论文地址:https://arxiv.org/abs/2412.02205
一 背景&目的
1.1 背景
商业智能 (BI) 旨在将大量数据转化为可用的见解,以便做出明智的决策 。典型的 BI 工作流包括多个阶段,例如数据准备、分析和可视化。它需要数据工程师、科学家和分析师使用各种专业工具(例如 Visual Studio Code、Power BI、Tableau)进行协作,这可能非常乏味且耗时 。因此,现代组织需要先进的技术来自动化和优化此工作流程。
由大型语言模型 (LLMs)提供支持的agent最新进展为简化 BI 工作流程提供了潜力。通过接收自然语言 (NL) 中的指令,LLM-based agents在可执行环境中执行任务规划、推理和动作。可显著降低 BI 任务的复杂性,例如代码生成 、文本到可视化的翻译和自动洞察发现。
以前关于BI 的LLM-based agents缺点:
- 工作主要关注单个任务或阶段,而没有将 BI 工作流作为一个整体考虑。
- 跨不同数据角色和工具的 BI 任务分离阻碍了无缝的信息流和洞察交流,增加了通信成本、延迟和错误。
- 由于 BI 的迭代和协作性质,这种依赖需要分析师和工程师之间来回沟通。
这些程序突出了现有碎片化和固定代理管道的局限性,因此,这导致不同角色、任务和工具之间存在巨大差距,从而阻碍了及时和明智的决策。
1.2 目的
目标是将 BI 工作流与基于一站式LLM的代理框架统一在一个环境中,以满足各种数据角色的要求
二 挑战
DataLab面临的挑战
- 对自适应LLM上下文管理的需求
- 上下文管理:在计算笔记本环境中,如何有效地管理和利用上下文信息是一个关键挑战。上下文信息的有效利用可以提高任务的执行效率和准确性。
- 策略需求:需要一种策略来提高代理在笔记本中的上下文利用能力,以实现更高的效率和成本效益。
