SparkStreaming
idea中初步实现
Spark core: SparkContext 核心数据结构:RDD
Spark sql: SparkSession 核心数据结构:DataFrame
Spark streaming: StreamingContext 核心数据结构:DStream(底层封装了RDD),遍历出其中的RDD即可进行sparkCore处理
Spark Streaming程序理论上是一旦启动,就不会停止,除非报错,人为停止,停电等其他突然场景导致程序终止
监控一个端口号中的数据,手动向端口号中打数据
master虚拟机上启动命令:nc -lk 12345,
ps aux | grep ‘nc -lk 10086’ , 找出该进程的端口号,kill -9 xxxx 来终止进程
若使用指令开启端口,**退出时应选择 ctrl+c(退出并终止进程),**使用ctrl+z只能退出界面,不能关闭该端口
1、案例一:
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Duration, Durations, StreamingContext}
object Demo1WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[2]") // 给定核数
conf.setAppName("spark Streaming 单词统计")
val sparkContext = new SparkContext(conf)
/**
* 创建Spark Streaming的运行环境,和前两个模块是不一样的
* Spark Streaming是依赖于Spark core的环境的
* this(sparkContext: SparkContext, batchDuration: Duration)
* Spark Streaming处理之前,是有一个接收数据的过程
* batchDuration,表示接收多少时间段内的数据
*/
val streamingContext = new StreamingContext(sparkContext, Durations.seconds(5))
/**
* Spark Streaming程序理论上是一旦启动,就不会停止,除非报错,人为停止,停电等其他突然场景导致程序终止
* 监控一个端口号中的数据,手动向端口号中打数据
* master虚拟机上启动命令:nc -lk 12345
*/
val rids: ReceiverInputDStream[String] = streamingContext.socketTextStream("master", 12345)
//hello world
val wordsDS: DStream[String] = rids.flatMap(_.split(" "))
val kvDS: DStream[(String, Int)] = wordsDS.map((_, 1))
val resDS: DStream[(String, Int)] = kvDS.reduceByKey(_ + _)
// val resDS: DStream[(String, Int)] = rids.flatMap(_.split(" "))
// .map((_, 1))
// .reduceByKey(_ + _)
println("--------------------------------------")
resDS.print()
println("--------------------------------------")
/**
* sparkStreaming启动的方式和前两个模块启动方式不一样
*/
streamingContext.start()
// 等待,根据上面设置的等待5秒钟(接收数据的时间)
streamingContext.awaitTermination()
// TODO:代表每个批次的开始和结束,并不是真的结束了
streamingContext.stop()
}
}
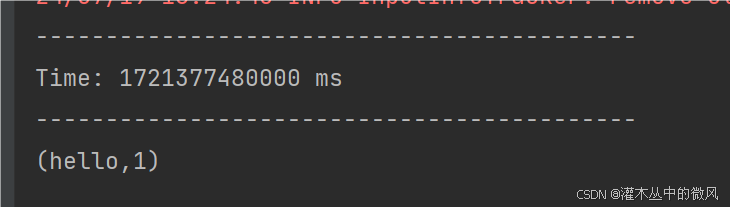
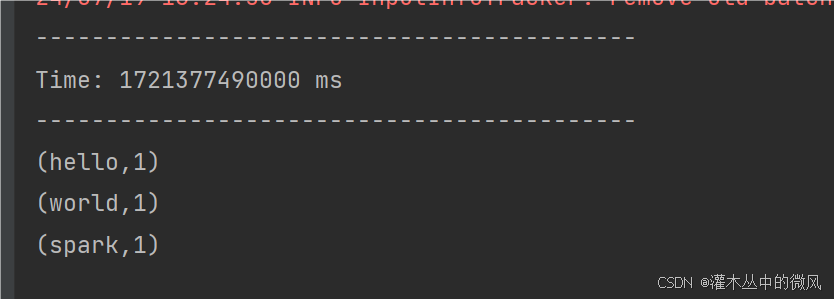
