方法可以是传统机器学习 和深度学习之间的一个很好的折中方案。
微调Transformer模型
现在我们探讨如何进行端到端的Transformer模型微调。在使用微调方 法时,我们不使用隐藏状态作为固定特征,而是如图2-6所示那样进行 训练。这要求分类头是可微的,这就是为什么这种方法通常使用神经 网络进行分类。
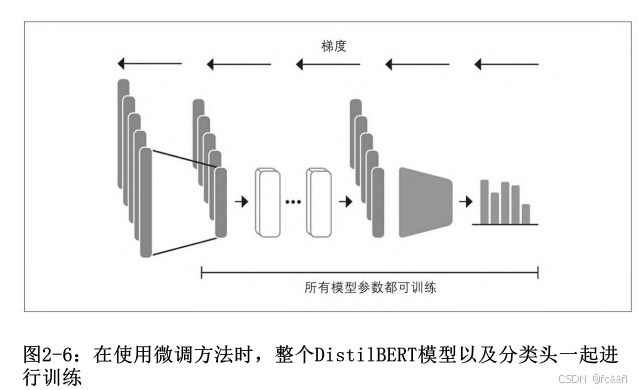
训练用作分类模型输入的隐藏状态将有助于我们避免使用可能不适合 分类任务的数据的问题。相反,初始隐藏状态在训练过程中适配,以 降低模型损失并提高其性能。
加载预训练模型

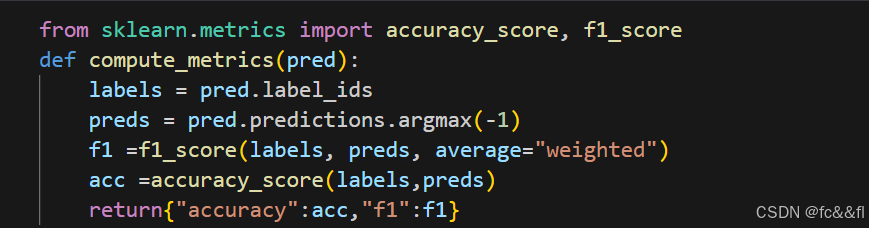
定义性能指标
为了在训练期间监控指标,我们需要为Trainer定义一个 compute_metrics()函数。该函数接收一个EvalPrediction对象(这是 一个具有predictions和label_ids属性的命名元组),并需要返回一 个将每个指标名称映射到其值的字典。对于我们的应用,我们将计算 模型的F1分数和准确率:
有了数据集和度量指标后,在定义Trainer类之前,我们只需要处理最 后两件事情: 1.登录我们的Hugging Face Hub账户。从而让我们能够将我们的微 调模型推送到Hub上,并与社区分享它。 2.定义训练运行的所有超参数。
登录hugging-face
from huggingface_hub import notebook_login
notebook_login()
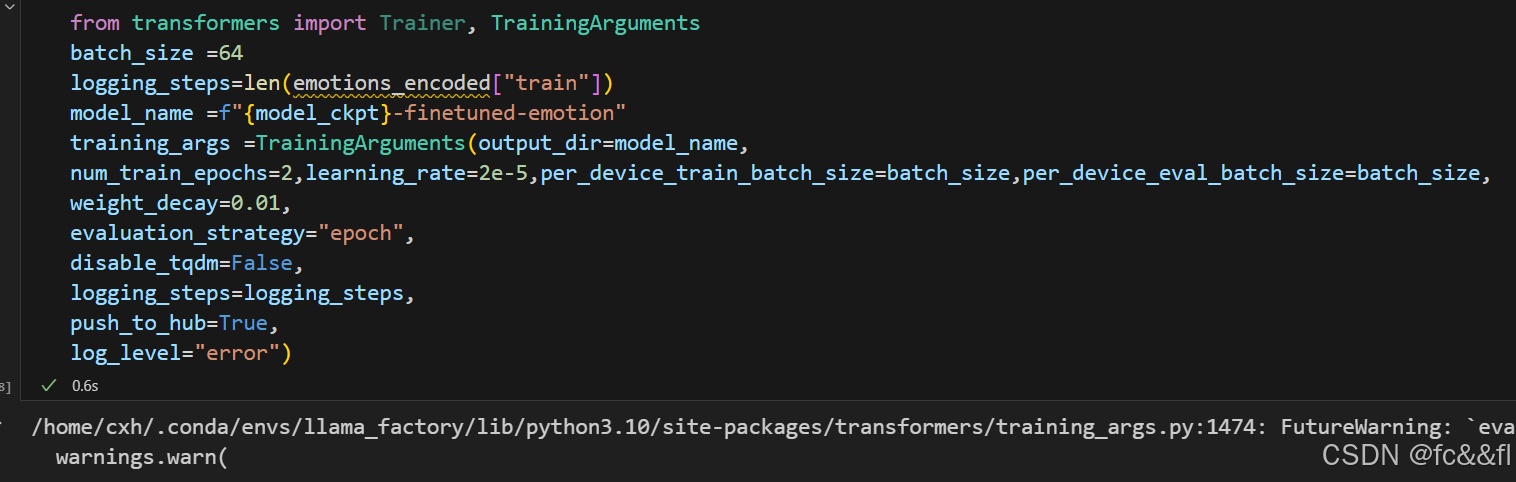
训练模型
我们将使用TrainingArguments类来定义训练参数。此类存储了大量信 息,从而为训练和评估提供细粒度的控制。最重要的参数是 output_dir,它是存储训练过程中所有工件的位置。以下是 TrainingArguments的完整示例:
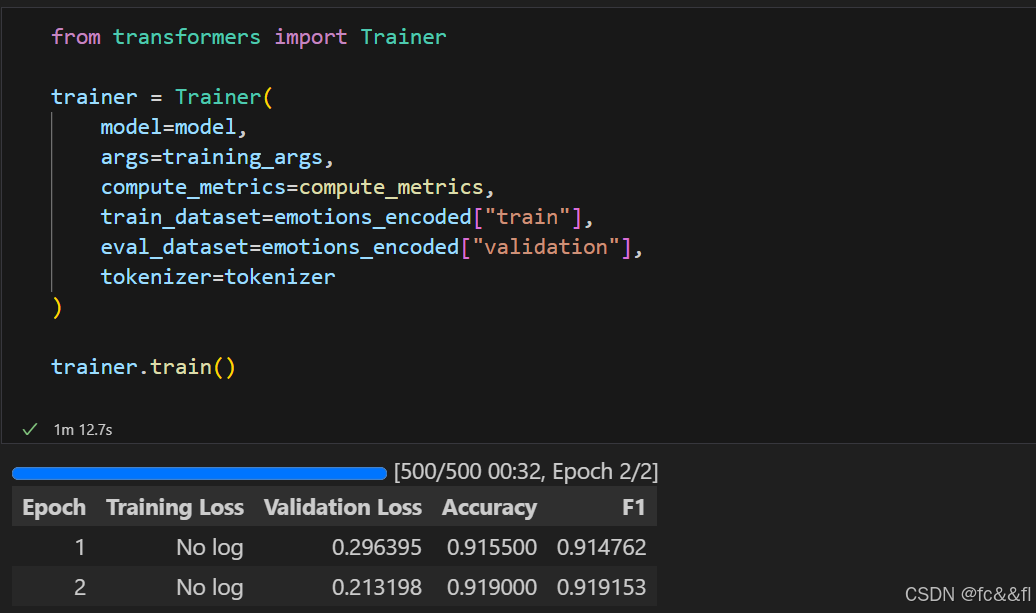
predict()方法的输出是一个PredictionOutput对象,它包含了 predictions和label_ids的数组,以及我们传给训练器的度量指标。 我们可以通过以下方式访问验证集上的度量指标:
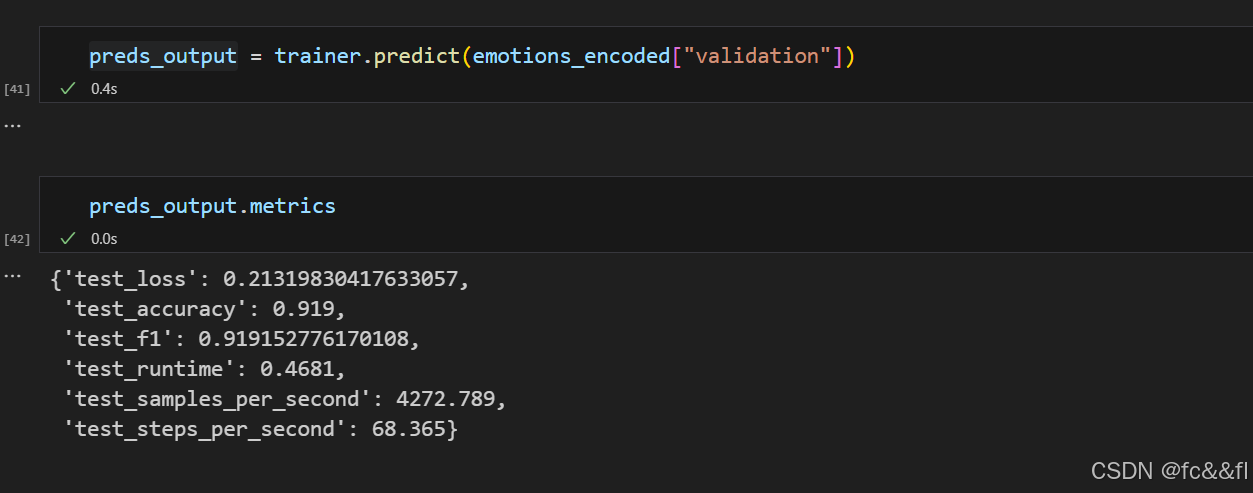
它还包含了每个类别的原始预测值。我们可以使用np.argmax()进行贪 婪解码预测,然后会得到预测标注,并且结果格式与前面的基于特征 的方法相同,以便我们进行比较:
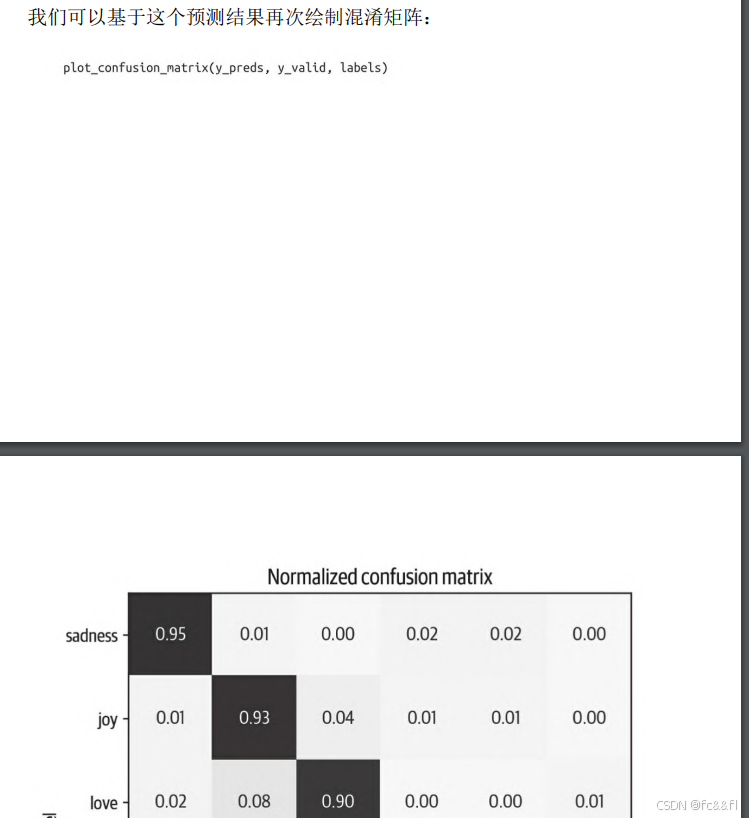
可见,与前面的基于特征的方法相比,微调方法的结果更接近于理想 的对角线混淆矩阵。love类别仍然经常与joy混淆,这点逻辑上也讲得 过去。surprise也经常被错误地识别为joy,或者与fear混淆。总体而 言,模型的性能似乎非常不错,但在我们结束之前,让我们深入了解 模型可能会犯的错误的类型。
储存和共享模型
下载自己的模型
使用自己的模型预测

4.本章小结
祝贺你,现在你知道了如何训练一个用于分类推文情感的Transformer
模型!我们已经讨论了基于特征和微调的两种互补方法,并研究了它
们的优势和劣势。
然而,这只是使用Transformer模型构建实际应用程序的第一步,我们
还有很多工作要做。以下是在NLP旅程中可能遇到的挑战清单:
我的老板希望我的模型昨天就上线了!
在大多数应用程序中,你并不希望你的模型闲置,你希望将它用于预
测!当模型被推送到Hub时,会自动创建一个推理端点,可以使用HTTP
请求调用它。如果你想了解更多信息,建议查看推理API的文档
(https://oreil.ly/XACF5)。
我的用户需要更快的预测!
我们已经讨论了解决此问题的一种方法:使用DistilBERT。在第8章
中,我们将深入研究知识蒸馏(DistilBERT创建的过程)以及其他加
速Transformer模型的技巧。
你的模型是否也可以执行X任务?
正如我们在本章中所提到的,Transformer模型非常多才多艺。在本书
的其余部分中,我们将使用相同的基本架构探索一系列任务,例如问
答和命名实体识别。
我的文本不是英语!
事实证明,Transformer模型能够支持多语言,在第4章中,我们将使
用它们同时处理多种语言。
我没有标注数据!
如果可用的标注数据非常少,则可能不能进行微调。在第9章中,我们
将探讨一些应对这种情况的技术。
现在我们已经了解了如何训练和共享Transforme。在第3章中,我们将
探索如何从头开始实现我们自己的Transformer模型。第三章.Transformer架构剖析
在第2章中,我们了解了对于Transformer模型进行微调和评估需要的 条件。现在我们来看看它们里面是如何工作的。在本章中,我们将探 索Transformer模型的主要组成部分,以及如何使用PyTorch实现它 们。我们还将提供关于如何在TensorFlow实现相同内容的指导。我们 首先专注于构建注意力机制,然后添加必要的部分来使Transformer编 码器起作用。我们还会简要地探讨编码器和解码器模块之间的架构差 异。在本章结束时,你将能够自己实现一个简单的Transformer模型!