- 信息冗余:简单地提供所有上下文信息可能导致信息冗余和高 token 成本,因此需要优化上下文信息的提取和利用。
- 任务之间的信息共享不足
- 任务复杂性:复杂的 BI 任务往往需要多个agent之间的协作,以完成多步骤推理和数据处理。许多现有的多智能体框架,如 ChatDev [ 16] 和 CAMEL [ 17],使用非结构化的自然语言进行通信。这可能会导致失真 [ 18],并且不足以处理 BI 任务的复杂性,这些任务通常涉及不同的信息类型(例如,数据、图表、文本)。
- 信息共享机制:一个有效且高效的代理间通信机制对于使他们对整体分析目标、当前数据上下文和执行动作的理解保持一致至关重要
- 协作效率:需要一种机制来协调多个代理的工作,确保任务的高效执行和结果的准确性。
- 缺乏领域知识整合
- 知识需求:将领域知识有效地整合到 LLM 中以提高其在特定任务上的表现是一个挑战。BI 任务通常涉及大型和肮脏的真实数据集,具有许多歧义。例如,业务数据表中的列名可能具有不明确的语义含义,并且用户查询通常包含特定于企业的术语。领域知识可以帮助 LLM 更好地理解和处理复杂的业务数据。
- 系统方法:需要一种系统的方法来生成、组织和利用领域知识。这包括数据的预处理、知识的提取和知识的更新。
- 知识更新:由于企业数据的动态性和复杂性,领域知识需要不断更新和维护,以保持其时效性和准确性。
三 解决方案
3.1 主要贡献
- DataLab,将 BI 工作流与基于一站式LLM的agent框架和jupyter notebook界面的集成统一起来的平台,以弥合不同角色、任务和工具之间的差距
- 开发了一种系统的方法,用于领域知识整合,以提高LLM-based agents在实际环境中完成企业特定 BI 任务的性能。
