前言
高并发,几乎是每个程序员都想拥有的经验。原因很简单:随着流量变大,会遇到各种各样的技术问题,比如接口响应超时、CPU load升高、GC频繁、死锁、大数据量存储等等,这些问题能推动我们在技术深度上不断精进。
在过往的面试中,如果候选人做过高并发的项目,我通常会让对方谈谈对于高并发的理解,但是能系统性地回答好此问题的人并不多,大概分成这样几类:
1、对数据化的指标没有概念:不清楚选择什么样的指标来衡量高并发系统?分不清并发量和QPS,甚至不知道自己系统的总用户量、活跃用户量,平峰和高峰时的QPS和TPS等关键数据。
2、设计了一些方案,但是细节掌握不透彻:讲不出该方案要关注的技术点和可能带来的副作用。比如读性能有瓶颈会引入缓存,但是忽视了缓存命中率、热点key、数据一致性等问题。
3、理解片面,把高并发设计等同于性能优化:大谈并发编程、多级缓存、异步化、水平扩容,却忽视高可用设计、服务治理和运维保障。
4、掌握大方案,却忽视最基本的东西:能讲清楚垂直分层、水平分区、缓存等大思路,却没意识去分析数据结构是否合理,算法是否高效,没想过从最根本的IO和计算两个维度去做细节优化。
Linux 专题
微服务专题
- 微服务架构有哪些优势?
- 微服务有哪些特点?
- 设计微服务的最佳实践是什么?
- 微服务架构如何运作?
- 微服务架构的优缺点是什么?
- 单片,SOA 和微服务架构有什么区别?
- 在使用微服务架构时,您面临哪些挑战?
- SOA 和微服务架构之间的主要区别是什么?
- 什么是 REST / RESTful 以及它的用途是什么?
- 什么是不同类型的微服务测试?
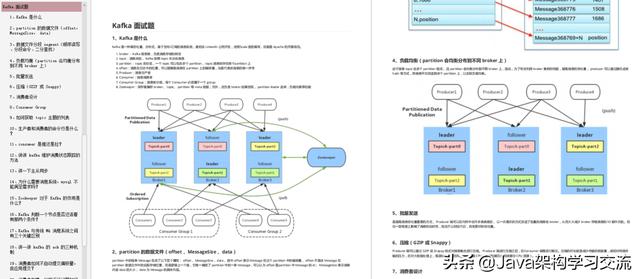
Kafka 专题
- Kafka 是什么
- 消费者设计
- 如何获取 topic 主题的列表
- 生产者和消费者的命令行是什么?
- 为什么需要消息系统,mysql 不能满足需求吗?
- Zookeeper 对于 Kafka 的作用是什么?
- Kafka 与传统 MQ 消息系统之间有三个关键区别
- 讲一讲 kafka 的 ack的三种机制
- kafka 的高可用机制是什么?
- kafka 如何不消费重复数据?比如扣款,我们不能重复的扣。
- kafka 分布式(不是单机)的情况下,如何保证消息的顺序消费?
Elasticsearch 专题
- Elasticsearch 了解多少,说说你们公司 es 的集群架构,索引数据大小,分片有多少,以及一些调优手段 。
- Elasticsearch 的倒排索引是什么
- Elasticsearch 是如何实现 master 选举的
- 详细描述一下 Elasticsearch 搜索的过程?
- Elasticsearch 是如何实现 Master 选举的?
- 客户端在和集群连接时,如何