案例一的执行结果:
无法对依次输入的所有相同单词进行汇总
2、案例二:
实现对依次输入的所有相同单词进行汇总
需要使用有状态的算子来处理当前批次数据与历史数据的关系
updateStateByKey[S: ClassTag](updateFunc: (Seq[V], Option[S]) => Option[S]): DStream[(K, S)]
Seq: 序列,表示历史键对应的值组成的序列 (hello, seq:[1,1,1])
Option: 当前批次输入键对应的value值,如果历史中没有该键,这个值就是None, 如果历史中出现了这个键,这个值就是Some(值)
有状态算子使用注意事项:
1、有状态算子ByKey算子只适用于k-v类型的DStream
2、有状态算子使用的时候,需要提前设置checkpoint的路径,因为需要将历史批次的结果存储下来
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Durations, StreamingContext}
object Demo2WordCount2 {
def main(args: Array[String]): Unit = {
/**
* Spark core: SparkContext 核心数据结构:RDD
* Spark sql: SparkSession 核心数据结构:DataFrame
* Spark streaming: StreamingContext 核心数据结构:DStream(底层封装了RDD)
*/
val conf = new SparkConf()
conf.setMaster("local[2]") // 给定核数
conf.setAppName("spark Streaming 单词统计")
val sparkContext = new SparkContext(conf)
/**
* 创建Spark Streaming的运行环境,和前两个模块是不一样的
* Spark Streaming是依赖于Spark core的环境的
* this(sparkContext: SparkContext, batchDuration: Duration)
* Spark Streaming处理之前,是有一个接收数据的过程
* batchDuration,表示接收多少时间段内的数据
*/
val streamingContext = new StreamingContext(sparkContext, Durations.seconds(5))
//TODO :设置缓存,设置的是一个文件夹,用来存储缓存的数据
streamingContext.checkpoint("spark/data/checkpoint2")
/**
* Spark Streaming程序理论上是一旦启动,就不会停止,除非报错,人为停止,停电等其他突然场景导致程序终止
* 监控一个端口号中的数据,手动向端口号中打数据
* master虚拟机上启动命令:nc -lk 12345
*/
val rids: ReceiverInputDStream[String] = streamingContext.socketTextStream("master", 12345)
//hello world
val wordsDS: DStream[String] = rids.flatMap(_.split(" "))
val kvDS: DStream[(String, Int)] = wordsDS.map((_, 1)) // (hello,1) (hello,1) (hello,1)
/**
* 每5秒中resDS中的数据,是当前5s内的数据
* reduceByKey,只会对当前5s批次中的数据求和
*/
// val resDS: DStream[(String, Int)] = kvDS.reduceByKey(_ + _)
/**
* 需要使用有状态的算子来处理当前批次数据与历史数据的关系
*
* updateStateByKey[S: ClassTag](updateFunc: (Seq[V], Option[S]) => Option[S]): DStream[(K, S)]