- 引入结构化的通信机制来制定不同agent之间的信息共享流程,以促进跨任务执行
- 提出了一种自适应上下文管理策略,以提高代理在计算笔记本中的上下文利用能力,以提高效率和成本效益。
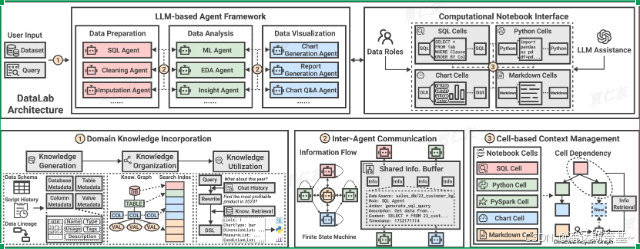
3.2 概述
3.2.1 架构
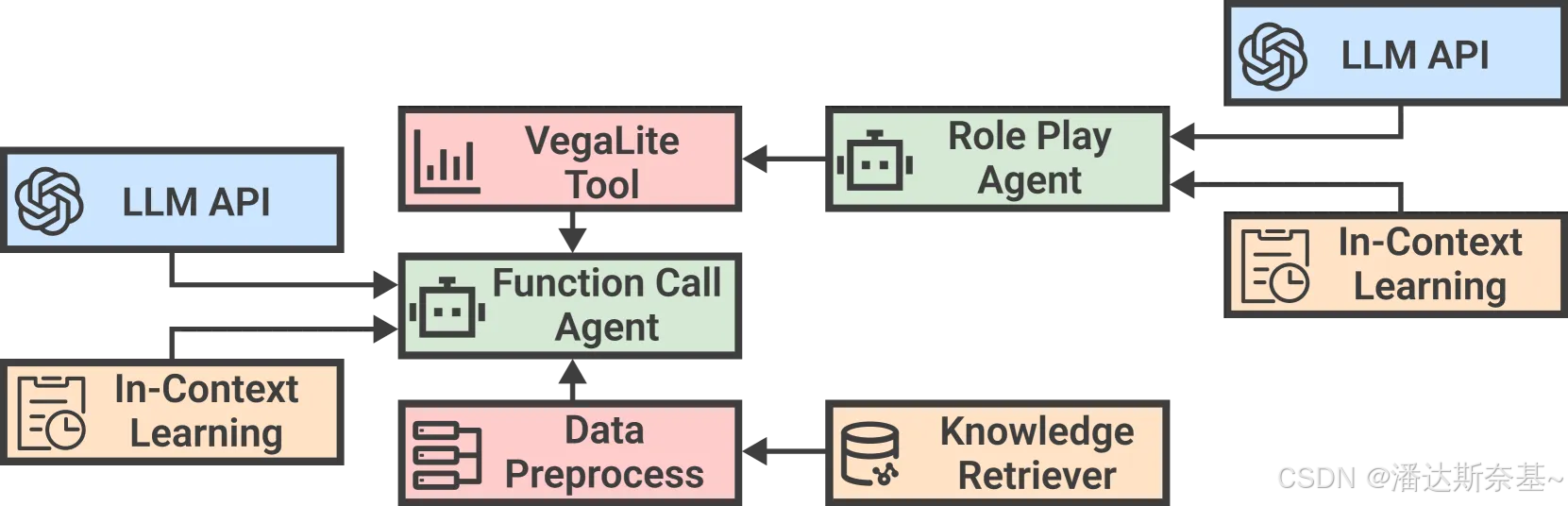
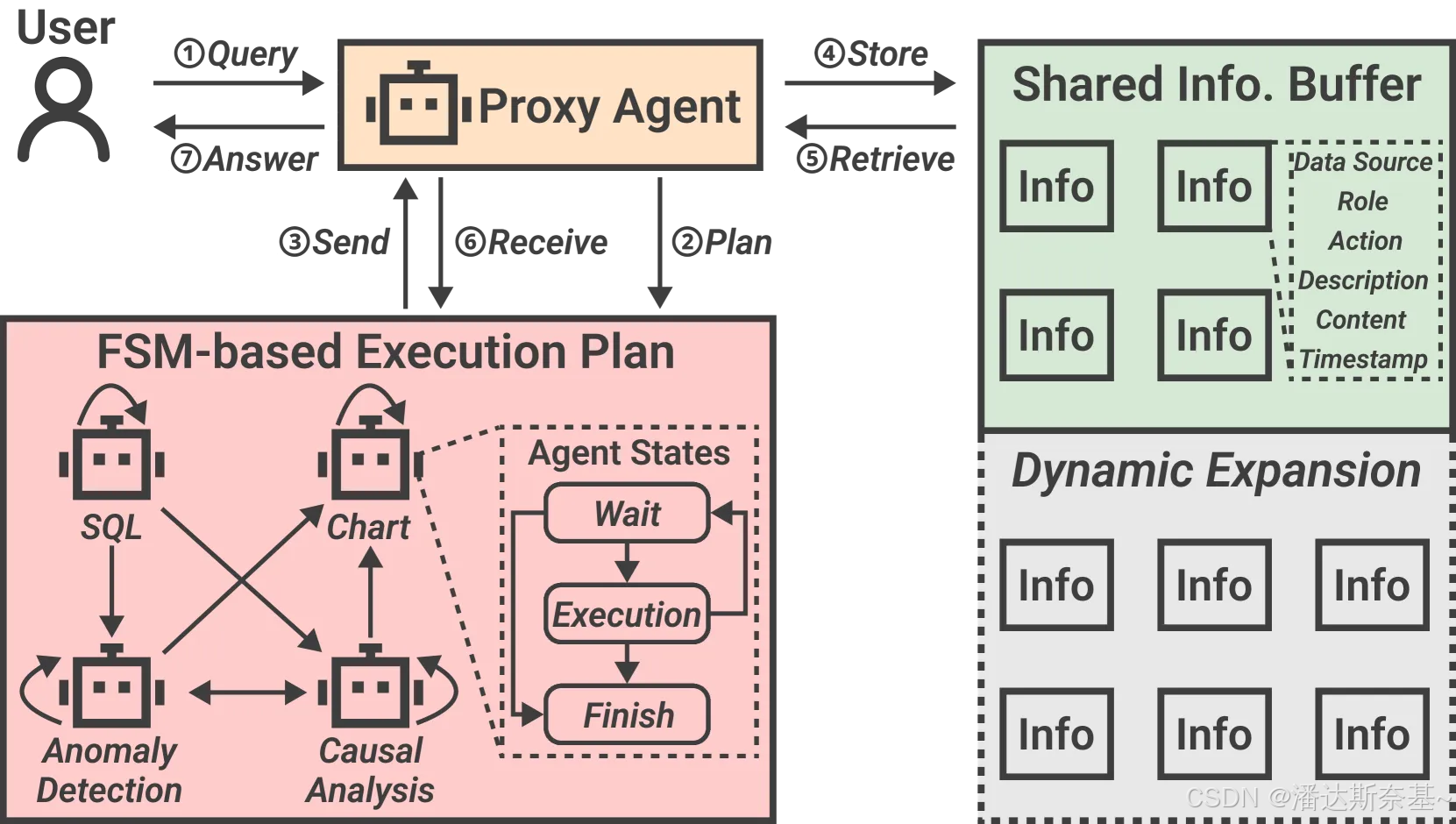
DataLab由两个主要组件组成:LLM-based Agent Framework 和 Computational Notebook Interface
- LLM-based Agent Framework
在 DataLab 中,根据用户需求为不同的 BI 任务设计了多个 Agent。为了实现这一目标,我们首先确定了几种常见的 BI 程序,并将它们抽象为代理在推理过程中可以调用的数据工具。示例工具包括用于代码执行的 Python 沙箱和用于可视化渲染的 Vega-Lite 环境。 - Computational Notebook Interface
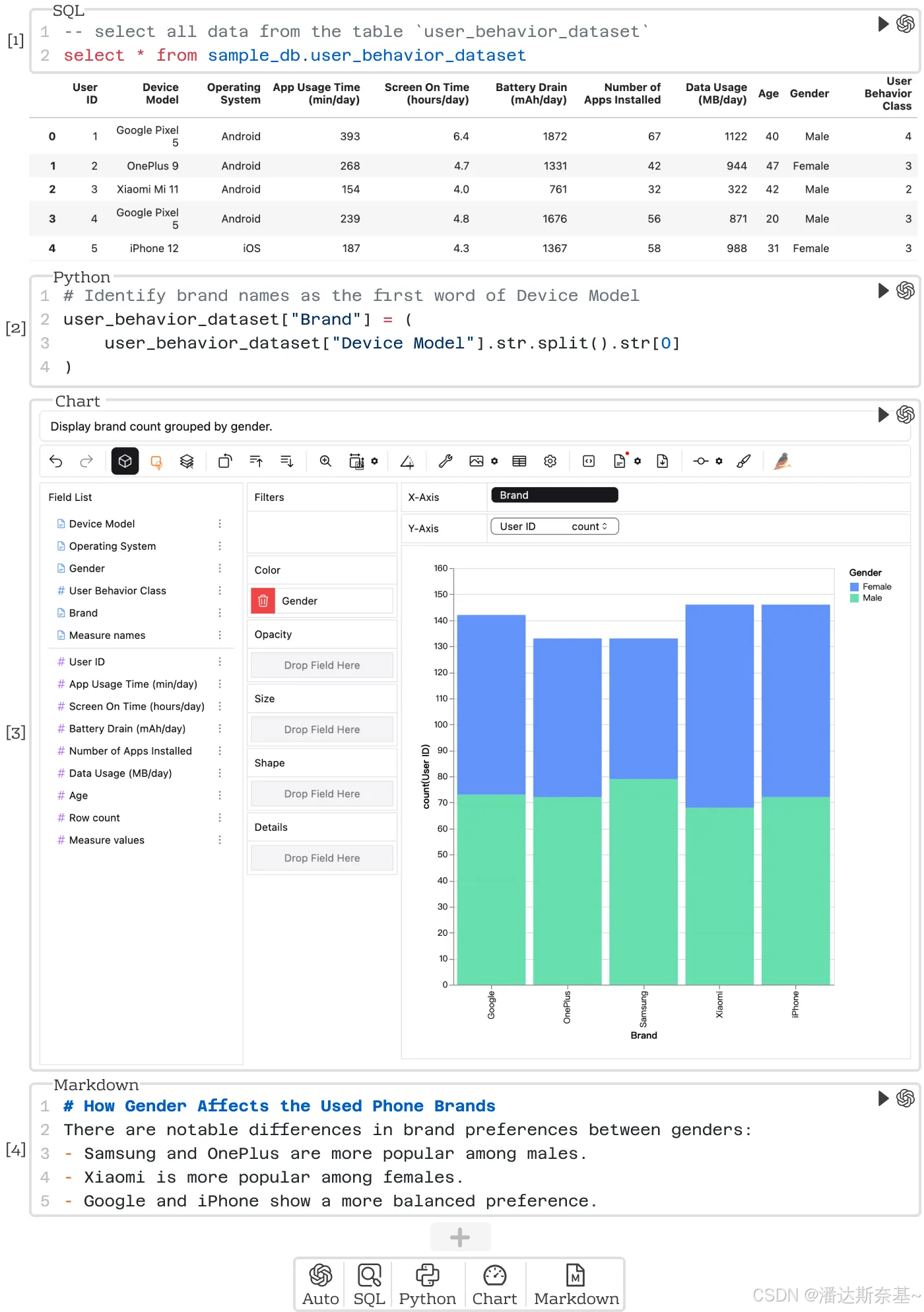
为不同的数据角色提供了一个统一的交互式协作环境,以完成其专业任务。为了实现这一目标,我们增强了 JupyterLab(一种广泛使用的笔记本界面)以支持多语言单元格和动态LLM帮助- SQL、Python/PySpark、Markdown 和 Chart 单元格组合在一起,使技术和非技术用户都可以在笔记本上轻松采用他们熟悉的工作流程
- 直接连接到后端数据库以执行 SQL 查询,并具有类似于 Tableau 的基于 GUI 的仪表板 以进行可视化创作