1.Transformer架构
原始Transformer是基于编码器-解码 器架构的,该架构广泛用于机器翻译等任务中,即将一个单词序列从 一种语言翻译成另一种语言。
该架构由两个组件组成:
编码器
将一个词元的输入序列转化为一系列嵌入向量,通常被称为隐藏状态 或上下文。
解码器
利用编码器的隐藏状态,逐步生成一个词元的输出序列,每次生成一 个词元。 而编码器和解码器又由如图3-1所示的几个构建块组成。
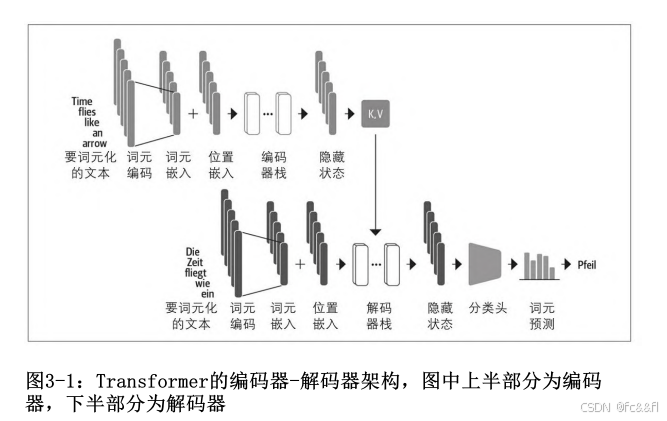
●输入的文本会使用第2章中所介绍的技术进行词元化,并转换成词元 嵌入。由于注意力机制不了解词元之间的相对位置,因此我们需要一 种方法将词元位置的信息注入输入,以便模拟文本的顺序性质。也就 是说,词元嵌入会与包含每个词元位置信息的位置嵌入进行组合。
●编码器由一系列编码器层或“块”堆叠而成,类似于计算机视觉中 叠加卷积层。解码器也是如此,由一系列解码器层堆叠而成。
●编码器的输出被提供给每个解码器层,然后解码器生成一个对于序 列中下一个最可能的词元的预测。该步骤的输出随后被反馈回解码器 以生成下一个词元,以此类推,直到达到特殊的结束序列(EOS)词 元。在图3-1的例子中,假设解码器已经预测了“Die”和“Zeit”。 现在它会把这两个作为输入,并作为所有编码器的输出,来预测下一 个词元“fliegt”。在下一步中,解码器将“fliegt”作为额外的输 入。我们重复这个过程,直到解码器预测出EOS词元或我们达到了最大 长度。
Transformer架构最初是为序列到序列的任务(如机器翻译)而设计 的,但编码器和解码器模块很快就被抽出来单独形成模型。虽然 Transformer模型已经有数百种不同的变体,但其中大部分属于以下三 种类型之一:
纯编码器
这些模型将文本输入序列转换为富数字表示的形式,非常适用于文本 分类或命名实体识别等任务。BERT及其变体,例如RoBERTa和 DistilBERT,属于这类架构。此架构中为给定词元计算的表示取决于 左侧(词元之前)和右侧(词元之后)上下文。这通常称为双向注意 力。
纯解码器
针对像“谢谢你的午餐,我有一个……”这样的文本提示,这类模型 将通过迭代预测最可能的下一个词来自动完成这个序列。GPT模型家族 属于这一类。在这种架构中,对于给定词元计算出来的表示仅依赖于 左侧的上下文。这通常称为因果或自回归注意力。
编码器-解码器
这类模型用于对一个文本序列到另一个文本序列的复杂映射进行建 模。它们适用于机器翻译和摘要任务。除了Transformer架构,它将编 码器和解码器相结合,BART和T5模型也属于这个类。
实际上,纯解码器和纯编码器架构的应用之间的区别有些模糊不清。 例如,像GPT系列中的纯解码器模型可以被优化用于传统上认为是序列 到序列任务的翻译任务。同样,BERT等纯编码器模型也可以应用于通 常与编码器-解码器或纯解码器模型相关的文本摘要任务注 。
2.编码器
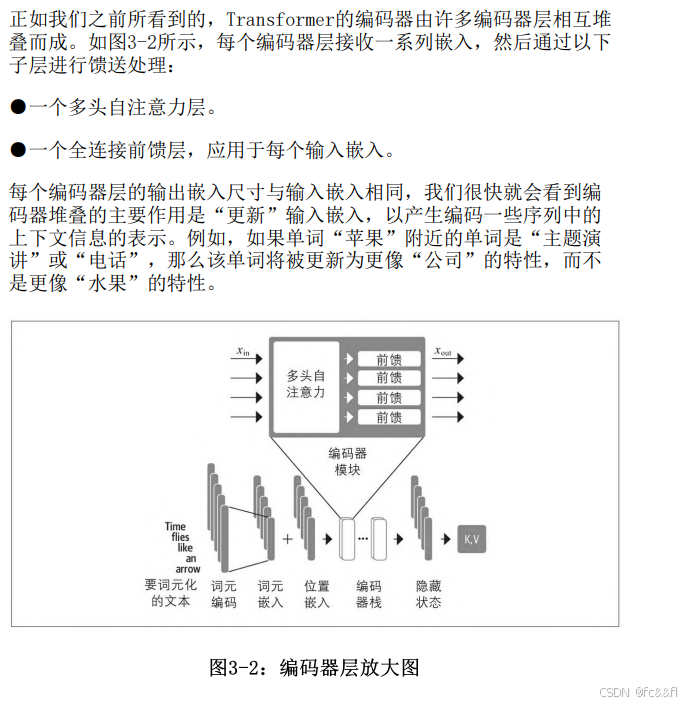
自注意力机制
正如我们在第1章中讨论的那样,注意力机制是一种神经网络为序列中 的每个元素分配不同权重或“注意力”的机制。对文本序列来说,元 素则为我们在第2章遇到的词元嵌入(其中每个词元映射为固定维度的 向量)。例如,在BERT中,每个词元表示为一个768维向量。自注意力 中的“自”指的是这些权重是针对同一组隐藏状态计算的,例如编码 器的所有隐藏状态。与自注意力相对应的,与循环模型相关的注意力 机制则计算每个编码器隐藏状态对于给定解码时间步的解码器隐藏状 态的相关性。
自注意力的主要思想是,不是使用固定的嵌入值来表示每个词元,而 是使用整个序列来计算每个嵌入值的加权平均值。另一种表述方式是 说,给定词元嵌入的序列x,…,x,自注意力产生新的嵌入序列,其 中每个是所有x的线性组合:

当你看到单词“flies”时会想到什么。也许你会想到令人讨厌的昆 虫,但是如果你得到更多的上下文,比如 “time flies like an arrow”,那么你会意识到“flies”表示 的是动词。同样地,我们可以通过以不同的比例结合所有词元嵌入来 创建“flies”的表示形式,也许可以给“time”和“arrow”的词元 嵌入分配较大的权重wji。用这种方式生成的嵌入称为上下文嵌入,早 在Transformer发明之前就存在了,例如ELMo语言模型 。
现在我们看一下注意力权重是如何计算的。
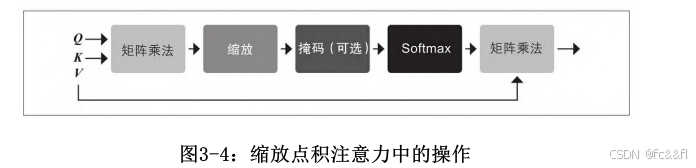
实现自注意力层的方法有好几种,但最常见的是那篇著名的 Transformer架构论文 所介绍的缩放点积注意力(scaled dotproduct attention)。要实现这种机制,需要四个主要步骤:
1.将每个词元嵌入投影到三个向量中,分别称为query、key和value。
2.计算注意力分数。我们使用相似度函数确定query和key向量的相关 程度。顾名思义,缩放点积注意力的相似度函数是点积,并通过嵌入 的矩阵乘法高效计算。相似的query和key将具有较大的点积,而那些 没有相似处的则几乎没有重叠。这一步的输出称为注意力分数,在一 个有n个输入词元的序列中,将对应着一个n×n的注意力分数矩阵。
3.计算注意力权重。点积在一般情况下有可能会产生任意大的数,这 可能会导致训练过程不稳定。为了处理这个问题,首先将注意力分数 乘以一个缩放因子来规范化它们的方差,然后再通过softmax进行规范 化,以确保所有列的值相加之和为1。结果得到一个n×n的矩阵,该矩 阵包含了所有的注意力权重wji。
4.更新词嵌入。计算完注意力权重之后,我们将它们与值向量v,…, v相乘,最终获得词嵌入表示。 1n
我们可以使用一个很赞的库,Jupyter的BertViz (https://oreil.ly/eQK3I),来可视化以上的注意力权重计算过 程。该库提供了一些可用于可视化Transformer模型的不同方面注意力 的函数。如果想可视化注意力权重,我们可以使用neuron_view模块, 该模块跟踪权重计算的过程,以显示如何将query向量和key向量相结 合以产生最终权重。由于BertViz需要访问模型的注意力层,因此我们 将使用BertViz中的模型类来实例化我们的BERT checkpoint,然后使 用show()函数为特定的编码器层和注意力头生成交互式可视化。请注 意,你需要单击左侧的“+”才能激活注意力可视化。
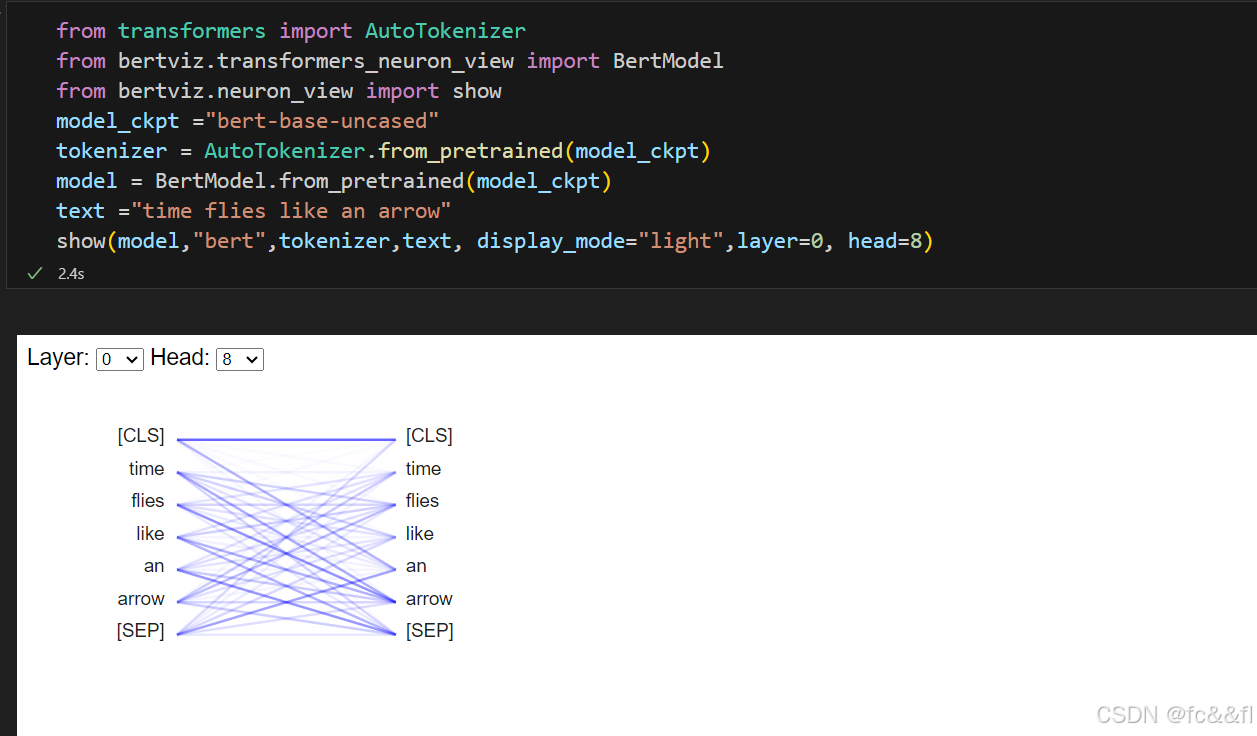
从以上可视化图中,我们可以看到query向量和key向量的值表示为一 条条的条带,其中每个条带的强度对应于其大小。连线的权重是根据 词元之间的注意力加权的,我们可以看到,“flies”的query向量与 “arrow”的key向量重叠最强。
在你第一次接触query、key和value向量的概念时,可能会觉得这些概 念有点晦涩难懂。这些概念受到信息检索系统的启发,但我们可以用 一个简单的类比来解释它们的含义。你可以这样想象,你正在超市购 买晚餐所需的所有食材。你有一份食谱,食谱里面每个食材可以视为 一个query。然后你会扫描货架,通过货架上的标注(key),以检查 该商品是否与你列表中的食材相匹配(相似度函数)。如果匹配成 功,那么你就从货架上取走这个商品(value)。
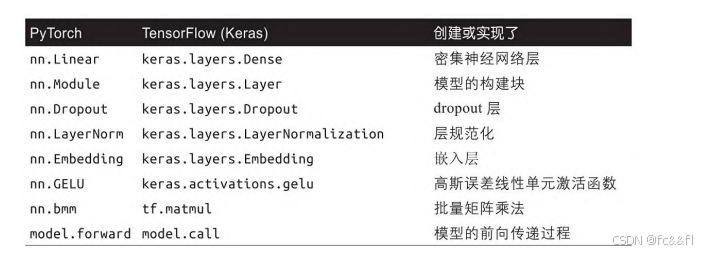
我们将使用PyTorch实现Transformer架构,使用TensorFlow实现 Transformer架构的步骤与之类似。两个框架中最重要的函数之间的映 射关系详见表3-1。
1)对文本进行词元化,因此我们使用词元分析 器提取输入ID:
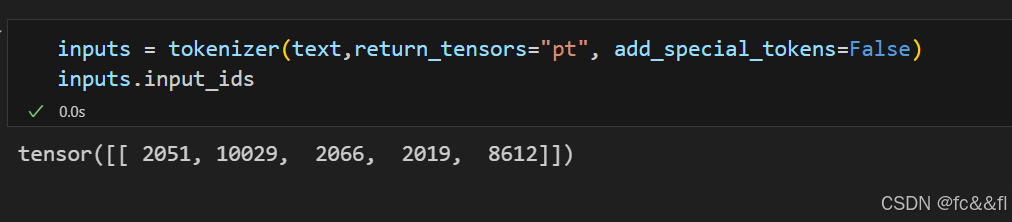
正如我们在第2章所看到的那样,句子中的每个词元都被映射到词元分 析器的词表中的唯一ID。为了保持简单,我们还通过设置 add_special_tokens=False来将[CLS]和[SEP]词元排除在外。接下 来,我们需要创建一些密集嵌入。这里的密集是指嵌入中的每个条目 都包含一个非零值。
2)在PyTorch中,我们可以通过使用 torch.nn.Embedding层来实现这一点,该层作为每个输入ID的查找 表:
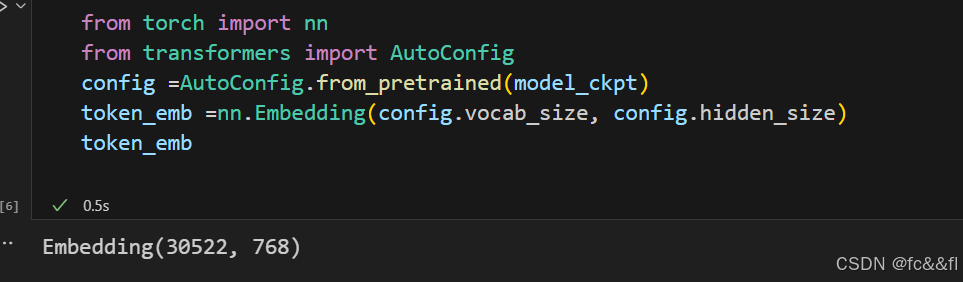
在这里,我们使用AutoConfig类加载了与bert-baseuncased checkpoint相关联的config.json文件。在 Hugging Face Transformers库中,每个checkpoint都被分配一个配 置文件,该文件指定了各种超参数,例如vocab_size和hidden_size。 在我们的示例中,每个输入ID将映射到nn.Embedding中存储的30 522 个嵌入向量之一,其中每个向量维度为768。AutoConfig类还存储其他 元数据,例如标注名称,用于格式化模型的预测。
需要注意的是,此时的词元嵌入与它们的上下文是独立的。这意味 着,同形异义词(拼写相同但意义不同的词),如前面例子中的 “flies”(“飞行”或“苍蝇”),具有相同的表示形式。后续的注 意力层的作用是将这些词元嵌入进行混合,以消除歧义,并通过其上 下文的内容来丰富每个词元的表示。
3)现在我们有了查找表,通过输入ID,我们可以生成嵌入向量:
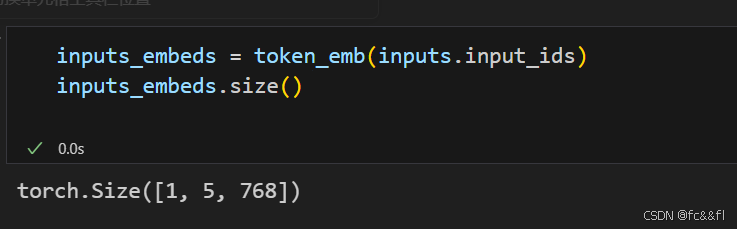
这给我们提供了一个形状为[batch_size,seq len,hidden_dim]的 张量,就像我们在第2章中看到的一样。这里我们将推迟位置编码,因 此下一步是创建query、key和value向量,并使用点积作为4)相似度函数 来计算注意力分数:
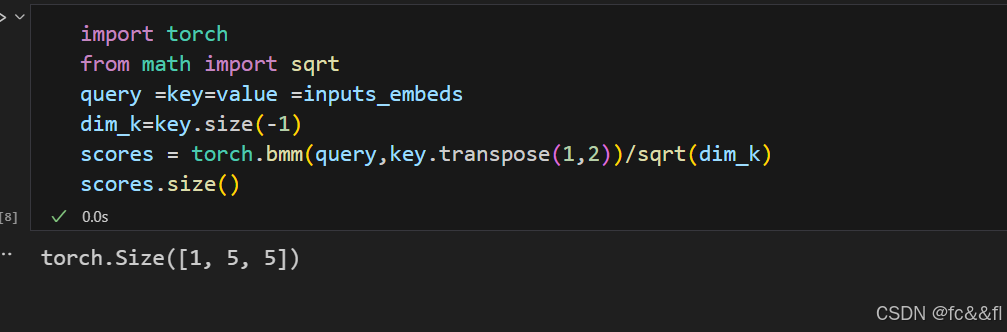
这产生了一个5×5矩阵,其中包含批量中每个样本的注意力分数。稍 后我们将看到,query、key和value向量是通过将独立的权重矩阵WQ应 用到嵌入中生成的,但这里为简单起见,我们将它们设为相等。在缩 放点积注意力中,点积按照嵌入向量的大小进行缩放,这样我们在训 练过程中就不会得到太多的大数,从而可以避免下一步要应用的 softmax饱和。
5)接下来我们应用softmax:
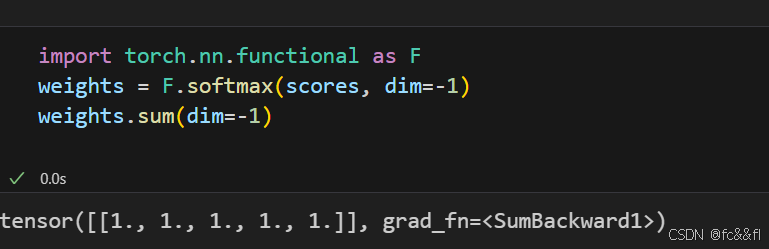
6)最后将注意力权重与值相乘
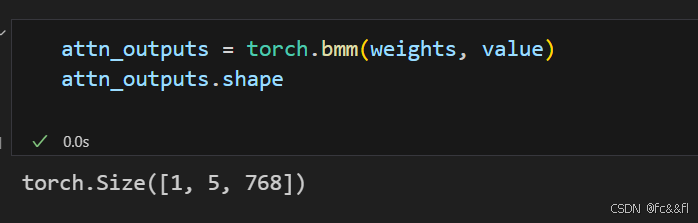
7)这就是全部了,我们已经完成了简化形式的自注意力机制实现的所有 步骤!请注意,整个过程仅涉及两个矩阵乘法和一个softmax,因此你 可以将“自注意力”视为一种花哨的平均形式。 我们把这些步骤封装成一个函数,以便以后我们可以重用它:
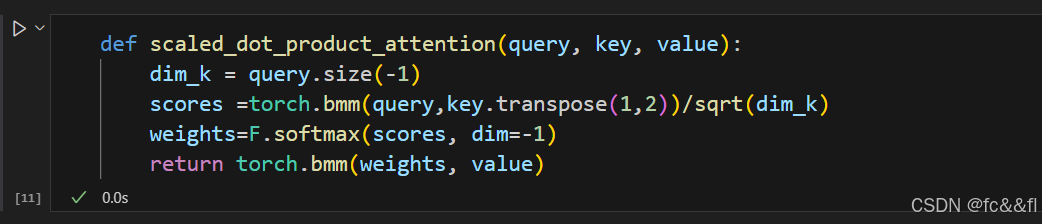
我们的注意力机制在query向量和key向量相等的情况下,会给上下文 中相同的单词分配非常高的分数,特别是给当前单词本身:query向量 与自身的点积总是1。而实际上,一个单词的含义将更好地受到上下文 中其他单词的影响,而不是同一单词(甚至自身)。以前面的句子为 例,通过结合“time”和“arrow”的信息来定义“flies”的含义, 比重复提及“flies”要更好。那么我们如何实现这点?
我们可以让模型使用三个不同的线性投影将初始词元向量投影到三个 不同的空间中,从而允许模型为query、key和value创建一个不同的向 量集。
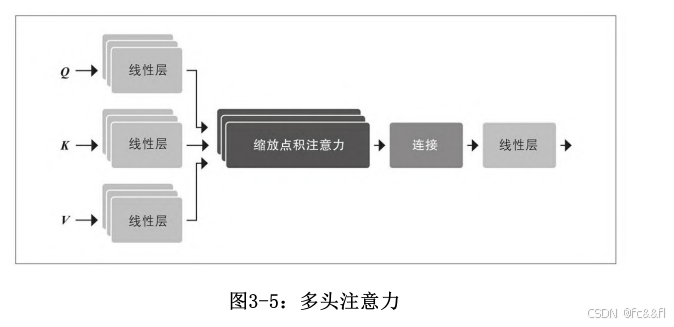
多头注意力
前面提到,我们将query、key和value视为相等来计算注意力分数和权 重。但在实践中,我们会使用自注意力层对每个嵌入应用三个独立的 线性变换,以生成query、key和value向量。这些变换对嵌入进行投 影,每个投影都带有其自己的可学习参数,这使得自注意力层能够专 注于序列的不同语义方面。
同时,拥有多组线性变换通常也是有益的,每组变换代表一种所谓的 注意力头。多头注意力层如图3-5所示。但是,为什么我们需要多个注 意力头?原因是一个注意力头的softmax函数往往会集中在相似度的某 一方面。拥有多个头能够让模型同时关注多个方面。例如,一个头负 责关注主谓交互,而另一个头负责找到附近的形容词。显然,我们没 有在模型中手工制作这些关系,它们完全是从数据中学习到的。如果 你对计算机视觉模型熟悉,你可能会发现其与卷积神经网络中的滤波 器相似,其中一个滤波器负责检测人脸,而另一个滤波器负责在图像 中找到汽车的车轮。
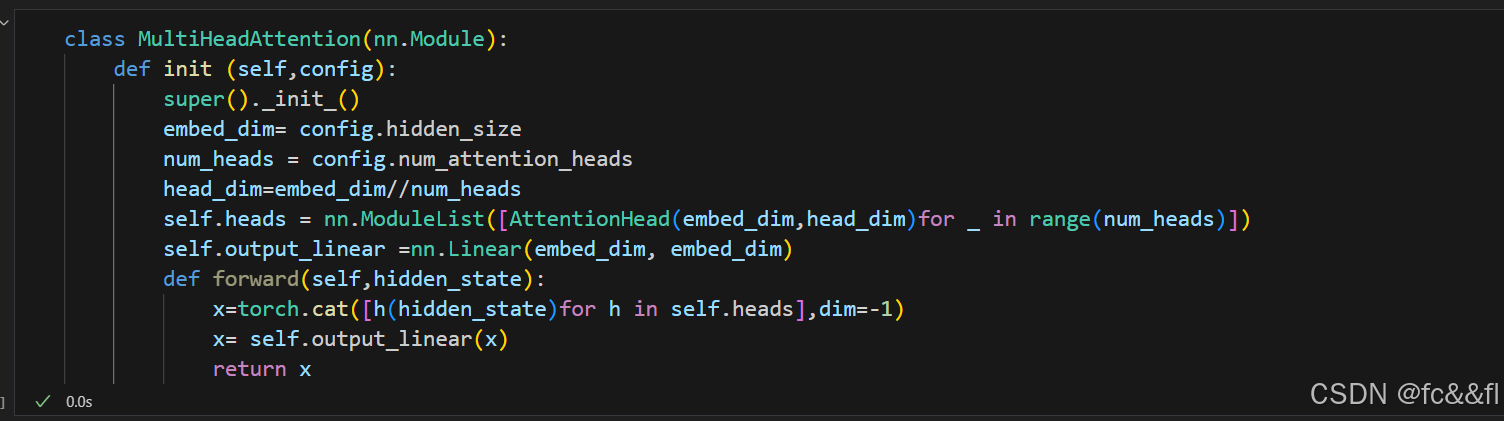
现在我们来编码实现,首先编写一个单独的注意力头的类:

这里我们初始化了三个独立的线性层,用于对嵌入向量执行矩阵乘 法,以生成形状为[batch_size,seq_len,head_dim]的张量,其中 head_dim是我们要投影的维数数量。尽管head_dim不一定比词元的嵌 入维数(embed_dim)小,但在实践中,我们选择head_dim是 embed_dim的倍数,以便跨每个头的计算能够保持恒定。例如,BERT有 12个注意力头,因此每个头的维数为768/12=64。 现在我们有了一个单独的注意力头,因此我们可以将每个注意力头的 输出串联起来,来实现完整的多头注意力层:
请注意,注意力头连接后的输出也通过最终的线性层进行馈送,以生 成形状为[batch_size,seq_len,hidden_dim]的输出张量,以适用于 下游的前馈网络。为了确认,我们看看多头注意力层是否产生了我们 输入的预期形状。在初始化MultiHeadAttention模块时,我们传递了 之前从预训练的BERT模型中加载的配置。这确保我们使用与BERT相同 的设置:
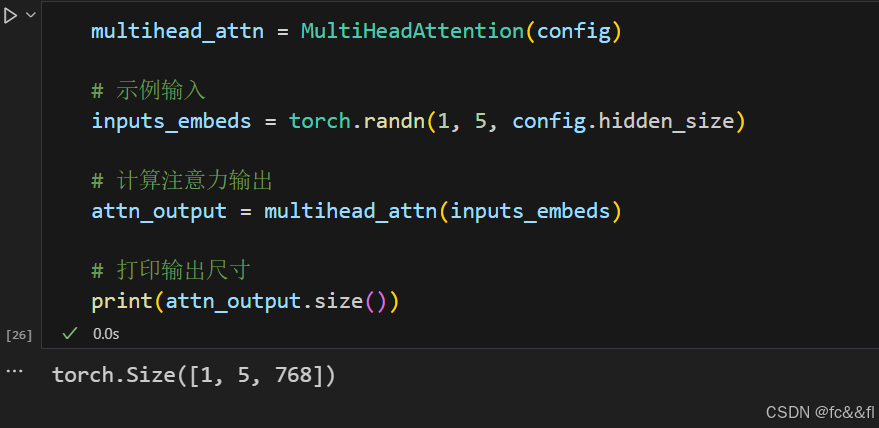
这么做是可行的!最后,我们再次使用BertViz可视化单词“flies” 的两个不同用法的注意力。这里我们可以使用BertViz的head_view() 函数,通过计算预训练checkpoint的注意力并指示句子边界的位置来 显示注意力:
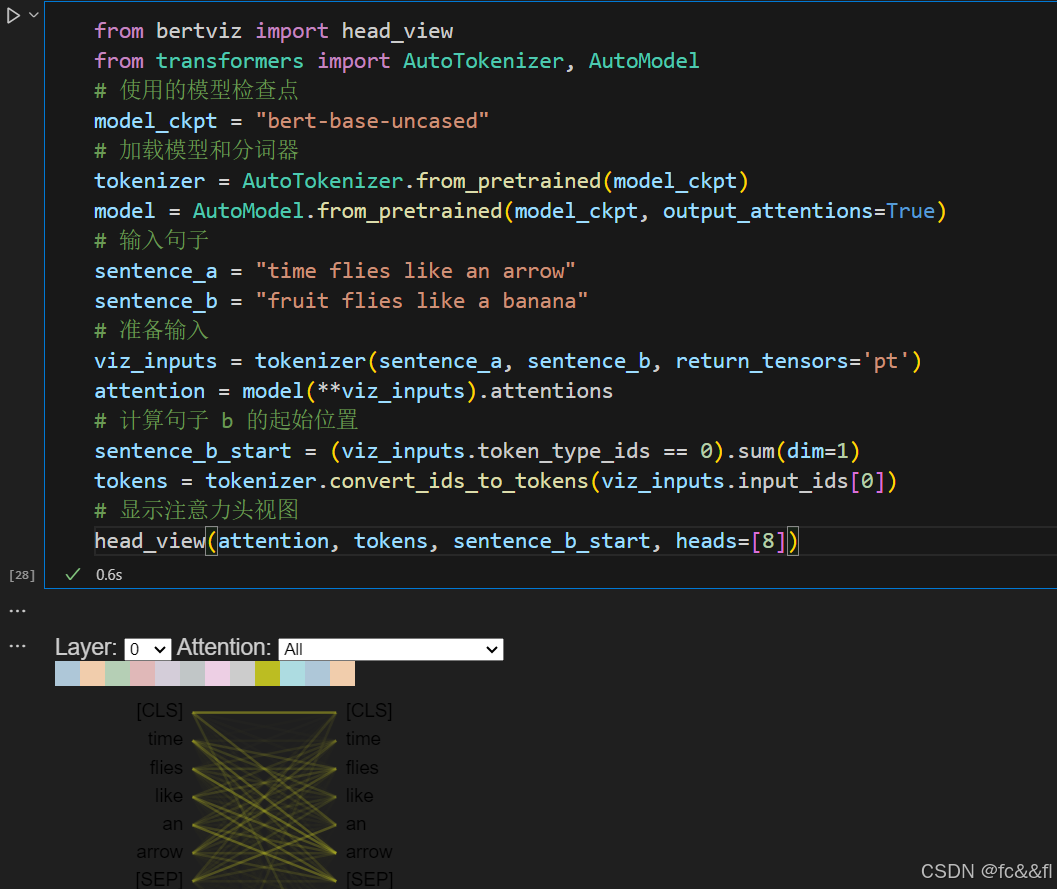
这种可视化展示了注意力权重,表现为连接正在被更新嵌入的词元 (左侧)与所有被关注的单词(右侧)之间的线条。线条的颜色深度 表现了注意力权重的大小,深色线条代表值接近于1,淡色线条代表值 接近于0。
在这个例子中,输入由两个句子组成,[CLS]和[SEP]符号是我们在第2 章中遇到的BERT的词元分析器中的特殊符号。从可视化结果中我们可 以看到注意力权重最大的是属于同一句子的单词,这表明BERT能够判 断出它应该关注同一句子中的单词。然而,对于单词“flies”,我们 可以看到BERT已经识别出在第一句中“arrow”是重要的,在第二句中 “fruit”和“banana”是重要的。这些注意力权重使模型能够根据它 所处的上下文来区分“flies”到底应该为动词还是名词!
至此我们已经讲述完注意力机制了,我们来看一下如何实现编码器层 缺失的一部分:位置编码前馈神经网络。
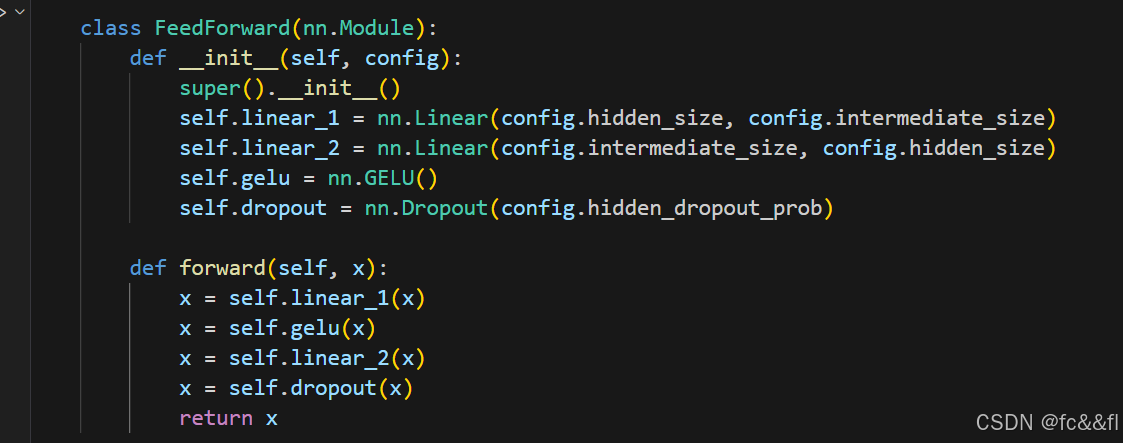
前馈层
编码器和解码器中的前馈子层仅是一个简单的两层全连接神经网络, 但有一点小小的不同:它不会将整个嵌入序列处理为单个向量,而是 独立处理每个嵌入。因此,该层通常称为位置编码前馈神经网络。有 时候你还会看到它又被称为内核大小为1的1维卷积,这种叫法通常来 自具有计算机视觉背景的人(例如,OpenAI GPT代码库就是这么叫 的)。论文中的经验法则是第一层的隐藏尺寸应为嵌入尺寸的四倍, 并且最常用的激活函数是GELU。这是大部分容量和记忆发生的地方, 也是扩展模型时最经常进行缩放的部分。我们可以将其实现为一个简 单的nn.Module,如下所示:
需要注意的是,像nn.Linear这样的前馈层通常应用于形状为 (batch_size,input_dim)的张量上,它将独立地作用于批量维度中 的每个元素。这对于除了最后一个维度之外的任何维度都是正确的, 因此当我们将形状为(batch_size,seq_len,hidden_dim)的张量传 给该层时,该层将独立地应用于批量和序列中的所有词元嵌入,这正 是我们想要的。我们可以通过传递注意力输出来测试这一点:
现在我们已经拥有了创建完整的Transformer编码器层的所有要素!唯 一剩下的部分是决定在哪里放置跳跃连接和层规范化。我们看看这会 如何影响模型架构。
添加层规范化
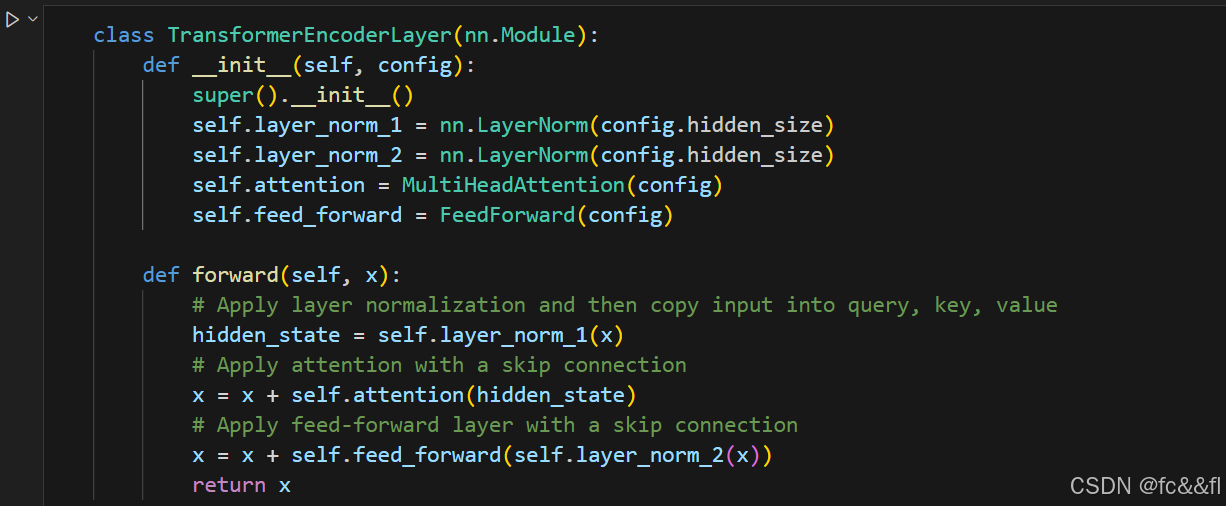
如前所述,Transformer架构使用了层规范化和跳跃连接。前者将批处 理中的每个输入规范化为零均值和单位方差。跳跃连接直接将张量传 给模型的下一层,而不做处理,只将其添加到处理的张量中。在将层 规范化放置在Transformer的编码器或解码器层中时,论文提供了两种 选项:1) 后置层规范化 这是Transformer论文中使用的一种结构,它把层规范化置于跳跃连接 之后。这种结构从头开始训练时会比较棘手,因为梯度可能会发散。 因此,在训练过程中我们经常会看到一个称为学习率预热的概念,其 中学习率在训练期间从一个小值逐渐增加到某个最大值。 2)前置层规范化 这是论文中最常见的布局,它将层规范化置于跳跃连接之前。这样做 往往在训练期间更加稳定,并且通常不需要任何学习率预热。
这两种方式的区别

这里我们将使用第二种方式,因此我们可以简单地将我们的基本构件 粘在一起,如下所示:
现在使用我们的输入嵌入来测试一下:

在更高层面的术语中,自注意力层和前馈层称为置换等变的——如果 输入被置换,那么层的相应输出将以完全相同的方式置换。
我们已经成功地从头开始实现了我们的第一个Transformer编码器层! 然而,我们设置编码器层的方式存在一个问题:它们对于词元的位置 是完全不变的。由于多头注意力层实际上是一种精致的加权和,因此 词元位置的信息将丢失 。
幸运的是,有一种简单的技巧可以使用位置嵌入来整合位置信息。我 们来看看。
位置嵌入
位置编码基于一个简单但非常有效的想法:用一个按向量排列的位置 相关模式来增强词元嵌入。如果该模式对于每个位置都是特定的,那 么每个栈中的注意力头和前馈层可以学习将位置信息融合到它们的转 换中。
有几种实现这个目标的方法,其中最流行的方法之一是使用可学习的 模式,特别是在预训练数据集足够大的情况下。这与仅使用词元嵌入 的方式完全相同,但是使用位置索引作为输入,而不是词元ID。通过 这种方法,在预训练期间可以学习到一种有效的编码词元位置的方 式。
我们创建一个自定义的Embeddings模块,它将输入的input_ids投影到 密集的隐藏状态上,并结合Position_ids的位置嵌入进行投影。最终 的嵌入层是两个嵌入层的简单求和:
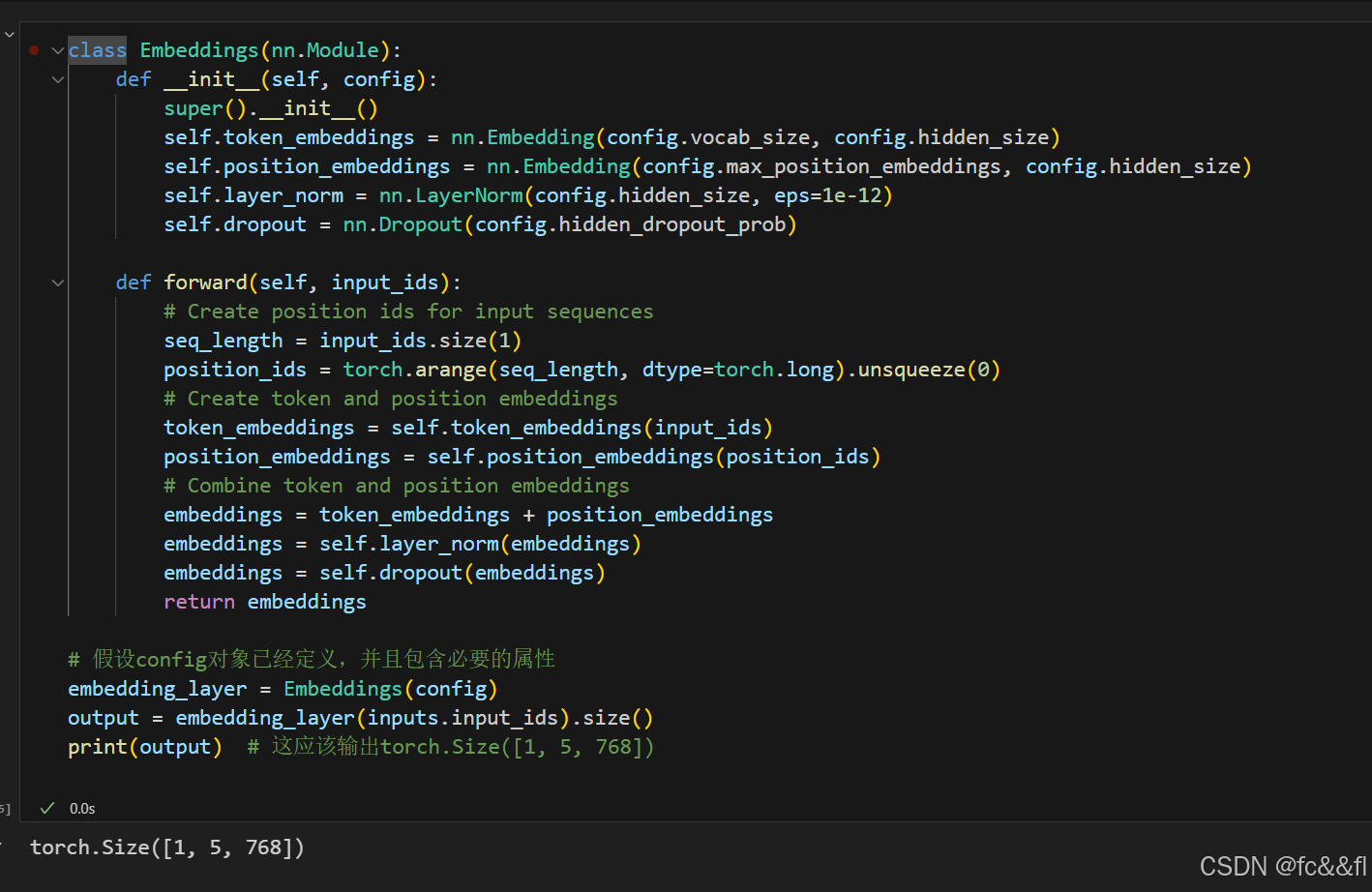
我们可以看到嵌入层现在为每个词元创建了一个密集的嵌入。 这种可学习的位置嵌入易于实现并广泛使用,除此之外,还有其他一 些方法:
绝对位置表示
Transformer模型可以使用由调制正弦和余弦信号组成的静态模式来编 码词元的位置。当没有大量数据可用时,这种方法尤其有效。
相对位置表示
通过结合绝对和相对位置表示的想法,旋转位置嵌入在许多任务上取 得了优秀的结果。GPT-Neo是一个采用旋转位置嵌入的模型的例子。
尽管绝对位置很重要,但有观点认为,在计算嵌入时,周围的词元最 为重要。相对位置表示遵循这种直觉,对词元之间的相对位置进行编 码。这不能仅通过在开头引入新的相对嵌入层来设置,因为相对嵌入 针对每个词元会因我们对序列的访问位置的不同而不同。对此,注意 力机制本身通过添加额外项来考虑词元之间的相对位置。像DeBERTa等 模型就使用这种表示 。
现在我们把所有内容整合起来,通过将嵌入与编码器层结合起来构建 完整的Transformer编码器:

添加分类头
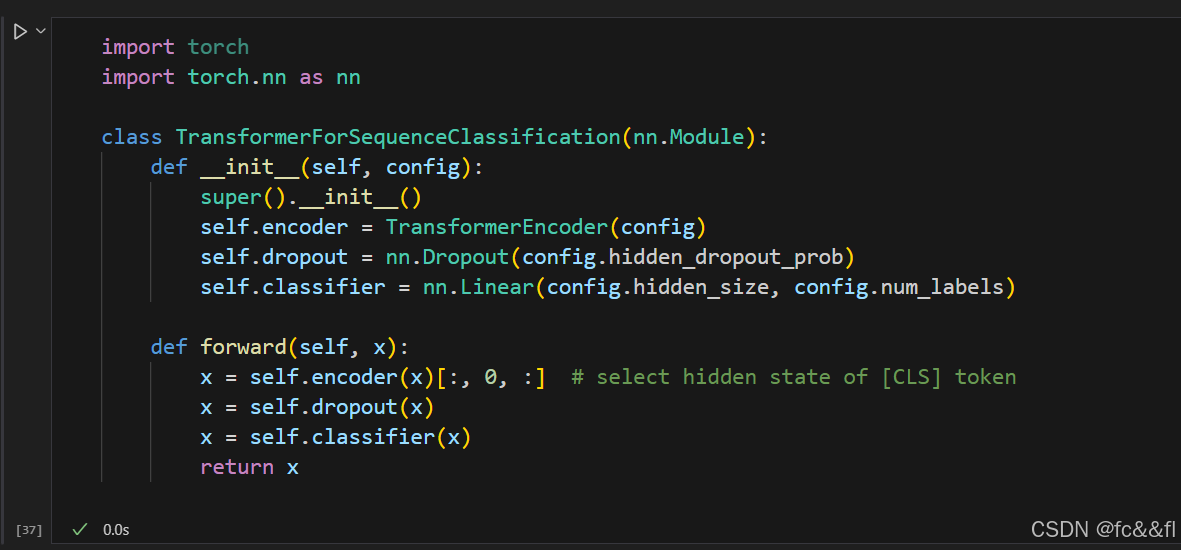
Transformer模型通常分为与任务无关的主体和与任务相关的头。我们 将在第4章讲述Hugging Face Transformers库的设计模式时会再次 提到这种模式。到目前为止,我们所构建的都是主体部分的内容,如 果我们想构建一个文本分类器,那么我们还需要将分类头附加到该主 体上。每个词元都有一个隐藏状态,但我们只需要做出一个预测。有 几种方法可以解决这个问题。一般来说,这种模型通常使用第一个词 元来进行预测,我们可以附加一个dropout和一个线性层来进行分类预 测。下面的类对现有的编码器进行了扩展以用于序列分类:
在初始化模型之前,我们需要定义希望预测的类数目:
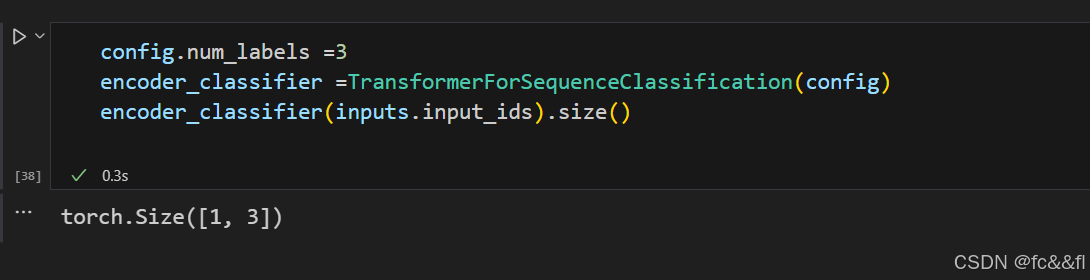
这正是我们一直在寻找的。对于批处理中的每个样本,我们会得到输 出中每个类别的非规范化logit值。这类似于我们在第2章中使用的 BERT模型(用于检测推文中的情感)。
至此我们对编码器以及如何将其与具体任务的头相组合的部分就结束 了。现在我们将注意力(双关语!)转向解码器。
3.解码器
解码器和编码器的主要区别在于解码器有两个注意力子 层:
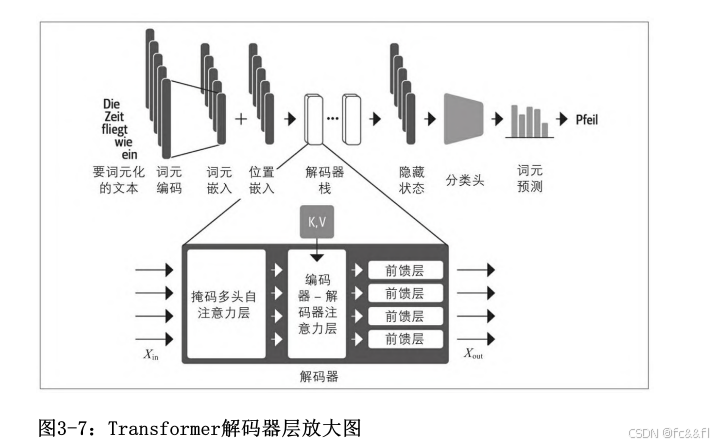
掩码多头自注意力层
确保我们在每个时间步生成的词元只基于过去的输出和当前正在预测 的词元。如果没有这样做,那么解码器将能够在训练时通过简单复制 目标翻译来欺骗我们,导致训练失败。我们需要对输入进行掩码,以 确保任务不是简单复制目标翻译。
