这个环境的系统性能一直无法提升,能否帮我找到系统的瓶颈在哪里?
系统优化后,虽然写入性能有所提升,但查询延迟却增加了,下一步我该如何排查和优化呢?
请帮我查看系统出现问题时的 CPU、磁盘和内存等资源使用情况,是否是由于资源紧张导致的问题?
在实际的工程应用和架构严谨的过程中,相信大家对于上面的几个问题并不陌生。当软件实际的工业环境中被应用时,“案发现场”究竟是什么样的直接关乎我们的应对策略;面对系统性能调优时,系统的瓶颈点如何快速定位成为难题;在系统架构严谨过程中,不同模块的运行情况以及协同情况成为我们迫切需要关注的内容。
1. 可观测性
而随着分布式架构渐成主流,可观测性(Observability)一词也日益频繁地被人提起。最初,它与可控制性(Controllability)一起,是由匈牙利数学家 Rudolf E. Kálmán 针对线性动态控制系统提出的一组对偶属性,原本的含义是“可以由其外部输出推断其内部状态的程度”。
在学术界,虽然“可观测性”这个名词是近几年才从控制理论中借用的舶来概念,不过其内容实际在计算机科学中已有多年的实践积累。学术界一般会将可观测性分解为三个更具体方向进行研究,分别是:事件日志、链路追踪和聚合度量,这三个方向各有侧重,又不是完全独立,它们天然就有重合或者可以结合之处,2017 年的分布式追踪峰会(2017 Distributed Tracing Summit)结束后,Peter Bourgon 撰写了总结文章《Metrics, Tracing, and Logging》系统地阐述了这三者的定义、特征,以及它们之间的关系与差异,受到了业界的广泛认可。
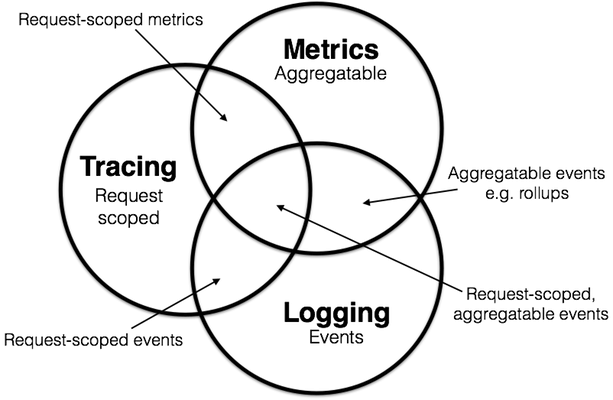
2. Apache IoTDB 分布式系统监控
在分布式场景下,采用事件日志的方式进行系统观测效率较低,因此链路追踪和聚合度量成为更优选择。自 Apache IoTDB 1.0.0 版本以来,Apache IoTDB 开始构建系统监控模块,完成了分布式架构下的系统监控框架的搭建、系统监控指标的定义与管理以及系统监控指标的采集。该监控模块支持系统各个模块在开发过程中平滑地新增监控指标,并由监控框架统一进行管理。
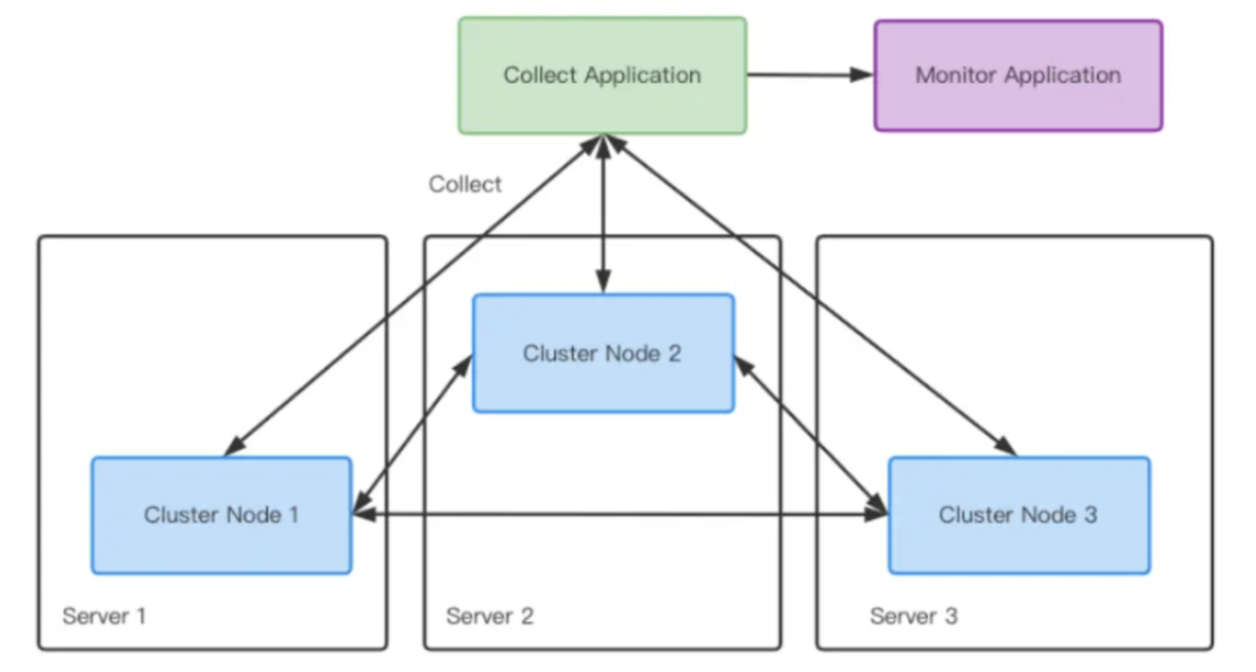
Apache IoTDB 分布式架构通过 Prometheus 和 Grafana 实现系统监控指标的采集与可视化。该系统结合了自顶向下的负载视角和自底向上的资源视角,能够有效监控集群状态,支持系统瓶颈定位、性能调优以及问题解决等多种场景。目前,IoTDB 提供了上千个监控指标,但其对性能的影响却不到 5%。因此,我们推荐所有用户开启监控模块,以保障线上 IoTDB 的高效运行。

3. 总结
本篇文章是《关于监控不得不说的故事》系列的第一篇。后续文章将详细介绍 Apache IoTDB 各类监控项的基本情况和使用方法,展示其在解决性能问题和故障排查方面的卓越能力。我们将与大家一起深入探索 Apache IoTDB 与监控的精彩故事,敬请期待!