* Seq: 序列,表示历史键对应的值组成的序列 (hello, seq:[1,1,1])
* Option: 当前批次输入键对应的value值,如果历史中没有该键,这个值就是None, 如果历史中出现了这个键,这个值就是Some(值)
* 有状态算子使用注意事项:
* 1、有状态算子ByKey算子只适用于k-v类型的DStream
* 2、有状态算子使用的时候,需要提前设置checkpoint的路径,因为需要将历史批次的结果存储下来
*/
val resDS: DStream[(String, Int)] = kvDS.updateStateByKey((seq1: Seq[Int], opt1: Option[Int]) => {
val sumValue: Int = seq1.sum
/**
* .getOrElse(0) 方法的作用是:如果Option容器包含的是Some(即值存在),则返回Some中包装的值;
* 如果Option容器是None(即值不存在),则返回括号中指定的默认值,在这个例子中是0。
*/
val num: Int = opt1.getOrElse(0)
Option(sumValue + num)
})
println("--------------------------------------")
resDS.print()
println("--------------------------------------")
/**
* sparkStreaming启动的方式和前两个模块启动方式不一样
*/
streamingContext.start()
streamingContext.awaitTermination()
streamingContext.stop()
}
}
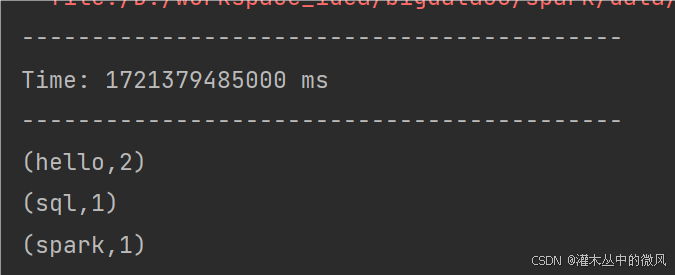
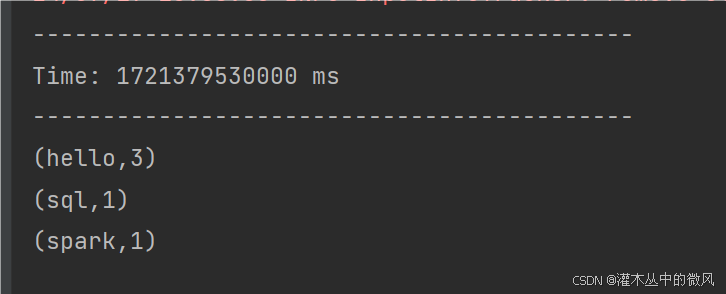
案例二执行结果:历史输入的相同的单词都会被统计
窗口类算子
1、如果只是为了计算当前批次接收的数据,直接调用reduceByKey
2、如果要将最新批次的数据与历史数据结合处理的话,需要调用有状态算子 updateStateByKey
3、如果要实现滑动窗口或者滚动窗口的话,需要使用窗口类算子reduceByKeyAndWindow
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object Demo3Window {
def main(args: Array[String]): Unit = {
/**
* 创建spark streaming的环境
* 旧版本创建的方式
*/
// val conf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("窗口案例")
// val context = new SparkContext(conf)
// val sc = new StreamingContext(context, Durations.seconds(5))
/**
* 新版本的创建方式
*/
val context: SparkContext = SparkSession.builder()
.master("local[2]")
.appName("窗口案例")
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate().sparkContext
/**
* 正常每次接收3s内的数据
* 注:这个时间为数据接收时间,目的是让时间与数据挂钩。
* 因为无法对监控端的数据进行定量,所以通过对时间定量的方式来对数据定量。
* 在逻辑上将数据想象为,一个个3s的时间间隔块,数据就存储在时间间隔块中。
* 这样以来就可以使用窗口所设置的参数(时间),窗口大小、滑动大小来进行任务的处理与执行。
*/
val sc = new StreamingContext(context, Durations.seconds(5))
//1000 ~ 65535(这些端口可用,但是有些特殊端口不可用,8088、8080、9870...)