编码器-解码器注意力层
请注意,与自注意力层不同,编码器-解码器注意力中的key和query向 量可能具有不同的长度。这是因为编码器和解码器输入通常涉及长度 不同的序列。因此,此层中的注意力得分矩阵是矩形的,而不是正方 形的。
对编码器栈的输出key和value向量执行多头注意力,并以解码器的中 间表示作为query 。在这种方式中,编码器-解码器注意力层学习如 何关联来自两个不同序列(例如两种不同语言)的词元。在每个块 中,解码器都可以访问编码器的key和value。
掩码自注意 力的技巧是引入一个掩码矩阵,该矩阵对角线下方的元素为1,上方的 元素为0:
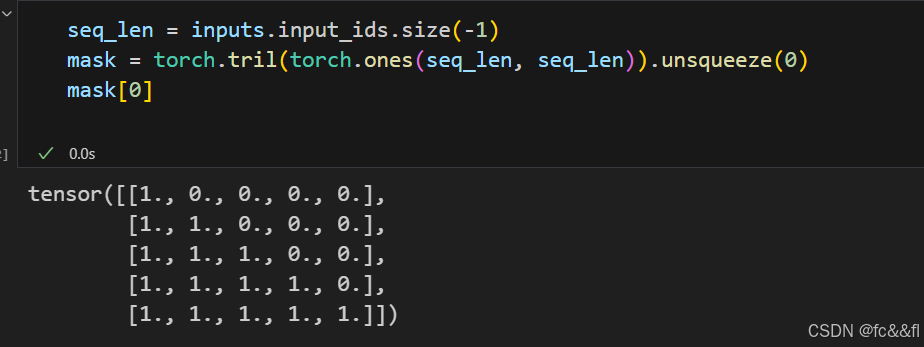
这里我们使用了PyTorch的tril()函数来创建下三角矩阵。一旦我们有 了这个掩码矩阵,我们可以使用Tensor.masked fill()将所有的0替 换为负无穷来防止每个注意力头查看后面的词元:
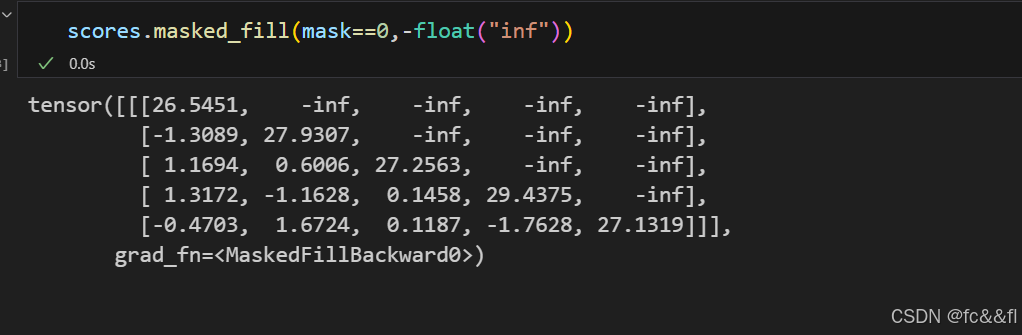
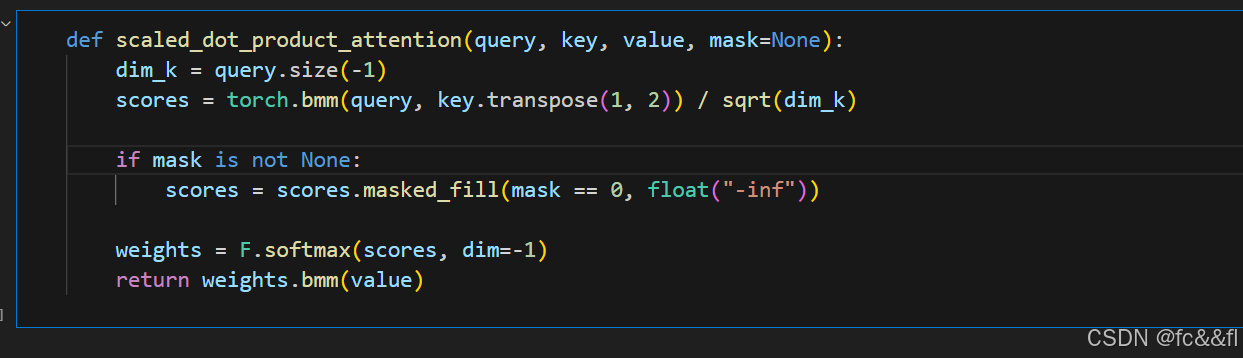
通过将矩阵对角线上方的值设为负无穷,可以保证当我们对分数进行 softmax时,注意力权重都为0,因为e-=0(回想一下softmax计算的是 规范化指数)。我们只需要对本章早先实现的缩放点积注意力函数进 行一点点修改,就能轻松地包含这种掩码行为:
在开始构建比文本分类更高级的 任务模型之前,我们稍微退后一步,看一看Transformer模型的各种分 支,以及它们之间的关系。
揭秘编码器-解码器注意力机制
这里我们用一个示例看看是否帮助你解开编码器-解码器注意力的神秘 面纱。想象一下,你(解码器)正在班上,参加一场考试。你的任务 是根据前面的单词(解码器输入)来预测下一个单词,听起来很简 单,但实际上非常难(你自己试试,预测本书的某一段的下一个单 词)。幸运的是,你旁边的同学(编码器)拥有整篇文章。不幸的 是,他们是留学生,文章是用他们的母语写的。不过聪明如你,你还 是想出了一种作弊的方式。你画了一幅小漫画,描述了你已经拥有的 文章内容(query),交给了你的同学。然后他们会尝试找出哪一段文 章与那个描述匹配(key),并画一幅漫画描述紧随该段文章之后的单 词(value),然后把这个答案传给你。有了这种系统性的帮助,你轻 松地通过了考试。
4.认识Transformer
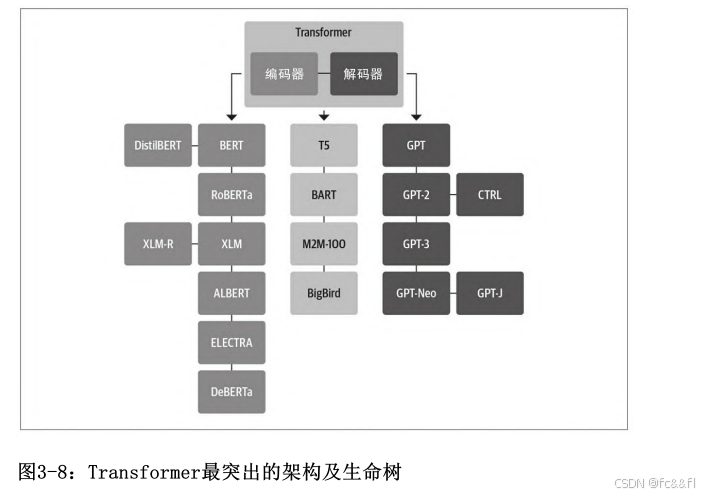
Transformer的生命树
随着时间的推移,三种主要的架构都进行了各自的演进。图3-8展示了 一些最著名的模型及其后代。 Transformer模型总计有超过50种不同的架构,因此图3-8未能涵盖所 有架构,它只列出了一些重要的里程碑。在本章前面部分,我们已经 详细介绍了Transformer模型最初的架构,现在我们着重研究一些比较 关键的后代架构,我们先从编码器分支开始。
5.本章小结
本章我们从Transformer架构的核心——自注意力机制的深入研究开 始,随后逐步添加了所有必要的组成部分来构建Transformer编码器模 型。我们添加了用于词元和位置信息的嵌入层,构建了一个前馈层以 补充注意力头,最后,我们往模型主体添加了一个分类头来进行预 测。我们还研究了Transformer架构的解码器部分,并在本章末尾浏览 了Transformer最重要的三种分支和模型架构。
第四章.多语言命名实体识别
1.数据集
本章我们将使用跨语言传输多语言编码器(XTREME)基准测试的子 集,即WikiANN,又称PAN-X 。该数据集包括多种语言的维基百科文 章,其中包括瑞士使用最广泛的四种语言:德语(62.8%)、法语 (22.9%)、意大利语(8.4%)和英语(5.9%)。每篇文章都用LOC (位置)、PER(人物)和ORG(组织)并以IOB2格式进行标注 (https://oreil.ly/yXMUn)。在IOB2这种格式中,B-前缀表示实体 的开头,位于之后的属于同一实体的连续词元则赋予I-前缀。O标记表 示该词元不属于任何实体。以如下句子为例:

要在XTREME中加载PAN-X的一个子集,我们需要知道要传给 load_dataset()函数的数据集配置。每当要处理具有多个领域的数据 集时,你可以使用get_dataset_config_names()函数来查找可用的子 集
有183个配置!太多了!我们需要缩小搜索范围,我们只寻找以 “PAN”开头的配置:
为了创建一个真实的瑞士语语料库,我们将从PAN-X中按照前面所述的 口语比例提取德语(de)、法语(fr)、意大利语(it)和英语 (en)语料库。我们这么做将会造成语言类别不平衡,这在现实世界 的数据集中非常普遍,其中由于缺乏熟练掌握该语言的领域专家,获 取少数民族语言的标注样本可能会很昂贵。这种不平衡的数据集将能 够模拟在多语言应用程序中工作时的常见情况,我们将看到如何构建 一个可以处理所有语言的模型。
为了追踪每种语言,我们创建一个Python defaultdict,将语言代码 作为key并将类型为DatasetDict的PAN-X语料库作为value进行存储:
这里我们使用shuffle()方法确保不会意外地偏向某个数据集拆分,而 select()方法允许我们根据fracs中的值对每个语料库进行下采样。然 后我们可以通过访问Dataset.num_rows属性来查看训练集中每种语言 的实例数量:

按照前面的设计,我们在德语方面拥有比其他所有语言加起来都多的 样本,所以我们将以德语作为起点,向法语、意大利语和英语进行零 样本跨语言迁移。
from collections import defaultdict, Counter
import pandas as pd
split2freqs = defaultdict(Counter)
for split, dataset in panx_de.items():
for row in dataset["ner_tags_str"]:
for tag in row:
if tag.startswith("B-"):
tag_type = tag[2:] # 获取 "B-" 后面的部分
split2freqs[split][tag_type] += 1
# 创建 DataFrame
df = pd.DataFrame.from_dict(split2freqs, orient="index")
print(df)
2.多语言Transformer
多语言Transformer模型通常以三种不 同的方式进行评估: en 在英语训练数据上进行微调,然后在每种语言的测试集上进行评估。 each 针对每种语言的测试数据进行微调和评估,以度量每种语言的性能。 all 在所有的训练数据上进行微调,然后在每种语言的测试数据集上进行 评估。
我们在本章中将使用XLM-R模型。
3.多语言词元化技术
XLM-R使用一种名为SentencePiece的词元分析器,而不是使用 WordPiece词元分析器。SentencePiece词元分析器是基于所有100种语 言的原始文本进行训练的。
SentencePiece词元分析器
SentencePiece词元分析器基于一种称为Unigram的子词分割类型,并 将每个输入文本编码为Unicode字符序列。这一特点对于处理多语言语 料库尤其有用,因为它能够忽略重音符号、标点符号以及许多语言 (如日语)中没有空格字符的情况。此外,SentencePiece的另一个特 别之处在于,它使用Unicode符号U+2581或者__字符(又称为下四分之 一块字符)来表示空格。这使得SentencePiece能够无歧义地反词元化 序列,也不需要依赖特定于语言的词元化预处理器。还是以我们前面 的示例为例,我们可以看到WordPiece丢失了“York”和“!”之间的 空格信息。而SentencePiece则保留了词元化后的文本中的空格,因此 我们可以无歧义地将其转换回原始文本。这一特性尤其适用于处理多 语言文本,因为它可以保持原始文本的完整性,而不会引入额外的歧 义。
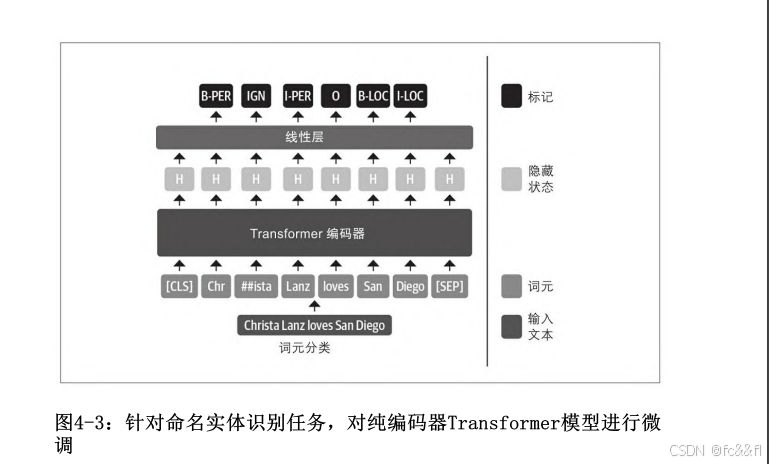
4.命名实体识别中的Transformers
5.自定义Hugging Face Transformers库模型类
我们已经看到,当我们从 预训练任务转换到下游任务时,我们需要用适合该任务的层替换模型 的最后一层。这个最后一层被称为模型头,它是与任务相关的部分
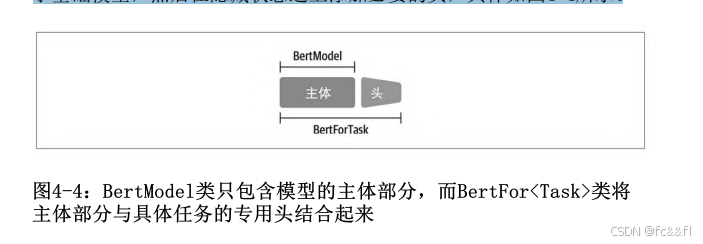
模型的其余部分称为主体,包括词元嵌入和Transformer层,这些层是 通用的、与任务无关的。这种结构表现在具体的代码实现类中,模型 主体在BertModel或GPT2Model之类的类中实现,这些类将返回最后一 层隐藏状态。而BertForMaskedLM或 BertForSequence Classification则为与任务相关的模型类,它们基 于基础模型,然后在隐藏状态之上添加必要的头,具体如图4-4所示。
创建用于词元分类的自定义模型
这里我们通过建立一个适用于XLM-R的自定义词元分类头的练习来进行 学习。由于XLM-R使用与RoBERTa相同的模型架构,因此我们将使用 RoBERTa作为基本模型,然后在此之上增加适用于XLM-R的设置。需要 注意的是,本练习出于教学目的,旨在向你展示如何为自己的任务构 建自定义模型。在实际工作中,对于词元分类, Hugging Face Transformers库已经有一个名为 XLMRobertaForTokenClassification的类可以使用,你可以直接导入 该类。
import torch.nn as nn
from transformers import XLMRobertaConfig
from transformers.modeling_outputs import TokenClassifierOutput
from transformers.models.roberta.modeling_roberta import RobertaModel
from transformers.models.roberta.modeling_roberta import RobertaPreTrainedModel
class XLMRobertaForTokenClassification(RobertaPreTrainedModel):
config_class = XLMRobertaConfig
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
