一、目的
以图片2007_001960为例,voc数据集中的原图和对应的语义分割标签分别如下:

图1 图2
图像级标签WSSS任务第一阶段最后生成的pseudo mask如下:

图3
我们的目的是把最后一张图生成彩色模式(第二张图那样),方便比较分割结果。
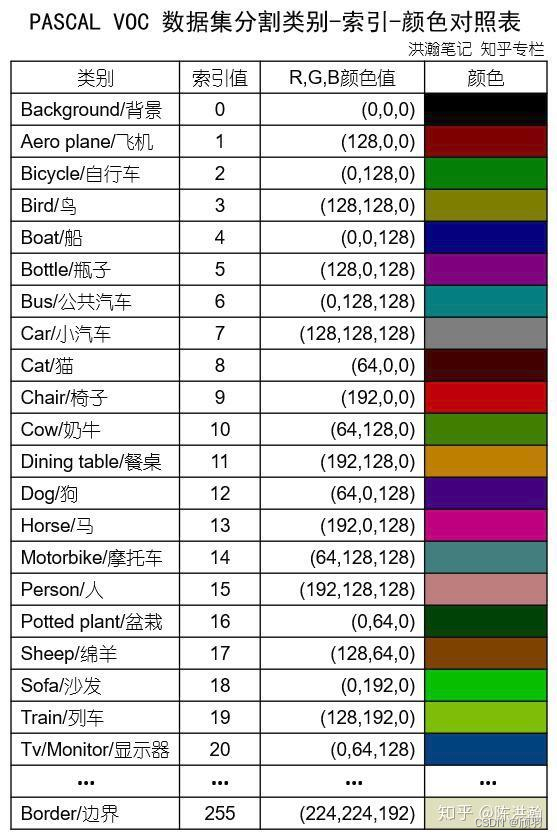
二、方法1(从voc标签中读取颜色类别信息)
参考文章PASCAL VOC数据集-分割标签索引颜色对照及程序中的代码。在voc数据集语义分割标签中随意找一张标签,读取图片的调色板信息,然后对我们的pseudo mask进行着色。
##测试voc的调色盘
from PIL import Image
import numpy as np
import imageio
#读取调色板信息
label_path = '/data6/VOCdevkit/VOC2012/SegmentationClass/2007_000033.png'
label_img = Image.open(label_path)
color_map = label_img.getpalette()
color_map_arr = np.array(color_map)
color_palette = np.reshape(color_map_arr,(256,1,3)).astype(np.uint8)
#读取pseudo mask,然后着色
gray_label=np.asarray(imageio.imread('./sem_seg/2007_001960.png'))
gray_label = Image.fromarray(gray_label,mode='L')
gray_label.putpalette(color_palette)
gray_label.save('new_img.png')
结果:

三、方法2(直接给类别编码颜色)
直接把voc的类别与颜色编码信息嵌入到代码中:
import numpy as np
import cv2
from PIL import Image
from matplotlib import pyplot as plt
# 获取VOC语义分割标签的类别颜色编码
def get_voc_color_encoding():
color_encoding = {
0: (0, 0, 0),
1: (128, 0, 0),
2: (0, 128, 0),
3: (128, 128, 0),
4: (0, 0, 128),
5: (128, 0, 128),
6: (0, 128, 128),
7: (128, 128, 128),
8: (64, 0, 0),
9: (192, 0, 0),
10: (64, 128, 0),
11: (192, 128, 0),
12: (64, 0, 128),
13: (192, 0, 128),
14: (64, 128, 128),
15: (192, 128, 128),
16: (0, 64, 0),
17: (128, 64, 0),
18: (0, 192, 0),
19: (128, 192, 0),
20: (0, 64, 128)
}
return color_encoding
# 将灰度标签转换为VOC语义分割标签的形式
def convert_gray_to_voc_label(gray_label):
voc_color_encoding = get_voc_color_encoding()
height, width = gray_label.shape[:2]
voc_label = np.zeros((height, width, 3), dtype=np.uint8)
# 使用灰度标签作为索引获取对应的颜色编码,并赋值给voc_label
for label in range(len(voc_color_encoding)):
indices = np.where(gray_label == label)
voc_label[indices] = voc_color_encoding[label]
return voc_label
# 读取灰度标签图像
gray_label = np.asarray(Image.open('./sem_seg/2007_001960.png'))
# 将灰度标签转换为VOC语义分割标签的形式
voc_label = convert_gray_to_voc_label(gray_label)
# 保存VOC语义分割标签图像
plt.imsave('voc_label_1.png', voc_label)
结果:

中间有一个小插曲,使用这个方法(最开始我是用opencv读取的图片),生成了这样的图片:
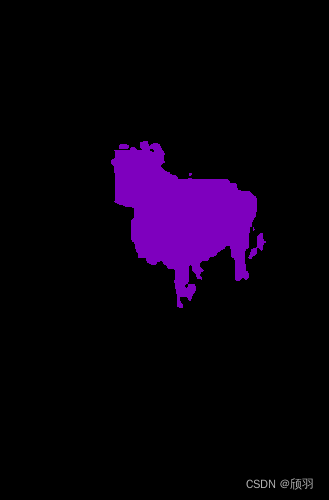
后来发现是opencv默认 读取和显示图片是bgr而非rgb,所以才出现颜色不一样的问题。具体可以参考文章基础知识(一) 图片格式RGB 与 BGR—— python、opencv、PIL、plt
四、其他说明
数据集标注的语音分割标签中前景的边界会有米色的边界。而我们生成的没有,是因为:在弱监督语义分割任务中,第一阶段是生成pseudo mask(伪掩膜),生成的掩膜每个像素位置的值都是类别。
对于voc中的标签和自己着色的标签,可能由于米色边界影响视觉看着不太一样,用着色器确认了一下,是一样的:

PS. 其中一些原理没有说明,后面有时间补充。