val infoDS: ReceiverInputDStream[String] = sc.socketTextStream("master", 10086)
val wordsDS: DStream[String] = infoDS.flatMap(_.split(" "))
val kvDS: DStream[(String, Int)] = wordsDS.map((_, 1))
/**
* 1、如果只是为了计算当前批次接收的数据,直接调用reduceByKey
* 2、如果要将最新批次的数据与历史数据结合处理的话,需要调用有状态算子 updateStateByKey
* 3、如果要实现滑动窗口或者滚动窗口的话,需要使用窗口类算子reduceByKeyAndWindow
*/
/**
* def reduceByKeyAndWindow(reduceFunc: (V, V) => V,windowDuration: Duration,slideDuration: Duration): DStream[(K, V)]
* reduceFunc 编写处理相同的键对应的value值做处理
* windowDuration 设置窗口的大小
* slideDuration 设置滑动的大小
* 每间隔slideDuration大小的时间计算一次数据,计算数据的范围是最近windowDuration大小时间的数据
*/
val resDS: DStream[(String, Int)] = kvDS
.reduceByKeyAndWindow((v1: Int, v2: Int) => v1 + v2, Durations.seconds(10), Durations.seconds(5))
/**
* 当窗口大小与滑动大小一致的时候,那么就会从滑动窗口转变成滚动窗口的效果
*/
// val resDS: DStream[(String, Int)] = kvDS.reduceByKeyAndWindow((v1: Int, v2: Int) => v1 + v2, Durations.seconds(10), Durations.seconds(10))
resDS.print()
sc.start()
sc.awaitTermination()
sc.stop()
}
}
DStreamToRDD
方式一:
foreachRDD:在DS中使用rdd的语法操作数据
缺点:该函数是没有返回值的,无法返回一个新的DStream
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
object Demo4DStream2RDD {
def main(args: Array[String]): Unit = {
//使用DataFrame的语法
val sparkSession: SparkSession = SparkSession.builder()
.master("local[2]")
.appName("rdd与DStream的关系")
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
//使用RDD的语法
val sparkContext: SparkContext = sparkSession.sparkContext
//使用DStream的语法
val streamingContext = new StreamingContext(sparkContext, Durations.seconds(5))
val infoDS: ReceiverInputDStream[String] = streamingContext.socketTextStream("master", 10086)
//如果DS不是键值形式的话,可以单独调用window函数进行设置窗口的形式
val new_infoDS: DStream[String] = infoDS.window(Durations.seconds(10), Durations.seconds(5))
// hello world java hello java
/**
* foreachRDD:在DS中使用rdd的语法操作数据
* 缺点:该函数是没有返回值的
* 需求:我们在想使用DS中的RDD的同时,想要使用结束后,会得到一个新的DS
*/
new_infoDS.foreachRDD((rdd:RDD[String])=>{
println("------------------------------")
// sparkCore处理数据
val resRDD: RDD[(String, Int)] = rdd.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
resRDD.foreach(println)
// rdd和df之间可以转换
// sparkSql处理数据
val df1: DataFrame = rdd.toDF.select($"value" as "info")
df1.createOrReplaceTempView("words")
val resDF: DataFrame = sparkSession.sql(
"""
|select
|t1.wds as word,
|count(1) as counts
|from
|(
|select
|explode(split(info,' ')) as wds
|from words) t1
|group by t1.wds
|""".stripMargin)
resDF.show()
})
streamingContext.start()
streamingContext.awaitTermination()
streamingContext.stop()
}
}
方式二:
面试题:foreachRDD与transform的区别
transform也可以循环遍历出DStream中封装的RDD,并且在计算后还会返回一个新的DStream对象
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
/**
* 面试题:foreachRDD与transform的区别
*/
object Demo5Transformat {
def main(args: Array[String]): Unit = {
//使用DataFrame的语法
val sparkSession: SparkSession = SparkSession.builder()
.master("local[2]")
.appName("rdd与DStream的关系")