# Load model body
self.roberta = RobertaModel(config, add_pooling_layer=False)
# Set up token classification head
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# Load and initialize weights
self.init_weights()
def forward(self, input_ids=None, attention_mask=None, token_type_ids=None, labels=None, **kwargs):
# Use model body to get encoder representations
outputs = self.roberta(input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids, **kwargs)
# Apply classifier to encoder representation
sequence_output = self.dropout(outputs[0])
logits = self.classifier(sequence_output)
# Calculate losses
loss = None
if labels is not None:
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
# Return model output object
return TokenClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions
)
加载自定义模型
现在我们准备加载词元分类模型。除了模型名称之外,我们还需要提 供一些额外的信息,包括我们将用于词元每个实体的标记以及每个标 记与ID之间的映射和反向映射。所有这些信息都可以从我们的tags变 量中进行推导,tags变量作为一个ClassLabel对象具有一个names属 性,我们可以使用它来推导映射:
第五章 文本生成
1.生成连贯文本的挑战
正如我们所看到的,对于像序列或词元分类这样的特定任务,生 成预测是相当简单的。模型产生一些logit,我们要么取最大值以获得 预测类,要么应用softmax函数以获得每个类的预测概率。相比之下, 将模型的概率输出转换为文本需要一种解码方法,这在文本生成中引 入了一些独特的挑战:
解码是迭代进行的,因此涉及的计算量比仅通过模型前向传递的一 次传输入要大得多。
生成的文本的质量和多样性取决于解码方法和相关的超参数的选 择。
2.贪婪搜索解码
1)从huggingface加载gpt2模型
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device ="cuda" if torch.cuda.is_available()else "cpu"
model_name ="gpt2"
tokenizer =AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)2)自己编写贪婪算法并使用
import pandas as pd
# 输入文本
input_txt = "Transformers are the"
input_ids = tokenizer(input_txt, return_tensors="pt")["input_ids"].to('cuda')
# 设置迭代参数
n_steps = 8
choices_per_step = 5
# 用于存储结果
iterations = []
# 不需要计算梯度
with torch.no_grad():
for step in range(n_steps):
iteration = dict()
iteration["Input"] = tokenizer.decode(input_ids[0])
# 生成模型输出
output = model(input_ids=input_ids)
# 获取最后一个token的logit并应用softmax
next_token_logits = output.logits[0, -1, :]
next_token_probs = torch.softmax(next_token_logits, dim=-1)
# 获取具有最高概率的tokens
sorted_ids = torch.argsort(next_token_probs, dim=-1, descending=True)
# 存储具有最高概率的tokens
for choice_idx in range(choices_per_step):
token_id = sorted_ids[choice_idx].item()
token_prob = next_token_probs[token_id].cpu().numpy()
token_choice = f"{tokenizer.decode([token_id])} ({100 * token_prob:.2f}%)"
iteration[f"Choice {choice_idx+1}"] = token_choice
# 选择下一个token(取最高概率的一个)
next_token_id = sorted_ids[0].item()
input_ids = torch.cat([input_ids, torch.tensor([[next_token_id]]).to('cuda')], dim=-1)
iterations.append(iteration)
# 转换结果为DataFrame以便于查看
df = pd.DataFrame(iterations)
print(df)
3)将使用 Hugging Face Transformers库内置的generate()函数来探索更复杂 的解码方法。
input_ids = tokenizer(input_txt, return_tensors="pt")["input_ids"].to(device)
output = model.generate(input_ids,max_new_tokens=n_steps, do_sample=False)
print(tokenizer.decode(output[0]))4)重现一开头的 OpenAI的独角兽故事
# 设置输入文本和最大长度
max_length = 128
input_txt = """In a shocking finding, scientist discovered
a herd of unicorns living in a remote, previously unexplored
valley, in the Andes Mountains. Even more surprising to the
researchers was the fact that the unicorns spoke perfect English.\n\n"""
# 将输入文本tokenize,并移动到GPU
input_ids = tokenizer(input_txt, return_tensors="pt")["input_ids"].to('cuda')
# 使用贪婪搜索生成输出
output_greedy = model.generate(input_ids, max_length=max_length, do_sample=False)
# 解码并打印输出
print(tokenizer.decode(output_greedy[0], skip_special_tokens=True))
5)贪婪搜索解码的一个主要缺点:
它往 往会产生重复的输出序列(最后两段是重复的),在新闻文章中这显 然是不可取的。这是贪婪搜索算法的一个常见问题,它们可能无法给 出最优解。在解码的上下文中,它们可能会错过整体概率更高的词序 列,只因为高概率的单词恰好在低概率的单词之前出现。 幸运的是,还有更好的方法——束搜索解码,这也是一种很流行的方 法。
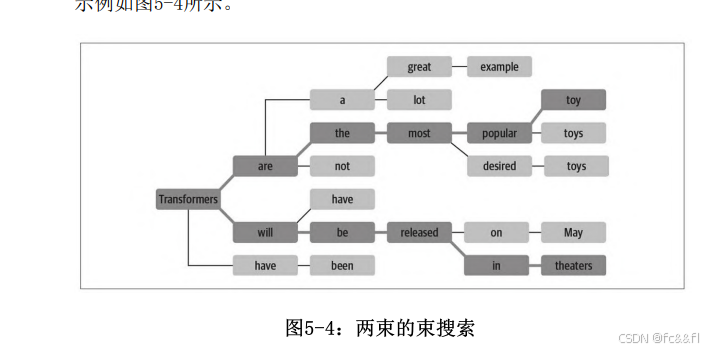
3.束搜索解码
不同于每次都选择概率最高的词元,束搜索会跟踪最有可能的下一个 top-b个词元,其中b称为束的数量或部分假设。下一个束是通过考虑 现有集合的所有可能的下一个词元扩展并选择最有可能的b个扩展而选 择的。该过程会一直重复,直到达到最大长度或遇到EOS词元,然后根 据它们的对数概率对b个束进行排名,选择最有可能的序列。束搜索的 示例如图5-4所示。
1)让我们计算并比较贪婪搜索和束搜索生成的文本的对数概率,以查看 束搜索是否可以提高总体概率。由于Hugging Face Transformers库 返回给定输入词元的下一个词元的非规范化logit,因此我们首先需要 规范化logit,以创建序列中每个词元在整个词表的概率分布。然后我 们需要选择仅存在于序列中的词元的概率。实现这些步骤的具体函数 如下:
import torch.nn.functional as F
def log_probs_from_logits(logits, labels):
logp =F.log_softmax(logits,dim=-1)
logp_label =torch.gather(logp,2,labels.unsqueeze(2)).squeeze(-1)
return logp_label以上函数给出了单个词元的对数概率,如果要获得序列的总对数概 率,我们只需将每个词元的对数概率相加。
def sequence_logprob(model,labels,input_len=0):
with torch.no_grad():
output =model(labels)
log_probs =log_probs_from_logits(
output.logits[:,:-1,:],labels[:,1:])
seq_log_prob =torch.sum(log_probs[:,input_len:])
return seq_log_prob.cpu().numpy()2)我们首先使用这些函数来计算对OpenAI提示使用贪婪解码器的序列对 数概率:
logp =sequence_logprob(model, output_greedy, input_len=len(input_ids[0]))
print(tokenizer.decode(output_greedy[0]))