- 基于agent的框架无缝集成LLM到每个JupyterLab单元格中。用户可以在notebook级别和单元格级别获得LLM帮助。
3.2.2 工作流
DataLab工作流程是
- 接收到指令后,DataLab 首先分析数据集并解释查询,在将领域知识输送到LLMs
- DataLab 利用各种代理来完成任务,这涉及通过结构化通信机制相互共享信息
- 相应结果呈现在notebook上,用户可以接受、剪辑、拒绝结果,继续BI工作流
- 上下文管理策略会在notebook中自动生成和维护单元格依赖关系,促进下一步agent调用
3.2.3 三个关键模块
- 领域知识整合(Domain Knowledge Incorporation)
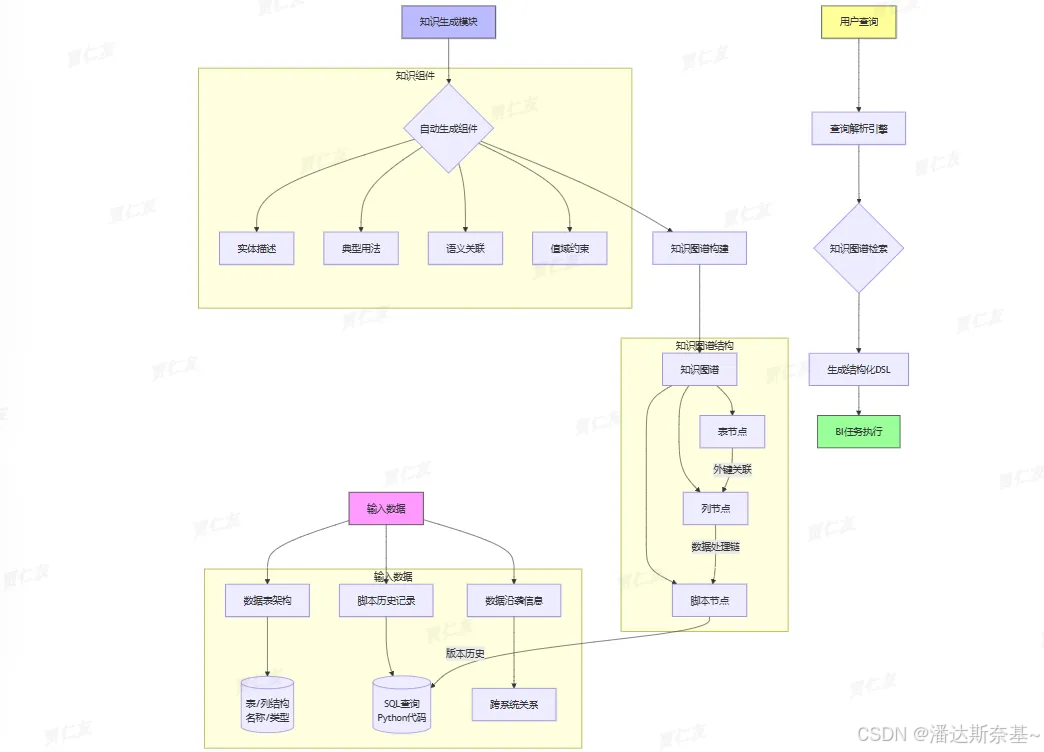
- 简单来说,领域知识整合模块接受三个输入:数据表的架构、关联的脚本历史记录(如SQL查询和Python代码),以及数据沿袭信息。然后,这个模块自动生成知识组件,组织成知识图谱,用于将模糊的用户查询转换为结构化的DSL(domain-specific languages (DSLs),提升BI任务性能。
- 流程:输入→处理→生成知识组件→构建知识图谱→转换查询→输出DSL→提升性能
- 代理间通信(Inter-Agent Communication)
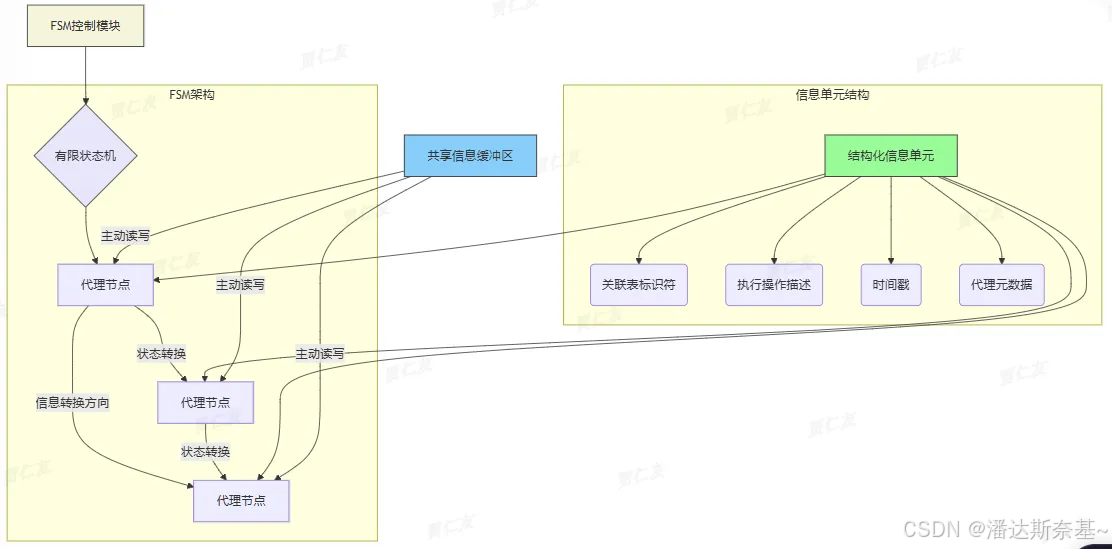
- 模块将agnet间的信息流建模为FSM,节点是agent,边是信息转换方向。
- 任务完成后,每个代理输出结构化信息单元,包含标识符和描述。
- 该模块存在一个共享的信息缓冲区,代理基于FSM主动交换信息,提高效率。
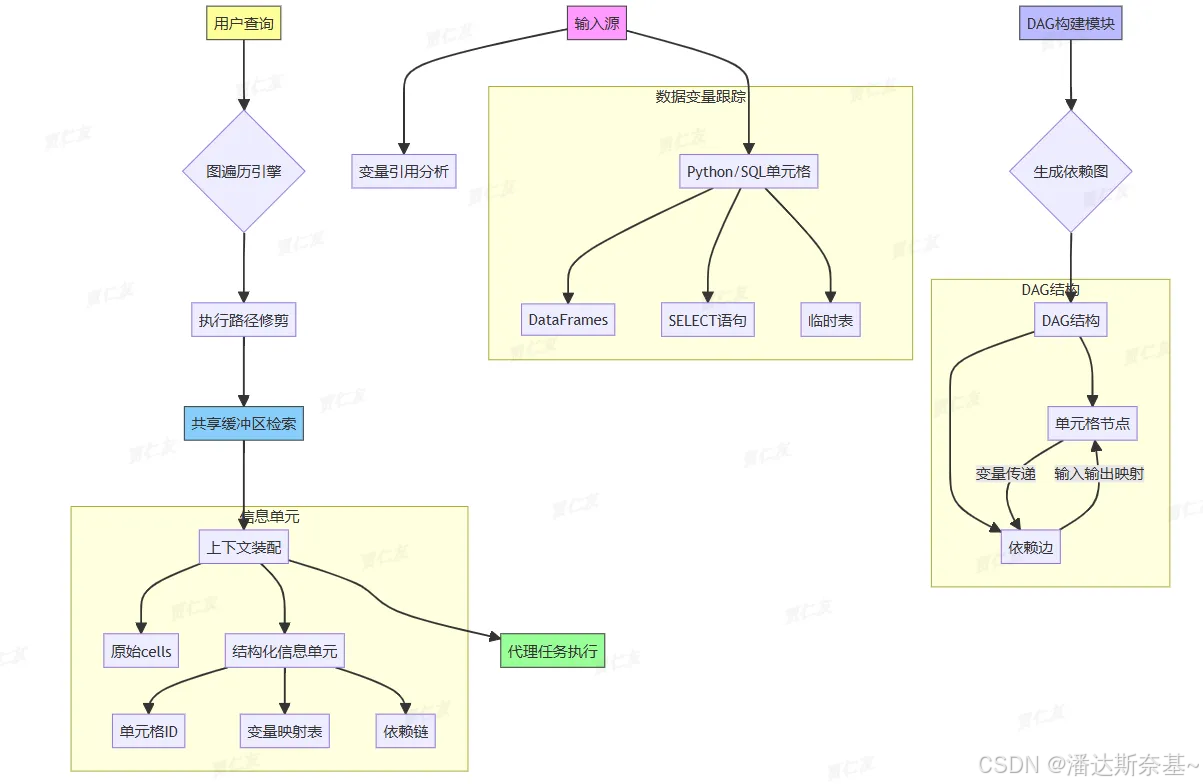
- 基于单元格的上下文管理(Cell-based Context Management)