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
//使用RDD的语法
val sparkContext: SparkContext = sparkSession.sparkContext
//使用DStream的语法
val streamingContext = new StreamingContext(sparkContext, Durations.seconds(5))
val infoDS: ReceiverInputDStream[String] = streamingContext.socketTextStream("master", 10086)
val resDS: DStream[(String, Int)] = infoDS.transform((rdd: RDD[String]) => {
//直接对rdd进行处理,返回新的rdd
// val resRDD: RDD[(String, Int)] = rdd.flatMap(_.split(" "))
// .map((_, 1))
// .reduceByKey(_ + _)
// resRDD
//将rdd转df,使用sql做分析
//rdd和df之间可以转换
val df1: DataFrame = rdd.toDF.select($"value" as "info")
df1.createOrReplaceTempView("words")
val resDF: DataFrame = sparkSession.sql(
"""
|select
|t1.wds as word,
|count(1) as counts
|from
|(
|select
|explode(split(info,' ')) as wds
|from words) t1
|group by t1.wds
|""".stripMargin)
val resRDD: RDD[(String, Int)] = resDF.rdd.map((row: Row) => (row.getAs[String](0), row.getAs[Int](1)))
resRDD
})
resDS.print()
streamingContext.start()
streamingContext.awaitTermination()
streamingContext.stop()
}
}
将代码提交到yarn集群上运行
指令:spark-submit --master yarn --deploy-mode client --class com.shujia.streaming.Demo6YarnSubmit spark-1.0.jar
可以使用ctrl+c,退出并终止进程
杀死yarn上运行的进程(有时候直接退出不会终止进程):yarn application -kill application_1721466291251_0002
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.apache.spark.streaming.{Durations, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object Demo6YarnSubmit {
def main(args: Array[String]): Unit = {
//使用DataFrame的语法
val sparkSession: SparkSession = SparkSession.builder()
// .master("local[2]")
.appName("rdd与DStream的关系")
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
//使用RDD的语法
val sparkContext: SparkContext = sparkSession.sparkContext
//使用DStream的语法
val streamingContext = new StreamingContext(sparkContext, Durations.seconds(5))
val infoDS: ReceiverInputDStream[String] = streamingContext.socketTextStream("master", 10086)
val resDS: DStream[(String, Int)] = infoDS.transform((rdd: RDD[String]) => {
//直接对rdd进行处理,返回新的rdd
// val resRDD: RDD[(String, Int)] = rdd.flatMap(_.split(" "))
// .map((_, 1))
// .reduceByKey(_ + _)
// resRDD
//将rdd转df,使用sql做分析
//rdd和df之间可以转换
val df1: DataFrame = rdd.toDF.select($"value" as "info")
df1.createOrReplaceTempView("words")
val resDF: DataFrame = sparkSession.sql(
"""
|select
|t1.wds as word,
|count(1) as counts
|from
|(
|select
|explode(split(info,' ')) as wds
|from words) t1
|group by t1.wds
|""".stripMargin)
val resRDD: RDD[(String, Int)] = resDF.rdd.map((row: Row) => (row.getAs[String](0), row.getAs[Int](1)))
resRDD
})
resDS.print()
streamingContext.start()
streamingContext.awaitTermination()
streamingContext.stop()
}
}
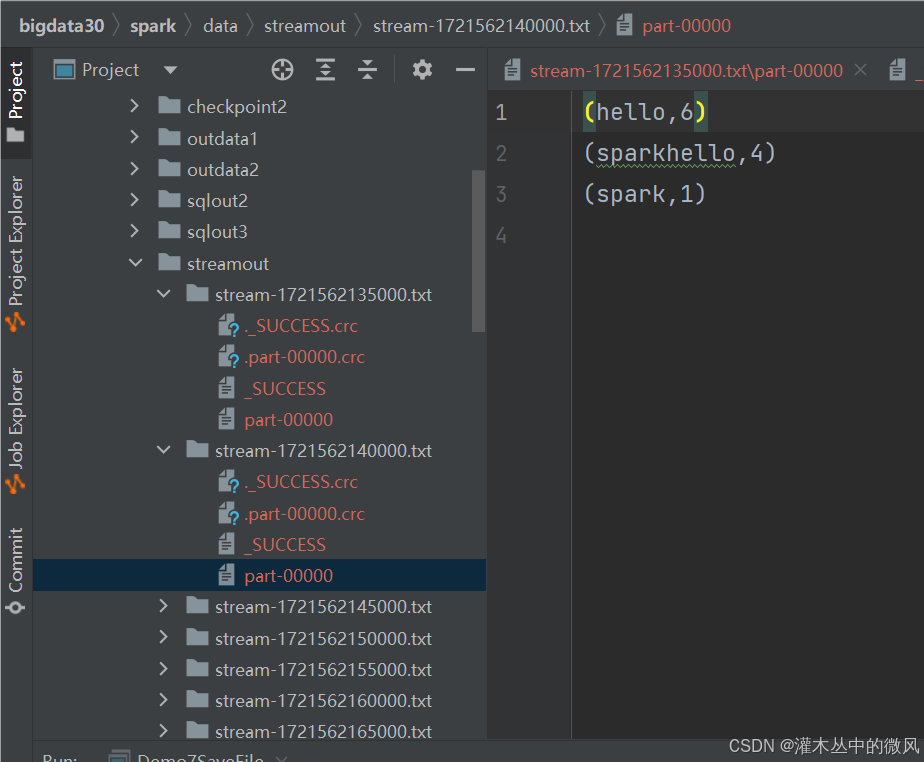
读取一个端口中数据写入到本地
saveAsTextFiles
- 将结果存储到磁盘中
- 只能设置文件夹的名字和文件的后缀
- 每一批次运行,都会产生新的小文件夹,文件夹中有结果数据文件
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.apache.spark.streaming.{Durations, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object Demo7SaveFile {