print(f"\nlog-prob:{logp:.2f}")3)现在我们来比较一下使用束搜索生成的序列。使用generate()函数并 指定num_beams参数的数量即可激活束搜索。我们选择的束数越多,结 果就可能越好。但是,生成过程变得更慢,因为我们要为每个束生成 并行序列:
output_beam = model.generate(input_ids,max_length=max_length, num_beams=5,do_sample=False)
logp =sequence_logprob(model,output_beam, input_len=len(input_ids[0]))
print(tokenizer.decode(output_beam[0]))
print(f"\nlog-prob:{logp:.2f}")4)我们可以看到,使用束搜索相较于简单的贪婪解码,得到了更好的对 数概率值(数值越高越好)。然而,我们可以看到束搜索一样存在重 复文本的问题。解决这个问题的一种方式是通过 no_repeat_ngram_size参数施加n-gram惩罚,该参数会跟踪已经出现 的n-gram并将下一个词元的概率设置为零,从而避免产生先前出现过 的n-gram:
output_beam = model.generate(input_ids,max_length=max_length, num_beams=5,do_sample=False,no_repeat_ngram_size=2)
logp =sequence_logprob(model,output_beam, input_len=len(input_ids[0]))
print(tokenizer.decode(output_beam[0]))
print(f"\nlog-prob:{logp:.2f}")4.采样方法
我们可以从温度中得到的主要教训是,它允许我 们控制样本的质量,但在连贯性(低温度)和多样性(高温度)之间 总是存在一个权衡,需要根据具体应用场景进行调整。
另一种调整连贯性和多样性之间权衡的方法是截断词汇的分布。这允 许我们自由地使用温度来调整多样性,但在一个更有限的范围内排除 在上下文中过于奇怪的词汇(即低概率词)。有两种主要方法:top-k 和核(或top-p)采样。
5.top-k和核采样
top-k和核(top-p)采样是使用温度的两种流行的替代或扩展方法。 在这两种情况下,基本思想是限制每个时间步可以采样的可能词元数 量。
top-k采样的思想是通过仅从具有最高概率的k个词元中进行采样来避 免低概率选择。这对分布的长尾部分施加了固定的截断,并确保我们 只从可能的选择中进行采样。
output_topk= model.generate(input_ids,top_k=50,max_length=max_length,do_sample=True)
print(tokenizer.decode(output_topk[0]))
一种替代方法是使用动态截断。在核(top-p)采样中,我们不选择固 定的截断值,而是设定一个当达到一定概率质量时的截断条件。假设 我们将该值设定为95%。然后,我们按概率降序排序所有词元,并从列 表顶部逐个添加词元,直到所选词元的概率之和达到95%。回到图5- 6,p的值定义了概率累积总和图上的水平线,我们仅从线下词元中进 行采样。根据输出分布的不同,可能只有一个(非常可能)词元或一 百个(等可能)词元。讲到这里,generate()函数还提供了一个激活 top-p采样的参数。
output_topk= model.generate(input_ids,top_k=50,max_length=max_length,do_sample=True,top_p=0.9)
print(tokenizer.decode(output_topk[0]))
由上可见,top-p采样方法也产生了一个连贯的故事,这次的新变化是 这些独角兽从澳大利亚迁徙到南美洲。你甚至可以结合这两种采样方 法,以兼顾两者的优点。设置top_k=50和top_p=0.9,表示从最多50个 词元中选择概率质量为90%的词元。
6.哪种解码方法最好
不幸的是,目前没有一种通用的最佳解码方法。最好的方法将取决于 你生成文本的任务性质。如果你想让你的模型执行像算术或提供特定 问题答案这样的精确任务,那么你应该降低温度或使用确定性方法, 如将贪婪搜索与束搜索相结合,以确保获得最可能的答案。如果你想 让模型生成更长的文本,甚至有点创造性,那么你应该切换采样方 法,增加温度或使用top-k和核采样的混合方法。
7.本章小结
在本章中,我们探讨了文本生成,这是与我们之前遇到的NLU任务非常 不同的任务。生成文本至少需要每个生成的词元进行一次前向传递, 如果使用束搜索则需要更多。这使得文本生成在计算上非常耗费,需 要适当的基础设施才能以规模运行文本生成模型。此外,一个好的解 码策略可以将模型的输出概率转化为离散的词元,从而提高文本的质 量。找到最佳的解码策略需要一些实验和对生成的文本进行主观评 估。 然而在实践中,仅凭直觉做出这些决策是不可取的!就像其他NLP任务 一样,我们应该选择一个反映我们想要解决问题的模型性能度量指 标。毫不奇怪,有很多选择,在第6章中我们将遇到最常见的选择,我 们将介绍如何训练和评估文本摘要模型。
第六章 文本摘要
本章将探讨如何利用Transformer预训练 模型来进行文本摘要。摘要是一种经典的序列到序列(seq2seq)任 务,需要输入文本和目标文本。正如我们在第1章中看到的那样, Transformer模型是一个出色的编码器-解码器架构。
在本章中,我们将建立自己的编码器-解码器模型,将多人对话压缩成 简明的摘要。但在此之前,我们先来看看摘要领域中一个经典数据 集:CNN/DailyMail语料库。
1.CNN/DailyMail数据集
from datasets import load_dataset
# 加载数据集
dataset = load_dataset("cnn_dailymail", "3.0.0")
# 打印数据集特征
print(f"Features: {dataset['train'].column_names}")
数据集有三列:article列包含新闻文章;highlights列包含摘要;id 列是每篇文章的唯一标识。
2.摘要基准
一种常见的新闻文章摘要基准是简单地取文章的前三句话。使用NLTK 的句子词元分析器,我们可以轻松实现这样的基准:

3.GPT-2生成摘要
from transformers import pipeline, set_seed
import nltk
from nltk.tokenize import sent_tokenize
# 设置随机种子
set_seed(42)
# 初始化生成文本的 pipeline
pipe = pipeline("text-generation", model="gpt2")
# 取前2000个样本并连接成一个字符串
sample_text = dataset["train"][1]["article"][:2000]
# 构建 GPT-2 查询
gpt2_query = sample_text + "\nTL;DR:\n"
# 使用 GPT-2 生成文本
pipe_out = pipe(gpt2_query, max_length=512, clean_up_tokenization_spaces=True)
# 将生成的文本切分为句子,并存储在 summaries 字典中
summaries = {}
summaries["gpt2"] = "\n".join(sent_tokenize(pipe_out[0]["generated_text"][len(gpt2_query):]))
# 打印摘要
print(summaries["gpt2"])
4.T5生成摘要
pipe=pipeline("summarization",model="t5-large")
pipe_out=pipe(sample_text)
summaries["t5"]="\n".join(sent_tokenize(pipe_out[0]["summary_text"]))5.BART
pipe=pipeline("summarization",model="facebook/bart-large-cnn")
pipe_out=pipe(sample_text)
summaries["bart"]="\n".join(sent_tokenize(pipe_out[0]["summary_text"]))6.PEGASUS
pipe=pipeline("summarization",model="google/pegasus-cnn_dailymail")
pipe_out=pipe(sample_text)
summaries["pegasus"]="\n".join(sent_tokenize(pipe_out[0]["summary_text"]))7.比较不同的摘要
现在我们已经用四个不同的模型生成了摘要,我们来比较一下它们的 结果。请记住,其中一个模型根本没有在数据集上进行训练(GPT2),一个模型在执行其他任务的同时进行了微调(T5),而另外两个 模型则专门针对这个任务进行了微调(BART和PEGASUS)。我们来看看 这些模型生成的摘要


理想情况下,我们将定义一个指标,在一些基准数据集上为所 有模型进行度量,并选择性能最佳的那一个。但是,如何为文本生成 定义一个指标呢?我们所看到的标准指标,如准确率、查准率和召回 率,都不易用于此任务。对于每个由人类撰写的“黄金标准”摘要, 可能有数十个可接受的摘要(通过同义词、释义或稍微不同的表达方 式)。 接下来我们将探讨一些常见的、用来度量生成文本的质量的指标
8.度量生成文本的质量
两个最常用的用于评估生成文本的度量指标是BLEU和ROUGE。我们看看 它们的定义。
1)BLEU
BLEU的思想很简单 :与其看生成文本中有多少个词元与参考文本的 词元完全对齐,不如看单词或n-gram。BLEU是基于查准率的度量指 标,这意味着当我们比较两个文本时,我们计算生成文本中出现在参 考文本中的单词数,并将其除以生成文本的长度。 然而,这种普通的查准率存在一个问题。假设生成文本只是一遍又一 遍地重复同一个单词,并且这个单词也出现在参考文本中。如果它重 复了与参考文本长度相同的次数,那么我们就得到了完美的查准率! 因此,BLEU论文的作者引入了一个轻微的修改:只计算一个单词在参 考文本中出现的次数。这里举一个例子,假设我们的参考文本为 “the cat is on the mat”,生成文本为 “the the the the the the”。
总的来说,文本生成领域仍在寻找更好的度量指标,克服BLEU等指标 的局限性是当前研究的一个活跃领域。BLEU指标的另一个缺点是它期 望文本已经进行了词元化。如果没有使用完全相同的文本词元化方 法,则可能会导致不同的结果。SacreBLEU指标通过内置词元化步骤来 解决这个问题。因此,它是基准测试的首选指标。