流程:- 输入:变量引用和单元格内容(Python/SQL)
- DAG构建模块处理输入,生成DAG
- 用户查询触发遍历DAG,进行修剪
- 从共享缓冲区检索信息
- 生成上下文(原始单元格和信息单元)
- 代理使用上下文完成任务
3.3 领域知识整合
DataLab的领域知识整合包括三个阶段:知识生成、组织、利用
3.3.1 知识生成(Knowledge Generation)
腾讯提出一种基于LLM的知识生成的方法,利用脚本历史通过精心设计的提示技术来抽象和总结知识组件,这种自动方法包括一个带有自我校准机制的Map-Reduce过程,为数据库、表和列生成高质量的知识。
- 问题:在实际BI场景中,歧义普遍存在,表现在底层数据库和用户的 NL 查询中,列名和用户请求之间的语义关系通常很模糊,导致 LLMs’ 在此类任务上性能欠佳
- 解决方法:
传统方法是使用检索增强生成(RAG),其知识是由领域专家手动构建的,构建过程既乏味又耗时,使用的是元数据、业务逻辑、行话。
通过在腾讯进行的广泛检查,观察到虽然 85% 的表缺乏全面的元数据,但它们主要与用于数据处理的各种 SQL 或 Python 脚本相关联。这些脚本揭示了实际业务上下文中的常见使用模式。此外,对于那些缺少足够处理脚本的表,数据沿袭信息(阐明它们与整个组织中其他表或列的联系)为元数据插补提供了替代资源。因此,受到LLMs非凡的代码理解和推理能力的启发,我们提出了一种LLM基于知识生成的方法(算法 1),该方法利用脚本历史通过精心设计的提示技术来抽象和总结知识组件。这种自动化方法包括一个带有自我校准机制的 Map-Reduce 过程,为数据库、表和列生成高质量的知识。
3.3.2 知识组织(Knowledge Organization)