def main(args: Array[String]): Unit = {
//使用DataFrame的语法
val sparkSession: SparkSession = SparkSession.builder()
.master("local[2]")
.appName("rdd与DStream的关系")
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
//使用RDD的语法
val sparkContext: SparkContext = sparkSession.sparkContext
//使用DStream的语法
val streamingContext = new StreamingContext(sparkContext, Durations.seconds(5))
val infoDS: ReceiverInputDStream[String] = streamingContext.socketTextStream("master", 10086)
val resDS: DStream[(String, Int)] = infoDS.transform((rdd: RDD[String]) => {
//直接对rdd进行处理,返回新的rdd
// val resRDD: RDD[(String, Int)] = rdd.flatMap(_.split(" "))
// .map((_, 1))
// .reduceByKey(_ + _)
// resRDD
//将rdd转df,使用sql做分析
//rdd和df之间可以转换
val df1: DataFrame = rdd.toDF.select($"value" as "info")
df1.createOrReplaceTempView("words")
val resDF: DataFrame = sparkSession.sql(
"""
|select
|t1.wds as word,
|count(1) as counts
|from
|(
|select
|explode(split(info,' ')) as wds
|from words) t1
|group by t1.wds
|""".stripMargin)
val resRDD: RDD[(String, Int)] = resDF.rdd.map((row: Row) => (row.getAs[String](0), row.getAs[Int](1)))
resRDD
})
// resDS.print()
/**
* 将结果存储到磁盘中
* 只能设置文件夹的名字和文件的后缀
* 每一批次运行,都会产生新的小文件夹,文件夹中有结果数据文件
*/
resDS.saveAsTextFiles("spark/data/streamout/stream","txt")
streamingContext.start()
streamingContext.awaitTermination()
streamingContext.stop()
}
}
读取一个端口中的数据写入到MySQL中
在写入数据时,会涉及到数据库连接对象、预编译对象连续创建的问题
方案一:
数据库连接对象、预编译对象会连续创建
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Durations, StreamingContext}
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import java.sql.{Connection, DriverManager, PreparedStatement}
object Demo8DS2Mysql {
def main(args: Array[String]): Unit = {
//使用DataFrame的语法
val sparkSession: SparkSession = SparkSession.builder()
.master("local[2]")
.appName("rdd与DStream的关系")
/**
* 这个配置是全局的,并且专门用于Spark SQL中的shuffle操作。它设置了在进行shuffle操作时,默认使用的分区数。
* Shuffle操作通常发生在需要跨多个节点重新分发数据的场景中,比如join、groupBy等操作。
*/
.config("spark.sql.shuffle.partitions", "1")
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
//使用RDD的语法
val sparkContext: SparkContext = sparkSession.sparkContext
//使用DStream的语法
val streamingContext = new StreamingContext(sparkContext, Durations.seconds(5))
val infoDS: ReceiverInputDStream[String] = streamingContext.socketTextStream("master", 10086)
infoDS.foreachRDD((rdd:RDD[String])=>{
println("======================= 正在处理一批数据 ==========================")
//处理rdd中每一条数据
rdd.foreach((line:String)=>{
//如果将创建连接的代码写在这里,这样的话,每条数据都会创建一次连接
/**
* 创建与数据库连接对象
*/
//注册驱动
Class.forName("com.mysql.jdbc.Driver")
//创建数据库连接对象
val conn: Connection = DriverManager.getConnection(
"jdbc:mysql://master:3306/bigdata30?useUnicode=true&characterEncoding=UTF-8&useSSL=false",
"root",
"123456"
)
//创建预编译对象
val statement: PreparedStatement = conn.prepareStatement("insert into students values(?,?,?,?,?)")