.通过代码计算生成文本的分 数。
!pip install sacrebleu
from datasets import load_metric
bleu_metric=load_metric("sacrebleu")bleu metric对象是Metric类的一个实例,它的工作方式类似于聚合 器:你可以使用add()添加单个实例,也可以通过add batch()添加整 个批量。在添加完需要评估的所有样本之后,调用compute()即可计算 指标。然后会返回一个包含多个值的字典,包括每个n-gram的查准 率、长度惩罚以及最终的BLEU分数。现在我们将bleu metric对象应 用于之前的示例:
import pandas as pd
import numpy as np
from datasets import load_metric
# 加载BLEU度量
bleu_metric = load_metric("bleu")
# 添加预测和参考
bleu_metric.add(prediction="the the the the the the", reference=["the cat is on the mat"])
# 计算BLEU分数
results = bleu_metric.compute(smooth_method="floor", smooth_value=0)
# 处理结果
# 将precisions中的每个值四舍五入到小数点后两位
precisions_rounded = np.round(results["precisions"], 2)
# 创建结果的DataFrame
results_df = pd.DataFrame.from_dict(results, orient="index", columns=["Value"])
# 显示结果
print(results_df)
2)ROUGE
9.在CNN/DailyMail数据集上评估PEGASUS
现在充分评估模型的条件都齐全了:我们拥有CNN/DailyMail测试集数 据集、评估用的ROUGE指标,以及一个摘要模型。我们只需要把这些部 分组合起来。首先,我们评估三句话基准模型的性能
def evaluate_summaries_baseline(dataset, metric, column_text="article", column_summary="highlights"):
# 生成摘要
summaries = [three_sentence_summary(text) for text in dataset[column_text]]
# 添加预测和参考
metric.add_batch(predictions=summaries, references=dataset[column_summary])
# 计算得分
score = metric.compute()
return score
然后我们把该函数应用于数据的一个子集。由于CNN/DailyMail数据集 的测试部分包含大约10 000个样本,生成所有这些文章的摘要需要很 多时间。回顾第5章,每个生成的词元都需要通过模型进行前向传递。 为每个样本生成100个词元将需要100万次前向传递,如果我们使用束 搜索,则此数字还需要乘以束的数量。为了让计算更快一些,我们将 对测试集进行子采样,最终使用1000个样本进行评估。这样我们使用 单个GPU上不到一小时就能完成PEGASUS模型的评估,而且得到稳定的 分数估计:
import pandas as pd
from datasets import load_metric
def evaluate_summaries_baseline(dataset, metric, column_text="article", column_summary="highlights"):
# 生成摘要
summaries = [three_sentence_summary(text) for text in dataset[column_text]]
# 添加预测和参考
metric.add_batch(predictions=summaries, references=dataset[column_summary])
# 计算得分
score = metric.compute()
return score
# 加载ROUGE度量
rouge_metric = load_metric("rouge")
# 选择测试数据中的1000个样本并打乱
test_sampled = dataset["test"].shuffle(seed=42).select(range(1000))
# 评估摘要
score = evaluate_summaries_baseline(test_sampled, rouge_metric)
# 提取ROUGE指标名称
rouge_names = score.keys()
# 格式化得分为字典
rouge_dict = {rn: score[rn]['mid']['fmeasure'] for rn in rouge_names}
# 转换为DataFrame并打印
df = pd.DataFrame.from_dict(rouge_dict, orient="index", columns=["baseline"]).T
print(df)
由于ROUGE和BLEU比人工评估的损失或准确率更好,因此在构建文本生 成模型时应重点关注它们,并仔细探索和选择解码策略。然而,这些 指标远非完美,因此应始终考虑人工评估。 现在我们已经有了评估函数,可以训练我们自己的摘要模型了。
10.训练摘要模型
1)我们将使用三星开发的SAMSum数据集 (https://oreil.ly/n1ggq),该数据集包含了一系列对话以及简短 的摘要。这些对话可以代表客户与客服中心之间的互动,并以此生成 准确的摘要以帮助改善客户服务,并检测客户请求中的常见模式。我 们先加载数据集并查看一个样本:
dataset_samsum = load_dataset("samsum", cache_dir=None,encoding='utf-8')
加入后面的参数解决'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte的bug
不,pip install py7zr才可以解决这个bug,去掉上面的encoding参数
from datasets import load_dataset
# 删除缓存
dataset_samsum = load_dataset("samsum", cache_dir=None)
split_lengths =[len(dataset_samsum[split])for split in dataset_samsum]
print(f"Split lengths:{split_lengths}")
print(f"Features:{dataset_samsum['train'].column_names}")
print("\nDialogue:")
print(dataset_samsum["test"][0]["dialogue" ])
print("\nSummary:")
print(dataset_samsum["test" ][0]["summary" ])2)评估PEGASUS在SAMSum上的性能
from datasets import load_dataset, load_metric
from transformers import PegasusTokenizer, PegasusForConditionalGeneration, pipeline
import pandas as pd
# 加载数据集
dataset_samsum = load_dataset("samsum")
# 加载模型和tokenizer
model_name = "google/pegasus-xsum"
model = PegasusForConditionalGeneration.from_pretrained(model_name)
tokenizer = PegasusTokenizer.from_pretrained(model_name)
# 初始化文本生成管道
pipe = pipeline("text-generation", model=model_name, tokenizer=tokenizer)
# 生成文本
pipe_out = pipe(dataset_samsum["test"][0]["dialogue"], max_length=1024)
# 加载ROUGE评估指标
rouge_metric = load_metric("rouge")
# 定义ROUGE评估函数
def evaluate_summaries_pegasus(dataset, metric, model, tokenizer, batch_size=16, device=torch.device('cuda' if torch.cuda.is_available() else 'cpu'), column_text="article", column_summary="highlights"):
def chunks(data, batch_size):
for i in range(0, len(data), batch_size):
yield data[i:i + batch_size]
article_batches = list(chunks(dataset[column_text], batch_size))
target_batches = list(chunks(dataset[column_summary], batch_size))
for article_batch, target_batch in tqdm(zip(article_batches, target_batches), total=len(article_batches)):
inputs = tokenizer(article_batch, max_length=1024, truncation=True, padding="max_length", return_tensors="pt")
summaries = model.generate(
input_ids=inputs["input_ids"].to(device),
attention_mask=inputs["attention_mask"].to(device),