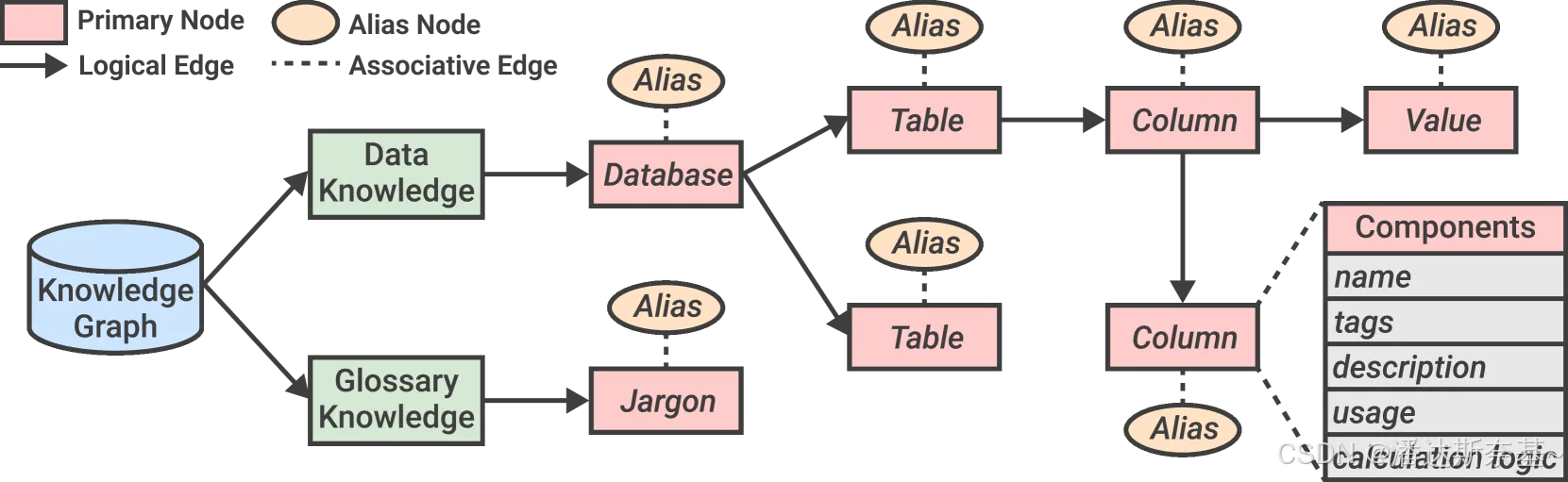
我们采用知识图 𝒢=(𝒱,ℰ)谱来系统地组织由我们的自动化方法(即元数据和业务逻辑)和手动构建的企业特定词汇表(即行话)生成的知识。
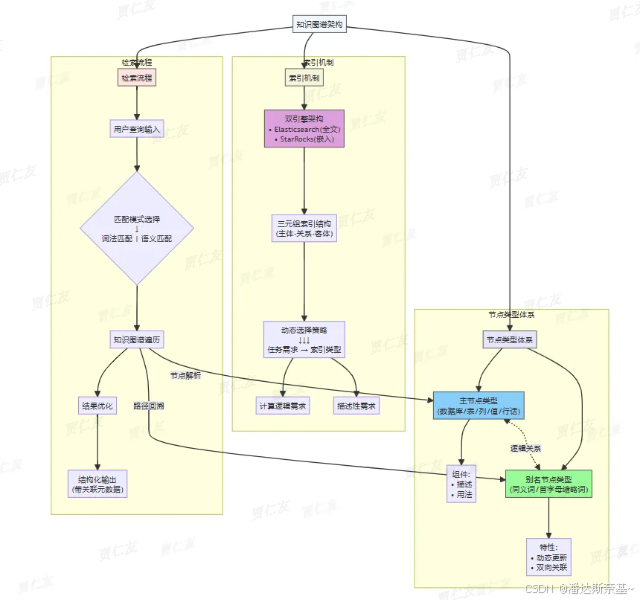
3.3.3 知识利用(Knowledge Utilization)
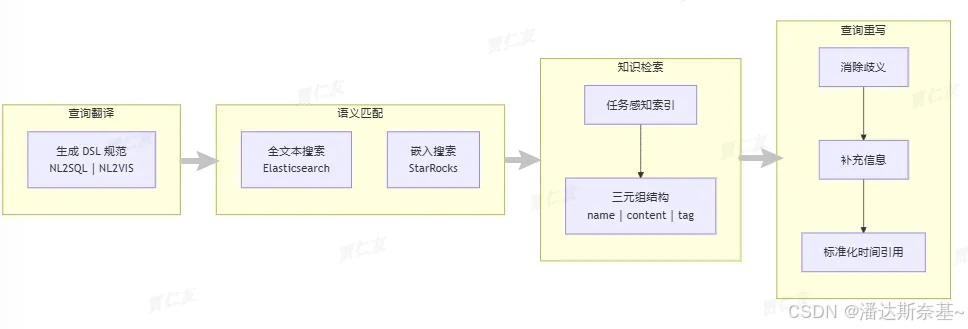
流程:
- 输入:查询𝒬
- 重写:重写它以提高清晰度和细节
- 知识检索:从知识图谱𝒢中检索其相关知识,采用从粗到细的方法来确保全面的精确地知识检索
- 知识翻译:查询被转换为DSL规范,以促进NL2SQL 和 NL2VIS 等下游任务
3.4 代理间通信
该模块目的是帮助多个 Agent 之间进行高效通信,以完成复杂的 BI 任务。
工作流程
- 初始化阶段
- 当用户提交一个查询时,代理框架中的代理(Agent)会首先进行分析,以制定一个执行计划。这个计划通常由有限状态机(FSM)定义,它描述了任务的各个子任务以及它们之间的依赖关系。
- 任务分配
- 执行计划将任务分解为多个子任务,并将这些子任务分配给不同的代理。每个代理负责执行特定的子任务。
- 信息共享
- 为了促进不同代理之间的协作,DataLab 设计了一个共享信息缓冲区(Shared Information Buffer)。每个代理在执行完其子任务后,会将结果信息存入共享缓冲区。
- 这种机制使得信息的生产者和消费者可以异步工作,减少了同步开销。生产者不需要等待消费者的反馈就可以继续处理,反之亦然。
- 信息格式化
- 为了提高信息共享的效率和准确性,DataLab 设计了一种结构化的信息格式。这种格式超越了纯自然语言,能够更好地表达代理之间的信息交换。