val info: Array[String] = line.split(",")
statement.setInt(1,info(0).toInt)
statement.setString(2,info(1))
statement.setInt(3,info(2).toInt)
statement.setString(4,info(3))
statement.setString(5,info(4))
//执行sql语句
statement.executeUpdate()
//释放资源
statement.close()
conn.close()
})
})
streamingContext.start()
streamingContext.awaitTermination()
streamingContext.stop()
}
}
方案二:
设想中的改造
- 我们将原本在rdd中创建连接的代码放到了ds遍历RDD中,发现PreparedStatement不能与task任务一起序列化到executor中的
- 这样的写法是不可以的!!!
infoDS.foreachRDD((rdd: RDD[String]) => {
println("======================= 正在处理一批数据 ==========================")
//如果将创建连接的代码写在这里,这样的话,每条数据都会创建一次连接
/**
* 创建与数据库连接对象
*/
//注册驱动
Class.forName("com.mysql.jdbc.Driver")
//创建数据库连接对象
val conn: Connection = DriverManager.getConnection(
"jdbc:mysql://master:3306/bigdata30?useUnicode=true&characterEncoding=UTF-8&useSSL=false",
"root",
"123456"
)
//创建预编译对象
val statement: PreparedStatement = conn.prepareStatement("insert into students values(?,?,?,?,?)")
//处理rdd中每一条数据
rdd.foreach((line: String) => {
val info: Array[String] = line.split(",")
statement.setInt(1, info(0).toInt)
statement.setString(2, info(1))
statement.setInt(3, info(2).toInt)
statement.setString(4, info(3))
statement.setString(5, info(4))
//执行sql语句
statement.executeUpdate()
})
//释放资源
statement.close()
conn.close()
})
方案三:
rdd中有一个算子foreachPartition
- rdd本质是由一系列分区构成的,如果我们可以将分区数设置为1,每个分区只创建一个连接即可
- RDD中只有一个分区,只需在遍历该分区时创建一次数据库连接对象、预编译对象
infoDS.foreachRDD((rdd: RDD[String]) => {
println("======================= 接收到 5s 一批次数据 ==========================")
/**
* 这个操作是针对特定的RDD(弹性分布式数据集)的,用于重新划分RDD的分区。
* 它强制Spark对RDD中的元素进行重新分配,以符合指定的分区数。
*/
rdd.repartition(1)
println(s" DS封装的RDD中的分区数为:${rdd.getNumPartitions} ")
/**
* foreachPartition,处理一个分区的数据
* 将一个分区的数据,封装成了一个迭代器
*/
rdd.foreachPartition((itr: Iterator[String]) => {
println("======================= 正在处理一个分区的数据 ==========================")
//如果将创建连接的代码写在这里,这样的话,每条数据都会创建一次连接
/**
* 创建与数据库连接对象
*/
//注册驱动
Class.forName("com.mysql.jdbc.Driver")
//创建数据库连接对象
val conn: Connection = DriverManager.getConnection(
"jdbc:mysql://master:3306/bigdata_30?useUnicode=true&characterEncoding=UTF-8&useSSL=false",
"root",
"123456"
)
//创建预编译对象
val statement: PreparedStatement = conn.prepareStatement("insert into students2 values(?,?,?,?,?)")
println("========================= 创建了一次连接 =========================")
itr.foreach((line: String) => {
val info: Array[String] = line.split(",")
statement.setInt(1, info(0).toInt)
statement.setString(2, info(1))
statement.setInt(3, info(2).toInt)
statement.setString(4, info(3))
statement.setString(5, info(4))
//执行sql语句
statement.executeUpdate()
})
statement.close()
conn.close()
})
})