length_penalty=0.8,
num_beams=8,
max_length=128
)
decoded_summaries = [tokenizer.decode(s, skip_special_tokens=True, clean_up_tokenization_spaces=True) for s in summaries]
decoded_summaries = [d.replace("<n>", " ") for d in decoded_summaries]
metric.add_batch(predictions=decoded_summaries, references=target_batch)
score = metric.compute()
return score
# 评估摘要
score = evaluate_summaries_pegasus(dataset_samsum["test"], rouge_metric, model, tokenizer, column_text="dialogue", column_summary="summary", batch_size=8)
# 获取ROUGE分数
rouge_names = ["rouge1", "rouge2", "rougeL", "rougeLsum"]
rouge_dict = {rn: score[rn].mid.fmeasure for rn in rouge_names}
# 转换为DataFrame
df_rouge = pd.DataFrame(rouge_dict, index=["pegasus"])
print(df_rouge)
3)微调PEGASUS
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir='pegasus-samsum',
num_train_epochs=1,
warmup_steps=500,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
weight_decay=0.01,
logging_steps=10,
push_to_hub=True,
evaluation_strategy='steps',
eval_steps=500,
save_steps=int(1e6),
gradient_accumulation_steps=16
)
trainer = Trainer(
model=model,
args=training_args,
tokenizer=tokenizer,
data_collator=seq2seq_data_collator,
train_dataset=dataset_samsum["train"],
eval_dataset=dataset_samsum["validation"]
)
# 开始训练
trainer.train()
# 定义rouge_metric
from datasets import load_metric
rouge_metric = load_metric("rouge")
# 评估
score = evaluate_summaries_pegasus(
dataset_samsum["test"],
rouge_metric,
trainer.model,
tokenizer,
batch_size=2,
column_text="dialogue",
column_summary="summary"
)
# 生成rouge_dict
rouge_dict = {rn: score[rn].mid.fmeasure for rn in rouge_metric.compute().keys()}
# 创建DataFrame
import pandas as pd
pd.DataFrame(rouge_dict, index=["pegasus"])
第七章构建问答系统
1.构建基于评论的问答系统
1)准备数据集
本书使用SubjQA数据集 来构建问答系统,该数据集包含10 000多条 关于商品和服务的英文用户评论,涉及六个领域:旅行社、餐厅、电 影、书籍、电子产品和杂货店。如图7-2所示,每条数据都包含一个问 题和一个评论,评论里面会有一个或多个词条可以准确回答该问题
本次示例将专注为电子领域(上面的electronics)构建问答系统。在 确定了领域之后,便要开始加载electronics数据子集,我们将该值传 给load_dataset()函数的name参数即可:
from datasets import load_dataset
subjqa=load_dataset("subjqa",name="electronics")
subjqa

对于文本分类等其他场景,最常用的方法是将超出长度的文本直接截 断并丢弃,因为即使缺失一部分文档,也能得出正确的分类预测结 果。但在问答场景,这种做法是有问题的,因为问题的答案很可能位 于上下文的末尾附近。
,处理这种问题的标准方法是在输 入上加一个滑动窗口,将原始长文本处理成多个短文本,其中每个窗 口都包含完全适配模型上下文的词元数量。
Hugging Face Transformers库提供了相关的API,可以在词元分析 器中设置return_overflowing_tokens=True来启用滑动窗口功能,滑 动窗口的大小由max_seq_length参数控制,步幅大小则由doc stride 参数控制。
2.用Haystack构建问答pipelin
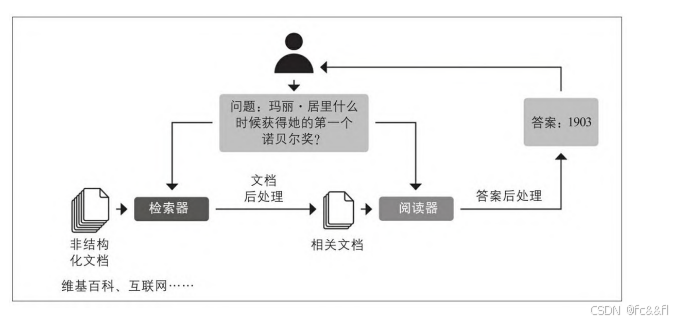
现在的问答系统通常都基于检索器-阅读器 (Retriever-Reader)架构,从名称就可以看出,这种架构有两个主 要组件:
检索器
如果向量的大部分元素为0,则称该向量是稀疏向量。
检索器(Retriever)旨在为给定查询操作检索相关文档,目前的检索 器通常分为三类:稀疏检索器(Sparse Retriever)、密集检索器 (Dense Retriever)和迭代检索器(Iterative Retriever)。稀 疏检索器使用词频将每个文档和查询表示为一个稀疏向量 (sparse vector) ,然后通过计算向量内积来确定查询和文档的 相关性,但稀疏检索不能解决术语不匹配问题,在问题与文档相似但 不存在重复术语的情况下,稀疏检索效果较差。随着深度学习的逐渐 成熟,发展出了密集检索器,密集检索器使用类似Transformer的编码 器将查询和文档表示为上下文嵌入(密集向量)。这些嵌入将语义编 码,通过理解查询内容来提高搜索准确率。迭代检索器则是通过多次 迭代从大集合从检索相关文档。
阅读器
阅读器(Reader)旨在从检索器输出的文档中提取答案。阅读器通常 是一个阅读理解模型,在本章末尾我们将见到可以生成具有自由格式 答案的模型样例。
如图7-9所示,还有其他组件能对检索器获取的文档或阅读器提取的答 案做后处理。例如,检索出来的文档可能需要以重新排序的方式,来 消除噪声或那些可能让使用者无法理解的文档。同样,当正确答案来 自长文档不同段落时,通常需要对答案进行后处理。
我们将使用Haystack库(https://haystack.deepset.ai)来构建问答 系统,它是一家专注于NLP领域的德国公司deepset (https://deepset.ai)所开发的。Haystack基于检索器-阅读器架 构,它将构建问答系统的大部分复杂性抽象出来,并与 Hugging Face Transformers库紧密集成。
Document Store
文档存储器,用于存储在检索时提供给检索器的文档和元数据。
Pipeline
流程控制器,封装了问答系统所有流程组件,用以编写自定义检索流 程或者合并多个检索器处理后的文档等。
在本章中会使用稀疏检索器和密集检索器,因此这里选用 Elasticsearch作为文档存储器,

初始化检索器
from haystack.document_store.elasticsearch import ElasticsearchDocumentStore
document_store=ElasticsearchDocumentStore(return_embedding=True)
初始化阅读器
第八章 Transformer模型调优
在本章中,我们将探讨四种互补技术,可用于加速你的Transformer模 型的预测并减少内存使用:知识蒸馏、量化、剪枝和使用 Open Neural Network Exchange(ONNX)格式和ONNX Runtime (ORT)进行图优化。
1.创建性能基准
2.第一个压缩技术:知 识蒸馏。
知识蒸馏是一种通用的方法,用于训练一个较小的学生模型来模仿一 个更慢但表现更好的较大的教师模型的行为。这种方法最初在2016年 集成模型的背景下引入 ,后来在一篇著名的2015年的论文中得到推 广。其被推广到深度神经网络,并应用于图像分类和自动语音识别 。
微调知识蒸馏
为在许多情况下,教师模型会给一个 类别分配高概率,而其他类别的概率接近于零。当出现这种情况时, 教师模型除了提供基准标注外,并没有提供太多附加信息,所以我们 在应用softmax前,会使用一个超参数温度T对logit进行缩放,以使概 率变得“更软” :
基于知识蒸馏的预训练技术
知识蒸馏还可以在预训练期间使用,我们可以创建一个通用的学生模 型,随后可对下游任务进行微调。在这种情况下,教师模型是一个预 训练语言模型,例如BERT,它将其关于掩码语言建模的知识迁移给学 生模型。例如,在DistilBERT论文中 ,掩码语言建模损失L由知识蒸 馏术语和余弦嵌入损失L=1-cos(hs,ht)扩展,以调整教师模型和学 生模型之间的隐藏状态向量方向:
由于我们已经有了经过微调的BERT-base模型,我们看看如何使用知识 蒸馏来微调更小、更快的模型。为了实现这一点,我们需要一种将交 叉熵损失与LKD项相结合的方法。幸运的是,我们可以通过创建自己的 训练器来做到这一点!
创建知识蒸馏训练器
从文献上来看,一个好的经验法则 是当教师模型和学生模型为同一模型类型时,知识蒸馏效果最好 。 这种情况的一个可能原因是不同的模型类型,比如BERT和RoBERTa,可 以具有不同的输出嵌入空间,这会阻碍学生模型模仿教师模型的能 力。在我们的案例研究中,教师模型是BERT,因此DistilBERT是一个 很自然的备选项,因为它的参数数量少了40%,并且已经被证明在下游 任务上取得了强大的结果。
3.利用量化技术使模型运算更快
4.使用权重剪枝使模型更稀疏
5.使用ONNX和ONNX Runtime进行推理优化
第九章.零样本学习和少样本学习
GPT-3模 型甚至可以仅用几十个样本就能处理各种不同的任务