- 信息单元(Information Units)包含了关键特征,如相关表的标识符和代理执行的动作的简要描述。
- 动态管理
- 代理框架中的代理会根据任务进度动态管理信息共享。代理会从共享缓冲区检索信息,并将其传递给其他代理以支持子任务的执行。
- 最终结果生成
- 当所有子任务完成后,代理框架中的代理会从共享缓冲区收集所有信息,并生成最终的答案返回给用户
- 当所有子任务完成后,代理框架中的代理会从共享缓冲区收集所有信息,并生成最终的答案返回给用户
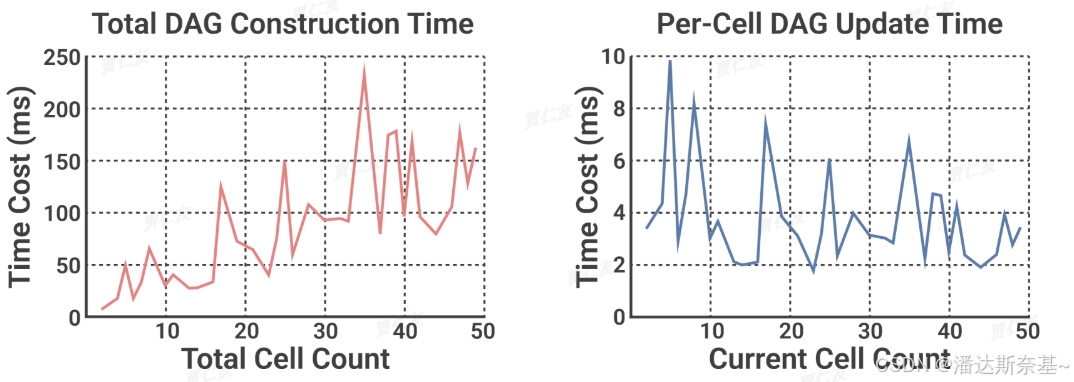
3.5 基于单元格的上下文管理
DataLab 的 Cell-based Context Management 模块通过构建和管理单元格之间的依赖关系,提高了计算notebook环境中上下文信息的利用效率。这种机制不仅提高了任务执行效率和准确性,还支持复杂的多步骤推理任务,增强了系统的灵活性和适应性。
在实际的BI使用中,通常涉及多个数据角色处理不同任务并在notbook上协作,会导致agent或者用户自己产生大量多语言单元格(python、SQL、chart)。如果简单地获取所有的单元格及其相关单元格信息是不切实际的,这样做效率低下,而且耗费token大。于是,腾讯将notebook中的单元格依赖关系建模为基于变量引用的 DAG,并提出了一种自适应上下文检索机制。
实现方法
- 构建依赖图(DAG):
- DataLab 使用有向无环图(DAG)来表示笔记本中单元格之间的依赖关系。每个节点代表一个单元格,边表示单元格之间的依赖关系。
- 通过分析单元格中的变量引用,DataLab 能够自动识别和构建这些依赖关系。
- 动态更新:
- 当用户修改某个单元格时,DataLab 会动态更新依赖图,以反映最新的依赖关系。
- 这种动态更新机制确保了上下文信息的实时性和准确性。
- 信息检索和利用:
- 在执行任务时,DataLab 会遍历依赖图,定位相关单元格,并从中提取必要的信息。
- 通过这种机制,DataLab 能够有效地利用上下文信息,避免重复计算和不必要的信息传递。
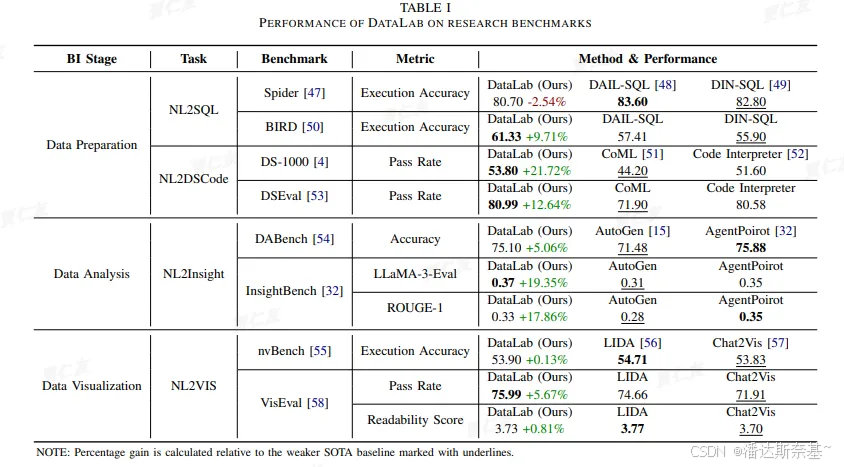
四 测评
4.1 整体
- NL2SQL 和 NL2VIS:
- DataLab 在这些任务上表现出色,准确率显著高于现有的基线方法。
- 在处理复杂的查询和多表连接时,DataLab 展示了其强大的推理能力。
- 数据清洗和特征工程:
- DataLab 在数据清洗任务中有效地识别和处理了数据中的错误和缺失值。
- 在特征工程任务中,DataLab 能够从原始数据中提取出有用的特征,显著提高了后续模型的性能。
- 模型训练和预测:
- 使用 DataLab 提取的特征,模型在训练和预测任务中表现出色,准确率和召回率均高于基线方法。
- DataLab 的上下文管理和多代理协作机制有效地提高了模型训练和预测的效率。
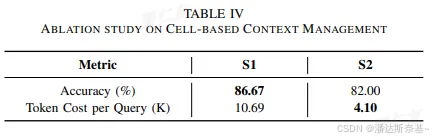
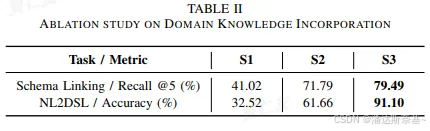
4.1 领域知识整合
设置额外提供生成的数据表和列的描述、用法和标记。它几乎占了我们实际部署中所有的成功案例。
进一步提供了数据表和列的所有生成知识,也可以有效提高准确率和召回率
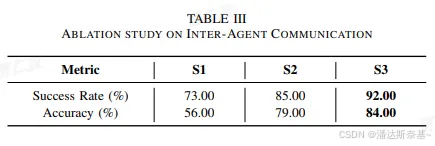
4.2 代理通讯
设置 FSM 和信息格式结构,可提高信息传递的效率和准确性
4.3 基于单元格的上下文管理
可以明显看到使用基于单元格的上下文管理后,从时间和token花费上都有明显下降,提高了效率